AWS open source newsletter #176
October 23rd, 2023 - Instalment #176
Welcome to #176 of the AWS open source newsletter, heading into Autumn and getting ready for the clocks to go back later in the week. How will you use that extra hour? Well, perhaps some of you might use it to check out this weeks new projects, which include a nice cli chat tool that uses Amazon Bedrock, a tool to help simplify deploying VSCode in the Cloud environments, and sample demos and code on chaos engineering, deploying Amazon Bedrock via AWS Lambda, and how you can use IAM Roles Anywhere to authenticate against external identity providers.
Or maybe you might use that extra hour to read up on the latest open source content, which this week features content on LangChain, Trivy, AWS CDK, Apache Spark, Pinecone, Redis, Postgres, pgVector, OpenSearch, ClickHouse, Chroma, Apache Iceberg, CfnGuard, Kubernetes, Karpenter, Kubecost, Amazon Corretto, NextJS, AWS Amplify, GraphQL, Ray, AWS Distro for OpenTelemetry, Grafana, Core WCF, AWS SAM, Amazon EMR on EKS, RabbitMQ, and Swift. That lot should keep you going.
Before you dive into the newsletter, I have a quick poll that I am looking to get more data points on. When you use open source projects, and integrate those with other services or technologies, I am looking to find out as a developer where you prefer to have the documentation. In the project repo, or with the technology you are integrating with? Please vote here, or add your a comment if you have another thought.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Rio Astamal, Parnab Basak, Efi Merdler-Kravitz, k.goto, dB., Elliott Cordo, Rajdip Chaudhuri, Avijit Goswami, Rajarshi Sarkar, Abi Asija, Verdant Ari Jain, Jonathan Katz, and Sebastien Stormacq.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
ask-bedrock
ask-bedrock is a new project that provide a command line interface that enables you to converse with your favourite Amazon Bedrock large language model. This tool is a wrapper around the low-level Amazon Bedrock APIs and Langchain. Its main added value is that it locally persists AWS account and model configuration to enable quick and easy interaction.
installer-vscode-for-web
installer-vscode-for-web is another tool from my fellow DA, Rio Astamal that simplifies the steps needed to turn your fresh cloud VM into fully functional VS Code for the web with HTTPS enabled. You can work from any device as long as it supports a modern web browser.

operatorpkg
operatorpkg is a set of packages used to develop Kubernetes operators at AWS. It contains opinions on top of existing projects like https://github.com/kubernetes/apimachinery and https://github.com/kubernetes-sigs/controller-runtime. In many cases, we plan to mature packages in operatorpkg before commiting them upstream.
Demos, Samples, Solutions and Workshops
lambda-bedrock-integration
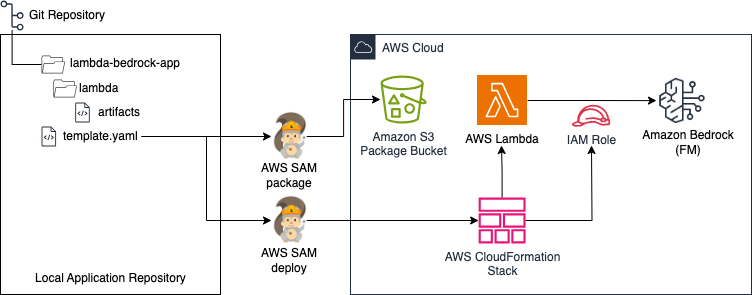
lambda-bedrock-integration This sample repository from my colleague Parnab Basak has sample code to integrate AWS Lambda with Amazon Bedrock. .NET, Python, Java, and NodeJS runtimes are supported, and you can use this with AWS SAM.
chaosinjection-lambda-samples
chaosinjection-lambda-samples This repository contains a code sample demonstrating how to inject chaos into AWS Lambda functions seamlessly. By leveraging AWS Fault Injection Simulator (FIS), it allows you to simulate real-world unpredictable conditions like increased latency or random function failures, without modifying your function’s original code. I have featured Efe’s project in an earlier newsletter (#167), and he has taken an innovative solution for injecting chaos into AWS Lambda via FIS and enhanced it. If you are heading out to re:Invent, he will be giving a talk on integrating Rust with AWS Lambda, so be sure to check that out.
blog-devops-iamra
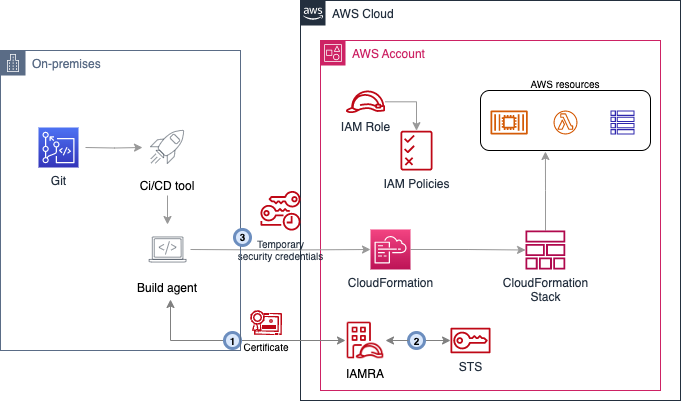
blog-devops-iamra this repo provides code that shows you how you can combine IAM Roles Anywhere and an existing public key infrastructure (PKI) to authenticate external build agents to AWS by using short-lived certificates to obtain AWS temporary credentials. You can follow along and build this by reading the supporting blog post, Enable external pipeline deployments to AWS Cloud by using IAM Roles Anywhere
aws-hpc-recipes
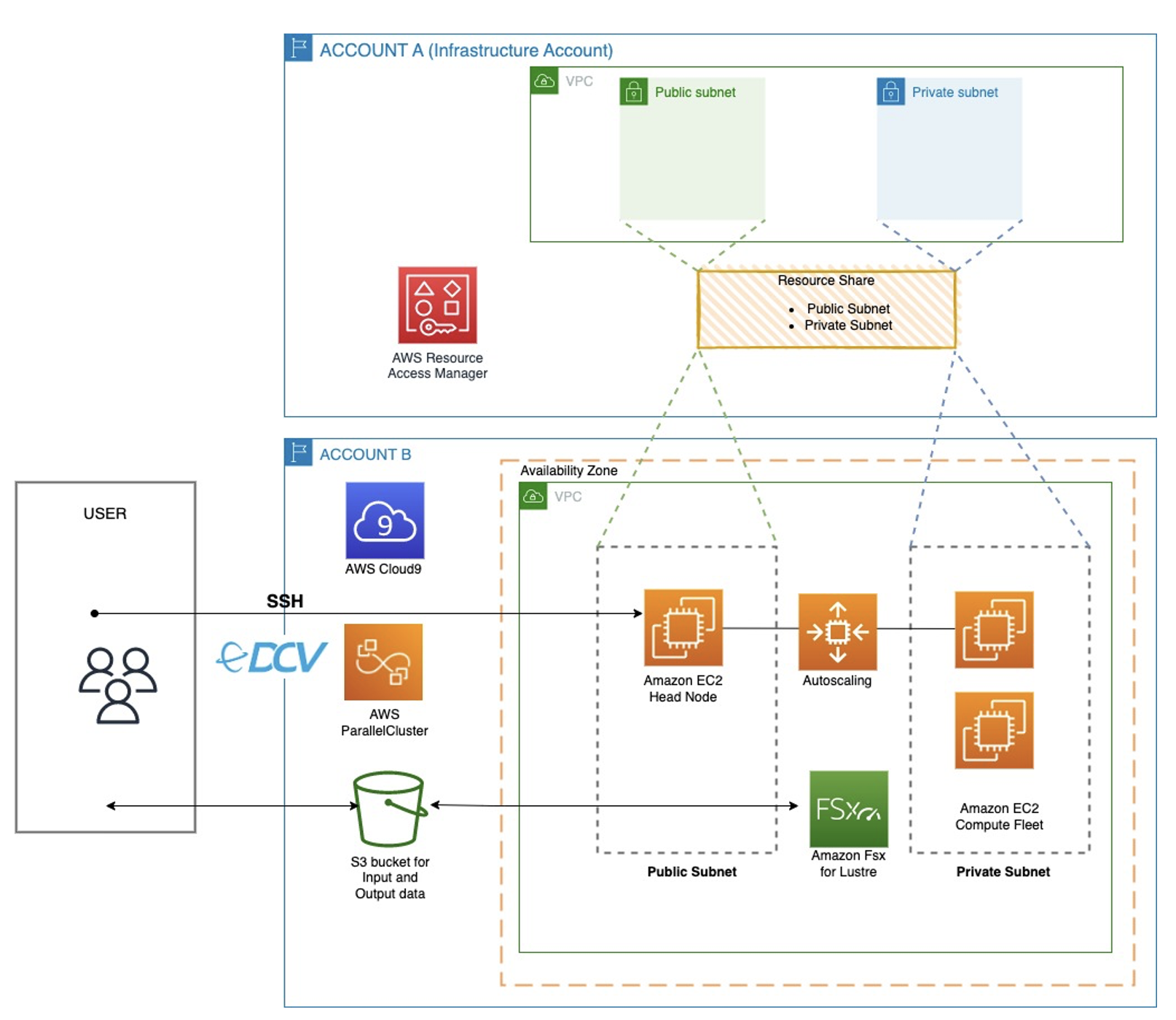
aws-hpc-recipes This repository contains example recipes that demonstrate how to build HPC systems using AWS ParallelCluster, and provides reference CloudFormation templates designed to work together to build complete HPC environments. Introducing a community recipe library for HPC infrastructure on AWS dives deeper into this project, looking at a few of the examples you can find [hands on]
bonus HPC content
- Introducing login nodes in AWS ParallelCluster shows you how you can use a new feature in AWS ParallelCluster 3.7 to add login nodes to your cluster, out of the box [hands on]
- Implementing AWS ParallelCluster in a Shared VPC shows you how you can get ParallelCluster up and running in a shared VPC environment where the VPC belongs to one account and it is shared to another account for resource deployment operations [hands on]
AWS and Community blog posts
Community round up
This weeks community roundup starts with AWS Community Builder k.goto who has put together Container image scanning with Trivy in AWS CDK that looks at a new CDK construct which you can find in the Construct Hub, that uses Trivy to perform security diagnostics on container images. Trivy is an open source security tool that can perform vulnerability testing and diagnostics on a wide range of targets, including container images, file systems, and even AWS accounts. Next up is dB. who has put together Getting started with Vector DBs in Python, which is a fantastic look at a number of Vector DB options, providing some sample code and details on how to work with each. This is an essential read this week, and dB. leaves us with an important question at the end: “I also wonder whether we need a generic client that’s agnostic to which vector DB is being used to help make code portable?” - what do you think? dB. provides an idea of what this might look like, so if you are interested in this space, why not reach out and collaborate. Finishing off this week we have with AWS Hero Elliott Cordo with his post, Running Jobs on Athena Spark explores running Spark jobs on Amazon Athena, and shares why he thinks these are “magical”.
Apache Iceberg
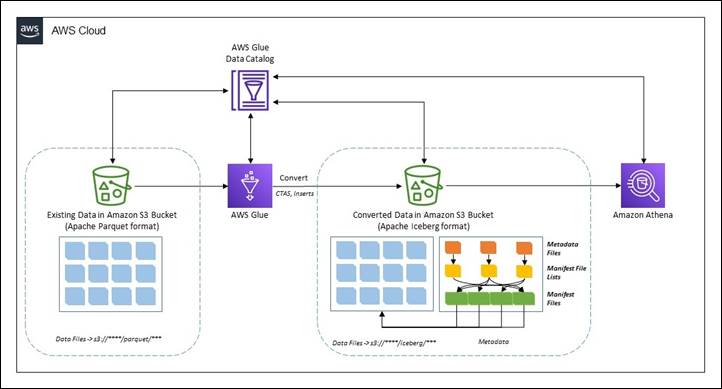
Apache Iceberg is an open source high-performance format for huge analytic tables, that solves the challenges with traditional approaches to managing data in data lakes. A couple of posts for you, starting with Migrate an existing data lake to a transactional data lake using Apache Iceberg where Rajdip Chaudhuri shows you how you can convert existing data in an Amazon S3 data lake in Apache Parquet format to Apache Iceberg format to support transactions on the data. In the post, he uses a feature of AWS Glue to run Jupyter Notebook based interactive session. [hands on]
Next we have Avijit Goswami and Rajarshi Sarkar who have put together Apache Iceberg optimization: Solving the small files problem in Amazon EMR, that looks at a new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena. Great post, with some solid data points at the end so check it out.

Celebrating CDKDay
Back on September 29th, CDK Day 2023 took place, celebrating all things CDK related (so CDK, cdk8s, cdktf, projen). Three tracks, including for the first time a dedicated Spanish track. Whilst not specifically related to this event, there has been some great content on AWS CDK published over the last couple of weeks, so here are might highlights.
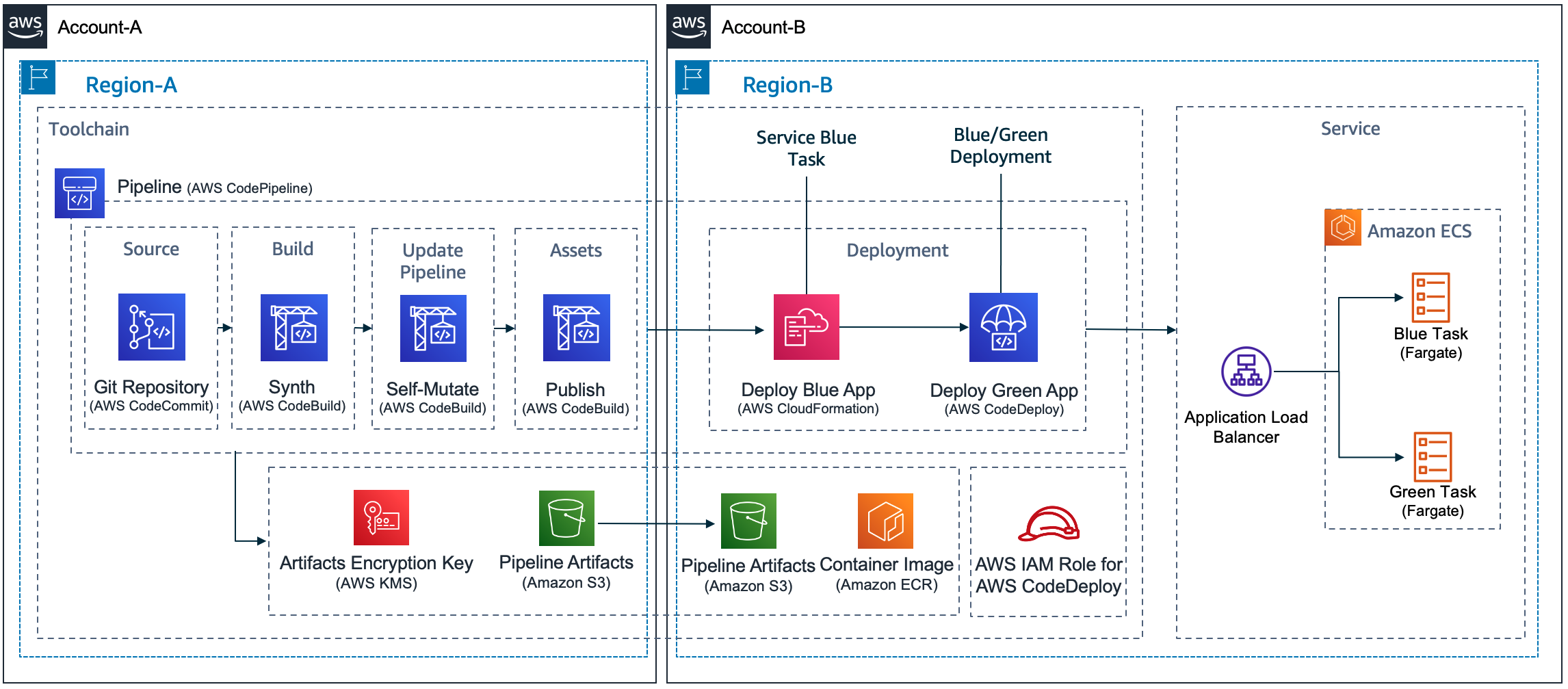
- Blue/Green deployments using AWS CDK Pipelines and AWS CodeDeploy is a nice deep dive, including demo, looking at the challenges associated with the creation of a pipeline that deploys an application using CodeDeploy in different combinations of accounts and regions [hands on]
- How to import existing resources into AWS CDK Stacks shows you how to import existing AWS Resources into an AWS CDK Stack, as well as looking at the recent new feature introduced by the AWS CDK team, that automates this process (via the cdk import command) [hands on]
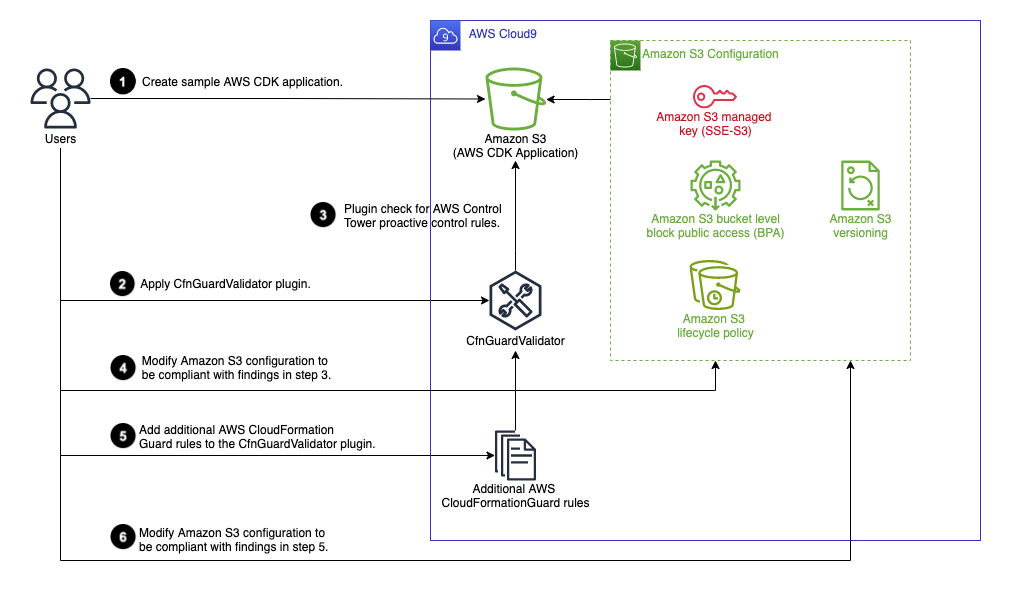
- Accelerating development with AWS CDK plugin – CfnGuardValidator explains how to integrate the CfnGuardValidator plugin (an AWS CDK plugin that allows developers to locally validate their AWS CDK code using AWS Control Tower proactive controls or AWS CloudFormation Guard rules) into your existing AWS CDK application [hands on]
- Enhancing Resource Isolation in AWS CDK with the App Staging Synthesizer explores a new experimental library, the App Staging Synthesizer, that enhances resource isolation and provides finer control over staging resources in CDK applications [hands on]
Cloud Native
- Build and deploy to Amazon EKS with Amazon CodeCatalyst provides a useful and practical guide on how teams can easily get started building, scanning, and deploying a microservice application to an EKS cluster using CodeCatalyst [hands on]

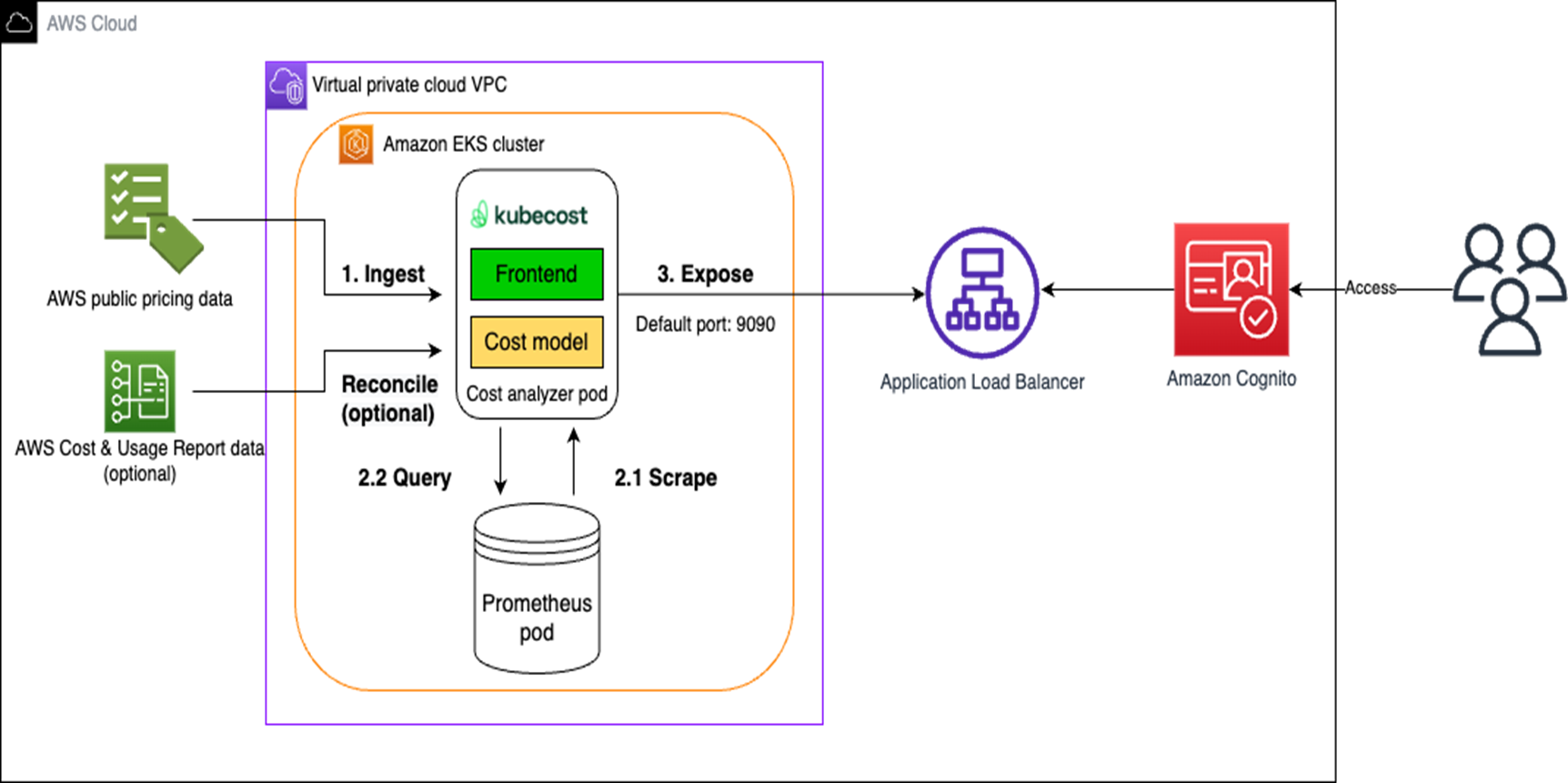
- Manage scale-to-zero scenarios with Karpenter and Serverless shows you how to scale your Amazon EKS clusters using cluster autoscaler and karpenter to save money and reduce your environmental impact [hands on]
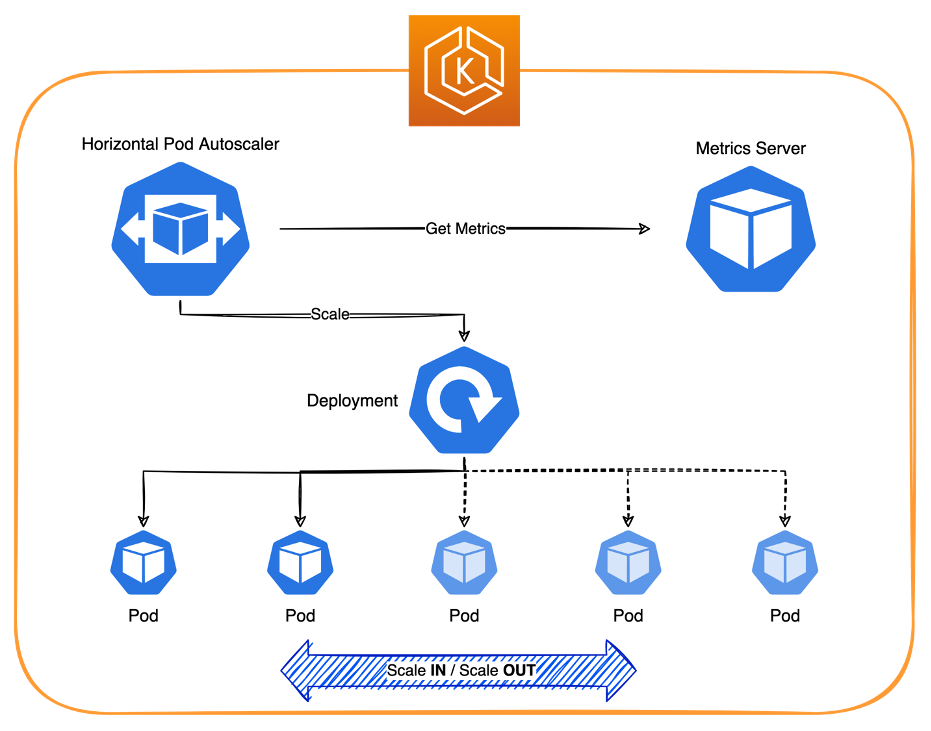
- Authenticate Kubecost Users with Application Load Balancer and Amazon Cognito provides a hands on walkthrough on how to leverage Kubecost with Application Load Balancer and Amazon Cognito for user authentication [hands on]
Other posts and quick reads
- Modern Tooling for Your Website using AWS, Contentful, and Next.js is a tutorial that helps you build a blog website from beginning to end with an A-level Lighthouse performance scale and low maintenance friction [hands on]
- Query Heterogeneous Data Sources through AWS AppSync GraphQL APIs looks at why you might want to consider using GraphQL when architecting solutions that have multiple data sources
- Orchestrate Ray-based machine learning workflows using Amazon SageMaker looks at the benefits of using Ray (an open-source distributed computing framework) and Amazon SageMaker for distributed ML, and provide a step-by-step guide on how to use these frameworks to build and deploy a scalable ML workflow [hands on]
- Monitor edge application performance using AWS IoT Greengrass and AWS Distro for OpenTelemetry demonstrates how to monitor and optimise edge application performance by enabling the power of AWS IoT Greengrass, AWS Distro for OpenTelemetry and Amazon Managed Grafana with a specific focus on the distributed tracing aspect [hands on]
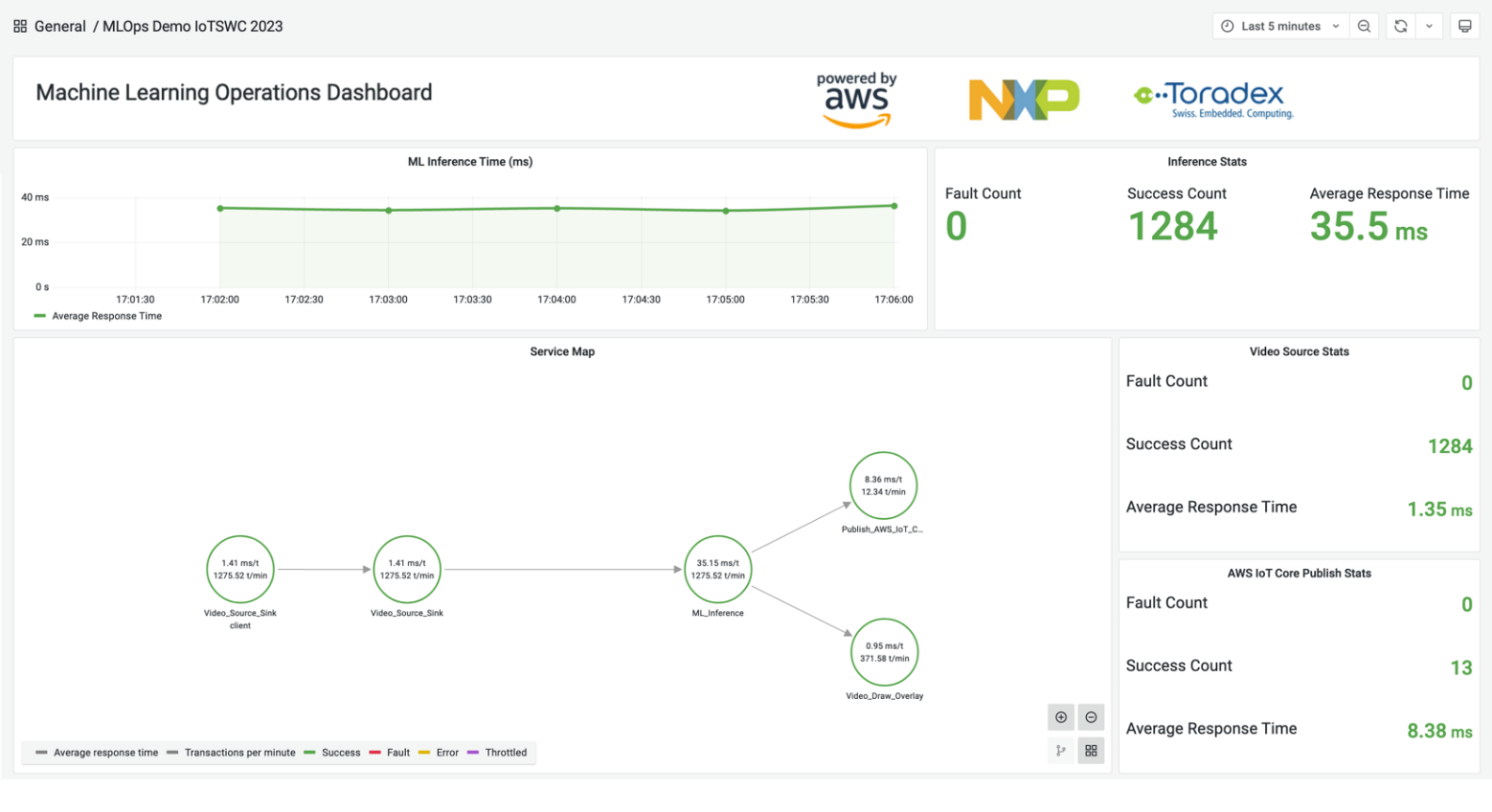
- Monitor IoT device health at scale with Amazon Managed Grafana provides a sample IoT health dashboard using Amazon Managed Grafana, that can scale to thousands of devices [hands on]

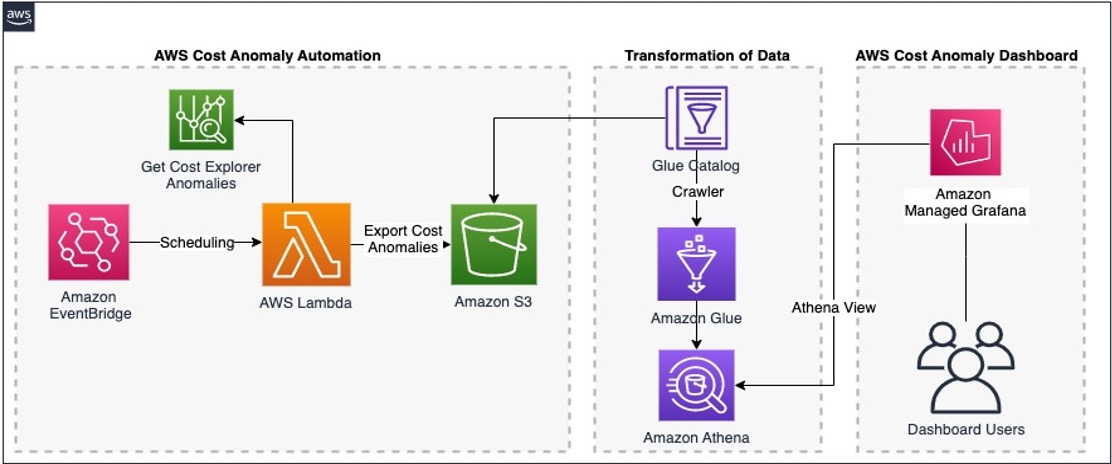
- Centralize AWS Cost Anomaly Detection using Amazon Managed Grafana is an essential read for those on a cost optimisation journey, and explains how Amazon Managed Grafana dashboards help our customers visualize and track the AWS cost anomalies that are outside the pattern of historical usage [hands on]
- Build an ultra-low latency online feature store for real-time inferencing using Amazon ElastiCache for Redis looks at how our customers are building online feature stores using an open-source feature store framework called Feast, to support mission-critical ML use cases that require ultra-low latency [hands on]

Quick updates
Amazon Corretto
On Oct 17, 2023 Amazon announced quarterly security and critical updates for Amazon Corretto Long-Term Supported (LTS) versions of OpenJDK. Corretto 21.0.1, 17.0.9, 11.0.21, and 8u392 are now available for download. Amazon Corretto is a no-cost, multi-platform, production-ready distribution of OpenJDK.
Core WCF
We had a couple of important updates for .NET developers last week.
Starting off with news that the .NET open-source team announced the release of CoreWCF v1.4.0 GA and CoreWCF v1.5.0-preview1. While 1.4.0-preview had generic Queue transport and RabbitMQ implementation, we received an open-source contribution for Apache Kafka implementation on top of our generic transport implementation. We have included this contribution in 1.4.0 GA which would enable Amazon Managed Kafka out of the box for dispatching and processing messages. They also released CoreWCF v1.5.0-preview1 which has additional binding implementation using Unix Domain Sockets (UDS) for CoreWCF and the WCF Client. Unix Domain Socket in CoreWCF and WCF Client will unlock an alternative for NetNamedPipe on Linux. NetNamedPipe only works on Windows, while UDS is cross-platform and is supported on both Linux and Windows. This is also the second most voted feature request in the CoreWCF open-source repository. With this launch in addition to adding a direct alternative in Linux, we are removing another hurdle for our customers to move to Linux with WCF applications using Named Pipes.
Following that was an update that the .NET open-source team announced last week support for Amazon SQS in Core WCF. They released aws-corewcf-extensions, an open-source project to augment Core WCF and the support for Amazon SQS therein. Customers can now use Amazon SQS queues with CoreWCF applications as they modernise their WCF applications to CoreWCF using the NuGet packages AWS.CoreWCF.Extensions and AWS.WCF.Extensions. This SQS support is built on top of CoreWCF.Queue implementation that currently powers CoreWCF.RabbitMQ and CoreWCF.Kafka which further works with AmazonMQ and Amazon MSK. This launch adds Amazon SQS on top of these existing extensions. In addition, aws-corewcf-extensions will act as a foundational open-source project to build other AWS service integrations to work with CoreWCF as the customer needs arise. This will also provide both internal AWS builders and external .NET community with an opportunity to build AWS integrations into a cohesive repository that is supported with a pipeline to ship packages to NuGET.
AWS SAM
Developers using SAM CLI to author their serverless application with Lambda functions can now create and use Lambda test events to test their function code. Test events are JSON objects that mock the structure of requests emitted by AWS services to invoke a Lambda function and return an execution result, serving to validate a successful operation or to identify errors. Previously, Lambda test events were only available in the Lambda console. With this launch, developers using SAM CLI can create and access a test event from their AWS account and share it with other team members. This capability makes it easier for developers using SAM CLI to collaborate and streamline testing workflows. It also allows developers to use a consistent set of test events across their entire team. Developers can make test events available to other team members in their AWS account using granular IAM permissions.
OpenSearch
The Amazon OpenSearch Service has expanded its geospatial capacities. With new aggregation support in version 2.9, you can do more statistical analysis on your data, making it simpler to draw conclusions and interpret them. With Amazon OpenSearch Service Version 2.9, we have added Geo Bounds, Geo Centroid, Geo Hash, and Geo Title. The new aggregations are available through OpenSearch APIs. Different aggregations can be used to gather insights on high-level overview of trends, patterns and establish co-relations within the data.
In other OpenSearch news, security analytics in Amazon OpenSearch Service added native support for Open Cybersecurity Schema Framework (OCSF) formatted data, that provides security detection rules for OCSF data ingested from Amazon Security Lake. In addition, security analytics also supports ingesting virtually any custom log type and creating custom detection rules. Correlation engine helps reduce incident response time by analysing and highlighting connections between potential security incidents. Previously, customers had to map and convert OCSF data to another supported format to run security detection rules. Now, security analytics supports OCSF formatted data and includes the ability to run detection and correlation rules on this data. Along with currently supported security event log sources, customers asked to support custom application logs. By extending the security capabilities supported for prepackaged log types to custom log types, customers can get a comprehensive view of security events across their organisation. Using the correlation engine, customers can detect relationships between logs generated from different sources, helping to reduce incident detection, analysis, and response times.
If that was not enough, we have more. Search Pipelines is a new feature in OpenSearch 2.9, that makes it easy to build query and result processing pipelines. This lets you build search query and result processing as a composition of modular processing steps without complicating your application software. Individual processing steps can include query rewriters, natural language processors, result rerankers, and filters. Along with the search pipeline framework, OpenSearch now includes a variety of standard processors: a script processor, which allows you to preprocess search queries with Painless; a search request modifier which lets you add a filter in DSL; a field renamer; and so on. Search Pipelines are also the integration technology on which other important features are built, including score normalisation for hybrid lexical and semantic searching, and AWS Personalize and AWS Kendra reranking. Pipelines can be explicitly invoked for the current query, or can be applied to all search requests on an index.
Amazon EMR on EKS
Announced a couple of weeks ago, the Interactive Endpoints for Amazon EMR on EKS enables customers to run interactive workloads using an integrated development environment such as EMR Studio. For customers that require control on their execution environment, they will be able to use their self-hosted Jupyter notebooks as an another mechanism to run their interactive workloads via Interactive Endpoints.
Interactive Endpoints also enhance the flexibility when running interactive workloads with Amazon EMR on EKS. When using Interactive Endpoints, customers will also be able to build a custom image with their application dependencies and use that image in running their interactive jobs using Interactive Endpoints. This is especially useful for customers who may need to use libraries in their code, which are not available in the public distribution of Amazon EMR on EKS Spark runtime. Finally, for enhanced application resiliency and accessibility, Interactive Endpoints also provides customers the full control on the instance type where the JEG pod will be deployed, including the ability to specify on-demand instances via a managed or self-managed node group.
Amazon EMR on EKS Interactive Endpoints are generally available on Amazon EMR on EKS release version 6.10 and later, and is available in all commercial AWS regions where Amazon EMR on EKS is currently available.
RabbitMQ
Amazon MQ now provides support for RabbitMQ version 3.11.20, which includes several fixes and improvements to the previous versions of RabbitMQ supported by Amazon MQ - 3.11.16. If you are running earlier versions of RabbitMQ, such as 3.10, 3.9 or 3.8, we strongly encourage you to upgrade to RabbitMQ 3.11. This can be accomplished with just a few clicks in the AWS Management Console. We also encourage you to enable automatic minor version upgrades on RabbitMQ 3.11 to help ensure your brokers take advantage of future fixes and improvements in 3.11.
Swift
AWS announced a couple of weeks ago the general availability of Swift Package Manager (SwiftPM) support in CodeArtifact. Swift is the language of choice for developing applications on the Apple platform, and the Swift Package Manager is used to distribute source code in the Swift ecosystem. With SwiftPM support in CodeArtifact, developers can publish and download their Swift package dependencies to their CodeArtifact repository.
CodeArtifact implements the HTTP-based registry protocol for SwiftPM defined in Swift Evolution proposal 0292. Prior to SE-0292, SwiftPM could only consume dependencies stored in Git repositories. Now, packages can be stored outside of Git in a package registry, providing improved build reproducibility, efficiency, and performance. SwiftPM can consume packages stored in Git repositories and package registries as part of the same application build, avoiding the need to migrate all dependencies into registries up front. CodeArtifact SwiftPM works with existing clients such as XCode and the swift CLI. Once packages are stored in CodeArtifact, developers can reference these package dependencies in CodeArtifact with their existing tools.
Check out the supporting blog post from my colleague Sebastien, New – Add Your Swift Packages to AWS CodeArtifact
Videos of the week
Contributing to Critical Open Source Projects: Lessons from PostgreSQL
If you missed the keynote from Jonathan Katz at the Open Source Summit in Bilbao, then here is your chance to watch it. Amazon Web Services has increased its contributions to the open source PostgreSQL project dramatically over the past two years. Jonathan Katz, a PostgreSQL Core Team member, shares details about AWS contributions to the recent PostgreSQL 16 release, and our plans to contribute over the long term to help build a strong and sustainable PostgreSQL community.
Enterprise Vector-based Information Retrieval & Prompt Engineering at Scale
Verdant Ari Jain looks at some of the challenges in building next generation information retrieval systems, and walkthroughs a set open source technologies on AWS that you can use to address these.
AWS SAM 👉 Deploy Swagger API Tutorial
Abi Asija provides a short tutorial on how you can use AWS Serverless Application Model (AWS SAM) tool together AWS Cloud9 to to deploy a REST API using a Swagger definition file to AWS.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group, Palma November, 14th, 5pm-9pm Parc Bit - Fundació IBIT
I am happy to join Miguel Salvà at the PAWS (AWS User Group in Palma) for an evening of open source talks, covering a broad range of topics from OSPO’s, working with open source communities, and open source at Aamzon. Going to be great. You can find out more by checking out the user groups page, PAWS User Group
Big Data Europe 21st-24th November, Online/Vilnius, Lithuania
I will be speaking at the Big Data Europe event, talking about how you can shift left and apply modern developer approaches to manage your Apache Airflow workflows. This builds upon a lot of the other work I have done in this space, so am really looking forward to doing this talk.
Check out the event page for registration details, as well as to check out all the other sessions - many of which feature open source projects and technologies.
re:Invent November, 27th-1st December, Las Vegas, USA
The annual must attend conference for all AWS developers is back, and with another strong line up of open source sessions, chalk talks, builder sessions, workshops and more. There will be a super cool open source booth, with a line up of great demos - I have taken a sneak look and so make sure you check out the demo schedule on the booth.
Find out more by checking out the event page, re:Invent 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen