AWS open source news and updates #90
November 15th, 2021 - Instalment #90
Updated, 18th Jan to remove dead links
Newsletter #90.
Another packed edition of his newsletter, with some great new open source projects such as ploomber (a project to help you build production pipelines for your notebooks), slic-starter (a complete starter project for production-grade serverless applications) and many more interesting projects covering RStudio, Spring Boot, a serverless software vending solution, Kubernetes on the edge and more. AWS and Community content this week covers AWS CDK, Steampipe, AWS Distro for OpenTelemetry, Dask, Flagger, Cortex, Apache Airflow, Apache Flink, OpenSearch, Reddis, RabbitMQ and more. Make sure you check out the videos too, this week featuring open source Observability and OpenSearch.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Azmi Mengü, Pawel Grzybek, Jozef Jaroščiak, fourTheroem, Kyle Davis, Dotan Horovits, Matt Hanson, Ariel Walcutt, Imtranur Rahman, Mary-Elizabeth Morin, Kinnar Sen, Nathaniel Ruiz Nowell, David Boeke, Bob Tordella, Jon Udell, Behram Irani, Madhav Vishnubhatta, Ethan Fahy, Zac Flamig, Nima Kaviani, Manabu McCloskey, Nicholas Thomson, Tom Zach, Kevin Bell, Stefan Prodan, Ramesh Sencha, Nate Bachmeier, Wallace Printz, Christian Mueller, Alex Pulver, Nick Lynch, Dzenan Softic, Sam Dengler, James Greenwood, Bikash Behera, and Kevin Higgins.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Community noticeboard
Research Papers
Check out the latest research papers released from Amazon focused on natural-language understanding and question answering are areas of focus, with additional topics ranging from self-learning to text summarisation. You can check these out on the post, Amazon’s 23 papers at EMNLP
AWS CDK
If you are looking for examples CDK projects, then AWS Community Builder Azmi Mengü has plenty of good examples you can get inspiration from. Head on over to his GitHub repos and see for yourself.
Latest open source projects
slic-starter
slic-starter Whilst I was watching the great sessions during AWS Community Day, I came across this project from fourTheorem. SLIC Starter is a complete starter project for production-grade serverless applications on AWS.

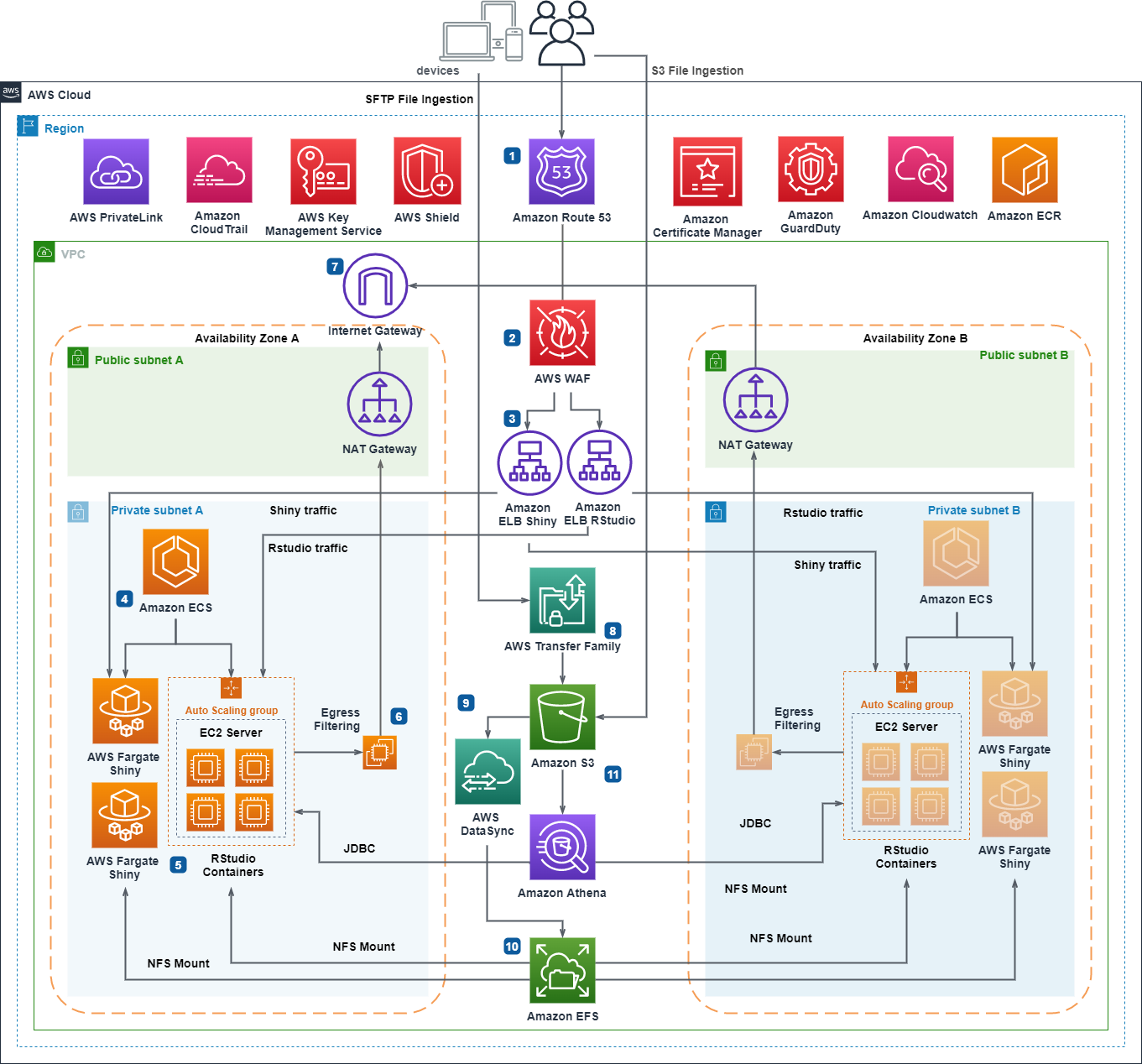
aws-fargate-with-rstudio-open-source
aws-fargate-with-rstudio-open-source this project delivers AWS CDK Python code to provision serverless infrastructure in AWS Cloud to run Open Source RStudio Server and Shiny. This is pretty nice, so make sure you bookmark this. I am also going through the code and going to re-use parts of it for other open source projects too.
ploomber
ploomber this project helps you with the challenges of working with .ipynb files allowing teams to develop collaborative, production-ready pipelines using JupyterLab or any text editor. This project is integrated with AWS so you can leverage it in your environments to develop locally, and then deploy to the cloud.
AWS-Connect-Manager
AWS-Connect-Manager this project from Jozef Jaroščiak provides Windows users with an easy to use tool to connect with your Amazon EC2 instances.
aws-kubernetes-edge-greengrass
aws-kubernetes-edge-greengrass this project demonstrates how to collect data from edge locations using Kubernetes (k3s) and AWS IoT Greengrass. The code shows you how to get up and running on a Raspberry Pi, and uses AWS CDK - two of my favourite things.
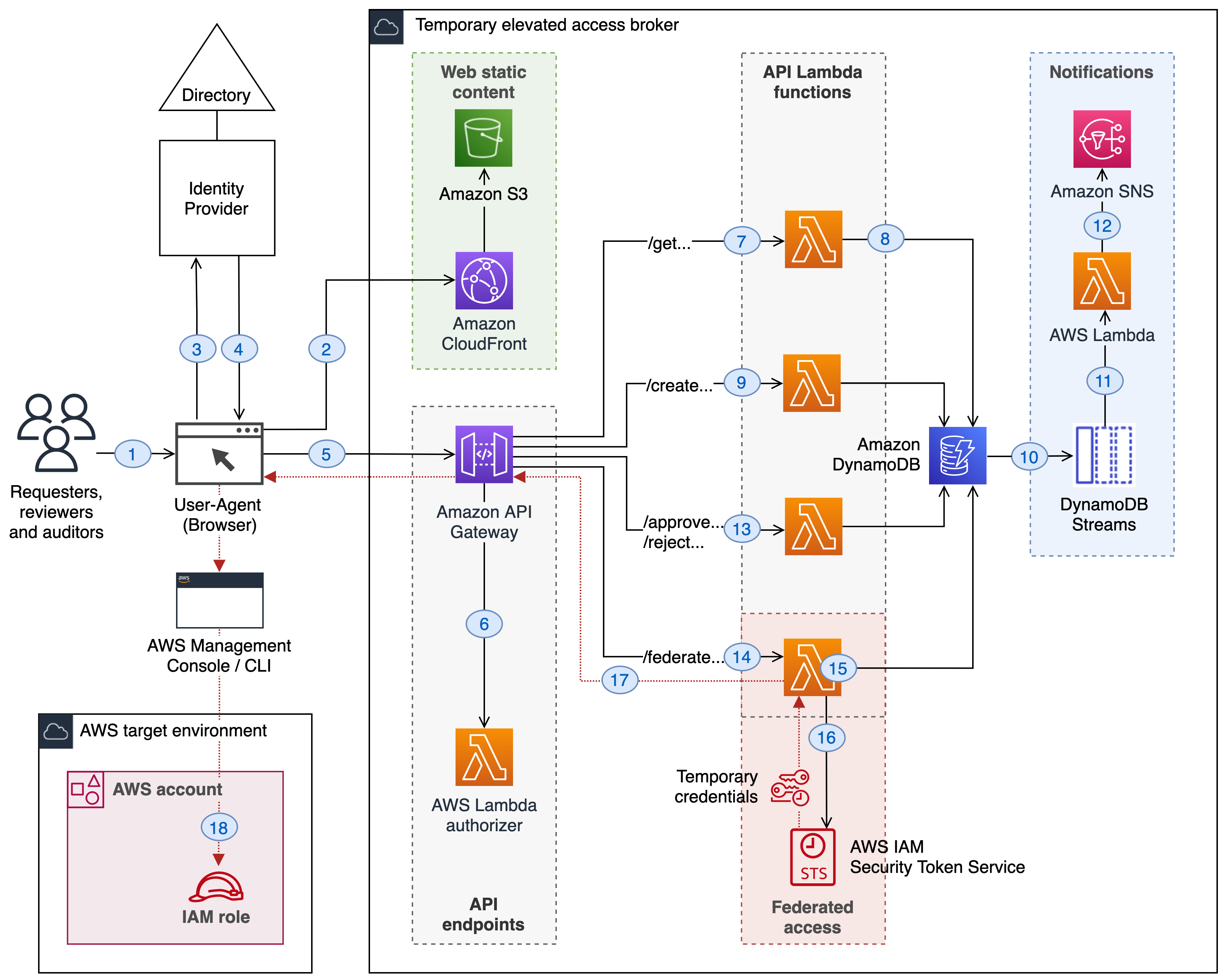
aws-iam-temporary-elevated-access-broker
aws-iam-temporary-elevated-access-broker this projects provides a minimal reference implementation for providing temporary elevated access to your AWS environment. James Greenwood, Bikash Behera, and Kevin Higgins walk you through how to use this project in the blog post, Managing temporary elevated access to your AWS environment
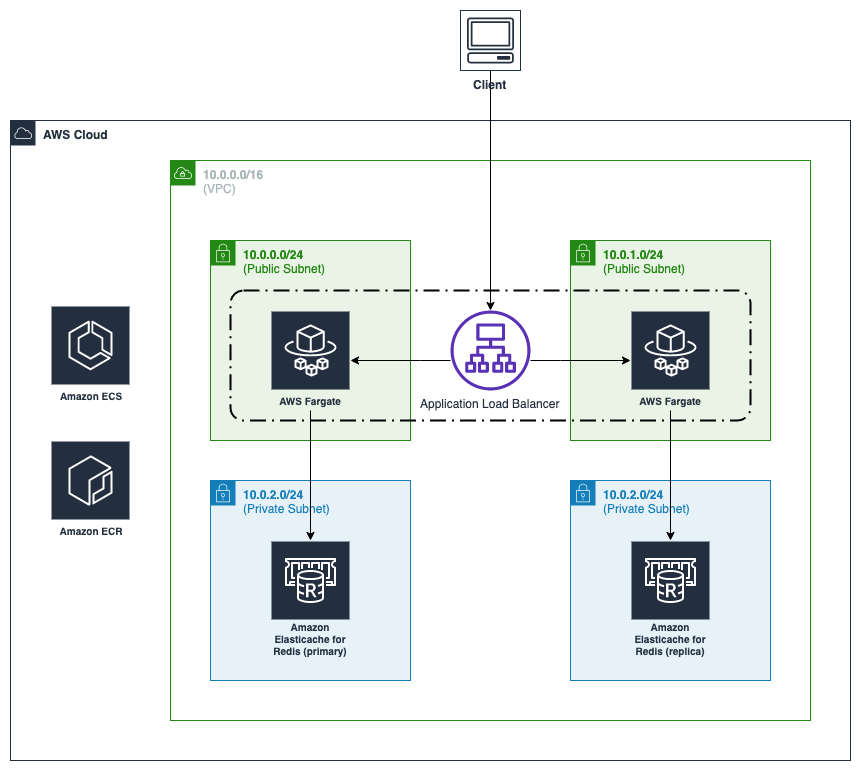
java-spring-boot-ecs-fargate-redis-caching
java-spring-boot-ecs-fargate-redis-caching this sample shows how a Spring Boot application can be deployed on ECS Fargate with Redis Caching Support to persist session data and improve application performance. The solution also provides the necessary templates to automatically provision the required infrastructure using CloudFormation to your desired AWS account.
aws-severless-vending-machine
aws-severless-vending-machine this repository shows you how to create a solution to developer teams consume IaC Products, like a “Vending Machine”, to automated deploy cloud service in their AWS Accounts without open a ticket or request in IT department. You can read the blog post Criando um portal de autosserviços para o provisionamento na AWS (in Portugese, but I tried translating with Amazon Translate and it did a great job)

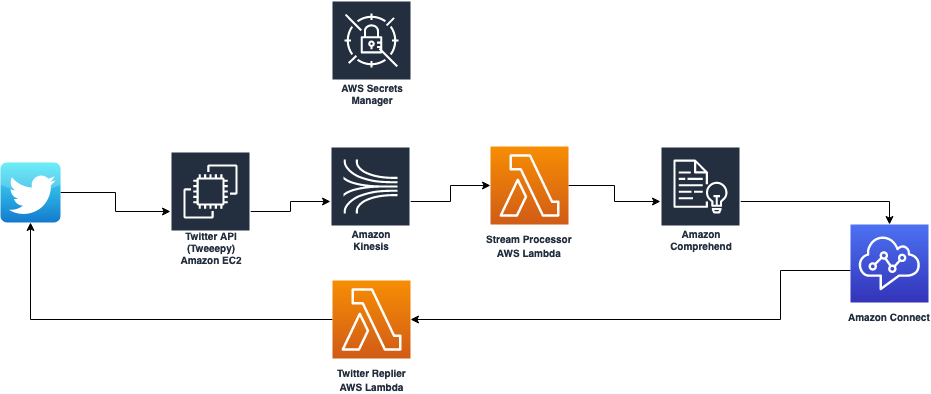
amazon-connect-twitter-listener
amazon-connect-twitter-listener I was recently chatting with a builder who was trying to implement social media integration with Amazon Connect, so I was pleasantly surprised when this project popped up on my open source radar. This project contains source code and supporting files for twitter streaming to Amazon Connect Tasks. Tweets are filtered on the specified tag and analyzed using comprehend to identify language and sentiment. Both tags are added as attributes to the task so additional branching decisions can be made. You need to set up your Amazon Connect project up first, but details are in the README
AWS and Community blog posts
AWS CDK
A couple of good AWS CDK posts this week, starting off with Comparing AWS Cloud Development Kit and AWS Controllers for Kubernetes in which Nima Kaviani, Manabu McCloskey, and Nicholas Thomson come together to compare strategies, tools and technologies to automate infrastructure and software rollout strategies when working with Kubernetes. They look at six areas of focus: Programming, Validation, Execution, Interaction, Operation, and Reconciliation.
A must read post from Alex Pulver and Nick Lynch is their post, Experimental construct libraries are now available in AWS CDK v2 where they share an update on the AWS CDK v2 experimental APIs, and how this can make it even easier to migrate from v1.
Steampipe
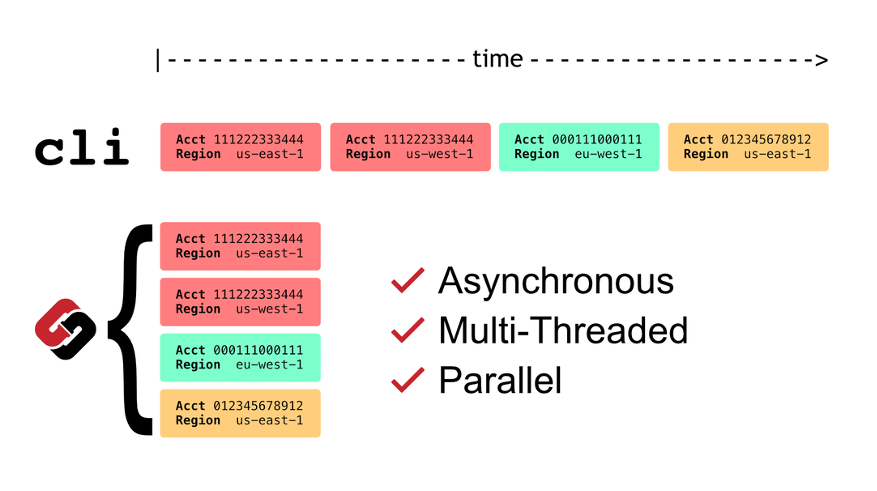
Steampipe is an open source tool for querying cloud APIs in a universal way and reasoning about the data in SQL. David Boeke, Bob Tordella, Jon Udell, and Nathan Wallace have collaborated together on this post, Querying AWS at scale across APIs, Regions, and accounts where they share a number of different approaches for how you can use this project to deliver the best possible speed and throughput. [hands on]
AWS Distro for OpenTelemetry
Nathaniel Ruiz Nowell explains how to get telemetry data from AWS Lambda Python functions, without having to change a line of code, in his post Auto-instrumenting a Python application with an AWS Distro for OpenTelemetry Lambda layer [hands on]

We also had with the post, How To Use OpenTelemetry With AWS Lambda from Tom Zach at Aspecto, that also shows you how to deploy a tracing-enabled lambda with OpenTelemetry.

To wrap up things in ADOT we had Alolita Sharma write AWS Distro for OpenTelemetry 0.14 is now available with updated Lambda layers, providing the release highlights and details on how you can download this image.
Flagger
Flagger is a CNCF incubating project that takes care of much of the undifferentiated heavy lifting of canary deployments on Kubernetes. In the post Performing canary deployments and metrics-driven rollback with Amazon Managed Service for Prometheus and Flagger Kevin Bell and Stefan Prodan explain how to perform canary deployments on Kubernetes using Flagger to orchestrate the rollout, promotion, and rollback of deployments. Taking care of metrics we have Amazon Managed Service for Prometheus, and letting you observe the canary deployment process, we have Amazon Managed Grafana. Nice! [hands on]
![]()
Cortex
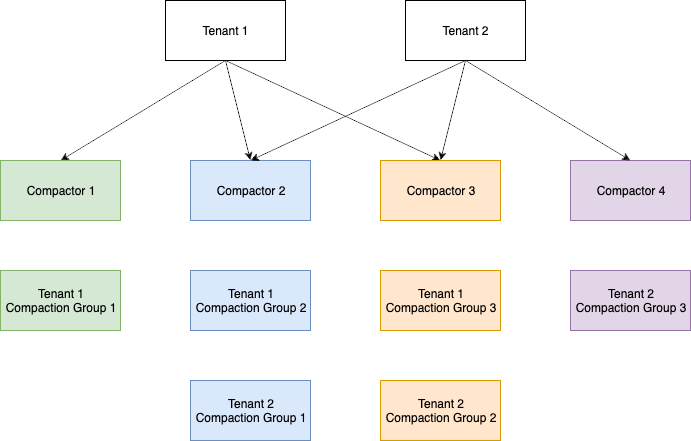
In the post, Scaling Cortex with parallel compaction Albert Choi, an intern on the Amazon Managed Service for Prometheus team, shares his experience of designing and implementing parallel compactors inside of the Cortex open source project.
Dask and Open Data
This week we have a couple of interesting posts on how to analyse open data sets using an open source project called Dask (an open source project in Python that provides parallelism for analytics). Combining open data sets together with open source software running on AWS is a growing trend to help provide insights that can help make the lives of emergency managers, climate scientists, and policy makers that much easier.
First up we have the post, Transforming Geospatial Data to Cloud-Native Frameworks with Element 84 on AWS, where Matt Hanson and Ariel Walcutt from Element 84 and Imtranur Rahman and Mary-Elizabeth Morin from AWS walk you through a solution you can put together than combines open data sets from Sentinel-2 (satellite imagery) with Dask, and a number of Python libraries to analyse and visualise the data. [hands on]

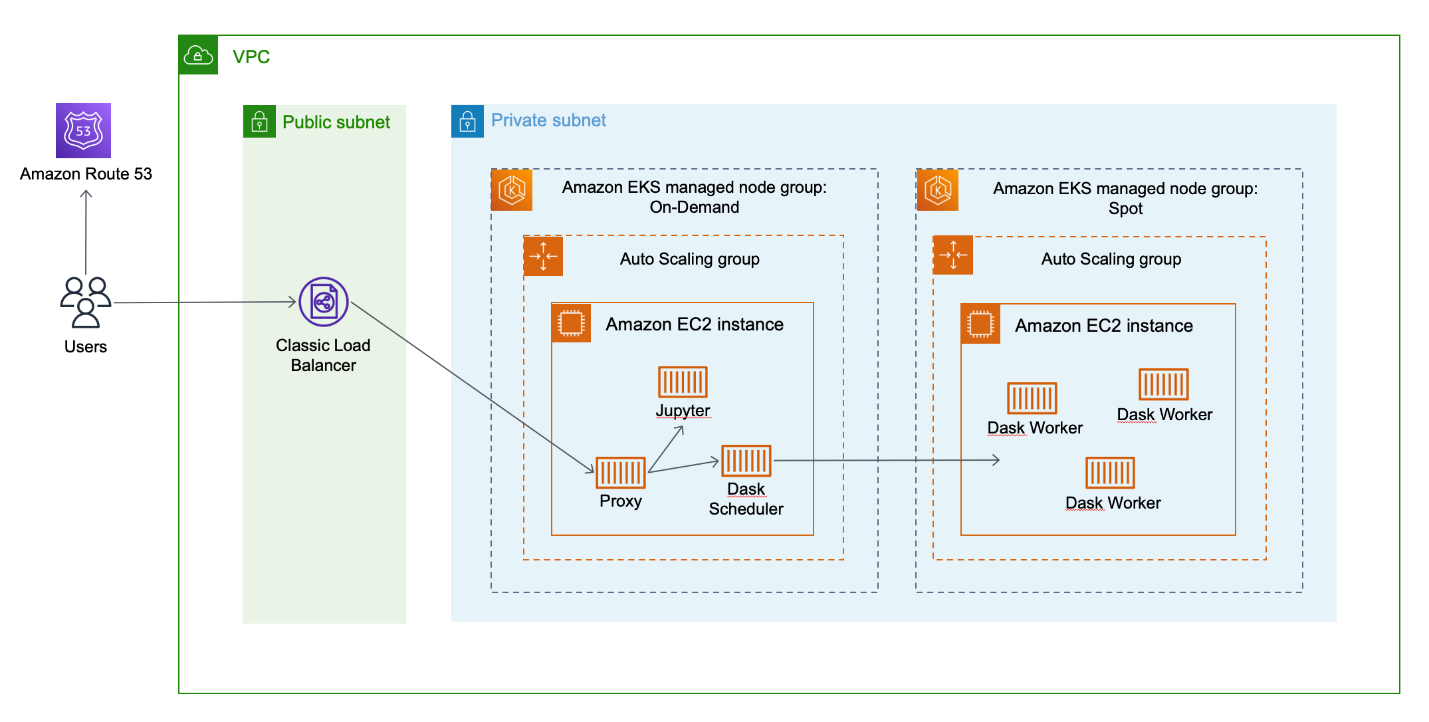
Following that we have Analyze terabyte-scale geospatial datasets with Dask and Jupyter on AWS, where Ethan Fahy and Zac Flamig show you how to set up this Kubernetes, Dask and Jupyter Pangeo solution on AWS to automatically scale your cloud compute resources and parallelise your workload across multiple Dask worker nodes. In this example they show you how you can run an example notebook that performs sample analyses on the Coupled Model Intercomparison Project 6 (CMIP6) dataset from the Registry of Open Data on AWS. [hands on]
Apache Airflow
Dzenan Softic and Sam Dengler demonstrate how to use a CodeArtifact repository to load your Python libraries in Apache Airflow in the post, Amazon MWAA with AWS CodeArtifact for Python dependencies

Apache Flink
In this post, Optimizing Apache Flink on Amazon EKS using Amazon EC2 Spot Instances Kinnar Sen shows you how to deploy a scalable, highly available, resilient, and cost optimised Flink application using Kubernetes via Amazon EKS and Amazon EC2 Spot Instances. [hands on]

OpenSearch
If you have a use case where you need to be able to run a single query against many different data sources, then you will find this post from Behram Irani and Madhav Vishnubhatta will be of interest. Using a capability of Amazon Athena called Amazon Athena Federated Queries, you can use an existing connector for OpenSearch to query your data in both OpenSearch and (in this example) Amazon S3. To find out more, read the post Query data in Amazon OpenSearch Service using SQL from Amazon Athena [hands on]

RabbitMQ
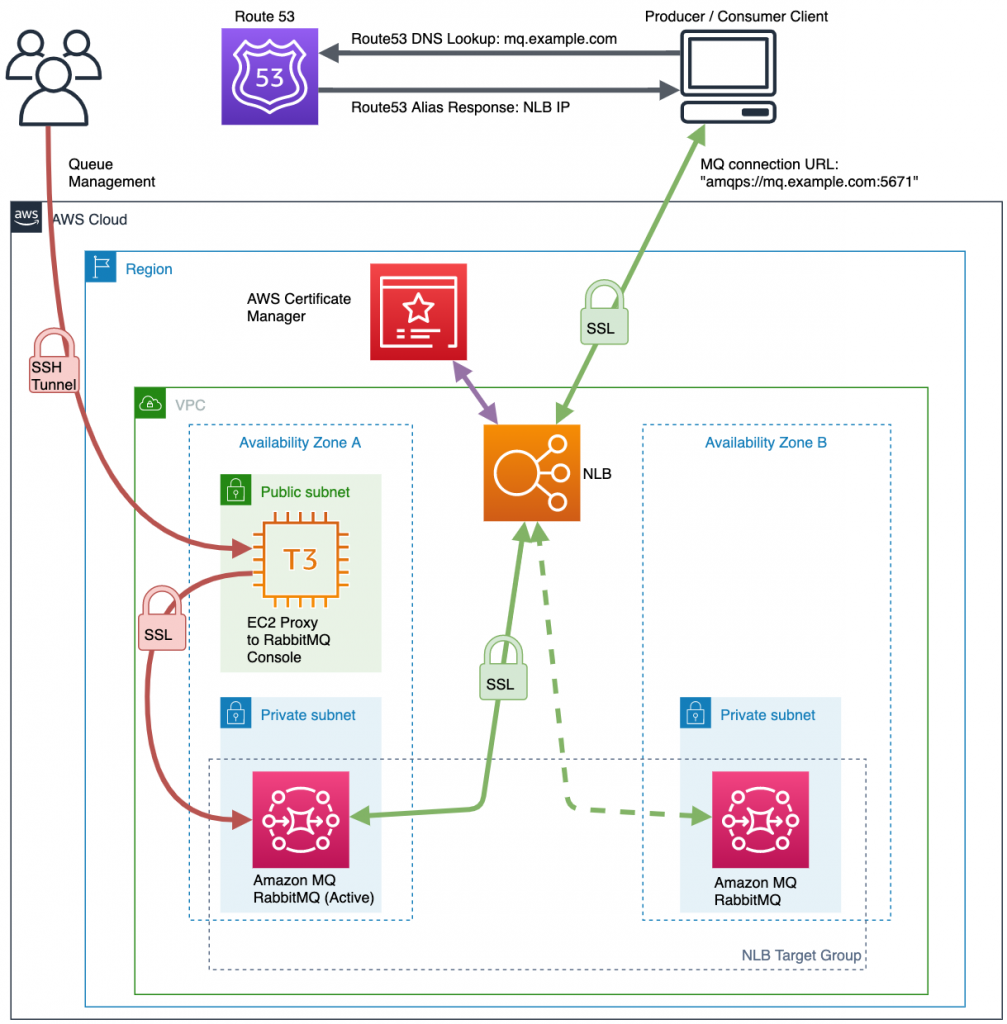
Amazon MQ provides two managed broker deployment connection options: public brokers and private brokers. Nate Bachmeier, Wallace Printz, and Christian Mueller have come together to share how to provision private Amazon MQ brokers behind a secure public load balancer endpoint using an example subdomain in the blog post, Creating static custom domain endpoints with Amazon MQ for RabbitMQ [hands on]
Redis
This post from Ramesh Sencha at Coupa, How Coupa migrated from a self-hosted Redis to fully managed Amazon ElastiCache details why Coupa migrated self managed Redis workloads to Amazon ElastiCache; the benefits, the approach and the architecture they chose.
Quick updates
Fluent Bit
Amazon Elastic Kubernetes Service (EKS) on Fargate now supports the use of Kubernetes Fluent Bit filters which provide enriched Kubernetes-specific metadata to Fluent Bit logs. Customers can now more easily observe and troubleshoot their applications by using the Kubernetes pod, container, or namespace name, among other Kubernetes metadata, to associate with their applications’ logs. Without support for the Kubernetes filter for Fluent Bit on EKS Fargate, customers had to manually read through log files to find the events they were interested in and it was difficult to associate a given log line with a Kubernetes application. Some customers who needed this kind of observability were unable to use Fargate with EKS and couldn’t benefit from its fully managed compute environment.
Video of the week
OpenSearch
In this recording from the AWS Summit, Kyle Davis will give you an understanding of the capabilities of OpenSearch, the first steps to get started (on or off AWS), a picture of how OpenSearch fits in your stack, a look into what’s in store for the future of the project as well as a guide to join the community and contribute.
{% youtube DPpbu5Jkkmc %}
Open source observability
Another great video from Dotan Horovits over at Logz.io. In this session he introduces observability, the role of open source in this area and then shows you some of the tools and projects in this space. Well worth 41 minutes of your time.
{% youtube McNAwoQtOfg %}
Events for your diary
Databricks | AWS Lakehouse Dev Day Live Workshop November 16th 9:00 AM PT
Delta Lake is an open source storage layer that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. You can use Delta Lake on top of your existing data lake. During this workshop you will learn how to:
- Make your existing Amazon S3 data lakes into a lakehouse with Delta Lake.
- Provide an easy-to-use platform for analysts to directly query data on your data lake using SQL Analytics
- Simplify and automate data pipelines for streaming and batch data to lower costs and boost productivity for your data teams
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen