Working with Managed Workflows for Apache Airflow (MWAA) and Amazon Redshift
Published Apr 7, 2023
Reading time 19 minutes
Working with Managed Workflows for Apache Airflow (MWAA) and Amazon Redshift
I was recently looking at some Stack Overflow questions from the AWS Collective and saw a number of folk having questions about the integration between Amazon Redshift and Managed Workflows for Apache Airflow (MWAA). I thought I would put together a quick post that might help folk address what I saw were some of the common challenges.
There is some code that accompanies this post, which you can find at the GitHub repository cdk-mwaa-redshift.
Pre-requisites You will need the following to be able to use the code in this repo:
- AWS CDK (I was using 2.72.1 and Node version 18.1.0)
- An AWS Region where MWAA is available
- Sufficient privileges to deploy resources within your AWS Account
COSTs I ran this for 24 hours and the cost was $165, so make sure if you do deploy this code that you delete/remove all the resources created once you have finished to ensure you do not incur further costs
Which Operator
One of the first things I have noticed is that there are a number of methods for orchestrating tasks to interact with Amazon Redshift. Apache Airflow uses “operators” to simplify your life when working with downstream systems, like Amazon Redshift. Depending on what you are trying to achieve, your first task is to identify which Apache Airflow operator you want to use.
Provider Packages Apache Airflow bundles up operators into “Provider Packages”. Depending on the version of Apache Airflow you are using AND the Airflow provider packages you have defined in your requirements.txt, will dictate which operators and what versions of those you have. The easiest way to determine which you have up and running is from the Apache Airflow UI, selecting the “Providers” under the Admin tab.
Why is this important? When working with Redshift, depending on the version of Airflow and the version of the Amazon Provider package, the Redshift operator classes change. For example, in earlier versions you would use
from airflow.providers.amazon.aws.operators.redshift import RedshiftSQLOperatorbut in newer versions you use
from airflow.providers.amazon.aws.operators.redshift_sql import RedshiftSQLOperatorThis is something to look out for when working with these operators.
These are the four that I could see come up most often:
- PythonOperator - you can use boto3 to directly write Python code to interact with your Redshift clusters
- RedshiftSQLOperator - the RedshiftSQLOperator operator uses an Airflow defined connection (default, “default_redshift_connection”) and then allows you to define SQL statements to run
- RedshiftDataOperator - the RedshiftDataOperator operator works using the Redshift Data API, and connects using your AWS credentials (default, “aws_default”)
- RedshiftToS3Transfer and S3ToRedshiftOperator - these operators either load date into your Redshift clusters from an S3 bucket, or export data from your Redshift clusters to a S3 bucket
These are the operators that I could think of - if you are using something different then let me know and I will update this post to include other ways.
The rest of this post will be looking at using these. What we will do is:
- set up an Amazon Redshift cluster, Managed Workflows for Apache Airflow environment, and the necessary S3 buckets
- automate the uploading of the sample data into our S3 buckets
- create the tables in our Redshift database using Airflow operators
- use Airflow operators to import the sample data
Setting up my test environment
To make things easier I have put together a simple CDK app that will deploy a new VPC, and into that VPC deploy a MWAA 2.4.3 environment, and an Amazon Redshift cluster. The stack also deploys some sample DAGs which we will use. The repo is here cdk-mwaa-redshift and we can deploy this as follows:
git clone https://github.com/094459/cdk-mwaa-redshift
You will need to modify the app.py and update the AWS Account and AWS Regions, as well as define unique S3 buckets for your installation. The current app.py contains examples which need to be changed or your deployment will fail.
cd cdk-mwaa-redshift
cdk deploy mwaa-demo-utils
cdk deploy mwaa-demo-vpc
cdk deploy mwaa-demo-dev-environment
cdk deploy mwaa-demo-redshift
You will be prompted after each stack to confirm you are happy to deploy. So after reviewing the security changes, answer Y to continue. After around 30 minutes, you should have everything setup.
RedshiftSQLOperator
We now have a completely new setup with no sample data. Our next step is to upload the sample data (which we can find info on in the Redshift documentation pages. We will use Airflow operators to automate these tasks.
First we will upload the files to our S3 bucket that was created when the Redshift cluster was setup (in my default app.py, this S3 bucket is called “mwaa-094459-redshift”). To do this we do not need a specific Redshift operator, we will just use the PythonOperator to do this, defining a function that does the file copying and uploading to our S3 bucket
S3_BUCKET = 'mwaa-094459-redshift'
DOWNLOAD_FILE = 'https://docs.aws.amazon.com/redshift/latest/gsg/samples/tickitdb.zip'
S3_FOLDER = 'sampletickit'
def download_zip():
s3c = boto3.client('s3')
indata = requests.get(DOWNLOAD_FILE)
n=0
with zipfile.ZipFile(io.BytesIO(indata.content)) as z:
zList=z.namelist()
print(zList)
for i in zList:
print(i)
zfiledata = BytesIO(z.read(i))
n += 1
s3c.put_object(Bucket=S3_BUCKET, Key=S3_FOLDER+'/'+i, Body=zfiledata)
dag = DAG(
'setup_sample_data_dag',
default_args=default_args,
description='Setup Sample Data from Redshift documentation',
schedule_interval=None,
start_date=datetime(2023, 1, 1),
catchup=False,
)
files_to_s3 = PythonOperator(
task_id='files_to_s3',
python_callable=download_zip,
dag=dag
)
files_to_s3
The next step is to create the tables as per the guide so that when we ingest the data, it is imported into the right tables. For this we are going to use the first Redshift operator, RedshiftSQLOperator
We will define a variable in our DAG that holds the sql we want to execute (copied from the guide above) and then we will use this operator to execute that query to create our tables.
sample_data_tables_venue_sql=""
create table IF NOT EXISTS public.venue(
venueid smallint not null distkey sortkey,
venuename varchar(100),
venuecity varchar(30),
venuestate char(2),
venueseats integer);
create_sample_venue_tables = RedshiftSQLOperator(
task_id = 'create_sample_venue_tables',
sql=sample_data_tables_venue_sql,
redshift_conn_id=REDSHIFT_CONNECTION_ID,
dag=dag
)
"""
And that is it. We just need to create these for each of the tables we want to created, and then we create the flow of the DAG to make these run in parallel
files_to_s3 >> create_sample_users_tables
files_to_s3 >> create_sample_category_tables
files_to_s3 >> create_sample_venue_tables
files_to_s3 >> create_sample_date_tables
files_to_s3 >> create_sample_listing_tables
files_to_s3 >> create_sample_sales_tables
files_to_s3 >> create_sample_event_tables
You can see the complete DAG in the repo here
Before we run this, we need to define how this operator is going to connect with our Redshift cluster (this is the redshift_conn_id value that we set in the DAG, but what we need to create via the Apache Airflow Connections). From the “ADMIN” tab, select “CONNECTIONS” and then click on the (+) to add a new connection.
In my setup, I used the following values:
- Connection Id - I used “default_redshift_connection”, you can use whatever you want but make sure it matches what you set in your operator within the DAG
- Connection Type - Amazon Redshift
- Extras - here I supplied a json string with the Redshift cluster I want to connect to ({“iam”: true, “cluster_identifier”: “mwaa-redshift-cluster”, “port”: 5439, “region”: “eu-west-1”, “db_user”: “awsuser”, “database”: “mwaa”})
If you need to connect to different Redshift clusters, you would create additional connections this way, with unique Connection Ids and then reference that Id within your operator.
Once we create this we can trigger our DAG to run. With luck, you should find that you now have the sample data in your S3 bucket, and seven tables created. Well done, now it is time to import that into our Redshift tables.
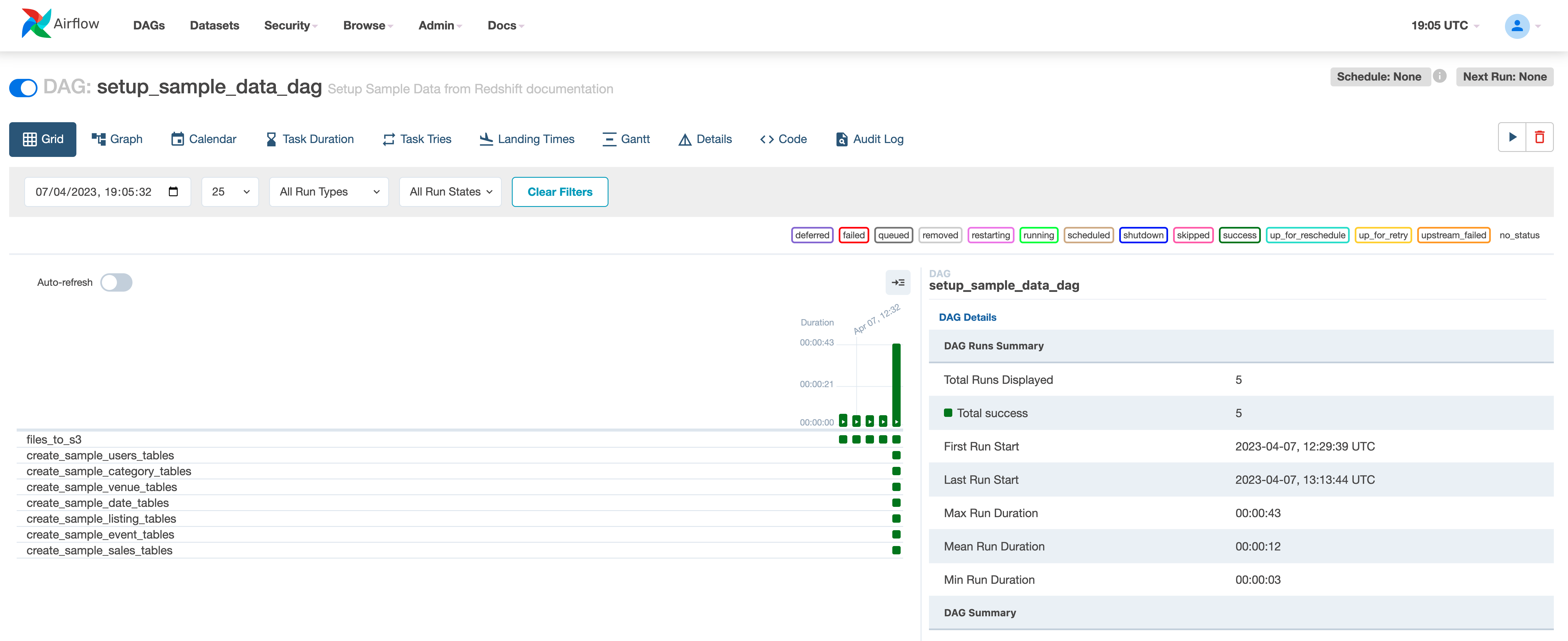
RedshiftToS3Transfer and S3ToRedshiftOperator
S3ToRedshiftOperator
Now that we have our data in our Amazon S3 buckets, the next step is to show how we can ingest data between Amazon S3 and Amazon Redshift.
When we look at the guide on how to set up the sample data manually, we can see it provides us with all the necessary Redshift SQL commands. We will be using those, and here is an example of one of those. Whilst most are the same, some do use slightly different syntax which is typical in real life use cases.
copy users from 's3://<myBucket>/tickit/allusers_pipe.txt'
iam_role default
delimiter '|' region '<aws-region>';
So let us put together a DAG using the S3ToRedshiftOperator operator.
# Example of how to use S3ToRedshiftOperator
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.amazon.aws.transfers.s3_to_redshift import S3ToRedshiftOperator
# Replace these with your own values
REDSHIFT_CONNECTION_ID = 'default_redshift_connection'
S3_BUCKET = 'mwaa-094459-redshift'
REDSHIFT_SCHEMA = 'mwaa'
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
's3_to_redshift_dag',
default_args=default_args,
description='Load CSV from S3 to Redshift',
schedule_interval=None,
start_date=datetime(2023, 1, 1),
catchup=False,
)
load_s3_to_redshift = S3ToRedshiftOperator(
task_id='load_s3_to_redshift',
s3_bucket=S3_BUCKET,
s3_key= 'tickit/allevents_pipe.txt',
schema=REDSHIFT_SCHEMA,
table='event',
copy_options=['CSV', 'DELIMITER "|"'],
redshift_conn_id=REDSHIFT_CONNECTION_ID,
dag=dag,
)
load_s3_to_redshift
When we now trigger this DAG, we then get output similar to the following:
[2023-04-06, 21:07:03 UTC] {{s3_to_redshift.py:184}} INFO - Executing COPY command...
[2023-04-06, 21:07:03 UTC] {{base.py:71}} INFO - Using connection ID 'default_redshift_connection' for task execution.
[2023-04-06, 21:07:03 UTC] {{sql.py:375}} INFO - Running statement:
COPY mwaa.public.event
FROM 's3://mwaa-094459-redshift/tickit/allevents_pipe.txt'
credentials
'aws_access_key_id=**hidden**;aws_secret_access_key=***;token=***'
CSV
DELIMITER '|'
FILLRECORD
IGNOREHEADER 1;
, parameters: None
[2023-04-06, 21:07:08 UTC] {{s3_to_redshift.py:189}} INFO - COPY command complete...
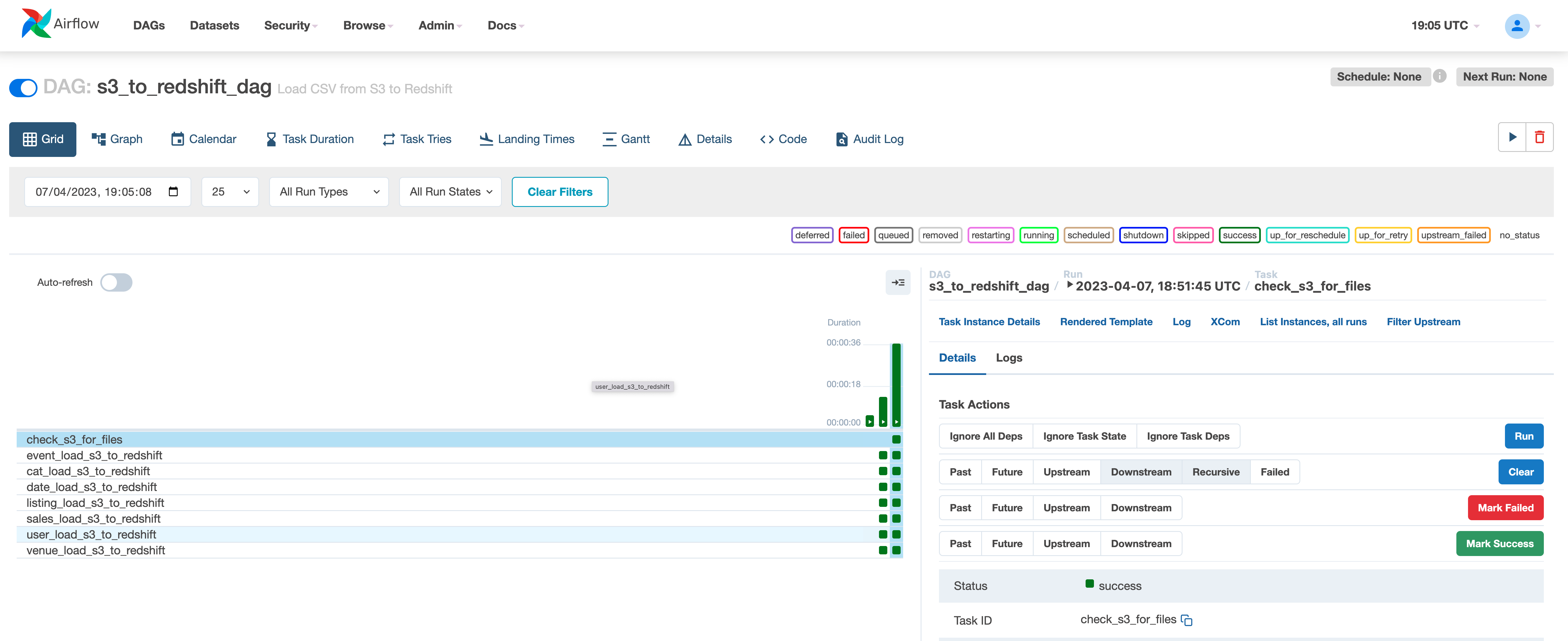
And when we check our Redshift cluster, we can now see we have the event data in the database. Awesome, we have used the S3ToRedshiftOperator to ingest the data. We now need to do this for all the remaining files.
We can tweak the import options by defining “copy_options” following standard Redshift configuration values. For a complete reference of Redshift options, go to the airflow.providers.amazon.aws.transfers.s3_to_redshift documentation page.
Check out the repo for the complete DAG which does this. You will notice that for each operation, we use slightly different configurations which map to the data we are ingesting.
RedshiftToS3Transfer
Now that we have some data in our Redshift cluster, we will use the next operator, RedshiftToS3Transfer, to export this to an S3 bucket that we have provided Redshift with permissions to access.
We first define some variables for our Redshift database and where we want to export the data to.
REDSHIFT_CONNECTION_ID = 'default_redshift_connection'
S3_BUCKET = 'mwaa-094459-redshift'
S3_EXPORT_FOLDER = 'export'
REDSHIFT_SCHEMA = 'mwaa'
REDSHIFT_TABLE = 'public.sales'
and then it is as simple as using the operator as follows, defining the target (export) S3 bucket and key (folder) and then selecting the database and table we want to export.
transfer_redshift_to_s3 = RedshiftToS3Operator(
task_id="transfer_redshift_to_s3",
redshift_conn_id=REDSHIFT_CONNECTION_ID,
s3_bucket=S3_BUCKET,
s3_key=S3_EXPORT_FOLDER,
schema=REDSHIFT_SCHEMA,
table=REDSHIFT_TABLE,
dag=dag
)
We can then trigger this DAG, and we should now see that we have a new folder called “export” with the contents of the Redshift table exported.
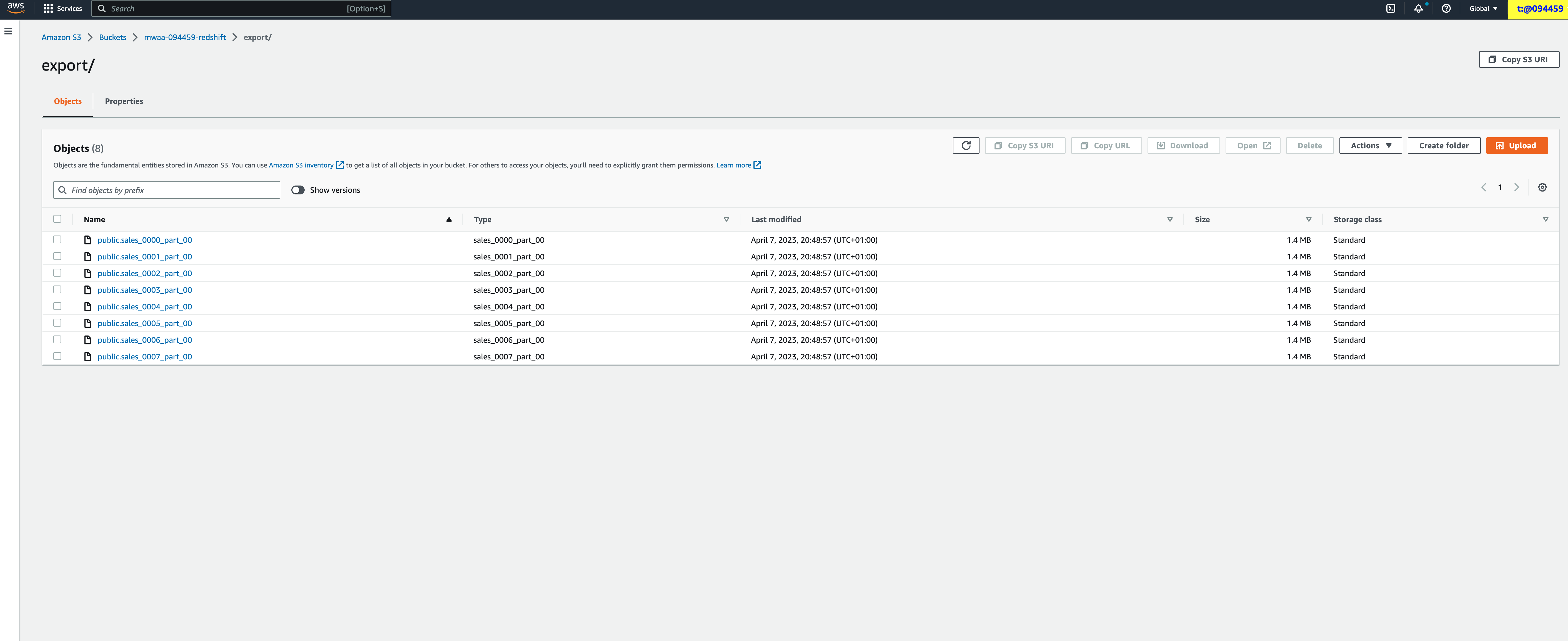
We can tweak the export options by defining “unload_options” following standard Redshift configuration values. For a complete reference of Redshift options, check out the airflow.providers.amazon.aws.transfers.redshift_to_s3 documentation page.
You can see the complete DAG here.
RedshiftDataOperator
When we created our Redshift tables, we used the RedshiftSQLOperator operator. We can use a different operator to achieve the same results. So what is different I can hear you all shouting into your screens! The RedshiftDataOperator uses the redshift-data api to achieve the same results, using the AWS API. When you use the RedshiftSQLOperator you are connecting via the wire protocol.
When using this operator, we do not need to define the “redshift_conn_id” connection as it will use the default AWS one. We do need however, to define some variables which our operator will use to know which Redshift cluster, database, and user we want to use.
REDSHIFT_CLUSTER = 'mwaa-redshift-cluster'
REDSHIFT_USER = 'awsuser'
REDSHIFT_SCHEMA = 'mwaa'
POLL_INTERVAL = 10
We define a variable to hold the SQL we want to run, in this case, to create the Redshift view
create_view_sql = """
create view loadview as
(select distinct tbl, trim(name) as table_name, query, starttime,
trim(filename) as input, line_number, colname, err_code,
trim(err_reason) as reason
from stl_load_errors sl, stv_tbl_perm sp
where sl.tbl = sp.id);
"""
and then we create our task
create_redshift_tblshting_view = RedshiftDataOperator(
task_id="create_redshift_tblshting_view",
cluster_identifier=REDSHIFT_CLUSTER,
database=REDSHIFT_SCHEMA,
db_user=REDSHIFT_USER,
sql=create_view_sql,
poll_interval=POLL_INTERVAL,
wait_for_completion=True,
dag=dag
)
We can now view from the Redshift query editor (I am using the nice v2 version) the complete Redshift sample data now deployed.
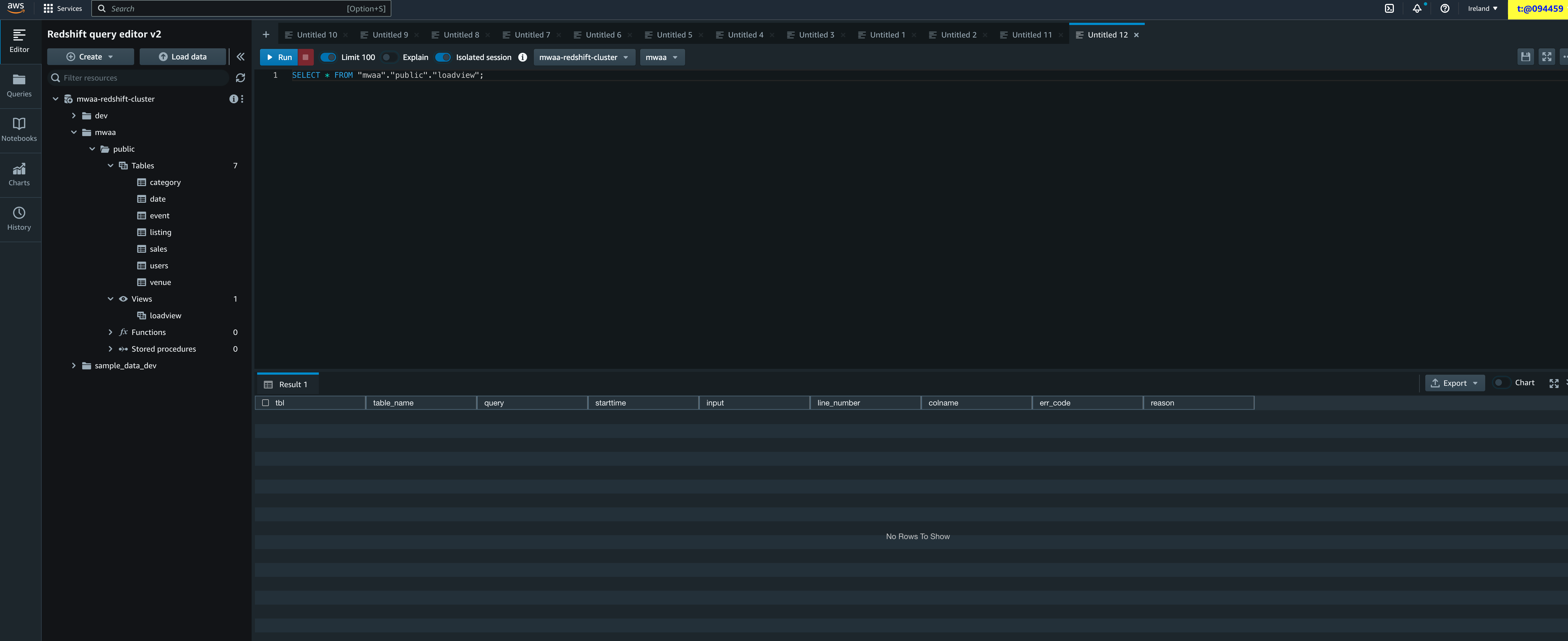
You can see the complete DAG here.
PythonOperator
The final method is creating some Python code within your DAG and then running this code via the PythonOperator operator. Why might you do this? The only use case I can think of is perhaps where what you are trying to achieve cannot be done by the previous operators.
Before using the PythonOperator
Before proceeding with using the PythonOperator, I would encourage you to consider this. If you do have something that is currently not achievable with the operators listed above, go to the open source project and discuss within the Airflow slack channel, after which you can raise an issue for a feature request. This is the first step in making new functionality within these operators, so think about whether this makes sense for you. Why should you consider doing this? Well, if you can push the functionality you need upstream, then this is less code for you to have to worry about and maintain. You would (or rather should) still play your part and contribute upstream, but the force multiplier effect of community will help you reduce the burdens of managing that code. Something to think about.
With that out of the way, how would you use the PythonOperator to work with Redshift? You would create a function within your DAG that has the logic for what you are looking to do, and then invoke via the operator. In this example DAG which I put together a few years back before I had discovered the Redshift operators, you can see how I created tables in Redshift.
def create_redshift_table():
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
DbUser=redshift_dbuser,
Sql="CREATE TABLE IF NOT EXISTS "+redshift_table_name+" (title character varying, rating int);"
)
print(resp)
return "OK"
create_redshift_table_if_not_exists = PythonOperator(
task_id="create_redshift_table_if_not_exists",
python_callable=create_redshift_table,
dag=dag
)
In the same DAG I also used this approach to mimic the RedshiftToS3Transfer operator
def s3_to_redshift(**kwargs):
ti = kwargs['task_instance']
queryId = ti.xcom_pull(key='return_value', task_ids='join_athena_tables' )
athenaKey='s3://'+s3_bucket_name+"/"+athena_results+"join_athena_tables/"+queryId+"_clean.csv"
sqlQuery="copy "+redshift_table_name+" from '"+athenaKey+"' iam_role '"+redshift_iam_arn+"' CSV IGNOREHEADER 1;"
rsd = boto3.client('redshift-data')
resp = rsd.execute_statement(
ClusterIdentifier=redshift_cluster,
Database=redshift_db,
SecretArn=redshift_secret_arn,
Sql=sqlQuery,
)
return "OK"
transfer_to_redshift = PythonOperator(
task_id="transfer_to_redshift",
python_callable=s3_to_redshift,
provide_context=True,
dag=dag
)
As you can see, using the Redshift operators is simpler and means I have much less work to do.
Diving deeper with the RedshiftSQLOperator
In this blog post we have only scratched the surface of what you can do with Apache Airflow and Amazon Redshift. Before we finish, I want to share a few more advanced topics that worth knowing about and will give you more confidence in how you orchestrate your Redshift tasks using Apache Airflow.
Setting up Redshift Clusters
You can actually setup and delete new Redshift clusters using Apache Airflow. We can see in the example_dags of a DAG that does a complete setup and delete of a Redshift cluster. There are a few things to think about however.
First, you should not store the password in the DAG itself as this can be seen in plain sight by a larger number of people than is needed. I would encourage you to either store this as a Variable within the Apache Airflow UI, or better still, integrate AWS Secrets Manager and then grab the password as a variable that way.
Integration with AWS Secrets Manager
Now some of you might have gone down the path of integrating MWAA with AWS Secrets Manager for your Variables and Connections. If you have done this, rather than creating the connections via the Apache Airflow UI via the ADMIN > CONNECTION menu, you need to create these in AWS Secrets Manager.
First you need to create your AWS Secret that will contain the JSON string for your connection details. To make this easier, you can use a small piece of Python code to generate this for your by changing the values for your setup:
import urllib.parse conn_type = 'redshift' host = '' #Specify the Amazon Redshift cluster endpoint. login = '' #Specify the username to use for authentication with Amazon Redshift. password = '' #Specify the password to use for authentication with Amazon Redshift. role_arn = urllib.parse.quote_plus('YOUR_EXECUTION_ROLE_ARN') region = '' #YOUR_REGION conn_string = '{0}://{1}:{2}@{3}?role_arn={4}®ion={5}'.format(conn_type, login, password, host,role_arn, region) print(conn_string)Running this will generate a string, and you need to copy this and use this when creating your AWS Secret. Here is an example of doing this via the cli
aws secretsmanager create-secret --name airflow/connections/default_redshift_connection --description "Apache Airflow to Redshift Cluster" --secret-string "{paste value here}" --region={your region}"Now when Apache Airflow goes to find the “default_redshift_connection” it will grab the details via AWS Secrets Manager
The second is to ensure that you lock down access to your Redshift cluster to only those clients that need it. In the example, access is wide open (““IpRanges”: [{“CidrIp”: “0.0.0.0/0”, “Description”: “Test description”}],") which is fine for testing but make sure you lock this down if you plan to use this for real use cases.
The final thing to bear in mind is that depending on what you plan on doing, you will need to make sure that the MWAA execution role has the right level of permissions. In the example CDK stack that is part of this tutorial, IAM privileges are scoped down to just the cluster name, and I did not add any of the DELETE actions. You should not provide broad access, so make sure you define the appropriate least privilege policies based on what you might want to do.
Connecting to your Redshift Cluster
The next topic is actually how your MWAA environment connects to your Redshift cluster. How you connect MWAA to your Redshift Clusters depends on a few things:
- Which operator you are using
- Where your Redshift and Apache Airflow environments are located
When you are using the RedshiftSQLOperator, RedshiftToS3Transfer, and S3ToRedshiftOperator you are connecting via the wire protocol. If you are using the RedshiftDataOperator or the PythonOperator via boto3, you are going to be accessing Redshift via the AWS API. This is important because it will determine how Apache Airflow knows how to connect with the Redshift cluster you want to connect to.
RedshiftSQLOperator, RedshiftToS3Transfer, and S3ToRedshiftOperator use an Airflow Connection document to define how to connect to your Redshift cluster, and this is configured within the actual operator itself. You can find more details on this by checking out the official documentation page here
A common problem with not being able to connect to Redshift clusters from Apache Airflow is that the security groups have not been changed to include a new inbound rule. In a situation where both the Apache Airflow and Redshift clusters are in the same VPC (the simplest scenario) this should be as simple as ensuring that the Apache Airflow security group is added as a source for the Redshift security group Inbound rule. In the following screenshot we can see what the Redshift cluster security looks like and how it includes an inbound rule for our Apache Airflow environment.
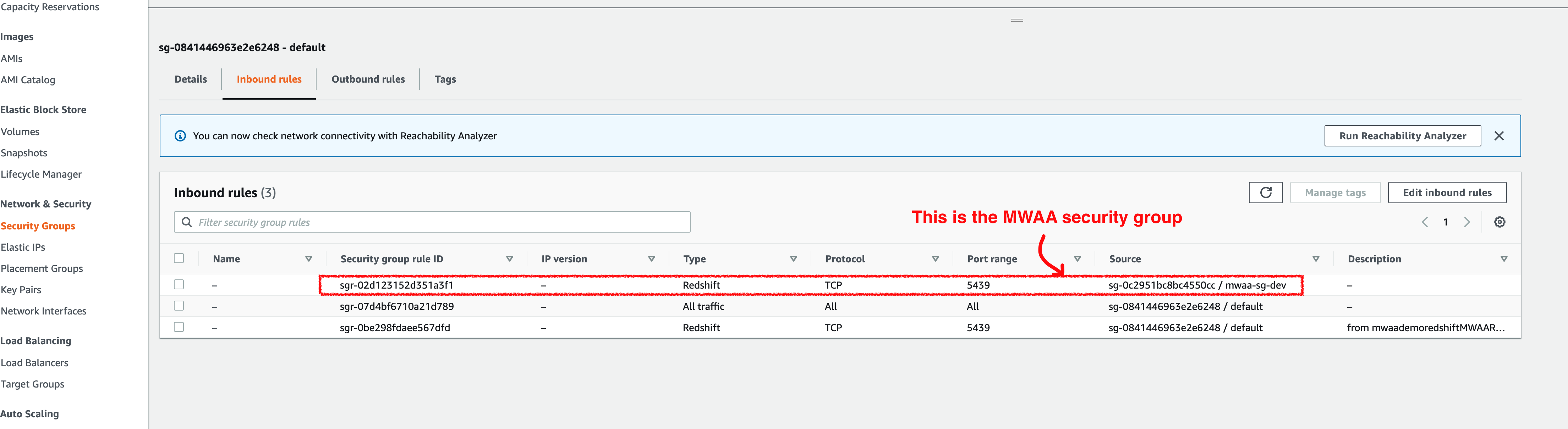 Where these are in different VPCs, you will need to configure this with something like VPC peering - this is outside the scope of this post, but let me know if this is something you would like me to cover.
Where these are in different VPCs, you will need to configure this with something like VPC peering - this is outside the scope of this post, but let me know if this is something you would like me to cover.
If you are still struggling to connect, then check out this knowledge article which might help provide more info.
Using XComs to grab results
The Redshift operators will generate automatically XComs output when they run. However, I have found that this is dependant on the version of the Redshift operators you are using, so make sure you are using the latest up to date ones. For example, I tried the same DAG using version 2.4.0, and 6.0.0 and I got no Xcoms output when running a query using the operator. However, when I upgraded to 7.3.0, it did generate automatically the query ID.
In this simple example DAG, I am running a query which will count some of the rows in one of the tables we have uploaded. I want to run this query, and then ensure that the results are returned in Xcoms. I might want to pass this output of this to the next task for example.
query_sql = """
with x as (
select
sellerid,
count(1) as rows_count
from public.listing
where sellerid is not null
group by sellerid
)
select
count(1) as id_count,
count(case when rows_count > 1 then 1 end) as duplicate_id_count,
sum(rows_count) as total_row_count,
sum(case when rows_count > 1 then rows_count else 0 end) as duplicate_row_count
from x;
"""
query_sql = RedshiftDataOperator(
task_id="query_sql",
cluster_identifier=REDSHIFT_CLUSTER,
database=REDSHIFT_SCHEMA,
db_user=REDSHIFT_USER,
sql=query_sql,
poll_interval=POLL_INTERVAL,
wait_for_completion=True,
dag=dag
)
When I run this, I can see that when I check XComs I get the Redshift query Id. I now need to grab this, so I create a quick function and then call it via the PythonOperator
def get_results(**kwargs):
print("Getting Results")
ti = kwargs['task_instance']
runqueryoutput = ti.xcom_pull(key='return_value', task_ids='query_sql')
client = boto3.client('redshift-data', region_name='eu-west-1')
response = client.get_statement_result(Id=runqueryoutput)
query_data = response['Records']
print(query_data)
return query_data
get_query_results = PythonOperator(
task_id='get_query_results',
python_callable=get_results,
dag=dag
)
And that is it all I need. The key piece here is to ensure that the “task_ids” is set to the correct task otherwise it will not return the correct value
ti = kwargs['task_instance']
runqueryoutput = ti.xcom_pull(key='return_value', task_ids='query_sql')
When I run this DAG, I can now see that when I check on the XComs on the Apache Airflow UI, I can see the output. I can also see the output by checking the Task log.
[2023-04-07, 21:08:33 UTC] {{logging_mixin.py:137}} INFO - Getting Results
[2023-04-07, 21:08:33 UTC] {{logging_mixin.py:137}} INFO - [[{'longValue': 48984}, {'longValue': 44789}, {'longValue': 192496}, {'longValue': 188301}]]
[2023-04-07, 21:08:33 UTC] {{python.py:177}} INFO - Done. Returned value was: [[{'longValue': 48984}, {'longValue': 44789}, {'longValue': 192496}, {'longValue': 188301}]]
Conclusion
In this short post we have explored a number of ways in which you can interact with Apache Airflow and Amazon Redshift. I hope this will help you understand what your options are and help get you started.
If you have found this blog post helpful, please give me some feedback by completing this very short survey here
Before you go however, make sure you check out the next section and delete/remove all the resources you have just setup.
Cleaning up
To remove all the resources deployed, use the following command.
cd cdk-mwaa-redshift
cdk destroy mwaa-demo-redshift
cdk destroy mwaa-demo-dev-environment
cdk destroy mwaa-demo-vpc
You will need to manually delete the S3 buckets.
Troubleshooting
What to do when it all goes horribly wrong!
In this section I just wanted to share some of the error I found when I was putting this blog together in the hope that if you get the same errors, this post can help you.
Connection timeouts
When I thought everything had been setup correctly, when triggering the DAG, I got an extended pause and then an error:
[2023-04-07, 21:33:55 UTC] {{taskinstance.py:1851}} ERROR - Task failed with exception
Traceback (most recent call last):
File "/usr/local/airflow/.local/lib/python3.10/site-packages/redshift_connector/core.py", line 585, in __init__
self._usock.connect((host, port))
TimeoutError: [Errno 110] Connection timed out
During handling of the above exception, another exception occurred:
It turned out that the issue was that my MWAA Security Group had not been added to the Redshift Security Group as an Inbound rule to access Redshift on port 5349. Once I added this, this resolved my problem. In the CDK stack that accompanies this post, this is automatically configured for you.
Errors importing listing_pipe.txt
Whilst most of the import worked fine, the listing_pipe.txt stubbornly refused to ingest. The error in the Airflow task was as follows:
redshift_connector.error.ProgrammingError: {'S': 'ERROR', 'C': 'XX000', 'M': "Load into table 'listing' failed. Check 'stl_load_errors' system table for details.", 'F': '../src/pg/src/backend/commands/commands_copy.c', 'L': '718', 'R': 'CheckMaxRowError'}
I found out that you could create a view within Redshift that helps you troubleshoot these kinds of issues.
create view loadview as
(select distinct tbl, trim(name) as table_name, query, starttime,
trim(filename) as input, line_number, colname, err_code,
trim(err_reason) as reason
from stl_load_errors sl, stv_tbl_perm sp
where sl.tbl = sp.id);
I was able to see that one line (54737) had an empty line. When I checked the file, sure enough there was a blank line. I then adjusted the DAG as follows, using the MAXERROR parameter
listing_load_s3_to_redshift = S3ToRedshiftOperator(
task_id='listing_load_s3_to_redshift',
s3_bucket=S3_BUCKET,
s3_key= 'tickit/listings_pipe.txt',
schema=REDSHIFT_SCHEMA,
table='public.listing',
copy_options=["CSV","DELIMITER '|'", "MAXERROR 5", "IGNOREHEADER 1"],
redshift_conn_id=REDSHIFT_CONNECTION_ID,
dag=dag,
)