AWS open source newsletter #204
Edition #204
Welcome to issue #204 of the AWS open source newsletter, the newsletter where we try and provide you the best open source on AWS content. Apologies for the long wait since the last edition, I will have to do better. Thanks for the lovely messages and feedback I have received over the past few weeks, this edition is for you!
As always, we have more great new projects to check out, which include projects that surface up your AWS costs in Home Assistant, a tool that you can use to ask questions about your code base that uses generative AI, a git large file storage (LFS) extension that lets you use Amazon S3, and a handy network cost calculator. We also have some great demo code too. Projects include a great demo of digital twins, how to do near real time news clustering and summarisation, a really fun demo of using a PS4 game to generate telemetry data when building and testing out observability tech, and more!
Also featured in this edition is content on some of your (and mine) favourite open source projects, which include Valkey, Keycloak, Apache Airflow, PostgreSQL, deequ, Kubernetes, ArgoCD, OTEL, Grafana, Spring Boot, Amazon Corretto, OpenShift, Kubecost, Karpenter, MySQL, MariaDB, Apache Flink, Apache Kafka, OpenZFS, InfluxDB, AWS Parallel Cluster, Lustre, Prometheus, Finch, Ubuntu, Home Assistant, Godot, and Cedar.
As always, get in touch if you want me to feature your projects in this open source newsletter. Until the next time, I will leave you to dive into the good stuff!
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
git-remote-s3
git-remote-s3 is a neat tool that provides you with the ability to use Amazon S3 as a Git Large File Storage (LFS) remote provider. It provides an implementation of a git remote helper to use S3 as a serverless Git server. The README provides good examples of how to set this up and example git commands that allow you to use this setup. This is pretty neat, and something I am going to try out for myself in future projects.
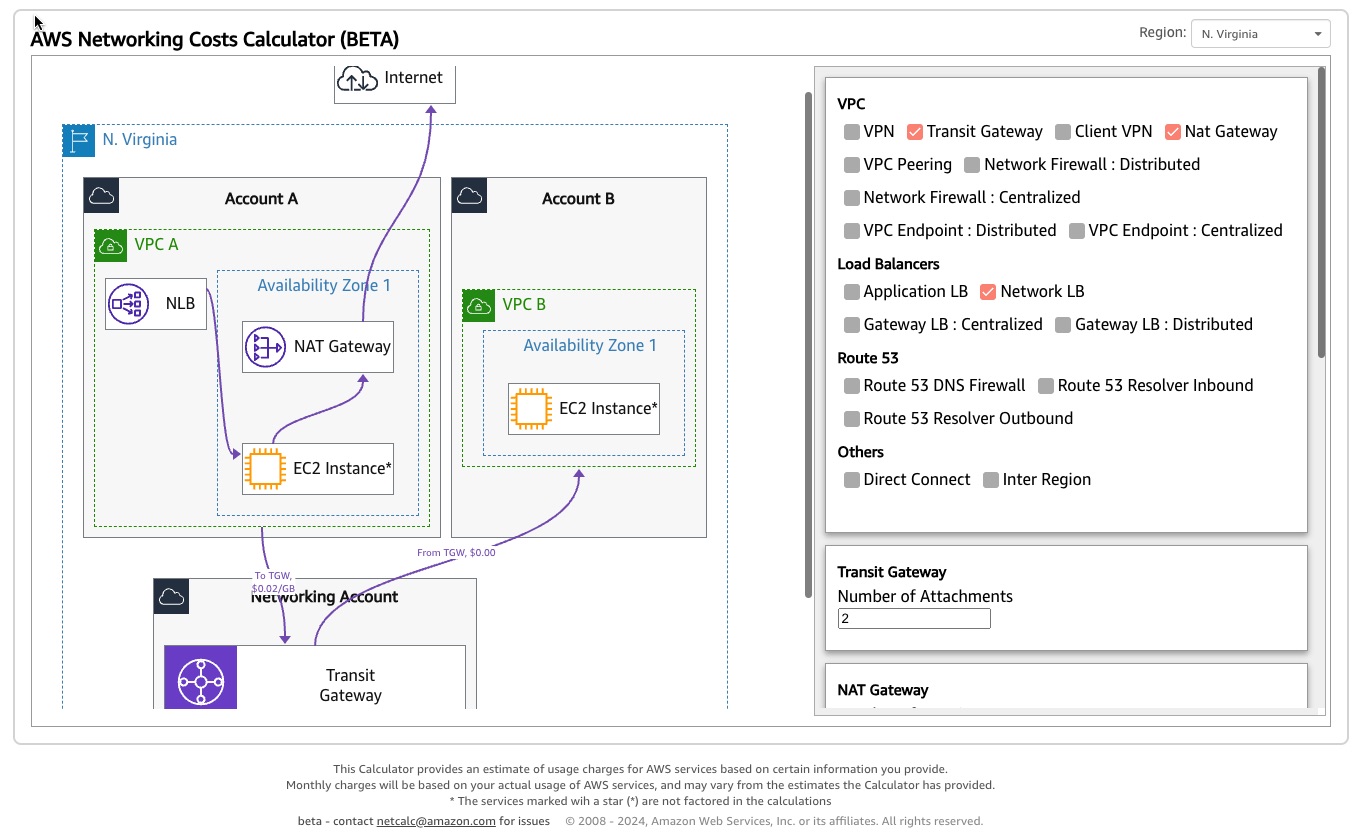
networking-costs-calculator
networking-costs-calculator provide a useful sample code for a networking costs calculator, helping to estimate the networking costs such as Data Transfer, Transit Gateway Attachments, NAT Gateways etc. The calculator has two main components: a serverless backend part, that uses the AWS Price List Query APIs to get the updated prices for the relevant networking services. These prices are cached in a DynamoDB table, and a ReactJS frontend web application, that is the user interface for estimating the costs for various networking services (hosted with S3 and CloudFront). The README provides everything you need to try this out, so what are you waiting for!
ha-aws-cost
ha-aws-cost is a project from Diego Marques for folks who use Home Assistant (a very popular open source home automation system), and provides custom component interacts with AWS to get the month to date cost and forecast cost and make it available on Home Assistant. It adds two new entities 1/Month to date cost: The current cost of your AWS account, and 2/Forecasted month costs: The forecasted cost based in your current consumption. Check out Diego’s post on LinkedIn that provides some more background to this project.
ziya
ziya is a code assist tool for Amazon Bedrock models that can read your entire codebase and answer questions. The tool currently operates in Read only mode, but doing more that this is on the road map.
cloudwatch-to-opensearch
cloudwatch-to-opensearch provides sample code that shows you how to ingest Amazon CloudWatch logs into Amazon OpenSearch Serverless. While CloudWatch Logs excels at collecting and storing log data, OpenSearch Serverless provides more powerful search, analytics, and visualisation capabilities on that log data. This project implements a serverless pipeline to get the best of both services - using CloudWatch Logs for log aggregation, and OpenSearch Serverless for log analysis.

cloudsec-ninja
cloudsec-ninja is an open source project that provides something for the Spanish speaking community, providing everything you need to develop Cloud Security skills. Whether you are a beginner or advanced practitioner, you will learn how to manage and implement security for your workloads on Amazon Web Services. Go check it out.
Demos, Samples, Solutions and Workshops
amplify-godot-engine-sample
amplify-godot-engine-sample for the past few years, Godot has been one of the most active and popular open source projects. If you are not familiar with it, it provides a game engine that allows you to build 2D and 3D games (currently half way through a Udemy course, and loving it!). If you wanted to know how you can use AWS Amplify with Godot, this repo provides some sample code using some of the Godot demo projects.
news-clustering-and-summarization
news-clustering-and-summarization this repository contains code for a near real-time news clustering and summarisation solution using AWS services like Lambda, Step Functions, Kinesis, and Bedrock. It demonstrates how to efficiently process, embed, cluster, and summarise large volumes of news articles to provide timely insights for financial services and other industries. This solution aims to launch a news Event feature that clusters related news stories into summaries, providing customers with near real-time updates on unfolding events. This augmented news consumption experience will enable users to easily follow evolving stories while maximising relevance and reducing the firehose of information for articles covering the same event. By tailoring news clusters around key events, this application can improve customer satisfaction and engagement.
Detailed docs will help you get up and running in no time.

content-based-item-recommender
content-based-item-recommender provides some example code the helps you deploy a content-based recommender system. It is called “content-based” as it bases the recommendation based on the matching between the input’s content and the items' content from your database. This uses prompt to large-language models (LLM) and vector search to perform the recommendation.

aws-eks-udp-telemetry
aws-eks-udp-telemetry is a project that I have tried to build myself many moons ago. Did you know that many of the amazing (and very realistic) racing games for consoles allow you to export telemetry data? When I found this out many moons ago, I put together some simple code that showed some simple telemetry (speed, tyre temperature). I kind of stopped there with plans to do great things, but as is often the way, the project was left half finished. So I am delighted that this project from AWS Community Builder Amador Criado provides a more complete version, including a blog post (Ingesting F1 Telemetry UDP real-time data in AWS EKS) where he dives into the details of how everything works. Great documentation, a supporting video - what more could you want. Really great stuff Amador.
scaling-with-karpenter
scaling-with-karpenter is a project from AWS Community Builder Romar Cablao that provides a demo of how Karpenter autoscale your Kubernetes clusters. To help you get started with the code, check out his supporting blog post, Scaling & Optimizing Kubernetes with Karpenter - An AWS Community Day Talk.
twinmaker-dynamicscenes-crossdock-demo
twinmaker-dynamicscenes-crossdock-demo provides code to create a demonstration of the AWS IoT TwinMaker dynamic scenes feature using a ‘cross-dock’ warehouse as an example. Using this demonstration code, the environment allows the simulation of goods on pallets entering the warehouse at the inbound docks, transition through sorting and then on to the outbound dock. The web interface showing the digital twin visualisation of the warehouse is shown below.

AWS and Community blog posts
This weeks essential reading
- Get started with Amazon ElastiCache for Valkey and Get started with Amazon MemoryDB for Valkey are must read posts that provide you an overview of ElastiCache for Valkey and Amazon MemoryDB for Valkey, their benefits, how you can upgrade to use Valkey and more [hands on]
- Access private code repositories for installing Python dependencies on Amazon MWAA for folks using Managed Workflows for Apache Airflow with a public facing web server but needing to access internal code or library repositories not exposed to the internet will want to read this and find out how to address this challenge [hands on]
- Single sign-on SSO for Amazon OpenSearch Service using SAML and Keycloak walks you through how to configure service provider-initiated authentication for OpenSearch Dashboards by using OpenSearch Service and Keycloak, looking at how to set up users, groups, and roles in Keycloak and configure their access to OpenSearch Dashboards [hands on]
What I am reading from around the Community
Each week I spent a lot of time reading posts from across the AWS community on open source topics. In this section I share what personally caught my eye and interest, and I hope that many of you will also find them interesting. It was really tough though, as there were so many great posts.
Starting things off this week is a series of very useful posts from AWS Community Builder Maurice Borgmeier on one of my favourite open source projects, Apache Airflow. The first post, Enabling Apache Airflow to copy large S3 objects provides important stuff to know about if you are orchestrating the copying of large s3 objects, including errors you might see and how to overcome these. Following that we have Making the TPC-H dataset available in Athena using Airflow that looks at how you can use Airflow to orchestrate the steps needed to benchmark your data systems, in this case Amazon Athena. I have used and written about TPC-H datasets before, so I know how tedious these steps can be. The final post from Maurice is Building Data Aggregation Pipelines using Apache Airflow and Athena which provides some examples (with a linked GitHub repo) of how you can build aggregate data pipelines with Apache Airflow as the orchestrator.
Sticking with the theme of data we have AWS Community Builder Daniel Chapman who shows you how you can move from proprietary to open source databases in his post, Migrating from SQLServer to Aurora PostgreSQL. Daniel provides more reasons why you should think about moving to PostgreSQL with his second post in this roundup, Minimising PostgreSQL RDS minor & major upgrade time with Blue/Green deployments, where he guides on how you can minimise downtime when performing minor/major engine upgrades using blue/green deployments. The final data related post comes from AWS Community Builder Abdul Raheem, who provides an overview of a really nice open source project called deequ that helps you test the quality of your data, in Deequ: Your Data’s BFF.
Wrapping up this community roundup we move to all things Cloud Native, starting off with AWS Community Builder Shakir who shows you how you can auto instrument a spring boot app with the OTEL agent, forward the telemetry data to backends via the Open Telemetry collector, and then visualise those in Grafana. Very cool, so if that sounds like your cup of tea, go read OTEL Auto Instrumentation Demo for SpringBoot with EKS and Grafana. Finally we have AWS Community Builder Benjamen Pyle who has put together Taking Local K8s for a Spin with Minikube and ArgoCD sharing his experiences running a local Kubernetes stack via Minikube and then get started with ArgoCD to deploy a sample application. He plans more posts, so make sure to follow Ben to keep up with his latest updates.
Cloud Native
- AWS and Kubecost Collaborate to Deliver Kubecost 2.0 for Amazon EKS Users looks at key new features of Kubecost (a tool that enables users to gain deeper cost insights into Kubernetes resources) and then shows you how you can can get started with each of them [hands on]
- Amazon EKS optimized Amazon Linux 2023 accelerated AMIs now available dives deep into the Amazon EKS-optimised AL2023 AMI and how it helps you improve the performance and security posture of your applications [hands on]
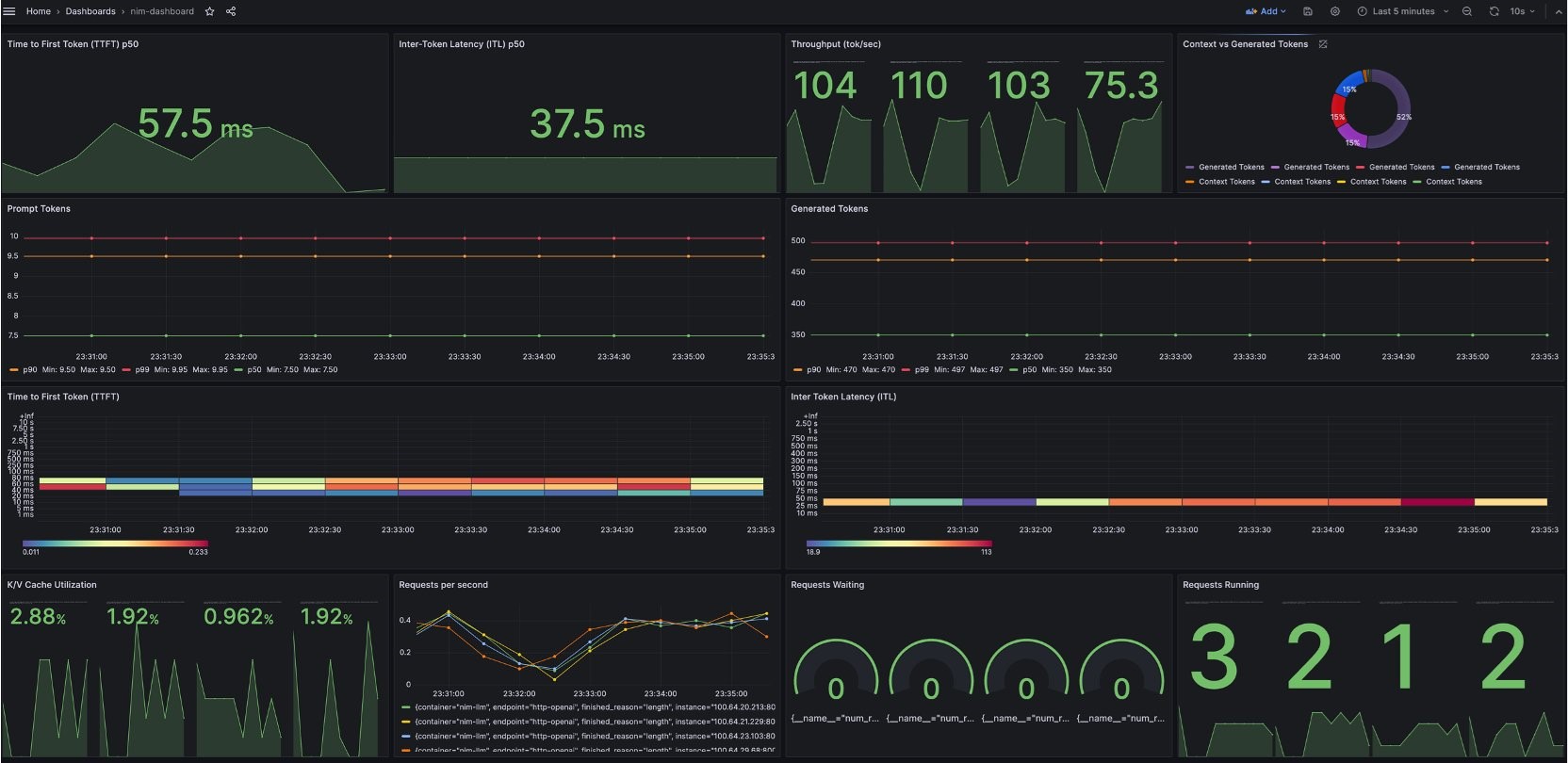
- Scaling a Large Language Model with NVIDIA NIM on Amazon EKS with Karpenter shows you how to deploy NVIDIA NIM on Amazon Elastic Kubernetes Service (Amazon EKS), demonstrating how you can manage and scale large language models (LLMs) [hands on]
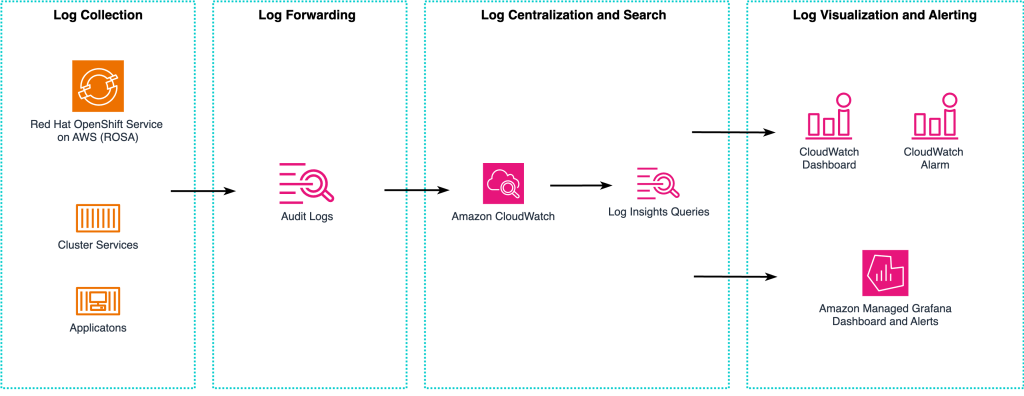
- Security auditing in ROSA using AWS observability services introduces key auditing concepts and demonstrate complementary approaches you can take to monitor your ROSA environments, learning how to configure the Cluster Logging Operator (CLO) in ROSA and how to visualise audit logs using Amazon CloudWatch alarms, CloudWatch Log Insights, and Amazon Managed Grafana [hands on]
Other posts to check out
- Troubleshoot Amazon RDS for MySQL and Amazon RDS for MariaDB Errors explores common errors which you can see when working with RDS for MySQL and RDS for MariaDB, and how to troubleshoot them [hands on]
- Build a dynamic rules engine with Amazon Managed Service for Apache Flink demonstrates how to implement a dynamic rules engine using Managed Service for Apache Flink with both the rules and input data streamed through Kinesis Data Streams [hands on]
- Migrate from Amazon Kinesis Data Analytics for SQL to Amazon Managed Service for Apache Flink and Amazon Managed Service for Apache Flink Studio explains how you can migrate your Kinesis Data Analytics for SQL workloads to Amazon Managed Service for Apache Flink or Apache Flink Studio
- Enhance PostgreSQL resiliency and recoverability using Amazon FSx for OpenZFS shows you how to create an application-consistent snapshot for your PostgreSQL database on Amazon FSx for OpenZFS, including how this approach allows you to roll back to the point-in-time of the snapshot in seconds, which provides you an extremely low RTO [hands on]
- Reliable Airline Baggage Tracking Solution using AWS IoT and Amazon MSK is a case study that shows how IBM developed a framework to modernise a traditional baggage tracking system using AWS Internet of Things (AWS IoT) services and Amazon Managed Streaming for Apache Kafka (Amazon MSK)

Quick updates
Amazon Corretto
On October 15, 2024 Amazon announced quarterly security and critical updates for Amazon Corretto Long-Term Supported (LTS) and Feature Release (FR) versions of OpenJDK. Corretto 23.0.1, 21.0.5, 17.0.13, 11.0.25, 8u432 are now available for download. Amazon Corretto is a no-cost, multi-platform, production-ready distribution of OpenJDK.
In addition, take note that if you are using version 8 or 11 of Amazon Corretto, we announced that Amazon is extending the End of Life (EOL) dates for Amazon Corretto 8 and Amazon Corretto 11. The new EOL dates are as follows:
- Amazon Corretto 8: December-2030 (Previous EOL date was April 2026)
- Amazon Corretto 11: January-2032 (Previous EOL date was September 2027)
Please note that Amazon will halt support for JavaFX, which is currently included in Corrretto 8, on its original EOL date of March-2026. After this date, JavaFX will no longer be included with Corretto 8.
Apache Airflow
You can now create Apache Airflow version 2.10 environments on Amazon Managed Workflows for Apache Airflow (MWAA). Apache Airflow 2.10 is the latest minor release of the popular open-source tool that helps customers author, schedule, and monitor workflows. Amazon MWAA is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. Apache Airflow 2.10 introduces several notable enhancements, such as a new Dark Mode for improved user experience, especially in low-light environments; dynamic dataset scheduling for flexible workflow management; and new task-level metrics for enhanced visibility into resource utilisation. This update also includes important security updates and bug fixes that enhance the security and reliability of your workflows.
Valkey
A couple of Valkey related updates for you. Starting off with news that a lot of folk have been asking about, a managed Valkey service. Valkey is an open source, high performance, key-value datastore stewarded by Linux Foundation. It is a drop in replacement of Redis OSS, backed by 40+ companies with rapid adoption since project inception in March 2024. Hundreds of thousands of customers use ElastiCache to improve their database and application performance and optimizs costs. ElastiCache for Valkey provides a fully managed experience built on open source technology while leveraging the security, operational excellence, 99.99% availability, and reliability from AWS. It is ideal for use cases such as caching, leaderboards, and session stores.
Amazon MemoryDB is a fully managed, Valkey and Redis OSS compatible database service, which provides multi-AZ durability, microsecond read and single-digit millisecond write latency, and high throughput. It is ideal for use cases such as caching, leaderboards, and session stores. With MemoryDB for Valkey, you can benefit from a fully managed experience built on open source technology while leveraging the security, operational excellence, and reliability that AWS provides.
Read more about both of these by checking out Amazon ElastiCache and Amazon MemoryDB announce support for Valkey from Rashim Gupta.
On a related note, GLIDE (General Language Independent Driver for Enterprise) is a new open source client library for Valkey. GLIDE supports Java, Python, and Node.js. GLIDE is one of the official client libraries for Valkey and it supports all Valkey commands. GLIDE supports Valkey versions 7.2 and 8.0, as well as Redis open source versions 6.2, 7.0, and 7.2. Valkey GLIDE is designed for reliability, optimised performance, and high-availability, for connecting to a Valkey or Redis OSS datastore. It is pre-configured with best practices learned from over a decade of operating Redis OSS-compatible services used by thousands of customers. To ensure consistency in application development and operations, GLIDE is implemented using a core driver framework, written in Rust, with language specific extensions. This design ensures consistency in features across languages, and reduces overall complexity.
PostgreSQL
A few updates for PostgreSQL users. Before you dive into that, just a reminder that Amazon Aurora PostgreSQL 12 end of standard support is February 28, 2025. You can either upgrade to a newer major version or continue to run Amazon Aurora PostgreSQL 12 past the end of standard support date with RDS Extended Support.
Amazon Aurora PostgreSQL-Compatible Edition now lets you forward write requests from Aurora read replicas to the writer instance, simplifying scaling read workloads that require read-after-write consistency. With this launch, local write forwarding is now available for both Aurora MySQL and Aurora PostgreSQL. With write forwarding, your applications can simply send both read and write requests to a read replica, and Aurora will take care of forwarding the write requests to the writer instance in your cluster. This way your applications can scale read workloads on Aurora Replicas without the need to maintain complex application logic to separates reads from writes. You can also select from different consistency levels to meet your application read-after-write consistency needs. Local write forwarding is supported on Aurora PostgreSQL versions 14.13, 15.8, 16.4 or higher.
Amazon Aurora PostgreSQL-Compatible Edition now supports PostgreSQL versions 16.4, 15.8, 14.13, 13.16, and 12.20. These releases contain product improvements and bug fixes made by the PostgreSQL community, along with Aurora-specific security and feature improvements. These releases also contain new Babelfish’s features and improvements.
Lastly incase you missed it, Amazon RDS for PostgreSQL 17.0 is now available in the Amazon RDS Database Preview Environment, allowing you to evaluate the pre-release of PostgreSQL 17 on Amazon RDS for PostgreSQL. You can deploy PostgreSQL 17.0 in the Amazon RDS Database Preview Environment that has the benefits of a fully managed database. PostgreSQL 17 includes updates to vacuuming that reduces memory usage, improves time to finish vacuuming, and shows progress of vacuuming indexes. With PostgreSQL 17, you no longer need to drop logical replication slots when performing a major version upgrade. PostgreSQL 17 continues to build on the SQL/JSON standard, adding support for JSON_TABLE features that can convert JSON to a standard PostgreSQL table. The MERGE command now supports the RETURNING clause, letting you further work with modified rows. PostgreSQL 17 also includes general improvements to query performance and adds more flexibility to partition management with the ability to SPLIT/MERGE partitions. Please refer to the PostgreSQL community announcement for more details.
MariaDB
Amazon RDS for MariaDB now supports MariaDB major version 11.4, the latest long-term maintenance release from the MariaDB community. Amazon RDS for MariaDB 11.4 now supports the Simple Password Check Plugin, and Cracklib Password Check Plugin for password validation. You can use these plugins together, or individually to enforce the security policies appropriate for your organisation. MariaDB 11.4 major version also includes improvements to database-level privileges, replication, and the InnoDB storage engine made by the MariaDB community. You can leverage Amazon RDS Managed Blue/Green deployments to upgrade your databases to RDS for MariaDB 11.4
InfluxDB
Amazon Timestream for InfluxDB now supports additional configuration options, providing you with more control over how the engine behaves and communicates with its clients.With today’s launch, Timestream for InfluxDB also introduces a feature that allows you to monitor instance CPU, Memory, and Disk utilisation metrics directly from the AWS Management Console. Timestream for InfluxDB offers the full feature set of the 2.7 open-source version of InfluxDB, the most popular open source time-series database engine, in a fully managed service with features like Multi-AZ high-availability and enhanced durability. You can now configure the port to access your InfluxDB instances, allowing for greater flexibility in your infrastructure setup. Additionally, over 20 new engine configuration parameters gives you precise control over your instance’s behaviour. To get started, navigate to the Amazon Timestream Console, and configure your instances according to your needs.
AWS Parallel Cluster
AWS ParallelCluster 3.11 is now generally available. Key features of this release include support for NICE DCV and custom action scripts on Login nodes. Use custom action scripts to automate the setup and configuration of Login Nodes to meet your specific organisation’s needs such as installing additional software, configuring settings, or custom commands. Add custom action scripts by uploading them to an S3 bucket and specifying their paths in the ParallelCluster YAML configuration file. Check out the release announcement for more info.
Lustre
Amazon FSx for Lustre, a service that provides high-performance, cost-effective, and scalable file storage for compute workloads, now provides additional performance metrics for improved visibility into file system activity and an enhanced monitoring dashboard with performance insights and recommendations. You can use the new Amazon Cloudwatch metrics and dashboard to right-size your file systems and optimise performance and costs. Previously, you could use performance metrics to monitor the file system storage capacity, throughput and IOPS delivered by the storage system, the primary performance characteristics for most workloads. Now, using additional performance metrics that include server- and disk-level resource utilisation, you can optimise performance and costs across an even wider range of compute- and GPU-intensive workloads, such as machine learning, high performance computing (HPC), video processing, and financial modelling. The enhanced monitoring dashboard provides actionable performance recommendations. For example, if your workload is network throughput-limited you can increase the file system throughput performance with a few clicks.
Prometheus
Amazon Managed Service for Prometheus is a fully managed Prometheus-compatible monitoring service that makes it easy to monitor and alarm on operational metrics at scale. It now offers customers the option to use Internet Protocol version 6 (IPv6) addresses for their new and existing workspaces. Customers moving to IPv6 can simplify their network stack by running and operating their Amazon Managed Service for Prometheus workspaces on a network that supports both IPv4 and IPv6. The continued growth of the internet is exhausting available Internet Protocol version 4 (IPv4) addresses. IPv6 increases the number of available addresses by several orders of magnitude so customers will no longer need to manage overlapping address spaces in their VPCs. Customers can now connect to Amazon Managed Service for Prometheus APIs with IPv6 connections. Customers can also continue to connect to Amazon Managed Service for Prometheus APIs via IPv4 connections if they do not utilise IPv6.
Kubernetes
Kubernetes version 1.31 introduced several new features and bug fixes, and AWS is excited to announce that you can now use Amazon Elastic Kubernetes Service (EKS) and Amazon EKS Distro to run Kubernetes version 1.31. Starting today, you can create new EKS clusters using version 1.31 and upgrade existing clusters to version 1.31 using the EKS console, the eksctl command line interface, or through an infrastructure-as-code tool. Kubernetes version 1.31 introduces several key improvements, including stable support for AppArmor security modules, storing timestamps for persistent volume phase transitions, and the beta VolumeAttributeClass API for modifying mutable properties of persistent volumes managed by compatible drivers like Amazon EBS CSI driver starting v1.35.0.
Ubuntu Pro
You can now launch Amazon EC2 Spot Instances using Ubuntu Pro based Amazon Machine Images (AMIs). You can now easily deploy Ubuntu Pro Spot instances and get five additional years of security updates from Canonical. You will be charged on a per-second basis for Ubuntu Pro EC2 AMI instances. For any new Ubuntu Pro EC2 AMI deployments, you will now see Ubuntu Pro charges in the Elastic Compute Cloud section of your AWS bill. Amazon EC2 Spot Instances let you take advantage of unused EC2 capacity available in the AWS cloud. Spot Instances are available at up to a 90% discount compared to On-Demand prices. You can use Spot Instances for various stateless, fault-tolerant, or flexible applications such as big data, containerised workloads, CI/CD, web servers, high-performance computing (HPC), and other test & development workloads. Spot Instances are easy to launch, scale, and manage through AWS services like Amazon ECS and Amazon EMR, or integrated third parties like Terraform and Jenkins.
Finch
This announcement made me very happy as I have been using Finch since the beginning of this year. AWS announced the general availability of Linux support for Finch, an open source command line tool that allows developers to build, run, and publish Linux containers. Finch simplifies container development by bundling a minimal native client with a curated selection of open-source components, allowing developers to build and manage containers without the hassle of managing intricate details.
With the addition of Linux support, Finch now provides a consistent and streamlined container development experience across all major operating systems. Developers can leverage the same familiar Finch commands to build, run, and publish their containers, whether they are working on Linux, macOS, or Windows. This allows teams to standardise their container workflows and tooling, improving productivity and collaboration. In addition to the expanded platform support, Finch also integrates with the Finch Daemon, which provides a subset of the Docker API specification. The Finch Daemon allows customers who rely on the Docker REST API to continue using it programmatically across all Finch-supported environments. While the Finch Daemon currently covers a core set of Docker APIs, we are actively working with the community to expand its functionality over time. Finch’s Linux support is available as RPM packages for Amazon Linux 2 and Amazon Linux 2023, which can be easily installed from the YUM repositories.
Check out the launch post from Hemanth AVS, Ashok Srirama, and Sai Charan Teja Gopaluni, Announcing Finch on Linux for Container Development
Videos of the week
Building scalable data platforms using Data on EKS
In this episode of the Kubernetes Bytes podcast, Bhavin sits down with Alex Lines and Vara Bonthu from AWS to talk about the Data on EKS project. The discussion dives into why AWS decided to build the Data on EKS project and provide patterns for EKS customers to use to deploy data platforms, machine learning and GenAI tools on EKS clusters. They talk about what’s included and what’s not included with each of these patterns and whats coming down the line.
Cedar
Another great video in this series. I have featured previous videos, so if you are new or learning Cedar, make sure you check all of the series out.
Sometimes our policies are not just about the current state of application data – what if we want to have a policy decision based on time or IP address? That’s where context in Cedar policies comes in. In this episode we show how to encode time and filter on IP addresses for a small example policy ensuring students only access an exam within a given time window and from approved IP addresses.
Unlocking the Power of Valkey Modules with Rust
This video caught my attention as this is the most common question I get asked when speaking to developers about Valkey - how does Valkey support modules. Check out this video to find out, but also check out the other videos too.
Events for your diary
If you are planning any events in 2024, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
All Things Open 27-29th October, Raleigh, North Carolina
Make sure you attend All Things Open this coming Autumn if you can, it is one of my favourite tech conferences, with the amazing community that comes year in, year out. As always my colleagues will be manning the AWS booth, and I am sure we will have some cool stuff and SWAG to share with the community.
Check out and grab your ticket while they are still available at 2024.allthingsopen.org
Manchester Tech Festival 29th October
I will be speaking about Cedar at the Manchester Tech Festival in October. Looking forward to sharing info about Cedar with the local developers attending. Hope to see some of you there.
PyCon Wroclaw November 30th, Wroclaw
I will be speaking at PyCon Wroclaw this coming November, and am super excited about meeting with the community. My talk will be on Cedar, and I will be covering an intro to this open source project, how to get started, as well as showing you some of the additional tools and resources that will help you get started on this really amazing project.
Find out more about this event by checking out the event page
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Madelyn Olson, Goumi Viswanathan, Siva Karuturi, Hemanth AVS, Ashok Srirama, Sai Charan Teja Gopaluni, Tim Wilhoit, Sajeev Attiyil Bhaskaran, Jason Janiak, Ajay Tripathy, Alex Thilen, Ankur Bhanawat, Shyam Sunder Rakhecha, Steven Carpenter, Aravindharaj Rajendran, Naim Mucaj, Aaron Dailey, Rashim Gupta, Julian Payne, Jesse Butler, Byant Biggs, Apoorva Kulkarni, Shawn Zhang, Praseeda Sathaye, Vara Bonthu, Subhash Sharma, Neeraj Kaushik, Vaibhav Ghadage, Venkat Gomatham, William Garcia, Kevin Ye, Mehdi Salehi, Sadique Puthen, Benjamen Pyle, Shakir, Daniel Chapman, Abdul Raheem, Maurice Borgmeier, Diego Marques, Romar Cablao, and Amador Criado.
Feedback
Please please please take 1 minute to complete this short survey.
Stay in touch with open source at AWS
Remember to check out the Open Source homepage for more open source goodness.
One of the pieces of feedback I received in 2023 was to create a repo where all the projects featured in this newsletter are listed. Where I can hear you all ask? Well as you ask so nicely, you can meander over to newsletter-oss-projects.
Made with ♥ from DevRel