AWS open source newsletter #181
November 27th, 2023 - Instalment #181
Welcome to #181 of the AWS open source newsletter, the place for all your AWS and open source needs. As some of you will know, this is re:Invent week, where many of my colleagues and tens of thousands of developers will be congregating to learn about Cloud, and hopefully discover plenty of open source goodness too. If you are going, make sure to visit the open source booth in the Expo floor. There is going to be a steady flow of great demos throughout the week, so check out the schedule which will be posted in the booth, as well as get to meet some of the open source folk at AWS. I wish I could be there, but alas, not this year. So if you are going to re:Invent, have a blast. It is such an amazing opportunity to meet fellow developers and find out about and learn lots of new cool things. Make sure you check out reinvent-session-concierge from Caylent (down below in the Demos section), your personal re:Invent concierge, and a really great idea.
Aside from that project, we have lots of other great new projects this week including a new library for PyTorch users to make it easier to work with Amazon S3, some Rust based CloudFormation macros, an AWS account “kill switch”, and demos that include some really nice generative AI projects that use open source tools such as Griptape. No newsletter is complete without a selection of great blog posts and articles to read, and this week we have some great hands on content that covers projects from a broad range of use cases, including Griptape, PyTorch, AWS Amplify, NextJS, WordPress, OpenJDK, Amazon Corretto, PostgreSQL, OpenSearch, SnapStart, Kong, AWS Copilot, MySQL, dbt, Apache Hudi, Apache Flink, Kubernetes, Amazon EKS, Kali, Karpenter, Istio, LangChain, Pinecone, Amazon EMR, Apache Spark, Prometheus, Lustre, OpenZFS, and Apache Kafka. There is so much great stuff, you will be kept very busy this week.
Before you dive into this week edition, I just wanted to share that there will be one more newsletter before I finish for the year, so watch out for the special end of year edition on Monday, 11th of December. I will be back in January, but will be enjoying some time away to rest and recharge.
AWS open source newsletter in Spanish
My colleague Guillermo Ruiz has been busy creating a monthly version of this newsletter for you Spanish readers out there. Much better than my poorly translated editions, this is your perfect guide to the best open source content for those of you who prefer to read in castellano. Go check it out, Boletín AWS Open Source, November Edition
Feedback
Please please please take 1 minute to complete this short survey. I have AWS credit codes for the first 50 as a thank you!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Efi Merdler-Kravitz, Jeffrey Lyon, Alex Pust, Salam Shaik, Rahul Pulikkot Nath, Sophia Parafina, Vadym Kazulkin, Alexander Rey, Jason Andrews, Nikhil Swaminathan, Danny Banks, Erik Hanchett, Stephen Siegert, Sunil Ramachandra, Julie Mills, James Eastham, and Damon Cortesi
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
s3-connector-for-pytorch
s3-connector-for-pytorch the Amazon S3 Connector for PyTorch delivers high throughput for PyTorch training jobs that access or store data in Amazon S3. Using the S3 Connector for PyTorch automatically optimises performance when downloading training data from and writing checkpoints to Amazon S3, eliminating the need to write your own code to list S3 buckets and manage concurrent requests. Amazon S3 Connector for PyTorch provides implementations of PyTorch’s dataset primitives that you can use to load training data from Amazon S3. It supports both map-style datasets for random data access patterns and iterable-style datasets for streaming sequential data access patterns. The S3 Connector for PyTorch also includes a checkpointing interface to save and load checkpoints directly to Amazon S3, without first saving to local storage.
cloudwatch-macros
cloudwatch-macros is the latest open source creation from AWS Hero Efi Merdler-Kravitz, focused on improving the CloudFormation and AWS SAM developer experience. This project features a collection of (basic at the moment) CloudFormation macros, written in Rust, offering seamless deployment through SAM. Check out Efi’s post on LinkedIn for more details and additional useful resources.
awskillswitch
awskillswitch is an open sourced tool from Jeffrey Lyon that is worth checking out. AWS Kill Switch is a Lambda function (and proof of concept client) that an organisation can implement in a dedicated “Security” account to give their security engineers the ability to delete IAM roles or apply a highly restrictive service control policy (SCP) on any account in their organisation. Make sure you check out the README for full details, but this looks like it might be one of those tools that are useful to have in the back pocket in times of need.
pagemosaic-website-starter
pagemosaic-website-starter is an open source tool from Alex Pust that helps you to host static websites on AWS, using AWS CDK under the covers from the looks of things. To deploy your website, simply transfer your website files to the /platform/web-app directory. Following this, execute the command pnpm deploy-platform to initiate the deployment process. Nice use of You Tube videos in the README to help you get started.
Demos, Samples, Solutions and Workshops
reinvent-session-concierge
reinvent-session-concierge is potentially a very useful tool for those of you heading out to re:Invent, and wanting to make sure that you make the most of your time there by attending the sessions of most interest to you. This project uses Amazon Bedrock Titan text embeddings stored in a PostgreSQL database to enable generative AI queries across the re:Invent session data. It combines both semantic search and traditional queries. I am going to be trying it out later today to help me plan my online viewing.
big-data-summarization-using-griptape-bedrock-redshift
big-data-summarization-using-griptape-bedrock-redshift I have looked at Griptape in other blog posts, so it was nice to see this repo that provides sample code and instructions for a Big data summarisation example using this popular open-source library, together with Amazon Bedrock and Amazon Redshift. In this sample, TitanXL LLM is used to summarise but Anthropic’s Claude v2 is also used to drive the application. This application sample demonstrates how data can be pulled from Amazon Redshift and then passed to the summarisation model. The driving model is isolated from the actual data and uses the tools provided to it to orchestrate the application.
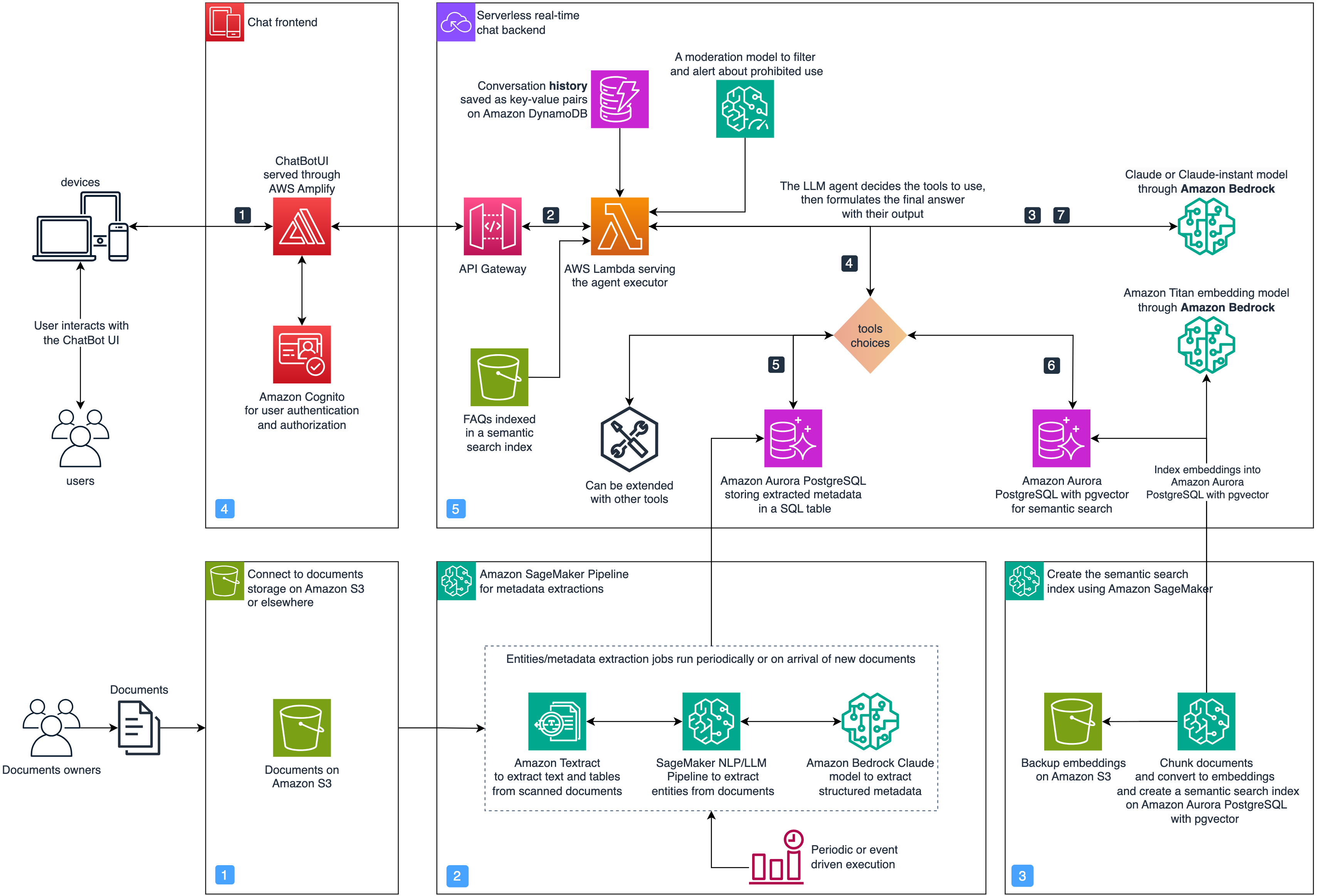
aws-agentic-document-assistant
aws-agentic-document-assistant The Agentic Documents Assistant is an LLM assistant that provides users with easy access to information and insights stored across their business documents, through natural conversations and question answering. It supports answering factual questions by retrieving information directly from documents using semantic search with the popular RAG design pattern. Additionally, it answers analytical questions by translating user questions into SQL queries and running them against a database of entities extracted from the documents with a batch process. It is also able to answer complex multi-step questions by combining different tools and data sources using an LLM agent design pattern.
Key features of this sample project include semantic search to augment response generation with relevant documents, structured metadata extraction and SQL queries for analytical reasoning, and an agent built with the Reason and Act (ReAct) instruction format that determines whether to use search or SQL to answer questions.
AWS and Community blog posts
Community round up
I always take time in reading posts from the community, so want to share some of the highlights from last week with you. First up is AWS Community Builder Salam Shaik who provides an overview of vector databases (so hot right now!) and a hands on guide on how you can get started with this using OpenSearch in his post, Building a vector-based search engine using Amazon Bedrock and Amazon Open Search Service. AWS Community Builder Vadym Kazulkin is back with the latest instalment for Java developers, and his journey in helping you dive deeper into running modern Java applications in the Cloud with the post, Measuring Lambda cold starts with AWS SnapStart - Part 9 Measuring with Java 21. From Java to Kong, an open source cloud native API gateway project that features in AWS Community Builder Alexander Rey’s post, Deploying Kong Gateway (OSS) in Production on AWS Using serverless Tools. This was the first time I had heard and read about the Pirate Weather API, but I approve. Rrrrr, tis brough out the inner rascal in me. It is tough to top Pirates, but AWS Community Builder Jason Andrews puts in a valiant effort in his post, Use AWS Graviton processors on AWS Fargate with Copilot looking at using AWS Copilot with AWS Graviton powered containers. Next up we have Rahul Pulikkot Nath with a tool for you .NET developers. In How To Easily Get Started with AWS Lambda Logging in .NET using Powertools, Rahul provides a hands on guide on how you can integrate Powertools for Lambda in your .NET functions, and provides video support as well.
To finish this round up this week, my colleague Sophia Parafina is continuing with the quest for more WordPress content buy putting together a couple of posts to help you automate the deployment of this open source content management system. First up is Automate WordPress Lightsail Deployments with AWS CDK, which provides a blueprint of how you can deploy Wordpress on Lightsail using AWS CDK. Following that we had Deploy WordPress with Lightsail and CloudFormation that took a different approach, this time using Amazon CloudFormation templates.
AWS Amplify
The AWS Amplify team have been super busy and have released some really great updates for you web developers.
Starting things off was news that AWS Amplify has a public preview of its code-first developer experience (Gen 2), enabling developers to build full-stack apps using TypeScript. Gen 2 shifts to a code-first approach that allows developers to express app requirements - data model, business logic, authorisation rules - in TypeScript. The necessary cloud infrastructure is automatically deployed based on the app code, without explicit infrastructure definitions.
Nikhil Swaminathan looks at this in more detail in his post, Introducing the Next Generation of AWS Amplify’s Fullstack Development Experience.

In other AWS Amplify news, we had Danny Banks and Erik Hanchett come together to write 6 New AWS Amplify Launches for Frontend Developers where they share improvements to our documentation site, Next.js 14 support, custom authentication providers, React Native social sign in, and UI components.
Up next was this post, Wildcard Subdomains for Multi-tenant Apps on AWS Amplify Hosting where Stephen Siegert looked at the announcement of wildcard subdomains when using a custom domain with your Amplify application. This is critical for developers that are building personalised user experiences in their Software as a Service (SaaS) or multi-tenant platforms. [hands on]
To complete the round up of AWS Amplify posts this week, we had Stephen Siegert back again with Introducing Support for Hosting Any SSR app on AWS Amplify Hosting that explored the announcement of a new deployment specification that enables developers to build plugins for hosting server-side rendering (SSR) applications on Amplify, which opens up Amplify Hosting’s SSR capabilities to all frameworks. Very cool.
Data and Analytics
Here are the pick of last weeks open source related data and analytics posts.
- Introducing persistent buffering for Amazon OpenSearch Ingestion looks at how to configure persistent buffering for Amazon OpenSearch Ingestion to enhance data durability, and simplify data ingestion architecture for Amazon OpenSearch Service [hands on]
- Introducing Group Replication plugin for active/active replication on Amazon RDS for MySQL explores MySQL Group Replication, its use cases, configuration, application-level considerations, and significance in modern database management [hands on]

- Implement data warehousing solution using dbt on Amazon Redshift highlights an optimal and cost-effective way of incorporating dbt within Amazon Redshift [hands on]
- Introducing Apache Hudi support with AWS Glue crawlers demonstrates how AWS Glue crawlers work for Hudi tables, and how with the support for Hudi crawler, you can quickly move to using AWS Glue Data Catalog as your primary Hudi table catalog [hands on]
Other posts and quick reads
- Monitoring and Visualizing Amazon EKS signals with Kiali and AWS managed open-source services demonstrates how to set up and access the Kiali dashboard to query Istio metrics in Amazon managed Prometheus [hands on]
- Optimize AZ traffic costs using Amazon EKS, Karpenter, and Istio presents a robust solution by integrating Istio, Karpenter, and Amazon EKS to address operational efficiency and cost-effectiveness [hands on]

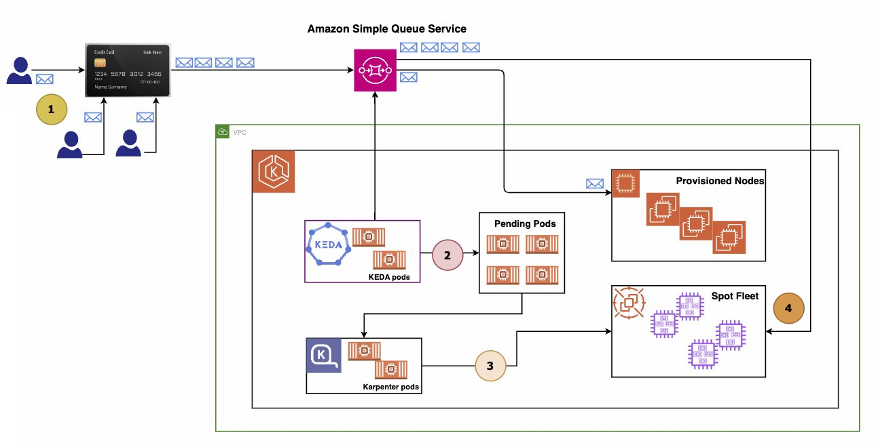
- Scalable and Cost-Effective Event-Driven Workloads with KEDA and Karpenter on Amazon EKS provides a simplified guide to integrating Kubernetes Event-Driven Autoscaling (KEDA) using Karpenter with Amazon EKS, for a more efficient, cost-effective, and high-performing setup [hands on]
- Use Amazon SageMaker Studio to build a RAG question answering solution with Llama 2, LangChain, and Pinecone for fast experimentation explores how to use Amazon SageMaker Studio to build a RAG question answering solution, using a number of open source technologies [hands on]
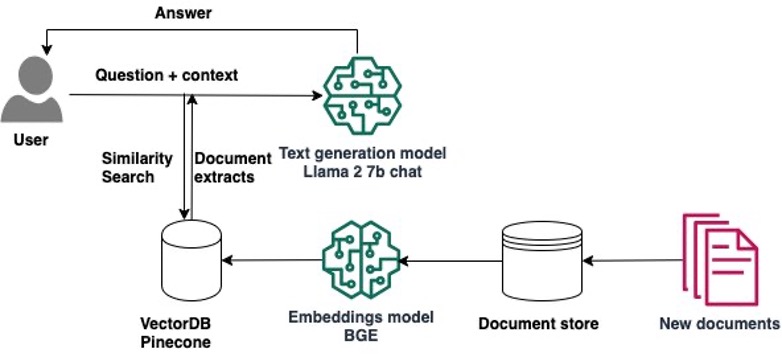
- Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights answers the question some of you might be asking, namely how can you supercharge your data analytics with generative AI using Amazon EMR, Amazon Bedrock, and the pyspark-ai library (ok, maybe it was just me asking then…) [hands on]
- 34 new or updated datasets available on the Registry of Open Data on AWS takes a look at new open data sets that are available for you to use, across climate, geospatial, life sciences, and machine learning use cases
Quick updates
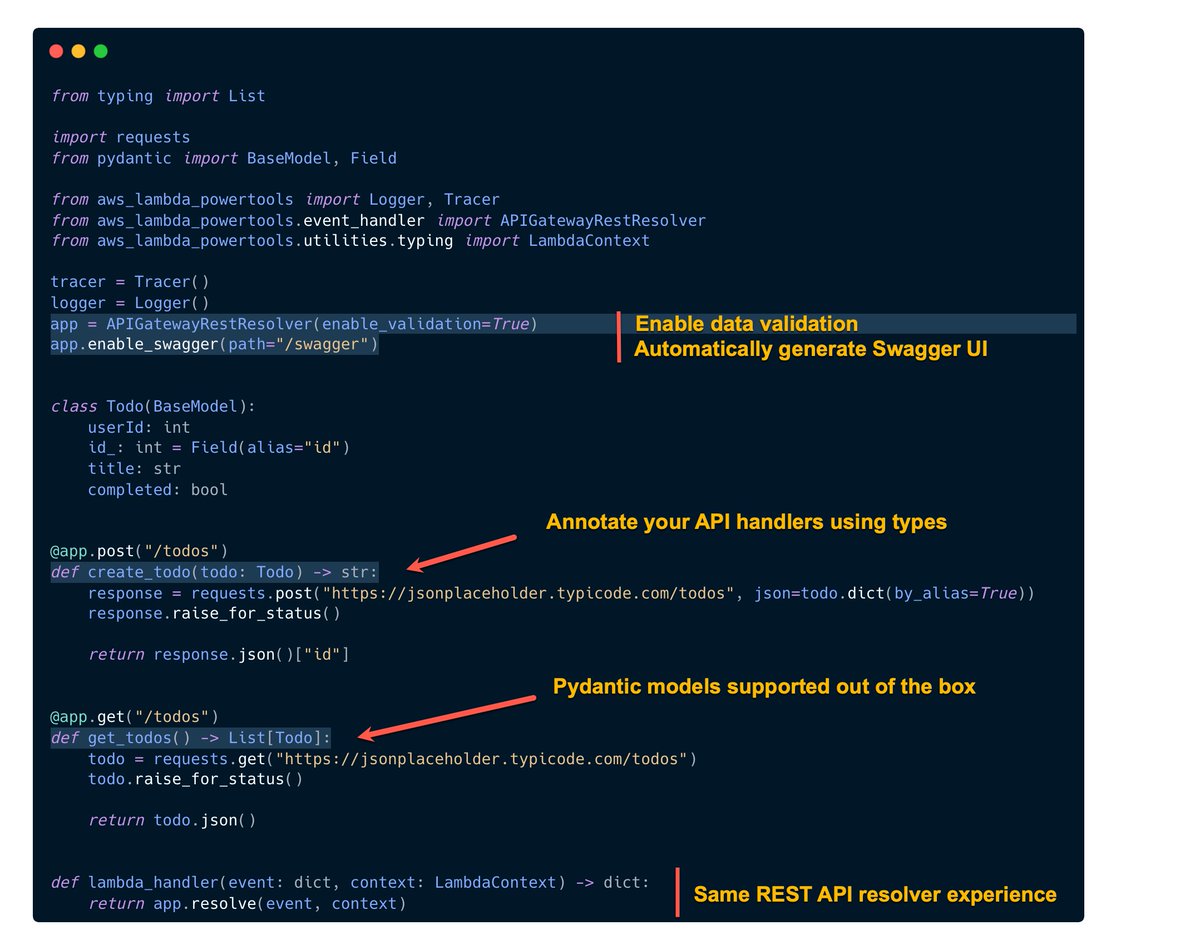
Powertools for Lambda
Version 2.2.8 of Powertools for Lambda Python was released last week, with Heitor sharing on X some of the updates, which include Request/Response data validation via types, OpenAPI & SwaggerUI for API Gateway REST/HTTP, ALB, Lambda Function URL, VPC Lattice, and more.
Apache Flink
Apache Flink is now generally available for Amazon EMR on EKS. With Apache Flink for Amazon EMR on EKS, customers can transform and analyze streaming data in real time with Apache Flink, an open-source framework for stateful computations over data streams. Amazon EMR on EKS is a deployment option for Amazon EMR that makes it easy for customers to run their big data applications and data lake analytics workloads on EKS. Customers already using Amazon EKS can run their Apache Flink application along with other types of applications on the same Amazon EKS cluster, helping improve resource utilization and simplify infrastructure management.
With this launch, customers can use Apache Flink on Amazon EMR on EKS to reduce the complexity of building and configuring Apache Flink applications. Customers can also leverage spot instance in Flink application with graceful decommission, and can achieve faster restart time using fine grained recovery and task local recovery with EBS. In addition, customers get access to key accessibility and monitoring features such as launching Flink application using jars in Amazon S3, monitoring integration with Amazon S3 and Amazon CloudWatch and container log rotation. Finally, customer can use connectors to integrate Amazon EMR on EKS with Amazon Glue Data Catalog, Amazon Kinesis Data Streams, Amazon DynamoDB Streams, and more.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports major version 16, starting with PostgreSQL version 16.1. RDS for PostgreSQL 16.1 includes support for logical decoding on read replicas, logical replication from standbys, and over 90 PostgreSQL extensions such as pgactive, pgvector, pg_tle, h3-pg, pg_cron, and rdkit. PostgreSQL 16 introduces a number of performance and visibility improvements including greater query parallelism, SIMD CPU acceleration, and a ‘pg_stat_io’ view that provides statistics on I/O usage. Further, with PostgreSQL 16, developers can now use SQL/JSON constructors and identity functions. You can upgrade your database using several options including RDS Blue/Green deployments, upgrade in-place, restore from a snapshot, or use AWS Data Migration Service.
MySQL
Amazon Relational Database Service (Amazon RDS) now offers the option to upgrade your MySQL 5.7 snapshots (Minor versions 16 to 43) to MySQL 8.0 (Minor versions 28, 32, 33, 34) using the RDS Console and the ModifyDBSnapshot API or CLI command. RDS for MySQL 5.7 will reach end of standard support on Feb 29, 2024. Upgrading snapshots ensures that you have the latest supported engine version. Using the snapshot upgrade feature, you can upgrade your MySQL 5.7 snapshots to MySQL 8.0 without restoring them.
Amazon Corretto
AWS Lambda now supports creating serverless applications using Java 21. This runtime is based on the latest long-term support release of AWS Corretto, Amazon’s distribution of the Open JDK. Developers can use Java 21 as both a managed runtime and a container base image, and AWS will automatically apply updates to the managed runtime and base image as they become available. The Lambda Java 21 runtime is built on the new Amazon Linux 2023 runtime, which provides a significantly smaller deployment footprint than earlier Amazon Linux 2-based runtimes, updated versions of common libraries such as glibc, and a new package manager. It supports AWS Lambda Snap Start (in supported Regions) for fast cold starts. Powertools for AWS Lambda (Java), a developer toolkit to implement serverless best practices and increase developer velocity, also supports Java 21.
Lustre
Amazon FSx for Lustre, a service that provides cost-effective, high-performance, scalable file storage for compute workloads, now supports throughput scaling. This capability enables you to adjust the throughput tier of your file systems to meet changing performance requirements with greater agility and lower cost.
A file system’s throughput determines the read/write speed that is supported by its file servers. When you create a file system, Amazon FSx for Lustre provisions a total amount of throughput based on the storage capacity and throughput tier you select. Starting today, you can scale your file system’s throughput tier up or down, allowing you to adjust your file system’s total throughput. With this feature, you can test multiple throughput levels when onboarding a new project, accommodate growing compute clusters, and manage periodic high throughput needs in a cost-effective manner. Throughput scaling is now supported on all Persistent SSD file systems at no additional cost in AWS regions where Amazon FSx for Lustre is available.
OpenZFS
Amazon FSx for OpenZFS now provides additional performance metrics for improved visibility into file system activity and an enhanced monitoring dashboard with performance insights and recommendations. You can use the new Amazon CloudWatch metrics and dashboard to right-size your file systems and optimise performance and costs.
Amazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system. FSx for OpenZFS delivers sub-millisecond latencies and up to 10 GB/s of throughput, along with rich ZFS-powered data management capabilities such as snapshots, data cloning, and compression. Previously, you could use performance metrics to monitor file system throughput and IOPS. Now, using additional performance metrics that include file server CPU, memory usage, storage disk throughput, and storage disk IOPS, you can optimise performance and costs across an even wider range of workloads, including read/write-intensive workloads such as Oracle databases and workloads with variable performance needs such as periodic reporting jobs. The enhanced monitoring dashboard provides actionable performance recommendations. For example, if your workload is disk I/O-limited you can increase file system disk I/0 performance with a few clicks.
These additional performance metrics and updated monitoring dashboard are available now, at no additional cost, for all new and existing file systems in all AWS Regions where Amazon FSx for OpenZFS is available.
Apache Kafka
A couple of updates this week for folks interested in Apache Kafka on AWS.
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports an enhanced version of Apache Kafka 3.6.0 that offers generally available Tiered Storage. Apache Kafka’s version 3.6.0 includes several bug fixes and new features, including early access for Tiered Storage. This enhanced version supports production-ready Tiered Storage, similar to previously launched Amazon MSK version 2.8.2, so customers can use it for mission-critical workloads. Tiered Storage makes storage management of your MSK Provisioned clusters easier by offering an elastically scalable and virtually unlimited remote storage tier in addition to the high-performance local storage tier. It also makes it more cost effective to store data for longer durations in Apache Kafka clusters.
Amazon MSK now automatically sends you alerts when you are at risk of exhausting your storage capacity. The alerts also provide recommendations on the best steps to take to manage your storage. This feature makes it easier for you to identify and quickly resolve storage capacity issues before they become critical. Amazon MSK automatically sends these alerts to the Amazon MSK Console, AWS Health Dashboard, Amazon EventBridge, and email contacts for your AWS account. You can also configure Amazon EventBridge to deliver these alerts via Slack or to tools such as New Relic and Datadog.
Bonus
Also this week, we had Sunil Ramachandra and Julie Mills put together Building a real-time recommendation engine with Amazon MSK and Rockset that provides a hands on guide of how to build a real-time product recommendation engine by leveraging the fully managed streaming capabilities of Amazon MSK, along with the real-time analytics and SQL capabilities of Rockset.
Videos of the week
You Can Run Java 21 on AWS Lambda
Your host James Eastham shows you how you can adopt Java 21 when building AWS Lambda functions. And how you can quickly get started using AWS SAM to quickly spin up new Java 21 based Lambda functions.
Generate real-time code suggestions in EMR Studio notebooks
Damon Cortesi provides a short video to show you how Amazon EMR Studio now integrates with Amazon CodeWhisperer to provide real-time code suggestions for Apache Spark. Make sure you check out his other videos, there is lots of great content.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
re:Invent November, 27th-1st December, Las Vegas, USA
The annual must attend conference for all AWS developers is back, and with another strong line up of open source sessions, chalk talks, builder sessions, workshops and more. There will be a super cool open source booth, with a line up of great demos - I have taken a sneak look and so make sure you check out the demo schedule on the booth.
Find out more by checking out the event page, re:Invent 2023 but make sure you also read about what you can expect in the demo zone in the post, Get Your Questions Answered at re:Invent 2023 in the AWS Modern Applications and Open Source Zone
The Amazon EKS team have published a post to help ensure that you do not miss the best Kubernetes related sessions. Go check it out at, Amazon EKS and Kubernetes sessions at AWS re:Invent 2023.
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen