AWS open source newsletter #197
Edition #197
Welcome to issue #197 of the AWS open source newsletter, the newsletter where we try and provide you the best open source on AWS content.
Like in previous editions of this newsletter, we feature new projects for you you practice your four freedoms. We have some great projects, including a sprinkling of repos that look to help you benchmark and assess your generative AI models and agents, a new fruity framework for building document understanding applications, a nice container command line tool that sysadmins will love, a tool to help you migrate your CodeCommit repositories, a really nice application of using generative AI to help automate CVE findings, and a neat generative AI newsletter generation demo. That should keep you all very busy. Also featured in this edition is content featuring open source technologies such as AWS CDK, PostgreSQL, Spring Boot, LangChain, pgbench, Kubernetes, Flowpipe, Istio, Apache Ranger, Karpenter, MySQL, Apache Airflow, Apache Flink, Apache Spark, Amazon EMR, AWS Amplify, RabbitMQ, and RubyGems.
Before diving into the newsletter, if you are currently looking to get deeper into open source, we have an exciting new role that has opened up in the Valkey project.
Sr Open Source Developer Advocate - Valkey
If you are passionate about open source and working with developers, a new role has opened up for a developer advocate for Valkey. If you love getting hands-on with software and sharing your enthusiasm for NoSQL databases with the wider tech community, then check out this role - Sr Open Source Developer Advocate - Valkey (US locations, office based with travel)
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
evaluating-large-language-models-using-llm-as-a-judge
evaluating-large-language-models-using-llm-as-a-judge This lab addresses this challenge by providing a practical solution for evaluating LLMs using LLM-as-a-Judge with Amazon Bedrock. This is relevant for developers and researchers working on evaluating LLM based applications. In the notebook you are guided using MT-Bench questions to generate test answers and evaluate them with a single-answer grading using the Bedrock API, Python and Langchain.
Evaluating large language models (LLM) is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, strong LLMs are used as judges to evaluate these models on more open-ended questions. The agreement between LLM judges and human preferences has been verified by introducing two benchmarks: Multi Turn (MT)-bench, a multi-turn question set, and Chatbot Arena, a crowdsourced battle platform. The results reveal that strong LLM judges can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans This makes LLM-as-a-judge a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain.
agent-evaluation
agent-evaluation is a generative AI-powered framework for testing virtual agents. Agent Evaluation implements an LLM agent (evaluator) that will orchestrate conversations with your own agent (target) and evaluate the responses during the conversation. The repo has links to detailed docs that provide example configurations and a reference guide to get you started.
rhubarb
rhubarb is a light-weight Python framework that makes it easy to build document understanding applications using Multi-modal Large Language Models (LLMs) and Embedding models. Rhubarb is created from the ground up to work with Amazon Bedrock and Anthropic Claude V3 Multi-modal Language Models, and Amazon Titan Multi-modal Embedding model.
Rhubarb can perform multiple document processing and understanding tasks. Fundamentally, Rhubarb uses Multi-modal language models and multi-modal embedding models available via Amazon Bedrock to perform document extraction, summarisation, Entity detection, Q&A and more. Rhubarb comes with built-in system prompts that makes it easy to use it for a number of different document understanding use-cases. You can customise Rhubarb by passing in your own system and user prompts. It supports deterministic JSON schema based output generation which makes it easy to integrate into downstream applications. Looks super interesting, on my to do list and will report back my findings.
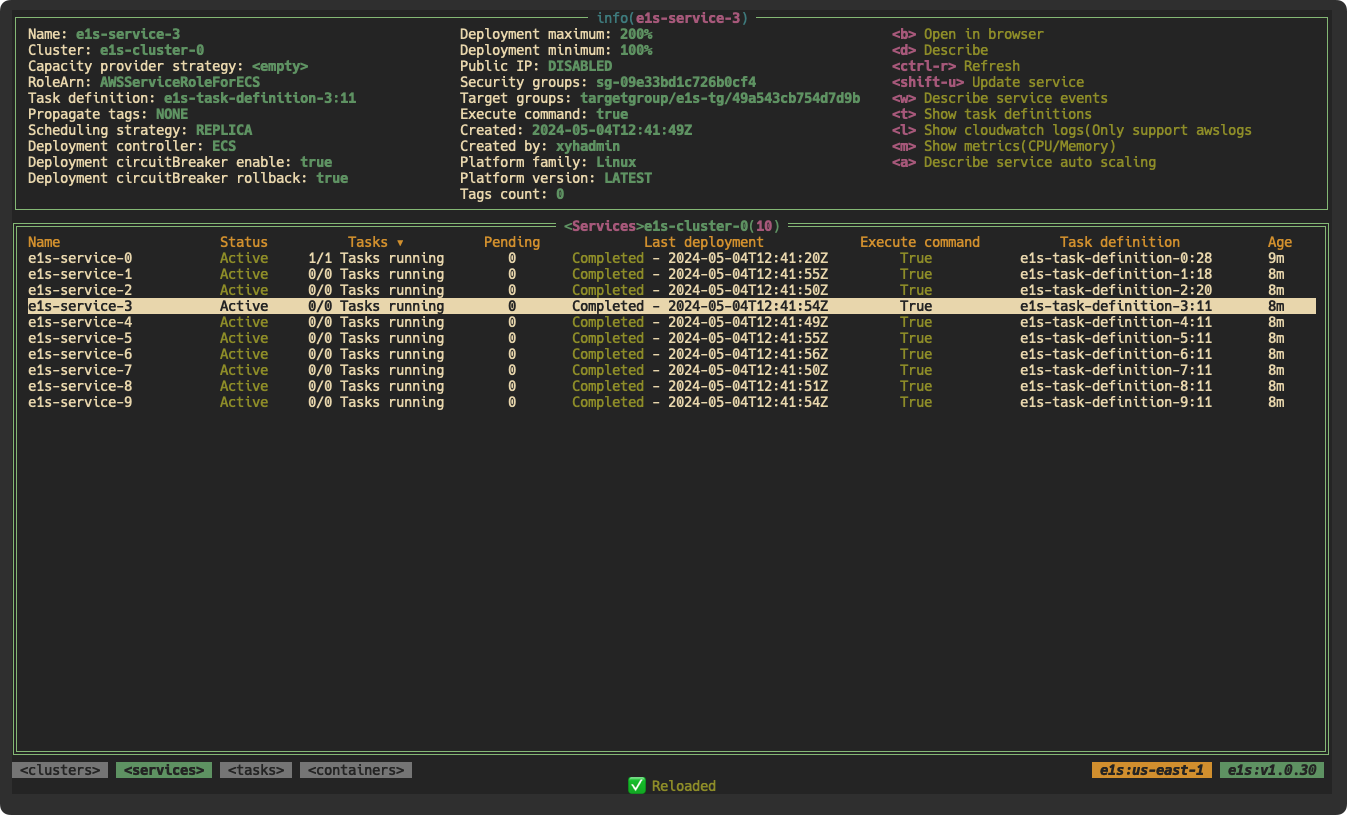
e1s
e1s is a terminal application from Xing Yahao to easily browse and manage AWS ECS resources, supports both Fargate and EC2 ECS launch types. Inspired by k9s. e1s uses the default aws-cli configuration. It does not store or send your access and secret key anywhere. The access and secret key are used only to securely connect to AWS API via AWS SDK. e1s is available on Linux, macOS and Windows platforms. Looks very cool, nice job Xing!
container-resiliency
container-resiliency the primary goal of this repository is to provide a comprehensive guide and patterns for organisations to design, deploy, and operate highly resilient and fault-tolerant containerised applications on AWS. These patterns aims to provide the knowledge and practical guidance necessary to mitigate risks, minimise downtime, and ensure the continuous availability and resilience of containerised applications on AWS, ultimately enhancing their overall operational efficiency and customer experience.

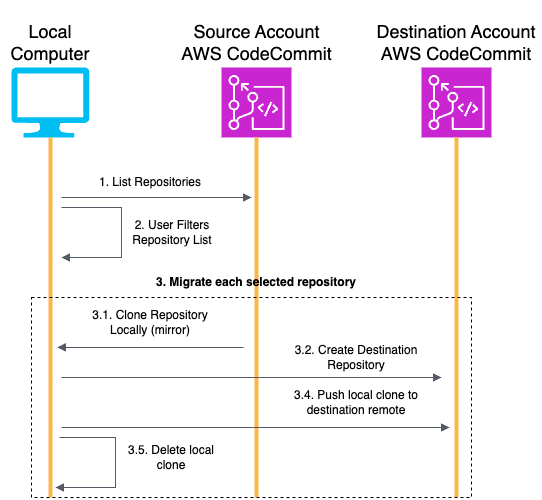
repository-migration-helper
repository-migration-helper is a Python CLI Helper tool to migrate Amazon CodeCommit repositories across AWS Accounts and Regions. Migrating CodeCommit repositories between AWS Accounts is a simple but repetitive process that can be automated for large-scale migrations. In this artefact, we share a Python script that provides a user-friendly interface to automate the migration of repositories in bulk. Using profiles configured for the AWS CLI, this tool makes it easy to move hundreds CodeCommit repositories in one command. The tool can also be used to migrate repositories between regions in one account when using the same profile for source and destination.
First the script fetches the full list of CodeCommit repositories in the source account. Then the user is asked to filter and/or validate the list of repositories to be migrated to the destination account. For each of the selected repositories, it clones the source repository locally (as a mirror including files and metadata). The script then creates the target repository on the destination account with matching name (with an optional custom prefix) and description. The local clone is then pushed to the destination remote and removed from the local disk.
multi-table-benchmark
multi-table-benchmark this repo is the DBInfer Benchmark (DBB), a set of benchmarks for measuring machine learning solutions over data stored as multiple tables. The repo provides detailed instructions on the different steps needed to set up your testing, as well as a Jupyter notebook tutorial to walk you through the key concepts.
Demos, Samples, Solutions and Workshops
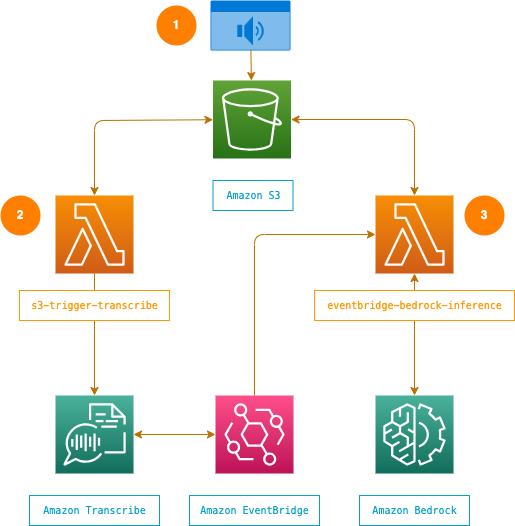
amazon-bedrock-audio-summarizer
amazon-bedrock-audio-summarizer This project provides an automated way to transcribe and summarise audio files using AWS. We use Amazon S3, AWS Lambda, Amazon Transcribe, and Amazon Bedrock (with Claude 3 Sonnet), to create text transcripts and summaries from uploaded audio recordings. I found out about this project from Dr Werner Vogels blog post, Hacking our way to better team meetings.
ai-driven-sql-generation
ai-driven-sql-generation this sample code from AWS Community Builder Hardik Singh Behl uses Amazon Bedrock with Spring AI to convert natural language queries to SQL queries, using Anthropic’s Claude 3 Haiku model.
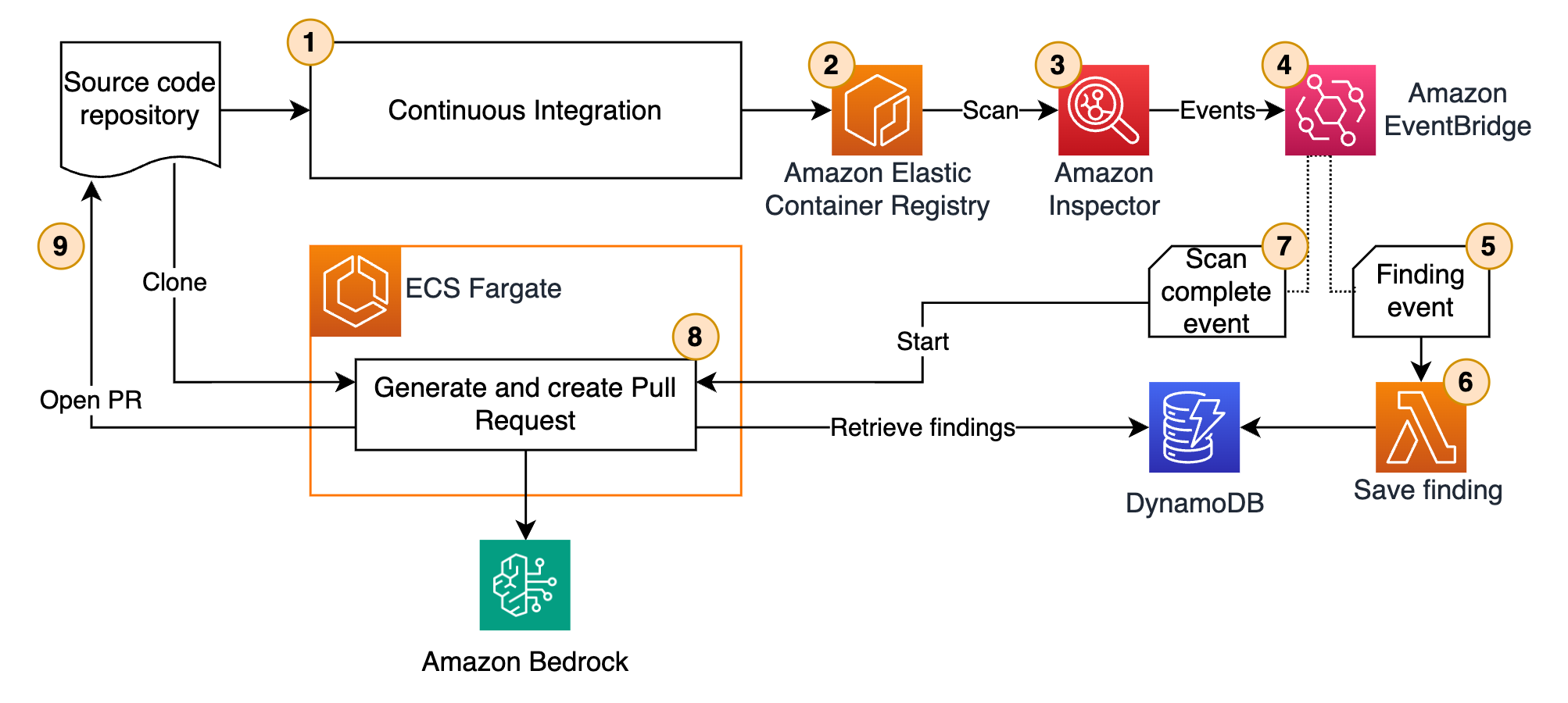
gen-ai-cve-patching
gen-ai-cve-patching This repository introduces an innovative automated remediation pipeline, designed to effectively address vulnerabilities detected by AWS ECR Inspector. By leveraging Generative AI through Amazon Bedrock’s in-context learning, this solution significantly enhances the security posture of application development workflows. The architecture integrates with CI/CD processes, offering a comprehensive and automated approach to vulnerability management. The architecture diagram provided illustrates the solution’s key components and their interactions, ensuring a holistic vulnerability remediation strategy.
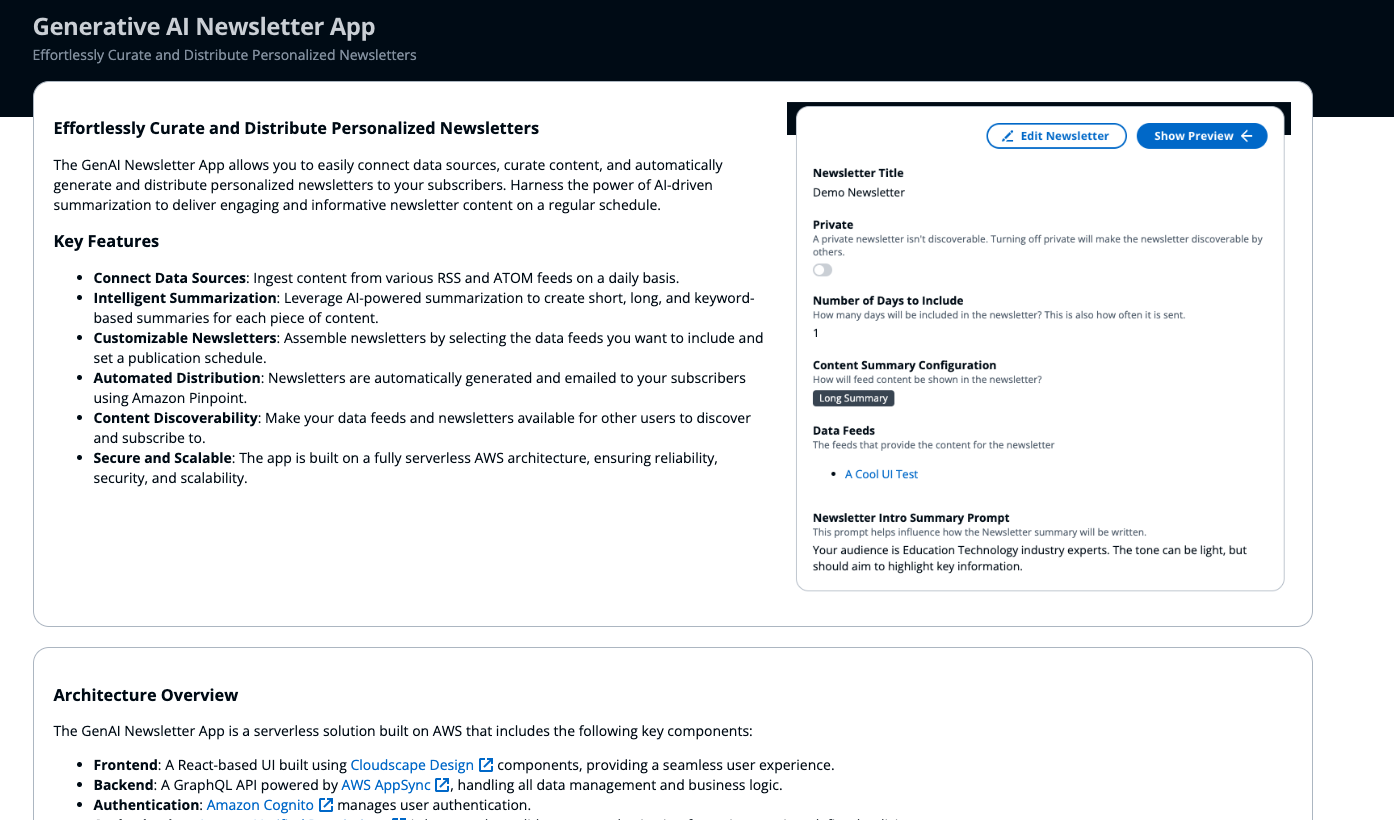
generative-ai-newsletter-app
generative-ai-newsletter-app is a ready-to-use serverless solution designed to allow users to create rich newsletters automatically with content summaries that are AI-generated. The application offers users the ability to influence the generative AI prompts to customise how content is summarised such as the tone, intended audience, and more. Users can stylise the HTML newsletter, define how frequently newsletters are created and share the newsletters with others.
AWS and Community blog posts
Each week I spent a lot of time reading posts from across the AWS community on open source topics. In this section I share what personally caught my eye and interest, and I hope that many of you will also find them interesting.
The best from around the Community
In this edition we are starting our community round up with AWS Hero Philipp Garbe’s post, Hey CDK, what should I know before refactoring CDK applications? which provides some essential tips that Philipp has for you around what to think when refactoring your CDK applications. Sticking with AWS CDK, we have AWS Community Builder Yvo van Zee who shares CDK CodeChecker v2: Breaking Free from Third-Party Dependencies which is essential reading this week, as it will help you build more robust CDK apps, and help you in situations where you might have third party dependencies. Some of the other posts that are linked to from this post were also very interesting to read, so well worth spending some time on this post,.
I featured AWS Community Builder Matt Camp’s repo on Deep Racer in a previous edition of this newsletter (#60), and Matt is back as he shares news about what you can expect with the latest update to the repo, in the post DeepRacer-for-Cloud v5.2.2 now available with new real-time training metrics .
AWS Hero and PostgreSQL expert Franck Pachot is back with more PostgreSQL knowledge for you, this time showing you how you can employ custom SQL within pgbench to design a load test that more accurately simulates real-world scenarios and identifies potential bottlenecks, in the post Custom SQL Scripts in PostgreSQL PgBench. Very nice post, check it out.
I have been spending a lot of time with Spring Boot recently as I explore the potential of Amazon Q Developer, so always appreciate good content on this topic. AWS Community Builder Vadym Kazulkin does just that, and in the latest in his ongoing series of posts on helping you to measure your cold start times when running Spring Boot on AWS Lambda, he takes a look at how to measure the cold and warm start time in the post, Spring Boot 3 application on AWS Lambda - Part 4 Measuring cold and warm starts with AWS Serverless Java Container.
Diving deep into Cloud Native land we have Sean Kane from SuperOrbital with his post, A Hands-on Deep Dive into AWS Auth and Kubernetes , and provides a hands-on approach to exploring the various options that AWS users can use to allow controlled access between AWS cloud resources and EKS Kubernetes cluster resources. I am a bit of a Authn/Authz geek, so love these kinds of posts, great stuff. Sticking on the security theme and staying in Cloud Nativer land, we have Paul Schwarzenberger who writes AWS Application Load Balancer mTLS with open-source cloud CA, where he shows you how to implement mTLS for AWS Application Load Balancer using an open source certificate authority.
Closing things for this edition and fresh from the community.aws Staff Picks we have Omshree Butani’s post for anyone who has been in that tricky situation of having lost access to their Linux instances, what do you do? Well, check out Recovering Access: A Guide for Lost EC2 Key Pair in Linux as this just might save your sanity if you find yourself in this situation.
Flowpipe
Flowpipe is an open source cloud scripting engine where you express pipelines, steps, and triggers in HCL, to orchestrate tasks that query AWS (and other services you regularly use). Bob Tordella, Jon Udell, and Spot show you how you can get started in the blog post, Flowpipe: A Cloud Scripting Engine for DevOps Workflows [hands on]
Cloud Native round up
- Simplify Amazon EKS Deployments with GitHub Actions and AWS CodeBuild is a great look at how to simplify Amazon EKS deployments with GitHub Actions and AWS CodeBuild [hands on]
- Enhancing Network Resilience with Istio on Amazon EKS dives into how Istio on Amazon EKS can enhance network resilience for microservices, by providing critical features like timeouts, retries, circuit breakers, rate limiting, and fault injection, Istio enables microservices to maintain responsive communication even when facing disruptions [hands on]

- Enable Private Access to the Amazon EKS Kubernetes API with AWS PrivateLink provides an innovative blueprint for harnessing AWS PrivateLink as a solution to enable private, cross-VPC, and cross-account access to the Amazon EKS Kubernetes API [hands on]

- Dive deep into security management: The Data on EKS Platform is a comprehensive guide on permission management in big data, particularly within the Amazon EKS platform using Apache Ranger, that equips you with the essential knowledge and tools for robust data security and management [hands on]
- How Slack adopted Karpenter to increase Operational and Cost Efficiency shows Slack’s journey to modernise its container platform on Amazon EKS and how they increased the cost savings and improved operational efficiency by leveraging Karpenter
Other posts and quick reads
- Use your corporate identities for analytics with Amazon EMR and AWS IAM Identity Center provides guidance on how to bring your IAM Identity Center identities to EMR Studio for analytics use cases, directly manage fine-grained permissions for the corporate users and groups using Lake Formation, and audit their data access [hands on]

- Use Kerberos authentication with Amazon Aurora MySQL shows you how to integrate self-managed Microsoft AD with AWS Managed Microsoft AD, enable Kerberos authentication in Amazon Aurora MySQL, and authenticate with Kerberos from Windows and Linux clients [hands on]
- Enhance PostgreSQL database security using hooks with Trusted Language Extensions has a look at enhancements made to hooks in TLE, and shows an example of how to create a client authentication hook [hands on]
- Managing object dependencies in PostgreSQL – Overview and helpful inspection queries (Part 1) and (Part 2) is a two part post that explores object binding in PostgreSQL, and how understanding and managing object dependencies is crucial for ensuring data integrity and making changes to the database without causing unexpected issues [hands on]
- Orchestrate an end-to-end ETL pipeline using Amazon S3, AWS Glue, and Amazon Redshift Serverless with Amazon MWAA demonstrates how to orchestrate an end-to-end extract, transform, and load (ETL) pipeline using Amazon Simple Storage Service (Amazon S3), AWS Glue, and Amazon Redshift Serverless with Amazon MWAA [hands on]

- Build APIs using OpenAPI, the AWS CDK and AWS Solutions Constructs shows you how you can build a robust, functional REST API based on an OpenAPI specification using the AWS CDK and AWS Solutions Constructs [hands on]
- Using ProxySQL to Replace Deprecated MySQL 8.0 Query Cache is a hands on guide that walks you through how to optimise Amazon Aurora/RDS MySQL 8.0 performance by using ProxySQL to replace deprecated Query Cache [hands on]
Quick updates
Apache Flink
Amazon Managed Service for Apache Flink makes it easier to transform and analyse streaming data in real time with Apache Flink. Apache Flink is an open source framework and engine for processing data streams. Amazon Managed Service for Apache Flink reduces the complexity of building and managing Apache Flink applications and integrates with Amazon Managed Streaming for Apache Kafka (Amazon MSK), Amazon Kinesis Data Streams, Amazon OpenSearch Service, Amazon DynamoDB streams, Amazon Simple Storage Service (Amazon S3), custom integrations, and more using built-in connectors.
You can now restore your Amazon Managed Service for Apache Flink application to the previous running version and application state from the most recent, successful snapshot. This feature will work when your application is running and is most useful when you want to immediately rollback to the previous application version to mitigate downstream impact of an application update. Prior to this launch, you could only rollback applications that were in updating or autoscaling statuses.
Apache Spark
Apache Spark provides detailed performance metrics for the driver and executors for jobs such as JVM heap memory, GC, shuffle information etc. These metrics can be used for performance troubleshooting and workload characterisation. Amazon Managed Service for Prometheus is a secure, serverless, fully-managed monitoring and alerting service. Amazon EMR Serverless now provides detailed performance monitoring of Apache Spark jobs with Amazon Managed Service for Prometheus, allowing you to analyse, monitor, and optimise your jobs using job-specific engine metrics and information about Spark event timelines, stages, tasks, and executors. With EMR Serverless integration with Amazon Managed Service for Prometheus, you can now monitor these performance metrics for multiple applications/jobs in a single view, making it easier for centralised teams to monitor these metrics to identify performance bottlenecks, historical trends etc.
This feature is generally available on EMR release versions 7.1.0.
Amazon EMR
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it simple for data engineers and data scientists to run open-source big data analytics frameworks without configuring, managing, and scaling clusters or servers. An EMR Serverless application uses workers to execute workloads, allowing users to configure ephemeral storage per worker based on the workload’s needs. Today, we are excited to introduce Shuffle-optimised disks on Amazon EMR Serverless, offering increased storage capacity (up to 2TB) and higher IOPS delivering better performance for I/O-intensive Spark and Hive workloads.
Shuffle is a fundamental step in an Apache Spark or Apache Hive job, involving I/O intensive operations that redistributes or reorganises data for parallel computations during operations like joins, aggregations, or transformations. Complex workloads with large datasets to shuffle require sufficient disk capacity and I/O performance for optimised shuffle processing. Shuffle-optimised disks offer up to 2TB of storage capacity and higher baseline IOPS, enabling you to efficiently run shuffle-heavy and I/O-intensive Spark and Hive workloads.
Shuffle-optimised disks are generally available on EMR release versions 7.1.0.
PostgreSQL
Amazon Relational Database Service (RDS) for PostgreSQL now supports the latest minor versions PostgreSQL 16.3, 15.7, 14.12, 13.15, and 12.19. This release of RDS for PostgreSQL also includes support for pgvector 0.7.0, which lets you index vectors larger than 2,000 dimensions and adds support for scalar and binary quantisation through expression indexes.
Amazon Aurora PostgreSQL-Compatible Edition now supports PostgreSQL versions 16.2, 15.6, 14.11, 13.14, and 12.18. These releases contain product improvements and bug fixes made by the PostgreSQL community, along with Aurora-specific improvements. These releases also offer improved performance through faster COPY operations (for PostgreSQL 16.2), Query Plan Management enhancements for queries with aggregate operations, and optimisations for further reducing the logical replication lag.
MySQL
Amazon RDS for MySQL now supports MySQL Innovation Release 8.3 in the Amazon RDS Database Preview Environment, allowing you to evaluate the latest Innovation Release on Amazon RDS for MySQL. You can deploy MySQL 8.3 in the Amazon RDS Database Preview Environment that has the benefits of a fully managed database, making it simpler to set up, operate, and monitor databases. MySQL 8.3 is the latest Innovation Release from the MySQL community. MySQL Innovation releases include bug fixes, security patches, as well as new features. MySQL Innovation releases are supported by the community until the next major & minor release, whereas MySQL Long Term Support (LTS) Releases, such as MySQL 8.0, are supported by the community for up to eight years.
RabbitMQ
Amazon MQ now provides support for RabbitMQ version 3.12.13, which includes several fixes and performance improvements to the previous versions of RabbitMQ supported by Amazon MQ. Starting from RabbitMQ 3.12.13, all Classic Queues on Amazon MQ brokers are upgraded to Classic Queues version 2 (CQv2) automatically. All queues on RabbitMQ 3.12 now behave similarly to lazy queues. These changes provide a significant improvement to throughput and lower memory usage for most use cases. If you are running earlier versions of RabbitMQ, such as 3.8, 3.9, 3.10 or 3.11, we strongly encourage you to upgrade to RabbitMQ 3.12.13. This can be accomplished with just a few clicks in the AWS Management Console. We also encourage you to enable automatic minor version upgrades on RabbitMQ 3.12.13 to help ensure your brokers take advantage of future fixes and improvements.
Amazon MQ for RabbitMQ will end support for RabbitMQ versions 3.8, 3.9 and 3.10 as indicated in the version support calendar.
AWS Amplify
AWS Amplify Gen 2, the code-first developer experience for building full-stack apps using TypeScript, is now generally available. Amplify Gen 2 enables developers to express app requirements like the data models, business logic, and authorisation rules in TypeScript. The necessary cloud infrastructure is then automatically provisioned, without needing explicit infrastructure definitions. This streamlined approach accelerates full-stack development for teams of all sizes.
We had a ton of great posts that dive deeper into this announcement, starting off with Rene and Ali’s post, Fullstack TypeScript: Reintroducing AWS Amplify. Daniel Wirjo and Fred Hoskyns look at the progression of full-stack web development and how AWS Amplify enables developers to adapt to the rapidly changing web application ecosystem in their post The evolution of full-stack development with AWS Amplify. Nikhil Swaminathan and Ali Spittel walk you through different team workflows and development environment improvements that the new version of Amplify offers in their post New in AWS Amplify: Expanded Fullstack Deployment Capabilities for Teams of All Sizes. In Amplify Storage: Now with fullstack TypeScript, powered by Amazon S3, Harshita Daddala shows you the brand new experience for file storage using AWS Amplify. The final post in this round up is Amplify Functions: Create serverless functions using TypeScript, powered by AWS Lambda, where Josef Aidt shares how you can use these in a wide variety of use cases, but often enhance or modify the behaviours of your resources to build a tailored user experience for your apps.
RubyGems
Announced a week or so back, RubyGems are now supported in CodeArtifact. Gems, which are used to distribute Ruby libraries, can now be stored in CodeArtifact. Popular tools including the RubyGems and Bundler CLIs can be used to publish and download gems from CodeArtifact repositories. Developers can configure CodeArtifact to fetch gems from RubyGems.org, the Ruby community’s gem hosting service. When a RubyGems package manager is connected to a CodeArtifact repository, CodeArtifact will automatically fetch gems requested by the client from RubyGems.org and store them in the CodeArtifact repository. By storing both private first-party gems and public, third-party gems in CodeArtifact, developers can access their critical application dependencies from a single source.
Check out the supporting blog post from my good friend Sebastien, Add your Ruby gems to AWS CodeArtifact
Videos of the week
Keynote Fifteen years of formal methods at AWS
Recorded at the Open Source Summit North America, Marc Brooker from AWS, provides a packed session that looks at the past, present, and future of building large scale systems, putting mathematics at the core. Super interesting look, and I learned a lot from this session, including how we open sourced Turmoil, a new tool that I have not checked out yet. My favourite slide from this, was “its just vibes man”!
Talking with Management About Open Source
My colleague Spot provides an essential guide on how you can speak to management about open source. Essential knowledge that you all need to know when engaging with these important stakeholders.
Events for your diary
If you are planning any events in 2024, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
PyCon Italia May 22nd-25th, Florence Italy
I will be speaking at PyCon Italia in the wonderful city of Florence in May, talking and showing you how you can use Cedar within your Python applications. This is one of my most favourite events, with an amazing community that comes together over a few days to share their passion of all things open source. If you are coming, then I would love to meet you so get in touch.
BSides Exeter July 27th, Exeter University, UK
Looking forward to joining the community at BSides Exeter to talk about one of my favourite open source projects, Cedar. Check out the event page and if you are in the area, come along and learn about Cedar and more!
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Hardik Singh Behl, Rene Brandel, Ali Spittel, Daniel Wirjo, Fred Hoskyns, Nikhil Swaminathan, Harshita Daddala, Josef Aidt, Pradeep Misra, Abhilash Nagilla, Deepmala Agarwal, Surendar Munimohan, Sai Kiran Kshatriya, Zhen Wang, Peter Celentano, Sukhpreet Kaur Bedi, Baji Shaik, Viswanatha Shastry Medipalli, Wajid Ali Mir, Yaser Raja, Radhika Jakkula, Sidhanth Muralidha, Biff Gaut, Bob Tordella, Jon Udell, Spot Callaway, Sébastien Stormacq, Deepak Kovvuri, Bharath Gajendran, Pawan Shrivastava, Ravi Thakur, Sagar Das, Sreedevi Velagala, Aaron Miller, Praseeda Sathaye, Vijay Chintalapati, Yuzhu Xiao, Xin Zhang, Quinn Cheong, Philipp Garbe, Yvo van Zee, Matt Camp, Franck Pachot, Vadym Kazulkin, Paul Schwarzenberger, Sean Kane, and Omshree Butani.
Feedback
Please please please take 1 minute to complete this short survey.
Stay in touch with open source at AWS
Remember to check out the Open Source homepage for more open source goodness.
One of the pieces of feedback I received in 2023 was to create a repo where all the projects featured in this newsletter are listed. Where I can hear you all ask? Well as you ask so nicely, you can meander over to newsletter-oss-projects.
Made with ♥ from DevRel