AWS open source news and updates #85
October 11th, 2021 - Instalment #85
Newsletter #85.
This week we have an interesting gaming flavour to this newsletter, with a couple of projects that are influenced or are directly related to gaming. We also have other new open source projects including one that shows you how you can run an OpenVSCode Server for AWS Graviton2. This weeks blog post and tutorials cover Apache Airflow, Apache Spark, Apache Kafka, Apache Ranger, Apache Flink, OpenSearch, Apache Lucene, PostgreSQL, AWS CDK, and Kubernetes. For those interested in machine learning, we have a literal Feast for you, in a nice post covering the open source project Feast. We also have a great post for those of you looking who are applying the open source way of working, internally (sometimes referred to as Innersource) so make sure you check that post out as it is really nice. Finally we have some new events added, so check those out and a couple of videos that you will want to bookmark/view.
With KubeCon happening this week, make sure you check out the Container Day. These are always packed full of the latest updates and great presentations from the containers team at AWS.
Container Day x KubeCon
Next week, the AWS Kubernetes team is back for the next instalment of Container Day x KubeCon, a full day of sessions on Amazon EKS and Kubernetes at AWS. In this live and virtual Twitch event, the AWS Kubernetes team, hosted by developer advocates Justin Garrison and Jesse Butler, will be covering new launches, demoing products and features, and answering your questions. Read more in the post, Save the date: Container Day x KubeCon to find out about the sessions and you can sign up here to be reminded when things kick off.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Starr Shaw, John Kennedy, Nico Triballier, Michael Hamilton, Joe Losinski, Eng-Hwa Tan, Raffa aka Picster, Debashish Chakrabarty, Akash Verma, Ian Mckay, Naga Appani, Chinmayi Narasimhadevara, Uma Ramadoss, Willem Pienaar, Matt Asay, Marcus Eagan, Henry Robalino, Varun Rao Bhamidimarri, Jalpan Randeri, Virginia Chu, Hunter Tom, Om Prakash Jha and Michael Hausenblas
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
vscode-spoty-army
vscode-spoty-army Gitpod is a great open source project that helps you to tun upstream VS Code on a remote machine with access through a modern web browser from any device, anywhere, via the OpenVSCode Server project. This project from Eng-Hwa Tan will help you to deploy an OpenVSCode Server for AWS Graviton2 (arm64) with spot instance using Amazon ECS.
cloudkeeper-ckui cloudkeeper-ckui this project really impressed me last week and got me thinking should game designers be hired by all projects/organisations to help design their UI’s. Cloudkeeper is an open source project that indexes resources, captures dependencies and maps out your AWS infrastructure in a graph so that it’s understandable for a human. Raffa aka Picster shared news last week on Reddit about a new project he is working on, a UI for this project.
Planet_Storm
Planet_Storm from application of a games UI to an actual game. This project provides an example game called Planet Storm, that is imagined as a 3D, physics-based, side-scrolling platformer inspired by the 1980’s IREM classic “Moon Patrol”. It uses the Open 3D Engine (O3DE) engine and the developers behind this, Starr Shaw and John Kennedy, share how you can build this yourself in the blog post, We Also Make Games: AWS’ First Internal O3DE Game is Now Available!
aws-instance-scheduler
aws-instance-scheduler if you ever needed to schedule the stopping and starting of EC2 and RDS resources across your AWS accounts, then this project is what you have been looking for. This helps reduce operational costs by stopping resources that are not in use and starting resources when their capacity is needed. It provides a solution for Cross-Account and Cross-Region scheduling EC2 and RDS instances/clusters using SSM Automation Runbooks.

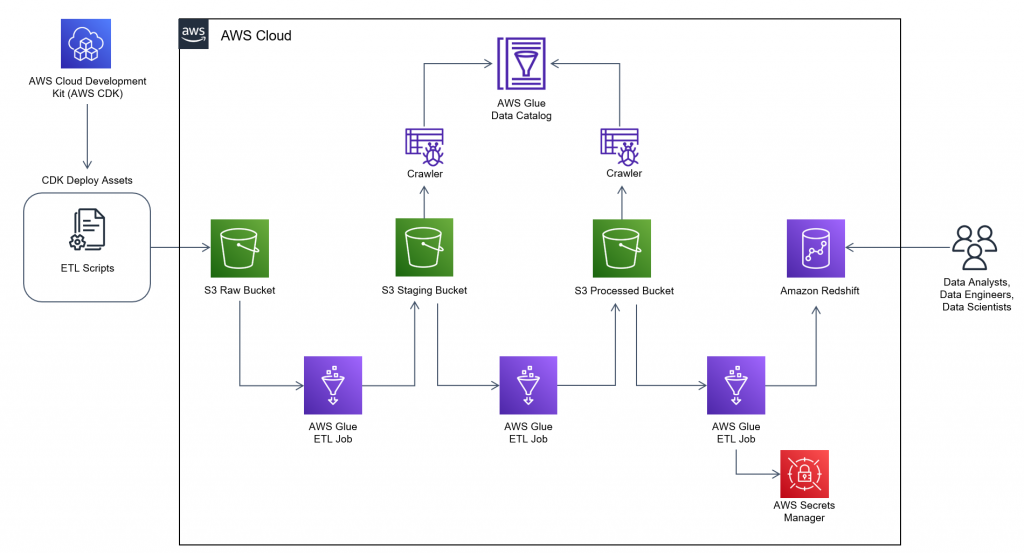
glue-workflow-aws-cdk
glue-workflow-aws-cdk this repository contains an example that creates a Glue Workflow containing multiple crawlers, glue jobs and triggers for the workflow. The workflow is manually triggered, but the script can be updated to run on a cron schedule.
Follow the blog post Field Notes: How to Build an AWS Glue Workflow using the AWS Cloud Development Kit from Michael Hamilton and Joe Losinski to get started.
AWS and Community blog posts
Kubernetes
Virginia Chu and Hunter Tom write in their post, Simplifying Kubernetes configurations using AWS Lambda how to create a multi-stage Dockerfile that uses eksctl, kubectl, and aws-auth. Why would you want to do that? This will help you manage your Amazon EKS clusters dynamically using a Lambda function rather than installing kubectl or eksctl on a local machine. Additionally, all container images are stored in a versioned format as infrastructure as code.
I also read this post from Okta, Secure Access to AWS EKS Clusters for Admins from Nico Triballier. In this tutorial, Nico shows you how you can use OpenID Connect (OIDC) to allow developers to securely access Amazon EKS clusters on AWS.
OpenSearch
AWS Hero and open sourcerer Ian Mckay put together this blog post, Migrating to OpenSearch with CloudFormation on how to migrate from an Elasticsearch domain to an OpenSearch domain. [hands on]
Apache Lucene
It was great to see this post from former colleague Matt Asay and Marcus Eagan from MongoDB, diving deep on how MongoDB Atlas uses Apache Lucene within Atlas Search. Read the post, How AWS and MongoDB collaborate to unlock the power of Apache Lucene

Innersource
InnerSource is the term for the emerging practice of organisations adopting the open source methodology and tools in order to build their applications. I was very excited to read Building an InnerSource ecosystem using AWS DevOps tools from Debashish Chakrabarty and Akash Verma. The post discusses how to build a model InnerSource ecosystem that leverages multiple AWS services, such as CodeBuild, CodeCommit, CodePipeline, CodeArtifact, and CodeGuru, along with other AWS services and open source tools such as the InnerSource Portal from SAP. The post provides a nice tool, the codecommit-crawler-innersource that provides a custom crawler for AWS CodeCommit that generates the repos.json that can be used by the SAP InnerSource Portal. [hands on]

Feast
Feast is an open source feature store and a fast, convenient way to serve machine learning (ML) features for training and online inference. Feast lets you build point-in-time correct training datasets from feature data, allows you to deploy a production-grade feature serving stack to AWS and simplifies tracking features models are using. Willem Pienaar, Principal Engineer at Tecton and creator of Feast created a post, Getting started with Feast, an open source feature store running on AWS Managed Services that does what it says on the tin - walks you through how you can use Feast using a real-time credit scoring example.

Apache Airflow
A couple of Apache Airflow posts this week (neither by me!), covering some cool topics that I often hear developers wanting to know how to do.
First up we have Uma Ramadoss who has put together this post, Automating a DAG deployment with Amazon Managed Workflows for Apache Airflow that goes beyond just creating a simple CI/CD pipeline for your workflows, and includes how you test them and then how you automate the deployment and updating of your MWAA environments. Super useful. [hands on]

To follow that, we have Henry Robalino who wrote Using Okta as an identity provider with Amazon MWAA which shows you how you can integrate an existing identity provider (in this instance, Okta) to authenticate via AWS SSO to your Amazon Managed Workflows for Apache Airflow (Amazon MWAA) environments. Very nice post indeed. [hands on]
Apache Flink/Apache Kafka
Chinmayi Narasimhadevara walks you through how to create stream processing applications using Apache Flink, in this hands on post, Query your Amazon MSK topics interactively using Amazon Kinesis Data Analytics Studio. Apache Flink is an open-source framework and engine for processing data streams, and in the post she walks you through creating some example applications to interact with streaming data from Apache Kafka in Scala, Python and SQL.
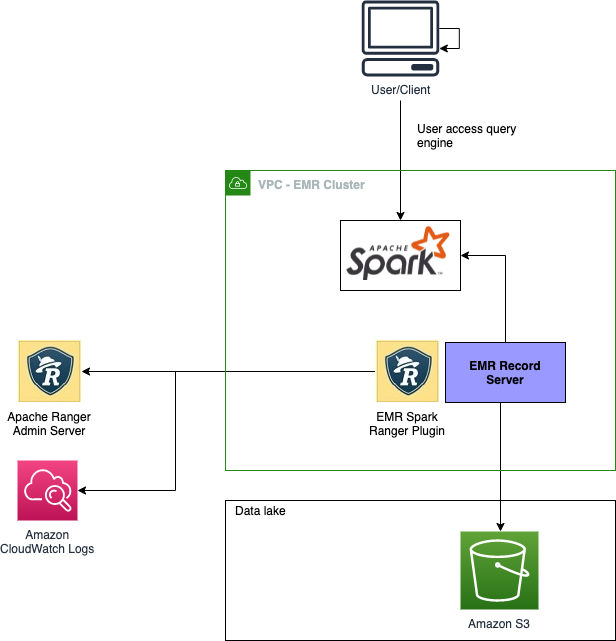
Apache Ranger
Apache Ranger is an open source project that provides security capabilities for Hadoop clusters, and in this post Authorize SparkSQL data manipulation on Amazon EMR using Apache Ranger from Varun Rao Bhamidimarri and Jalpan Randeri, you will learn more about how Amazon EMR 6.4 has introduced additional authorising capabilities for data manipulation statements with Apache Ranger 2.0.
PostgreSQL
Naga Appani has put together this post, Tune sorting operations in PostgreSQL with work_mem where he talks about how and where to identify queries that are suboptimal, such as ones that require sorting on disk, and how to use various optimisation techniques to improve performance. What is work_mem? Read the post to find out what it is and why it is important in how you optimise your queries.
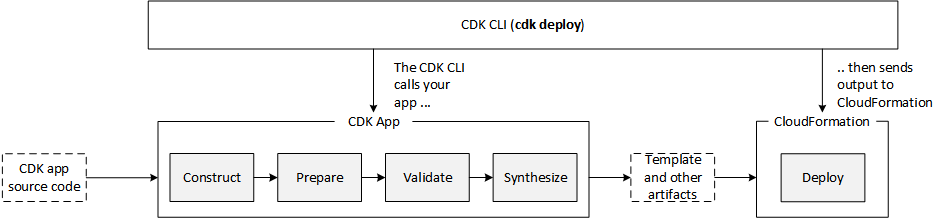
AWS CDK
Om Prakash Jha writes in his post, Align with best practices while creating infrastructure using CDK Aspects, how if you are utilising AWS CDK to provision your infrastructure, you can apply some best practices to not only to evaluate compliance of your resources against the best practices, but also modify their state to make them compliant before they are created.
Quick updates
Apache Spark
Amazon EMR now supports Apache Spark SQL to insert data into and update Apache Hive metadata tables when Apache Ranger integration is enabled. In January we launched Amazon EMR integration with Apache Ranger, a feature that allows you to define and enforce database, table, and column-level permissions when Apache Spark users access data in Amazon S3 through the Hive Metastore.
Previously, with Apache Ranger is enabled, you were limited to only being able to read data using Spark SQL statements such as SHOW DATABASES and DESCRIBE TABLE. Now, you can also insert data into, or update the Apache Hive metadata tables with these statements: INSERT INTO, INSERT OVERWRITE, and ALTER TABLE.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports PostGIS major version 3.1. This new version of PostGIS is available on PostgreSQL versions 13.4, 12.8, 11.13, 10.18, and higher.
PostGIS allows you to store, query and analyse geospatial data within a PostgreSQL database. PostGIS 3.1 significantly improves performance such as spatial joins, which now run up to 6.8X faster on PostgreSQL 13. As an example, you could use a spatial join to count the number of people living in an area defined by the reception of mobile phones from radio towers.
PostGIS 3.1 is the new default version on PostgreSQL 10 and higher starting with the new minor versions. However, you can still create older versions of PostGIS in your PostgreSQL database, e.g., if you require version stability.
Ubuntu
Amazon EC2 now supports Hibernation for Ubuntu 20.04 LTS operating system. Hibernation allows you to pause your EC2 Instances and resume them at a later time, rather than fully terminating and restarting them. Resuming your instance lets your applications continue from where they left off so that you don’t have to restart your OS and application from scratch. Hibernation is useful for cases where rebuilding application state is time-consuming (e.g., developer desktops) or an application’s start-up steps can be prepared in advance of a scale-out.
For Ubuntu 20.04 LTS, Hibernation is supported for On-Demand Instances running on C3, C4, C5, C5d, I3, M3, M4, M5, M5a, M5ad, M5d, R3, R4, R5, R5a, R5ad, R5d, T2, T3, and T3a with up to 150 GB of RAM.
Video of the week
This week we have Michael Hausenblas' session at the Swiss Cloud Native Day, where he gave this session How open source made observability mainstream.
{% youtube kZci80ksfAM %}
Following that we have this recorded workshop from Provectus, Amazon SageMaker and Open-Source Tools for ML: Better Together.
{% youtube 0EnJyyV10sU %}
Workshops
Hadoop on Kubernetes
If you have not seen or worked through this workshop, EMR on EKS Workshop then it provides a nice entry point into running some of the open source analytics tools such as Apache Spark on Kubernetes.
Events for your diary
Coming up later this week we have…
Container Day x KubeCon October 12th, 8:00 AM – 4:00 PM (PDT)
The AWS Kubernetes team is back for the next instillment of Container Day x KubeCon, a full day of sessions on Amazon EKS and Kubernetes at AWS. In this live and virtual Twitch event, the AWS Kubernetes team, hosted by developer advocates Justin Garrison and Jesse Butler, will be covering new launches, demoing products and features, and answering your questions.
GraphQL API security best practices with AWS AppSync and AWS Amplify 14th October, 11am AEST
As a developer, the most important parts of managing your applications should always include enhancing performance while strengthening security. In this webinar, we take you through security best practices for your GraphQL API’s with AWS AppSync and AWS Amplify, providing you with an understanding of how these can be applied to your applications. In this session, you will learn about:
- GraphQL Protocol and how to configure a schema
- Possible ways to authenticate and authorise access to GraphQL APIs
- How to configure network security for your API
- How to enable observability for your API with logging, tracing or auditing
Flink Forwards Global 2021 October 26th/27th
Flink Forward Global 2021 is a 2-day virtual conference for the Apache Flink and stream processing communities. Apache Flink is an open-source distributed engine for processing data streams that can support both streaming and batch workloads. Flink Forward has keynote presentations and talks on production Flink use cases, technical deep dive sessions, and the growth of the Flink ecosystem. You can meet core Flink committers, new and experienced users, and thought leaders who share experiences and best practices in stream processing, real-time analytics, and the management of mission-critical Flink deployments in production.
Databricks | AWS Lakehouse Dev Day Live Workshop November 16th 9:00 AM PT
Delta Lake is an open source storage layer that provides ACID transactions, scalable metadata handling, and unifies streaming and batch data processing. You can use Delta Lake on top of your existing data lake. During this workshop you will learn how to:
- Make your existing Amazon S3 data lakes into a lakehouse with Delta Lake.
- Provide an easy-to-use platform for analysts to directly query data on your data lake using SQL Analytics
- Simplify and automate data pipelines for streaming and batch data to lower costs and boost productivity for your data teams
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen