AWS open source news and updates #52
January 18th, 2021 - Instalment #52
Newsletter #52
This week we have a number of posts covering AWS Cloud Development Kit, (AWS CDK) as well as Managed Workflows for Apache Airflow (MWAA) which you should check out (ok, I’ll admit I might have been involved in some of those) as well as a couple of interesting projects. Don’t miss the summary of re:Invent from last week - still plenty of time to catch up with the on demand videos. I cover both the open source track and the sessions from other tracks that feature open source projects. But before you dive into the newsletter, a couple of short notices including a very nice open source newsletter that is a must sign up to…
Apache Software Foundation
If you have not seen/read the Apache Software Foundation blog, then well worth signing up to The Apache Software Foundation Blog to catch up with all the latest news and updates from many of the projects you are likely to be using. Aside from that they also share some great insights into open source, community and the overall impact of open source in society. Great stuff, and this weeks must read.
Console
Fellow Amazonian Jackson Kelley has a brilliant open source newsletter that is absolutely essential you sign up to. Aside from covering great open source projects, each week he talks to open source builders and asks them some great questions. These are the hook that will keep you coming back. Awesome work Jackson!
Take a look and sign up here.
Python 2.7 end of support
Make sure you check this post, Announcing the end of support for Python 2.7 in the AWS SDK for Python and AWS CLI v1 if you are using v1 of the AWS Cli and Python 2.7. Important details and dates with regards to end of support which you should make sure you understand and plan for.
Celebrate open source contributors
The articles posted in this series are only possible thanks to contributors and project maintainers and so I would like to shout out and thank those folks who really do power open source and enable us all to build on top of what they have created.
So thank you to the following superstars: Yi Ai, Michael Hausenblas, Gary Stafford, Florian Valery, Denis Gladkikh, Michael Bailey, Andrea Cavagna, the folks at cloudquery, Rene Brandel, Brian Likosar, Larry Heathcote, Amit Gupta, Troy Ameigh, Julia Kroll, Dipankar Ghosal, Janakarajan Natarajan, Prashant Agrawal, Jennifer Bland, Matt Coulter and Elad Ben-Israel.
Make sure you find and follow these builders and keep up to date with their open source projects and contributions.
Latest from open source projects
coldsnap
coldsnap coldsnap is an open source command-line interface that uses the Amazon EBS direct APIs to upload and download snapshots. It does not need to launch an EC2 instance or manage EBS volume attachments. It can be used to simplify snapshot handling in an automated pipeline. The tool came to my attention via this blog post from Michael Bailey, Open Source Tool Release: Gaining Novel AWS Access With EBS Direct APIs where he look at some of the innovative ways that the APIs can be used. To give you a hint, check out this extract:
“In relation to the work of Crypsis (a Palo Alto Networks company that provides cybersecurity professional services including digital forensics and incident response (DFIR), offensive security and proactive work), EBS direct APIs could be used to interact with AWS in ways not previously seen.”
They provide links to a repo with some code as well. Definitely a post to check out this week.
formik-core
formik-core FormKiQ Core is an Open Source Headless Document Management System (DMS) that runs completely AWS and can support any size organisation, from personal websites to large, enterprise organisations requiring full control of any number of internal and external documents. It looks like it is built from serverless components which means you can focus on writing great content and leave the infrastructure to AWS.
Blog posts from the community and customers
PySpark, Apache Spark, Apache Airflow and more
I missed these somehow, but Gary Stafford has put together a couple of great posts that show a number of open source big data tools that you have probably heard of, but maybe not sure what they do or how they fit together. To set the scene, he talks about Running PySpark Applications on Amazon EMR and shares how to use PySpark, a python API for Apache Spark, to interact with a number of these open source big data tools.
In his follow up post, Running Spark Jobs on Amazon EMR with Apache Airflow he walks you through how to setup orchestration to automate the steps from the first step, putting a typical use case of how these technologies can work together to produce faster time to value from your data. This is probably the best walkthrough I have seen for the newly launched Managed Workflows for Apache Flow I have seen so far.

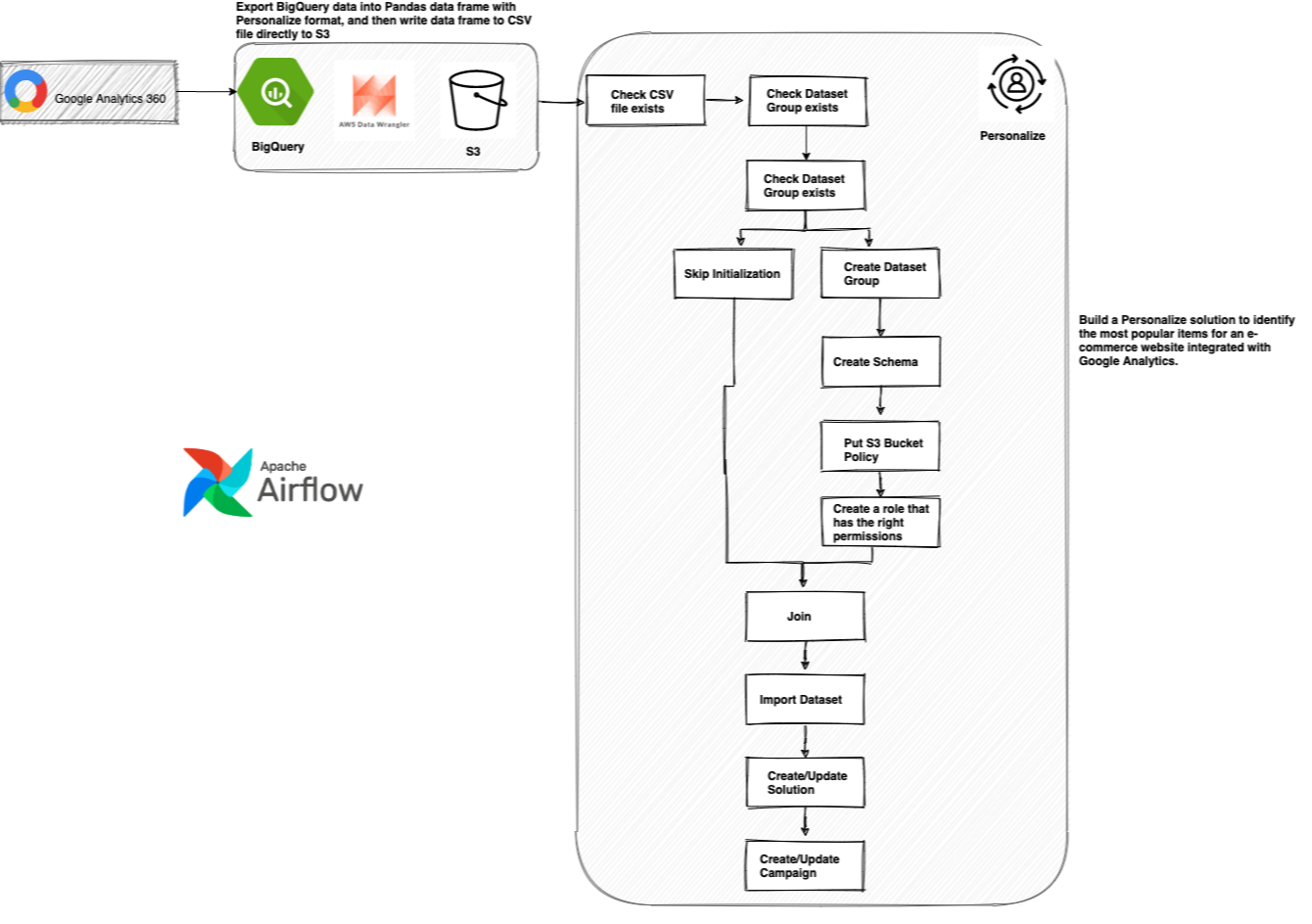
We had another great blog post over the Christmas period that I missed. In Automating a Machine Learning Workflow using Google BigQuery and Amazon Managed Apache Airflow, AWS Community Builder Yi Ai shows you how you can orchestrate workflows across different vendors. The walk through helps you build the workflow end to end, and you can modify it to your own ends. I especially liked the workaround to be able to deploy Python packages you might need on your worker nodes. If you are interested in orchestration or Apache Airflow, then check this out.
ECS ComposeX
Wordpress CMS from docker-compose to AWS in a few steps John Preston shares a blog post to coincide with the latest release of the ECS-ComposeX tool 0.11 showing you how you can simply automate the deployment of one of the most common CMS
Deploying Ghost 3.00
Deploying Ghost 3.0 to AWS using EC2 Auto Scaling, RDS and Terraform – Pt 1 Florian Valery writes a two part post (second part is in the blog post) on how to deploy the Ghost open source blogging software in the Cloud. Ghost is a free and open source blogging platform written in JavaScript and distributed under the MIT License, designed to simplify the process of online publishing for individual bloggers as well as online publications. Florian provides everything you need including code/scripts in the GitHub repo.

AWS Amplify
A couple of posts this week. First up we have one on getting deeper insights into your traffic. Following that we have one on how to use AWS Amplify to add authentication to a Vue application.
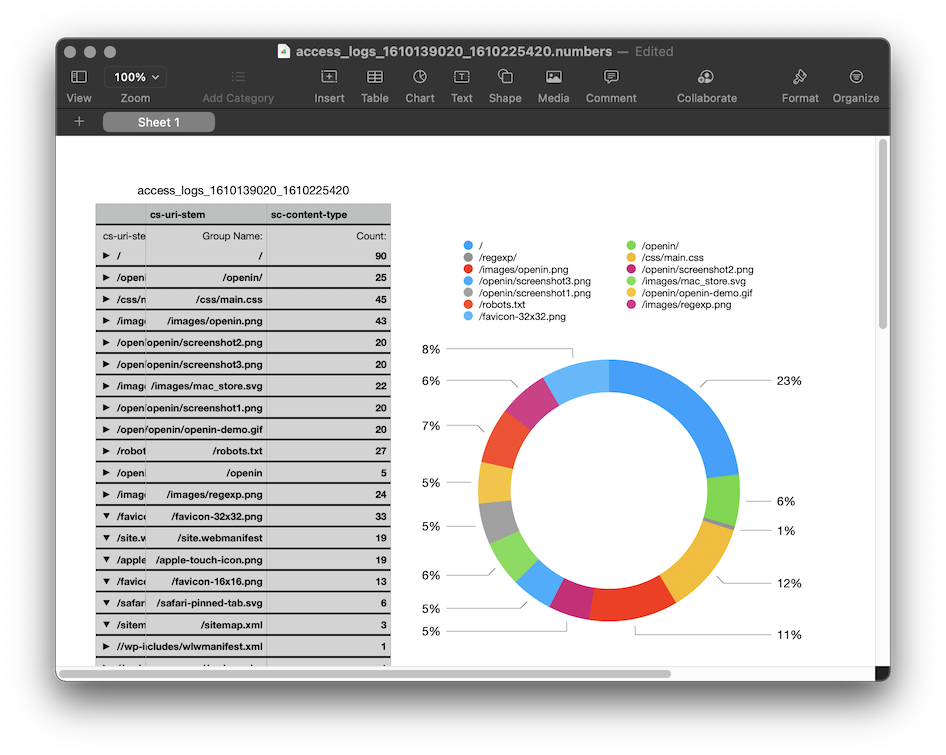
If you love AWS Amplify and you use it to run/host some of your applications but you are now looking for a way to get deeper insights in how your users are interacting with it. What are the most popular pages or are there any issues that you need to fix. Analysing logs is one part of how to address this, and Denis Gladkikh has put together this blog post, Analyzing AWS Amplify Access logs. Part 1. to walk you through a number of different options. Take a read to find out what the options are and watch out for part 2 when it surfaces by following Denis (and checking out his other blog posts)
CloudQuery
How to run AWS CIS Benchmark with CloudQuery I have introduced readers to this newsletter about this open source project before (check out newsletter 45) and cloudquery is an open source tool that allows you to interact with your cloud infrastructure via queryable SQL or Graphs for easy monitoring, governance and security. In this post, they show you how to run AWS CIS benchmark with CloudQuery using out-of-the-box SQL statements that you can customised to your environment. Watch out for future posts too.
AWS Single Sign On
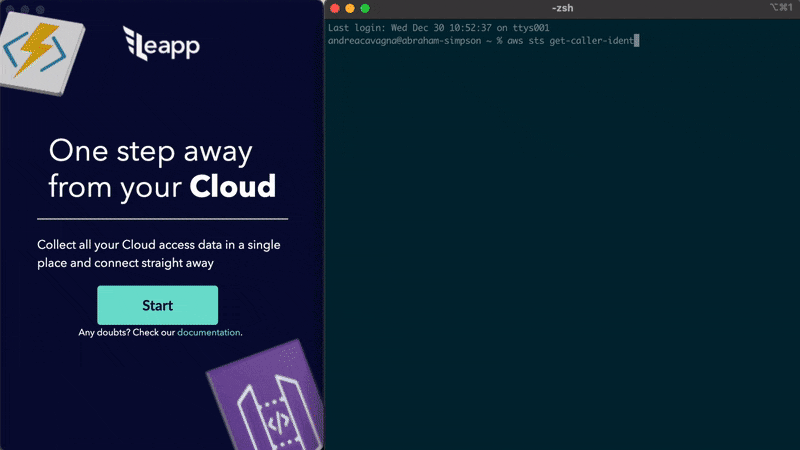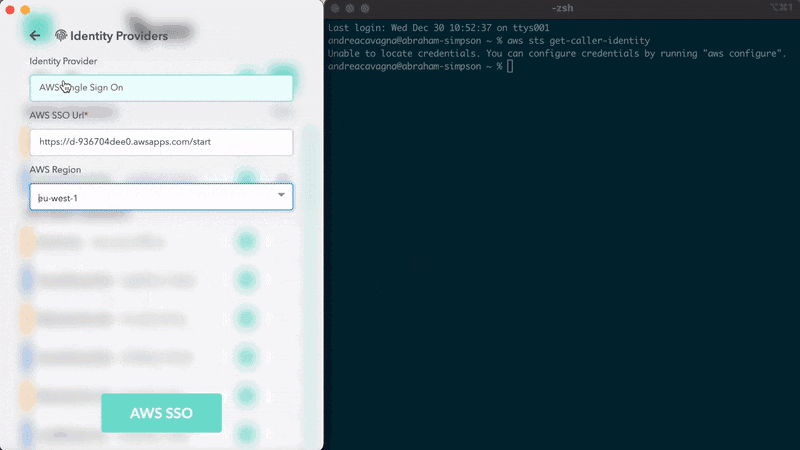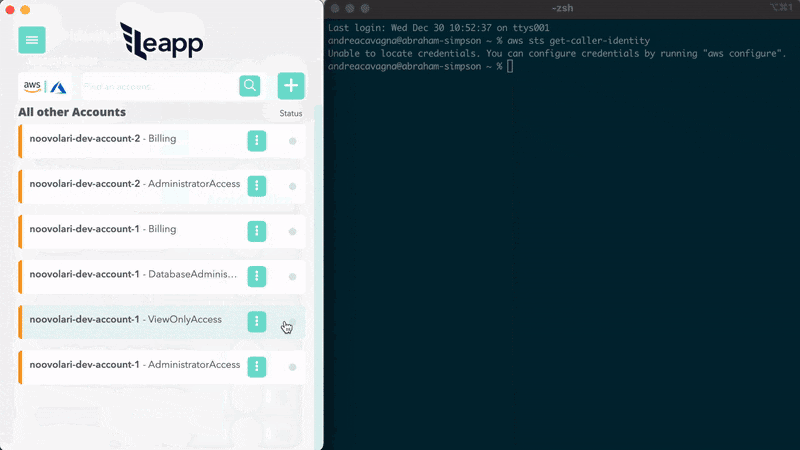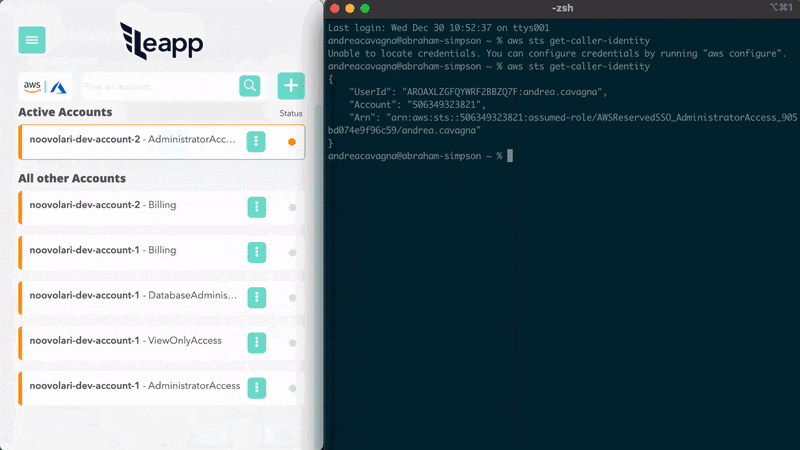
AWS Single Sign-on for DevOps: is CLI v2 the best option? Andrea Cavagna has put together a post that talks about the various options you have today when it comes to AWS single sign on (AWS SSO). He shares insights of the strengths and weakness before sharing an updat eabout a project I have talked about previously, Leaap, and how this now integrates with AWS Single Sign on so that you can simplify your life and make it easier and safer to connect to your AWS resources. Check out the source code here - https://github.com/Noovolari/leapp
AWS open source posts
AWS Open Distro for OpenTelemetry
Migrating X-Ray tracing to AWS Distro for OpenTelemetry open source builder Michael Hausenblas shows you how you can send traces from an AWS Distro for OpenTelemetry (ADOT) enabled application to X-Ray, to help kick start you if you are looking to migrate your applications traces (and logs and metrics in the future too). Michael uses an example Amazon EKS to show you how you would migrate a typical distributed tracing setup.
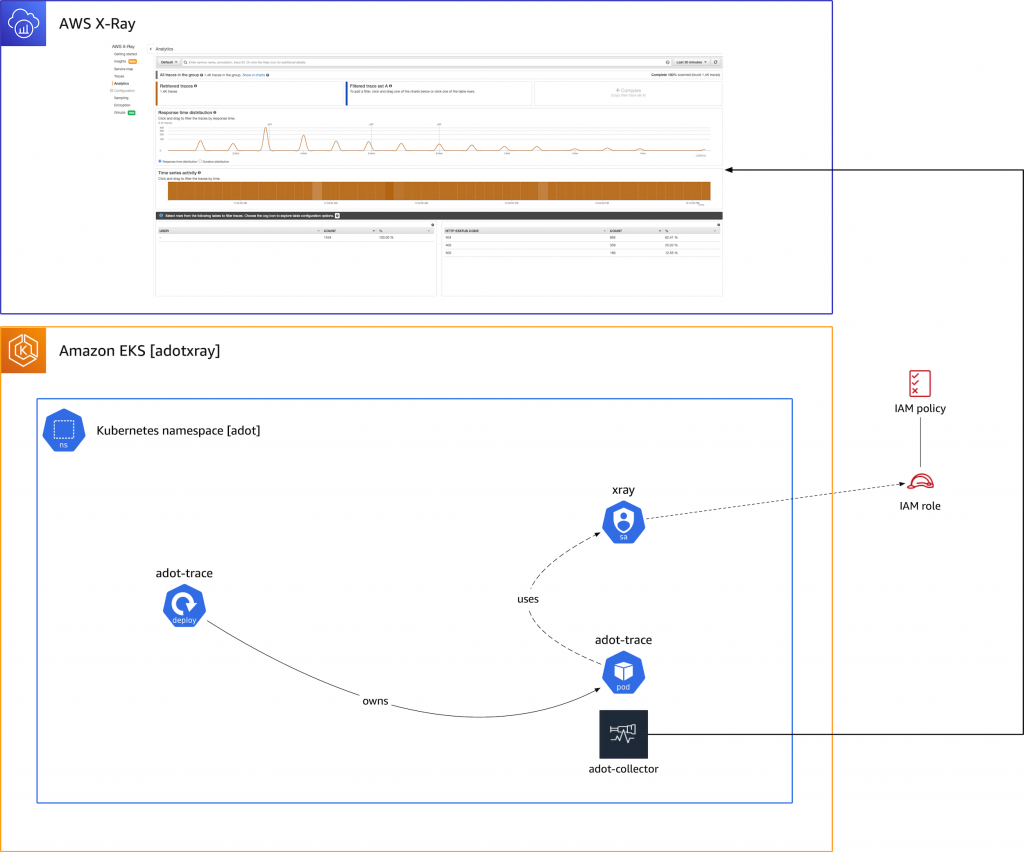
(Thanks Michael for spotting the typo!)
AWS CDK
This week we have a few stories covering the AWS Cloud Development Kit, or AWS CDK.
Kicking off with Richard H Boyd’s post, CDK Corner – January 2021 sharing some updates about the AWS CDK roadmap if you missed the sessions during re:Invent. Richard talks about AWS CDKv2, what was learnt and what common issues it is looking to address. Essential reading.
Following that why not educate yourself in the backstory of AWS CDK. In this post, Working backwards: The story behind the AWS Cloud Development Kit, I talked with Elad Ben-Israel to understand how AWS CDK came about, how the team set themselves up for success and the importance of open source projects addressing real problems.
Finally we have Matt Coulter (Technical Architect at Liberty Mutual), whose post The CDK Patterns open source journey, takes a look at the journey and path of CDK Patterns, an open source repository that shares re-usable patterns to solve real developer use cases. More than that though, the post talks about how these are aligned to things like the Well Architected Framework to provide more confidence when using these assets. Matts post highlights some of the reasons why this project has been so impactful and garnered so much interest and contributions, with some great data points. If you have not heard or reviewed the site, check it out today - full links provided in the post.
AWS Amplify
NEW in Amplify DataStore: Selective sync and sort functionality this post from Rene Brandel shares new features that have been incorporated into Amplify DataStore. From the blog post:
Amplify DataStore (JavaScript, Android, and iOS) provides frontend web and and mobile developers a persistent on-device storage repository for you to write, read, and observe changes to data even if you are online or offline, and seamlessly sync to the cloud as well as across devices. With the recent Amplify Library release, DataStore gains the ability to selectively sync a subset of your app data and to sort your app data.
Apache Airflow
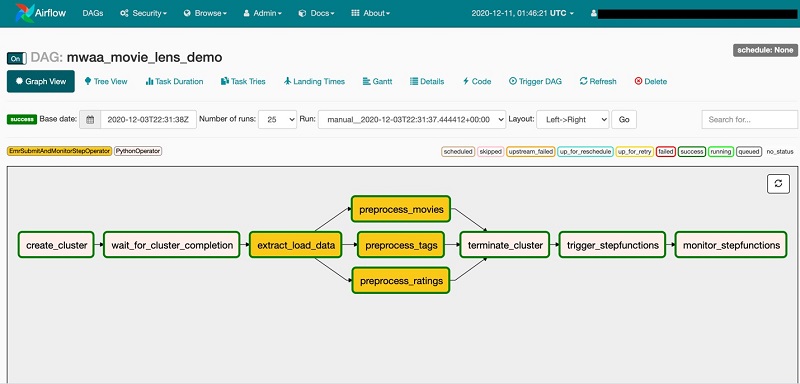
Building complex workflows with Amazon MWAA, AWS Step Functions, AWS Glue, and Amazon EMR Dipankar Ghosal has put together a post to show how you can build complex workflows in Apache Airflow, or more specifically the recently launched Managed Workflows for Apache Airflow. This post demonstrates how to use Amazon MWAA as a primary workflow management service to create and run complex workflows and extend the directed acyclic graph (DAG) to start and monitor a state machine created using Step Functions. If you are just getting started with this service then this is a must read. I have spent quite a bit of time over the last week getting introduced to this service, and I was glad for some of the insights that Dipankar shares.
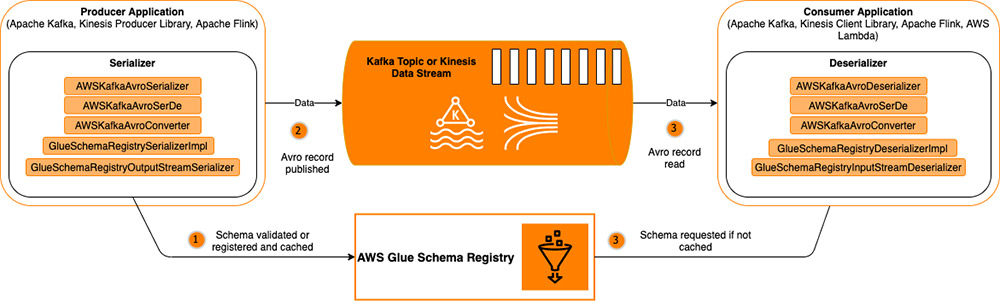
Apache Kafka
Data streaming technologies like Apache Kafka serve as a highly available transport layer that decouples the data-producing applications from data processors. One problem that arises however, is that due to the number of applications producing, processing, routing, and consuming data, it can become difficult to coordinate and evolve data schemas, like adding or removing a data field, without introducing data quality issues and downstream application failures. In this post, Validate, evolve, and control schemas in Amazon MSK and Amazon Kinesis Data Streams with AWS Glue Schema Registry Brian Likosar and Larry Heathcote provide some answers as to how you can use schema registries to solve this problem.
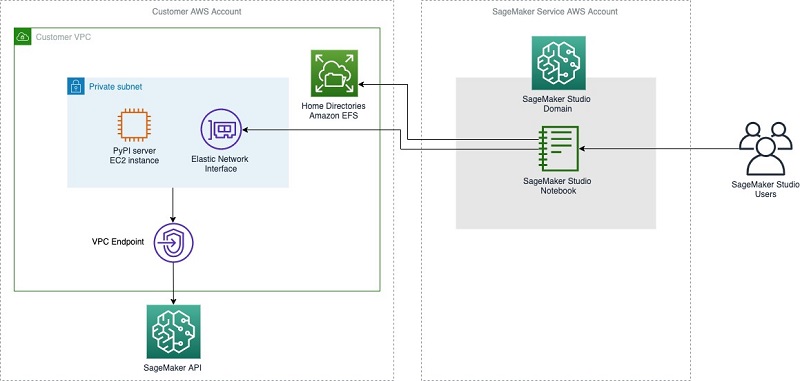
PyPi
Hosting a private PyPI server for Amazon SageMaker Studio notebooks in a VPC Julia Kroll shares how you can setup a private PyPi repository (Python Package Index), running on an Amazon EC2 instance. PyPi repos are used when using standard tools such as pip, and it makes it easy to find and install hundreds of thousands of packages, including common packages such as NumPy, Pandas, Matplotlib, Pytest, Requests, Django, and BeautifulSoup. If you are looking for more control on how your developers or build environments install python packages, then this post is for you.
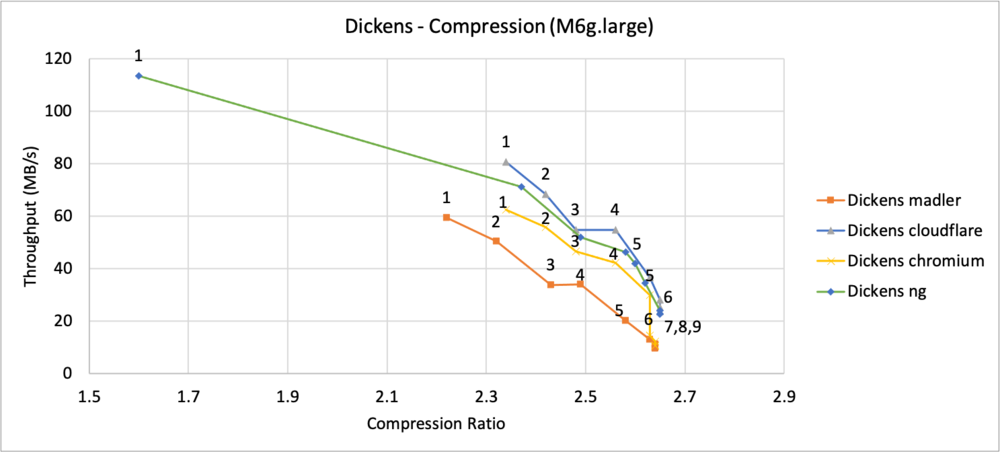
zlib
Improving zlib-cloudflare and comparing performance with other zlib forks Janakarajan Natarajan shares some of the work we have been doing to help improve and optimise the performance of this library. The zlib compression library is widely used to compress and decompress data. This library is utilized by popular programs like the Java Development Kit (JDK), Linux distributions, libpng, Git, and many others. In thie post Janakarajan describes the work done in zlib-cloudflare to improve its decompression performance and he takes a look at how this compares with other zlib forks on both compression and decompression operations, using the Silesia Corpus (a collection of modern-day workloads) and a custom benchmark tool.
Elasticsearch
Masking field values with Amazon Elasticsearch Service Prashant Agrawal takes you through how to set up field masking within your Amazon ES domain. Field masking is an alternative to field-level security that lets you anonymise the data in a field rather than remove it altogether. This is helpful where you have use cases where users reviewing those insights should not have access to all the details from the log data.
AWS Partners
Calico
Enterprise Security and Networking for Amazon EKS Clusters with Calico and Calico Enterprise Amit Gupta, VP at Tigera and Troy Ameigh from AWS share news of a new AWS Quickstart that provides everything you need to leverage Calico and Calico Enterprise (installation and configuration) in your Amazon Elastic Kubernetes Service (Amazon EKS) clusters, enabling you to take advantage of the full set of Kubernetes security, observability, and networking features, including Calico’s flexible IP address management capabilities.
re:Invent
If you missed these sessions last week then fear not, you can catch them on the on demand capability before these videos move to the AWS You Tube channel. Lots of great sessions to check out.
Containers
- COM302: Vulnerability scanning for Kubernetes applications: Why and how Liz Rice, VP of open source engineering at Aqua Security demonstrates how vulnerability scanners work, and covers why they are important learning about open-source tools that you can build into your CI/CD pipeline and your running Kubernetes deployment to help you detect vulnerabilities in your applications.
- DOP401: Simplifying Kubernetes application management with cdk8s Eli Polonsky’s session on the CDK for Kubernetes (cdk8s), a new open-source software development framework that lets you define Kubernetes applications and resources using familiar programming languages. The session showed you how to use the construct programming model and the cdk8s+ library to define your Kubernetes applications and share common definitions as reusable components with your team, organization, and community.
Rust
- OPN205: Next-gen networking infrastructure with Rust and Tokio Carl Lerche and Sean McArthur session covered why you should be thinking how the combination of Tokio and Rust are great combinations when building reliable network applications without comprising performance and speed. Great deep dive session.
- OPN401: Securing Bottlerocket updates with TUF and Rust in this session iliana talked about the approach to building the over-the-air update system for Bottlerocket, building on top of The Update Framework (TUF), now a CNCF graduated project. She covers the Rust library and tooling for the project and dives deep into the TUF specification and how AWS implemented it in Rust.
- OPN402: Rust-vmm: Secure VM-based isolation made simple Rust-vmm is an open-source project that maintains a set of secure and highly reusable virtualization building blocks designed to be used as part of battle-tested, virtual machine monitors (VMMs) such as Firecracker and Cloud Hypervisor. Andreea Florescu from AWS and Samuel Ortiz, Principal Software Engineer at Intel showed you how to use rust-vmm building blocks (with some additional glue and a simple API) to assemble and run a VMM that isolates Linux guests.
Elasticsearch
- OPN207: The future of Elasticsearch: Open Distro for Elasticsearch Kyle Davis takes a peek in his crytal ball at a look at what the future holds for the Open Distro for Elasticsearch is a 100 percent open-source distribution of Elasticsearch that includes advanced features previously only available in commercial software.
Apache Cassandra
- OPN307: Pronto: An IaC suite for managing Cassandra at scale Aaron Elman from AWS introduced Ben Covi and Achal Kumar from Intuit in this session covering a project I have covered in previous issues of this newsletter, Pronto. Pronto is an effort to give back to the community with an open-sourced framework of tools for self-managed Cassandra. It automates Packer, Terraform, and Ansible to go from an empty account to a running cluster in less than an hour.
Apache Kafka
- ANT325: Guide to Apache Kafka replication and migration with Amazon MSK Jeremiah O’Connor and Priyanka Chaudhary shared how you can use MirrorMaker 2.0 to continuously replicate clusters and migrate live Apache Kafka workloads into Amazon MSK.
Machine Learning
-
OPN308: Designing better ML systems: Learnings from Netflix Netflix open-sourced Metaflow, its human-centric ML platform. Savin Goyal, Software Engineer at Netflix shared some of the lessons learned in its multi-year journey building the ML systems that Metaflow incorporates, covering a diverse range of scale from one-time experimentation on laptops to large-scale model training and serving systems on AWS.
-
OPN306: Deploying PyTorch models for inference using TorchServe my colleague Shashank Prasanna and Geeta Chauhan, Head of AI Partnership Engineering at Facebook took a look at some of the challenges around deploying PyTorch models into production and how Torchserve can help you.
-
AIM410: Achieve real-time inference at scale on AWS with Deep Java Library in this session Zach Kimberg will show you how to deploy BERT, one of the 70+ models available in the DJL model zoo, on Amazon EMR with Spark and Flink to achieve real-time inference at scale, using AWS developed Deep Java Library (DJL). Many of today’s big data solutions (Apache Spark, Kafka, Flink, etc.) are Java-based, so the deployment of deep learning models in Java offers advantages in performance and reduced overhead.
-
CON305: Running machine learning workflows at enterprise scale using Kubeflow Peter Dalbhanjan from AWS and Mohan Muppidi, a ML Cloud Architect at iRobot take you through the journey of enterprise AWS customer iRobot in adopting Kubeflow to run its machine learning (ML) workflows.
AWS Amplify and AWS AppSync
A couple of must see sessions if you are looking to maximise what you do with AWS Amplify and AWS AppSync.
- FWM302: Build and deploy dynamic Jamstack apps with AWS Amplify Shawn Wang covered Jamstack, a modern web development architecture built with JavaScript, APIs, and Markup. This new way of building websites and applications delivers performance, higher security, lower cost of scaling, and a better developer experience. This session covered how to bring your Jamstack applications to life in record time when you develop and deploy with AWS Amplify.
- FWM305: Faster application iteration with AWS Amplify CI/CD Nader Dabit from AWS Sumin Kang, Associate Director of Engineering (Growth) at Noom co-presented this situation on how to deploy your full-stack application via the AWS Amplify Console and set up a basic CI/CD pipeline, covering how Noom were able achieve easier collaboration and faster feature releases through “blindingly fast” iteration with the AWS Amplify Console.
FreeRTOS
- IOT402: How to build connected microcontroller apps with FreeRTOS Richard Elberger shared the hardware, software, and operational aspects of connecting an MCU to the cloud. This session should help you be clearer when planning your future IoT projects to understand your hardware, software, and operational choices.
Learning
AWS CDK
Learn how to define and provision cloud infrastructure using the AWS Cloud Development Kit (CDK) with our new digital course AWS Cloud Development Kit (CDK) Primer. This intermediate course is designed for developers that are familiar with AWS services, including AWS CloudFormation.
The 1.5-hour course explains how to model, provision, modify, and delete cloud application resources using familiar programming languages. By taking this course, you’ll be able to state the key concepts of the AWS CDK, describe its core components, define applications in your preferred programming language, deploy applications using the CLI, and design reusable constructs. Upon completion, you can reinforce your learning with our hands-on lab, where you’ll work through a real-world cloud scenario to leverage your favourite IDE and programming language to define your applications.
Learn from AWS experts. Advance your skills and knowledge. Build your future in the AWS Cloud. Enrol today.
Quick updates
Apache Ranger
Amazon EMR now natively integrates with Apache Ranger, allowing you to define, enforce, and audit fine-grained data access control. With this feature, you can define and enforce 1/ database, table, and column level authorisation policies for Apache Spark and Apache Hive users to access data through Hive Metastore, and 2/ prefix and object level authorisation policies when accessing data in Amazon S3 via the Amazon EMR File System (EMRFS), leveraging Amazon CloudWatch to capture auditing logs.
Apache Ranger is an open-source tool to enable, monitor, and manage comprehensive data security across the Hadoop platform. Previously, you can use Apache Ranger to enforce fine-grained authorisation on data in HDFS with Apache Hive using this blog post. Now this native integration enables additional capabilities. You can define three types of authorisation policies on Apache Ranger Policy Admin server. You can set table, column, and row level authorisation for Apache Hive, table and column level authorisation for Apache Spark, and prefix and object level authorisation for Amazon S3. Amazon EMR automatically installs and configures the corresponding Apache Ranger plugins on the cluster. These Ranger plugins sync up with the Policy Admin server for authorisation polices, enforce data access control, and send auditing events to Amazon CloudWatch Logs.
Read more here.
MySQL
Starting today, you can perform an in-place upgrade of your Amazon Aurora database cluster from MySQL major version 5.6 to 5.7. Instead of backing up and restoring the database to the new version, you can upgrade with just a few clicks in the Amazon RDS Management Console or by using the AWS SDK or CLI. Aurora MySQL 5.7 offers enhancements such as JSON support, spatial indexes, and generated columns. Aurora’s native implementation of spatial indexing also can deliver >20x better write performance and >10x better read performance than MySQL 5.7 for spatial datasets.
To upgrade to Aurora MySQL 5.7, select the “Modify” option on the AWS Management Console corresponding to the database instance you want to upgrade, choose the version of Aurora MySQL 5.7 you want to upgrade to, and proceed with the wizard. The upgrade may be applied immediately (if you select the “Apply Immediately” option), or during your next maintenance window (by default). Please note that in either case, your database cluster will be unavailable during the upgrade and your database instances will be restarted. Please review the Aurora documentation to learn more.
Porting assistant for .NET
Porting Assistant for .NET is an open source analysis tool that scans .NET Framework applications and generates a .NET Core or .NET 5 compatibility assessment, helping you port your applications to Linux faster. Porting .NET Framework applications to .NET Core or .NET 5 helps customers take advantage of the performance, cost savings, and robust ecosystem of Linux.
The graphical user interface of Porting Assistant for .NET is now available in open source. Users can now view, modify, and contribute to its source code. The Porting Assistant for .NET data store and analytics engine , which includes information such as package compatibility and their known replacements, is already available through open source. With the new release, user can also participate in the UI development process.
Porting Assistant for .NET UI is a React application that uses Electron application framework. Porting Assistant for .NET UI leverages AWS UI components, which AWS has released along with Porting Assistant. AWS UI is a collection of React components that help create intuitive, responsive, and accessible user experiences for web applications. AWS UI is available under the terms of the Apache 2.0 open source license. This release of AWS UI is just the first step in a larger process of creating a new open source design system. Stay tuned for future updates in this space!
Events for your diary
Projen Community Meeting January 20th, 5-6pm GMT
Last chance to sign up for this even this week. Projen is a code-first approach for managing software project configuration. This is the first meeting of the projen community. The event will mostly be an unstructured conversation about current and future plans for projen. Any topics are welcome!
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen.
Your feedback matters!
I have put together a short feedback survey, which I would ask you to take - it will take no more than 2 minutes. You can access here. Many thanks!