AWS open source news and updates #81
September 13th, 2021 - Instalment #81
Updated 18th Jan, remove dead links
Newsletter #81.
Welcome new and existing readers of this newsletter to another edition with plenty to excite you. This weeks brand new open source projects include some great new AWS CDK constructs to help you with things such as Apache Airflow, a tool to help you with your IAM policies, a really nice tool to explore and interact with AWS SQS and something for Minecraft fans. If that was not enough, the AWS and community blog posts cover all the news from last weeks GA for EKS Anywhere and other Kubernetes related articles. For those interested in the topic of big data, we have a bumper lot of content including posts covering Apache Airflow, Apache Spark, Apache Kafka, PartiQL, Apache Nifi and more. On top of that we have posts covering AWS CDK, open source file systems, the announcement last week of the latest HPC open source tool from AWS and more. There are also a few new events in the Events section, so check those out and put them in your diary.
Job of the week
*Principal Developer Advocate - Java Specialist
In case you missed this last week, we have a new opening in my team for anyone in the Cambridge/Boston area in the US. As a Principal Developer Advocate in the AWS Developer Relations organisation, you will work to earn trust with Enterprise developers and the broader Java community through your technical leadership and expertise. This is a high-impact role that’s well-suited to someone with domain-specific technical experience that enjoys sharing what they have learned in order to help users solve their technical issues and overcome any challenges they face. You will have the ability to influence and educate customers at every stage of their experience with technologies such as OpenJDK, Serverless, Containers, DevOps tools and more.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Harinder Seera, Roshani Nagmote, Aditya Bindal, Khaled ElGalaind, Rajesh Parangi Sharabhalingappa, Nicolas Weil, Nagesh Subrahmanyam, Arun A K, Hari Rongali, Wayne R. Vincent, Swapna Chawhan, Justin Garrison, Channy Yun, Frank Munz, Ali Spittel, Matt Coles, Yihui Han, Ray Gibson, Pahud Hsieh, Shakeel Ahmad, Evgeny Vaganov, Darius Januskis, Keerti Shah, Ray Zaman, David Desroches, Ameer Hakme, Brandon Rubadou, Ravi Menon, and John O’Donnell.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
serverless-airflow
serverless-airflow two of my favourite things combined in this open source project, an AWS CDK construct that provisions AWS resources to build an Apache Airflow environment. You can use Python or Typescript. Nice job Yihui Han.

minecraft-ondemand
minecraft-ondemand Ray Gibson’s open sourced project that helps you provision resources on AWS to deploy Minecraft servers frugally will delight lots of you. Clean and easy to follow docs, together with some cost estimates provide everything you need to get going. Where was this at the beginning of the lockdown :-)
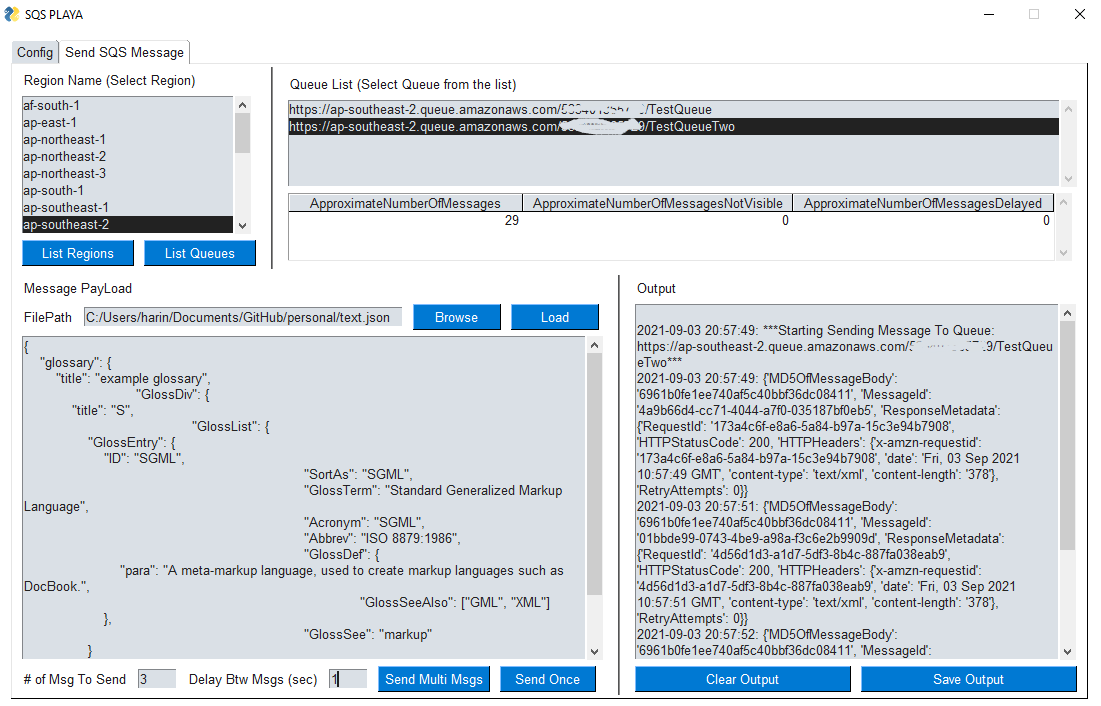
sqs-workbench
sqs-workbench this is a fantastic tool from AWS Community Builder Harinder Seera, that helps you easily explore AWS SQS through this gui based interface. What is more, you can see how to get started by reading his post, AWS SQS Workbench - A Simple & Non-Technical Tool To Interact With AWS SQS.
AWSXenos
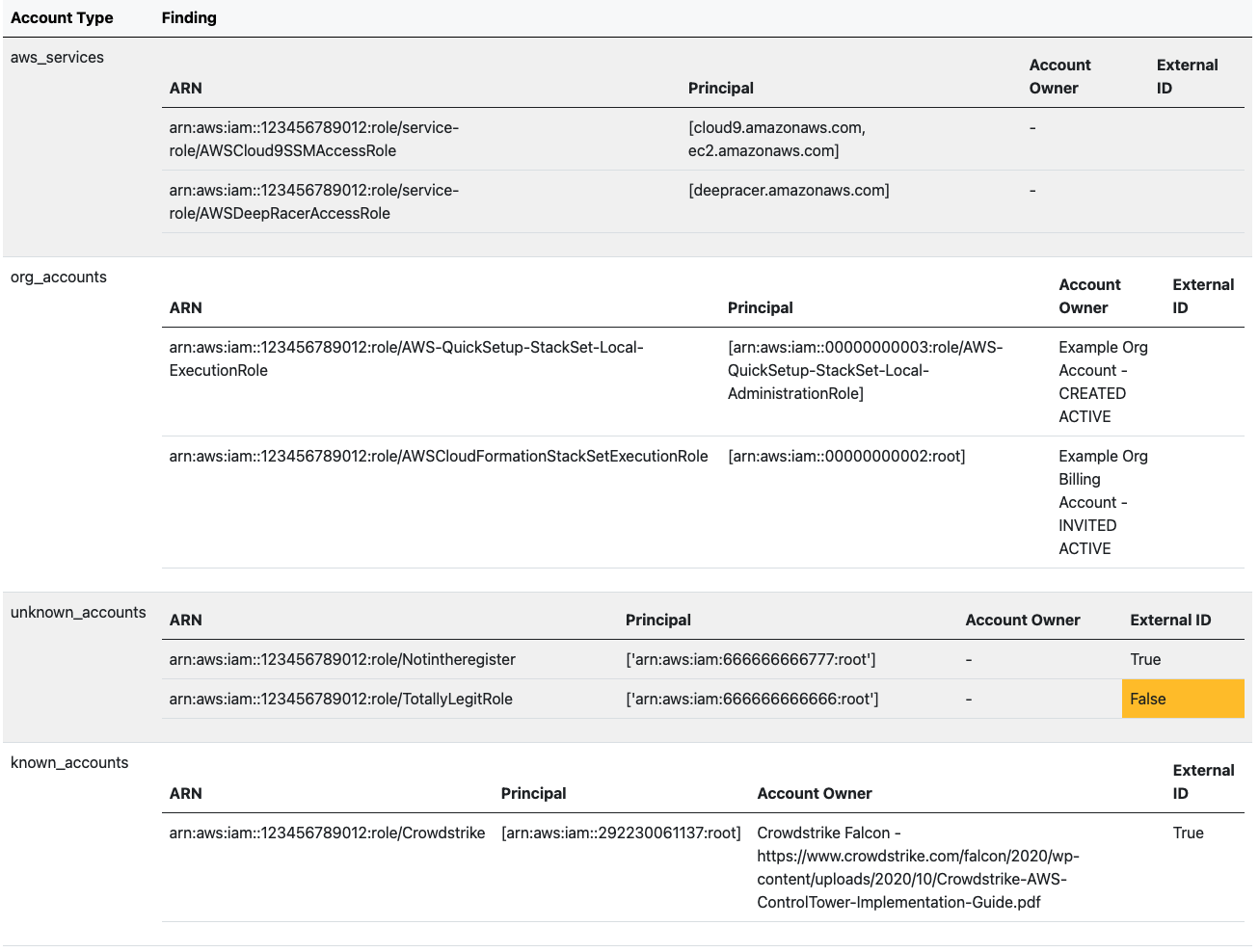
AWSXenos if you are looking for open source tools to help you understand and then tighten up your IAM policies and permissions, then check this tool out from AirWalk. AWSXenos will list all the trust relationships in all the IAM roles, and S3 buckets, in an AWS account and give you a breakdown of all the accounts that have trust relationships to your account. If you are thinking that AWS Access Analyser does this, then you are no wrong, however, they have put together some reasons why this project might help you address additional features not available in Access Analyser.
cdktf-aws-eks
cdktf-aws-eks Pahud Hsieh has put together another CDK construct, this time providing an cdktf construct library for Amazon EKS.
eks-anywhere
eks-anywhere Amazon EKS Anywhere is a new deployment option for Amazon EKS that enables you to easily create and operate Kubernetes clusters on-premises with your own virtual machines. Read more about this below, but this is the project home page.
AWS CDK - RFC
RFC for CDK Have your say in this Request for Comment (RFC) in the AWS CDK GitHub project page. This is a request for comments about Integration testing for CDK apps. Read about the current proposal, the discussion in the commands and then share your thoughts.
AWS and Community blog posts
Kubernetes
Last week, we announced the general availability of a new deployment option for Amazon Elastic Kubernetes Service (Amazon EKS) called Amazon EKS Anywhere.
In the officinal announcement post, Amazon EKS Anywhere – Now Generally Available to Create and Manage Kubernetes Clusters on Premises, Channy Yun takes a closer look at what this means, compares this offering against other choices customers have for running their Kubernetes clusters, provides a quick start and some things you will find helpful to know around the security model, support and more. [hands on]
We also had Justin Garrison put together Getting started with Amazon EKS Anywhere which will take you through how to get your first Amazon EKS Anywhere Kubernetes cluster running on your local machine. [hands on]

I believe Justin will be streaming live about Amazon EKS Anywhere in more detail later today, so head on over to the Containers from the Couch You Tube channel.
Rancher is a popular open-source container management tool utilized by many organizations that provides an intuitive user interface for managing and deploying the Kubernetes clusters on Amazon Elastic Kubernetes Service (Amazon EKS) or Amazon Elastic Compute Cloud (Amazon EC2). This post Collect, Aaggregate, and analyze Rancher Kubernetes Cluster logs with Amazon CloudWatch from Darius Januskis and Keerti Shah demonstrates how to send logs from your Rancher Kubernetes environment on Amazon EC2 to Amazon CloudWatch Logs. [hands on]

To finish up the Kubernetes updates this week, we have Nagesh Subrahmanyam who writes, Implementing the Saga Orchestration pattern with Amazon EKS and Amazon SNS described the Saga Orchestration pattern for coordinating. This was new to me, Saga patterns are used to bring multiple microservices together for concluding an end-to-end business process. The Saga patterns can be applied for all business processes that span across multiple microservices. In this particular post, he looks at Orders, Orders Rollback, and Inventory microservices with Amazon SNS passing messages between microservices. This pattern can be applied in digital transformation projects where features are implemented as microservices. Source code repository is linked to so you can try this out for yourself. [hands on]

AWS Amplify
Another great post last week was Ali Spittel’s 10 New AWS Amplify Features to Check Out which is a must read to keep up with the new features you have available to you when using AWS Amplify. From Next.js support, Apple pay integration, cool stuff if you need to work with location or maps, make sure you check out these cool new capabilities.
AWS CDK
Reference and import existing assets into AWS CDK Matt Coles has put together this excellent resource and guide for anyone who is building CDK applications to deploy their cloud infrastructure, and wants to reference or import existing resources. The post covers most of the use cases you might expect to come across (some of which I have had to figure out, so this post would have saved me quite a bit of time/effort). [hands on]
Apache Spark
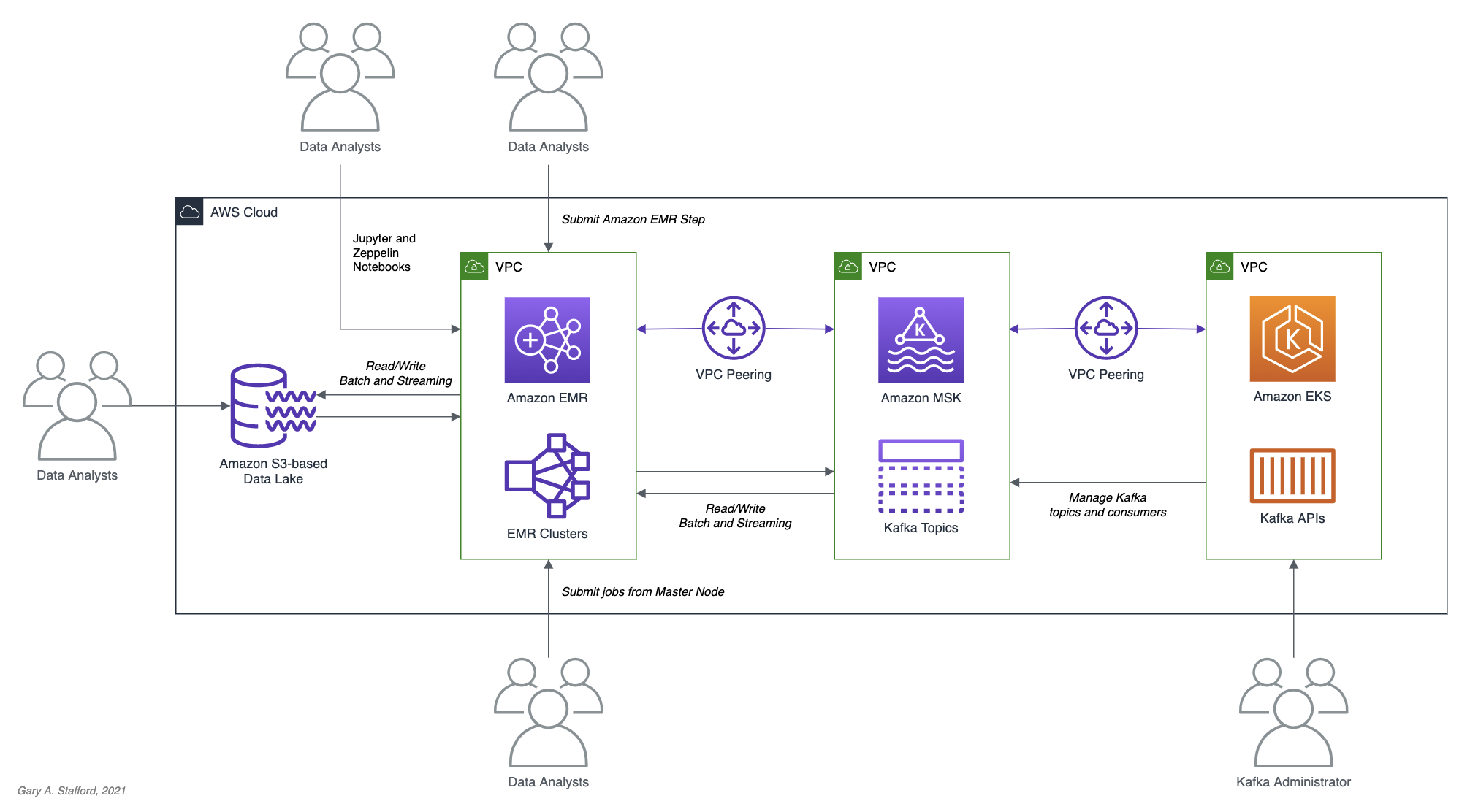
Posts from Gary Stafford are always something to look forward to, so grab a cup of your favourite beverage and take in his latest post, Getting Started with Spark Structured Streaming and Kafka on AWS using Amazon MSK and Amazon EMR. Following on from a previous post which I shared in this newsletter, in this post Gary’s shows how to use Apache Spark and Spark Structured Streaming with Apache Kafka. [hands on]
Apache Kafka
Brandon Rubadou, Ravi Menon, and John O’Donnell have collaborated on this post, Hybrid Cloud Architectures Using Self-hosted Apache Kafka and AWS Glue. In it they share an architecture that provides hybrid cloud data integration and analytics capability, leveraging AWS services along with Apache Kafka that ensures that your on-premises workloads are tightly integrated with your larger data lake solution.

Apache Airflow
I try and spend as much time as I can lurking in the Apache Airflow slack channels, a great source of inspiration. As part of some stuff I worked on to help a customer, I wrote how to use Amazon Managed Workflows for Apache Airflow (MWAA) when wanting to read/write data across different AWS accounts. Check out the whole post in Reading and writing data across different AWS accounts with Amazon Managed Workflows for Apache Airflow v2.x
Delta Sharing
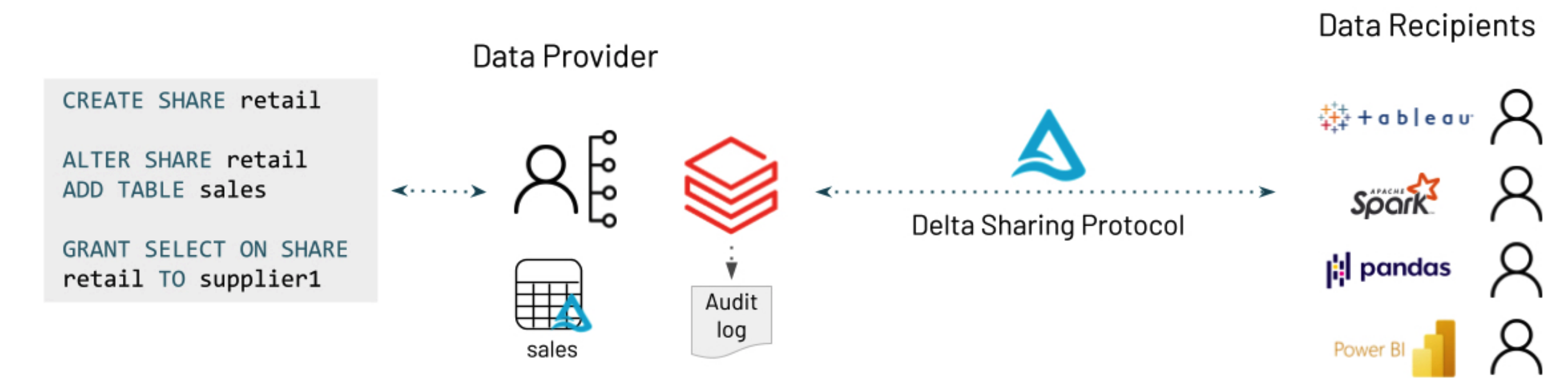
I love reading about new open source projects, and last week it was delta sharing, an open protocol for secure data sharing. A former colleague Frank Munz (DevRel over at Databricks) put together a great walk through on how to use this project. Find out more by reading his blog post, Share Large Amounts of Live Data With Delta Sharing and Docker [hands on]
Apache NiFi
Apache NiFi is a very cool open-source site-to-site data transfer tool that abstracts writing code by providing a simple drag-and-drop interface of predefined processor modules, which you can use to connect a variety of data sources and targets and perform lightweight data transformations. In this post, Stream time series data into Amazon Timestream using Apache NiFi, Arun A K, Hari Rongali, and Wayne R. Vincent discuss how Apache NiFi users can ingest time series data into Timestream without explicitly writing code. [hands on]

PartiQL
PartiQL is a SQL-compatible query language that makes it easy to efficiently query data, regardless of where or in what format it’s stored. In the post A PartiQL deep dive: Understand the language and bring SQL queries to AWS non-relational database services, Swapna Chawhan explains some of the important PartiQL features and basics so you can effectively use the language to explore databases that require PartiQL knowledge. Unlike traditional SQL, the PartiQL query language also meets the needs of NoSQL and non-relational databases. PartiQL is fully open sourced under the Apache2.0 license and the open-source implementation provides an interactive shell that allows you to write and evaluate PartiQL queries.

PyTorch
Amazon S3 plugin for PyTorch is an open-source library which is built to be used with the deep learning framework PyTorch for streaming data from Amazon Simple Storage Service (Amazon S3). With this feature available in PyTorch Deep Learning Containers, you can take advantage of using data from S3 buckets directly with PyTorch dataset and dataloader APIs without needing to download it first on local storage. To see how this works, Roshani Nagmote, Aditya Bindal, Khaled ElGalaind, and Rajesh Parangi Sharabhalingappa have put together Announcing the Amazon S3 plugin for PyTorch which will walk you through a couple of examples. [hands on]
SPEKE
Secure Packager and Encoder Key Exchange (SPEKE) defines the standard for communication between encryptors and packagers or encoders of media content and digital rights management (DRM) key providers. The SPEKE Reference Server is an implementation of the SPEKE API and minimal implementation of back-end software to generate AES keys for an encoder or packager. The Reference Server has been donated to open source by Amazon and is available from GitHub for installation, use and customisation. Nicolas Weil shares the latest updates in this specification (SPEKE v2) in the post, Improve streaming content security with SPEKE v2.0 and AWS Elemental MediaPackage

AWS ParallelCluster
Brendan Bouffler and Rye Robinson introduced an important announcement for AWS ParallCluster users last week. In New: Introducing AWS ParallelCluster 3 dives into the key features of the new release, including enhancements to the API, integration with EC2 Imagebuilder, the new configuration file format, simpler network configuration, fine grain IAM permissions and more.
BeeGFS
In Enabling parallel file systems in the cloud with Amazon EC2 (Part I: BeeGFS) Ray Zaman, David Desroches, and Ameer Hakme show you how to deploy the popular open source parallel file system, BeeGFS, using AWS D3en and I3en EC2 instances. [hands on]

Quick updates
OpenSearch
There are a few quick updates this week from the ever increasingly active OpenSearch community.
- Amazon Elasticsearch Service has a new name: Amazon OpenSearch Service. This change, which was previously announced here, coincides with the addition of support for OpenSearch 1.0. You can now run and scale both OpenSearch and Elasticsearch (until version 7.10) clusters on Amazon OpenSearch Service and get all of the same benefits you have enjoyed so far from Amazon Elasticsearch Service. Read more in the announcement, Amazon Elasticsearch Service is now Amazon OpenSearch Service; adds support for OpenSearch 1.0
- Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) now supports index transforms that enables customers to extract significant information from large data sets and store summarised views in new indices. Customers can derive new insights, further analyse, and visualise trends from the new summary index. Index transforms are similar to “materialized views” in databases and provide an interactive way to aggregate and store summarised views from large data sets so that you can visualise and analyse the data more easily. For example, you can summarise the annual sales index with multiple fields using transforms to organise the data by region, quarter, and then revenue. Using OpenSearch Dashboards or the transforms API, customers can schedule and run index transforms jobs to create the summarised indices for analysing trends and patterns. Read more in the announcement, Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) now supports Index Transforms
- Amazon OpenSearch Service now supports OpenSearch Dashboards Notebooks, a new feature that enables OpenSearch users to interactively and collaboratively develop rich reports backed by live data and queries. A notebook is a document made up of cells or paragraphs that can combine markdown, SQL and Piped Processing Language (PPL) queries, and visualizations with support for multi-timelines so that users can easily tell a story. Notebooks can be developed, shared as an OpenSearch Dashboards link, PDF or PNG, and refreshed directly from OpenSearch Dashboards to foster data driven exploration and collaboration among OpenSearch users and their stakeholders. Common use cases for notebooks includes creating postmortem reports, designing run books, building live infrastructure reports, or even documentation. Read more in, OpenSearch Dashboards Notebooks, a new visual reporting feature, now available on Amazon OpenSearch Service (successor to Amazon Elasticsearch Service)
Suricata
Suricata is an open source threat detection engine that provides capabilities including intrusion detection, intrusion prevention and network security monitoring. AWS Network Firewall uses Suricata to provide network protections for all of your Amazon Virtual Private Clouds (VPCs). AWS Network Firewall is now a HIPAA eligible service. This means you can use AWS Network Firewall to secure and inspect protected health information (PHI) stored in your accounts. If you have a HIPAA Business Associate Addendum (BAA) in place with AWS, you can now start using AWS Network Firewall for your HIPAA-regulated workloads.
Also, incase you missed it, there was a new blog post last week covering some additional deployment options and use cases you might have. Check out the post from Shakeel Ahmad and Evgeny Vaganov Deployment models for AWS Network Firewall with VPC routing enhancements
RabbitMQ
You can now launch RabbitMQ 3.8.22 brokers on Amazon MQ. This release includes a fix for an issue with queues using per-message TTL (time to live), identified in the previously supported version, RabbitMQ 3.8.17, and we recommend upgrading to RabbitMQ 3.8.22.
Linux
Amazon EC2 now supports Hibernation for On-Demand Nitro-based instances running Red Hat Enterprise Linux (RHEL) version 8, CentOS version 8, and Fedora version 34 onwards. Hibernation allows you to pause your EC2 Instances and resume them at a later time, rather than fully terminating and restarting them. Resuming your instance lets your applications continue from where they left off so that you don’t have to restart your OS and application from scratch. Hibernation is useful for cases where rebuilding application state is time-consuming (e.g., developer desktops) or an application’s start-up steps can be prepared in advance of a scale-out. For RHEL version 8, CentOS version 8, and Fedora version 34 onwards, Hibernation is supported for On-Demand Instances running on Nitro-based instances (C5, C5d, M5, M5a, M5ad, M5d, R5, R5a, R5ad, R5d, T3, and T3a) with up to 150 GB of RAM.
AWS CDK
During August, 2021, 4 new versions of the AWS Cloud Development Kit (CDK) for JavaScript, TypeScript, Java, Python, .NET and Go were released (v1.117.0 through v1.120.0). These releases include multiple additions to the Kinesis Firehose Construct Library, including compression and prefixes on S3 delivery stream destinations, delivery stream metrics, S3 source backups, AWS Lambda-based data processors and more. Additionally, CloudFront Construct Library now supports Origin Shield, CloudWatch supports defining alarms across AWS accounts, and Cognito User Pools support Device Tracking. These releases resolve 28 issues and introduce 37 new features that span 30 different modules across the library. Many of these changes were contributed by the developer community. Read more in AWS CDK releases v1.117.0 - v1.120.0
Events for your diary
Data in Motion: Combining the strengths of AWS and Confluent September 22nd, 11am MDT
In this webinar, Big Compass, Confluent, and AWS will come together to explore the strengths of Confluent and AWS, and how each technology can complement one another for various use cases. The webinar covers ways to combine AWS and Confluent in a hybrid platform, how to build your serverless applications with AWS and Confluent, and a look at real-world use cases for AWS and Confluent.
Cloud Native Day 23rd September, Bern Switzerland
What is this, an in person event returning? A stellar line up including our own Michael Hausenblas, an event looking at CNCF projects and the future of IT. Find out more and to view prices/register, by clicking here.
GraphQL API security best practices with AWS AppSync and AWS Amplify 14th October, 11am AEST
As a developer, the most important parts of managing your applications should always include enhancing performance while strengthening security. In this webinar, we take you through security best practices for your GraphQL API’s with AWS AppSync and AWS Amplify, providing you with an understanding of how these can be applied to your applications. In this session, you will learn about:
- GraphQL Protocol and how to configure a schema
- Possible ways to authenticate and authorise access to GraphQL APIs
- How to configure network security for your API
- How to enable observability for your API with logging, tracing or auditing
Flink Forwards Global 2021 October 26th/27th
Flink Forward Global 2021 is a 2-day virtual conference for the Apache Flink and stream processing communities. Apache Flink is an open-source distributed engine for processing data streams that can support both streaming and batch workloads. Flink Forward has keynote presentations and talks on production Flink use cases, technical deep dive sessions, and the growth of the Flink ecosystem. You can meet core Flink committers, new and experienced users, and thought leaders who share experiences and best practices in stream processing, real-time analytics, and the management of mission-critical Flink deployments in production.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen