AWS open source news and updates #108
April 11th, 2022 - Instalment #108
Newsletter #108.
A little later the usual as it was a busy week last week, and I was lucky enough to speak at some great events. It certainly seems that things are returning to normality now on the tech events scene, and it was great to meet so many customers and builders who were enthusiastic champions of open source. The AWS Summit season is upon us, with the Brussels summit just gone and Paris Summit happening this week. I will be speaking in London and Berlin, but will also be at the Madrid Summit, so if you are planning to go, it would be great to meet up.
This week we have the usual round up of new and latest open source projects, tools and demos from the AWS Community. Make sure you check out “eventbridge-transformer” if you are doing anything in the event driven architecture space, “aws-resource-based-policy-collector” is a tool that will help you report on your AWS environment, “harpo” provides an abstraction layer for accessing secrets, “aws-virtual-kubelet” is a tool that allows you to provision and maintain EC2 instances through regular Kubernetes operations, “vivid-state-machine”, that provides you with the ability to create and illustrate state machines in C/C++, “amplify-graphql-seed-plugin”, an AWS Amplify plugin to help you to seed the databases of your Amplify projects with data using an AppSync GraphQL API, and many more.
We also have content covering Apache Iceberg, Lustre, PostgreSQL, SaaS Boost, MLflow, PartiQL, Kubernetes, Apache Hudi, MariaDB, MySQL, Serverless Framework, GraphQL, and XGBoost. This week also features a collection of great follow along posts covering AWS Amplify, so if you are a web developer, make sure you check those out. We also have a video featuring last weeks featured AWS GameKit, and then the usual round up of events to put on your diary.
Do you have an interesting open source project you want to share?
As always, if you are working on anything interesting you would like me to include in this weekly round up, please drop me a line at ricsue@amazon.com.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Chris Short, Rumi Olsen, Naseer Ahmed, Igor Alekseev, Kunal Gautam, Gabriele Cacciola, Udit Mehrotra, Nethravathi Muddarajaiah, Abhinav Sarin, Maheswaran S, Veerendra Nayak, Sam Selvan, Virginia Chu and Joseph Keating, Jimmy Ray, Javier Marasco, David Boyne, and Will Dady
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
Community
eventbridge-transformer
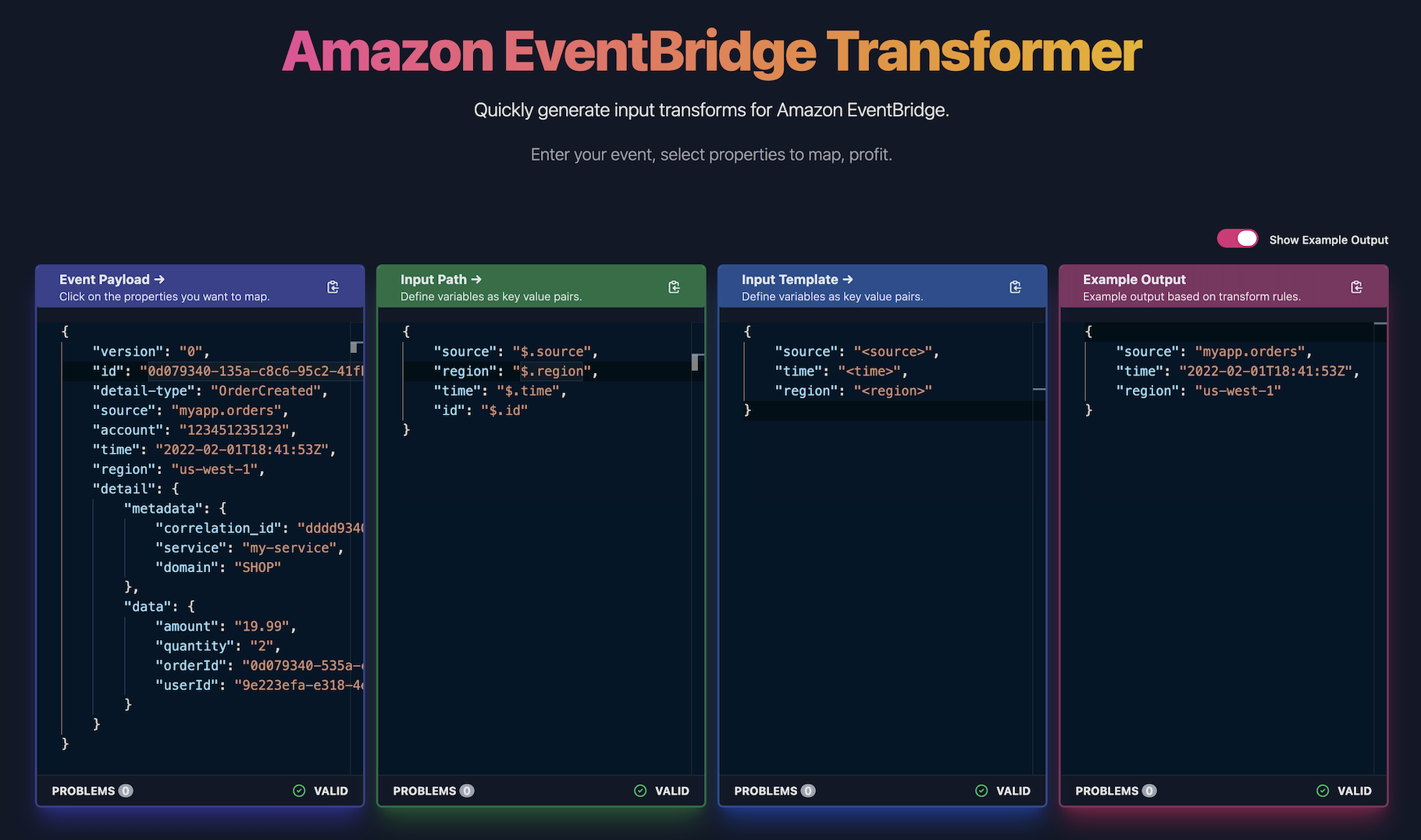
eventbridge-transformer its always interesting to see the latest open source project that AWS Community Builder David Boyne has been cooking up, and he had been sharing updates via social media for a few days before dropping info on this project, eventbridge-transformer. This is an online tool to quickly build input templates and paths for Amazon EventBridge. As always, bar raising documentation and examples provided, and you can check out an online version of the tool which David is running at https://eventbridge-transformer.vercel.app/
http-cron
http-cron this project allows you to POST to HTTP endpoints at regular intervals (to trigger jobs, etc.). Can be run as a standalone daemon, reading from a cron.yaml file, or as a component in a Clojure system. It provides a drop-in replacement for the process which runs on AWS Elastic Beanstalk worker instances in the presence of a cron.yaml, providing an alternative which can be run in a local environment.
aws-resource-based-policy-collector
aws-resource-based-policy-collector this library from Will Dady aims to collect resource-based policies from an AWS account. This does not currently support all AWS Services, but the documentation includes those that are. If you find this useful, and you need other services included why not contact Will and let him know.
harpo
harpo this open source tool written in Go from Javier Marasco provides an abstraction layer that is based on a folder/path model, and allows you to reference secrets that you store in services like AWS Secrets Manager.
Tools
aws-virtual-kubelet
aws-virtual-kubelet AWS Virtual Kubelet aims to provide an extension to your Kubernetes cluster that can provision and maintain EC2 instances through regular Kubernetes operations. This enables usage of non-standard operating systems for container ecosystems, such as MacOS.
amazon-macie-finding-data-reveal
amazon-macie-finding-data-reveal this is a command line utility to help you investigate the sensitive data associated with Macie findings. Macie generates sensitive data findings when it discovers sensitive data in S3 objects that you configure a sensitive data discovery job to analyse. This CLI automates the manual steps involved with retrieving the object where the sensitive data was discovered and viewing the discovered sensitive data based on its location.
migrate-blob-data-from-rdbms-to-amazon-s3
migrate-blob-data-from-rdbms-to-amazon-s3 this is a very detailed solution that lets you move binary data that you might be storing in your relational databases and move it to object storage, via Amazon S3. Make sure you read through the README to understand how this works and the tradeoffs, and there is additional information for what to think about if you want to run something like this in production.
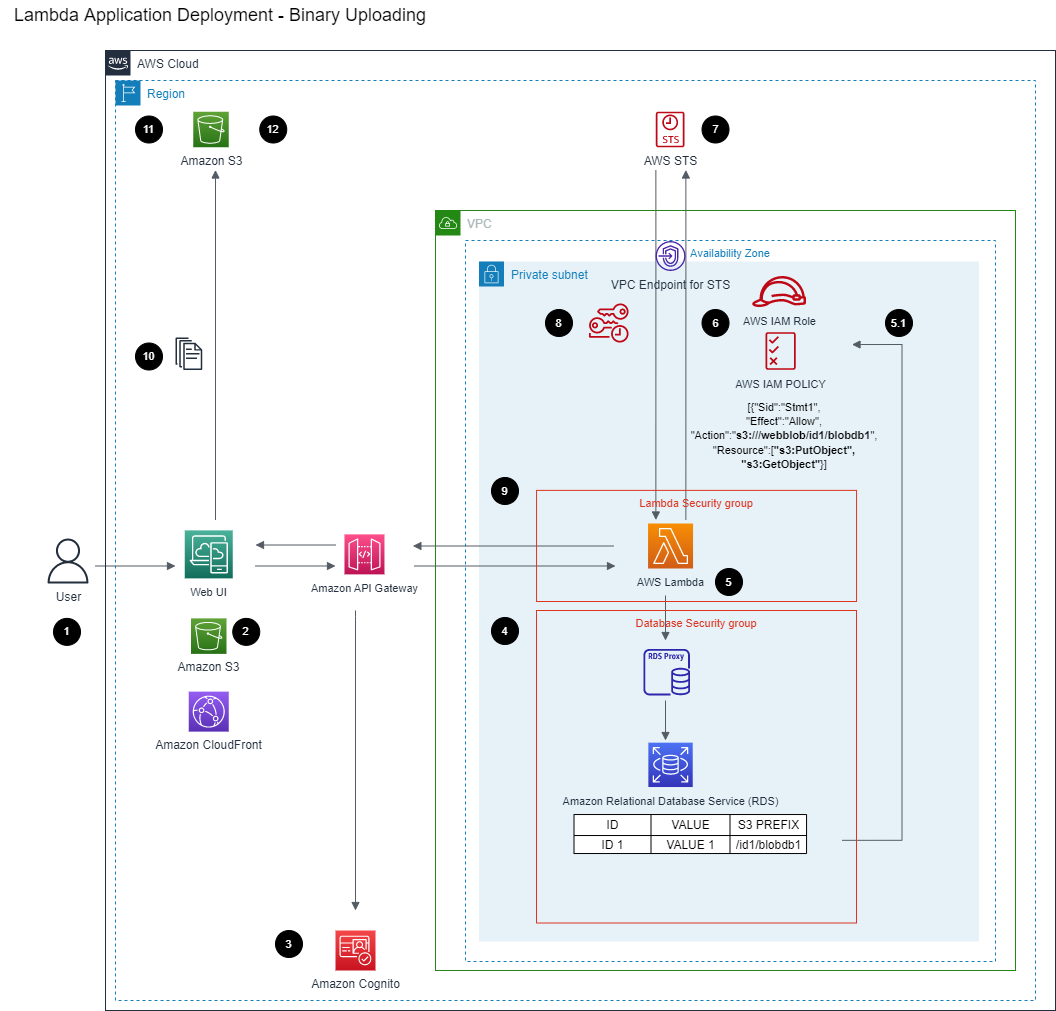
amazon-rds-for-sql-server-custom-log-shipping
amazon-rds-for-sql-server-custom-log-shipping this repo contains a custom log shipping solution is built using Microsoft’s native log shipping principles, where the transaction log backups are copied from the primary SQL Server instance to the secondary SQL Server instance and applied to each of the secondary databases individually on a scheduled basis. A tracking table records the history of backup and restore operations, and is used as the monitor. The following diagram illustrates this architecture.

vivid-state-machine
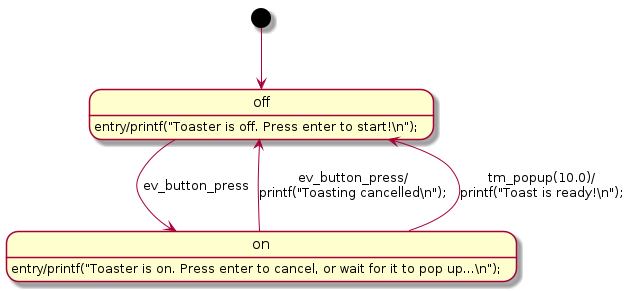
vivid-state-machine provides a cross-platform library for implementing state machines in C/C++ and vividly documenting them in UML. The UML diagram reflects the source code, there’s no need to maintain it manually. This project will help you to develop and test applications on a PC or in the cloud, then deploy to embedded hardware. The extensible binding layer supports bare-metal uCs, RTOSs including FreeRTOS, as well as Linux and Windows.
aws-java-nio-spi-for-s3
aws-java-nio-spi-for-s3 is a Java NIO.2 service provider for S3, allowing Java NIO operations to be performed on paths using the s3 scheme. This package implements the service provider interface (SPI) defined for Java NIO.2 in JDK 1.7 providing “plug-in” non-blocking access to S3 objects for Java applications using Java NIO.2 for file access.
amplify-graphql-seed-plugin
amplify-graphql-seed-plugin this is an Amplify Plugin which helps your to seed the databases of your Amplify projects with data using an AppSync GraphQL API. It can be used to seed local mock databases, as well as remote databases, e.g. for testing purposes. This plugin allows you to customise and auto-generate mock data, including data with relationships between models, beyond the capabilities of the ‘Auto-generate data’ functionality in Amplify Studio.
aws-fpga-f1-u200
aws-fpga-f1-u200 this tool will be handy for those looking to move between using local FPGA cards (such as the u200) and AWS F1 instances. This tool enables customers to migrate designs seamlessly between on-premise U200 Alveo cards and the AWS F1 platform in a full custom RTL development flow. This gives choice to the customers to use either a Vitis flow or a full custom RTL/Vivado design flow and seamlessly migrate designs between Alveo U200 and F1. Check out the project for more details, including how to use this tool.
Demos and Samples
textract-boleto-reader
textract-boleto-reader this project aims to show the art of the possible in relation to the use of Amazon Textract to read and extract all fields and values from Brazilian bank slips (Boleto), as well as the barcode number.
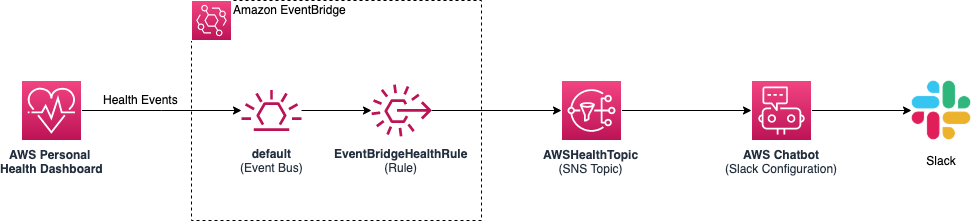
monitor-aws-health-using-slack
monitor-aws-health-using-slack ChatOps is the process of using familiar messaging platforms, such as Slack and Amazon Chime, to manage software deployment and operation tasks. Using ChatOps, teams can manage their environments right from their chat clients and easily share their findings with their peers. This repository demonstrates how AWS Chatbot can be configured to send Slack notifications for events that impact the health of AWS resources within your account.
AWS and Community blog posts
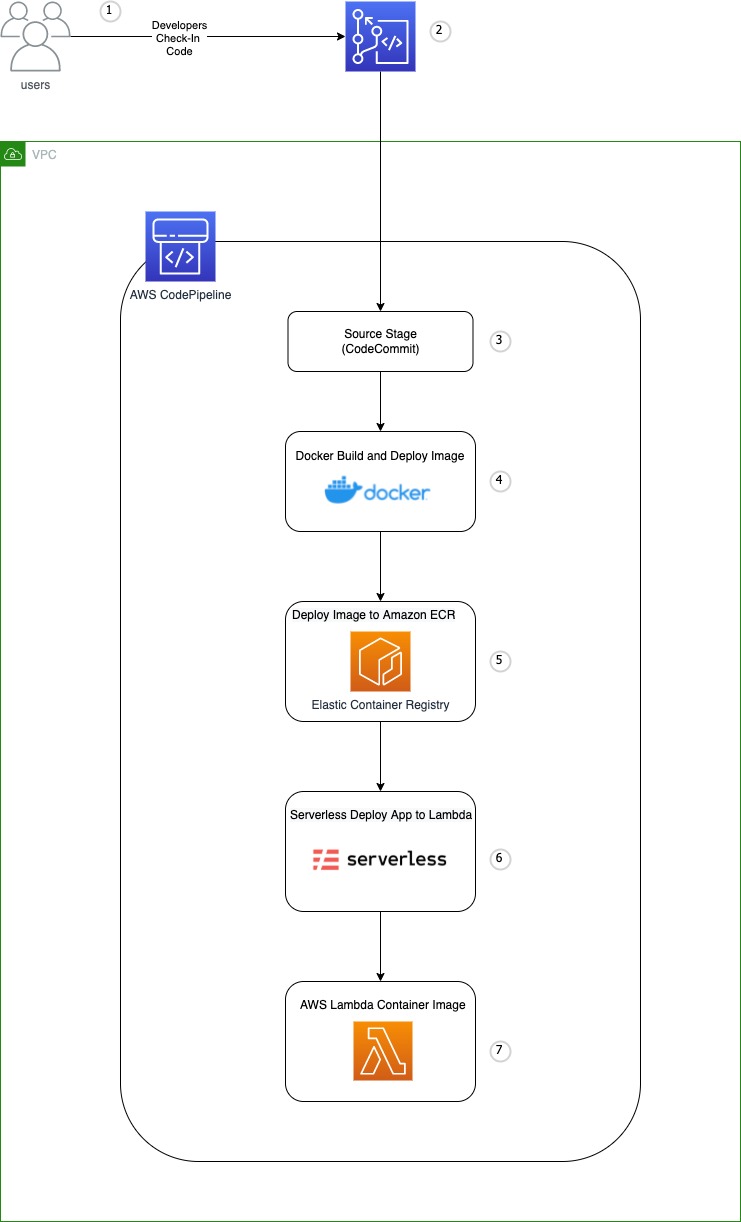
Serverless Framework
The Serverless Framework is an open source command-line tool that uses easy and approachable YAML syntax to deploy both your code and cloud infrastructure needed for your application. Whilst similar to AWS SAM, Serverless Framework is extensible via plugins, which have been created by the community (and at least from the GitHub page, are numerous!). Virginia Chu and Joseph Keating have put together this post, Simplify development using AWS Lambda container image with a Serverless Framework demonstrate how to use The Serverless Framework and other open source tools and AWS continuous integration and deployment (CI/CD) services to deploy Lambda-based container images to AWS. [hands on]
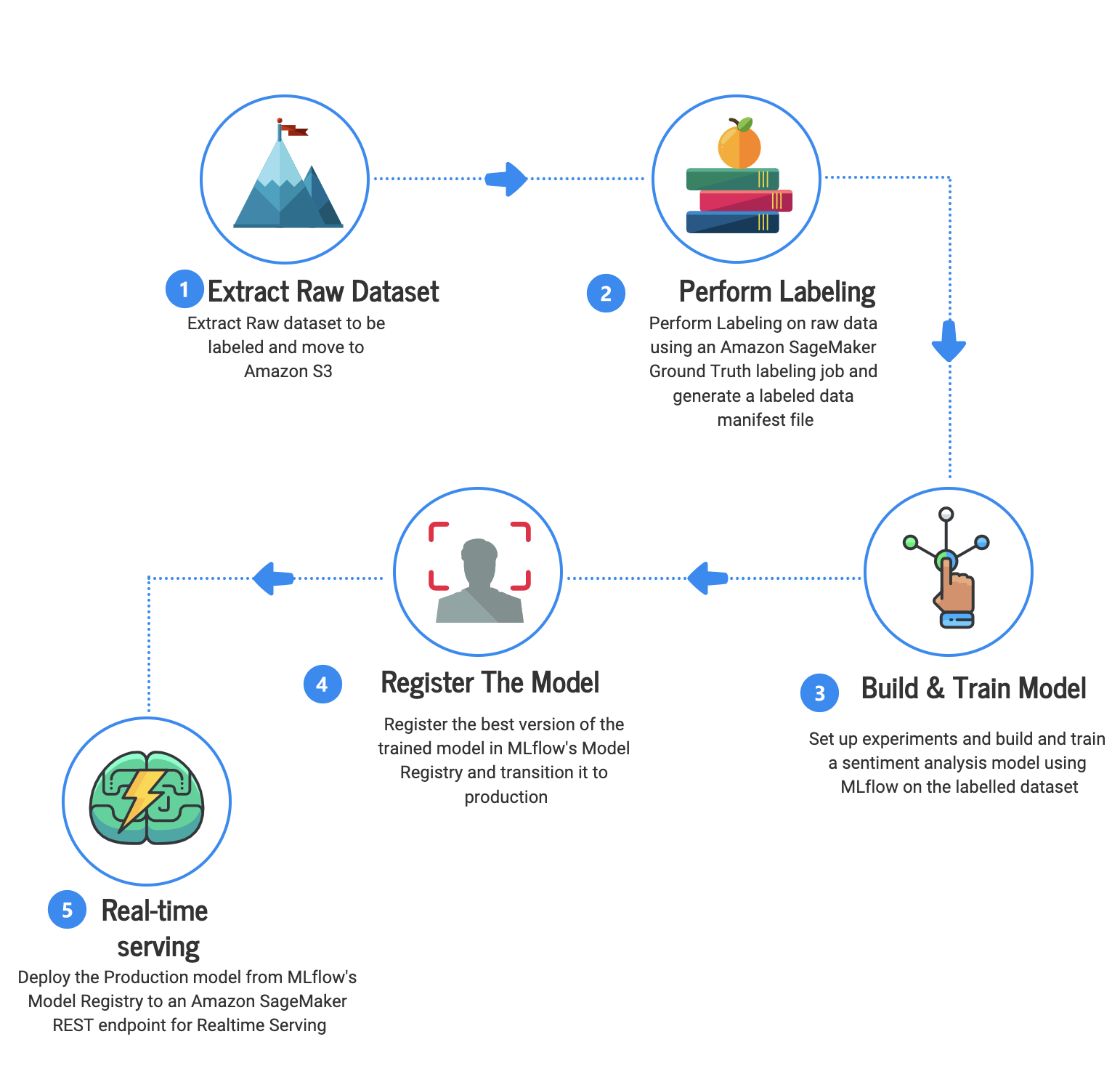
MLflow
In the post Build an MLOps sentiment analysis pipeline using Amazon SageMaker Ground Truth and Databricks MLflow, Rumi Olsen, Naseer Ahmed, and Igor Alekseev show you how to use Ground Truth to label a raw dataset, and the use the labeled data to train a simple linear classifier using Scikit-learn. One trained, they show you how to use MLflow to track hyperparameters and metrics, register a production-grade model, and deploy the trained model to SageMaker as an endpoint. [hands on]
Kubernetes
Chris Short shared news last week that Amazon Elastic Kubernetes Service (Amazon EKS) will now support for Kubernetes 1.22, in his post Amazon EKS now supports Kubernetes 1.22. Read the post to find out some of the ways the team has been contributing to the various open source projects, as well as a look at the release highlights.
EKS Newsletter Have you checked out and subscribed to the weekly EKS News newsletter? If not, I suggest you sign up to keep up to date on the regular updates and news around this technology.
Last week also saw Jimmy Ray write Amazon EKS, AWS CDK, and Go, who shares his experiences and learnings as a long-time Java coder that also uses Go, to build with the AWS CDK in Go. [hands on]
PostgreSQL
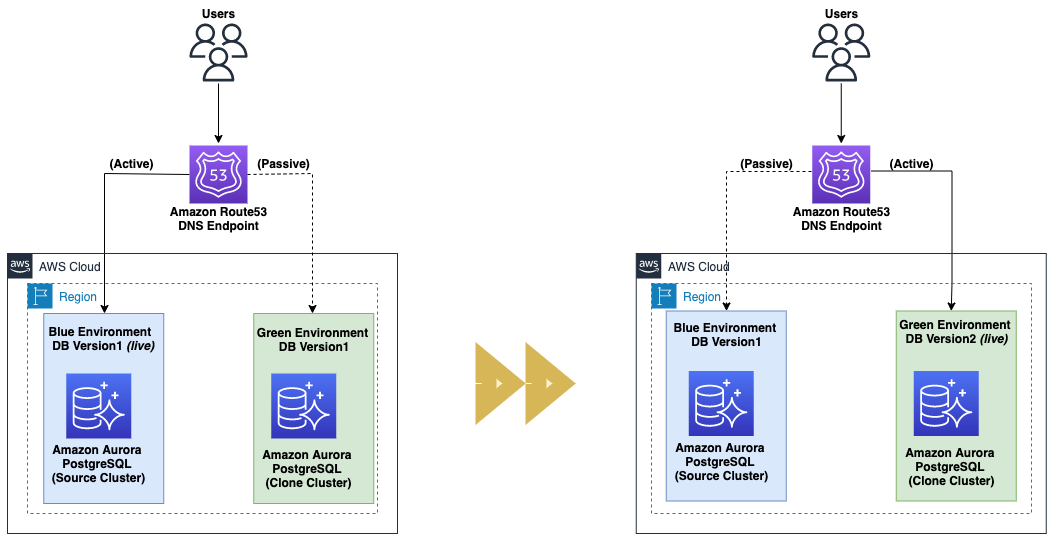
A blue/green deployment is a deployment strategy in which you create two separate, but identical environments. One environment (blue) is running the current application version and one environment (green) is running the new application version. Using a blue/green deployment strategy increases application availability and reduces deployment risk by simplifying the rollback process if a deployment fails. Once testing has been completed on the green environment, live application traffic is directed to the green environment and the blue environment is deprecated. Nethravathi Muddarajaiah, Abhinav Sarin, and Maheswaran S have put together this post, Amazon Aurora PostgreSQL blue/green deployment using fast database cloning to show you how to take advantage of Amazon Aurora PostgreSQL-Compatible Edition for a blue/green deployment strategy by using Aurora fast database cloning for database changes and major version and minor version upgrades. [hands on]
MariaDB / MySQL
Veerendra Nayak and Sam Selvan present three different methods for migrating from self-managed MariaDB to Amazon Aurora MySQL, in the post Migrate self-managed MariaDB to Amazon Aurora MySQL. Each with different downtimes associated with them and you can also apply these methods to move from self-managed MySQL and Percona MySQL databases to Aurora MySQL. [hands on]
Other posts worth checking out
- Introducing Protocol buffers (protobuf) schema support in AWS Glue Schema Registry takes a look at protocol buffers schema support in AWS Glue Schema Registry and how to use Protocol buffers schemas in stream processing Java applications that integrate with Apache Kafka
- Customize the Amazon SageMaker XGBoost algorithm container explores the inner workings of the SageMaker XGBoost algorithm container and provide pragmatic scripts to directly customise the container
- Add Interactive Maps in React using Amplify Geo, powered by Amazon Location Service shows you how to add location based functionality into your Amplify applications [hands on]
- Build a photo gallery React app using Amplify Studio’s new file storage capabilities will guide you in how to build a photo gallery filled with images using AWS Amplify Studio’s new storage capabilities [hands on]
- Build a Social Media Timeline with Amplify Studio another AWS Amplify demo, this time showing you how you can build a social media timeline [hands on]
- Create real-time applications via serverless WebSockets with new AWS AppSync GraphQL subscriptions filtering capabilities takes a look at how you can use enhanced filtering in your GraphQL subscriptions to allow for more flexibility when developing real-time applications [hands on]
- High-performance cloud storage comes of age with Amazon FSx for Lustre explores some of the use cases and what you can do with this high performance, open source file system
Case Studies
- Using Structural Variant Analysis on AWS with Amazon FSx for Lustre in Novel Therapeutic Discovery shows how using the high performance file system Lustre can accelerate workloads that sequence data and reduce the time it takes to identify structural variants that may hopefully lead to new medicines for patients suffering with chronic kidney disease
Quick updates
Apache Hudi
Kunal Gautam, Gabriele Cacciola, and Udit Mehrotra have come together to share some of the new and exciting features in Hudi 0.9.0 available on Amazon EMR versions 5.34 and 6.5.0 and later in the post, New features from Apache Hudi 0.9.0 on Amazon EMR. These new features enable the ability for data pipelines to be built solely with SQL statements, thereby making it easier to build transactional data lakes on Amazon S3. [hands on]
Apache Iceberg
Announced last week, Amazon Athena ACID transactions is a new capability that adds insert, update, delete, and time travel operations to Athena’s SQL data manipulation language (DML). Athena ACID transactions enable multiple concurrent users to make reliable, row-level modifications to their Amazon S3 data from Athena’s console, API, and ODBC and JDBC drivers. Built on the Apache Iceberg table format, Athena ACID transactions are optimised for Amazon S3 storage, support seamless schema evolution, and ensure atomic operations across other services and engines that support the Iceberg table format such as Amazon EMR, Apache Spark, and Apache Flink.
Athena ACID transactions can help you make business- and regulatory-driven updates to your data using familiar SQL syntax and without requiring a custom record locking solution. Responding to a data erasure request is as simple as issuing a SQL DELETE operation. Making manual record corrections can be accomplished via a single UPDATE statement. And with time travel capability, you can recover data that was recently deleted using just a SELECT statement.
Lustre
AWS Backup enhances its support for Amazon FSx for Lustre file systems by now allowing protection of data on its Persistent 2 deployment type. AWS Backup’s centralised data protection capabilities across AWS services including the ability to create immutable, logically air-gapped backups across AWS Regions and accounts, prove-able compliance, and single-click restore, are now available for Amazon FSx for Lustre Persistent 2 file systems.
PartiQL
Amazon Athena now supports data stored in Amazon Ion format, a richly-typed, self-describing format developed and open-sourced by Amazon. Amazon Ion provides interchangeable binary and text formats which combine the ease of use of text with the efficiency of binary encoding. The Ion format is currently used by internal Amazon teams, by AWS services such as Amazon Quantum Ledger Database (Amazon QLDB), and in the open source SQL query language PartiQL.
Using Athena’s new Amazon Ion Serializer/Deserializer (SerDe), you can now create and read Ion tables that can be queried and joined with data in other formats such as Parquet, Avro, and CSV. The Ion format is well-suited for sparsely populated hierarchical data such as medical history records and retail order documents which are complex to model and difficult to optimise for structured queries. Using Athena and Ion, the raw data remains easily readable by domain professionals, can be queried and analysed using standard SQL queries, and is compact and space-efficient so it saves on log retention and data transfers.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) Proxy now supports Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL - Compatible edition major version 13. PostgreSQL 13 includes many new features and performance enhancements such as de-duplication of B-tree index entries, improved performance for queries that use partitioned tables, better query planning when using extended statistics, parallelized vacuuming of indexes, and incremental sorting. Amazon RDS Proxy is a fully managed and a highly available database proxy for Amazon RDS and Amazon Aurora databases. Amazon RDS Proxy helps improve application scalability, resiliency, and security.
Saas Boost
AWS SaaS Boost is an open source project that provides organisations with ready-to-use core software elements for successfully running SaaS workloads in the cloud. These past few months the team have been hard at work on the v2.0.0 release of SaaS Boost, and the first stable release candidate is now ready for preview. This release candidate includes a multitude of changes to the internals of SaaS Boost to enable the highly requested Multicontainer support feature!
Check out the release by heading over to the project page, v2.0.0 : Multicontainer Pre-Release
Videos of the week
AWS GameKit
AWS GameKit is an open source game engine solution toolkit that brings AWS cloud services directly to your game engine. GameKit includes a plugin for Unreal Engine, libraries for connecting to your game backend, samples, and documentation. Join Ali, Kyle Lee, and Brian Terry as they dive deep through the announcement I shared in #107 of this newsletter.
Events for your diary
Hugging Face SageMaker Workshop Accelerate BERT Inference with Knowledge Distillation & AWS Inferentia April 13th, 5pm BST
This workshop will demonstrate how to accelerate BERT Inference using different optimization techniques like knowledge distillation to make the model fast and keep the accuracy. In the workshop, you will learn how to apply knowledge distillation to compress a large model to a small model, and then from the small model to an optimized neuron model with AWS Inferentia.
Find out more and register, via the page Accelerate BERT Inference with Knowledge Distillation & AWS Inferentia
GitOpsCon Europe May 17th, Valencia Spain
GitOpsCon Europe is designed to foster collaboration, discussion, and knowledge sharing on GitOps. This event is aimed at audiences that are new to GitOps as well as those currently using GitOps within their organisation. Get connected with others that are passionate about GitOps. Learn from practitioners about pitfalls to avoid, hurdles to jump, and how to adopt GitOps in your cloud native environment.
The event is vendor-neutral and is being organised by the CNCF GitOps Working Group. Topics include getting started with GitOps, scaling and managing GitOps, lessons learned from production deployments, technical sessions, and thought leadership.
Read more about this from the official page here.
CDK Day May 26th - Virtual
This is a community organised event about AWS CDK, cdktf, projen and cdk8s. This will be third year they run this event, and if the previous two are anything to go by, this will be essential viewing - live streamed via You Tube. Check out and register for the event over at their home page at https://www.cdkday.com/
OpenSearch Every Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting - Feb2022
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen