Working with the RedshiftToS3Transfer operator and Amazon Managed Workflows for Apache Airflow
Published May 15, 2021
Reading time 18 minutes
Introduction
Inspired by a recent conversation within the Apache Airflow open source slack community, I decided to channel the inner terrier within me to tackle this particular issue, around getting an Apache Airflow operator (the protagonist for this post) to work.
I found the perfect catalyst in the way of the original launch post of Amazon Managed Workflows for Apache Airflow (MWAA). As is often the way, diving into that post (creating a workflow to take some source files, transform them and then move them into Amazon Redshift) led me down some unexpected paths to here, this post.
What I hope you will learn by reading this post is a) how to replicate the original workflow from the launch post for yourself, and b) an additional step of taking the tables from that Amazon Redshift database and exporting them to Amazon S3, a common use case that data engineers are asked to do.
In that second part we meet the main actor, the RedshiftToS3Transfer operator, and get to know how to set it up and get it going.
Let’s get started.
What will you need
- An AWS account with the right level of privileges
- The latest/up to date aws cli - at least version 1.19.73 / 2.24
- A MWAA environment up and running - may I suggest you check out some of my earlier blog post like this one if you are familiar with AWS CDK or this one, if you are not.
You will find source code for this post at the usual place, my residence over on GitHub
NOTE! You will see some output in this walkthrough that contains aws credentials (aws_access/secret_keys) but don’t worry these are not real ones!
Costs
When I ran this and took a look at my AWS bill, it was around $50 for the 5-6 hours I was playing around putting this blog post together. Make sure you cleanup/delete all the resources after you have finished!
Getting Started
The first thing we need to do is setup the Amazon Redshift cluster. To make this easy, I have created a CDK app that builds everything you need.
├── cdk
│ └── mwaa-redshift
│ ├── app.py
│ ├── cdk.json
│ ├── files
│ │ └── readme.txt
│ ├── mwaa_redshift
│ │ ├── mwaa_redshift_stack.py
│ │ └── mwaa_redshift_vpc.py
│ └── requirements.txt
├── dags
│ ├── movielens-redshift-s3.py
│ └── movielens-redshift.py
└── variables.json
If you look at the app.py file, it contains the following configuration options you will need to change for your own setup.
env_EU=core.Environment(region="eu-west-1", account="XXXXXXXXXX")
props = {
'redshifts3location': 'mwaa-redshift-blog',
'mwaadag' : 'airflow-094459',
'mwaa-sg':'sg-01f25764ea72db0f2',
'mwaa-vpc-id':'vpc-001c3b06c3e39c278',
'redshiftclustername':'mwaa-redshift-clusterxxx',
'redshiftdb':'mwaa',
'redshiftusername':'awsuser'
}
I have commented the code, but the first parameter (redshifts3location) is the name of the NEW S3 bucket you will create. This should not exist or the deployment will fail. The next one (mwaadag) is the location of the MWAA Dags folder, the (mwaa-sg) is the name of the security group for your MWAA environment, which the deployment will amend to add an additional ingress rule for Redshift, and finally (mwaa-vpc-id) the VPC id which is used to populate the Redshift subnet group to enable connectivity.
The next three configure the Amazon Redshift environment, providing the cluster name (redshiftclustername), the default database that will be created (redshiftdb) and then the name of the Redshift admin user name (redshiftusername). The password will be auto generated and stored in AWS Secrets Manager.
Finally, make sure you adjust your environment details (region/account) to reflect your own environment.
Once you have changed this values for your own environment, you can deploy the stack.
$ cd cdk/mwaa-redshift
$ cdk deploy MWAA-Redshift-VPC
$ cdk deploy MWAA-Redshift-Cluster
You will be prompted about proceeding (this is a nice feature of CDK which asks you to confirm when there are security related changes being made). If the deployment has been successful, you should see output which you will use later on.
✅ MWAA-RedShift-Cluster
Outputs:
MWAA-RedShift-Cluster.MWAAVPCESG = mwaa-redshift-cluster-mwaavperedshiftxxx-1n5aroq4bokge
MWAA-RedShift-Cluster.RedshiftClusterEndpoint = mwaa-redshift-clusterxxx.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com
MWAA-RedShift-Cluster.RedshiftIAMARN = arn:aws:iam::XXXXXXXXXX:role/MWAA-RedShift-Cluster-mwaaredshiftservicerole2nd63-1HKOCE7NNXXXX
MWAA-RedShift-Cluster.RedshiftSecretARN = arn:aws:secretsmanager:eu-west-1: XXXXXXXXXX㊙️MWAARedshiftClusterSecret9B-SBoNAJOCWZFN-xXxXxX
MWAA-Redshift-Cluster.redshiftvpcendpointcli = aws redshift create-endpoint-access --cluster-identifier mwaa-redshift-clusterxxx --resource-owner XXXXXXXXXX --endpoint-name mwaa-redshift-endpoint --subnet-group-name mwaa-redshift-cluster-mwaavperedshiftcsg-1n2p5ro6twlrr --vpc-security-group-ids sg-01f25764ea71db0f2
You can have a look at the Amazon Redshift console if you want and you should see the new cluster ready to go.
Update permissions for your MWAA environment
Now that the Amazon Redshift cluster has been setup, we have a new Amazon S3 bucket (in my demo, it is called “mwaa-redshift-blog” - it should have a folder called “files”) that will be used to download data from the web, transform it and then ingest into Amazon Redshift.
We need to add some additional permissions to the MWAA Execution policy so that it can read/write files in the new S3 bucket we are going to be using to download the files (and then later exporting them back). In my MWAA environment, I amend my policy as follows, by adding “mwaa-redshift-blog” to the resources MWAA can access ():
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::airflow-094459",
"arn:aws:s3:::airflow-094459/*",
"arn:aws:s3:::mwaa-redshift-094459",
"arn:aws:s3:::mwaa-redshift-094459/*",
"arn:aws:s3:::mwaa-redshift-blog",
"arn:aws:s3:::mwaa-redshift-blog/*"
]
},
Whist we are talking about permissions, as part of the Redshift cluster deployment, a new IAM Role is created (you can see the name in the outputs once the CDK app has completed). If you take a look at the permissions, you will see it looks like the following:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::mwaa-redshift-blog/*",
"arn:aws:s3:::mwaa-redshift-blog",
"arn:aws:s3:::airflow-094459/*",
"arn:aws:s3:::airflow-094459"
],
"Effect": "Allow"
}
]
}
We have only given it access to our new folder as well as the MWAA Dags folder. We could tighten this up further by removing the specific S3 actions needed, so experiment removing those until you get something that works.
Uploading and running the movielens DAG
Now that we have all the infrastructure ready to go, it is time to create our workflow/DAG. I have modified the original DAG from the blog post slightly, and you will need to do a few things before we are ready to go.
You can find the DAG here, movielens-redshift.py. If we take a look at the DAG, we can see the following section:
test_http = Variable.get("test_http", default_var="undefined")
download_http = Variable.get("download_http", default_var="undefined")
s3_bucket_name = Variable.get("s3_bucket_name", default_var="undefined")
s3_key = Variable.get("s3_key", default_var="undefined")
redshift_cluster = Variable.get("redshift_cluster", default_var="undefined")
redshift_db = Variable.get("redshift_db", default_var="undefined")
redshift_dbuser = Variable.get("redshift_dbuser", default_var="undefined")
redshift_table_name = Variable.get("redshift_table_name", default_var="undefined")
redshift_iam_arn = Variable.get("redshift_iam_arn", default_var="undefined")
redshift_secret_arn = Variable.get("redshift_secret_arn", default_var="undefined")
athena_db = Variable.get("demo_athena_db", default_var="undefined")
athena_results = Variable.get("athena_results", default_var="undefined")
So we do not have to hard code references, we use Apache Airflow variables to store the configuration details. This makes this workflow much easier to re-purpose.
In the GitHub repo you will find a file called variables.json which when you look at it:
{
"athena_results": "athena-results/",
"download_http": "http://files.grouplens.org/datasets/movielens/ml-latest-small.zip",
"s3_key": "files/",
"test_http": "https://grouplens.org/datasets/movielens/latest/",
"aws_connection": "aws_redshift",
"demo_athena_db": "demo_athena_db",
"redshift_airflow_connection": "redshift_default",
"redshift_cluster": "mwaa-redshift",
"redshift_db": "mwaa",
"redshift_dbuser": "awsuser",
"redshift_table_name": "movie_demo",
"redshift_iam_arn": "arn:aws:iam::XXXXXXXXXXX:role/RedShift-MWAA-Role",
"redshift_secret_arn": "arn:aws:secretsmanager:eu-west-1:XXXXXXXXXX㊙️mwaa-redshift-cluster-XXXXX",
"s3_bucket_name": "mwaa-redshift-blog"
}
You WILL need to modify the last three variables (redshift_iam_arn, redshift_secret_arn and s3_bucket_name) using the values that were output as part of the Redshift cluster build. Once amended you can then import these into MWAA via the Apache Airflow UI. Once you have done this, you should have a list of the variables with the values listed. MWAA stores these securely in the MWAA metstore database. If you prefer, you could change the configuration of MWAA to look for variables in AWS Secrets Manager, and then manage these values via CDK perhaps - for this post I am keeping it simple and just using standard variables through the Apache Airflow UI.
The rest of the DAG is the same as the blog post, and you should deploy this to your DAGS folder via your preferred method (I use a very simple CI/CD system which you can replicate for yourself in my blog post, A simple CI/CD system for your Amazon Managed Workflows for Apache Airflow development workflow
Once you have uploaded it you should see it in the main Apache Airflow UI.
Triggering the DAG
We should be ready to go now. From the UI you can turn on/enable and then trigger the DAG called movielens-refshift and the workflow should take around 5-10 minutes to complete. If the workflow looks all dark green, then you should be good.
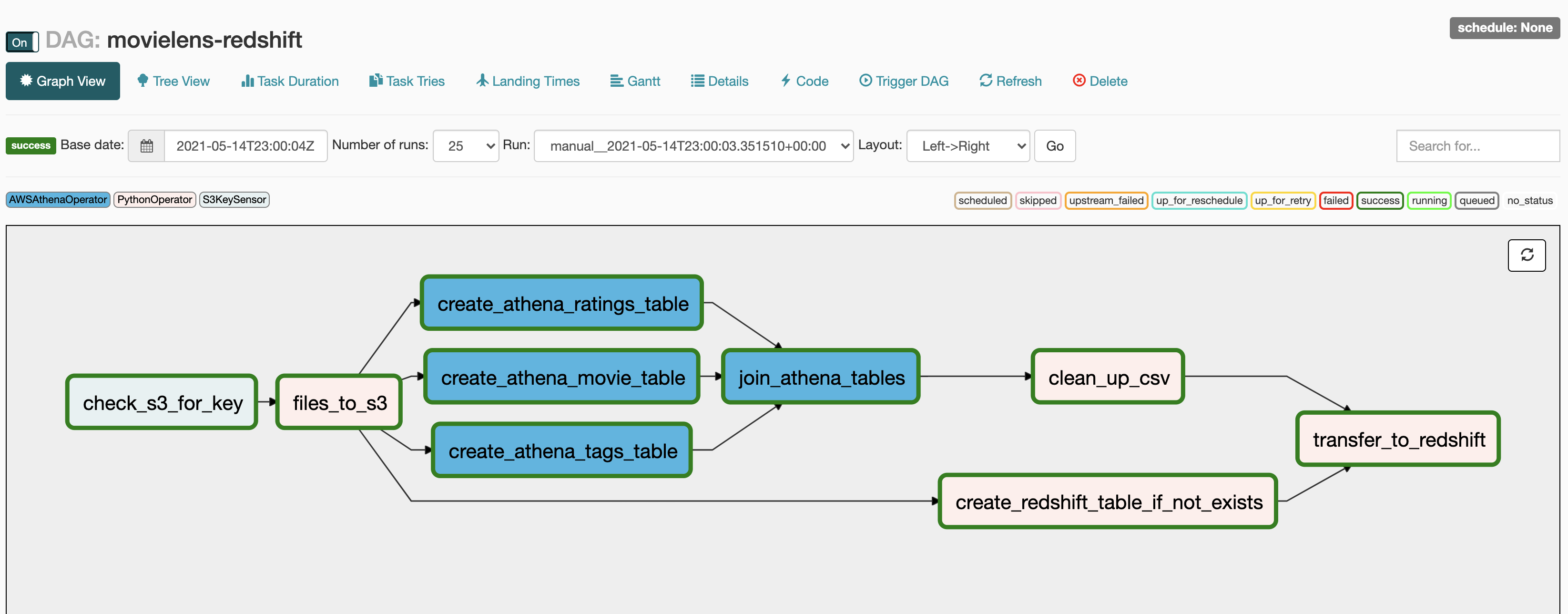
If you look at the logs you should see something like:
[2021-05-14 23:01:41,762] {{logging_mixin.py:112}} INFO - Running %s on host %s <TaskInstance: movielens-redshift.transfer_to_redshift 2021-05-14T23:00:03.351510+00:00 [running]> ip-10-192-21-59.eu-west-1.compute.internal
[2021-05-14 23:01:41,873] {{logging_mixin.py:112}} INFO - b8535f99-89a3-4036-9cb3-502a19397f8d
[2021-05-14 23:01:41,898] {{logging_mixin.py:112}} INFO - s3://mwaa-redshift-blog/athena-results/join_athena_tables/b8535f99-89a3-4036-9cb3-502a19397f8d_clean.csv
[2021-05-14 23:01:41,921] {{logging_mixin.py:112}} INFO - copy movie_demo from 's3://mwaa-redshift-blog/athena-results/join_athena_tables/b8535f99-89a3-4036-9cb3-502a19397f8d_clean.csv' iam_role 'arn:aws:iam::704533066374:role/MWAA-RedShift-Cluster-mwaaredshiftservicerole2nd63-1WNFQCTTKXXXX' CSV IGNOREHEADER 1;
[2021-05-14 23:01:42,144] {{logging_mixin.py:112}} INFO - {'ClusterIdentifier': 'mwaa-redshift-clusterxxx', 'CreatedAt': datetime.datetime(2021, 5, 14, 23, 1, 42, 24000, tzinfo=tzlocal()), 'Database': 'mwaa', 'Id': 'cf455937-21ab-4399-95fa-cf3c60703688', 'SecretArn': 'arn:aws:secretsmanager:eu-west-1:xxxxxxxxx㊙️MWAARedshiftClusterSecret9B-687wkB7p4hID-xxxxx', 'ResponseMetadata': {'RequestId': '3c1c47c5-a3b4-4e4f-91a6-a15dd33610b7', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '3c1c47c5-a3b4-4e4f-91a6-a15dd33610b7', 'content-type': 'application/x-amz-json-1.1', 'content-length': '254', 'date': 'Fri, 14 May 2021 23:01:42 GMT'}, 'RetryAttempts': 0}}
[2021-05-14 23:01:42,173] {{python_operator.py:114}} INFO - Done. Returned value was: OK
[2021-05-14 23:01:42,216] {{taskinstance.py:1070}} INFO - Marking task as SUCCESS.dag_id=movielens-redshift, task_id=transfer_to_redshift, execution_date=20210514T230003, start_date=20210514T230140, end_date=20210514T230142
[2021-05-14 23:01:45,644] {{logging_mixin.py:112}} INFO - [2021-05-14 23:01:45,644] {{local_task_job.py:102}} INFO - Task exited with return code 0
If you look at your Amazon S3 bucket, you should now see the files under the files folder.
Finally, if you look at Queries from the Redshift console, you should see a successful query appear:
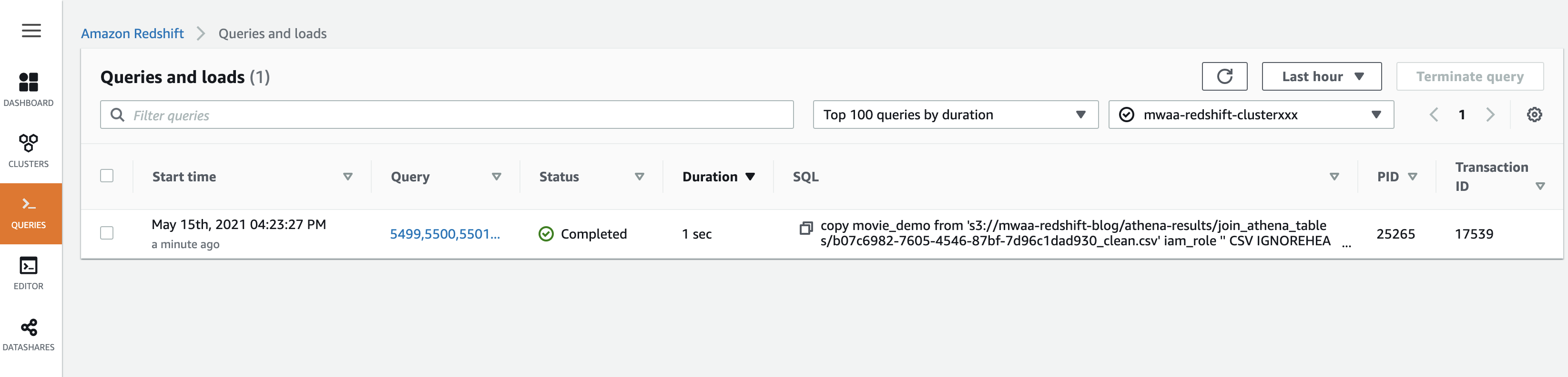
The part of the DAG that moves the data from S3 to Redshift is as follows:
def s3_to_redshift(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
print(queryId)
athenaKey='s3://'+s3_bucket_name+"/"+athena_results+"join_athena_tables/"+queryId+"_clean.csv"
print(athenaKey)
sqlQuery="copy "+redshift_table_name+" from '"+athenaKey+"' iam_role '"+redshift_iam_arn+"' CSV IGNOREHEADER 1;"
print(sqlQuery)
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
#DbUser=redshift_dbuser,
SecretArn=redshift_secret_arn,
Sql=sqlQuery,
)
print(resp)
return "OK"
In essence, we are not using an Apache Airflow operator but some Python code and boto3 and the redshift-data apis.
Congratulations, you have now replicated the original launch blog post for MWAA. Now let us take a look at how we move that data to back to S3 from Redshift.
Uploading and running the movielens-s3 DAG
We have created another DAG, which you can find here, movielens-redshift-s3.py.
If we take a look at the DAG, we can see the following section looks familiar. We are using the same variables, so nothing new to create:
s3_bucket_name = Variable.get("s3_bucket_name", default_var="undefined")
s3_key = Variable.get("s3_key", default_var="undefined")
redshift_table_name = Variable.get("redshift_table_name", default_var="undefined")
redshift_airflow_connection = Variable.get("redshift_airflow_connection", default_var="undefined")
aws_connection = Variable.get("aws_connection", default_var="undefined")
In this DAG we are going to use an operator called RedshiftToS3Transfer. You can see the extract from the DAG as follows:
unload_to_S3 = RedshiftToS3Transfer(
task_id='unload_to_S3',
schema='public',
table=redshift_table_name,
s3_bucket=s3_bucket_name,
s3_key=s3_key,
redshift_conn_id=redshift_airflow_connection,
unload_options = ['CSV'],
aws_conn_id = aws_connection
)
In the first DAG, we used boto3 and called the redshift-data apis (constructing the information that allowed us to run the unload task). In order for this to work with the RedshiftToS3Transfer operator, we need to create a new connection which contains the details of the Redshift cluster.
We do this by creating an Apache Airflow connection, which will be used by this DAG to understand how to connect to the Redshift cluster we created.
When creating this we will give it a name (Conn ID) which is how we will refer to it in the code. If you look up at the variables, we configured this to be redshift_default (from the variables.json entry “redshift_airflow_connection”: “redshift_default”), so we will give it that name.
For the Conn Type we select Amazon Web Services.
For the Host, we use the Redshift cluster endpoint - again this was set in the variables above and is output as part of the CDK app deployment.
For schema we set this to “mwaa” as this is the name of the database we created (so change if you have deviated from the above)
For username and password, enter “awsuser” (change if you changed yours from the defaults) and then for password, you will need to retrieve the password from the AWS Secret Manager (it will be a randomised string).
Finally, port should be set to 5439. It should look a little like this
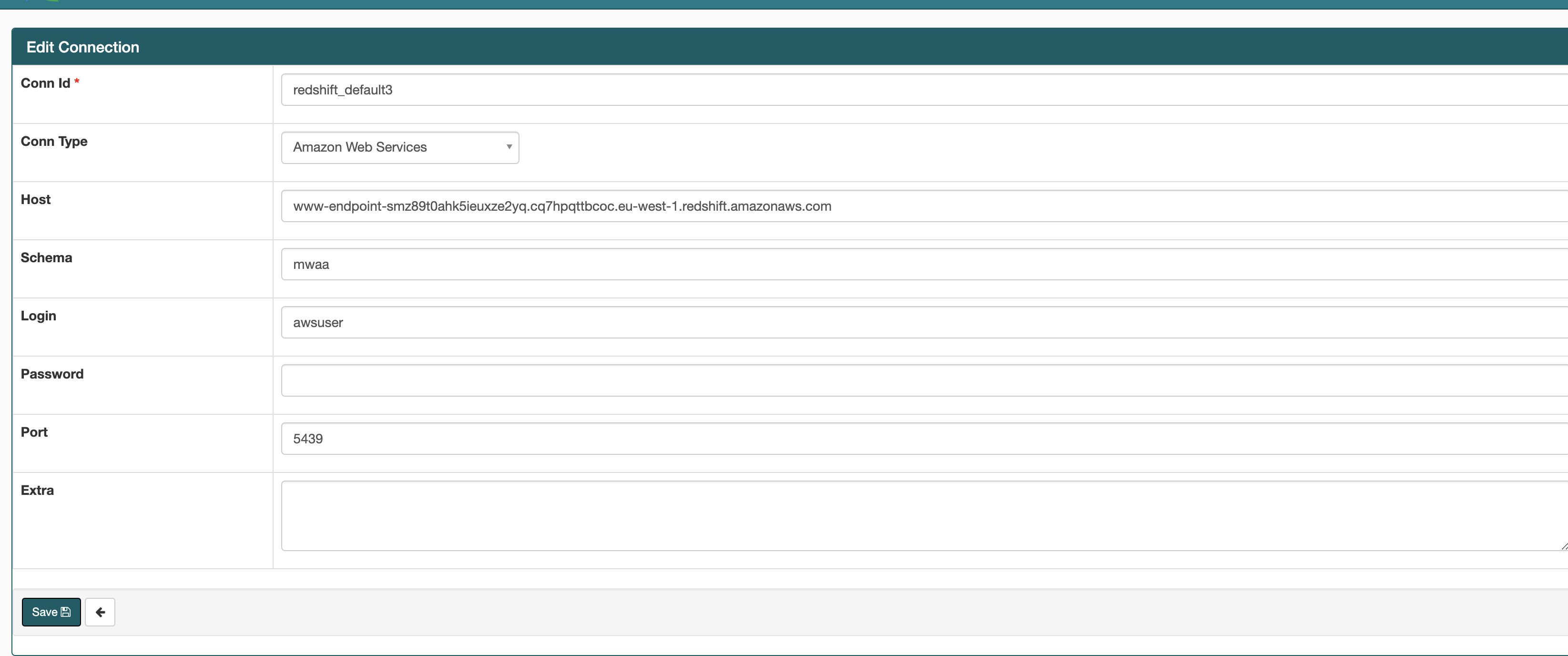
Save the connection, and it you are now ready to go.
Triggering the DAG
From the UI you can turn on/enable and then trigger the DAG called movielens-refshift-s3. If we try and now run the export, what happens? It looks like it hangs, but after a few seconds we see the following in the logs.
[2021-05-12 16:53:23,303] {{redshift_to_s3_operator.py:124}} INFO - Executing UNLOAD command...
[2021-05-12 16:53:23,333] {{logging_mixin.py:112}} INFO - [2021-05-12 16:53:23,333] {{base_hook.py:89}} INFO - Using connection to: id: redshift_default3. Host: mwaa-redshift-clusterxxx.cq7hpqttXXXX.eu-west-1.redshift.amazonaws.com, Port: None, Schema: mwaa, Login: awsuser, Password: XXXXXXXX, extra: None
[2021-05-12 16:55:34,323] {{taskinstance.py:1150}} ERROR - could not connect to server: Connection timed out
Is the server running on host "mwaa-redshift-clusterxxx.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com" (10.192.X.XXX) and accepting
TCP/IP connections on port 5432?
This is to be expected. The MWAA and Amazon Redshift clusters are in two different VPCs, and by default there is no access. So what are our options? Well, we have a few..
- we could create a VPC and then deploy both MWAA and our Amazon Redshift cluster in that VPC and use security groups to control access at the network level
- we could enable Amazon Redshift in Public mode, and then use security groups to control who can access at the network level
- you could configure your own networking solution to enable connectivity between the MWAA VPC and the Amazon Redshift VPC, for example setting up VPC Peering between the two VPCs
- we could configure Redshift-managed VPC endpoints
I am going to look at the last option to addressing this, configuring Amazon Redshift-managed VPC endpoints. You can dive deeper into this topic by checking out this post, Enable private access to Amazon Redshift from your client applications in another VPC
Configuring Amazon Redshift-managed VPC endpoints
The first thing we need to do is enable a feature within our Redshift cluster called Cluster Relocation, which we can do through the aws cli - adjust for your cluster name and the aws region you are in.
$ aws redshift modify-cluster --cluster-identifier {your-cluster-name} --availability-zone-relocation --region={your region}
Which should produce output like the following:
{
"Cluster": {
"ClusterIdentifier": "mwaa-redshift-clusterxxx",
"NodeType": "ra3.4xlarge",
"ClusterStatus": "available",
"ClusterAvailabilityStatus": "Available",
"MasterUsername": "awsuser",
"DBName": "mwaa",
"Endpoint": {
"Address": "mwaa-redshift-clusterxxx.cq7hpqttXXXX.eu-west-1.redshift.amazonaws.com",
"Port": 5439
},
"ClusterCreateTime": "2021-05-12T15:45:57.316Z",
"AutomatedSnapshotRetentionPeriod": 1,
"ManualSnapshotRetentionPeriod": -1,
"ClusterSecurityGroups": [],
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-0a3c2ec446bf3XXX",
"Status": "active"
}
],
"ClusterParameterGroups": [
{
"ParameterGroupName": "default.redshift-1.0",
"ParameterApplyStatus": "in-sync"
}
],
"ClusterSubnetGroupName": "mwaa-redshift-cluster-mwaaredshiftclustersubnets12b38881-18687maiqstqw",
"VpcId": "vpc-009458f3af3d0XXXX",
"AvailabilityZone": "eu-west-1b",
"PreferredMaintenanceWindow": "fri:23:30-sat:00:00",
"PendingModifiedValues": {},
"ClusterVersion": "1.0",
"AllowVersionUpgrade": true,
"NumberOfNodes": 2,
"PubliclyAccessible": false,
"Encrypted": true,
"Tags": [],
"KmsKeyId": "arn:aws:kms:eu-west-1:XXXXXXXXXX:key/3644d5bf-b7c1-489b-95d1-e4ebb9816982",
"EnhancedVpcRouting": false,
"IamRoles": [
{
"IamRoleArn": "arn:aws:iam:: XXXXXXXXXX:role/MWAA-RedShift-Cluster-mwaaredshiftservicerole26FEF-IJCNHR9TMXBN",
"ApplyStatus": "in-sync"
}
],
"MaintenanceTrackName": "current",
"DeferredMaintenanceWindows": [],
"NextMaintenanceWindowStartTime": "2021-05-14T23:30:00Z"
}
}
You can check that this change has taken effect with the following command (if you do not use jq, then look for the “AvailabilityZoneRelocationStatus” parameter set to “enabled”):
$ aws redshift describe-clusters --cluster-identifier {your-cluster-name} --region={your region} | jq -r '.Clusters[] | .AvailabilityZoneRelocationStatus'
And you should get “enabled” if it is working ok.
The CDK app will have created a new Subnet group, the name of which you can see in the outputs. This Subnet group contains the subnet ids for the MWAA VPC, so grab that info as you will need it in the next step when creating the VPC Endpoint itself.
We can setup the VPC Endpoint connection. Replace the parameters below with:
{your-cluster-name} - the name of your Redshift cluster {your-aws-account} - the name of your aws account {your-subnet-group} - the name of the Redshift subnet group that was mentioned above {your-vpc-sg} - this is the MWAA security group
If you want you can change the endpoint-name, when running this it will create one called “mwaa-redshift-endpoint”.
To make this easier, if you check the outputs you should see the command line you need to execute as part of the outputs.
$ aws redshift create-endpoint-access --cluster-identifier {your-cluster-name} --resource-owner {your-aws-account} --endpoint-name mwaa-redshift-endpoint --subnet-group-name {your-subnet-group} --vpc-security-group-ids {your-vpc-sg} --region={your region}
Which should output the following
{
"ClusterIdentifier": "mwaa-redshift-clusterxxx",
"ResourceOwner": "704533066374",
"SubnetGroupName": "mwaa-redshift-cluster-mwaavperedshiftcsg-1n5aroq4bokge",
"EndpointStatus": "creating",
"EndpointName": "mwaa-redshift-endpoint",
"Port": 5439,
"VpcSecurityGroups": [
{
"VpcSecurityGroupId": "sg-01f25764ea72db0f2",
"Status": "active"
}
]
}
It will take around 5 minutes to create this and when finished, the output of this will be to create a new VPC Endpoint, which our MWAA environment will have access to.
This will create a new Redshift endpoint which we will need to use to replace the Apache Airflow connection we created earlier on. To find this endpoint, we use the following command (change the “mwaa-redshift-endpoint” if you used a different name):
$ aws redshift describe-endpoint-access --endpoint-name mwaa-redshift-endpoint | jq '.EndpointAccessList[] | .Address'
Which should display something like
"mwaa-redshift-endpoint-endpoint-amwgdyw5zgkicyjnwvnc.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com"
And we can now update the Connection value in the Apache Airflow UI with this updated Redshift connection value.
When we try again, we can now see that it works…progress! Alas, we get a different error. You will see something like the following:
[2021-05-15 18:15:15,428] {{logging_mixin.py:112}} INFO - [2021-05-15 18:15:15,428] {{base_hook.py:89}} INFO - Using connection to: id: redshift_default3. Host: mwaa-redshift-endpoint-endpoint-amwgdyw5zgkicyjnwvnc.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com, Port: 5439, Schema: mwaa, Login: awsuser, Password: XXXXXXXX, extra: None
[2021-05-15 18:15:16,273] {{logging_mixin.py:112}} INFO - [2021-05-15 18:15:16,273] {{dbapi_hook.py:174}} INFO -
UNLOAD ('SELECT * FROM public.movie_demo')
TO 's3://mwaa-redshift-blog/files//movie_demo_'
with credentials
'aws_access_key_id=DXZAZJ\zxRSAHZ;aws_secret_access_key=QSC6FHRv\zx\zxatJHdEhUEtXAGYs35'
CSV;
[2021-05-15 18:15:16,419] {{taskinstance.py:1150}} ERROR - S3ServiceException:The AWS Access Key Id you provided does not exist in our records.,Status 403,Error InvalidAccessKeyId,Rid DXZAZJ\zxRSAHZ,ExtRid 5rTDV6AnoE8pM8fsx3PTyeJozEUtdPHaxxwsKKJ3ODd5hgb3HvEf9EGoMcge8gKsEhBYqqAMar0=,CanRetry 1
DETAIL:
-----------------------------------------------
error: S3ServiceException:The AWS Access Key Id you provided does not exist in our records.,Status 403,Error InvalidAccessKeyId,Rid DXZAZJ\zxRSAHZ,ExtRid 5rTDV6AnoE8pM8fsx3PTyeJozEUtdPHaxxwsKKJ3ODd5hgb3HvEf9EGoMcge8gKsEhBYqqAMar0=,CanRetry 1
code: 8001
context: Listing bucket=mwaa-redshift-blog prefix=files//movie_demo_
query: 0
location: s3_utility.cpp:840
process: padbmaster [pid=19490]
-----------------------------------------------
It turns out we need to do one more thing to get this working.
Configuring AWS credentials for RedshiftToS3Transfer
We now need to configure credentials that the Amazon Redshift cluster will use when running the unload operation. We have a couple of options:
- we can store the aws credentials as a json tuple in the Apache Airflow Connections
- we can store the same credentials but use the native integration with AWS Secrets Manager to do the same
To keep things simple, I am going to use the Apache Airflow (but will create a follow on post that shows how to do the other)
You will need to create or use an existing IAM user that will be configured to connect to the Redshift cluster to perform the unload transaction. You should create a user with the minimal permissions. You will need to have to hand the “aws_access_key_id” and the “aws_secret_access_key” as you are going to add these to the Apache Airflow connection document.
From the Connections in the Apache Airflow UI, find the connection document you have configured (if you are following along in this example, I have used one called “aws_redshift” and configured the DAGs to use this too. This is currently empty, so all I need to do is add your keys in the following format in the extras field (at the bottom of the page):
{
"aws_access_key_id" : "XASDASDSADSAFDFDSF", "aws_secret_access_key": "7DSFDSFDSFDSdsfdsfdskfjklsdjfkldsjf"
}
After saving this, we can try again.
Success, the workflow should show dark green, and when we look at the logs we can see:
[2021-05-15 18:23:26,049] {{redshift_to_s3_operator.py:124}} INFO - Executing UNLOAD command...
[2021-05-15 18:23:26,080] {{logging_mixin.py:112}} INFO - [2021-05-15 18:23:26,079] {{base_hook.py:89}} INFO - Using connection to: id: redshift_default3. Host: mwaa-redshift-endpoint-endpoint-amwgdyw5zgkicyjnwvnc.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com, Port: 5439, Schema: mwaa, Login: awsuser, Password: XXXXXXXX, extra: None
[2021-05-15 18:23:26,953] {{logging_mixin.py:112}} INFO - [2021-05-15 18:23:26,953] {{dbapi_hook.py:174}} INFO -
UNLOAD ('SELECT * FROM public.movie_demo')
TO 's3://mwaa-redshift-blog/files//movie_demo_'
with credentials
'aws_access_key_id=AXSDADSADSADSADSASD;aws_secret_access_key=7D3YSipzrVecasdsadsadSADSADSAbc7oYvbxi'
CSV;
[2021-05-15 18:23:27,446] {{redshift_to_s3_operator.py:126}} INFO - UNLOAD command complete...
And if we look at the S3 bucket, we can see the files, that have been exported from Redshift.
Troubleshooting
As I was testing this out, I came across a couple of errors that you may see so thought I would document what the errors were and how I resolved the issue.
AWS cli version
When I was running the “aws redshift create-endpoint-access” I got errors and looking at the available options, the “create-endpoint-access” was not available. I was using 1.18.209, so upgraded and the problem was resolved.
S3 Folder issues
The CDK application creates the bucket and a folder called files, which is used as part of the first DAG. I got the following errors:
[2021-05-15 15:20:24,340] {{standard_task_runner.py:78}} INFO - Job 117232: Subtask check_s3_for_key
[2021-05-15 15:20:24,434] {{logging_mixin.py:112}} INFO - Running %s on host %s <TaskInstance: movielens-redshift.check_s3_for_key 2021-05-15T15:20:19.064158+00:00 [running]> ip-10-192-21-59.eu-west-1.compute.internal
[2021-05-15 15:20:24,581] {{s3_key_sensor.py:88}} INFO - Poking for key : s3://mwaa-redshift-blog/files/
[2021-05-15 15:20:45,206] {{s3_key_sensor.py:88}} INFO - Poking for key : s3://mwaa-redshift-blog/files/
..
..
[2021-05-15 15:20:45,333] {{taskinstance.py:1150}} ERROR - Snap. Time is OUT.
Even though the folder existed, MWAA and specifically this operator could not see it. The fix as it turned out was simple, and required me to use a wildcard when using the bucket_key parameter. In this post I stored this in the Apache Airflow variables, so I changed from “files/” to “files/*” and the sensor then worked.
Amazon Redshift username password error
When triggering the Amazon Redshift to S3 DAG, I got the following error.
[2021-05-15 11:03:44,466] {{standard_task_runner.py:78}} INFO - Job 117231: Subtask unload_to_S3
[2021-05-15 11:03:44,569] {{logging_mixin.py:112}} INFO - Running %s on host %s <TaskInstance: movielens-redshift-s3.unload_to_S3 2021-05-15T11:03:39.979947+00:00 [running]> ip-10-192-21-59.eu-west-1.compute.internal
[2021-05-15 11:03:44,693] {{redshift_to_s3_operator.py:124}} INFO - Executing UNLOAD command...
[2021-05-15 11:03:44,722] {{logging_mixin.py:112}} INFO - [2021-05-15 11:03:44,722] {{base_hook.py:89}} INFO - Using connection to: id: redshift_default3. Host: www-endpoint-smz89t0ahk5ieuxze2yq.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com, Port: 5439, Schema: mwaa, Login: awsuser, Password: XXXXXXXX, extra: None
[2021-05-15 11:03:45,493] {{taskinstance.py:1150}} ERROR - FATAL: password authentication failed for user "awsuser"
FATAL: password authentication failed for user "awsuser"
The resolution was simple, I had forgotten to add the password to the connection document in MWAA, so all I had to do was obtain the password from AWS Secrets Manager, and then store that in the password field.
Amazon Redshift connection times out
While I was getting the Redshift-managed VPC endpoint setup, when I triggered the Amazon Redshift to S3 DAG, the task stayed green (running) for a while, and eventually failed with the following error.
[2021-05-14 23:40:34,440] {{logging_mixin.py:112}} INFO - Running %s on host %s <TaskInstance: movielens-redshift-s3.unload_to_S3 2021-05-14T23:40:29.106506+00:00 [running]> ip-10-192-21-59.eu-west-1.compute.internal
[2021-05-14 23:40:34,602] {{redshift_to_s3_operator.py:124}} INFO - Executing UNLOAD command...
[2021-05-14 23:40:34,636] {{logging_mixin.py:112}} INFO - [2021-05-14 23:40:34,635] {{base_hook.py:89}} INFO - Using connection to: id: redshift_default3. Host: aaa-endpoint-bg5whiw3h4rvuimskvn2.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com, Port: 5439, Schema: mwaa, Login: awsuser, Password: XXXXXXXX, extra: None
[2021-05-14 23:42:44,915] {{taskinstance.py:1150}} ERROR - could not connect to server: Connection timed out
Is the server running on host "aaa-endpoint-bg5whiw3h4rvuimskvn2.cq7hpqttbcoc.eu-west-1.redshift.amazonaws.com" (10.192.21.140) and accepting
TCP/IP connections on port 5439?
It took me a while to figure this out, but the solution involved a few things:
- setup a Redshift Subnet Group with the subnets from the MWAA environment
- enable the MWAA security group to allow inbound Redshift traffic (port 5439)
- setup the Redshift-managed VPC endpoint setup with the correct environment - you need to do this AFTER the subnet group has been setup, otherwise only the existing Redshift VPC will appear
Conclusion
In this post I have shown you how you can use and integrate Apache Airflow to orchestrate data engineering tasks across a number of AWS services, importing data from origin to Amazon S3, transforming it via Amazon Athena, creating tables in Amazon Redshift before exporting it to an Amazon S3 bucket.
Clean up
Make sure you delete all the resources, which you can do quickly by running these commands.
$ cdk destroy MWAA-Redshift-Cluster
$ cdk destroy MWAA-Redshift-VPC
And then emptying/delete the Amazon S3 bucket.