AWS open source newsletter #178
November 6th, 2023 - Instalment #178
Welcome to #178 of the AWS open source newsletter, the place for all your AWS and open source needs. This week we feature more new open source projects for you to practice your four freedoms. We have a useful tool that helps you synchronise your AWS Identity Centre users with the users you provision in your Amazon RDS databases, we share the AWS data solutions framework that helps you build data solutions following opinionated best practices, a resource explorer for your AWS accounts, a guardrails solution for your AWS account, and a couple of demo repositories that take a look at Localstack and RSS. Also featured in this edition is reading material that should keep you busy on a number of open source technologies, including Spring Boot, Amazon Corretto, Rust, MySQL, PostgreSQL, Kubernetes, Amazon EKS, Apache Airflow, OpenSearch, AWS Neuron, Finch, LangChain, PyTorch, Drupal, Apache Spark, Apache Iceberg, Karpenter, JupyterHub, AWS SAM, SnapStart, and more.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Vadym Kazulkin, Ryan Stebich, Jason Andrews, Andrii Melashchenko, Lucas Soriano Alves Duarte, Apoorva Kulkarni, Ravi Yadav, Vara Bonthu, Giacomo Tomolillo, Justin Garrison, Phile Estes, Matt Muller, Chirag Dave, Shagun Arora, David Nalley, Nithya Ruff , Arun Gupta, Trevor Sullivan, and many others!
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
sso-sync-to-amazon-rds
sso-sync-to-amazon-rds This project sets up AWS Lambda functions, Amazon EventBridge rule, Amazon VPC Endpoint for AWS IAM Identity Center (successor to AWS Single Sign-On), the related Security Groups and permissions necessary to automatically provision database users to the Amazon Relational Database Service (Amazon RDS) cluster using AWS Cloud Development Kit (AWS CDK). When a new user is created in IAM Identity Center and the user belongs to the group specified in a IAM_IDC_GROUP_NAME variable, EventBridge rule will trigger the Lambda function. The Lambda function will create a new user in a specified Amazon RDS cluster. The user will then be able to login to the database using their SSO username and IAM credentials. Adding a user to the configured group will trigger the Lambda function as well.

data-solutions-framework-on-aws
data-solutions-framework-on-aws is a framework for implementation and delivery of data solutions with built-in AWS best practices. Data Solutions Framework on AWS (DSF) is an abstraction atop AWS services based on AWS Cloud Development Kit (CDK) L3 constructs, packaged as a library. You can leverage DSF to implement your data platform in weeks rather than in months. DSF is available in TypeScript and Python. Use the framework to build your data solutions instead of building cloud infrastructure from scratch. Compose data solutions using integrated building blocks via Infrastructure as Code (IaC), that allow you to benefit from smart defaults and built-in AWS best practices. You can also customize or extend according to your requirements. Check out the dedicated documentation page, complete with examples to get you started.
resource-explorer-with-organizations
resource-explorer-with-organizations you may have a use cases where you are eager to find lingering resources, or resources that were not at their optimal settings. By utilising Resource Explorer and Step Functions, you can gather all the necessary information from these accounts, and use them to create a report to gain a wider understanding of the state of your AWS accounts. As of this release, the limitation of Resource Explorer is that it is done on a per account basis. However, the README provides details of a workaround to deploy this to all your accounts in our AWS Organization using StackSets. The use case shown in the repo shows you how you can find resources in an multiple AWS accounts over multiple regions, and generating an Excel Document displaying the Account it belongs to, Name, Resource Type, and ARN of the resource.
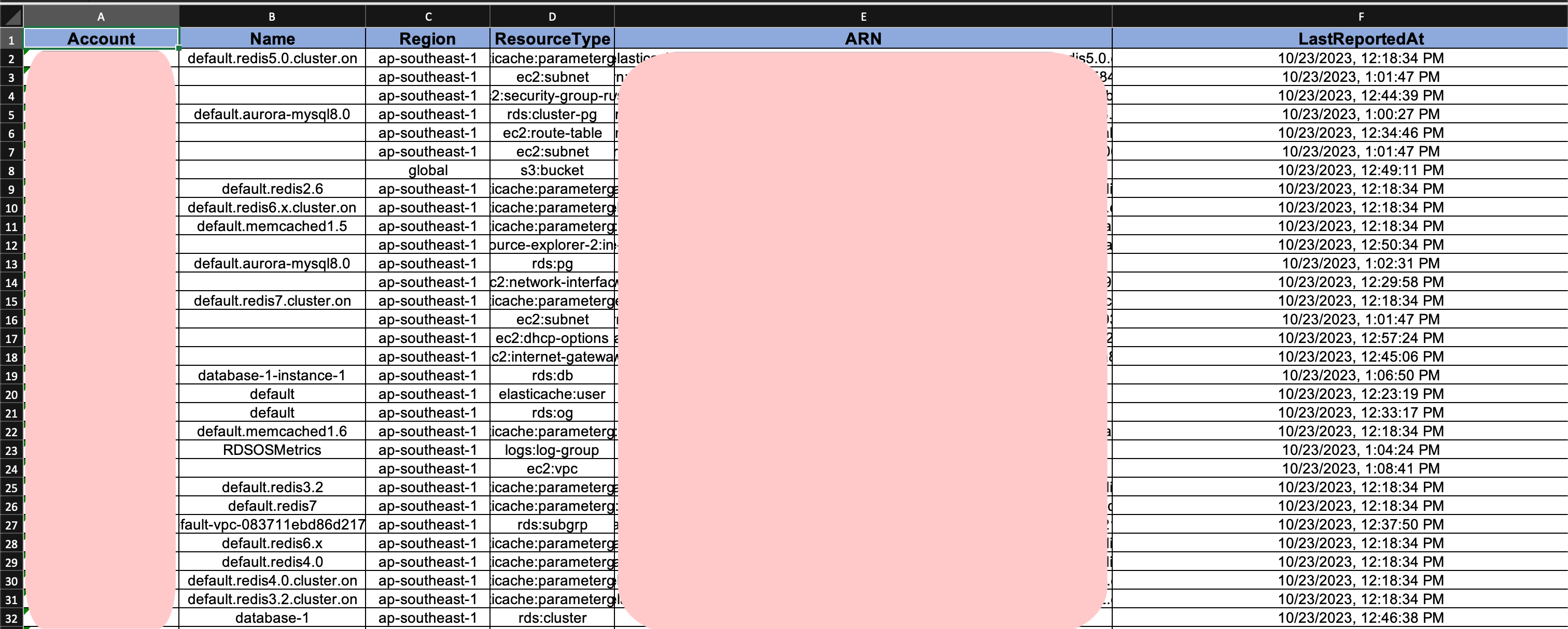
The repo provides details of how you can deploy this tool, so make sure you check that out too.
garnet-framework
garnet-framework Garnet is an open-source framework for building scalable, reliable and interoperable platforms leveraging open standards, FIWARE open source technology and AWS Cloud services. It supports the development and integration of smart and efficient solutions across multiple domains such as Smart Cities, Regions and Campuses, Energy and Utilities, Agriculture, Smart Building, Automotive and Manufacturing. The repo provides code and links to the dedicated documentation site to help you get started.

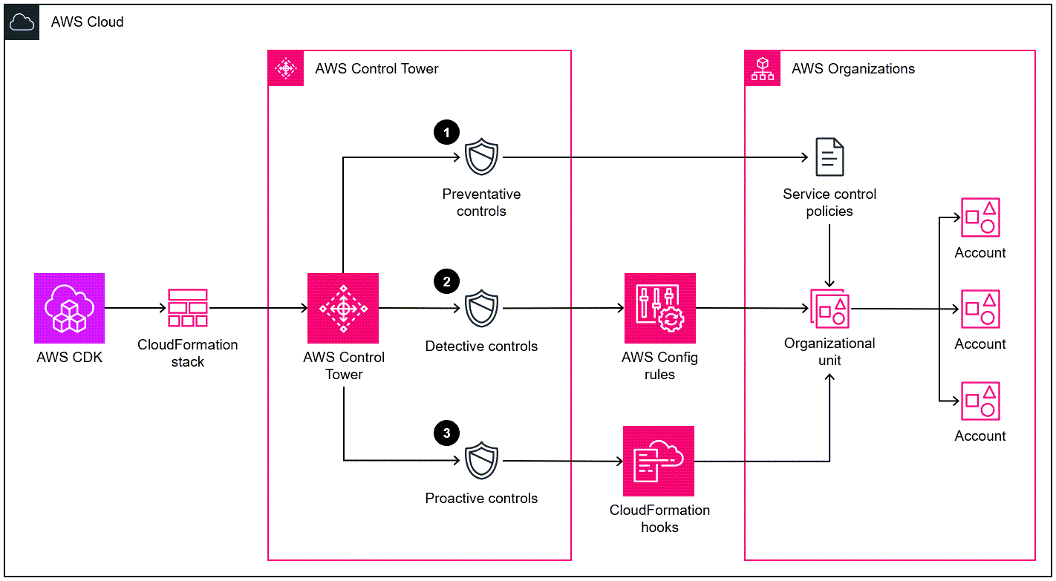
aws-control-tower-controls-cdk
aws-control-tower-controls-cdk This pattern describes how to use AWS CloudFormation and AWS Cloud Development Kit (AWS CDK) to implement and administer preventive, detective, and proactive AWS Control Tower controls as infrastructure as code (IaC). A control (also known as a guardrail) is a high-level rule that provides ongoing governance for your overall AWS Control Tower environment. For example, you can use controls to require logging for your AWS accounts and then configure automatic notifications if specific security-related events occur. Check out the REAMDE for more details on what you can do with this.
Demos, Samples, Solutions and Workshops
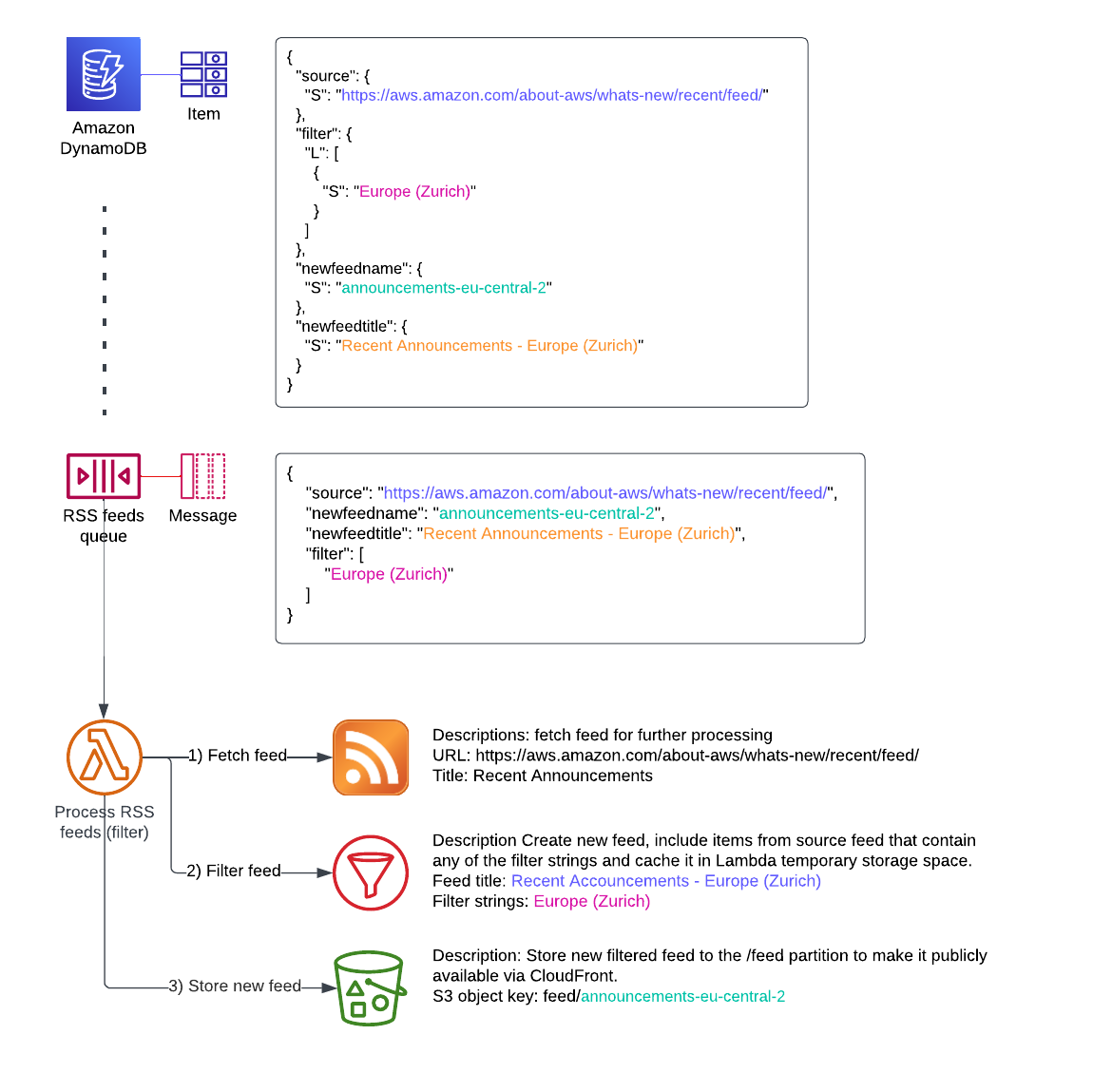
serverless-rss-filtered-feed-gen
serverless-rss-filtered-feed-gen This is a configurable serverless solution that generates filtered rss feeds and makes them public accessible. Defined RSS sources are read at a given interval and new filtered feeds are generated and stored. The architecture uses a minimum number of AWS services to keep it easy to maintain and cost-effective.
localstack-aws-cdk-example
localstack-aws-cdk-example This repo aims to showcase the usage of Localstack and AWS CDK to address specific integration challenges regarding local development where the end target is the AWS platform. If you are unfamiliar with Localstack, it is an open source, fully functional local AWS cloud stack that allows you to develop and test your cloud and Serverless apps offline.
powertools-lambda-kotlin
powertools-lambda-kotlin This project demonstrates the Lambda for Powertools Kotlin module deployed using Serverless Application Model with Gradle running the build. This example is configured for Java 8 only; in order to use a newer version, check out the Gradle configuration guide in the main project README. You can also use sam init to create a new Gradle-powered Powertools application - choose to use the AWS Quick Start Templates, and then Hello World Example with Powertools for AWS Lambda, Java 17 runtime, and finally gradle.
AWS and Community blog posts
Community round up
This weeks community round up starts with a great post from AWS Community Builder Vadym Kazulkin, who shares his deep expertise in Java and Amazon Corretto, and explores how he measured cold start times when using Amazon Corretto 17 and SnapStart in his post, Measuring Lambda cold starts with AWS SnapStart - Part 8 Measuring with Java 17. Make sure you check his previous posts too. Next we have a couple of posts on Kubernetes, starting with Ryan Stebich and his guide on how you can consume secrets within your Kubernetes workloads, in Easily Consume AWS Secrets Manager Secrets From Your Amazon EKS Workloads. This is an excellent post, and man could I have used this a few months ago when I was trying to figure this stuff out. Following that we have a subject near and dear to my heart, multi-architecture systems. I have done many talks on this in the past, as well as blog posts and code examples, so was super excited to read Multi-architecture Kubernetes clusters on Amazon EKS from AWS Community Builder Jason Andrews. Great stuff! The final post this week comes from AWS Community Builder Andrii Melashchenko, who looks at at generating a CI/CD pipeline using AWS Serverless Application Model (SAM), Node.js, and GitHub Actions in his post, An efficient way to build your serverless microservices. Part 3. CI/CD with AWS SAM..
Jupyter
In Building multi-tenant JupyterHub Platforms on Amazon EKS, Lucas Soriano Alves Duarte, Apoorva Kulkarni, Ravi Yadav, and Vara Bonthu collaborate to share information on the process of building, deploying, and harnessing the power of multi-tenant JupyterHub environments on Amazon EKS at scale. This is a must read post this week, with the level of depth as well as completeness that this solution provides should make it of interest to everyone. [hands on]

Kubernetes
A couple of updates this week.
First is news that Karpenter, a Kubernetes node lifecycle manager, that was donated to the Cloud Native Computing Foundation (CNCF) as part of Kubernetes Autoscaling Special Interest Group, has now progressed from alpha to beta. What does this mean? Well find out by reading the post, Karpenter graduates to beta, where Giacomo Tomolillo and Justin Garrison share all.
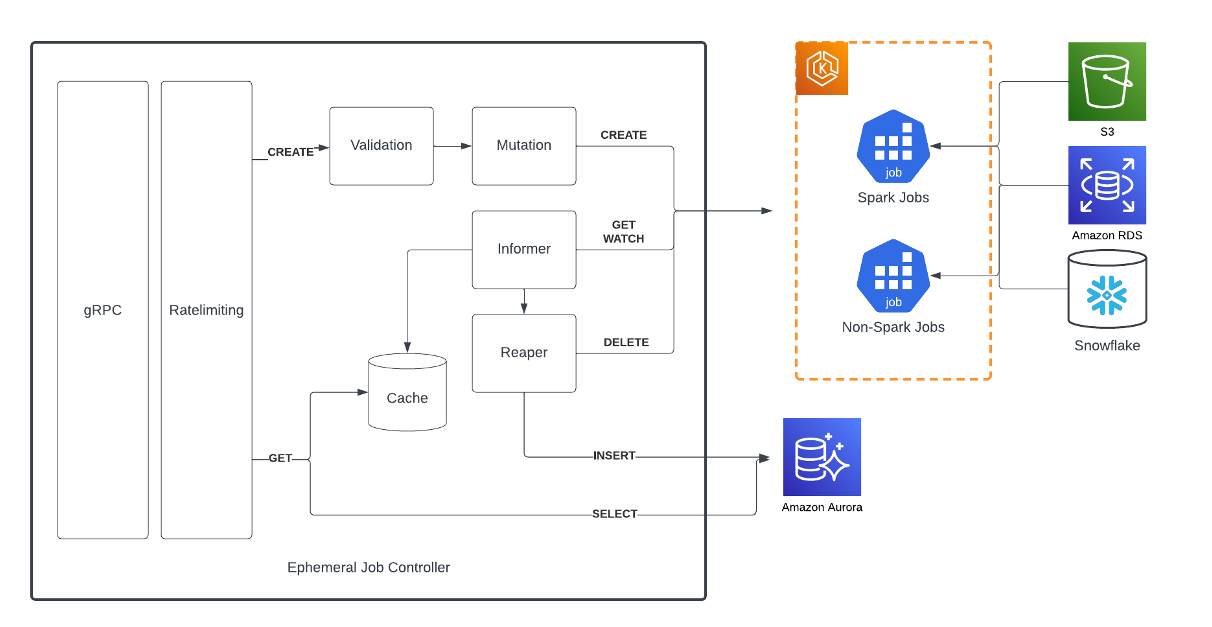
Following that we had a case study from Lacework, who shared some of their learnings from their experience in operating Kubernetes Batch jobs at scale in the post, Lacework’s batch workloads on Amazon EKS: Lessons learned . Abhi Karode, Shane Corbett, Vara Bonthu, together with Derek Brown at Lacework go into details and leave with three key take aways for you to think about.
Big Data and Analytics
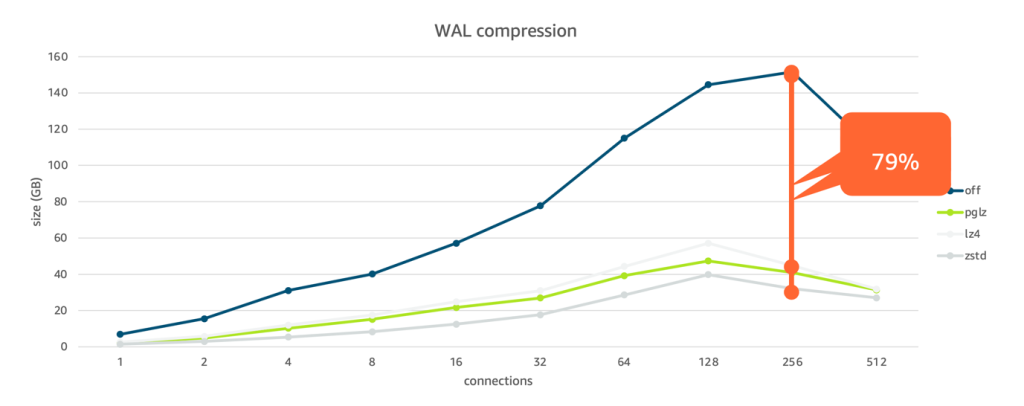
- Impactful features in PostgreSQL 15 is a must read post that looks at some of the most impactful features of PostgreSQL 15. We explore the MERGE statement, new WAL compression algorithms, enhancements to logical replication and PUBLIC schema permissions, improvements to partition tables, and some general performance improvements [hands on]
- Powering Amazon RDS with AWS Graviton3: Benchmarks compare the performances of AWS Graviton2 and AWS Graviton3 instances on open-source engines supported by Amazon RDS, to validate them from a db-centric perspective - a must read! [hands on]

- Use Amazon DynamoDB incremental export to update Apache Iceberg tables explains how to bulk process a series of full and incremental exports using Amazon EMR Serverless with Apache Spark to produce a single Apache Iceberg table [hands on]

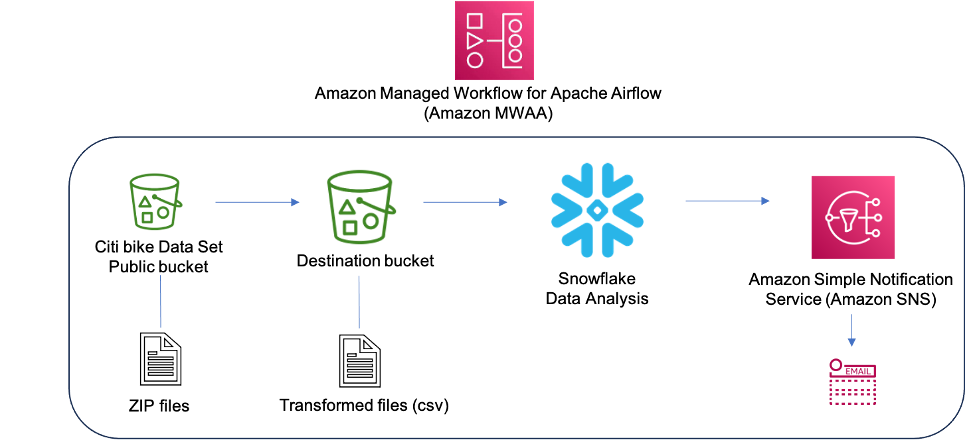
- Use Snowflake with Amazon MWAA to orchestrate data pipelines provides an overview of orchestrating your data pipeline using Snowflake operators in your Amazon MWAA environment [hands on]
- Enable cost-efficient operational analytics with Amazon OpenSearch Ingestion demonstrates how to use OpenSearch Ingestion pipelines to build a cost-optimized infrastructure for log analytics and observability events [hands on]

- An automated approach to perform an in-place engine upgrade in Amazon OpenSearch Service discusses what to consider when planning to upgrade your existing Elasticsearch engine in your OpenSearch Service domain to the OpenSearch engine
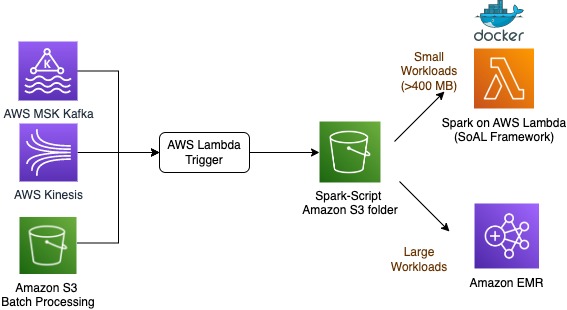
- Spark on AWS Lambda: An Apache Spark runtime for AWS Lambda highlights the Spark on AWS Lambda (SoAL) architecture, provides infrastructure as code (IaC), offers step-by-step instructions for setting up the SoAL framework in your AWS account, and outlines SoAL architectural patterns for enterprises [hands on]
Other posts and quick reads
- Intelligently search Drupal content using Amazon Kendra shows you how to use the Amazon Kendra Drupal connector to configure the connector as a data source for your Amazon Kendra index and search your Drupal documents [hands on]
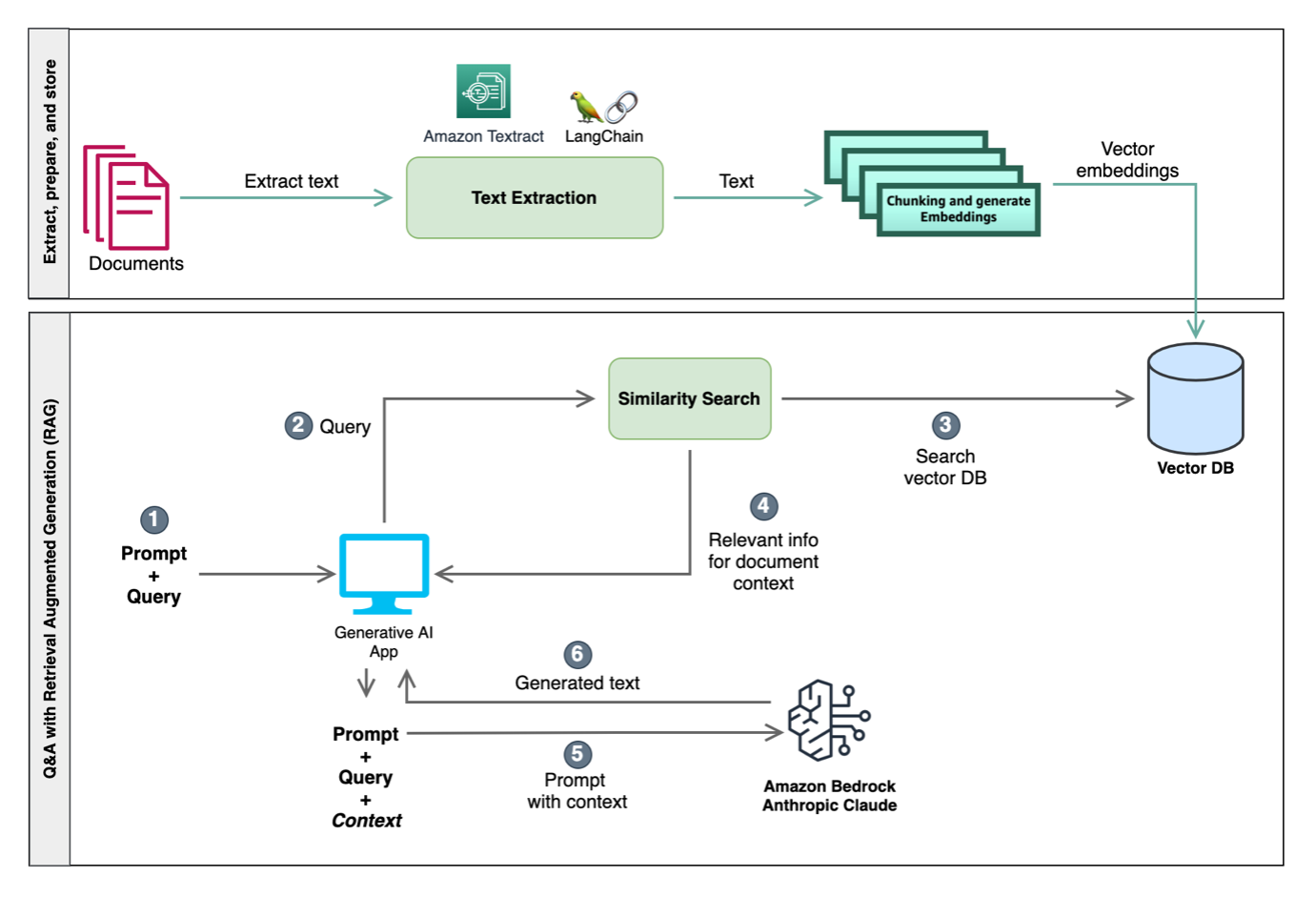
- Intelligent document processing with Amazon Textract, Amazon Bedrock, and LangChain looks at the various mechanisms of augmenting an intelligent document processing (IDP) workflow with LLMs via Amazon Bedrock, Amazon Textract, and the popular open source LangChain framework [hands on]
- Intuitivo achieves higher throughput while saving on AI/ML costs using AWS Inferentia and PyTorch provides an interesting case study on how this customer was able to see a five times increase in processing speed and a 95 percent reduction in inference costs compared to our previous solution
Quick updates
NodeJS
If you are a NodeJS developer, then make sure you read Announcing the end of support for Node.js 14.x in the AWS SDK for JavaScript (v3), that looks at important news around end of life support and options you can consider.
Ruby
Along similar lines to the previous update, we also saw the end of life announcement for users of the Ruby 2.3 and 2.4 runtimes in the AWS SDK for Ruby. Check out the details in Matt Muller’s post, Announcing the end of support for Ruby runtimes 2.3 and 2.4 for the AWS SDK For Ruby
Finch
Great news for folks looking for a great tool to work with container. Last week we announced the general availability of Finch, an open source command line tool that allows developers to build, run, and publish Linux containers on macOS. With this release, we are also launching a website that should help you find all the Finch-related information, tutorials, and other resources to get started with Finch.
Since we first announced Finch in November 2022, we have launched capabilities that enhance the developer experience when working with containers locally and interacting with container registries. We introduced container image signing, and support for both creating and running images using Seekable OCI (SOCI), an AWS open-source technology for faster container launches by lazily loading the container image. We addressed key papercuts including persistent disk support and VM initialisation time reduction, and created a benchmark tool to continually measure and improve Finch performance.
Check out the official blog post, Ready for Flight: Announcing Finch 1.0 GA! where Phil Estes provides a detailed recap of progress made since the announcement, and what you can expect going forward.
AWS Neuron
AWS Neuron is a software development kit (SDK) enabling high-performance deep learning acceleration using AWS Inferentia and Trainium, AWS’s custom designed machine learning accelerators. Neuron includes a compiler, runtime driver, as well as debug and profiling utilities with a TensorBoard plugin for visualisation, and is pre-integrated into popular machine learning frameworks like Pytorch, TensorFlow and MXNet, to provide a seamless machine learning acceleration workflow. Last week saw the release of Neuron 2.15, which now adds support for Llama-2 70b model training as well as PyTorch 2.0 support.
OpenSearch
A few updates this week for OpenSearch fans.
Users can now benefit from more efficient query filtering with OpenSearch’s k-NN FAISS engine by using OpenSearch 2.9 on the Amazon OpenSearch Service. Previously exclusive to OpenSearch’s Lucene k-NN engine, OpenSearch’s efficient vector query filters capability intelligently evaluates optimal filtering strategies—like pre-filtering with approximate nearest neighbor (ANN) or filtering with exact k-nearest neighbor (k-NN)—to determine the best strategy to deliver accurate and low latency vector search queries. In earlier OpenSearch versions, vector queries on the FAISS engine used post-filtering techniques, which enabled filtered queries at scale, but it potentially returns less than the requested “k” number of results. Efficient vector query filters have demonstrated the ability to deliver low latency and accurate results enabling customers to create more responsive vector search applications such as semantic or visual search experiences. Vector query filters is a key enabler for hybrid search empowering users to perform vector search while filtering on metadata to retrieve more relevant information using both vector and lexical techniques. This new feature enhances OpenSearch’s existing query filtering capability by providing improved accuracy and speed.
Following that is news that Amazon OpenSearch Service now offers customers the option to use Internet Protocol version 6 (IPv6) addresses for their new and existing domains. Customers moving to IPv6 can simplify their network stack by running their OpenSearch Service domains on a network that supports both IPv4 and IPv6.
PostgreSQL
We had a flurry of updates this week covering all things PostgreSQL.
First up is news that Amazon Aurora PostgreSQL-Compatible Edition now supports the mysql_fdw extension which allows your PostgreSQL database to connect and retrieve data stored in Amazon Aurora MySQL-compatible, RDS MySQL, and self-managed MySQL and MariaDB databases. Foreign Data Wrappers are libraries for PostgreSQL databases that can communicate with an external data source, abstracting the details of connecting to the data source and obtaining data from it. The mysql_fdw PostgreSQL extension provides a Foreign Data Wrapper for easy and efficient federated query access to MySQL and MariaDB compatible databases. To get started, see Working with MySQL databases by using the mysql_fdw extension. The mysql_fdw extension is available on Aurora PostgreSQL 15.4, 14.9, 13.12, 12.16 and higher.
Next up is an update to the Amazon Aurora PostgreSQL query plan management supported by the apg_plan_mgmt extension, that now includes the ability to capture query plans on read-only replica instances. Query plan management (QPM) includes other improvements in this version such as limiting the capture of query plans based on the estimated cost. The PostgreSQL query optimiser creates a query execution plan for a SQL statement at a specific point in time. As conditions change, the optimiser might pick a different plan which changes performance. QPM provides you with capabilities such as: limiting the optimiser to a small number of known good plans, assess the impact of creating or dropping an index, and automatically detect lower cost plans. By using the new extension function create_replica_plan_capture, you can now capture query plans generated from all your replicas and store the captured plans in the apg_plan_mgmt schema tables using the postgres_fdw extension. QPM can then apply the approved plans that you identify across all your replicas including Amazon Aurora global databases. The apg_plan_mgmt extension version 2.5 is available on Aurora PostgreSQL 15.4, 14.9, 13.12, 12.16 and higher.
The final update this week looked at an update to Amazon Relational Database Service (Amazon RDS) Blue/Green Deployments. This now supports safer, simpler, and faster updates to your Amazon Aurora PostgreSQL-Compatible Edition and Amazon RDS for PostgreSQL databases. Blue/Green Deployments create a fully managed staging environment using PostgreSQL community logical replication, that allows you to deploy and test production changes, keeping your current production database safer. With a few clicks, you can promote the staging environment to be the new production system in as fast as a minute, with no data loss and no changes to your application to switch database endpoints. Use Amazon RDS Blue/Green Deployments for deploying changes to production, such as major version database engine upgrades, schema changes, maintenance updates, and scaling instances. Blue/Green Deployments use built-in switchover guardrails that will time-out promotion of the staging environment if it exceeds your maximum tolerable downtime, detects replication errors, or identifies instance health check errors.
Chirag Dave dives deeper on this topic in the post, New – Fully managed Blue/Green Deployment in Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL
MySQL
A few updates this week for MySQL users.
The most important one which you should know about is starting last week, long-term support (LTS) will be provided on Amazon Aurora MySQL-Compatible Edition 3 (with MySQL 8.0 compatibility) on the Aurora MySQL 3.04 (compatible with MySQL 8.0.28) minor version. Database clusters that use LTS releases can stay on the same minor version for at least three years. During the lifetime of an Aurora MySQL LTS release, new patches introduce fixes to critical matters such as security issues. These patches don’t include any new features.
Making MySQL restarts quicker is the focus of the next update. Amazon Aurora MySQL now includes optimisations that reduce the database restart time by up to 65% versus without optimisations. These improvements are achieved by deferring portions of the buffer pool initialisation and validation process to occur after the database is already online and accepting connections. These optimisations will improve database availability for unplanned events such as unexpected database restarts and planned operations such as minor version upgrades. To learn more about availability benefits, you can refer to our blog titled ‘Reduce downtime with Amazon Aurora MySQL database restart time optimisations’. These optimisations are enabled by default on Aurora MySQL versions 3.05 and higher.
You can dive deeper by reading Reduce downtime with Amazon Aurora MySQL database restart time optimizations, where Shagun Arora looks at the new Aurora MySQL optimisations introduced in Aurora MySQL version 3 that allow for reduced downtime and fewer disruptions to your workloads after a restart.
The final MySQL update was news from last week, where we announced news that Amazon Aurora MySQL-Compatible Edition 3 (with MySQL 8.0 compatibility) will support MySQL 8.0.32. In addition to several security enhancements and bug fixes, MySQL 8.0.32 includes several improvements, such as Instant DDL support for drop column operations, support for new language-specific collations, Generated Invisible Primary Keys (GIPKs), and performance schema monitoring enhancements. For more details, refer to the Aurora MySQL 3 and MySQL 8.0.32 release notes. This release includes optimisations that reduce the database restart time by up to 65% versus without optimisations.
Videos of the week
Open Source at Amazon
If you missed this last week, my colleagues David Nalley and Nithya Ruff joined Arun Gupta for a fire side chat about why Amazon cares about and contributes to open source.
Rust Programming Tutorial for Developers
Join Trevor Sullivan as he takes a look at the preview version of their Software Development Kit (SDK) for Rust developers. You can use the Rust SDK to interact with nearly any service in the AWS portfolio. In the video, you will explore the Rust SDK for AWS, and learn how it’s designed, and spend some hands-on time with the Amazon S3 service. You will also learn how to research calling APIs including the CreateBucket and PutObject operations, which are among the most common in the S3 service.
CI CD Pipeline with Spring Boot and AWS
In this extended video, you will see how you can set up a CI CD Pipeline with Spring Boot and AWS.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group, Palma November, 14th, 5pm-9pm Parc Bit - Fundació IBIT
I am happy to join Miguel Salvà at the PAWS (AWS User Group in Palma) for an evening of open source talks, covering a broad range of topics from OSPO’s, working with open source communities, and open source at Aamzon. Going to be great. You can find out more by checking out the user groups page, PAWS User Group
Big Data Europe 21st-24th November, Online/Vilnius, Lithuania
I will be speaking at the Big Data Europe event, talking about how you can shift left and apply modern developer approaches to manage your Apache Airflow workflows. This builds upon a lot of the other work I have done in this space, so am really looking forward to doing this talk.
Check out the event page for registration details, as well as to check out all the other sessions - many of which feature open source projects and technologies.
re:Invent November, 27th-1st December, Las Vegas, USA
The annual must attend conference for all AWS developers is back, and with another strong line up of open source sessions, chalk talks, builder sessions, workshops and more. There will be a super cool open source booth, with a line up of great demos - I have taken a sneak look and so make sure you check out the demo schedule on the booth.
Find out more by checking out the event page, re:Invent 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen