AWS open source news and updates #104
March 14th, 2022 - Instalment #104
Newsletter #104.
Welcome to #104 of the AWS open source news and updates newsletter, bringing you the latest updates from around the AWS and Communities. This week we have yet more great new open source projects, including a Deno runtime for your Lambda functions, data lineage and data testing tools, a performance testing tool for Apache Kafka, an ELT tool for Amazon Redshift, an Amazon S3 archive tool, and many more. We also have a round up of new blog posts for you to read on topics such as Apache Spark, cfn-guard, Delta Lake, Hugging Face, Spinnaker, Grafana, Apache Hudi, PostgreSQL, Amazon Corretto, OpenQASM, Envoy, Bottlerocket, the Amazon Genomics CLI, Apache Airflow, Mantil, rtdl, OpenSearch, Metabase, and many more. Make sure you check out this weeks videos featuring Vault, Packer, Terraform, ROS and Kubernetes, and as always, we have events and meet-ups coming up this week which you should check out. Speaking of meet-ups, the call for papers for the third CDK Day was announced last week, so lets start there…
CDK Day - Call for Papers
Make sure you keep the 26th May free, as this will be the third CDK Day. This is a community organised event about AWS CDK, cdktf, projen and cdk8s. The CFP is now open, so please check this out.
They are looking for speakers from diverse backgrounds representing the whole spectrum of experience, so if your session is “my first experience using cdk” please submit it just as much as “my experience as a top 10 core AWS CDK contributor” - everyone is welcome.
We are focusing on shorter sessions this year which is why the options are 20 minutes or a panel discussion. The panel discussion option would be if you and some people you know have a discussion you think attendees would be interested in hearing.
Find out more by checking out the call for papers page.
Do you have an interesting open source project you want to share?
As always, if you are working on anything interesting you would like me to include in this weekly round up, please drop me a line at ricsue@amazon.com.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Aidan Steele, Trivikram Kamat, Percy Musaka, Daniel Jelušić, Gavin Johnson, Vacha Shah, Adam Spicer, Paul Hargis, Vedant Jain, James Yi, Simon Zamarin, Ben Freiberg, Marcus Ziller, Praseeda Sathaye, Divya Sharma, Shawn McCoy, Xin Liu, Mike Cook, Jacqui De Sa, Justin Garrison, Oscar Medina, Sarah MacDonald, J. Cole Morrison, Mihai Criveti, Elif Samedin, Shimon Tolts, and Noaa Barki.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
Community
begin-deno-runtime
begin-deno-runtime if you are looking for a Deno runtime as a Lambda Layer, then this is the project for you.
aws-sdk-js-codemod
aws-sdk-js-codemod this repository from Trivikram Kamat contains a collection of codemod scripts for use with JSCodeshift that help update AWS SDK for JavaScript APIs.
postinvoke
postinvoke another project from Aidan Steele, that lets you run in-process code after your Go-powered Lambda function has returned. With some recent new features of AWS Lambda which allow you to have background processes that can continue running (e.g. for cleanup) after a Lambda function has returned its response, what if you want to do cleanup in the function process itself? This library will help you to achieve that. Nice!
Tools
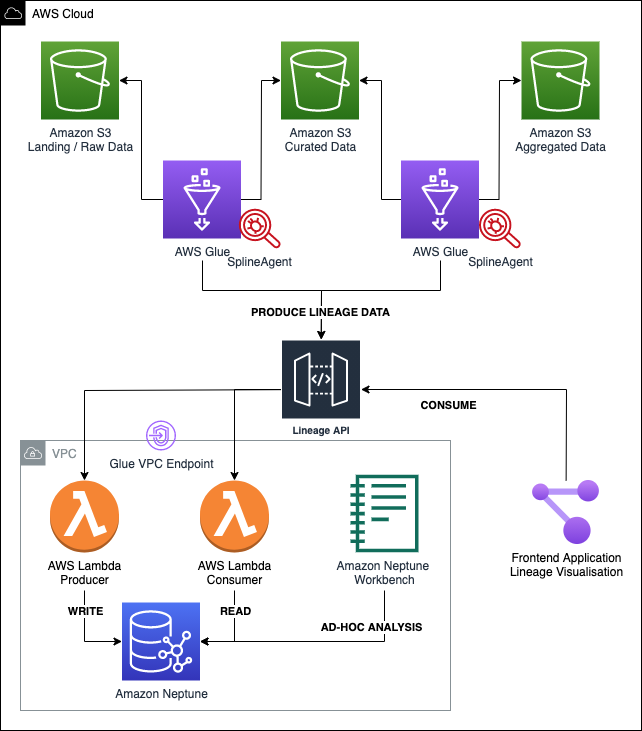
data-lineage-for-data-lake-example
data-lineage-for-data-lake-example Spline is a free and open-source tool for automated tracking data lineage and data pipeline structure in your organisation. This repository contains an example project for building Data Lineage for data lakes using AWS Glue, Amazon Neptune and Spline Agent.
distributed-load-testing-with-locust-on-ecs
distributed-load-testing-with-locust-on-ecs
This sample shows you how to deploy Locust, a modern load testing framework, to Amazon Elastic Container Service (ECS). It leverages a serverless compute engine Fargate with spot capacity, which allows you to run massive-scale load test without managing infrastructure and with relatively low cost (70% cheaper than using on-demand capacity).
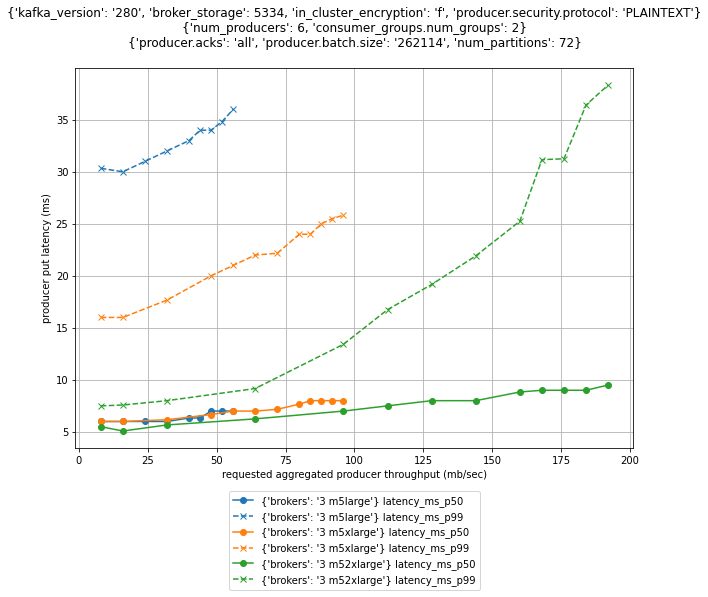
performance-testing-framework-for-apache-kafka
performance-testing-framework-for-apache-kafka this tool is designed to evaluate the maximum throughput of a cluster and compare the put latency of different broker, producer, and consumer configurations. To run a test, you basically specify the different parameters that should be tested and the tool will iterate through all different combinations of the parameters, producing a graph similar to the one below. Please note the warning - This code is NOT intended for production cluster. It will delete topics on your clusters. Only use it on dedicated test clusters.
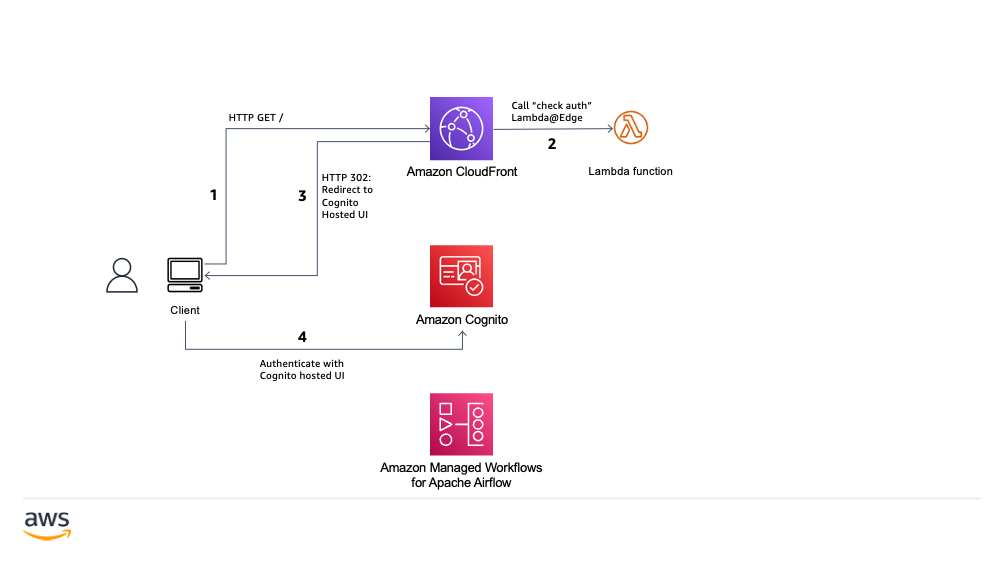
mwaa-public-webserver-custom-domain
mwaa-public-webserver-custom-domain a popular request, how to enable custom domain names when accessing the Apache Airflow UI in Managed Workflows for Apache Airflow. The sample code to demonstrate using Amazon CloudFront, AWS Lambda@Edge, and Amazon Cognito to enable custom domain for a public MWAA deployment.
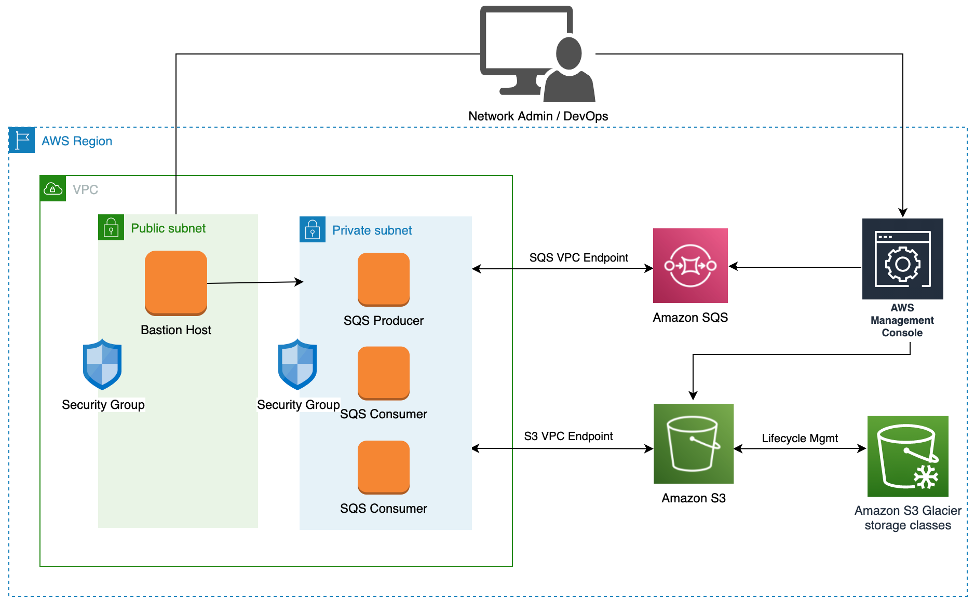
redshift-etl-framework
redshift-etl-framework is a lightweight and config driven ETL (extract, transform, load) framework to perform ETL, ELT and ELTL operations on data lakes using Amazon Redshift
amazon-s3-archive-builder
amazon-s3-archive-builder - this project provides a solution to build compressed archive objects (tar.gz) suitable for Amazon S3 Glacier. S3 customers who have not designed for data archiving in their cloud storage architectures and who are looking to reduce operational costs associated with non-archival storage classes may find it costly to archive into Glacier via lifecycle policies or S3 Intelligent Tiering. This is particularly the case if the workloads do not align with cold storage best practices. Best practices include but are not limited to; reducing the number of objects that will ultimately be archived and organising objects into archives by an indexing scheme or lookup strategy thereby reducing or eliminating the overhead associated with restoring archived objects of interest. This project was motivated by a real customer use case that needed to be archived into Amazon S3 Glacier. The objects were logs relatively small in size and produced by a distributed application that was writing them periodically (5 minutes) to S3 Standard.
Demos and Samples
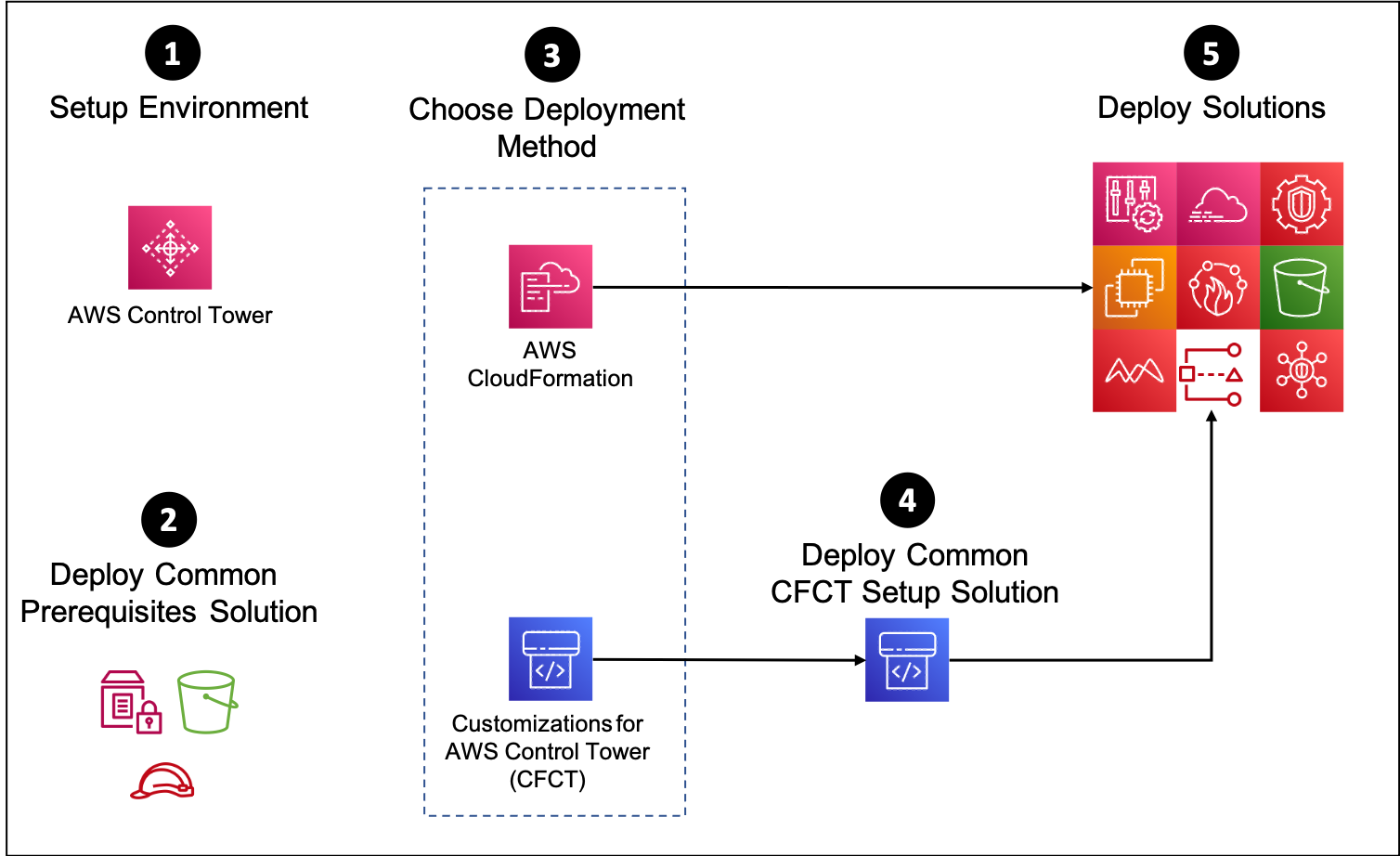
aws-security-reference-architecture-examples
aws-security-reference-architecture-examples - this resource provides example solutions demonstrating how to implement patterns within the AWS Security Reference Architecture guide using CloudFormation and Customizations for AWS Control Tower.
amazon-sagemaker-delta-lake-integration
amazon-sagemaker-delta-lake-integration repository contains Amazon SageMaker Notebook samples and code that can be used to integrate SageMaker with open-source Delta Lake tables. This might be useful if you are trying to build hybrid ML solutions with open-source technologies for example. To help you get started with the repo, make sure you read the post Load and transform data from Delta Lake using Amazon SageMaker Studio and Apache Spark from Paul Hargis and Vedant Jain.
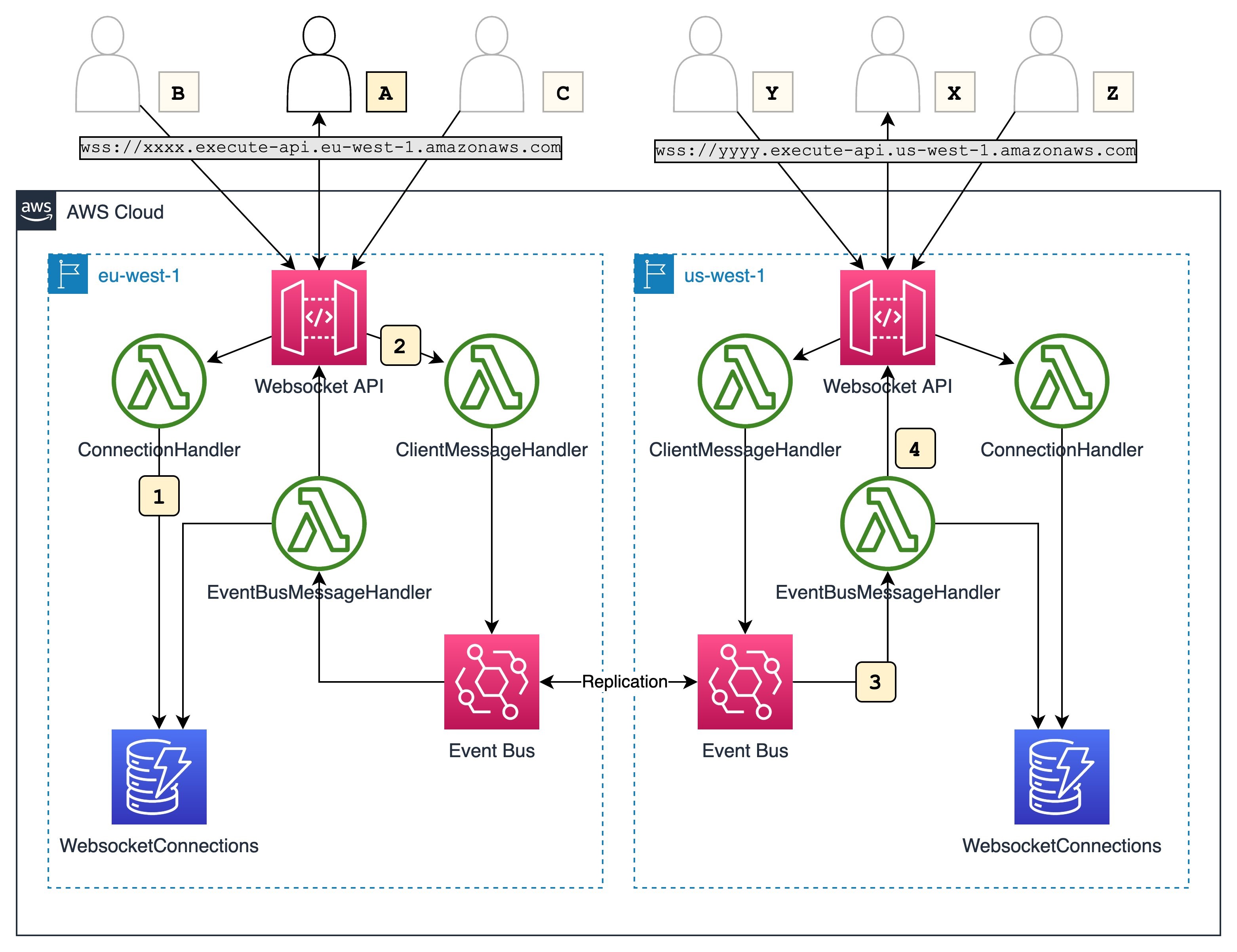
multi-region-websocket-api
multi-region-websocket-api this repository provides code that will help you build a multi-regional WebSocket API for a global real-time chat application. Ben Freiberg and Marcus Ziller have put together a blog post to help you get started with this project, Building serverless multi-Region WebSocket APIs.
AWS and Community blog posts
Mantil
Mantil is an open-source framework for writing serverless apps in Go. Daniel Jelušić has put together a blog post, User sign-up example with Mantil, Go, JWT, AWS Lambda, SES and DynamoDB that shows you how to create a simple sign-up workflow using Mantil, consisting of a registration and activation process. If you want to explore this project in more detail, this is the perfect opportunity.
rtdl
rtdl is an open source project that aims to make it easy to build and maintain a real-time data lake. Gavin Johnson has put digital pen to digital paper and written this blog post, How to Build a Real-Time Data Lake on AWS with rtdl and Segment to show you how you can deployand build a data lake on AWS with data from Segment.
OpenSearch
Backporting is a common process in OpenSearch in order to maintain release branches separate from main and to be ready for a release. In Auto Backport in OpenSearch, Vacha Shah talks about how the team navigated backports manually in OpenSearch and pursued automation to streamline the process and use it across various repos.
Amazon Corretto
Check out the post, Asynchronous Logging in Corretto 17, and stay up to date with the latest features of OpenJDK. Xin Liu and Mike Cook take a look at a new Unified Logging (UL) features in OpenJDK and Corretto 17. Asynchronous logging reduces application pauses due to UL by decoupling logging from disk I/O. Dynamic configuration, which has been available since OpenJDK 9, provides true on-demand logging to avoid the constant overhead of UL until it is really needed. [hands on]

Bottlerocket
Bottlerocket is a Linux-based, open-source, container-optimised operating system. Justin Garrison takes a look at a new capability that was announced last week in how Bottlerocket now supports NVIDIA GPUs for accelerated computing workloads. You can now use NVIDIA-based Amazon Elastic Compute Cloud (EC2) instance types with Bottlerocket to accelerate your machine learning (ML), artificial intelligence (AI), and similar workloads that require GPU compute devices. Check out the post, Bottlerocket support for NVIDIA GPUs [hands on]
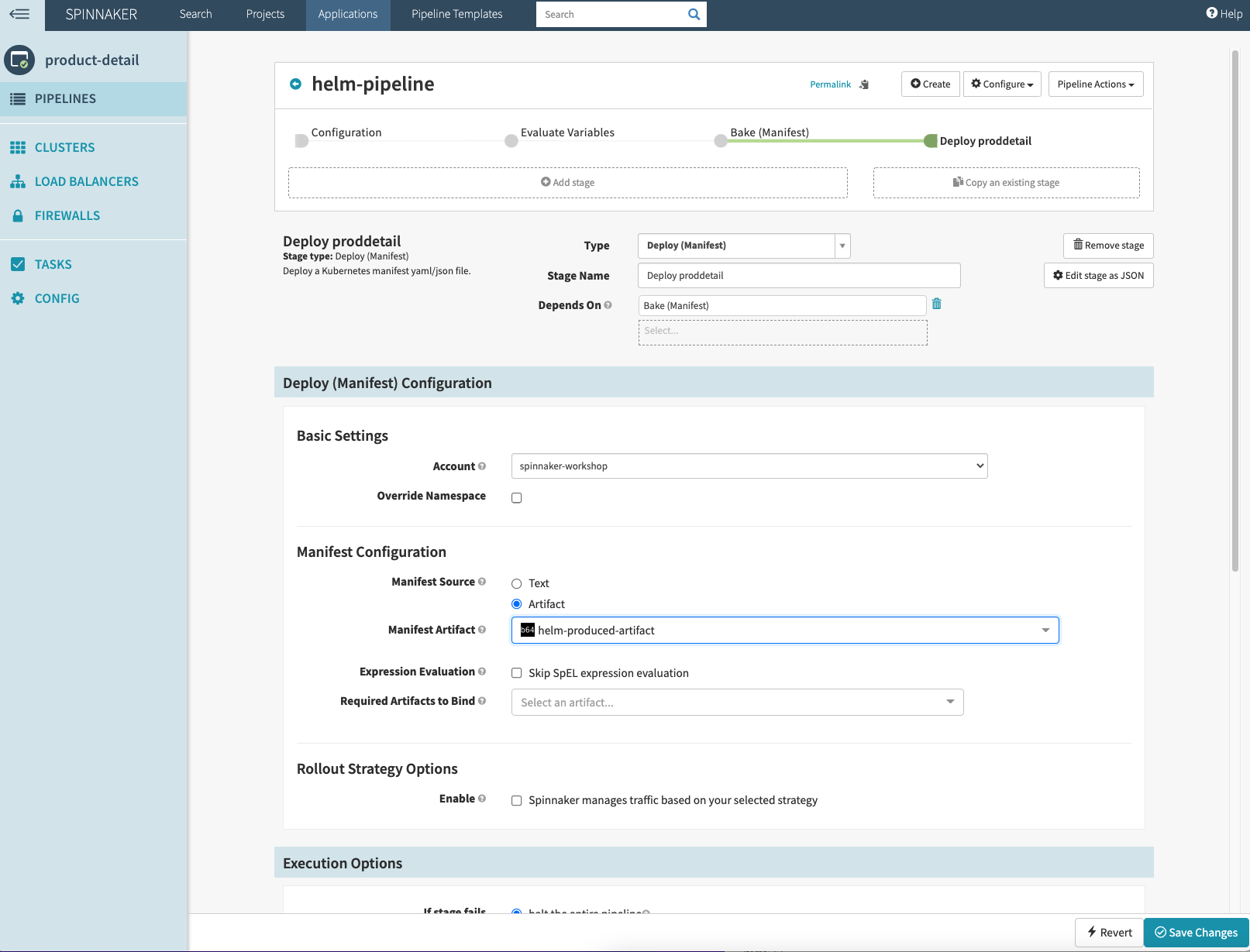
Spinnaker
In the post Managing Spinnaker using Spinnaker Operator in Amazon EKS Praseeda Sathaye shares with you how you can install the Spinnaker Service using Spinnaker Operator. The post shows the process of setting up a sample microservice in Spinnaker service using Spinnaker service YAML configuration, building a helm-based Spinnaker CD pipeline, and showing this working via a sample update. This is a nice deep dive, and I helped test this out so it gets my seal of approval! [hands on]
Apache Hudi
Apache Hudi (Hudi) allows you to build streaming data lakes with incremental data pipelines, with support for transactions, record-level updates, and deletes on data stored in data lakes. Hudi is integrated with various AWS analytics services, like AWS Glue, Amazon EMR, Athena, and Amazon Redshift. This helps you ingest data from a variety of sources via batch streaming while enabling in-place updates to an append-oriented storage system such as Amazon S3 (or HDFS). Nikhil Khokhar and Dipta S Bhattacharya share with you a serverless approach to integrating Hudi with a streaming use case and how to create an in-place updatable data lake on Amazon S3 in their blog post, Build a serverless pipeline to analyze streaming data using AWS Glue, Apache Hudi, and Amazon S3. [hands on]

Metabase
Metabase is an open source business intelligence tool that lets you create charts and dashboards using data from a variety of databases and data sources. Percy Musaka shares the lessons learned in his guide, Running Metabase on AWS Lightsail. Read the post to where Percy explains to how to install Metabase using AWS Lightsail, and how to connect Metabase to the PostgreSQL database.
Apache Airflow
A couple of posts last week from me. First up we had Orchestrating hybrid workflows using Amazon Managed Workflows for Apache Airflow (MWAA) where I show you how you can use Apache Airflow in conjunction with the ECSOperator to orchestrate your data pipelines across your hybrid architectures.

Following that, I put together Contributing to the Apache Airflow project - part two, the concluding post that shares my journey contributing to this open source project. I share my learnings at the end and I hope that this will provide some helpful hints as well as encourage others to make their first contributions.
PostgreSQL
Essential reading if you are working with PostgreSQL. Divya Sharma and Shawn McCoy share some of the issues that duplicate key violations can cause in a PostgreSQL database in their post, Hidden dangers of duplicate key violations in PostgreSQL and how to avoid them [hands on]
cfn-guard
Cfn-guard is a general-purpose open source tool developed by the CloudFormation team for expressing policy-as-code that can be enforced against structured hierarchical data, such as JSON or YAML. In his post, Enforce best practices in AWS Systems Manager documents leveraging CFN Guard Adam Spicer shares how an organisation can use cfn-guard in their processes to enforce standards and best practices for AWS Systems Manager (SSM) documents, to enforce standards and best practices. [hands on]
Hugging Face
Document summarisation is an example of a key use case within the M&E industry, where for example you might want to generate article headlines to create short-form summaries for push notifications. In the post, Democratize documentation summarization with Hugging Face on Amazon SageMaker James Yi and Simon Zamarin explore how Amazon SageMaker can be used to deploy a state-of-the-art document summarisation solution using the Hugging Face library. [hands on]
Other posts worth checking out
- Amazon Braket launches OpenQASM support announces that customers can now run OpenQASM programs on all gate-based devices on Amazon Braket
- Decoding protobuf messages using AWS Lambda will show you how to decode protobuf messages in a data stream processing application
- Query and visualize Amazon Redshift operational metrics using the Amazon Redshift plugin for Grafana guides you through setting up an Amazon Managed Grafana workspace and configuring an Amazon Redshift cluster with a Grafana data source for it
- Build microservices using Amazon Keyspaces and Amazon Elastic Container Service will show you how you can implement an isolated and scalable microservices pattern for running Apache Cassandra workloads
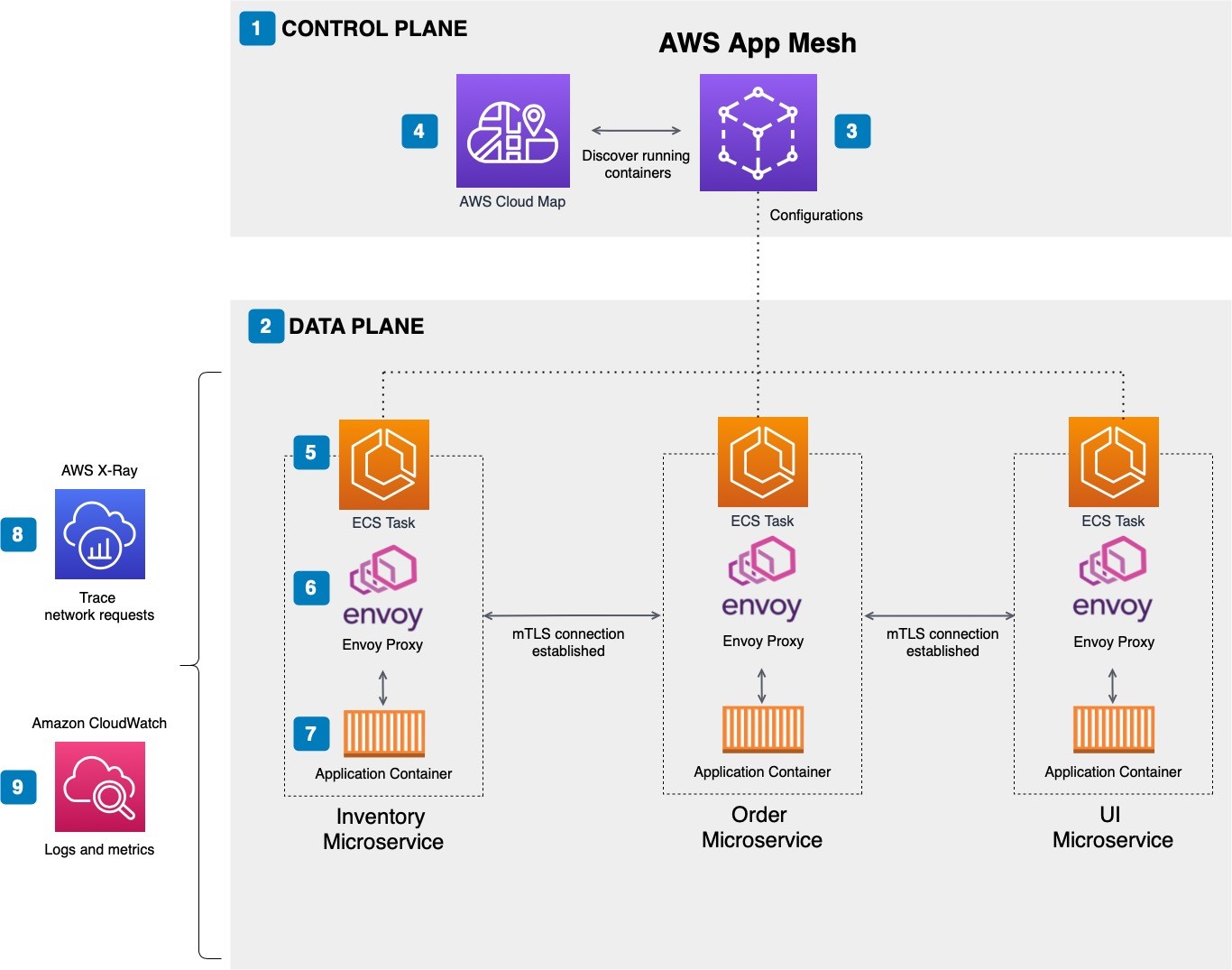
- Deploying service-mesh-based architectures using AWS App Mesh and Amazon ECS will help you solve some of the most common pitfalls of managing microservice architectures with envoy
- Build and Deploy a Microsoft .NET Core Web API application to AWS App Runner using CloudFormation shows you how to build a Microsoft.NET Core Web API application with AWS AppRunner
- Prepare for faster disaster recovery: Deploy an Amazon Aurora global database with Terraform provides a walk through managing an Aurora global database after a failover event using this Terraform module

Quick updates
MySQL
Following the announcement of updates in MySQL database versions 5.7 and 8.0, we have updated Amazon Relational Database Service (Amazon RDS) for MySQL to support MySQL minor versions 5.7.37, and 8.0.28.
Apache Airflow
As new versions of Apache Airflow are added to the Managed Workflows for Apache Airflow service, one of the common questions that gets asked is how can I migrate an existing environment? Well, I am happy to share that we have now published this guidance, so make sure you check it out. Read more at What is the Amazon MWAA migration guide?
Apache Kafka
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now allows custom configuration providers for MSK Connect. With this capability, you can store secrets with providers such as Amazon Secrets Manager and avoid storing passwords and other credentials in connector and worker configuration properties. You can supply any Apache Kafka compatible ConfigProvider as part of an MSK Connect plugin, and use this to fetch configuration.
Amazon Genomics CLI
Amazon Genomics CLI simplifies and automates the deployment of cloud resources like workflow engines and compute clusters, providing genomics and life science customers with an easy-to-use command line to quickly setup and run genomics workflows on Amazon Web Services (AWS). The Amazon Genomics CLI has added Snakemake to its catalog of workflow management tools for genomics analysis, which also includes Cromwell, Nextflow, and miniWDL. Inspired by GNU Make, Snakemake specifies workflows as rules that breakdown the workflow into smaller steps of dependencies. Snakemake automatically determines dependencies between rules and also provides additional controls via python-based rule definition syntactic structures. The benefits of reproducibility and transparency that workflow management tools, like Snakemake, provide are realized at scale via the Amazon Genomics CLI.
Amplify iOS Library
The Developer Preview of the Amplify iOS Library that has been rewritten to exclusively use Swift. This initial release enables Swift developers to add cloud-based app features, including Auth, Storage, Data, and APIs, without having to transition to Objective-C to debug or contribute to the underlying open-source code. In coming releases, we plan to add support for additional Amplify use cases, as well as Swift-based language features like structured concurrency. This release also includes rearchitected Auth (sign-up/sign-in) and Storage (file upload/download) workflows that provide better debuggabilty and visibility into underlying state management. We have also taken this opportunity to remove calls to deprecated Apple APIs. Finally, we have layered the new library on the new AWS SDK for Swift that was released as Developer Preview last year. This allows developers to use Amplify’s use case-centric APIs—like Auth and DataStore—and use the AWS SDK for Swift for a breadth of service-centric APIs.
Videos of the week
Building a Secure AWS Golden Image Pipeline with Packer, Vault and Terraform
Mihai Criveti and Elif Samedin from HashiCorp provide an end-to-end demo of a Terraform, Vault, and Packer-based CI/CD workflow for building secure and compliant OS images. Triggering Ansible and OpenSCAP for OS image compliance and post-install steps.
ROS
Check out this video from Jacqui De Sa on how you can scale your robotics testing by using WorldForge. I have done demos using this tool before, and it is super easy to quickly generate lots of different test environments for your robots to explore and see how they get on. If you are looking at how to do this at scale, you should check this video out.
Guardrails for EKS Clusters
Check out this video featuring Oscar Medina from AWS, and Sarah MacDonald, and J. Cole Morrison from HashiCorp in learning about creating guardrails for AWS EKS clusters.
Events for your diary
If you have an event you want me to publish here, please contact me and I will include it in this listing.
Responding To Threats In AWS Linux & Kubernetes Environments March 16th 9am PDT
Check out this Webinar to learn about real-life attack techniques used to compromise AWS Linux and Kubernetes environments and how to gain the level of visibility and depth that’s required to respond to cloud incidents most efficiently.
Read more about what to expect and register via this link.
Prevent Kubernetes misconfigurations with Datree open-source CLI March 17, 12:00 PM GMT
The Singapore Kubernetes User Group meet up on the 17th of March with a great sounding session on how to help prevent Kubernetes misconfigurations with Datree open-source CLI. AWS Community Hero, CEO & Co-Founder at Datree Shimon Tolts together with Noaa Barki will be your speakers.
Find out more on what to expect and sign up over at meetup.com, here.
Building an Open Data Lakehouse with Presto, Hudi, and AWS S3 March 29th, 10am PT
In this 90 minute hands on-virtual lab that will walk you through how to build an Open Data Lakehouse stack with Presto, Apache Hudi, and AWS S3.
If you want to learn more about these open source projects, this looks like the perfect opportunity. Check it out and register on their registration page.
OpenSearch Every Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting - Feb2022
GitOpsCon Europe May 17th, Valencia Spain
GitOpsCon Europe is designed to foster collaboration, discussion, and knowledge sharing on GitOps. This event is aimed at audiences that are new to GitOps as well as those currently using GitOps within their organisation. Get connected with others that are passionate about GitOps. Learn from practitioners about pitfalls to avoid, hurdles to jump, and how to adopt GitOps in your cloud native environment.
The event is vendor-neutral and is being organised by the CNCF GitOps Working Group. Topics include getting started with GitOps, scaling and managing GitOps, lessons learned from production deployments, technical sessions, and thought leadership.
Read more about this from the official page here.
CDK Day May 26th - Virtual
This is a community organised event about AWS CDK, cdktf, projen and cdk8s. This will be third year they run this event, and if the previous two are anything to go by, this will be essential viewing - live streamed via You Tube. Check out and register for the event over at their home page at https://www.cdkday.com/
CFP
Apache Airflow CFP closes March, 14th
A heads up to folks who are interested in all things Apache Airflow. Apache Airflow Summit 2022 has been announced and the call for papers (cfp) is now open. The bar for sessions is always very high, so looking forward to this event already.
If you have an idea for a talk, why not submit one via the cfp process. Check out the event, Apache Airflow Summit 2022
If you maybe have wanted to do a session, then I am very happy to help with feedback or coaching to help you feel more comfortable in creating and/or delivering your session. If this something that has been on your mind, but you just needed a little support, PLEASE get in touch.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen