AWS open source newsletter #182
December 11th, 2023 - Instalment #182
Welcome to #182 of the AWS open source newsletter, the place for all your AWS and open source needs. This is a special re:Invent packed edition of this newsletter, attempting to catch up and cover all the main talking points, sessions, and announcements. Whilst there is a lot of content to go through, I know that many of you will still be wanting to know about new projects you can try out, and the good news is that we have plenty.
We have some really great new projects for you to try out over the festive period. We have tools to help you assess and analyse your serverless components in use, a new SDK for NodeJS developers, a tool that simplifies providing access to Kubernetes resources, a database scheme validation project, a new Kubernetes csi for Amazon S3, as well as sample projects that include a really cool reference solution for regional data residency, the serverlessvideo project (you might have seen this during re:Invent), and a couple of demo repositories that are using generative AI (I particularly like the travel itinerary generator project).
From projects to prose, as always, we feature a diverse range of open source technologies in this edition. Projects covered include Redis, Go, MLFlow, MySQL, PostgreSQL, MariaDB, dbt, OpenRewrite, Amazon Corretto, Amazon EMR, lakeFS, Apache Kafka, Memecached, Grafana, GraphQL, Code-OSS, Rust, Kotlin, FreeRTOS, Prometheus, Kubernetes, Amazon EKS, OpenZFS, OpenSearch, AWS Distro for OpenTelemetry, AWS CDK, Powertools for Lambda, Jupyter, and cdk8s.
This is the last issue of 2023, but don’t panic, we will be back in January 2024 for more open source goodness. Before I leave you, I just wanted to say a big thank you to all you readers for coming back week after week. I really appreciate it, and it keeps me going. Until the next issue, enjoy the holiday season, rest and recharge and will see you all very soon.
Feedback
If you would love to give me an early Christmas present, then why not take a minute to complete this short survey.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Allan Chua, Benjamin Chastanier , Abhishek Gupta, Cristian Magherusan-Stanciu, Efi Merdler-Kravitz , Adam North, Sam Clark, Ronald Bradford, Matan Bordo, Viktor Vedmich, Mike Golubev, Imaya Kumar Jagannathan, Gustavo Franco, Marc Chene, Heitor Lessa, Ran Isenberg, Piyush Jain, Jason Weill, Jonathan Katz, Matthew Bonig, Donnie Prakoso, Aaron Todd, Zelda Hessler, Eric Peña, Bruno Pistone, Giuseppe Angelo Porcelli, Sofian Hamiti, Vikesh Pandey, Danilo Poccia, Noritaka Sekiyama, Akira Ajisaka, Jason Ganz, Kinshuk Pahare, Benjamin Menuet, Dave Comer, Jeff Li, Shunan Xiang, Yuli Khodorkovskiy, Rajat Jain, Rohan Bhatia, Eric Felice, and Rinisha Marar.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
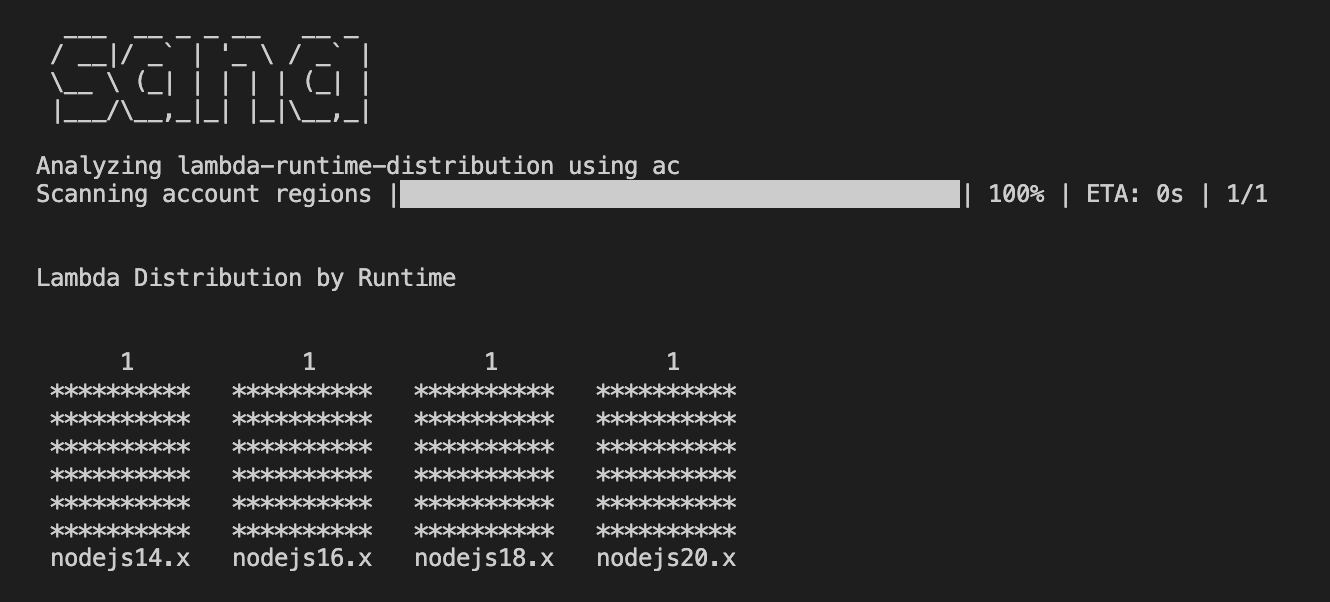
sana
sana is a new project from AWS Community Builder Allan Chua that hopes to bring more sana-ty (did you see what I did there), to serverless developers. It is a command line tool for analyzing account-wide serverless components. Alan is looking for feedback, so try it out (great documentation with lots of examples) and let him know.
aws-lite
aws-lite is simple, fast, extensible Node.js client for interacting with AWS services. It is developed and maintained by the folks at OpenJS Foundation Architect, and you can think of it as a community-driven alternative to AWS’s JavaScript SDK. If you are a node developer and looking to explore the options you have for interacting with AWS services, why not check this out.
iam-eks-user-mapper
iam-eks-user-mapper is another open source tool from the fine folks at Qovery, that automatically gives AWS IAM users access to your Kubernetes cluster. Check out the supporting blog post, Releasing IAM EKS User Mapper in open-source, where Benjamin Chastanier shares more about how this tool can help you manage AWS IAM user access to Kubernetes clusters efficiently and securely.

multi-database-schema-validator
multi-database-schema-validator is a Python based too to help you with database migration. Schema validation plays a vital role during migration, and this Python based validation tool helps in finding the gaps between source and target database objects like Tables, Views, Indexes, Keys, Stored procedures, Functions, Triggers and Sequences with encrypted connection. It generates an output summary and a detailed report in formats such as Microsoft Excel (xlsx) and html. The report explains the object level match percentage (%) per database, per schema and list of missing objects at target referring to the source.
The blog post, Automate the schema validation process for multiple databases like SQL Server, Oracle, PostgreSQL, and MySQL databases using Python explains how to validate the database objects post-migration for multiple databases like SQL Server, Oracle, PostgreSQL, and MySQL databases using the [hands on]

aws-redis-iam-auth-provider-golang
aws-redis-iam-auth-provider-golang is a project from my colleague Abhishek Gupta that helps you authenticate Go apps to Redis on AWS using IAM. Find out more and how to use it by reading Abhishek’s post, Using IAM authentication for Redis on AWS
assume_role_with_mfa
assume_role_with_mfa is a handy small MFA GUI tool from Cristian Magherusan-Stanciu designed to be used as credential_proces for AWS CLI configuration profiles. This is a workaround for the official AWS MFA setup, that works for the CLI but does not work for the Go SDK, as reported at aws-sdk-go-v2/#2356.
mountpoint-s3-csi-driver
mountpoint-s3-csi-driver the Mountpoint for Amazon S3 Container Storage Interface (CSI) Driver allows your Kubernetes applications to access Amazon S3 objects through a file system interface. Built on Mountpoint for Amazon S3, the Mountpoint CSI driver presents an Amazon S3 bucket as a storage volume accessible by containers in your Kubernetes cluster. The Mountpoint CSI driver implements the CSI specification for container orchestrators (CO) to manage storage volumes. For Amazon EKS clusters, the Mountpoint for Amazon S3 CSI driver is also available as an EKS add-on to provide automatic installation and management.
Demos, Samples, Solutions and Workshops
DREM
drem also known as the AWS DeepRacer Event Manager (DREM) is used to run and manage all aspects of in-person events for AWS DeepRacer, an autonomous 1/18th scale race car designed to test reinforcement learning (RL) models by racing on a physical track. DREM offers event organizers tools for managing users, models, cars and fleets, events, as well as time recording and leaderboards. Race participants also use DREM to upload their RL models.

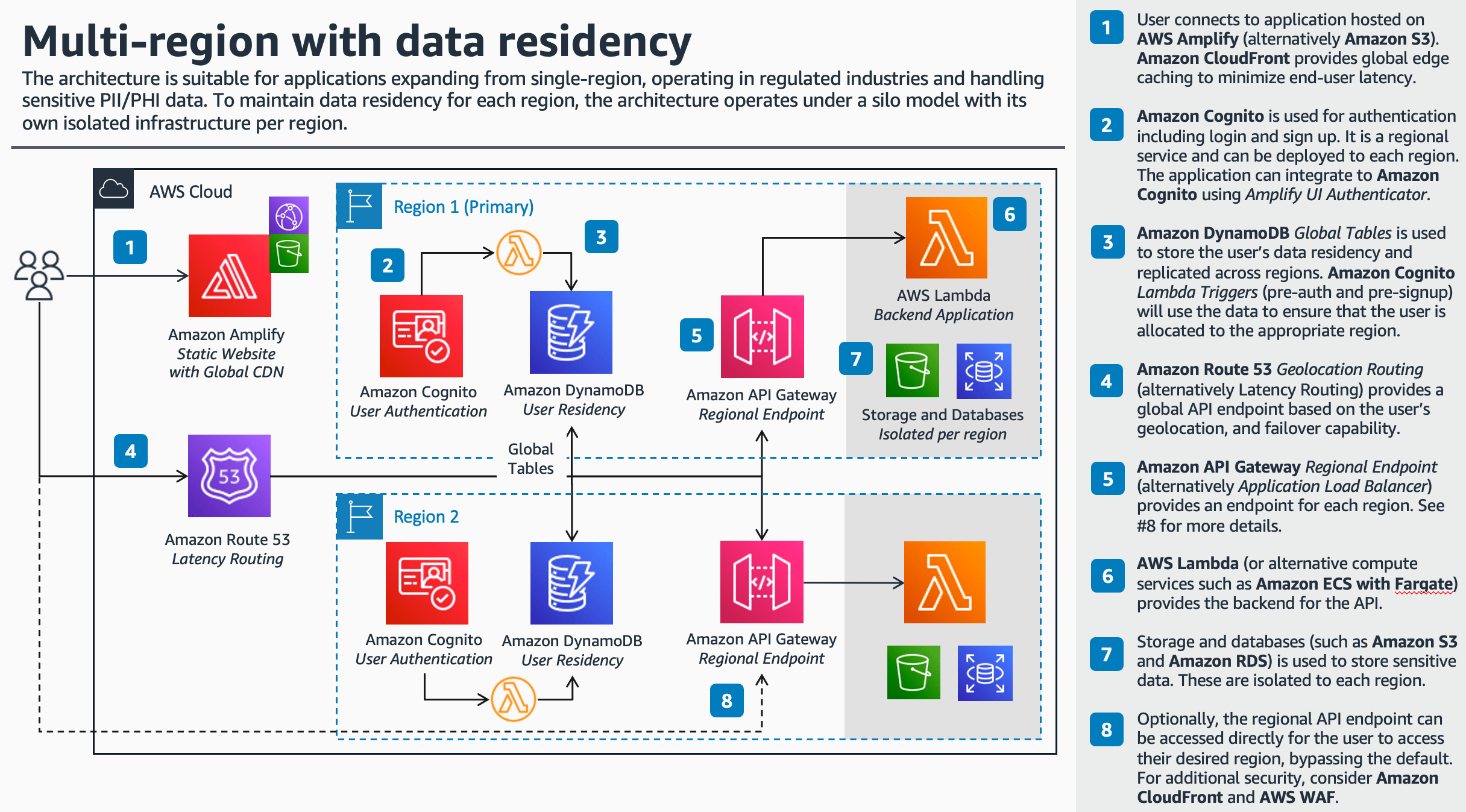
multi-region-data-residency
multi-region-data-residency This repository demonstrates how to deploy a multi-region architecture with data residency for sensitive data, such as Personally Identifiable Information (PII) or Personal Health Information (PHI) data. To maintain data residency for each region, the architecture operates under a silo model with its own isolated infrastructure stack per region. The architecture is suitable for businesses in specific verticals such as Health-care / Life-sciences (HCLS) and FinTech, with business requirements to isolate customer PII/PHI data to a specific region, expanding globally from a single-region architecture, and/or operating in strict regulatory or compliance environments.
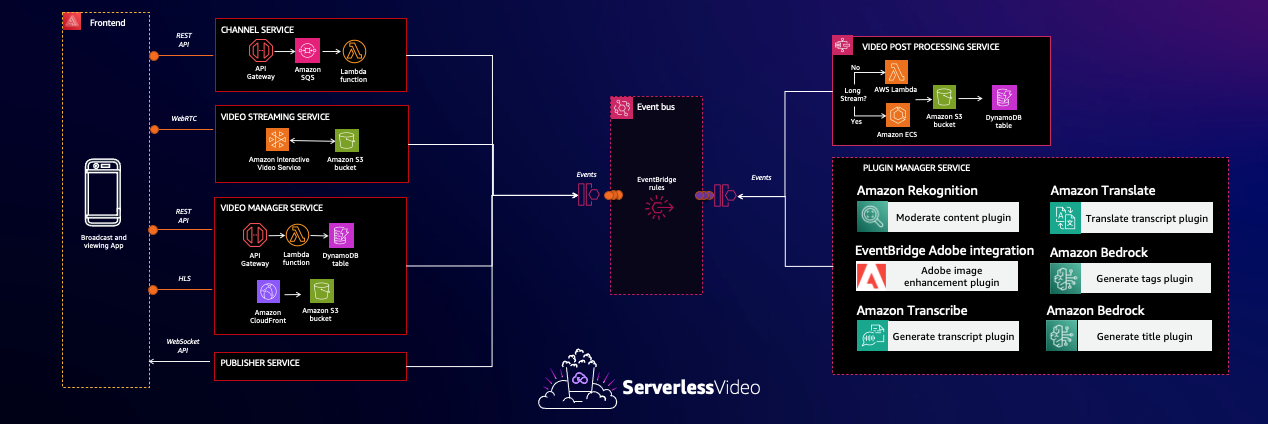
serverless-video
serverless-video if you were at re:Invent you might have seen (or even recorded) a video using this project. This new demo is an event-driven video streaming application called serverlessVideo. serverlessVideo is a best practices example of a cost-effective serverless video streaming application built on a microservices architecture. serverlessVideo enables AWS users to broadcast live video content directly from their cell phones. At the same time, viewers can access live streams and watch on-demand videos. Additionally, serverlessVideo encourages serverless developers to extend the application’s functionality by creating custom plugins that hook into the application’s event driven architecure.
Check out the README for a very detailed description of the architecture and a break down of the microservices involved in delivering this demo. Very nice indeed.
rustifying-serverless
rustifying-serverless AWS Hero Efi Merdler-Kravitz shares how to use Rust in your existing Serverless projects, which is code that he used in his re:Invent talk (COM306: “Rustifying” serverless: Boost AWS Lambda performance with Rust)
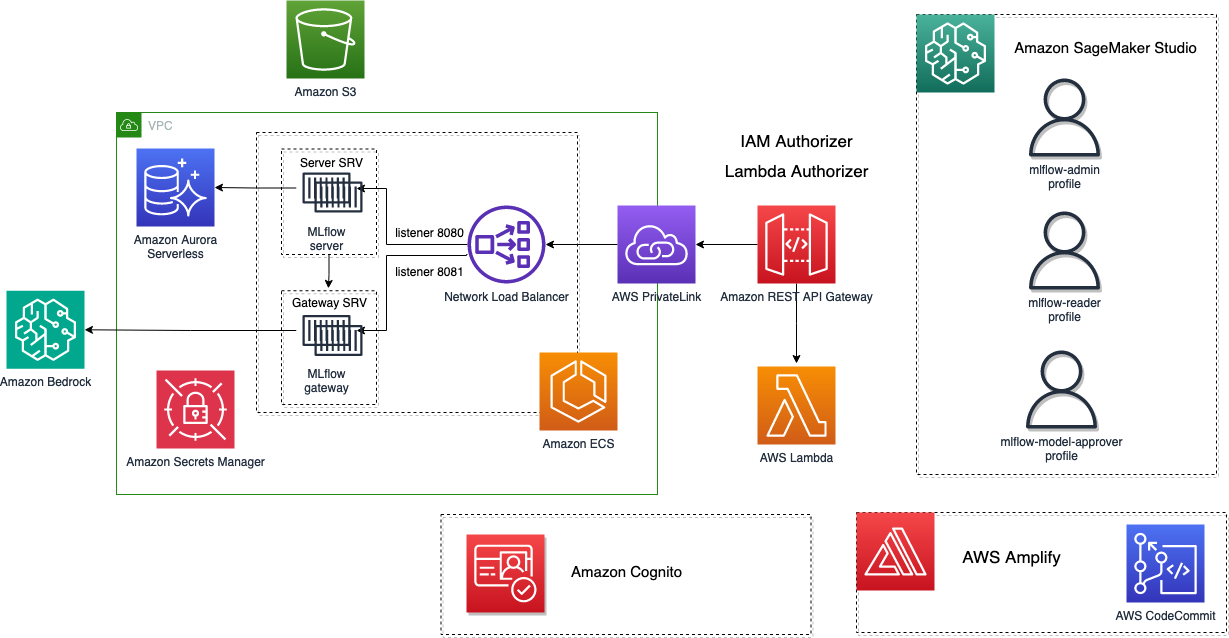
sagemaker-studio-mlflow-integration
sagemaker-studio-mlflow-integration provides an great guide on how to deploy the popular open source project, MLFlow on AWS. The repo is regularly updated to align with the latest release on MLflow. The current last supported version of MLflow is 2.8.1, including MLflow tracking server and MLflow Gateway AI.
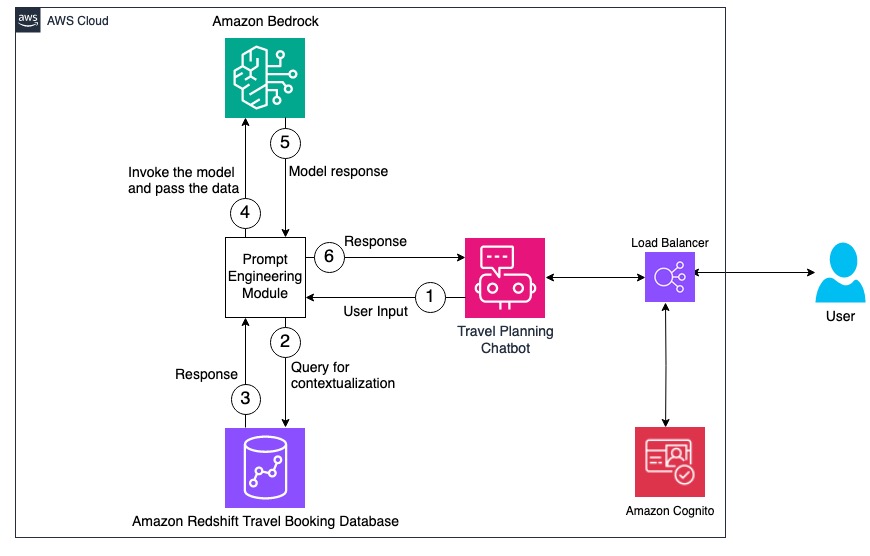
personalized-travel-itinerary-planner
personalized-travel-itinerary-planner as we head into the holiday season, what perfect demo to try out than a tool that uses generative AI to provide personalised travel recommendations. This solution contains two major components. At first, we will extract the user’s information like Name, location, hobbies, interests and Favourite food etc along with their upcoming travel booking details. With this information we will stitch a user prompt together and pass it to Amazon Bedrock/Anthropic Claude LLM to obtain a personalized travel itinerary that the Customers can use. Below architecture diagram provides us a high level overview of the workflow and the components involved in this architecture.
aws-bedrock-with-rag-and-react
aws-bedrock-with-rag-and-react rag and react is not some new dance genre (maybe it should be!) but a new demo project that helps you quickly and inexpensively begin prototyping and vetting business use cases for GenAI using a custom corpus of knowledge with Retrieval Augmented Generation (RAG) in a low-code ReactJS application. This solution contains a backend Flask application which uses LangChain to provide PDF data as embeddings to your choice of text-gen foundational model via Amazon Web Services (AWS) new, managed LLM-provider service, Amazon Bedrock and your choice of vector database with FAISS or a Kendra Index.
AWS and Community blog posts
Advanced JDBC Wrapper Driver
The Amazon Web Services JDBC Driver is an open sourced, advanced JDBC wrapper. This wrapper is complementary to and extends the functionality of an existing JDBC driver to help an application take advantage of the features of clustered databases such as Amazon Aurora. We featured this project in #174 but if you want to know more about this driver, then Dave Cramer has put together essential reading in his post, Achieve one second or less downtime with the Advanced JDBC Wrapper Driver when upgrading Amazon RDS Multi-AZ DB Clusters as he explores how to use the driver to handle the failover of an Amazon Aurora cluster. [hands on]
PostgreSQL
We had plenty of great content for PostgreSQL fans over the last couple of weeks.
To start we have Jeff Li and Shunan Xiang who show you four architectures to store business objects with array data fields to a PostgreSQL database in the post, Architectures for managing array data in PostgreSQL. They explore table design, its effects on applications and data migration jobs, and also show how to search and filter database records based on array values and what options are available to improve operation performance.
If you are looking for options and ideas to minimise downtime for your PostgreSQL upgrades, then check out Fast switchovers with PgBouncer on Amazon RDS Multi-AZ deployments with two readable standbys for PostgreSQL from Yuli Khodorkovskiy and Rajat Jain. They demonstrate how you can typically achieve less than one second of write downtime during a minor version upgrade on an Amazon RDS Multi-AZ cluster for PostgreSQL using the patches for PgBouncer from AWS. [hands on]
The last post in this round up is from Rohan Bhatia, Eric Felice, and Rinisha Marar who have put together Using write forwarding with Amazon Aurora Global Database for PostgreSQL. In this post they show you how to enable and use the write forwarding feature within an Aurora Global Database for PostgreSQL to provide benefits for your application in terms of scalability, geographic load balancing, disaster recovery, and cost optimization. Read the post to understand more about write forwarding and where you might find it beneficial.

dbt
dbt is an open source, SQL-first templating engine that allows you to write repeatable and extensible data transforms in Python and SQL. In the post, Build and manage your modern data stack using dbt and AWS Glue through dbt-glue, the new “trusted” dbt adapter Noritaka Sekiyama, Akira Ajisaka, Jason Ganz, Kinshuk Pahare, and Benjamin Menuet come together to talk about dbt-glue, and open source battle-tested dbt AWS Glue adapter, that is now a trusted adapter based on our strategic collaboration with dbt Labs. [hands on]

OpenRewrite
OpenRewrite is an open source project that helps developers refactor code. Amazon Q Code Transformation uses parts of OpenRewrite to help developers transform their code, and in the post Upgrade your Java applications with Amazon Q Code Transformation (preview) my colleague Danilo Poccia shows how you can use Amazon Q to help you migrate and refactor codes, using a Java 8 to Java 17 example application. This is really cool stuff, as there are so many good features with newer versions of OpenJDK that this could be a great way to finally start upgrading some of your older code bases.

Other posts and quick reads
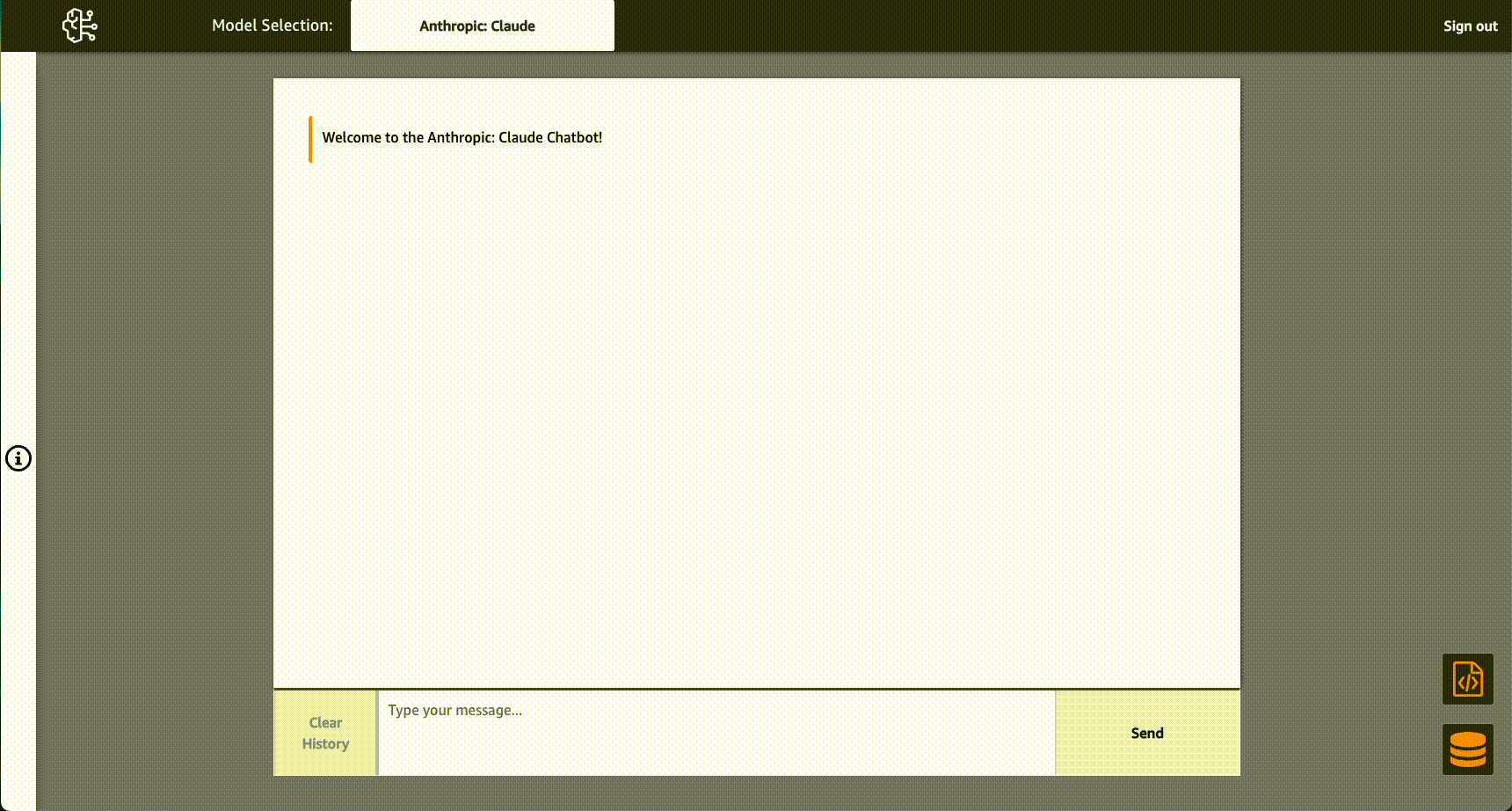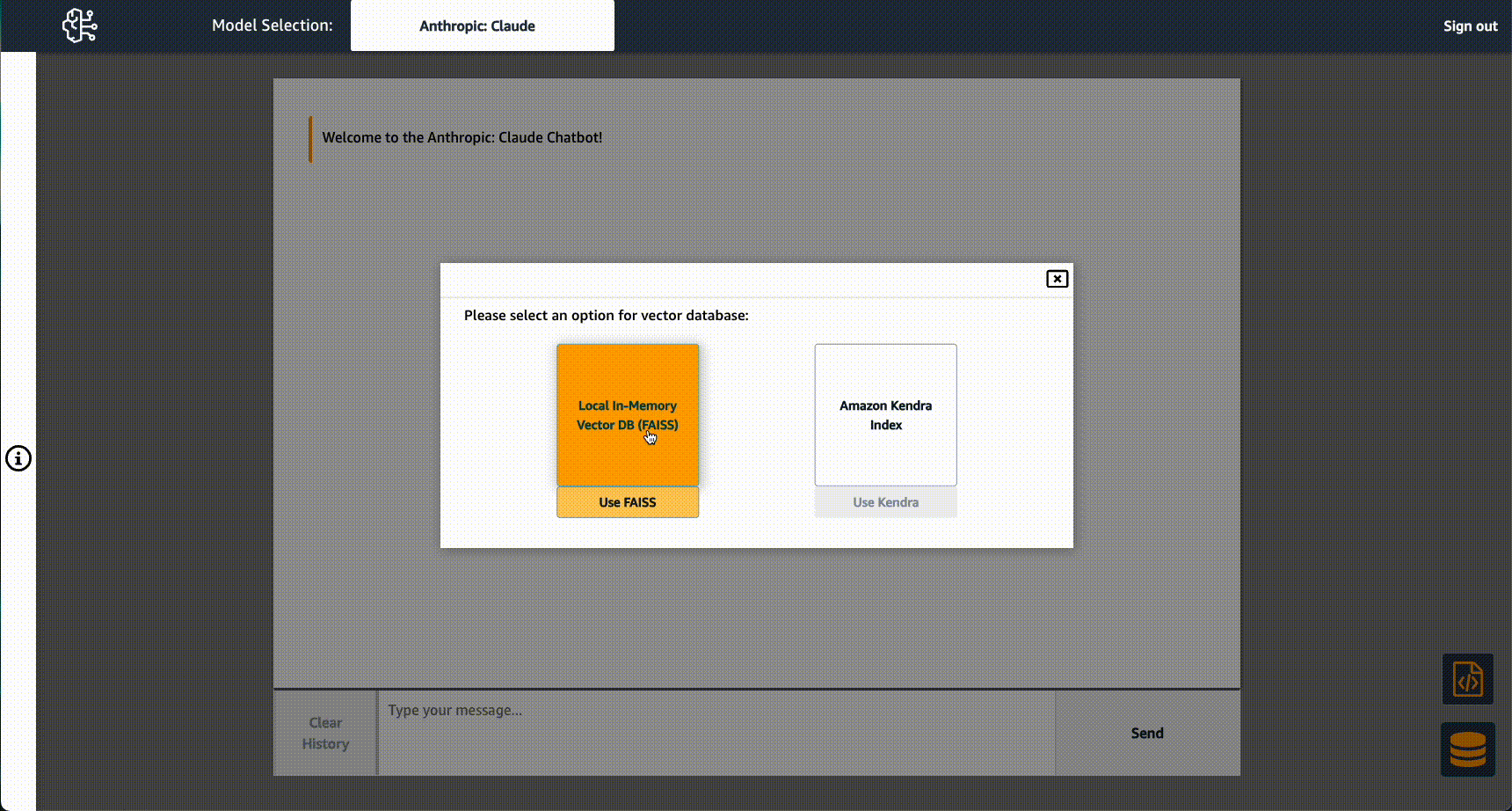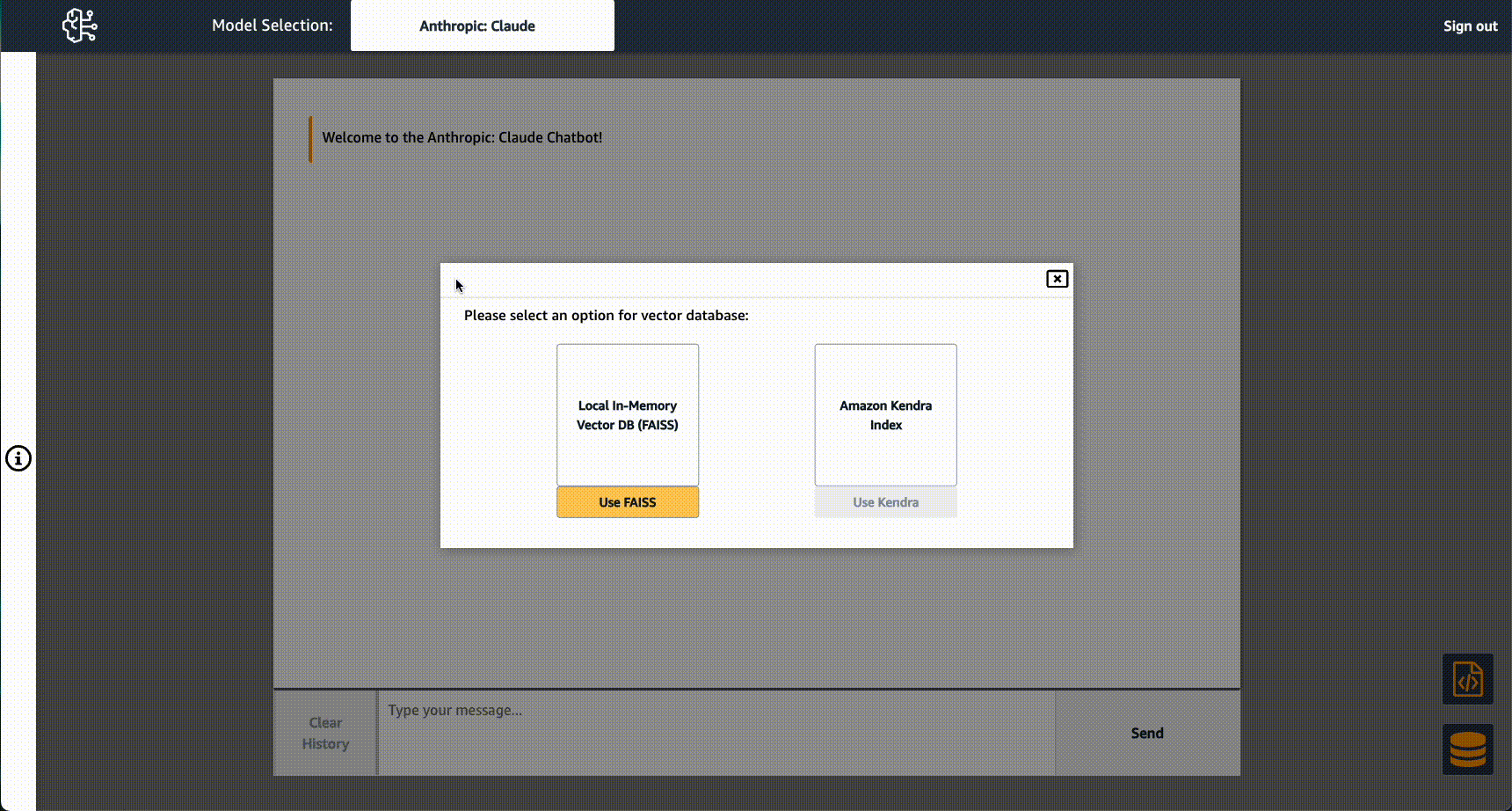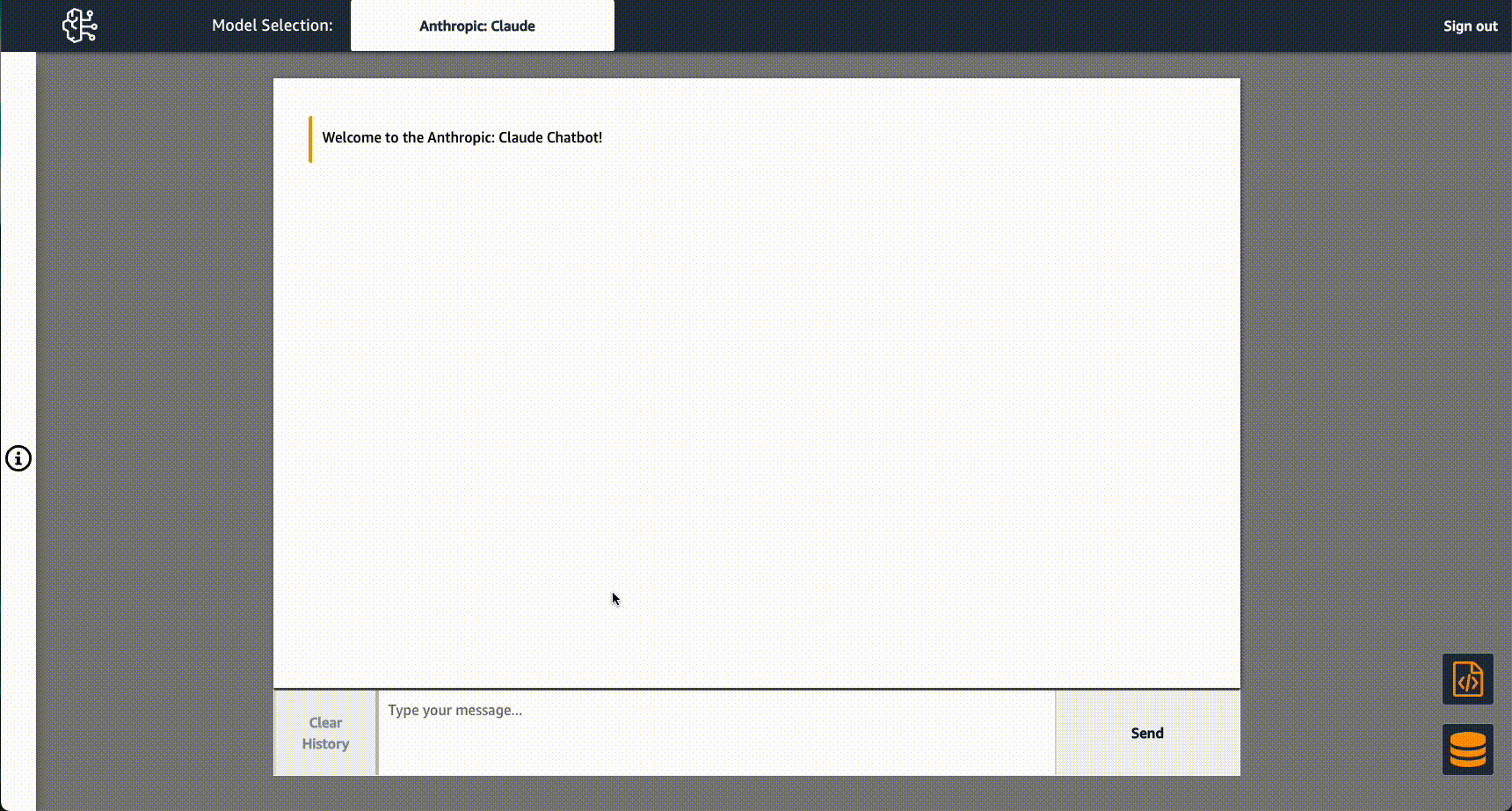
- Use Amazon EMR with S3 Access Grants to scale Spark access to Amazon S3 provides a hands on guide to how to set up and use Amazon S3 Access Grants with Amazon EMR in order to easily manage data access for your Amazon EMR workloads [hands on]
- lakeFS and Amazon S3 Express One Zone: Highly performant data version control for ML/AI dives into data versioning on Amazon S3 with lakeFS, showing how lakeFS uses Amazon S3 Express One Zone to deliver up to 10x faster versioning operations within lakeFS [hands on]
- Use Amazon FSx for Lustre to share Amazon S3 data across accounts guides you through the process of seamlessly integrating an Amazon FSx for Lustre file system with an Amazon S3 data lake [hands on]

- Amazon MSK now provides up to 29% more throughput and up to 24% lower costs with AWS Graviton3 support looks at the performance gains achieved while using Graviton-based M7g instances with your Apache Kafka clusters
- Amazon ElastiCache Serverless for Redis and Memcached is now available takes a look at the re:Invent announcement of Amazon ElastiCache Serverless for Redis and Memcached [hands on]
- Solutions for building modern applications with Amazon ElastiCache and Amazon MemoryDB for Redis explores a number of different use cases and applications of how to build highly scalable modern applications using in-memory database solutions like ElastiCache and MemoryDB

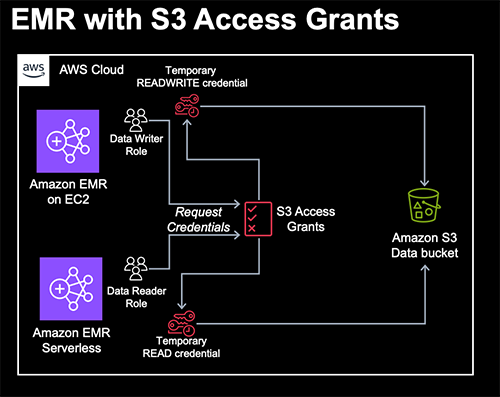
- Visualize AWS Health events using Amazon Managed Grafana will show you how to visualise AWS Health (a service that helps you stay informed about the status of your AWS resources and services) events using Amazon Managed Grafana to gain deeper insights across multiple Health events in a centralized place [hands on]
- Create a GraphQL API for any existing MySQL and PostgreSQL database provides a hands on guide on how to create a new GraphQL API using AWS CDK to create queries and mutations that run SQL statements with MySQL and PostgreSQL databases [hands on]

- Build a GraphQL API for your Amazon Aurora MySQL database using AWS AppSync and the RDS Data API goes through the process of creating an AppSync GraphQL API from an existing MySQL database [hands on]
Quick updates
Code-OSS
During re:Invent, a new integrated development environment (IDE) option was launched in Amazon SageMaker Studio: Code Editor. It is based on Code-OSS (Visual Studio Code – Open Source). To find out more, Eric Peña, Bruno Pistone, Giuseppe Angelo Porcelli, Sofian Hamiti, and Vikesh Pandey have put together New – Code Editor, based on Code-OSS VS Code Open Source now available in Amazon SageMaker Studio, that helps you get started.

Rust
Zelda Hessler announced the general availability of the AWS SDK for Rust in the post, Announcing general availability of the AWS SDK for Rust. Check it out to find out how to get started, how to contribute to the SDK development, and what is on the public roadmap.
Kotlin
We had good news for Kotlin developers too, with the announcement of the general availability of the AWS SDK for Kotlin. Aaron Todd shares more details in the post, Announcing general availability of the AWS SDK for Kotlin and covers some of the high level features as well as sharing links to the roadmap.
FreeRTOS
FreeRTOS is an open-source, cloud-neutral real-time operating system for microcontrollers and microprocessors that offers a fast, dependable, and responsive kernel, making it easy for you to design and develop cloud-connected IoT devices. An update that some of you might have missed is that the FreeRTOS roadmap is now published on freertos.org and GitHub. With this update, you can transparently access information on specific FreeRTOS features and have a consolidated view of upcoming, ongoing, and shipped FreeRTOS projects to plan your projects accordingly. In addition, you can track the status of your requested FreeRTOS features or the projects you have volunteered to work on.
FreeRTOS announced the availability last week of modular and composable Over-The-Air update (OTA) libraries that make it easy for you to configure and customize the system update process for your Internet of Things (IoT) devices. Using FreeRTOS OTA libraries, you can quickly build connected products capable of seamlessly processing remote firmware update tasks, thus allowing you to manage and maintain your device fleet to be up to date. With the new update, you can now configure FreeRTOS open source OTA libraries in small batches for better flexibility as compared to using a large library that may require base-code modification. For example, to retain operational integrity and continuity of your deployed IoT devices, you can now configure your modular FreeRTOS libraries to first require the device to be in a ‘safe’ or ‘commissioning’ mode and only then accept and process software update messages.
Prometheus
Announced last week was the Amazon Managed Service for Prometheus collector, a fully-managed agentless collector customers can use to collect Prometheus metrics from their workloads running on Amazon EKS. Customers can now enable the discovery and collection of Prometheus metrics from their Amazon EKS applications and infrastructure through the EKS console or through an API call, without having to self-manage agents.
Customers currently invest days, if not weeks, of effort to monitor, right-size, and operate Prometheus agents. Now with Amazon Managed Service for Prometheus collector, customers can automatically discover and collect Prometheus metrics from their Amazon EKS applications, infrastructure, and the Kubernetes apiserver without having to install any agents in their cluster. The fully-managed collector removes the “undifferentiated heavy lifting” of installing, patching, scaling, and upgrading agents for the discovery and collection of Prometheus metrics. The collector provides customers with a multi-AZ, highly available, reliable, and fully-managed service for collecting Prometheus metrics without any data ever leaving secure VPCs.
Kubernetes
If you have spent any time working with Kubernetes on AWS, you will be familiar with having to work with IAM roles for service accounts (IRSA). To make developers lives easier, Amazon EKS introduced EKS Pod Identity last week, which is a new feature that simplifies how cluster administrators can configure Kubernetes applications to obtain AWS IAM permissions. These permissions can now be easily configured with fewer steps directly through EKS console, APIs, and CLI. EKS Pod Identity makes it easy to use an IAM role across multiple clusters and simplifies policy management by enabling the reuse of permission policies across IAM roles.
EKS Pod Identity offers cluster administrators a simplified workflow for authenticating applications to all AWS resources such as Amazon S3 buckets, Amazon DynamoDB tables, and more. As a result, cluster administrators need not switch between the EKS and IAM services, or execute privileged IAM operations to configure permissions required by your applications. IAM roles can now be used across multiple clusters without the need to update the role trust policy when creating new clusters. IAM credentials supplied by EKS Pod Identity include support for role session tags, with support for attributes such as cluster name, namespace, service account name. Role session tags enable administrators to author a single permission policy that can work across roles by allowing access to AWS resources based on matching tags.
My colleague Donnie Prakoso put together a nice post to walk you through it. Check it out, Amazon EKS Pod Identity simplifies IAM permissions for applications on Amazon EKS clusters.

OpenZFS
AWS announced on-demand data replication for Amazon FSx for OpenZFS, enabling you to easily and efficiently transfer incremental point-in-time snapshots of your volumes between file systems. On-demand data replication provides a simple and resilient way to replicate production data in a separate file system for development, experimentation, and analytics workloads.
Amazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system, with rich OpenZFS-powered data management capabilities like snapshots, data cloning, and compression, as well as sub-millisecond latencies and up to 10 GB/s of throughput. Previously, you could use snapshots to replicate volumes within a file system, making it quick and easy to test new changes to your data and applications. Now, you can also replicate volumes across file systems, enabling full isolation of production and development workloads, so developers or analysts can work with production data without impacting the production environment.
You can replicate volumes across file systems in the same account and region in all regions where FSx for OpenZFS is available. There is no charge for on-demand data replication, but you will pay standard AWS data transfer charges when you replicate across availability zones from or to a Single-AZ file system.
Read Announcing on-demand data replication for Amazon FSx for OpenZFS to dive deeper into this new capability.
OpenSearch
OpenSearch Service 2.11 now comes with OpenSearch Neural Sparse Retrieval. Search practitioners now have an additional search method to use for their search applications with improved semantic understanding, while keeping computational cost and computational latency low, more in line with lexical search.
Neural Sparse Retrieval is a new kind of sparse embedding method, similar in many ways to classic term-based indexing, but with a better understanding of low-frequency words and phrases. Neural Sparse Retrieval uses transformer-based models (e.g. GPT or BERT) to build information-rich embeddings which solve for the lexical challenge with vocabulary mismatch in a scalable way. This new sparse retrieval functionality with OpenSearch Service offers document-only mode and bi-encoder mode, each with different advantages. Document-only mode can deliver low-latency performance more comparable to lexical search, with limitations for advanced syntax as compared to dense methods. Bi-encoder mode maximizes search relevance while performing at higher latency. With this update, users can now choose the method that works best for their performance, accuracy, and cost requirements.
AWS Distro for OpenTelemetry
In case you missed it, just before re:Invent, we announced the general availability of logs in the AWS Distro for OpenTelemetry (ADOT). ADOT is a secure, production-ready, AWS supported distribution of the OpenTelemetry project. With this launch, customers can use the ADOT collector and supported OpenTelemetry SDKs (for Java, JavaScript, .NET, and Python) to collect and send logs to Amazon CloudWatch and backends supporting OpenTelemetry Protocol (OTLP) such as Amazon OpenSearch (AOS).
Customers can now use ADOT to collect all telemetry data from their containerized AWS workloads running in Amazon Elastic Kubernetes Service (EKS) and Amazon Elastic Container Service (ECS) in a standardized manner. By adding support for the Filelog receiver and the AWS CloudWatch Logs exporter to the ADOT collector, you now have a reliable way to collect application logs and ingest them into observability backends. AWS delivers security patches and provides support for logging use cases with this launch. For example, by configuring the ADOT collector in an EKS cluster, using the EKS add-on, you can collect logs from a variety of sources including Syslog and Log4j. At the same time, you can get out-of-the-box metadata enrichment based on OpenTelemetry’s semantic conventions, which enables you to improve correlation of the logs with metrics and traces.
Videos of the week
re:Invent special
To help you make sure you do not miss the best open source related content from re:Invent, this week I feature a re:Invent special, with what I think are the pick of the bunch. More videos are being added, so I will add those as and when they become available in future issues of this newsletter. Until then, enjoy these gems.
COM302: Advanced AWS CDK: Lessons learned from 4 years of use
Matthew Bonig delivered a masterclass in presenting with one of my favourite sessions (and topics) on AWS CDK. Matthew dives deep as he shares lessons learnt, best practices, patterns, and workflows developed over the last 4 years of using AWS CDK.
OPN302: AWS open source strategy and contributions for PostgreSQL
PostgreSQL is a popular open source relational database that is available on Amazon RDS and Amazon Aurora and also helps power Amazon.com. Given the importance of PostgreSQL to Amazon and AWS users, AWS is committed to investing in PostgreSQL to help both the project and its builder community be successful. Jonathan Katz explores what the general open source strategy is for AWS with PostgreSQL and how AWS contributes, including features in recent PostgreSQL releases, upcoming releases and roadmap, and how AWS supports related PostgreSQL projects including extensions like PostGIS, pgvector, pg_tle, and more.
I would also recommend you check out Jonathan’s 400 level session, Best practices for querying vector data for gen AI apps in PostgreSQL, which was one of my favourite sessions that I watched. This goes super deep, but Jonathan has a nack of explaining things so well, that you don’t realise how deep you have just been!
OPN203: Jupyter AI: Open source brings LLMs to your notebooks
At AWS, our developers built Jupyter AI, an open source project to connect JupyterLab with generative AI large language models (LLMs) like Amazon Titan and OpenAI’s gpt-3.5-turbo (used in ChatGPT). Piyush Jain and Jason Weill explore how you can use the power of these models to become more productive. Learn from several use cases, including code refactoring, debugging, code explanation, and answering common questions, about how Jupyter AI can answer questions based on user input, help explain and fix code errors, and learn from and answer questions about local data files. Announced at JupyterCon 2023, Jupyter AI is available as free, open source software.
OPN305: The pragmatic serverless Python developer
Heitor Lessa and Ran Isenberg dive deep into lots of open source tools, including Powertools for AWS Lambda—a toolkit that can help you implement serverless best practices and increase developer velocity in this essential session for Python developers.
COP332: Operating with AWS open source observability
Open standards are becoming a popular mechanism for implementing observability for organizations that adopt the OpenTelemetry CNCF project. Imaya Kumar Jagannathan, Gustavo Franco, and Marc Chene co present this session on how to incorporate Amazon Managed Grafana, Amazon Managed Service for Prometheus, and Amazon OpenSearch Service for storage and analysis of the three core dimensions of observability: metrics, logs, and traces.
BOA310: New era of IaC: Effective Kubernetes management with cdk8s
Cloud Development Kit for Kubernetes (cdk8s) helps you use your favourite programming language to write secure and well-architected Kubernetes applications. My colleague Viktor Vedmich and Mike Golubev show you how to use AI code assistant Amazon CodeWhisperer to help write cdk8s code for validation of manifests against organizational policies and to revolutionize your deployment processes, promoting consistency and efficiency across development teams. You will see of the power of cdk8s and CodeWhisperer in action to avoid misconfigurations and costly mistakes. Very cool.
Podcast
It has been a while since I have featured a pod cast (not sure why, my bad! expect me to be sharing more of these in 2024) but I enjoyed the conversation between Adam North, Sam Clark, Ronald Bradford, and Matan Bordo who talk about lessons learned from upgrading MySQL wtih Amazon RDS managed services.
You can check out the podcast page, Mastering EOL Migrations: Lessons learned from MySQL 5.7 to 8.0 with RDS managed services which provides links to your favourite podcast consuming channels, or alternatively check out the video below.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
FOSDEM Brussels, Belgium 3rd and 4th February, 2024
FOSDEM is a free event for software developers to meet, share ideas and collaborate. Every year, thousands of developers of free and open source software from all over the world gather at the event in Brussels. You don’t need to register. Just turn up and join in!
Find out more by heading to the site home page, FOSDEM 24
SOOCon 24 London, UK 7th and 8th February, 2024
The State of Open Conference is back in the new year, and what better opportunity to combine with your trip to Fosdem, than come along to the wonderful Brewery in the City of London and catch up with the hundreds of open source developers, enthusiasts, hackers, and more. Check out the event page, and if you are so inclined, there is still chance to submit a talk as the call for papers (cfp) is open until the 15th of December.
You can view more at the site page, SOOCon24
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen