AWS open source newsletter #177
October 30th, 2023 - Instalment #177
Welcome to #177 of the AWS open source newsletter, the Halloween special. You will find no tricks in this edition, only treats, with more new projects for you to check out and content that are a feast for your eyes. This weeks new projects include a tool to help you easily deploy vector databases on Kubernetes, an observability toolkit, a tool to help you benchmark network latency, as well as lots of new demos on generative AI. You will not find any horror stories in this weeks written round up, only tales of open source adventure with some of your favourite open source technologies. Featured in this edition are Bottlerocket, KubeArmor, NGINX, Wordpress, Milvus, Falcon-40B, JupyterHub, Dask, Flux GitOps, Crossplane, Kubernetes, Amazon EKS, Babelfish for Aurora PostgreSQL, PostgreSQL, Linux, Apache Hive, Apache Spark, Apache Kafka, Apache Hudi, Delta Lake, Apache Iceberg, OpenSearch, Dremio, OpenShift, OpenCLIP, Apache Airflow, MWAA, Amazon Corretto, OpenJDK, and AWS CDK.
As always, we finish with our videos and events section, so make sure you do not miss those. With the Airflow Summit just gone, I feature my pick from an amazing selection of really great videos, as well as featuring videos on AWS CDK and Amazon Corretto. Go check them out.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Maximilian Schellhorn, Dennis Kieselhorst, Denis Traub, Adam Keller, Gary Stafford, John Jackson, Danilo Poccia, Craig Bossie, Aditi Sharma, Pavankumar Kasani, Runeet Vashisht, Rakesh Raghav, Alex Zarenin, Amit Arora, Jacob Mevorach, Carlos Santana, Isaac Mosquera, Manabu McCloskey, Ramon Ramirez-Linan, Sophia Parafina, Joe Stech, Mike Chambers, Haowen Huang, Christian Bonzelet, Rustem Feyzkhanov, Martyn Kilbryde, Farooq Ashraf, Jared Dean, and Ravi Yadav
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
weaviate-on-eks
weaviate-on-eks this repository includes sample code that can be used to deploy and configure an instance of the Weaviate distributed vector database on EKS.
observability-solution-kit
observability-solution-kit this repository is the Ollyv sdk. The Ollyv sdk offers a simple way to configure its behaviour through *.properties files, which are environment-specific. Currently code is provide from NodeLambda ✨ · NodeExpress 👟 · JavaSpring 🦚
trading-latency-benchmark
trading-latency-benchmark This repository contains a network latency test stack that consists of Java based trading client and Ansible playbooks to coordinate distributed tests. Java based trading client is designed to send limit and cancel orders, allowing you to measure round-trip times of the network communication.
Demos, Samples, Solutions and Workshops
gen-ai-on-eks
gen-ai-on-eks this repository aims to showcase how to finetune a FM model in Amazon EKS cluster using, JupyterHub to provision notebooks and craft both serving and training scripts, RayOperator to manage Ray Clusters and Karpenter to manage Node Scaling.
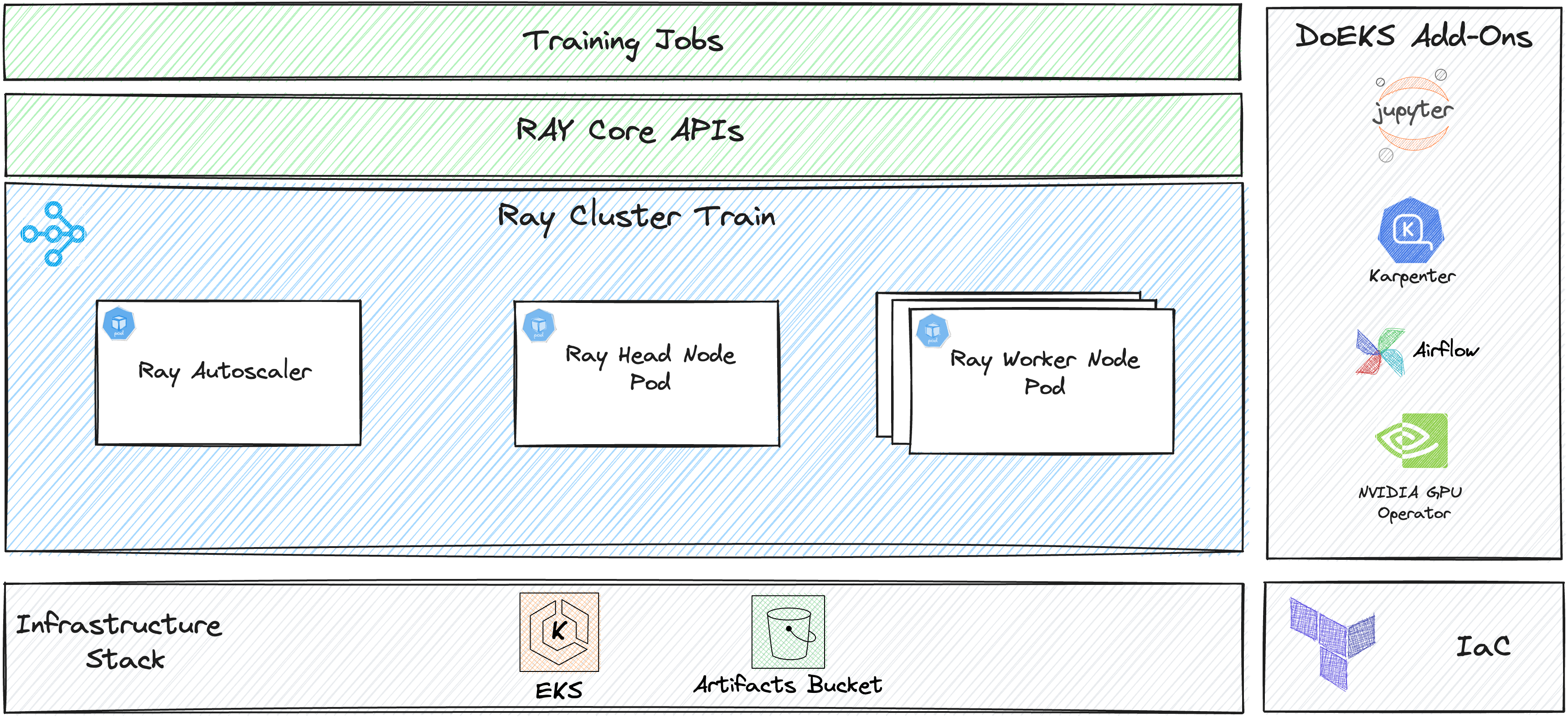
aws-inference-benchmark aws-inference-benchmark this project from Rustem Feyzkhanov contains code for running deep learning inference benchmarks on different AWS instances and service types. Check out his post, Making LLMs Scalable: Cloud Inference with AWS Fargate and Copilot where Rustem shows you in more details how you can use this repo.
makit-llm-lambda
makit-llm-lambda this repo from Martyn Kilbryde is an example of how you can run a Large Language Model (LLM) inside an AWS Lambda Function. Whilst the code will help you deploy to AWS Lambda, it can be ran locally inside Docker for testing as well. The function contains the full LLM model and the code to use the model, allowing basic text generation from a HTTP call into it.
awesome-codewhisperer
awesome-codewhisperer this repo from Christian Bonzelet is a great collection of resources for those of you who are experimenting with Generative AI coding assistants such as Amazon CodeWhisperer. This resource should keep you busy, and help you master Amazon CodeWhisperer in no time.
quarkus-bedrock-demo
quarkus-bedrock-demo This is a sample project from my colleague Denis Traub, based on work from Vini , that demonstrates how to access Amazon Bedrock from a Quarkus application deployed on AWS Lambda.
multi-tenant-chatbot-using-rag-with-amazon-bedrock
multi-tenant-chatbot-using-rag-with-amazon-bedrock provides a solution for building a multi-tenant chatbot with Retrieval Augmented Generation (RAG). RAG is a common pattern where a general-purpose language model is queried with a user question along with additional contextual information extracted from private documents. To help you understand and deploy the code, check out the supporting blog post from Farooq Ashraf, Jared Dean, and Ravi Yadav, Build a multi-tenant chatbot with RAG using Amazon Bedrock and Amazon EKS
AWS and Community blog posts
Community round up
Starting our community round up this week with security, we have this post, Securing attacks targeted at user or kernel level for customer X with KubeArmor & AWS Bottlerocket, that explores the enhanced security the user can get by combined use of AWS Bottlerocket and KubeArmor (a runtime security engine). Next we have a couple of posts for Amazon Lightsail users from my colleague Sophia Parafina. In Load Testing Wordpress Amazon Lightsail Instances Sophia looks at how you can use open source testing tools like Locust to load test your sites and make sure they are up to handling the load you want to test against. Following that we have Deploy NGINX with AWS CloudShell and Lightsail In Five Steps that provides a nice cli driven way of deploying one of the most popular open source web servers, NGINX.
Next up we have Joe Stech who writes about an increasingly popular topic, Vector databases. In this instance, he looks at Milvus, and shows you how you can deploy this vector database on your Amazon EKS cluster in his post, Running the top open source Vector Database on AWS: What They Don’t Tell You in the Quickstart Guide.
To finish up this week, Mike Chambers and Haowen Huang have put together Deploying Falcon-40B Open-Source LLM on Amazon SageMaker: A Comparative Guide, that does what it says on the tin - provides a nice deep dive and walk through on how you can deploy Falcon-40B. They look at a number of options you have, and make sure you keep an eye out for a follow up post that is in the works.
Open Science Studio
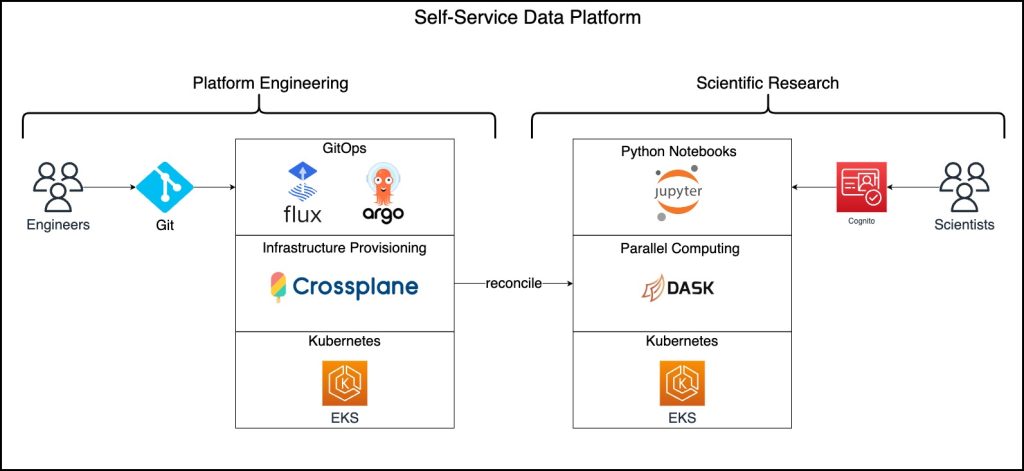
Super interesting post that explores how open source technologies, together with open source, is enabling scientists across the globe to collaborate. Jacob Mevorach, Carlos Santana, Isaac Mosquera, Manabu McCloskey, and Ramon Ramirez-Linan have come together to write, Enabling Scientists to Collaborate with Amazon EKS and Open Science Studio which looks at how they have combined a number of open source technologies (JupyterHub, Dask, Flux GitOps, Crossplane, and others) and deployed these on Amazon EKS. (On another note, it was awesome to meet up with Carlos at All Things Open. He really is an open source legend!)
Migrating to open source
We had a number of posts that looked at different aspects of how you can move/migrate workloads to open source technologies. We start with Migrate SQL Server to Babelfish for Aurora PostgreSQL using the Compass tool and AWS DMS where Amit Arora shows you how to migrate a Microsoft SQL Server database to Babelfish, including data migration with the AWS Database Migration Service (AWS DMS), using the SQL Server Northwind sample database for the migration.
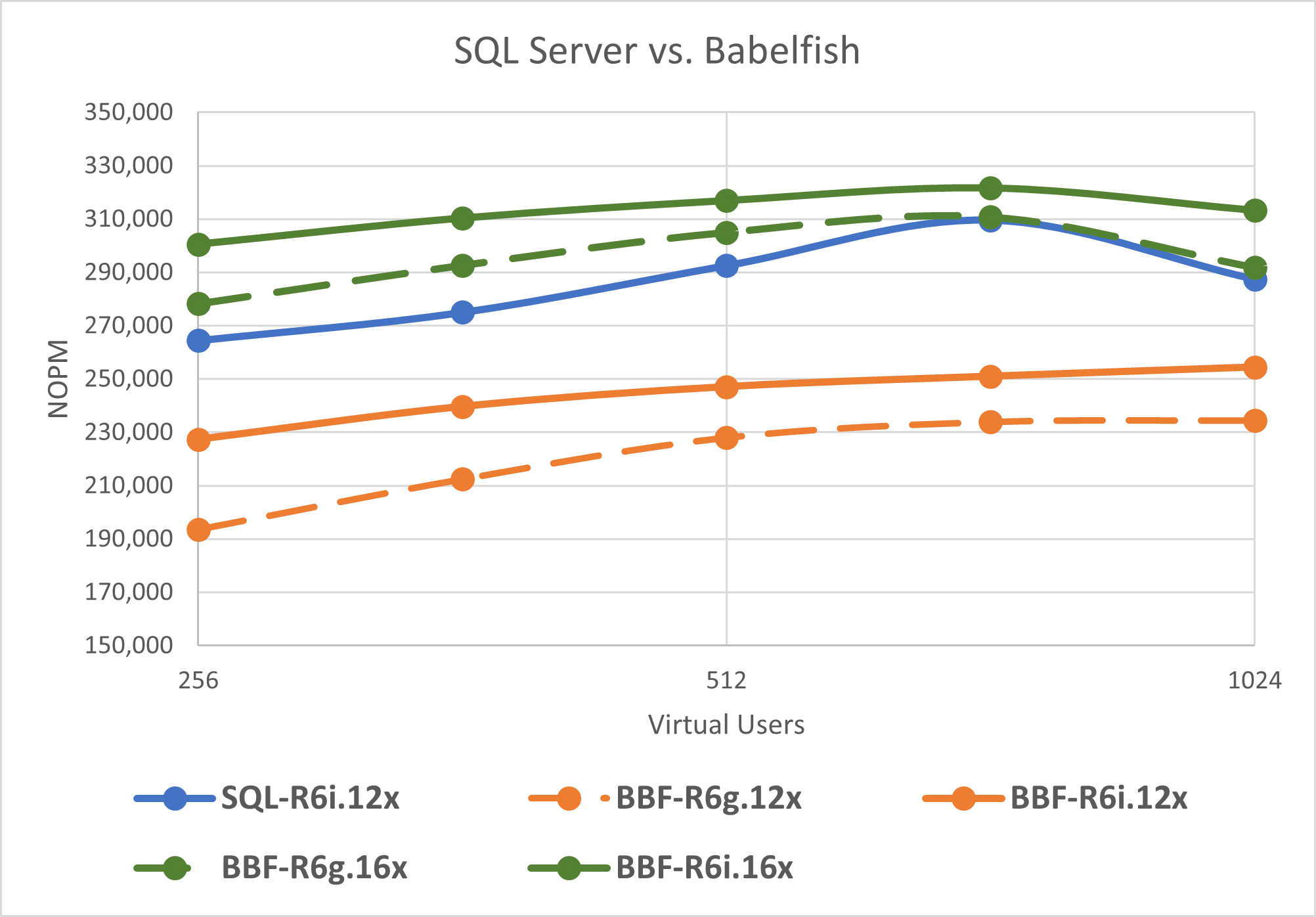
On a related note, we had Alex Zarenin write Comparing performance of new releases of Babelfish and comparing Babelfish performance with SQL Server that compares the performance of the newest releases of Babelfish for Aurora PostgreSQL and provide performance and price-performance comparisons between Babelfish and Microsoft SQL Server 2022.
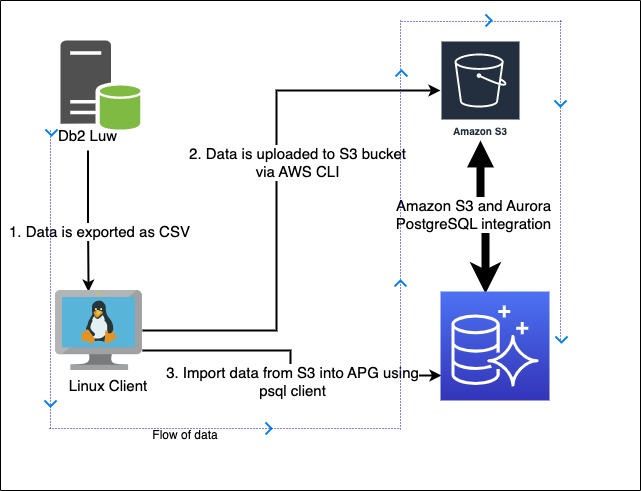
Keeping on the data theme, we had Migrate IBM Db2 LUW to Amazon Aurora PostgreSQL or Amazon RDS for PostgreSQL where Rakesh Raghav provide an overview of database migration from IBM Db2 LUW to a number of different PostgreSQL options on AWS.
Finally, we had Refactor to Modern .NET and Move to Linux, where Craig Bossie, Aditi Sharma, Pavankumar Kasani, and Runeet Vashisht discuss and walk you through some of your options when it comes to modernising your .NET workloads and how you can leverage open source technologies in doing so.
Big Data and Analytics
We had some great content covering the various big data and analytics open source technologies that you can use on AWS. Here is my pick this week:
- Run Apache Hive workloads using Spark SQL with Amazon EMR on EKS looks at how Amazon EMR on EKS releases 6.7.0 and higher include a Spark SQL job driver that lets directly run Spark SQL scripts via the StartJobRun API, enabling you to run your existing Hive scripts as SparkSQL jobs on Amazon EMR on EKS [hands on]
- Run Spark SQL on Amazon Athena Spark helps you get started with Spark SQL on Amazon Athena, and is the first in a series of posts (so keep an eye out for the next instalment) [hands on]
- Resolve private DNS hostnames for Amazon MSK Connect is a hands on guide that helps you set up MSK Connect using a private DNS, a feature that allows you to configure connectors to reference public or private domain names [hands on]

- Load data incrementally from transactional data lakes to data warehouses takes a look at different architecture patterns to keep data in sync and up to date between data lakes built on open table formats (Apache Hudi, Delta Lake, or Apache Iceberg) and data warehouses such as Amazon Redshift [hands on]
- Introducing concurrent segment search in OpenSearch dives deep into how you can improve search latency across a variety of workload types with concurrent segment search, a feature that requires non-trivial changes but can yield great results [hands on]
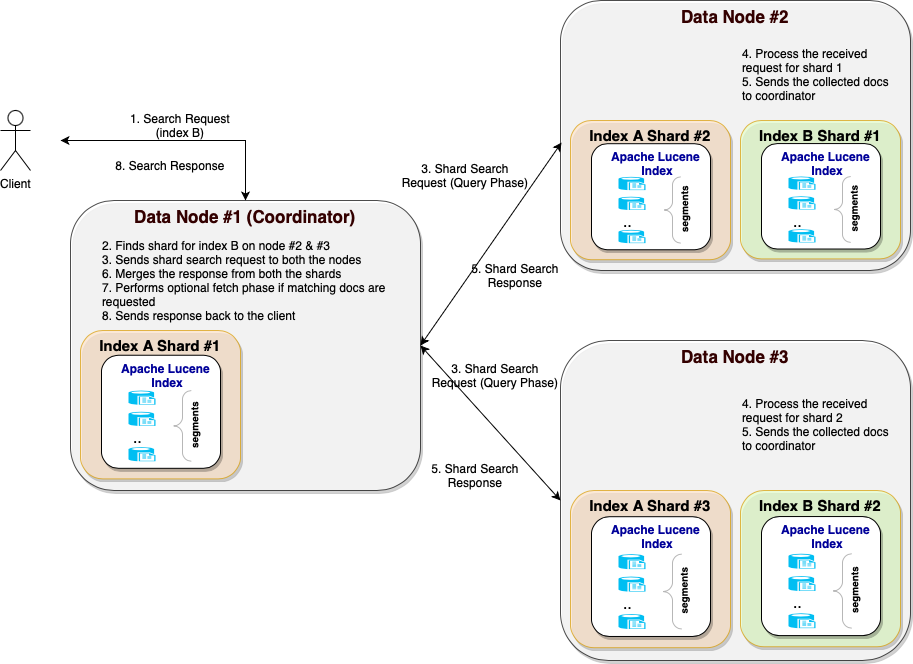
- Building a Data Lakehouse with Amazon S3 and Dremio on Apache Iceberg Tables looks at how efficiently you could implement a data lakehouse using Amazon Simple Storage Service (Amazon S3) and Dremio on Apache Iceberg [hands on]
Other posts and quick reads
- Build multi-layer maps in Amazon OpenSearch Service provides a hands on guide on how to use multi-layer maps in OpenSearch Service [hands on]

- Persistent storage for Amazon AppStream 2.0 Linux Fleets on Amazon Elastic File System looks at some education use cases around the use of Linux based virtual desktops and additional storage requirements, and how you can leverage AWS services to address those [hands on]
- Build ROSA Clusters with Terraform takes a look at the official Red Hat Cloud Services Provider for Terraform, that enables you to automate the provisioning Red Hat OpenShift Service on AWS clusters (ROSA) with Terraform [hands on]
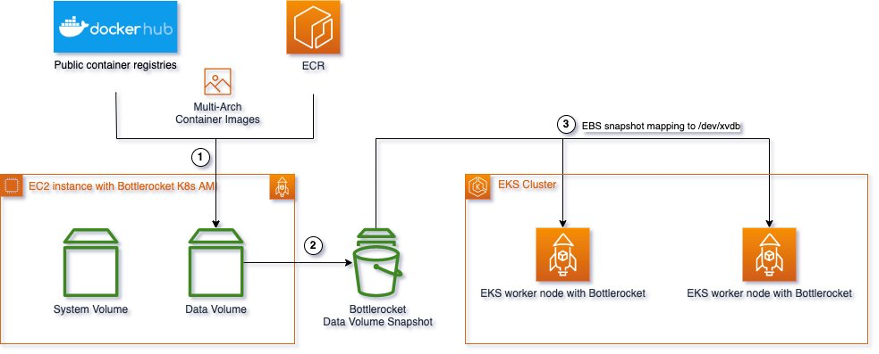
- Reduce container startup time on Amazon EKS with Bottlerocket data volume is a great post that shows how using the data volume of Bottlerocket instances to prefetch container images can significantly reduce the time required to pull large images from Amazon ECR, dramatically improving the efficiency and performance of container startup on Amazon EKS by decreasing boot time [hands on]
Quick updates
OpenSearch
We had a few updates for OpenSearch users.
Announced last week, Amazon OpenSearch Serverless now supports automated data deletion based on time through easy set up of index lifecycle policies. OpenSearch Serverless is the serverless option for Amazon OpenSearch Service that makes it simpler for you to run search and analytics workloads without having to think about infrastructure management. OpenSearch Serverless introduces new index lifecycle policies to streamline the management of data retention and deletion. You can now use APIs or a simple configuration interface in the AWS Console to set data retention polices for the time series collections, eliminating the need for creating daily indexes or scripts to delete the aged data. OpenSearch Serverless automatically and efficiently handles index roll over and deletion of aged data based on index policies, minimising the operational overhead.
Following that was news that Amazon OpenSearch Service now supports new administrative options that provide more granular control over troubleshooting potential issues with your cluster. These options include the ability to restart the OpenSearch process on a node, and the ability to restart a data node. Amazon OpenSearch Service monitors key health parameters of nodes for anomalies and takes corrective actions to help clusters remain stable. Expert users of OpenSearch Service have indicated interest in more control over some of these automated mitigation actions. With the new administrative options to restart the OpenSearch process on a node, and the ability to restart a node, customers have more control , if and when required. Customers can trigger these actions using the AWS Console, command line interface (CLI), or the AWS software development kit (AWS SDK).
We also had a new post, Announcing Data Prepper 2.5.0 that looks at the the latest version of Data Prepper (a server-side data collector capable of filtering, enriching, transforming, normalising, and aggregating data for downstream use), which includes a new OpenSearch source, new dissect and translate processors, and additions to the existing key-value processor.
PostgreSQL
A few updates this week.
Following the announcement of updates to the PostgreSQL database by the open source community, we have updated Amazon Aurora PostgreSQL-Compatible Edition to support PostgreSQL 15.4, 14.9, 13.12, 12.16, and 11.21. These releases contains product improvements and bug fixes made by the PostgreSQL community, along with Aurora-specific improvements. This release also contains new features and improvements such as Babelfish for Aurora PostgreSQL version 3.3. Refer to the Aurora version policy to help you to decide how often to upgrade and how to plan your upgrade process. As a reminder, if you are running any version of Amazon Aurora PostgreSQL 11, you must upgrade to a newer major version by February 29, 2024.
Amazon Aurora PostgreSQL-Compatible Edition now supports v0.5.0 of the pgvector extension to store embeddings from machine learning (ML) models in your database and to perform efficient similarity searches. This version includes Hierarchical Navigable Small World (HNSW) indexing support, parallelisation of ivfflat index builds, and improves performance of its distance functions. Embeddings are numerical representations (vectors) created from generative AI that capture the semantic meaning of text input into a large language model (LLM). pgvector can store and search embeddings from Amazon Bedrock, Amazon SageMaker, and more. With pgvector on Amazon RDS, you can simply set up, operate, and scale databases for your GenAI applications. pgvector 0.5.0 adds support for HNSW indexing, which lets you execute similarity searches with low latency and produces highly relevant results. Additionally, HNSW in pgvector supports concurrent inserts, and updating/deleting vectors from the index. You can integrate your GenAI applications with pgvector using open-source frameworks like LangChain, simplifying searches over your vector data. The pgvector extension version 0.5.0 is available on Aurora PostgreSQL 15.4, 14.9, 13.12, 12.16 and higher
Kubernetes
For cloud native developers we had a series of updates this week on all things Amazon EKS.
Announced last week, was news that you can now bring your own managed IAM policies for use with EKS clusters, helping them meet regulatory and compliance requirements with fine grained control over what IAM permissions their Kubernetes clusters can assume. The EKS create cluster and create node group APIs require IAM roles with permissions attached to perform cluster operations like creating load balancers, describing and tagging EC2 instances, and downloading container images. EKS vends AWS managed policies to simplify the process of staying up to date on these required permissions. Now, you can attach customer managed policies to the cluster and node group IAM roles, and more easily meet compliance requirements, especially in highly regulated industries.
Following that was news last week that customers can update the subnets and security groups associated with their existing Amazon Elastic Kubernetes Service (EKS) clusters. This additional cluster management flexibility makes it simpler for cluster administrators to stay in sync with changes made to Amazon Virtual Private Cloud (VPC) resources.
Finally, AWS Marketplace announced a new subscription experience in the Amazon Elastic Kubernetes Service (EKS) console. This feature allows AWS customers to subscribe to Kubernetes software from leading Independent Software Vendors (ISVs) directly in the EKS console without needing to visit the AWS Marketplace website.
Apache Kafka
A couple of updates this week for Apache Kafka fans.
You can now integrate Amazon Managed Streaming for Apache Kafka (Amazon MSK) with Amazon EventBridge Pipes in the MSK service console, making it easier to send events from your Apache Kafka cluster to one of over 14 AWS service targets, including Amazon SQS, Amazon Kinesis Data Streams and Firehose, AWS Step Functions, Amazon SNS, or Amazon EventBridge event buses. The EventBridge Pipes integration also supports the EventBridge API Destinations target which uses API calls to send your events to software as a service (SaaS) applications or your own applications within or outside AWS. Getting your data flowing from your Kafka cluster is as simple as selecting a cluster, choosing “Create EventBridge Pipe” from the Actions menu, naming the connection, and selecting a target. You can customise batch size, batch window, starting position, and more, if desired. An optional filtering step allows only specific events to flow into the pipe and an optional enrichment step using AWS Lambda, AWS Step Functions, API Destinations, or Amazon API Gateway can be used to enrich or transform your events before they reach the target. By removing the need to write, manage, and scale undifferentiated integration code, the EventBridge Pipes integration allows you spend your time building your services rather than connecting them.
Amazon MSK Replicator is a new feature of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that enables you to reliably replicate data across Amazon MSK clusters in different or the same AWS region(s) in a few clicks. With MSK Replicator, you can easily build regionally resilient streaming applications for increased availability and business continuity. MSK Replicator provides automatic asynchronous replication across MSK clusters, eliminating the need to write custom code, manage infrastructure, or setup cross-region networking. MSK Replicator automatically scales the underlying resources so that you can replicate data on-demand without having to monitor or scale capacity. MSK Replicator also replicates the necessary Kafka metadata including topic configurations, Access Control Lists (ACLs), and consumer group offsets. If an unexpected event occurs in a region, you can failover to the other AWS region and seamlessly resume processing. You can also use MSK Replicator to provide lower latency data access in different geographic regions or to distribute data to your partners.
Check out the blog post from my colleague Danilo Poccia, Introducing Amazon MSK Replicator – Fully Managed Replication across MSK Clusters in Same or Different AWS Regions
Videos of the week
Generative AI: Image Identification and Classification with Amazon Bedrock, OpenSearch, and OpenCLIP
Another great piece from regular open source contributor Gary Stafford, where he walks you through how you can use some open source technologies together with Amazon Bedrock and some of the foundational models that it provides developer access to, to create a cool AI-powered Vehicle Damage Evaluator Demo.
You can also follow along in the blog post that accompanies this video: Image Identification and Classification with Amazon Bedrock, OpenSearch, and OpenCLIP

Reducing Costs by Maximizing Airflow and DAG Performance
There were lots of great session from the recent Apache Airflow Summit (check out the entire list of videos here) but this was my pick from the lot. John Jackson dives deep and looks at how you can maximise the efficiency and performance of your workflows in Apache Airflow, helping you to reduce your costs. A must watch video this week if you are a user of Apache Airflow.
Effectively running Java applications on AWS
There are several options to get Java running in the Cloud. Join Maximilian Schellhorn and Dennis Kieselhorst as they dive deep with a mix of presentations and live demonstrations to learn how to effectively run Java applications on Amazon Web Services (AWS). You will get an overview about recent cloud-native developments in the Java ecosystem and Amazon Corretto, a production-ready distribution of the OpenJDK. We’ll guide you through different deployment options both for containers and Serverless functions including services like AWS Lambda, Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS). You will also understand how to leverage development tools such as CLIs and IDE support, infrastructure as code and Observability tooling. After this session you will be able to make well informed decisions when running Java workloads on AWS.
AWS CDK Assets
In this video, Adam Keller explores a cornerstone feature of the AWS Cloud Development Kit (CDK)—Assets. This tutorial is designed to offer a comprehensive understanding of what CDK Assets are, why they’re an integral part of infrastructure management, and how you can effectively use them in your Infrastructure as Code (IaC).
You’ll learn the ins and outs of asset handling in AWS CDK, including how to seamlessly include static files like configurations, code, or even Docker images into your cloud deployment. We’ll walk through the types of assets you can manage, and how they interact with various AWS services like Lambda, S3, and ECR.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group, Palma November, 14th, 5pm-9pm Parc Bit - Fundació IBIT
I am happy to join Miguel Salvà at the PAWS (AWS User Group in Palma) for an evening of open source talks, covering a broad range of topics from OSPO’s, working with open source communities, and open source at Aamzon. Going to be great. You can find out more by checking out the user groups page, PAWS User Group
Big Data Europe 21st-24th November, Online/Vilnius, Lithuania
I will be speaking at the Big Data Europe event, talking about how you can shift left and apply modern developer approaches to manage your Apache Airflow workflows. This builds upon a lot of the other work I have done in this space, so am really looking forward to doing this talk.
Check out the event page for registration details, as well as to check out all the other sessions - many of which feature open source projects and technologies.
re:Invent November, 27th-1st December, Las Vegas, USA
The annual must attend conference for all AWS developers is back, and with another strong line up of open source sessions, chalk talks, builder sessions, workshops and more. There will be a super cool open source booth, with a line up of great demos - I have taken a sneak look and so make sure you check out the demo schedule on the booth.
Find out more by checking out the event page, re:Invent 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen