Orchestrating hybrid workflows using Amazon Managed Workflows for Apache Airflow (MWAA)
Published Mar 7, 2022
Reading time 46 minutes
Using Apache Airflow to orchestrate hybrid workflows
In some recent discussions with customers, the topic of how open source is increasingly being used as a common mechanisms to help build re-usable solutions that can protect investments in engineering and development time, skills and that work across on premises and Cloud environment. In 2021 my most viewed blog post talked about how you can build and deploy containerised applications, anywhere (Cloud, your data centre, other Clouds) and on anything (Intel and Arm). I wanted to combine the learnings from that post (and the code) and apply it to another topic I have been diving deeper into, Apache Airflow. I wanted to explore how you can combine the two to see how you can start to build data pipelines that work across hybrid architectures seamlessly.
Use Case
So why would we want to do this? I can see a number of real world applications, but the two that stand out for me are:
- where you want to leverage and use existing legacy/heritage systems within your data analytics pipelines
- where local regulation and compliance places additional controls as to where data can be processed
In this post I will show how you can address both of these use cases, combining open source technology and a number of AWS products and services that will enable you to orchestrate workflows across heterogeneous environments using Apache Airflow. In this demo I want to show you how you might approach orchestrating a data pipeline to build a centralised data lake across all your Cloud and non Cloud based data silos, that respect local processing and controls that you might have.
This is what we will end up building.
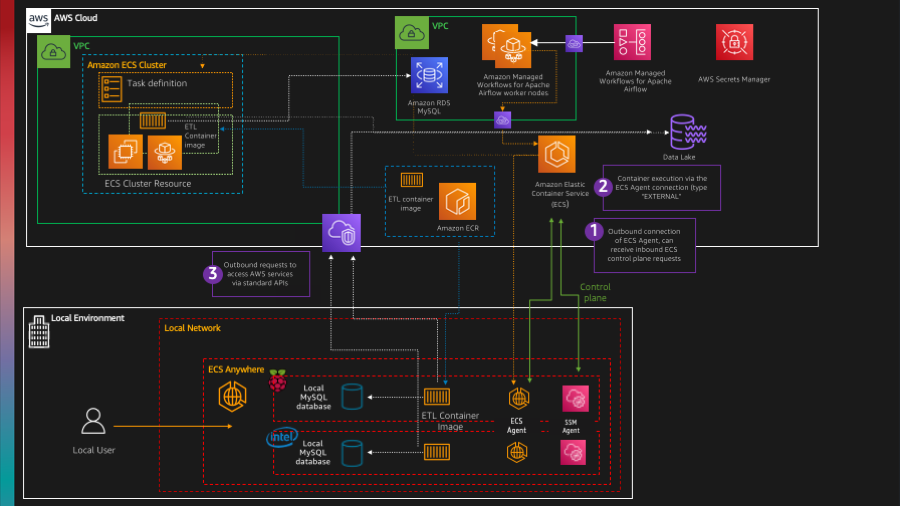
As always, you can find the code for this walk through in this GitHub repo, blogpost-airflow-hybrid
Approach
First up we need to create our demo customer data. I used Mockaroo and found it super intuitive to generate sample data, and then use that to setup a sample customer database running on MySQL. I am not going to cover setting that up, but I have included the data scripts in the repo, and there is a section at the end of this blog where I share my setup if you want to set this up yourself.The demo will have two MySQL databases running, with the same database schema but with different data. One will be running on an Amazon RDS MySQL instance in AWS, and the other I have running on my local Ubuntu machine here at Home HQ.
The goal of this demo/walk through is to orchestrate a workflow that will allow us to do batch extracts from these databases, based on some specific criteria (to simulate some regulator controls for example) and upload these into our data lake. We will be used an Amazon S3 bucket for this purpose, as it is a common scenario.
The approach I am going to take is to create an Apache Airflow workflow (DAG) and leverage an Apache Airflow operator, ECSOperator, which allows us to launch container based images. The container based images we launch will contain our ETL code, and this will be parameterised so that we can re-use this multiple times, changing the behaviour by providing parameters during launch (for example, different SQL queries). Finally, we will use ECS Anywhere, which uses the open source amazon-ecs-agent to simplify how we can run our containers anywhere - in the Cloud, on premises or on other Clouds.
To make this blog post easier to follow, I will break it down into the different tasks. First, creating our ETL container that we can use to extract our data. Following that I will show how we can run this via Amazon ECS, and then walk through the process of deploying ECS Anywhere so we can run it on Amazon EC2 instances (Cloud) and on my humble (very old) Ubuntu 18.04 box (on-prem). With that all working, we will then switch to Apache Airflow and create our DAG that puts these pieces together and creates a workflow that will define and launch these containers to run our ETL scripts and upload our data in our data lake.
Time to get started.
Pre-reqs
If you want to follow along, then you will need the following:
- An AWS account with the right level of privileges and the AWS cli set up and running locally
- AWS CDK installed and configured (the latest version, v1 or v2)
- Docker and Docker Compose in order to be able to build your container images and test locally
- Access to an AWS region where Managed Workflows for Apache Airflow is supported - I will be using eu-west-2 (London)
- An environment of Amazon Managed Workflows for Apache Airflow already setup. You can follow an earlier post, and I have included the AWS CDK code on how to build that environment within the repo
- MySQL databases running a database and data you can query - it doesn’t have to be the same as I have used, you can use your own. I have provided the sql customer dummy data incase you wanted to use that if you try this demo for yourself. They key thing here is that you have one running locally and one running in the cloud. I am using Amazon RDS MySQL, but you could easily run MySQL a different way if you want. I have provided some details on how I set this up at the end of the blog post.
- AWS Secrets configured to contain connection details to the MySQL databases
The AWS cost for running this for 24 hours is around “$45” according to my info on the AWS Billing console.
Creating our ETL container
Creating our ETL script
First up we need to create our Python code that will do our ETL magic. For the sake of simplicity, I have created a simple script that takes some parameters and then runs a query, and uploads the results to Amazon S3.
from copy import copy
from mysql.connector import MySQLConnection, Error
from python_mysql_dbconfig import read_db_config
import sys
import csv
import boto3
import json
import socket
def query_with_fetchone(query2run,secret,region):
try:
# Grab MySQL connection and database settings. We areusing AWS Secrets Manager
# but you could use another service like Hashicorp Vault
# We cannot use Apache Airflow to store these as this script runs stand alone
secret_name = secret
region_name = region
session = boto3.session.Session()
client = session.client(
service_name='secretsmanager',
region_name=region_name
)
get_secret_value_response = client.get_secret_value(SecretId=secret_name)
info=json.loads(get_secret_value_response['SecretString'])
pw=info['password']
un=info['username']
hs=info['host']
db=info['database']
# Output to the log so we can see and confirm WHERE we are running and WHAT
# we are connecting to
print("Connecting to ",str(hs)," database ", str(db), " as user ", str(un))
print("Database host IP is :", socket.gethostbyname(hs))
print("Source IP is ", socket.gethostname())
conn = MySQLConnection(user=un, password=pw, host=hs, database=db)
cursor = conn.cursor()
query=query2run
print("Query is", str(query))
cursor.execute(query)
records = cursor.fetchall()
c = csv.writer(open("temp.csv","w"))
c.writerows(records)
print("Records exported:")
for row in records:
print(row[0],",",row[1],",",row[2],",",row[3],",",row[4],",",row[5], ",",row[6],",",row[7] )
except Error as e:
print(e)
finally:
cursor.close()
conn.close()
def upload_to_s3(s3bucket,s3folder,region):
# We will upload the temp (temp.csv) file and copy it based on the input params of the script (bucket and dir/file)
try:
s3 = boto3.client('s3', region_name=region)
s3.upload_file('temp.csv',s3bucket,s3folder)
except FileNotFoundError:
print("The file was not found")
return False
except Error as e:
print(e)
if __name__ == '__main__':
try:
arg = sys.argv[2]
except IndexError:
raise SystemExit(f"Usage: {sys.argv[0]} <s3 bucket><s3 file><query><secret><region>")
# The script needs the following arguments to run
# 1. Target S3 bucket where the output of the SQL script will be copied
# 2. Target S3 folder/filename
# 3. The query to execute
# 4. The parameter store (we use AWS Secrets) which holds the values on where to find the MySQL database
# 5. The AWS region
s3bucket=sys.argv[1]
s3folder=sys.argv[2]
query2run=sys.argv[3]
secret=sys.argv[4]
region=sys.argv[5]
query_with_fetchone(query2run,secret,region)
upload_to_s3(s3bucket,s3folder,region)
AWS Secrets
This script takes a number of arguments (documented above in the script) and you may see that the 4th argument is a value we have not yet mentioned, the parameter store. When putting a solution like this, we need a central store that our containers will be able to access some key information in a secure way, where ever they might be running. It felt wrong to include credential information in files when using this approach (it is an option, and you can do that with the code in the repo if you wish). I decided I would use AWS Secrets to store the credentials and connection details for the MySQL databases. You could of course use other services such as HashiCorp’s Vault to do a similar thing. All we need is a way of being able to 1/store important credentials, 2/access them where ever our container needs to run.
Our script needs four pieces of information: database host, database name, user to connect to the database and password for the user.
Create a json file (I called my tmp-elt.json) as follows, and then change the values for the ones you need:
{
"username": "app",
"password": "{secure password}",
"host": "localmysql-airflow-hybrid",
"database" : "localdemo"
}
aws secretsmanager create-secret --name localmysql-airflow-hybrid --description "Used by Apache Airflow ELT container" --secret-string file://tmp-elt.json --region={your region}
Which gives me this output.
{
"ARN": "arn:aws:secretsmanager:eu-west-2:xxxxx㊙️localmysql-airflow-hybrid-XXXXXX",
"Name": "localmysql-airflow-hybrid",
"VersionId": "45ff7ccf-2b10-4c0e-bbbc-9fb161a65ecd"
}
And we can check that this has stored everything by trying to retrieve the secret.
Note! this will display the secret values, so be careful when using this command to ensure you do not accidentally disclose those values.
aws secretsmanager get-secret-value --secret-id localmysql-airflow-hybrid --region={your region}
And if successful, you will see your values. The Python script we have created does the same as this step, except it uses the boto3 library in order to interact with and obtain these values.
You should now have defined AWS Secrets for your MySQL databases. In my specific case, the two that I created are:
- localmysql-airflow-hybrid - this is configured to look for a database on my “local” network via a host of localmysql.beachgeek.co.uk
- rds-airflow-hybrid - this is configured to point to my MySQL database configured within Amazon RDS
We are now ready to connect to these databases and start extracting some valuable insights…
Testing our Script
To make sure everything is working before we package up and containerise it, we can run this from the command line. You can run the following command:
(from the docker folder)
python app/read-data-q.py
Which gives us this informational message
Usage: app/read-data-q.py <s3 bucket><s3 file><query><secret><region>
This is expected, as we have not provided any arguments. Now we can try with some arguments.
python app/read-data-q.py ricsue-airflow-hybrid customer/regional-001.csv "select * from customers WHERE country = 'Spain' " rds-airflow-hybrid eu-west-2
and a couple of things should happen. First, you should see some out like the following:
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is a483e7ab1cb5.ant.amazon.com
Query is select * from customers WHERE country = 'Spain'
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
the second is that if you go to your Amazon S3 bucket, you should now have a folder and file called (using the example above) customer/regional-001.csv.
Assuming you have success, we are now ready to move to the next stage which is packaging up this so we can run it via a container.
Containerising our ETL script
Most organisations will have their own workflow for containerising applications, and so feel free to adopt/use those if you want.
In order to containerise our application, we need to create a Docker file. As we are using Python, I am going to select a Python base image for this container (public.ecr.aws/docker/library/python:latest).
The script we created in the previous step is in an app folder, so we set this with the WORKDIR. We then copy to and run PIP to install our Python dependencies (mysql-connector-python and boto3). We then copy the files and specify how we want this container to start when it is run (executing “python3 app/read-data.py” )
FROM public.ecr.aws/docker/library/python:latest
WORKDIR /app
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY . .
CMD [ "python3", "app/read-data.py"]
To build/package our container, we need to 1/ Build our image using docker build, 2/ Tag the image and then 3/ Push the image to a container repository. To simplify this part of the process, you will find a script (setup.sh) which takes our Python script and create our container repository (in Amazon ECR), builds and then tag’s before pushing the image to that repo.
Before running the script you just need to change the variables AWS_DEFAULT_REGION, AWS_ACCOUNT and then if you want to customise for your own purposes, change AWS_ECR_REPO and COMMIT_HASH.
#!/usr/bin/env bash
# Change these values for your own environment
# it should match what values you use in the CDK app
# if you are using this script together to deploy
# the multi-arch demo
AWS_DEFAULT_REGION=eu-west-2
AWS_ACCOUNT=704533066374
AWS_ECR_REPO=hybrid-airflow
COMMIT_HASH="airflw"
# You can alter these values, but the defaults will work for any environment
IMAGE_TAG=${COMMIT_HASH:=latest}
AMD_TAG=${COMMIT_HASH}-amd64
DOCKER_CLI_EXPERIMENTAL=enabled
REPOSITORY_URI=$AWS_ACCOUNT.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com/$AWS_ECR_REPO
# Login to ECR
$(aws ecr get-login --region $AWS_DEFAULT_REGION --no-include-email)
# create AWS ECR Repo
if (aws ecr describe-repositories --repository-names $AWS_ECR_REPO ) then
echo "Skipping the create repo as already exists"
else
echo "Creating repos as it does not exists"
aws ecr create-repository --region $AWS_DEFAULT_REGION --repository-name $AWS_ECR_REPO
fi
# Build initial image and upload to ECR Repo
docker build -t $REPOSITORY_URI:latest .
docker tag $REPOSITORY_URI:latest $REPOSITORY_URI:$AMD_TAG
docker push $REPOSITORY_URI:$AMD_TAG
# Create the image manifests and upload to ECR
docker manifest create $REPOSITORY_URI:$COMMIT_HASH $REPOSITORY_URI:$AMD_TAG
docker manifest annotate --arch amd64 $REPOSITORY_URI:$COMMIT_HASH $REPOSITORY_URI:$AMD_TAG
docker manifest inspect $REPOSITORY_URI:$COMMIT_HASH
docker manifest push $REPOSITORY_URI:$COMMIT_HASH
When you run the script, you should see output similar to the following. From my home broadband connection, this took around 10-15 minutes to complete, so the amount it will take will vary depending on how good your internet speed (upload) is:
Login Succeeded
An error occurred (RepositoryNotFoundException) when calling the DescribeRepositories operation: The repository with name 'hybrid-airflow' does not exist in the registry with id '704533066374'
Creating repos as it does not exists
{
"repository": {
"repositoryArn": "arn:aws:ecr:eu-west-1:704533066374:repository/hybrid-airflow",
"registryId": "704533066374",
"repositoryName": "hybrid-airflow",
"repositoryUri": "704533066374.dkr.ecr.eu-west-1.amazonaws.com/hybrid-airflow",
"createdAt": 1646401450.0,
"imageTagMutability": "MUTABLE",
"imageScanningConfiguration": {
"scanOnPush": false
},
"encryptionConfiguration": {
"encryptionType": "AES256"
}
}
}
[+] Building 1.1s (10/10) FINISHED
=> [internal] load build definition from Dockerfile 0.2s
=> => transferring dockerfile: 43B 0.0s
=> [internal] load .dockerignore 0.1s
=> => transferring context: 2B 0.0s
=> [internal] load metadata for public.ecr.aws/docker/library/python:latest 0.0s
=> [internal] load build context 0.1s
=> => transferring context: 6.51kB 0.0s
=> [1/5] FROM public.ecr.aws/docker/library/python:latest 0.0s
=> CACHED [2/5] WORKDIR /app 0.0s
=> CACHED [3/5] COPY requirements.txt requirements.txt 0.0s
=> CACHED [4/5] RUN pip3 install -r requirements.txt 0.0s
=> [5/5] COPY . . 0.3s
=> exporting to image 0.2s
=> => exporting layers 0.1s
=> => writing image sha256:3a8c17fca355a08ac805d91484b2c40a221e66538bde05d541ce4c63889a420f 0.0s
=> => naming to 704533066374.dkr.ecr.eu-west-1.amazonaws.com/hybrid-airflow:latest 0.0s
Use 'docker scan' to run Snyk tests against images to find vulnerabilities and learn how to fix them
The push refers to repository [704533066374.dkr.ecr.eu-west-1.amazonaws.com/hybrid-airflow]
79b32f350172: Pushed
d2495859a48d: Pushing [=> ] 6.078MB/236.4MB
251a457ff355: Pushed
0ff6b99009cb: Pushed
6da81147b608: Pushed
3a12cc54983b: Pushed
9018eb0987e9: Pushing [=========> ] 11.09MB/56.36MB
ccfb32241621: Pushing [=================================================> ] 18.36MB/18.48MB
204e42b3d47b: Pushing [=> ] 14.71MB/528.4MB
613ab28cf833: Pushing [==> ] 7.124MB/151.9MB
bed676ceab7a: Waiting
6398d5cccd2c: Waiting
0b0f2f2f5279: Waiting
..
..
airflw-amd64: digest: sha256:4012f734f03c125e2dfd97977aafba07232bd3e91936759b6045f764bc948d15 size: 3052
Created manifest list 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw
{
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.docker.distribution.manifest.v2+json",
"size": 3052,
"digest": "sha256:4012f734f03c125e2dfd97977aafba07232bd3e91936759b6045f764bc948d15",
"platform": {
"architecture": "amd64",
"os": "linux"
}
}
]
}
sha256:9b97129b993f94ffb9699a2ea75cce9dae6c541a3f81bc5433c12f6825d71a18
If you open the Amazon ECR console, you should now see your new container repository and image. The container image should now be available via the following resource uri
704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw
Testing our containerised ETL script
Now that we have this script containerised, lets see how it works. First of all we can try the following
docker run 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw
Which should provide you the following output
Unable to find image '704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw' locally
airflw: Pulling from hybrid-airflow
Digest: sha256:9b97129b993f94ffb9699a2ea75cce9dae6c541a3f81bc5433c12f6825d71a18
Status: Downloaded newer image for 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw
Usage: app/read-data-q.py <s3 bucket><s3 file><query><secret><region>
Note! If you get an error such as:
docker: Error response from daemon: pull access denied for 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow, repository does not exist or may require 'docker login': denied: Your authorization token has expired. Reauthenticate and try again.then you can re login to your Amazon ECR environment. This is the command I use, yours will be different based on the region you are in
$(aws ecr get-login --region eu-west-2 --no-include-email)
We know this would generate an error as we have not supplied the correct parameters, but we can see that it is providing the expected behavior. Now lets try with this command:
docker run 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw ricsue-airflow-hybrid customer/regional-001.csv "select * from customers WHERE country = 'Spain' " rds-airflow-hybrid eu-west-2
This time I get a different error. The end part of the error gives us some clues..
...
...
botocore.exceptions.NoCredentialsError: Unable to locate credentials
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/app/app/read-data-q.py", line 79, in <module>
query_with_fetchone(query2run,secret,region)
File "/app/app/read-data-q.py", line 50, in query_with_fetchone cursor.close()
UnboundLocalError: local variable 'cursor' referenced before assignment
The reason for the error is that there are no AWS credentials that this container has in order to interact with AWS. We can easily fix that.
We could add our AWS credentials in our Container but I would NOT recommend that, and it is generally a very bad idea to do so. Instead, we can create two environment variables (AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY) which we will pass into Docker when we run the container as environment variables.
Note Please do not disclose the values of thsee publicly, or store them where others might be able to copy them.
export AWS_ACCESS_KEY_ID=XXXXXXXXX
export AWS_SECRET_ACCESS_KEY=XXXXXXX
We can now change our Docker run command slightly and try again
docker run -e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID -e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw ricsue-airflow-hybrid customer/regional-001.csv "select * from customers WHERE country = 'Spain' " rds-airflow-hybrid eu-west-2
And this time, success!
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is e8d3ffa8e4a2
Query is select * from customers WHERE country = 'Spain'
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
For the eagled eyed, you can see the output is the same (which is re-assuring) but the Source IP is different. This is because this time, the source host was the Docker container running this script.
What about testing this against our local MySQL server which is running a similar data set. I run this command, with the only difference being the AWS Secret which determines which MySQL database to try and connect to.
docker run -e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID -e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw ricsue-airflow-hybrid customer/regional-002.csv "select * from customers WHERE country = 'Spain' " localmysql-airflow-hybrid eu-west-2
We get an error.
Traceback (most recent call last):
File "/app/app/read-data-q.py", line 31, in query_with_fetchone
print("Database host IP is :", socket.gethostbyname(hs))
socket.gaierror: [Errno -2] Name or service not known
During handling of the above exception, another exception occurred:
This is to be expected. At the beginning of this walk through I explained we were using /etc/hosts to do resolution of the database host. Again Docker allows us to enable Host based lookups with a command line options, –network=host so we can retry with this command:
docker run --network=host -e AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID -e AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY 704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw ricsue-airflow-hybrid customer/regional-002.csv "select * from customers WHERE country = 'Spain' " localmysql-airflow-hybrid eu-west-2
Success! This time we get a different set of data (the sample data for the two regions is not the same) and we can see the connection details are updated to reflect we are accessing a local database. In a real world scenario these would be local DNS resolvable addresses you use to connect to your resources.
Connecting to localmysql.beachgeek.co.uk database localdemo as user root
Database host IP is : 127.0.1.1
Source IP is 28d3faa8e331
Query is select * from customers WHERE country = 'Spain'
Records exported:
164 , 2021-04-02 , Dag , Delacourt , ddelacourt4j@nydailynews.com , Male , 200.12.59.159 , Spain
To recap what we have done so far is to containerise our ETL script, and successfully run this against both local and remote instances of our MySQL databases. The next stage is to move these onto a container orchestrator. I am going to be using Amazon ECS, which is my favourite way to run my container applications. Right, let’s get straight to it.
Running our ETL container on Amazon ECS
Creating our ECS Cluster
We are now going to set up an Amazon ECS cluster on AWS, in the same region as where we have been working so far. We could do this manually, but to simplify this part of the setup, within the GitHub repo you will find the cdk/cdk-ecs folder which contains a CDK stack that will deploy and configure an Amazon ECS cluster, and then create an ECS Task Definition which will container all the bits of our ETL container we did above. I have tested this on both v1 and v2 CDK and it works fine with both. This will create a VPC and deploy a new ECS Cluster and an ECS node within that cluster.
We first need to update the app.py and update some of the properties. You will need to update the AWS and Region account for your own environment. The values for ecr-repo and image-tag need to be the same as what we used in the setup of the Amazon ECR repository (the previous steps, where we ran the setup.sh script - the default values used are the same used here). Once updated save the file.
The value for s3 is the target Amazon S3 bucket you will upload files to. This is used to create permissions in this bucket to copy files. If you set this incorrectly, the ETL script will fail to upload because of a lack of permissions.
from aws_cdk import core
from ecs_anywhere.ecs_anywhere_vpc import EcsAnywhereVPCStack
from ecs_anywhere.ecs_anywhere_taskdef import EcsAnywhereTaskDefStack
env_EU=core.Environment(region="eu-west-2", account="704533066374")
props = {
'ecsclustername':'hybrid-airflow',
'ecr-repo': 'hybrid-airflow',
'image-tag' : 'airflw',
'awsvpccidr':'10.0.0.0/16',
's3':'ricsue-airflow-hybrid'
}
app = core.App()
mydc_vpc = EcsAnywhereVPCStack(
scope=app,
id="ecs-anywhere-vpc",
env=env_EU,
props=props
)
mydc_ecs_cicd = EcsAnywhereTaskDefStack(
scope=app,
id="ecs-anywhere-taskdef",
env=env_EU,
vpc=mydc_vpc.vpc,
props=props
)
app.synth()
From the command line, when you type:
cdk ls
You should get something like the following:
ecs-anywhere-vpc
ecs-anywhere-taskdef
We create our Amazon ECS VPC by running:
cdk deploy ecs-anywhere-vpc
Note! Typically an AWS account is limited to 5 VPCs, so check your AWS account to see how many you have configured before running this otherwise running this stack will generate an error.
And when completed, we can deploy our Amazon ECS Cluster by running:
cdk deploy ecs-anywhere-taskdef
(answer Y to any prompts you might get) which should result in output similar to the following:
✅ ecs-anywhere-taskdef
Outputs:
ecs-anywhere-taskdef.ECSClusterName = hybrid-airflow-cluster
ecs-anywhere-taskdef.ECSRoleName = hybrid-airflow-ECSInstanceRole
ecs-anywhere-taskdef.ECSAnywhereRoleName = hybrid-airflow-ExternalECSAnywhereRole
Stack ARN:
arn:aws:cloudformation:eu-west-2:704533066374:stack/ecs-anywhere-taskdef/28b05150-9b9c-11ec-a2db-02449e7c3502
We will need some of the values that this CDK app has output, so take note of these.
We can validate that everything has been setup by going to the AWS console and viewing the Amazon ECS console. Alternatively we can run the following command:
aws ecs list-clusters --region={your region}
Which should display something like the following (depending on how many other ECS Clusters you might already have setup) and we can see that we have our new ECS Cluster - the name is defined in the variables in the app.py of ecsclustername (“hybrid-airflow”) following by “-cluster”.
{
"clusterArns": [
"arn:aws:ecs:eu-west-2:704533066374:cluster/hybrid-airflow-cluster"
]
}
Exploring the ECS CDK stack
Before continuing it is worth covering what exactly we just did by exploring the CDK file. The CDK file that deployed this ECS Cluster and configured our Task Definition (the thing that will run our application) is “ecs_anywhere_taskdef.py”. As we can see from the beginning of the file, we import the values from the app.py (“props”) which we will use to define things like the name of the ECS Cluster, the Container image, permissions and so on.
class EcsAnywhereTaskDefStack(core.Stack):
def __init__(self, scope: core.Construct, id: str, vpc, props, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
We create variables for the container image of our ETL application, by referencing the container repository (here we are using Amazon ECR, but you could use others).
airflow_repo = ecr.Repository.from_repository_name(self, "Hybrid-ELT-Repo", repository_name=f"{props['ecr-repo']}")
airflow_image = ecs.ContainerImage.from_ecr_repository(airflow_repo, f"{props['image-tag']}")
When we create the ECS Cluster, it will create an EC2 instance and this instance will need an IAM Role to give it the needed permissions. This is the ECS Task Execution Role. Here we only need to define it and give it a name “role_name”
ecscluster_role = iam.Role(
self,
f"{props['ecsclustername']}-ecsrole",
role_name=f"{props['ecsclustername']}-ECSInstanceRole",
assumed_by=iam.ServicePrincipal("ssm.amazonaws.com"),
managed_policies=[iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSSMManagedInstanceCore")]
)
ecscluster_role.add_managed_policy(iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AmazonEC2ContainerServiceforEC2Role"))
We then create our ECS Cluster, give it a name and then provision some EC2 resources using the IAM Role we just created
ecscluster = ecs.Cluster(
self,
f"{props['ecsclustername']}-ecscluster",
cluster_name=f"{props['ecsclustername']}-cluster",
vpc=vpc
)
ecscluster.add_capacity(
"x86AutoScalingGroup",
instance_type=ec2.InstanceType("t2.xlarge"),
desired_capacity=1
)
We now need to create a Role for the ECS Task definition. This will be the IAM Role that our application will use, so we define here the different permissions scoped as low as possible. We pass in some of those variables such as the S3 bucket and the ECS Cluster name.
First we create the policy.
data_lake = s3.Bucket.from_bucket_name(self, "DataLake", f"{props['s3']}")
data_lake_arn = data_lake.bucket_arn
task_def_policy_document = iam.PolicyDocument(
statements=[
iam.PolicyStatement(
actions=[ "s3:*" ],
effect=iam.Effect.ALLOW,
resources=[
f"{data_lake_arn}/*",
f"{data_lake_arn}"
],
),
iam.PolicyStatement(
actions=[
"ecs:RunTask",
"ecs:DescribeTasks",
"ecs:RegisterTaskDefinition",
"ecs:DescribeTaskDefinition",
"ecs:ListTasks"
],
effect=iam.Effect.ALLOW,
resources=[
"*"
],
),
iam.PolicyStatement(
actions=[
"iam:PassRole"
],
effect=iam.Effect.ALLOW,
resources=[ "*" ],
conditions= { "StringLike": { "iam:PassedToService": "ecs-tasks.amazonaws.com" } },
),
iam.PolicyStatement(
actions=[
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents",
"logs:GetLogEvents",
"logs:GetLogRecord",
"logs:GetLogGroupFields",
"logs:GetQueryResults"
],
effect=iam.Effect.ALLOW,
resources=[
f"arn:aws:logs:*:*:log-group:/ecs/{props['ecsclustername']}:log-stream:/ecs/*"
]
)
]
)
And then we create the IAM Roles, and attach any managed policies we might need (in this case, we want to use the Secrets Manager managed policy so we can read our secrets)
task_def_policy_document_role = iam.Role(
self,
"ECSTaskDefRole",
role_name=f"{props['ecsclustername']}-ECSTaskDefRole",
assumed_by=iam.ServicePrincipal("ecs-tasks.amazonaws.com"),
inline_policies={"ECSTaskDefPolicyDocument": task_def_policy_document}
)
managed_secret_manager_policy = iam.ManagedPolicy.from_aws_managed_policy_name("SecretsManagerReadWrite")
task_def_policy_document_role.add_managed_policy(managed_secret_manager_policy)
The final bit is to actually create our Task Definition, defining the actual container image, the command override, the resources, etc. We also need to define and then create the AWS CloudWatch logging group so we can view the logs in AWS CloudWatch. You can configure other logging targets if you want.
log_group = log.LogGroup(
self,
"LogGroup",
log_group_name=f"/ecs/{props['ecsclustername']}"
)
ec2_task_definition = ecs.Ec2TaskDefinition(
self,
f"{props['ecsclustername']}-ApacheAirflowTaskDef",
family="apache-airflow",
network_mode=ecs.NetworkMode.HOST,
task_role=task_def_policy_document_role
)
ec2_task_definition.add_container(
"Hybrid-ELT-TaskDef",
image=airflow_image,
memory_limit_mib=1024,
cpu=100,
# Configure CloudWatch logging
logging=ecs.LogDrivers.aws_logs(stream_prefix=f"{props['ecsclustername']}",log_group=log_group),
essential=True,
command= [ "ricsue-airflow-hybrid", "period1/hq-data.csv", "select * from customers WHERE country = \"Spain\"", "rds-airflow-hybrid", "eu-west-2" ],
)
And that is it, once deployed, in around 5 minutes we have our new ECS Cluster, with an EC2 resource up and running and our Task Definition defined and ready to run. In theory, we can now just run this and it should be the same as when we ran it locally using Docker.
Running our ELT Container (Amazon ECS Task Definition)
From a command line, you can kick off this Task by running the following command.
export ECS_CLUSTER="hybrid-airflow-cluster"
export TASK_DEF="apache-airflow"
export DEFAULT_REGION="eu-west-2"
aws ecs run-task --cluster $ECS_CLUSTER --launch-type EC2 --task-definition $TASK_DEF --region=$DEFAULT_REGION
Which should create output like this:
{
"tasks": [
{
"attachments": [],
"attributes": [
{
"name": "ecs.cpu-architecture",
"value": "x86_64"
}
],
"availabilityZone": "eu-west-2b",
"clusterArn": "arn:aws:ecs:eu-west-2:704533066374:cluster/hybrid-airflow-cluster",
"containerInstanceArn": "arn:aws:ecs:eu-west-2:704533066374:container-instance/hybrid-airflow-cluster/c7550837cbcb4a19a1fdcd79cb600062",
"containers": [
{
"containerArn": "arn:aws:ecs:eu-west-2:704533066374:container/hybrid-airflow-cluster/b357bc55e60b4557a2eccb3619a8ec64/a30c90c7-25f8-4091-8532-69cdf6d8c3ce",
"taskArn": "arn:aws:ecs:eu-west-2:704533066374:task/hybrid-airflow-cluster/b357bc55e60b4557a2eccb3619a8ec64",
"name": "Hybrid-ELT-TaskDef",
"image": "704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw",
"lastStatus": "PENDING",
"networkInterfaces": [],
"cpu": "100",
"memory": "1024"
}
],
"cpu": "100",
"createdAt": 1646582727.378,
"desiredStatus": "RUNNING",
"enableExecuteCommand": false,
"group": "family:apache-airflow",
"lastStatus": "PENDING",
"launchType": "EC2",
"memory": "1024",
"overrides": {
"containerOverrides": [
{
"name": "Hybrid-ELT-TaskDef"
}
],
"inferenceAcceleratorOverrides": []
},
"tags": [],
"taskArn": "arn:aws:ecs:eu-west-2:704533066374:task/hybrid-airflow-cluster/b357bc55e60b4557a2eccb3619a8ec64",
"taskDefinitionArn": "arn:aws:ecs:eu-west-2:704533066374:task-definition/apache-airflow:6",
"version": 1
}
],
"failures": []
}
We have configured AWS CloudWatch logging, so we can go here to see the output of this. From the CDK stack we defined our logging group “/ecs/hybrid-airflow” so we can open up this log group and we can see an entry in the format of
hybrid-airflow/Hybrid-ELT-TaskDef/b357bc55e60b4557a2eccb3619a8ec64
When we open up this stream we can see that the output is exactly what we expected, and matches what we can when we ran this container locally.
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is ip-10-0-3-129.eu-west-2.compute.internal
Query is select * from customers WHERE country = "Spain"
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
We have now successfully run our containerised ETL script in the Cloud. Next step, running this anywhere with ECS Anywhere…
Deploying ECS Anywhere
Before we can run our containerised ETL script in our local environment, we need to install the Amazon ECS Anywhere agent. This extends the Amazon ECS control plane and allows you to integrate external resources that allow you to run your Task Definitions (your apps) wherever the ECS Anywhere agent is running. These appear as a new ECS launch type of “EXTERNAL” (whereas when you run your Task Definitions you might typically be using EC2 or FARGATE).
Note! If you want to dive deeper that I suggest you check out the ECS Workshop where they have a dedicated section on ECS Anywhere.
To deploy ECS Anywhere, we will need to do the following:
- Create a new IAM Role that will be used by ECS Anywhere (the control plane)
- Install the ECS Anywhere Agent and integrating into an existing ECS Cluster
Before diving in though, which kinds of hosts can you deploy the ECS Anywhere agent onto? You can check the latest OSs supported by visiting the FAQ page. As of writing, this includes Amazon Linux 2, Bottlerocket, Ubuntu, RHEL, SUSE, Debian, CentOS, and Fedora. You should also consider the host resources, as the CPU and Memory available will dictate how Tasks are executed on which hosts. Which ever distribution you use, you will need to have the AWS cli installed and configured so make sure this has been done before proceeding.
NEWS FLASH Announced this week, you can now run the ECS Anywhere agent on Windows. I am very excited about this, and I will try and find a Windows machine on which to try this out as an addendum in the future.
For the purposes of this walkthrough, I have used two different hosts. The first is my local Ubuntu 18.04 box which is sat next to me. It has an Intel i5 CPU (quad core) and 8 GB of ram. The second is an EC2 instance, an m6i.large which has 2vCPUs and 8GB ram. This is running Amazon Linux 2. As you will recall from the pre-req’s, on BOTH of these instances, I have installed MySQL and amended the /etc/hosts to add a local hosts entry to the name “localmysql.beachgeek.co.uk”.
The EC2 instance is ip-10-0-0-207.eu-west-2.compute.internal, and we will see this later as confirmation that this “local” ECS Anywhere agent is running our ETL scripts.
Creating the IAM Role
Before we install the ECS Anywhere agent, we need to create an IAM Role which will be used by the agent. This will have been created by the ECS CDK stack, and we can look at the code that creates this:
external_task_def_policy_document_role = iam.Role(
self,
"ExternalECSAnywhereRole",
role_name=f"{props['ecsclustername']}-ExternalECSAnywhereRole",
assumed_by=iam.ServicePrincipal("ecs-tasks.amazonaws.com")
)
external_managed_SSM_policy = iam.ManagedPolicy.from_aws_managed_policy_name("AmazonSSMManagedInstanceCore")
external_managed_ECS_policy = iam.ManagedPolicy.from_aws_managed_policy_name("service-role/AmazonEC2ContainerServiceforEC2Role")
external_task_def_policy_document_role.add_managed_policy(external_managed_SSM_policy)
external_task_def_policy_document_role.add_managed_policy(external_managed_ECS_policy)
As we can see it adds to AWS IAM Managed policies (“AmazonSSMManagedInstanceCore” and “AmazonEC2ContainerServiceforEC2Role”) which will provide the ECS Anywhere agent everything it needs to connect to and register as an external managed instance in the ECS Cluster. The output of this will be displayed when you deployed the script:
ecs-anywhere-taskdef.ECSAnywhereRoleName = hybrid-airflow-ExternalECSAnywhereRole
We will need this when we install the ECS Anywhere agent.
Installing & integration of ECS Anywhere
There are two ways you can do this. Via a script that is generated via the Amazon ECS Console, or via the cli.
Via the Amazon ECS Console
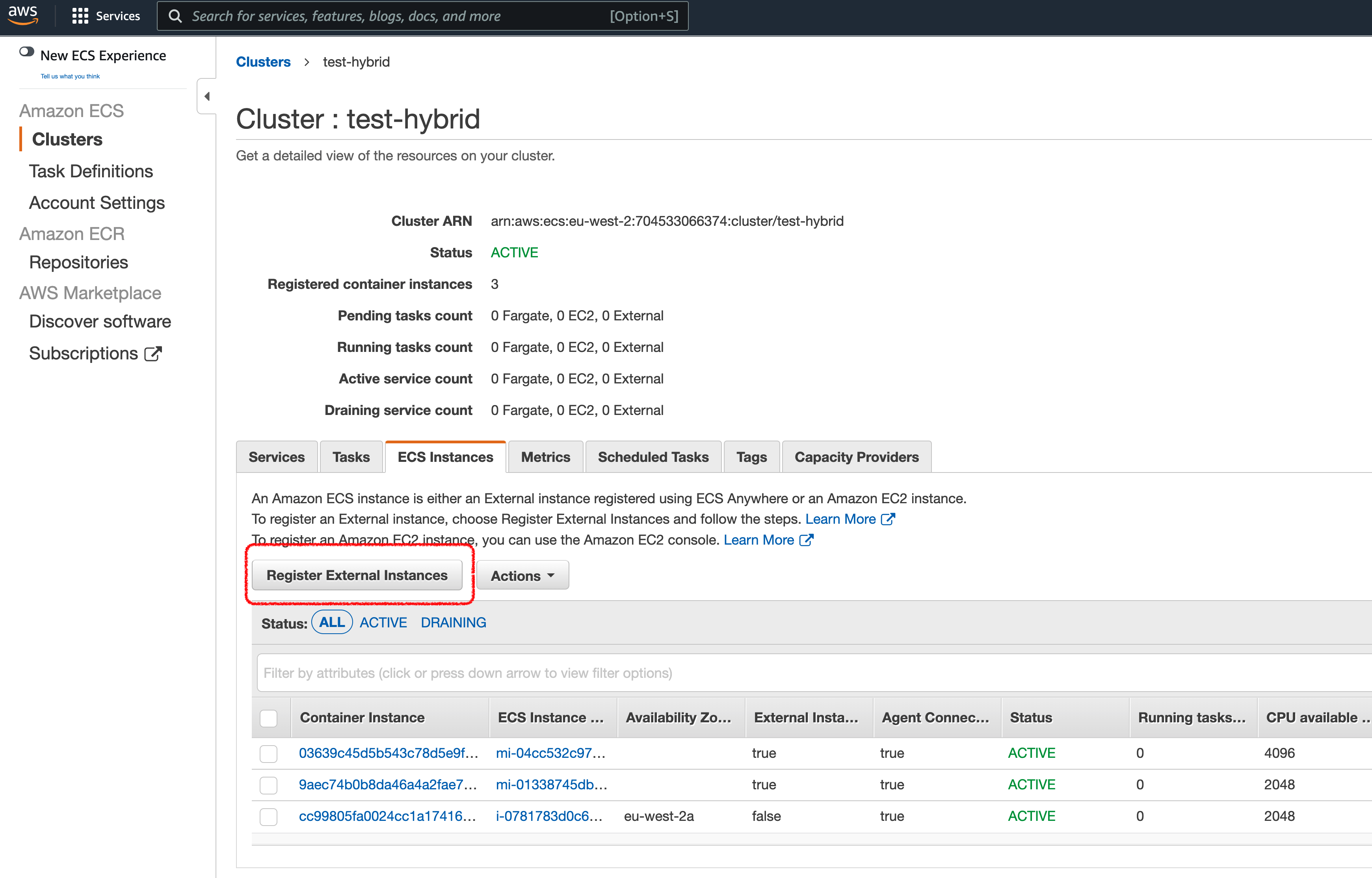
From the Amazon ECS Console, there is an easy way to add an external resource via the ECS Anywhere agent. If you click on the ECS Cluster, you will see a button that allows you to “Register External Instances”.
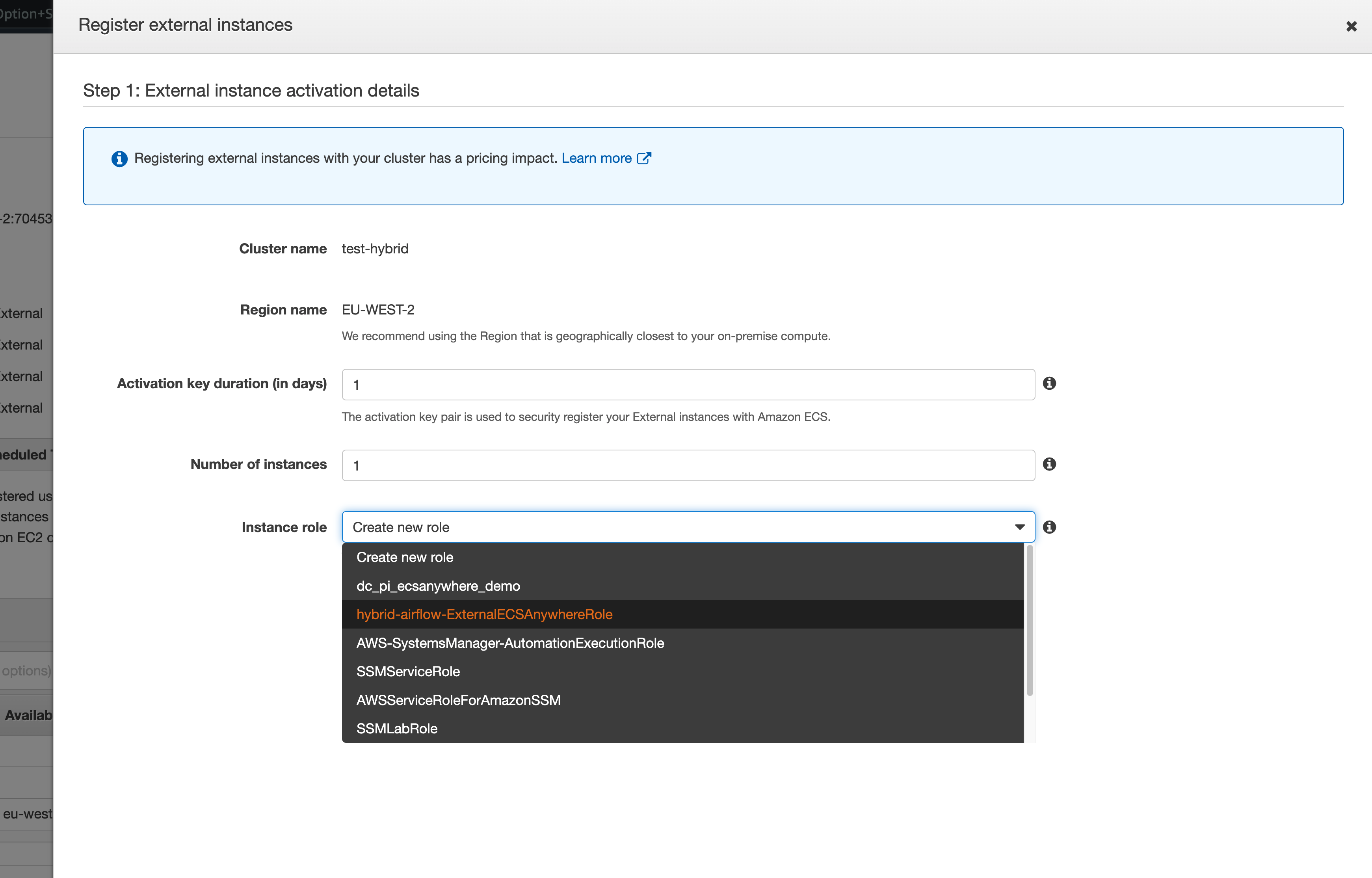
When you click on it, you will need to select the name of the IAM Role we just created. In the example above, it will be “hybrid-airflow-ExternalECSAnywhereRole” but it may be different if you are following along.
When you click on NEXT, you will see some text. You will use this to install the ECS Anywhere agent. Copy this and then paste it into a terminal of the system you want to install the ECS Anywhere agent.
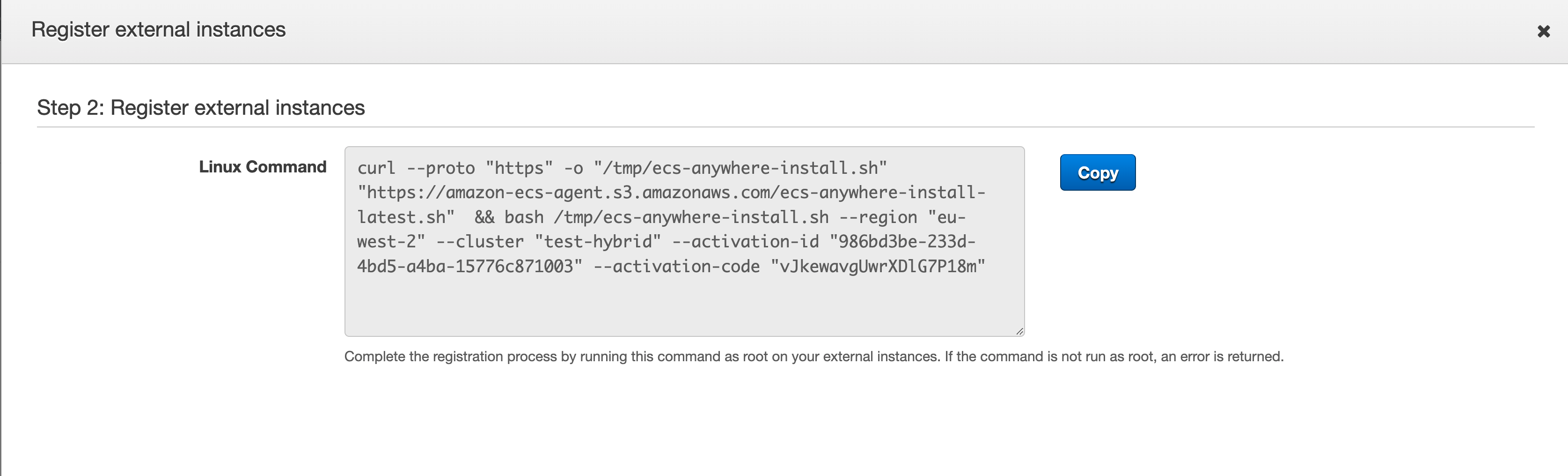
Note! Be careful as this activation script is time bound and will expire after a period of time. Do not share this and make it public. I have changed the details in the screenshot, so this is for illustration purposes only.
The installation process will take 5-10 minutes, and you will get confirmation if successful.
You can confirm that you now have a new resource in your ECS Cluster, by clicking on the ECS Cluster and checking for External Instances (highlighted in red, you can see here I have two registered)
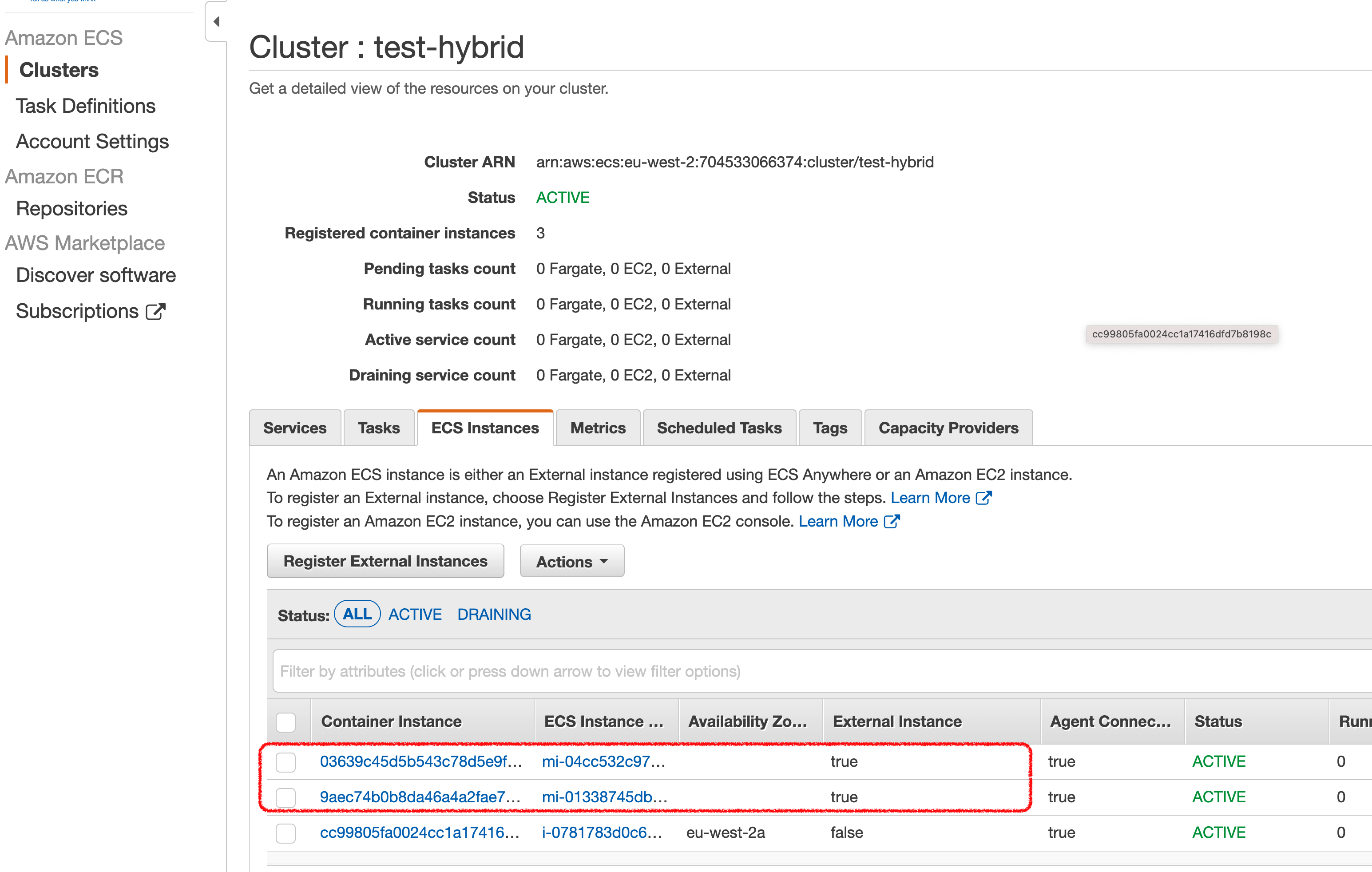
Via the Amazon ECS Console
To install via the command line, first open up a terminal session in the machine you want to install the agent. First I create some environment variables:
- ECS_CLUSTER={the name of the ECS cluster}
- ROLE={the name of the ECS Anywhere Role}
- DEFAULT_REGION={the AWS region you are working in}
Using my example above, I create the following
export ECS_CLUSTER="hybrid-airflow-cluster"
export ROLE_NAME="hybrid-airflow-ExternalECSAnywhereRole"
export DEFAULT_REGION="eu-west-2"
Now run this command on the machine
aws ssm create-activation --iam-role $ROLE_NAME | tee ssm-activation.json
Which will given you output similar to. A file will be created (ssm-activation.json) which contains this info.
{
"ActivationCode": "sAsr8ZpOktv/hFnytAWS",
"ActivationId": "b9dbd803-3b67-4719-b23e-d6f849722007"
}
We will now create a couple of new environment variables with these values:
export ACTIVATION_ID="b9dbd803-3b67-4719-b23e-d6f849722007"
export ACTIVATION_CODE="sAsr8ZpOktv/hFnytAWS"
Next we download the agent installation script
curl -o "ecs-anywhere-install.sh" "https://amazon-ecs-agent.s3.amazonaws.com/ecs-anywhere-install-latest.sh" && sudo chmod +x ecs-anywhere-install.sh
And then finally, we run the script passing in the environment variables we have already created
sudo ./ecs-anywhere-install.sh \
--cluster $ECS_CLUSTER \
--activation-id $ACTIVATION_ID \
--activation-code $ACTIVATION_CODE \
--region $DEFAULT_REGION
The script will now start to install, connect and then register the AWS SSM and ECS agents. If successful, you will see something like this:
# Trying to wait for ECS agent to start ...
Ping ECS Agent registered successfully! Container instance arn: "arn:aws:ecs:eu-west-2:704533066374:container-instance/hybrid-airflow-cluster/6863489c26b24c27ad2f91c458b3bd82"
You can check your ECS cluster here https://console.aws.amazon.com/ecs/home?region=eu-west-2#/clusters/hybrid-airflow-cluster
# ok
As with the Console installation, you can check that this has worked by checking the AWS ECS Console. You can also use the command line:
aws ecs list-container-instances --cluster $ECS_CLUSTER
Which should provide you something similar to the following:
{
"containerInstanceArns": [
"arn:aws:ecs:eu-west-2:704533066374:container-instance/hybrid-airflow-cluster/6863489c26b24c27ad2f91c458b3bd82",
"arn:aws:ecs:eu-west-2:704533066374:container-instance/hybrid-airflow-cluster/c7550837cbcb4a19a1fdcd79cb600062"
]
}
As you can see, the first instance there is the one we have just integrated into the ECS Cluster. Now that we have this installed, we can test running our ETL container via Amazon ECS.
Troubleshooting
Note! I have previously covered installation of the ECS Anywhere on a previous blog post (most viewed blog post) which provides some additional details that you can refer to if you get stuck!
Running our ETL script “locally”
We now have “EXTERNAL” resources within our ECS Cluster, which enable us to determine where we want to run our Task Definitions (our containerised ETL script in this case). We can try this out next.
Running our Task locally
From a command line, you can kick off running our containerised ETL script by running the following command. You will notice it is exactly the same command, the only difference is that the launch-type parameter has changed to EXTERNAL.
export ECS_CLUSTER="hybrid-airflow-cluster"
export TASK_DEF="apache-airflow"
export DEFAULT_REGION="eu-west-2"
aws ecs run-task --cluster $ECS_CLUSTER --launch-type EXTERNAL --task-definition $TASK_DEF --region=$DEFAULT_REGION
When we kick this off, we get a similar output. Notice the “launchType” this time, we shows up as “EXTERNAL”.
{
"tasks": [
{
"attachments": [],
"attributes": [
{
"name": "ecs.cpu-architecture",
"value": "x86_64"
}
],
"clusterArn": "arn:aws:ecs:eu-west-2:704533066374:cluster/hybrid-airflow-cluster",
"containerInstanceArn": "arn:aws:ecs:eu-west-2:704533066374:container-instance/hybrid-airflow-cluster/6863489c26b24c27ad2f91c458b3bd82",
"containers": [
{
"containerArn": "arn:aws:ecs:eu-west-2:704533066374:container/hybrid-airflow-cluster/fc43322ecb55404fa086c266329b3a4c/8e387f3d-aa7d-4878-adfd-194866d35e25",
"taskArn": "arn:aws:ecs:eu-west-2:704533066374:task/hybrid-airflow-cluster/fc43322ecb55404fa086c266329b3a4c",
"name": "Hybrid-ELT-TaskDef",
"image": "704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw",
"lastStatus": "PENDING",
"networkInterfaces": [],
"cpu": "100",
"memory": "1024"
}
],
"cpu": "100",
"createdAt": 1646652352.003,
"desiredStatus": "RUNNING",
"enableExecuteCommand": false,
"group": "family:apache-airflow",
"lastStatus": "PENDING",
"launchType": "EXTERNAL",
"memory": "1024",
"overrides": {
"containerOverrides": [
{
"name": "Hybrid-ELT-TaskDef"
}
],
"inferenceAcceleratorOverrides": []
},
"tags": [],
"taskArn": "arn:aws:ecs:eu-west-2:704533066374:task/hybrid-airflow-cluster/fc43322ecb55404fa086c266329b3a4c",
"taskDefinitionArn": "arn:aws:ecs:eu-west-2:704533066374:task-definition/apache-airflow:6",
"version": 1
}
],
"failures": []
}
As we did before, we can check in the CloudWatch logs and we can see this worked. We can see that the Source IP is our “local” ECS Anywhere instance.
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is ip-10-0-0-207.eu-west-2.compute.internal
Query is select * from customers WHERE location = "Spain"
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
Accessing local resources
The previous example showed us running our containerised ETL script but accessing resources in the Cloud. For the specific use case we are looking at (hybrid orchestration) we really need to show this accessing local resources. We will do that in the next section, as we move to how we can orchestrate these via Apache Airflow.
Creating and running our hybrid workflow using Apache Airflow
Up until now, we have validated that we can take our ETL script, containerise it and then run it anywhere: Cloud, locally and even our developer setup. The next stage is to incorporate this as part of our data pipeline, using Apache Airflow.
Setting up Apache Airflow
To start off with we need an Apache Airflow environment. I have put together a post on how you can get this up and running on AWS using Managed Workflows for Apache Airflow (MWAA), which you can check out here. I have included the code within the code repo.
ECSOperator
Apache Airflow has a number Operators, which you can think of as templates that make it easier to perform tasks. These Operators are used when you define tasks, and you pass in various details and the code behind the Operators does the heavy lifting. There are a number of Operators that enable you to work with AWS services (these are packaged into what is called the Amazon provider package) and the one we are interested in is the ECS Operator, which allows us to define and run ECS Tasks - i.e. our ETL container script.
MWAA uses dedicated workers to execute the tasks, and in order to govern what these worker nodes can do, they have an IAM Role. The IAM Role (known as the MWAA Execution Policy) governs what resources your workflows have access to. We need to add some additional permissions if we want our workflows (and therefore, the worker nodes) to be able to create and run ECS Tasks. The required permissions have been added to the CDK script, but are here for reference:
iam.PolicyStatement(
actions=[
"ecs:RunTask",
"ecs:DescribeTasks",
"ecs:RegisterTaskDefinition",
"ecs:DescribeTaskDefinition",
"ecs:ListTasks"
],
effect=iam.Effect.ALLOW,
resources=[
"*"
],
),
iam.PolicyStatement(
actions=[
"iam:PassRole"
],
effect=iam.Effect.ALLOW,
resources=[ "*" ],
conditions= { "StringLike": { "iam:PassedToService": "ecs-tasks.amazonaws.com" } },
),
Creating our Workflow
Withe the foundational stuff now done, we can create our workflow. It starts off like any other typical DAG by importing the Python libraries we are going to use. As you can see, we import the ECSOperator.
from airflow import DAG
from datetime import datetime, timedelta
from airflow.providers.amazon.aws.operators.ecs import ECSOperator
default_args = {
'owner': 'ubuntu',
'start_date': datetime(2022, 3, 9),
'retry_delay': timedelta(seconds=60*60)
}
We now create our task, using the ECSOperator and supplying configuration details. In the example below I have hard coded some of the values (for example the ECS Cluster name and Task Definitions, but you could either store these as variables within Apache Airflow, a centralised store like AWS Secrets, or event use a parameter file when triggering the DAG.
with DAG('hybrid_airflow_dag', catchup=False, default_args=default_args, schedule_interval=None) as dag:
cloudquery = ECSOperator(
task_id="cloudquery",
dag=dag,
cluster="hybrid-airflow-cluster",
task_definition="apache-airflow",
overrides={ },
launch_type="EC2",
awslogs_group="/ecs/hybrid-airflow",
awslogs_stream_prefix="ecs/Hybrid-ELT-TaskDef",
reattach = True
)
cloudquery
And that is it. We have not defined a schedule, we will just make this an on demand workflow for testing. We save this (the code is in the repo) and upload it into the Apache Airflow DAGs folder and in a few seconds the workflow should appear in the Apache Airflow UI.
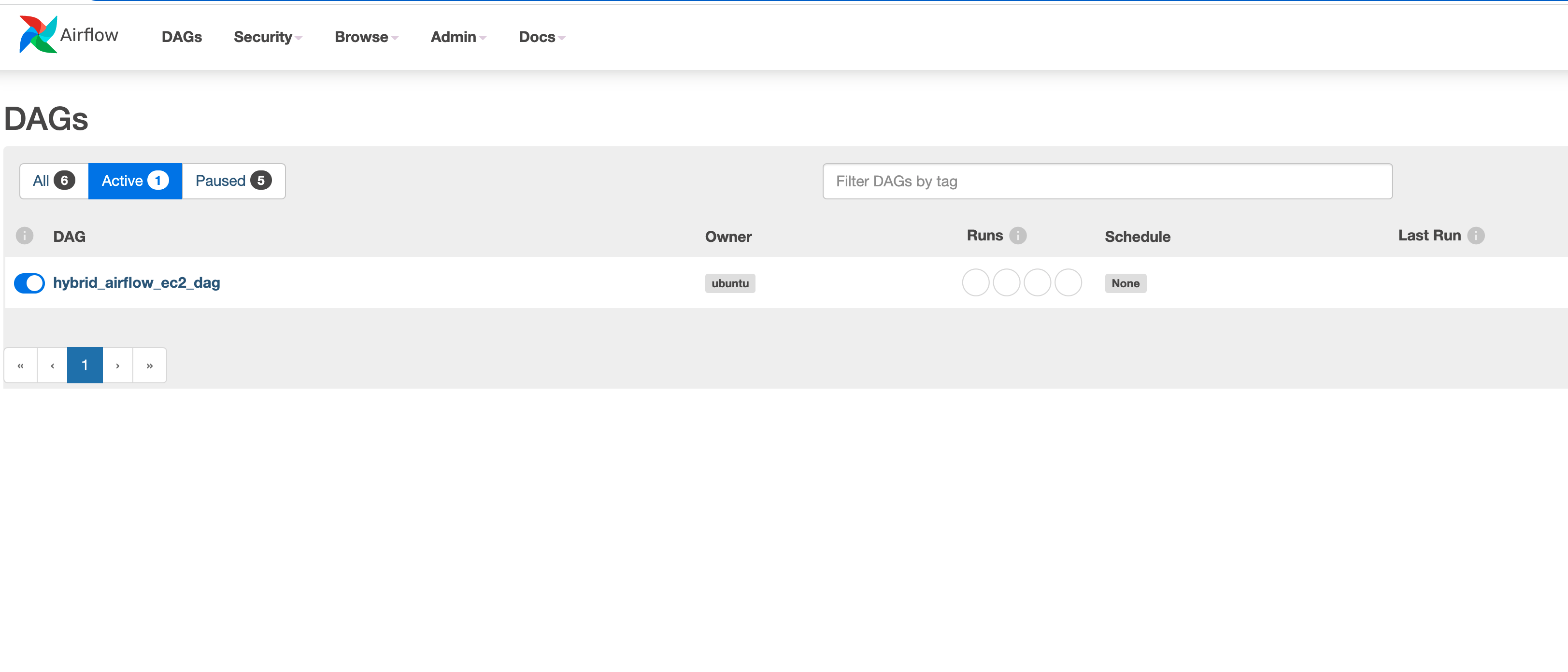
Running our Workflow - Cloud
We can enable the workflow by unpausing it, and then we can trigger it to test. Once triggered, Apache Airflow will submit this task to the scheduler which will queue the task via the executor to a MWAA worker node. The task will execute on there, running the ECS Task Definition using the parameters above. These are the same that we used when we ran this via the command line.
After about 2-3 minutes, the task should complete. The colour of the task in the Apache Airflow UI will change from light green (running) to dark green (complete). We can now view the log by clicking on the task and click on Log. You will see something similar to the following (I have omitted some of the log for brevity):
...
--------------------------------------------------------------------------------
[2022-03-06, 21:05:07 UTC] {{taskinstance.py:1242}} INFO - Starting attempt 1 of 1
[2022-03-06, 21:05:07 UTC] {{taskinstance.py:1243}} INFO -
--------------------------------------------------------------------------------
[2022-03-06, 21:05:08 UTC] {{taskinstance.py:1262}} INFO - Executing <Task(ECSOperator): cloudquery> on 2022-03-06 21:05:06.837966+00:00
[2022-03-06, 21:05:08 UTC] {{standard_task_runner.py:52}} INFO - Started process 13324 to run task
[2022-03-06, 21:05:08 UTC] {{standard_task_runner.py:52}} INFO - Started process 13324 to run task
[2022-03-06, 21:05:08 UTC] {{standard_task_runner.py:77}} INFO - Job 346: Subtask cloudquery
[2022-03-06, 21:05:08 UTC] {{base_aws.py:401}} INFO - Airflow Connection: aws_conn_id=aws_default
[2022-03-06, 21:05:08 UTC] {{base_aws.py:190}} INFO - No credentials retrieved from Connection
[2022-03-06, 21:05:08 UTC] {{base_aws.py:93}} INFO - Creating session with aws_access_key_id=None region_name=eu-west-2
[2022-03-06, 21:05:08 UTC] {{base_aws.py:168}} INFO - role_arn is None
[2022-03-06, 21:05:08 UTC] {{logging_mixin.py:109}} INFO - Running <TaskInstance: hybrid_airflow_ec2_dag.cloudquery manual__2022-03-06T21:05:06.837966+00:00 [running]> on host ip-10-192-20-189.eu-west-2.compute.internal
[2022-03-06, 21:05:08 UTC] {{taskinstance.py:1429}} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_OWNER=ubuntu
AIRFLOW_CTX_DAG_ID=hybrid_airflow_ec2_dag
AIRFLOW_CTX_TASK_ID=cloudquery
AIRFLOW_CTX_EXECUTION_DATE=2022-03-06T21:05:06.837966+00:00
AIRFLOW_CTX_DAG_RUN_ID=manual__2022-03-06T21:05:06.837966+00:00
[2022-03-06, 21:05:08 UTC] {{ecs.py:300}} INFO - Running ECS Task - Task definition: apache-airflow - on cluster hybrid-airflow-cluster
[2022-03-06, 21:05:08 UTC] {{ecs.py:302}} INFO - ECSOperator overrides: {}
[2022-03-06, 21:05:08 UTC] {{ecs.py:418}} INFO - No active previously launched task found to reattach
[2022-03-06, 21:05:08 UTC] {{ecs.py:375}} INFO - ECS Task started:
[2022-03-06, 21:05:08 UTC] {{ecs.py:379}} INFO - ECS task ID is: 42a9f08a68ce46f985a3177e9aca3bce
[2022-03-06, 21:05:08 UTC] {{ecs.py:313}} INFO - Starting ECS Task Log Fetcher
[2022-03-06, 21:06:09 UTC] {{ecs.py:328}} INFO - ECS Task has been successfully executed
[2022-03-06, 21:06:09 UTC] {{taskinstance.py:1280}} INFO - Marking task as SUCCESS. dag_id=hybrid_airflow_ec2_dag, task_id=cloudquery, execution_date=20220306T210506, start_date=20220306T210507, end_date=20220306T210609
[2022-03-06, 21:06:09 UTC] {{local_task_job.py:154}} INFO - Task exited with return code 0
[2022-03-06, 21:06:09 UTC] {{local_task_job.py:264}} INFO - 0 downstream tasks scheduled from follow-on schedule check
If we look at the logs in our AWS CloudWatch group.
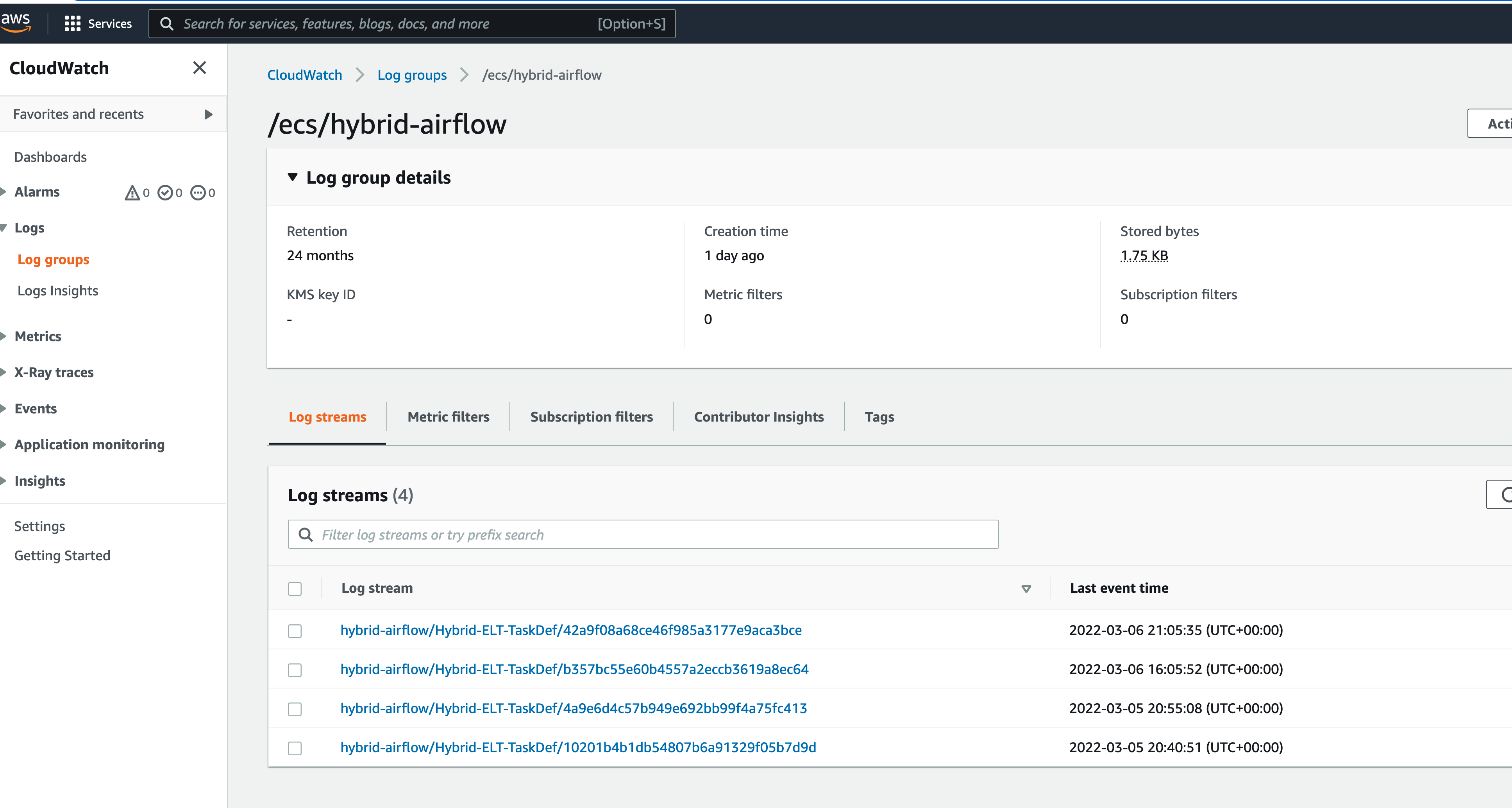
We can see the following:
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is ip-10-0-3-129.eu-west-2.compute.internal
Query is select * from customers WHERE country = "Spain"
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
Success! We have now triggered our workflow via Apache Airflow. The Task Definition ran on our EC2 instance that is in the Cloud (we can see that from the Source IP and by checking this against the EC2 instance that is running containers for the ECS Cluster). Now see how to trigger the task locally.
Running our Workflow - Local
To run our task on our local node, all we need to do is change the “launch_type” from “EC2” to “EXTERNAL”. When the ECS Cluster receives the request to run this task, it will take a look at which nodes are running the ECS Anywhere agent, and then select on to run the task on there.
remotequery = ECSOperator(
task_id="remotequery",
dag=dag,
cluster="hybrid-airflow-cluster",
task_definition="apache-airflow",
overrides={ },
launch_type="EXTERNAL",
awslogs_group="/ecs/hybrid-airflow",
awslogs_stream_prefix="ecs/Hybrid-ELT-TaskDef",
reattach = True
)
remotequery
When we create a new DAG that does this and upload it (the code is in the repo) we can trigger this in exactly the same way. Once triggered, like before we need to wait 2-3 minutes. Once finished, we can check the Logs within the Apache Airflow UI, or via the CloudWatch log stream.
Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com database demo as user admin
Database host IP is : 18.169.169.151
Source IP is ip-10-0-0-207.eu-west-2.compute.internal
Query is select * from customers WHERE country = "Spain"
Records exported:
171 , 2021-06-21 18:24:25 , Wiatt , Revell , wrevell4q@umn.edu , Female , 26.6.23.83 , Spain
632 , 2021-11-14 18:44:25 , Sheppard , Rylett , sryletthj@java.com , Genderfluid , 50.1.207.70 , Spain
783 , 2021-03-29 18:05:12 , Sloane , Maylour , smaylourlq@1und1.de , Female , 194.84.247.201 , Spain
We can see that this time the source IP is our local machine where we have the ECS Anywhere agent running.
Running our Workflow - Local and accessing local resources
In the previous example, we were still accessing the Cloud based MySQL database (“Connecting to demords.cidws7o4yy7e.eu-west-2.rds.amazonaws.com…") but what we really want to do is to connect to our local resources when orchestrating these kinds of hybrid tasks. Lets do that now.
If you can recall, the ETL script uses parameters stored in AWS Secrets (you could use a different repository if you wanted) to know which MySQL database to connect to. We can see this in the command we pass into the containerised ETL script
"command" : [ "ricsue-airflow-hybrid","period1/region-data.csv", "select * from customers WHERE country = \"Spain\"", "rds-airflow-hybrid","eu-west-2" ]}
The value of “rds-airflow-hybrid” points to an AWS Secrets record that stores the database host, database, username and password. At the beginning of this walkthrough we created another record that points to our local MySQL database, which is “localmysql-airflow-hybrid” so we can create a new task that looks like the following:
with DAG('hybrid_airflow_dag', catchup=False, default_args=default_args, schedule_interval=None) as dag:
localquery = ECSOperator(
task_id="localquery",
dag=dag,
cluster="hybrid-airflow-cluster",
task_definition="apache-airflow",
overrides={ "containerOverrides": [
{
"name": "Hybrid-ELT-TaskDef",
"command" : [ "ricsue-airflow-hybrid","period1/region-data.csv", "select * from customers WHERE country = \"Spain\"", "localmysql-airflow-hybrid","eu-west-2" ]}
] },
launch_type="EC2",
awslogs_group="/ecs/hybrid-airflow",
awslogs_stream_prefix="ecs/Hybrid-ELT-TaskDef",
reattach = True
)
localquery
As before, after creating this new DAG and uploading it (the code is in the repo) we can trigger this in exactly the same way. Once triggered, like before we need to wait 2-3 minutes. Once finished, we can check the Logs within the Apache Airflow UI, or via the CloudWatch log stream.
Connecting to localmysql.beachgeek.co.uk database localdemo as user root
Database host IP is : 127.0.0.1
Source IP is ip-10-0-0-207.eu-west-2.compute.internal
Query is select * from customers WHERE country = "Spain"
Records exported:
164 , 2021-04-02 , Dag , Delacourt , ddelacourt4j@nydailynews.com , Male , 200.12.59.159 , Spain
We can see that the source IP is our local machine where we have the ECS Anywhere agent running, AND we are now connecting to our local MySQL instance.
Note! The reason why we have a different set of results this time is that we are using a different set of sample data. In all the previous queries, we were running them against the Amazon RDS MySQL instance
Congratulations! We have now orchestrated running a local ETL script via ECS Anywhere accessing local resources, and uploaded the results back up to our data lake on Amazon S3.
Doing more with your Workflow
Now that you have the basics, you can extend this and play around with how you can create re-usable workflows. Some of the things you can do include:
- Over-ride the default ETL script parameters we defined in the Task Defintion - for example, we can change the query or any of the other parameters for our ETL script
with DAG('hybrid_airflow_dag', catchup=False, default_args=default_args, schedule_interval=None) as dag:
cloudquery = ECSOperator(
task_id="cloudquery",
dag=dag,
cluster="hybrid-airflow-cluster",
task_definition="apache-airflow",
overrides={ "containerOverrides": [
{
"name": "airflow-hybrid-demo",
"command" : [ "ricsue-airflow-hybrid","period1/region-data.csv", "select * from customers WHERE country = \"Poland\"", "rds-airflow-hybrid","eu-west-2" ]}
] },
launch_type="EC2",
awslogs_group="/ecs/hybrid-airflow",
awslogs_stream_prefix="ecs/Hybrid-ELT-TaskDef",
reattach = True
)
cloudquery
- Create new Task Defintions, using the PythonOperator and boto3 to create a new Task Definition and then run it via the ECSOperator. This is an example of how you would do that.
from airflow import DAG
from datetime import datetime, timedelta
from airflow.providers.amazon.aws.operators.ecs import ECSOperator
from airflow.operators.python import PythonOperator
import boto3
default_args = {
'owner': 'ubuntu',
'start_date': datetime(2019, 8, 14),
'retry_delay': timedelta(seconds=60*60)
}
def create_task():
client = boto3.client("ecs", region_name="eu-west-2")
response = client.register_task_definition(
containerDefinitions=[
{
"name": "Hybrid-ELT-TaskDef",
"image": "704533066374.dkr.ecr.eu-west-2.amazonaws.com/hybrid-airflow:airflw",
"cpu": 0,
"portMappings": [],
"essential": True,
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"command": ["ricsue-airflow-hybrid","period1/hq-data.csv", "select * from customers WHERE country = \"England\"", "rds-airflow-hybrid","eu-west-2"],
"logConfiguration": {"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/hybrid-airflow",
"awslogs-region": "eu-west-2",
"awslogs-stream-prefix":"ecs/Hybrid-ELT-TaskDef" }
}
}
],
taskRoleArn="arn:aws:iam::704533066374:role/hybrid-airflow-ECSTaskDefRole",
executionRoleArn="arn:aws:iam::704533066374:role/ecs-anywhere-taskdef-hybridairflowApacheAirflowTas-1QL1K5RWWCUTD",
family= "apache-airflow",
networkMode="host",
requiresCompatibilities= [
"EXTERNAL"
],
cpu= "256",
memory= "512")
print(response)
with DAG('hybrid_airflow_dag_taskdef', catchup=False, default_args=default_args, schedule_interval=None) as dag:
create_taskdef = PythonOperator(
task_id='create_taskdef',
provide_context=True,
python_callable=create_task,
dag=dag
)
cloudquery = ECSOperator(
task_id="cloudquery",
dag=dag,
cluster="hybrid-airflow-cluster",
task_definition="apache-airflow",
overrides={ },
launch_type="EC2",
awslogs_group="/ecs/hybrid-airflow",
awslogs_stream_prefix="ecs/Hybrid-ELT-TaskDef",
reattach = True
)
create_taskdef >> cloudquery
Conclusion
What did we learn?
In this walk through we saw how we can take some of the steps you might typically use when creating a data pipeline, containerise those, and then create workflows in Apache Airflow that allow you to orchestrate hybrid data pipelines to run where ever we need them - in the Cloud or in a remote data centre or network.
How can you improve this?
There are lots of ways you could use an approach like this, and I would love to hear from you.
I would love to get your feedback on this post. What did you like, what do you think needs improving? If you could complete this very very short survey, I will use this information to improve future posts.
Many thanks!
Before you go, make sure you think about removing/cleaning up the AWS resources (and local ones) you might have setup.
Cleaning up
If you have followed this walk through, then before leaving make sure you remove/delete any resources you created to ensure you do not keep any recurring costs. Review and clean up the following resources you may have provisioned as you followed along
- Delete the DAGs that run the hybrid workflow
- Delete the Amazon ECS cluster and tasks
- Delete the Amazon ECR container repository and images
- Delete the files you have copied to the Amazon S3 bucket
- Delete the sample customer databases (and if you created them, MySQL instances)
- Uninstall the ECS Anywhere agent and purge any local container images
- Delete any CloudWatch log groups that were created
Troubleshooting
As with all of my blogging adventures, I often come across things that I did not expect, and plenty of mistakes I make which will hopefully save you the time. So here is a few of the gotcha’s I found during the setting up of this.
- Troubleshooting ECS Anywhere - as mentioned else where, you can run into some issues which I have comprehensively outlined in another blog post,
- Permissions - as I was putting this walk through together, I encountered many IAM related permissions issues. This is because I do not want to start off with broad access and resource privileges, which means trial and error to identify the needed permissions. Here are some of the errors that I encountered that were permissions related. These have all been incorporated in the CDK stack above, and is included for reference.
Apache Airflow Worker Tasks
- When using the ECSOperator, I ran into permissions when trying to execute the ECS Operator task. This is the error I encountered.
botocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the RunTask operation: User: arn:aws:sts::704533066374:assumed-role/AmazonMWAA-hybrid-demo-kwZCZS/AmazonMWAA-airflow is not authorized to perform: ecs:RunTask on resource: arn:aws:ecs:eu-west-2:704533066374:task-definition/airflow-hybrid-ecs-task because no identity-based policy allows the ecs:RunTask action
[2022-02-01, 13:02:29 UTC] {{taskinstance.py:1280}} INFO - Marking task as FAILED. dag_id=airflow_dag_test, task_id=airflow-hybrid-ecs-task-query, execution_date=20220201T130226, start_date=20220201T130227, end_date=20220201T130229
[2022-02-01, 13:02:29 UTC] {{standard_task_runner.py:91}} ERROR - Failed to execute job 3 for task airflow-hybrid-ecs-task-query
I needed to amend my MWAA Execution policy, to enable these permissions. This is the policy that I added
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecs:RunTask",
"ecs:DescribeTasks"
],
"Resource": "*"
},
{
"Action": "iam:PassRole",
"Effect": "Allow",
"Resource": [
"*"
],
"Condition": {
"StringLike": {
"iam:PassedToService": "ecs-tasks.amazonaws.com"
}
}
}
]
}
And I needed to update the Trust relationship of the MWAA Execution role as follows
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": "ecs-tasks.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- When using boto3 to create a new Task Definition we encountered another error:
botocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the RegisterTaskDefinition operation: User: arn:aws:sts::704533066374:assumed-role/AmazonMWAA-hybrid-demo-kwZCZS/AmazonMWAA-airflow is not authorized to perform: ecs:RegisterTaskDefinition on resource: * because no identity-based policy allows the ecs:RegisterTaskDefinition action
[2022-02-03, 15:43:01 UTC] {{taskinstance.py:1280}} INFO - Marking task as FAILED. dag_id=airflow_ecsanywhere_boto3, task_id=create_taskdef, execution_date=20220203T154259, start_date=20220203T154301, end_date=20220203T154301
[2022-02-03, 15:43:01 UTC] {{standard_task_runner.py:91}} ERROR - Failed to execute job 36 for task create_taskdef
We just needed to add a further ECS action, “ecs:RegisterTaskDefinition”
- One of the features of the ECSOperator is the “attach=True” switch. Enabling this generated permissions error.
botocore.errorfactory.AccessDeniedException: An error occurred (AccessDeniedException) when calling the DescribeTaskDefinition operation: User: arn:aws:sts::704533066374:assumed-role/AmazonMWAA-hybrid-demo-kwZCZS/AmazonMWAA-airflow is not authorized to perform: ecs:DescribeTaskDefinition on resource: * because no identity-based policy allows the ecs:DescribeTaskDefinition action
[2022-03-03, 11:41:16 UTC] {{taskinstance.py:1280}} INFO - Marking task as FAILED. dag_id=hybrid_airflow_dag_test, task_id=cloudquery, execution_date=20220303T114110, start_date=20220303T114114, end_date=20220303T114116
Adding the following additional permissions resolve this
"ecs:DescribeTaskDefinition",
"ecs:ListTasks"
- Updating the Trust relationships on the ECS Cluster Task Execution role, to resolve a number of not allowed to pass Role error messages. Edit the Trust Relationship of the ECS Execution Role so that the MWAA Workers are allowed to execute these tasks on our behalf.
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": [
"ecs-tasks.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
and change to add the Apache Airflow service (which will allow the workers/schedulers to kick this off)
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "",
"Effect": "Allow",
"Principal": {
"Service": [
"airflow-env.amazonaws.com",
"airflow.amazonaws.com",
"ecs-tasks.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
- The workflow ran into permissions issues when copying the files to the Amazon S3 bucket. I needed to amend my MWAA Execution policy, so I created a new policy that allows you to copy files to the S3 bucket and attached it. This is what it looked like (the Resource will be different depending on where you want to copy your files to)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:ListBucket",
"s3:DeleteObject"
],
"Resource": [
"arn:aws:s3:::ricsue-airflow-hybrid*"
]
}
]
}
- The workflows were not generating any CloudWatch logs, and this was because I had not added the correct permissions. To fix this, I amended the policy to include (and match) the AWS CloudWatch logging group that was created during the ECS Cluster creation.
and also make it so that we can do the necessary logging
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:CreateLogGroup",
"logs:PutLogEvents",
"logs:GetLogEvents",
"logs:GetLogRecord",
"logs:GetLogGroupFields",
"logs:GetQueryResults"
],
"Resource": [
"arn:aws:logs:*:*:log-group:/ecs/hyrid-airflow:log-stream:/ecs/*"
]
}
Setting up the MySQL test data
How I set up my MySql database machine locally - Ubuntu
This is the procedure I used. I assume you have some basic knowledge of MySQL. This is ok for a test/demo setup, but absolutely not ok for anything else. As root user you will need to run the following commands:
sudo apt update
sudo apt install mysql-server
sudo mysql_secure_installation
Follow the prompts to enable local access. I did have to run “sudo mysql -uroot -p” to login in order to be able to setup permissions. Create mysql users and update permissions so it can connect/query databases (I create a user called admin which has access to all databases from any hosts)
On the machine you have just install MySQL, update bind to 0.0.0.0 on /etc/mysql/mysql.conf.d/mysqld.cnf and then “sudo systemctl restart mysql” Update your local /etc/hosts to add the host name for the local database that will be used by the ETL script to connect to. You use this value when defining the connection details in AWS Secrets. We use /etc/hosts as this is a simple demo setup. I used “127.0.1.1 localmysql.beachgeek.co.uk” in my setup. Test connectivity to that and make sure it resolves to 127.0.0.1. Now login to MySQL and create your demo database and then create a table using the following
create database localdemo;
use localdemo;
create table customers ( id INT, date DATE, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), gender VARCHAR(50), ip_address VARCHAR(20), country VARCHAR(50), consent VARCHAR(50) );
Copy the sample customer data in the repo, and you can now import the data using the following command>
mysql -u {user} -p localdemo < customer-reg-2.sql
How I set up my MySql database machine locally - Amazon Linux 2
A similar process was used to install MySQL on Amazon Linux 2. Run the following commands to install and configure MySQL.
sudo yum install https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm
sudo amazon-linux-extras install epel -y
sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
sudo yum install mysql-community-server
sudo systemctl enable --now mysqld
You will now need to change the root password. To find the current temporary password, run “sudo grep ‘temporary password’ /var/log/mysqld.log” which will show you the password. Something like this:
you will see: 022-01-26T17:27:51.108997Z 6 [Note] [MY-010454] [Server] A temporary password is generated for root@localhost: F+lFfe*QG8qX
And then set new root password with
sudo mysql_secure_installation -p'F+lFfe*QG8qX'
Update your local /etc/hosts to add the host name for the local database that will be used by the ETL script to connect to. You use this value when defining the connection details in AWS Secrets. We use /etc/hosts as this is a simple demo setup. I used “127.0.1.1 localmysql.beachgeek.co.uk” in my setup. Test connectivity to that and make sure it resolves to 127.0.0.1. Now login to MySQL and create your demo database and then create a table using the following
create database localdemo;
use localdemo;
create table customers ( id INT, date DATE, first_name VARCHAR(50), last_name VARCHAR(50), email VARCHAR(50), gender VARCHAR(50), ip_address VARCHAR(20), country VARCHAR(50), consent VARCHAR(50) );
Copy the sample customer data in the repo, and you can now import the data using the following command>
mysql -u {user} -p localdemo < customer-reg-2.sql