AWS open source news and updates #78
August 2nd, 2021 - Instalment #78
Newsletter #78.
This is the last newsletter for the next three weeks, as I will be taking some time off and shutting down my laptop. I will look forward to bringing you a very full edition when I return, but in the meantime enjoy another great collection of open source projects and blog posts to help you get the most out of open source on AWS. This week we have a collection of posts on Apache Airflow, a must read post for AWS CDK users on the Construct Hub Preview, some great posts covering analytics and big data technologies such as Apache Spark and Apache Kafka, a look at some new capabilities within AWS services such as openCypher and a round up of quick updates and case studies to finish off.
Enjoy the updates, and see you in a few weeks time.
Book: Spring Boot on AWS
Over the weekend Tom Hombergs, Philip Riecks and Björn Wilmsmann held an online launch party for their book Stratospheric: From zero to production with Spring Boot and AWS. This is an essential resource for any Java developer who is working with AWS.
Celebrating open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following open source heroes: Sofian Hamiti, Jenna Pederson, Sebastien Stormacq, Dotan Horovits, Alex Pulver, Ravi Itha, Muhammad Zahid Ali, César Prieto Ballester, Bruno Bardelli, Tom McMeekin, Parnab Basak, Brad Bebee, Mark Richman, Mikhail Vasilyev, Rob Mesirow, Anil Lalwani, David Sapin, Mihir Desai, Maciej Radzikowski, Trivikram Kamat, Steve Roberts, Biroj Nayak, Jessica Ho, Justin Leto, David Ehrlich, and Shreyas Subramanian
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest open source projects
metabadger
metabadger this open source tool from Salesforce helps you to prevent SSRF attacks on AWS EC2 via automated upgrades to the more secure Instance Metadata Service v2 (IMDSv2). The project provides detailed documentation on the background and use cases that this tool is looking to help, how to setup and install as well as how to run this project.

cdk-ipv6
cdk-ipv6 - my colleague Sebastien Stormacq released this open source project over the weekend that will help you create IPv6 VPCs
aws-cdk-pipelines-datalake-infrastructure
aws-cdk-pipelines-datalake-infrastructure - this is an open sourced solution to help you build a data lake on AWS. To help you get started, Ravi Itha and Muhammad Zahid Ali have written this blog post, Deploy data lake ETL jobs using CDK Pipelines that should make your life a little easier.
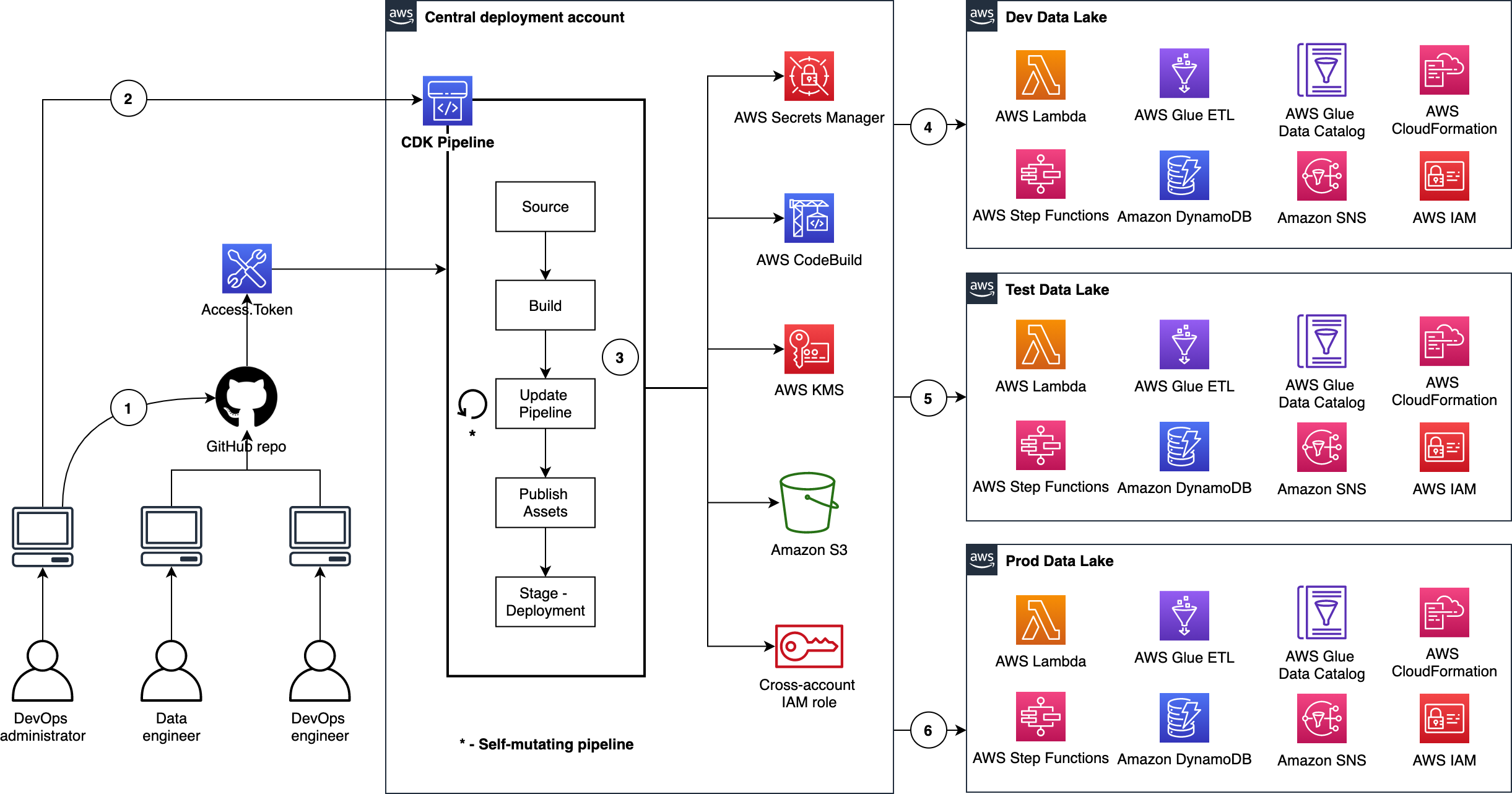
aws-cdk-tfsec
aws-cdk-tfsec - this is an open source project that shows you how you can analyse and secure Terraform code using a CI/CD Pipeline and tfsec. This blog post, Secure and analyse your Terraform code using AWS CodeCommit, AWS CodePipeline, AWS CodeBuild and tfsec from César Prieto Ballester and Bruno Bardelli walks you through the code. tfsec is an open sourced static analysis security scanner for your Terraform code, including more than 90 preconfigured checks with the ability to add custom checks.
mwaa-dashboard
mwaa-dashboard is an open source project that helps you automate Amazon CloudWatch dashboards and alarms for your Amazon Managed Workflows for Apache Airflow (MWAA) environments. Mark Richman provides everything you need to help you get this project up and running in his blog post, Automating Amazon CloudWatch dashboards and alarms for Amazon Managed Workflows for Apache Airflow which is a super nice post (I am using this to monitor my own test/development pipelines, and has really helped simplify this task)
aws-cdk-codecommit-snyk
aws-cdk-codecommit-snyk this open source project provides a CDK construct that uses Snyk CLI to scan Python packages for open source package vulnerabilities. BK Das provides detailed information on the architecture as well as how to get started in his post, Use the Snyk CLI to scan Python packages using AWS CodeCommit, AWS CodePipeline, and AWS CodeBuild
AWS and Community blog posts
https://logz.io/learn/guides/opentelemetry-guide/
Apache Airflow
We have a number of posts this week featuring Apache Airflow, or more specifically, Amazon’s Managed Workflows for Apache Airflow (MWAA).
First up we have Parnab Basak with Deploying to Amazon Managed Workflows for Apache Airflow with CI/CD tools which will show you how you can set up a simple CI/CD system to automate how you can deploy your DAGs into MWAA. He covers how you can do this using CodeCommit/CodePipeline, GitHub/GitHub actions, Jenkins and Bitbucket/Bitbucket Pipelines.
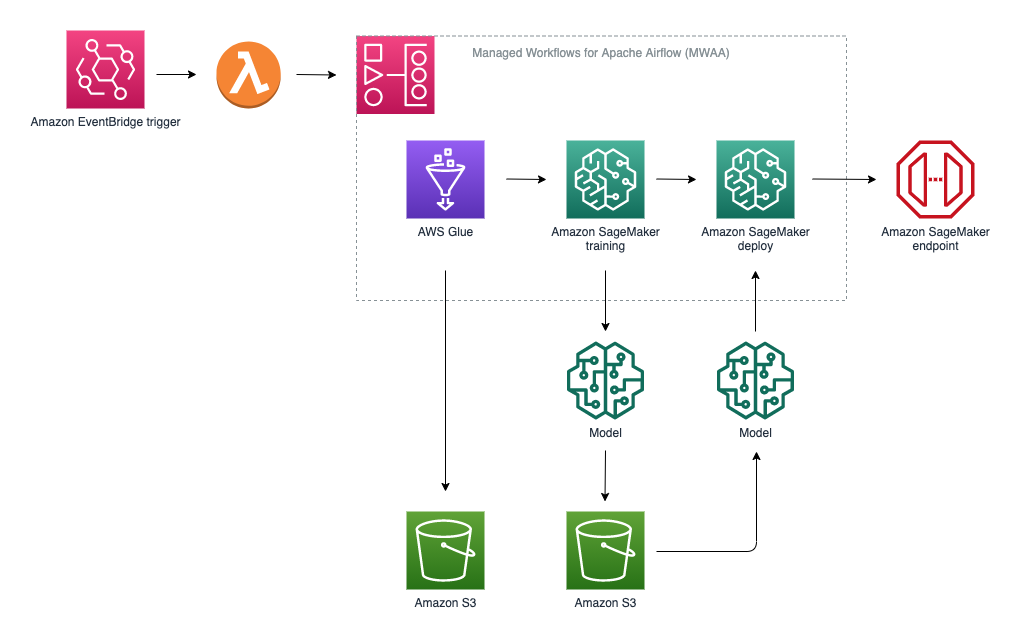
Next up, we have Justin Leto, David Ehrlich, and Shreyas Subramanian show you how to orchestrate an ML pipeline using the popular XGBoost (eXtreme Gradient Boosting) algorithm in the post, Orchestrate XGBoost ML Pipelines with Amazon Managed Workflows for Apache Airflow. They cover how to dynamically create and run AWS Glue jobs to preprocess training and validation data. How to construct the DAG to support ML pipelines, including the import statements, the DAG operator configuration, the DAG task definitions, and the DAG dependency definition. Finally, they show the difference between using native Airflow operators vs. invoking AWS SDK API calls from a generic PythonOperator. [hands on]
Lastly, I have a post written by myself, Working with parameters and variables in Amazon Managed Workflows for Apache Airflow which is a long read with examples, scripts and code that will dive deep into how you can work with parameters and variables within MWAA, what you need to be aware of that is perhaps different to self hosted Apache Airflow and how you can put this all together to create re-usable workflows. [hands on]
Apache Kafka
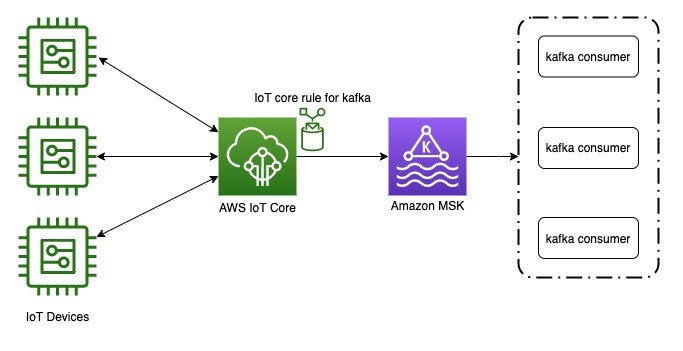
If you are looking to use Apache Kafka to help you ingest and process high-volume high-frequency streaming data (in this particular example, IoT data), then this is a post you will want to check out. Siddhesh Keluskar has put this detailed post, Field Notes: Deliver Messages Using an IoT Rule Action to Amazon Managed Streaming for Apache Kafka which will show you how you can build a real-time streaming data pipeline by securely delivering MQTT messages to a highly-scalable, durable, and reliable system using Apache Kafka. [hands on]
Apache Spark
What would we ever do if the taxi drivers of NYC stopped working and stopped providing the rich data sets that we use week in, week out to show case how to use data analytics tools? I am not sure, but whilst they are still generating all that great data, we can be thankful that this helps put together blog posts like this one, Visualize data using Apache Spark running on Amazon EMR with Amazon QuickSight from Tom McMeekin. This a really nice in depth post that covers a lot more than the title suggest. You will explore how to setup and use Apache Spark on Amazon EMR, openLDAP, deploy a Thrift server, use Beeline as your jdbc client and many more great open source tools. Well worth diving deep into. [hands on]

AWS Cloud Development Kit (AWS CDK)
Last week Alex Pulver put together this post, Construct Hub Preview, that announced the Construct Hub preview. This is a one-stop destination for finding, reusing and sharing constructs authored by AWS, AWS Partner Network partners, third parties, and the developer community. As the CDK developer community has grown, customers have told us that they do not have an easy way to find the construct libraries created by the community because the constructs have been published through various package managers. The Construct Hub will now be a central location where CDK users can find a comprehensive collection of constructs to help them build their applications.
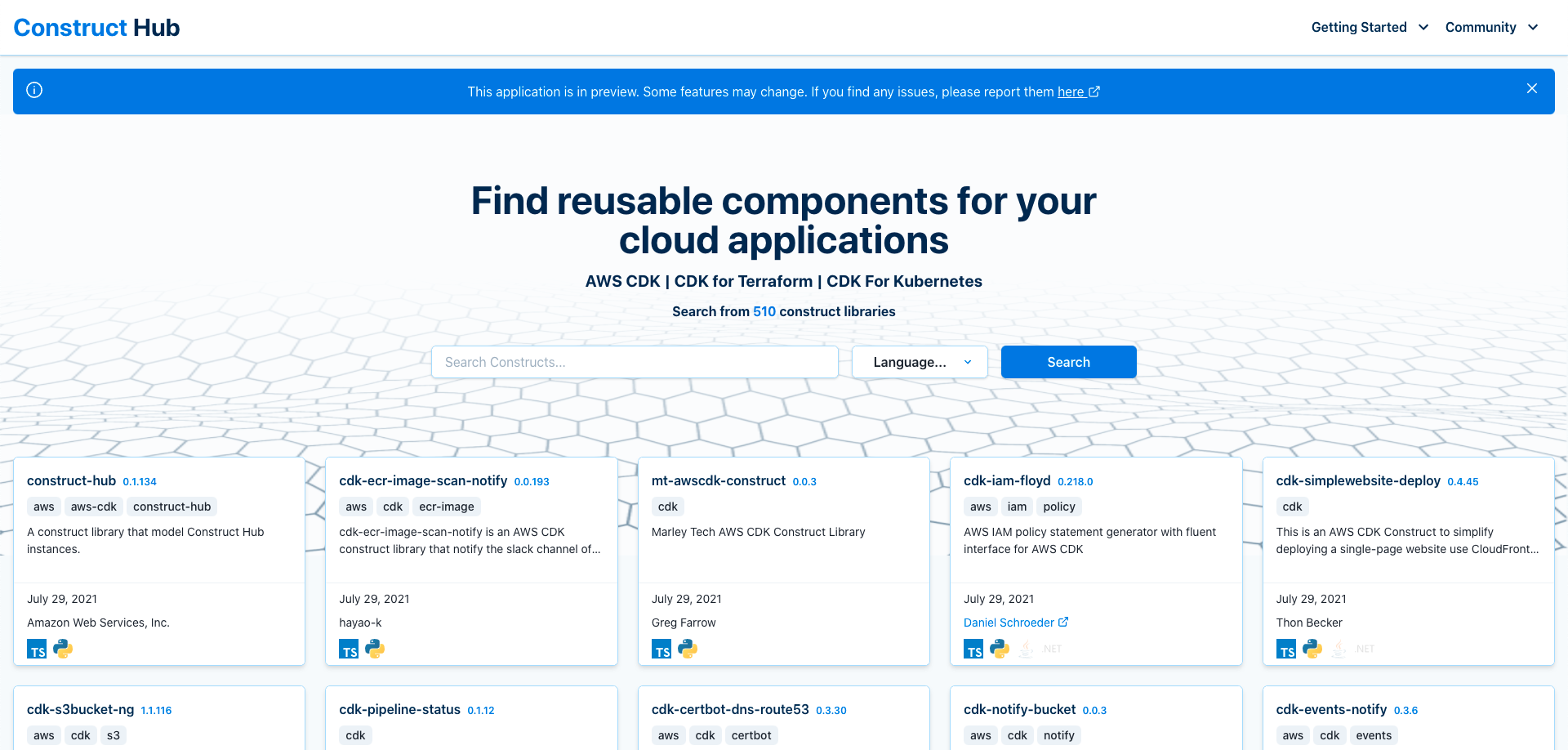
As Alex concludes, “This is an open-source preview, and we need your help to make the Construct Hub the best end-to-end experience for discovering and sharing constructs.” This is a must read post this week, so make sure you check it out.
DevOps
Finding the right balance of open-source tools and AWS services that will meet your functional and non-functional requirements, to help you maximise the value you get from those resources is the focus on this post, Choosing a Well-Architected CI/CD approach: Open Source on AWS from Mikhail Vasilyev. The post helps you with a decision making framework aligned to the Well Architected framework, and looks at source code management, continuous integration and container registry options you can choose from, and how these all can work together.
Colleague Jenna Pederson has been working on using Inspec, an open-source framework for testing and auditing your applications and infrastructure in her latest blog post, How to use CDK Outputs in your Inspec tests showing you how you can use this together with a feature of CDK to help you build better tests for your Infrastructure as Code. [hands on]
MLFlow
MLflow is an open source platform to manage the ML lifecycle, including experimentation, reproducibility, deployment, and a central model registry. Sofian Hamiti builds on a previous blog post showing you how to deploy MLflow on AWS, and builds on that to share how you can automate an end-to-end ML lifecycle using MLflow and Amazon SageMaker Pipelines. Well worth reading, MLOps with MLFlow and Amazon SageMaker Pipelines [hands on]
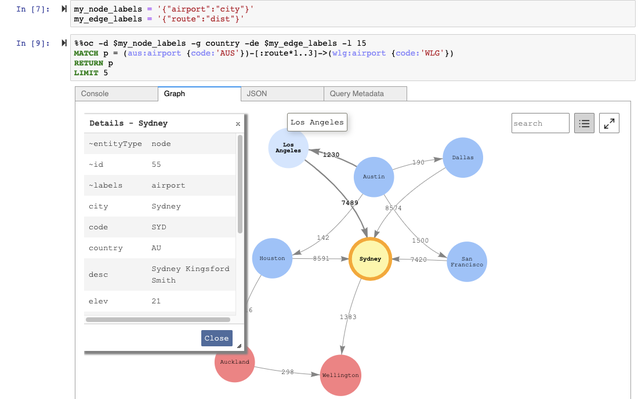
openCypher
Brad Bebee posted this last week, Announcing openCypher for Amazon Neptune: Building better graph applications with openCypher and Gremlin together sharing news of how developers can now use openCypher and Apache TinkerPop Gremlin to build or migrate property graph applications. Check the quick updates section for more details.
OpenSearch
OpenSearch Dashboards Notebooks lets you easily combine live visualizations, narrative text, and SQL and Piped Processing Language (PPL) queries so that you can tell your data’s story. Viraj Phanse, Ashwin Kumar, Anirudha Jadhav, Eli Fisher collaborated on this post, Feature Deep Dive: OpenSearch Dashboards Notebooks that explores popular use cases for Notebooks, how the feature works, and how to get started with it.
OpenTelemetry
This post, Beginner’s Guide to OpenTelemetry, from Dotan Horovits at logz.io provides a really nice, clean and easy to follow introduction into the world of OpenTelemetry. Well worth spending ten minutes of your time, and the videos are also very informative. Make sure you check this out this week.
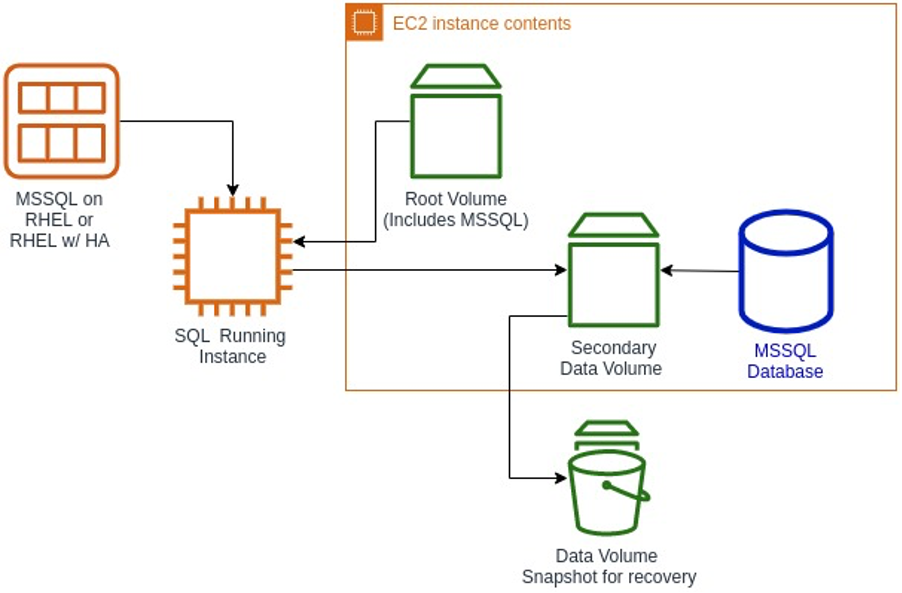
Red Hat Enterprise Linux
One of the ways many business' are looking to modernise their workloads is to move from proprietary systems to open source. This includes running workloads such as MS SQL Server, which you can now run on Linux. In this post, Understanding Amazon Machine Images for Red Hat Enterprise Linux with Microsoft SQL Server Kumar Abhinav provides a deep dive into how to deploy SQL Server on RHEL using these new AMIs, how to tune instances for performance, and how to reduce licensing costs with RHEL.
AWS SDKs
In this post, Mocking modular AWS SDK for JavaScript (v3) in Unit Tests Trivikram Kamat and Maciej Radzikowski show you how you can mock the SDK clients using the community-driven AWS SDK Client mock library. [hands on]
Case Studies
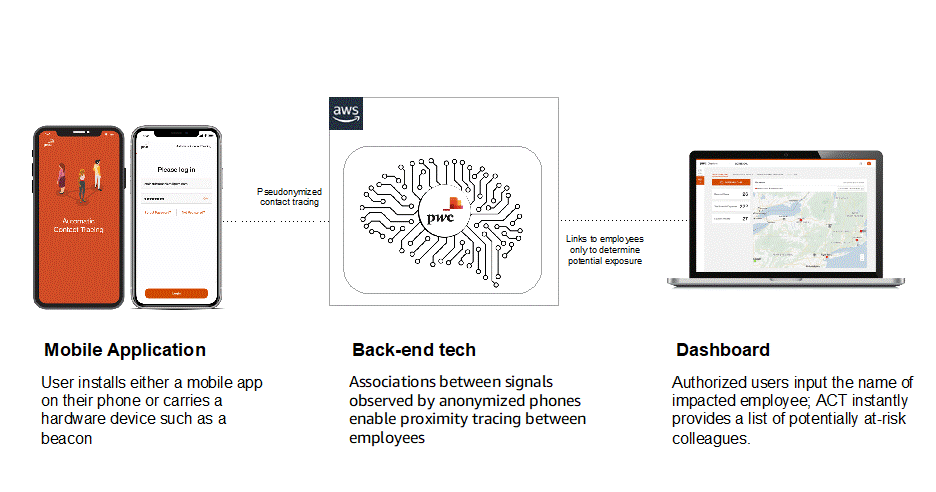
Apache Cassandra
In this post, Idea to product: PricewaterhouseCoopers launches Check-In within three months on Amazon Keyspaces Rob Mesirow, Anil Lalwani, David Sapin, and Mihir Desai show you how PwC built the Check-In solution from idea to product within 3 months using Amazon Keyspaces (for Apache Cassandra) and additional open source technologies on AWS. Check-In is a single, technology-driven solution that provides clients the data to plan, prevent, and react precisely to mitigate risk to their people and business. Read on to find out more about Check-In and how PwC were able to reduce the time it took them, to go from idea to launch.
Core WCF
Core WCF is a port of Windows Communication Framework (WCF) to .NET Core. Used to build service-oriented applications based on the .NET Framework, WCF enabled applications to asynchronously send data, packaged as messages, between service endpoints.
In this interview, Supporting development of Core WCF, Steve Roberts is joined by Biroj Nayak, a Senior Software Development Engineer working in Amazon Elastic Compute Cloud (Amazon EC2), to talk about the open source Core WCF project and the contributions he’s been involved with.
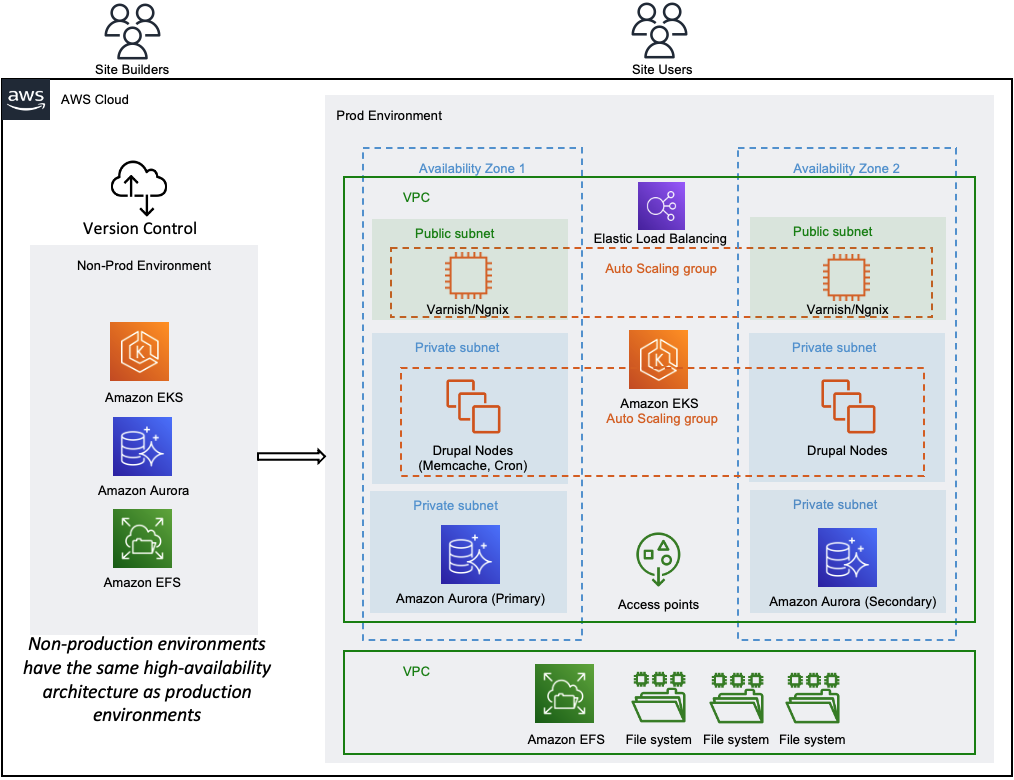
Drupal
Jessica Ho takes a look at how Acquia and Amazon Web Services (AWS) together offer a secure, resilient, and highly performant solution with the next-generation enterprise digital experience platform, Acquia Cloud Next. To find out more, read the post, How Acquia Enables a Highly Scalable Drupal Digital Experience Platform on AWS
Quick updates
openCypher
Amazon Neptune announced support for openCypher, a popular query language for building applications with graph databases. Developers can now use openCypher with Amazon Neptune, giving them more choices to build or migrate graph applications to a highly available, secure, and fully managed graph database. Support for openCypher is compatible with our customers’ existing property graphs and developers can use both Apache TinkerPop Gremlin and openCypher queries within the same graph.
Customers like openCypher’s syntax, which is inspired by SQL, because it provides a familiar structure to compose queries for graph applications. With the addition of openCypher, Amazon Neptune now provides customers with that widest array of query language support including openCypher, Gremlin, and W3C SPARQL. Customers can use the openCypher and Gremlin query languages together over the same property graph data. Support for openCypher is compatible with the Bolt protocol, enabling customers to continue to run applications that use the Bolt protocol to connect to Neptune.
openCypher is available in lab mode in this release and is enabled by default. Neptune customers who use Gremlin can immediately start using openCypher to query their graphs. New customers can get started with loading and querying their data using openCypher. Customers migrating to Neptune can easily connect to the graph database and continue to use their existing openCypher queries to build and run graph applications.
Customers using openCypher have access to all Neptune features, such as the Neptune workbench, which now supports querying and visualising results of openCypher queries. Support for openCypher is available in all regions where Neptune is supported, and there are no additional charges to use openCypher.
Check out the documentation page, Accessing the Neptune Graph with openCypher
SPARQL
Amazon Neptune announces support for SPARQL 1.1 Graph Store HTTP Protocol (GSP) for graphs using W3C’s Resource Description Framework (RDF). Using GSP on SPARQL 1.1 endpoints, customers now have an efficient method to interact with complete named graphs within a graph store. This can streamline building graph applications using Amazon Neptune and tools that support the W3C Recommendation GSP such as Apache Jena.
GSP provides customers with convenient endpoints for manipulating an entire named graph in one HTTP request, instead of having to write multiple complex SPARQL 1.1 queries to achieve the same result. SPARQL 1.1 provides a query-based approach to fetching, inserting, and deleting RDF triples, GSP supports these actions on entire named graphs in the graph store. The addition of GSP in Neptune introduces a new endpoint URL: https://your-neptune-endpoint:port/sparql/gsp/ that customers can use to access RDF graphs in Neptune.
To find out more, check out the documentation page Using the SPARQL Graph-Store HTTP protocol (GSP) in Amazon Neptune
RabbitMQ
You can now launch RabbitMQ 3.8.17 brokers on Amazon MQ. This patch update to RabbitMQ contains several fixes and enhancements compared to the previously supported version, RabbitMQ 3.8.11. To learn more, read the RabbitMQ Changelog.
Suricata
AWS Network Firewall uses the open source intrusion prevention system (IPS), Suricata, for stateful inspection, and is now a Payment Card Industry Data Security Standard (PCI DSS) compliant service. Customers can now use AWS Network Firewall to capture, transmit, and retrieve sensitive payment card data for use cases such as payment processing that are subject to PCI DSS.
FreeRTOS
FreeRTOS 202107.00 now includes the Simple Network Time Protocol (SNTP) client library to make it easier for developers to add time information in their FreeRTOS-based IoT applications. The SNTP client library, named coreSNTP, is used to synchronise clocks between two devices or a device and the cloud.
You can use coreSNTP in IoT applications where devices need to display time or use time for its business logic (e.g. control temperature and lighting). In addition, you can use coreSNTP to validate certificates during TLS handshakes with the cloud or, if required, generate signatures to authenticate cloud storage requests (e.g. SigV4 signatures for HTTPs requests to Amazon Simple Storage Service). The SNTP functionality becomes especially important in IoT devices that cannot retain time and date information in the absence of external power (e.g., IoT devices that do not contain real-time-clock modules).
Find out more by reading the README
Events for your diary
Cloud Native Day 23rd September, Bern Switzerland
What is this, an in person event returning? A stellar line up including our own Michael Hausenblas, an event looking at CNCF projects and the future of IT. Find out more and to view prices/register, by clicking here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on [@AWSOpen](https://twitter.com/AWSOpen