AWS open source news and updates #97
Jan 22nd, 2022 - Instalment #97
Newsletter #97.
Welcome to another edition of the AWS open source newsletter, packed with more great new open source projects, content, and events. This week, we have new projects that help you improve security by de-obfuscating strings, a library to help you automate the configuration of your build pipelines, a new Terraform module, a nice new VSCode plugin that will help you when working with IAM, and several more. For open source content, the topics covered this week include Apache Spark, Apache Iceberg, OpenTelemetry, PostgreSQL, Jupyter, Apache Airflow, Apache Log4j,RabbitMQ, Amazon Corretto, AWS ParallelCluster, Hugging Face, OpenSearch and more. Make sure you don’t miss this weeks video on Smith, and we have four meet-ups happening later this week, check those out too.
As always, if you have any cool posts you would like me to share, or if you have a request for particular topics you would like to see more of, then please drop me a message or write a comment below.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Ashwin Pc, Drew Mullen, Ben Kehoe, Sebastian Bille, Gaurav Dhamija, 방신우, Vikram Mehto, Yoginder Sethi, Ganesh Sawhney, Qiang Zhang, Ryan Dsouza, Yaser Raja, Peter Celentano, Manuel Pozo, Jérôme Van Der Linden, Antonio Lagrotteria, Simon Willison, Beau Carnes, and Michael Dowling.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
jndi-deobfuscate-python
jndi-deobfuscate-python This tool processes text logs to look for Java Naming and Directory Interface (JNDI) lookup strings, and outputs deobfuscated strings when it finds them. De-obfuscated strings can be used by other tools (not included), in order to retrieve malicious payloads from an attacker. JNDI lookup strings came into spotlight during a recent series of Common Vulnerabilities and Exposures (CVEs) around a popular Java logging library, Apache Log4j.
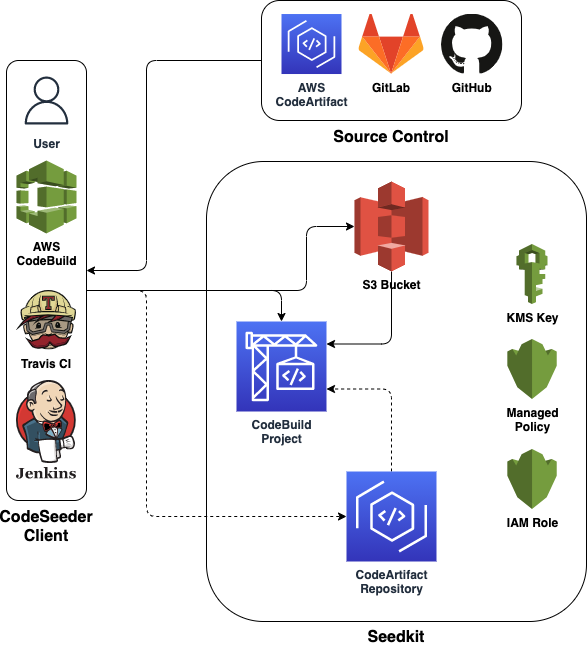
aws-codeseeder
aws-codeseeder this project enables builders to easily “seed” python code to AWS CodeBuild for execution in their cloud environments. aws-codeseeder eliminates the need to install and configure libraries and utilities locally or on a build system (i.e. Jenkins). Instead the library enables builders to easily execute an AWS CodeBuild instance with the utilities they require then seed local python code to, and execute it within, the CodeBuild instance. Check out the detailed docs for more info on how this works.
route53-recovery-controller
route53-recovery-controller Drew Mullen released his first Terraform Module as part of the Amazon Web Services (AWS) Integrations & Automations (I&A) team, Route53 Application Recovery Controller (ARC). Route 53 ARC can continuously monitor your application’s ability to recover from failure and control recovery across multiple AWS Availability Zones, AWS Regions, and on-premises environments. And this module makes it easy to add resiliency to your already deployed applications!
iam-legend
iam-legend AWS Community Builder Sebastian Bille has put together this useful extension for VSCode users (like me!) that make it easier when working with IAM policies, and provides IAM policy actions autocomplete, documentation & wildcard resolution. Nice!
aws-lambda-api-event-utils
aws-lambda-api-event-utils this library from Ben Kehoe starts with the question “There are many other libraries, in Python and in other languages, for handling HTTP events in Lambda. So why this library?” Find out the answer by checking out this project.
assume-aws-role-action
assume-aws-role-action these GitHub actions enable workflows to obtain AWS Access Credentials for a desired IAM Role using AWS IAM SAML and a GitHub Actions Repository Token.
s3-credentials
s3-credentials is an open source project from Simon Willison that helps you create credentials for accessing S3 buckets. In the latest update from his blog, Weeknotes: s3-credentials prefix and Datasette 0.60, he shares some new features of this project, that might be especially helpful if you are building multi-tenet solutions.
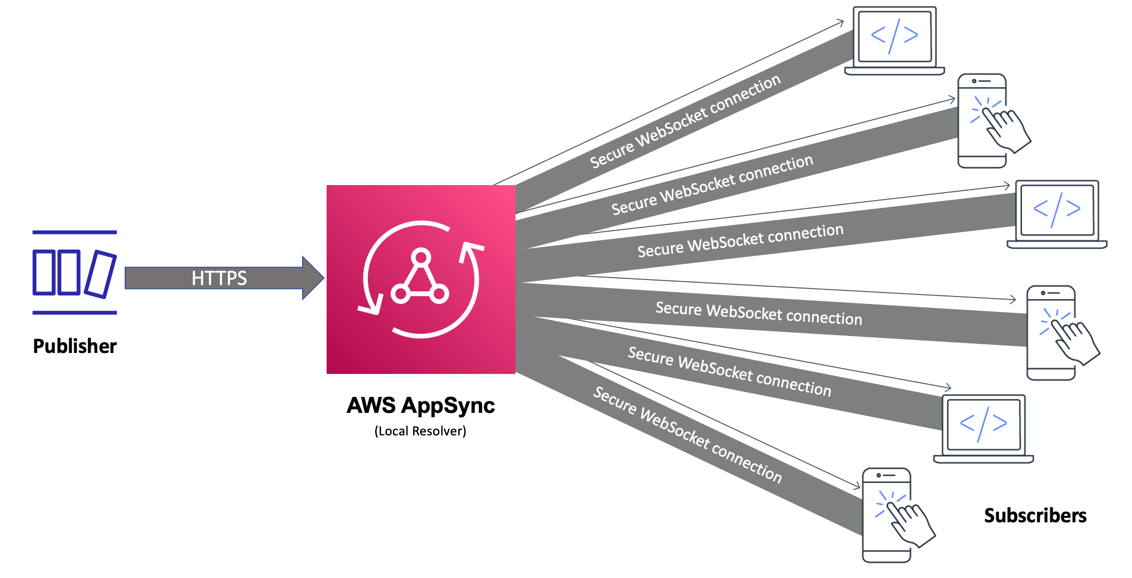
simpleWSAPI
simpleWSAPI this repo contains an implementation of a simple real-time API based on WebSockets where clients are subscribed to a specific channel and any JSON data can be pushed automatically to clients listening/subscribed to the channel. To help you walk through this, check out the post from Ed Lima Simple serverless WebSocket real-time API with AWS AppSync (little or no GraphQL experience required)
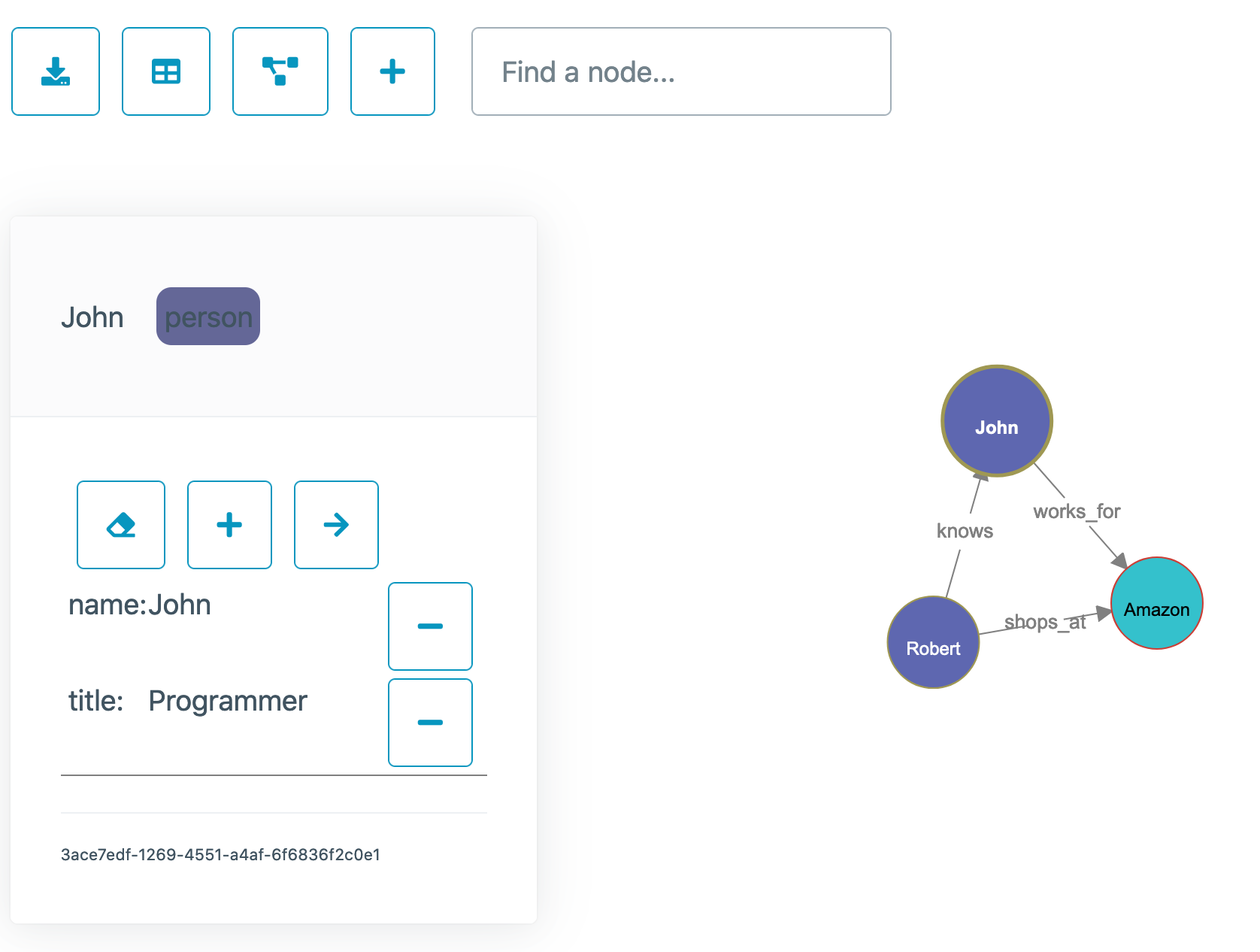
cdk-neptune-knowledge-graph
cdk-neptune-knowledge-graph this sample application deploys a Neptune cluster and a static web site to provide a convenient user interface for building a knowledge graph. It uses Cognito to provide authentication to the web site. Read the README for more details.
dms-psql-post-data
dms-psql-post-data 방신우 shares this script that may come in hand if you are looking at doing any PostgreSQL-to-PostgreSQL migrations. Why might you need this script? Well, its in the README, but to summarise, this script can help you resolve some artefacts that are not migrated, and if you want to target the migrated database as primary.
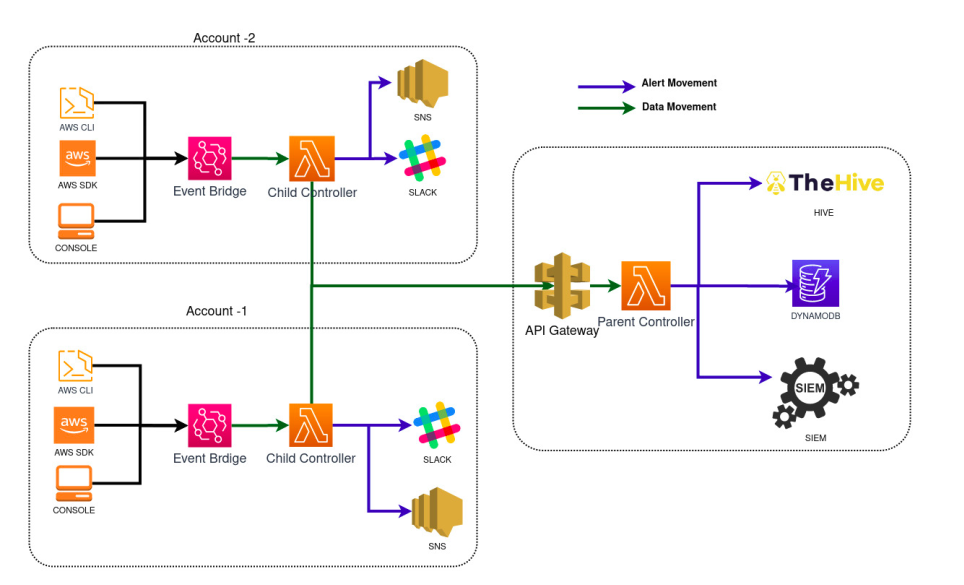
DIAL
DIAL DIAL(Did I Alert Lambda?) is an open source project that provides a centralised security misconfiguration detection framework which completely runs on AWS Managed services like AWS API Gateway, AWS Event Bridge & AWS Lambda
AWS and Community blog posts
OpenTelemetry
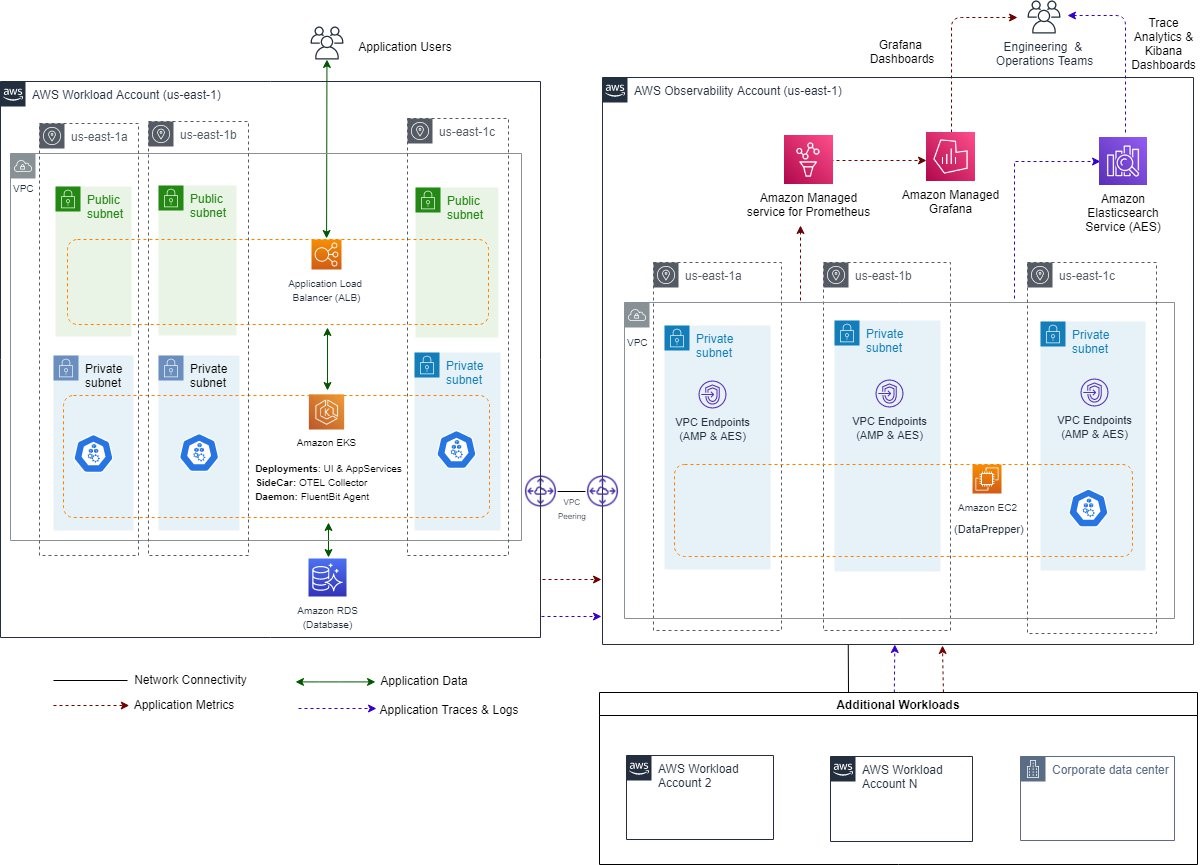
In Build an observability solution using managed AWS services and the OpenTelemetry standard Gaurav Dhamija, Vikram Mehto, and Yoginder Sethi share how to build an open standards observability solution using managed AWS services. The posts covers how to centralise the metrics, traces, and logs collected from workloads running in various AWS accounts using AWS Distro for OpenTelemetry (ADOT), Amazon Managed Grafana, Amazon Managed Service for Prometheus, and Amazon OpenSearch Service. [hands on]
Graph Notebooks
Whether you’re creating a new graph data model and queries, or exploring an existing graph dataset, it can be useful to have an interactive query environment that allows you to visualise the results. In the post, Use Docker containers to deploy Graph Notebooks on AWS, Ganesh Sawhney and Qiang Zhang share how to host a Jupyter notebook and use it to load data into your Amazon Neptune database, query it, and visualise the results. [hands on]

PostgreSQL
If you are looking for guidance on how to set up PostgreSQL bi-directional replication using pglogical, Yaser Raja and Peter Celentano have you covered in their post, PostgreSQL bi-directional replication using pglogical [hands on]

OpenSearch
Ashwin Pc explores how plugins work for OpenSearch Dashboards in his post, Introduction to OpenSearch Dashboard Plugins [hands on]
Micro-Frontends using AWS CDK
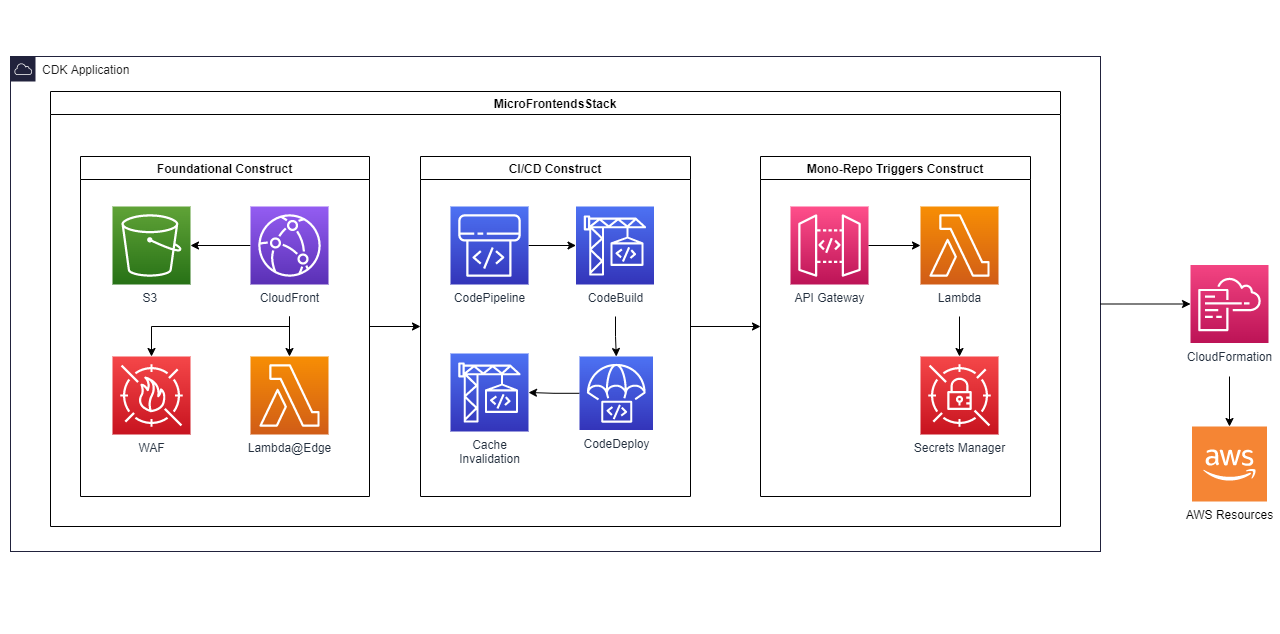
In the follow up from a post where Antonio Lagrotteria shared the first in a series of posts aimed at showing you how to build a complete server-less architecture aiming at deploying and hosting client-side mono-repo micro-frontends, this time he is back with a post that walks you through how to provision a mono-repo micro-frontend architecture in his post, A Complete CDK for a Module-Federated Micro-Frontends AWS Architecture. Great post, and can’t wait for the next instalment. [hands on]
Apache Airflow
If you love learning from how companies use technology, then you will love this post from the lovely folk at Voodoo, How Voodoo did Airflow 101. Manuel Pozo shares their experience on how Voodoo run Apache Airflow, but also the pros and cons of this platform, and a few tips to work around some issues they found during their journey.
Apache Log4j
A couple of posts this weeks, covering Apache Log4j. In light of the recent security incidents, these are worth reading.
First up we have Ryan Dsouza, who provides guidance to help industrial customers respond to the recently disclosed Log4j vulnerability, in his post What actions customers can take to protect, detect, and respond to Log4j vulnerabilities in Operational Technology (OT) and Industrial Internet of Things (IIoT) environments. He covers how to identify if you are susceptible to the issue, and then how to address the vulnerability.
Following that we have our friends at the fictitious company, “I Love My Local Farmer”, where Jérôme Van Der Linden takes a look at a practical example of how this might impact you and some of the options you have to help protect yourself in the post, Protecting from vulnerabilities in Java: How we managed the log4j crisis [hands on]
Other posts worth checking out
Last week, these posts also caught my eye.
- Distributed fine-tuning of a BERT Large model for a Question-Answering Task using Hugging Face Transformers on Amazon SageMaker looks at how you can accelerate training and fine-tuning of Hugging Face Transformer models using SageMaker distributed libraries
- Using the ParallelCluster 3 Configuration Converter helps you get started with AWS ParallelCluster 3, a major release with several changes and a lot of new features
- Using Spot Instances with AWS ParallelCluster and Amazon FSx for Lustre will help you optimise your costs by showing you how to configure AWS ParallelCluster to handle Spot Instance interruption
- Broadpeak Launches New Video Streaming API SaaS Platform with Support from AWS SaaS Factory takes a peek at how Broadpeak navigated business and technical decisions to build the new platform as a software-as-a-service (SaaS) solution
Quick updates
Apache Iceberg
Announced last week was Amazon EMR 6.5.0 now includes Apache Iceberg version 0.12. Apache Iceberg is an open table format for large data sets in Amazon S3 and provides fast query performance over large tables, atomic commits, concurrent writes, and SQL-compatible table evolution. With the current release, you can use Apache Spark 3.1.2 on EMR clusters with the Iceberg table format.
Apache Iceberg offers an open source table format for data stored in data lakes that helps data engineers manage complex challenges such as managing continuously evolving data sets while maintaining query performance. Iceberg allows you to:
- Maintain transactional consistency on tables between multiple applications where files can be added, removed or modified atomically with full read isolation and multiple concurrent writes
- Implement full schema evolution to track changes to a table over time
- Issue time travel queries to query historical data and verify changes between updates
- Organize tables into flexible partition layouts with partition evolution enabling updates to partition schemes as queries and data volumes change without relying on physical directories
- Rollback tables to prior versions to quickly correct issues and return tables to a known good state
- Perform advanced planning and filtering in high performance queries on large data sets etc.
Amazon Corretto
On January 18th, Amazon announced quarterly security and critical updates for Amazon Corretto Long-Term Supported (LTS) versions. Corretto 11.0.14 and 8.322 are now available for download. Amazon Corretto 17 updates will be available shortly after the release is tagged in the OpenJDK 17 repository.
Apache Spark
Amazon EMR now supports Apache Spark SQL to insert data into and update Glue Data Catalog tables when Lake Formation integration is enabled. Amazon EMR integration with AWS Lake Formation allows you to define and enforce database, table, and column-level permissions when Apache Spark users access data in Amazon S3 through the Glue Data Catalog. Previously, with AWS Lake Formation integration is enabled, you were limited to only being able to read data using Spark SQL statements such as SHOW DATABASES and DESCRIBE TABLE. Now, you can also insert data into, or update the Glue Data Catalog tables with these statements: INSERT INTO, INSERT OVERWRITE, and ALTER TABLE. This feature is enabled from Amazon EMR 5.34
RabbitMQ
Amazon MQ now provides support for RabbitMQ version 3.8.26. This patch update to RabbitMQ contains several fixes and enhancements compared to the previously supported version, RabbitMQ 3.8.23.
Open Data
Whilst not open source, open data helps builders spend more time on data analysis rather than data acquisition, making it easy to find a wide variety of datasets that are made publicly available. 19 new data sets are now available, covering climate and weather, geospatial, life sciences, and machine learning. Read the full announcement, New datasets available on the Registry of Open Data from Meta, the Brazilian Space Agency, Radboud University Medical Center, and others
Videos of the week
Smithy
This is a must watch video for those building APIs. Michael Dowling, shares they story of this great open source project, the origins, how to get started and how it is being used. Really great session, where time just seems to fly past.
AWS CDK
If you are looking for an introduction in how to use AWS CDK as part of your infrastructure as code journey, then check out this session from Beau Carnes, How to Define Cloud Infrastructure with the AWS Cloud Development Kit. Nice!
Events for your diary
If you have an event you want me to publish here, please contact me and I will include it in this listing. Later this week, we have some great meetups happening.
AWS Startup Showcase Season January 26th, 10:00am PDT
Join AWS and theCUBE as eight innovative companies within the AWS Partner ecosystem highlight their latest developments in the open source community.
Serverless London User Group: Lambda Powertools January, 26th at 9PM GMT
Don’t miss this meetup, which will be “a relaxed conversation with Heitor Lessa, Sara Gerion and Yan Cui about the evolution of Lambda Powertools and how it can help you build serverless applications.”
Read more and register at, Let’s talk about Lambda Powertools!
Cloud DevSecOps with Bridgecrew and Terraform Thursday, Jan 27 at 9am PT / 12pm ET
From scanning infrastructure as code (IaC) for security misconfigurations to implementing automated DevSecOps workflows, this workshop will provide a hands-on experience to automate your cloud security.
Sign up and reserve your spot, Cloud DevSecOps with Bridgecrew and Terraform
Presto Tech Talks: Presto + Pinot by Uber & AWS Lake Formation by Ahana Friday, January 28, 5PM PT
Join this meetup to hear from speakers who are using Presto with Pinot and Presto with AWS Lake Formation. Learn from experienced developers who use Presto at scale, with their highly valuable insights!
Read and register here
CFP
A heads up to folks who are interested in all things Apache Airflow. Apache Airflow Summit 2022 has been announced and the call for papers (cfp) is now open. The bar for sessions is always very high, so looking forward to this event already.
If you have an idea for a talk, why not submit one via the cfp process. Check out the event, Apache Airflow Summit 2022
If you maybe have wanted to do a session, then I am very happy to help with feedback or coaching to help you feel more comfortable in creating and/or delivering your session. If this something that has been on your mind, but you just needed a little support, PLEASE get in touch.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen