AWS open source newsletter #175
October 16th, 2023 - Instalment #175
Welcome to #175 of the AWS open source newsletter, back after recharging in the wonderful countyside of Yorkshire. I am publishing this weeks newsletter from Raleigh, North Carolina. All Things Open is happening this week, and you will catch me at the AWS booth where I will be showing off some cool open source stuff (Cedar, Apache Airflow, and a few others), and I also have a talk on Tuesday. If you are about, come say hello.
It has been a couple of weeks since the last AWS open source newsletter, and there was just so much good content to try and squeeze into this weeks edition, I have kept some of the good stuff for next week. In this weeks edition, following on from the launch of Amazon Bedrock, we have a number of new projects across different programming languages, that provide demos, examples, and tools to get you started. We have a couple of projects to help you keep track of your IPv4 addresses, and a very neat tool to help you with your AWS resource tagging hygiene. Finally, we have a new repo that hosts a number of blueprints to help you get started with Karpenter, so don’t miss that one.
From repos to written content, and this week we feature content across some of your favourite projects, which this week includes Redis, MariaDB, and PostgreSQL, Cloud Native Operational Excellence, CNOE, Crossplane, Apache Airflow, Apache Flink, Amazon EMR, Powertools for AWS Lambda, Kubernetes, Prometheus, Grafana, AWS Distributed OpenTelemetry(ADOT), Karpenter, CoreDNS, etcd, Istio, SUSE, AWS-LC, Spring Boot, Apache Kafka, Amazon Corretto, AWS CDK, Amazon Linux, Bottlerocket, cdk8s, AWS Amplify, NextJS, and more!
As always, check out the videos and events at the end of the newsletter. As always, if you have your own events you would like us to share with the readers, drop me a line.
Silent Disco @ Open Source Summit
As some may know, back in the day I used to spin “stacks of wax” (to use the vernacular!) and had a blast reliving old glories by putting together a silent disco at the Open Source Summit, EU in Bilbao. If you were there, or just want to try out some new music, I have put together the play list and Spotify play list for you here.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Cristian Magherusan-Stanciu, Abhishek Gupta, dB., François Bouteruche, Ricardo Ferreira, Dennis Traub, Vinicius Senger, Suman Debnath, Libby Clark, Colleen Betik, Madelyn Olson, Nima Kaviani, Brian Hammons, Manabu McCloskey, Paul Roberts, Christina Andonov, Boyan Dimitrov, Carlos Santana, Apoorva Kulkarni, Ulrich Hinze, Johannes Gunther, Patrick Oberherr, Mohan CV, Diego Colombatto, Muthuvelan Swaminathan, Bhupesh Sharma, Devika Singh, Pascal Vogel, Arnav Mediratta, Leah Tucker, Sheetal Joshi, Rene Brandel, Wesley, Danny Banks, Julien Simon, Gazal, and Michael Liendo.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
aws-ipv4-cost-viewer
aws-ipv4-cost-viewer is a new CLI tool from regular contributor to this newsletter, Cristian Magherusan-Stanciu. This tool shows the future public IPv4 costs for a variety of AWS resources across all AWS regions from an account. Very handy with the up coming changes to pricing for public IP addresses. Interestingly, the tool was creating with help from ChatGPT, and I like how Christian has included the details of the messages used to come up with the code. A trend I hope to see more of, so nice.
ipv4-usage-monitoring-for-aws
ipv4-usage-monitoring-for-aws is a script that follows on from the previous project, and allows you to iterate through all regions and all accounts in an organisation to enumerate all public IPs and flag certain IPs that may be unnecessary for further investigation.
aws-list-resources
aws-list-resources lists resources that are present in a given AWS account and region(s), that uses the AWS Cloud Control API. Discovered resources are written to a JSON output file. You will need to make sure you have AWS credentials configured for your target account. This can either be done using environment variables or by
amazon-bedrock-langchain-go
amazon-bedrock-langchain-go is a new project from my colleague Abhishek Gupta that provides a Langchain go wrapper that allows you to interact with Amazon Bedrock.
amazon-bedrock-go-sdk-examples
amazon-bedrock-go-sdk-examples is another project from Abhishek, this time providing examples of how you can use the AWS Go SDK to call Amazon Bedrock, providing plenty of examples that include a basic bootstrap example, chat bots, generating content, image generation and more.
opensearch-sdk-py
opensearch-sdk-py is a project I got to learn about during Open Source Summit, chatting with dB. It provides an experimental OpenSearch Python SDK enables you to implement Extensions that provide additional functionality to OpenSearch by registering that functionality through a set of extension points. When OpenSearch functionality is provided by a REST API, Extensions will use the OpenSearch Python Client to implement it. However, when REST APIs do not provide this information, its binary transport protocol is used. That protocol is implemented in this SDK. Unlike the OpenSearch Java SDK the Python implementation reimplements the protocol in pure python. This is on my to do list of project to try out.
awstaghelper
awstaghelper is the second project this week from Cristian Magherusan-Stanciu, and provides a command line tool to ease adding and managing tags to and from CSV files across the wide range of AWS resources. Tags are critical to managing AWS resources at scale, so why not give this a look and see if you can improve your tagging hygiene.
Demos, Samples, Solutions and Workshops
karpenter-blueprints
karpenter-blueprints provides a list of common workload scenarios following best practices. Each blueprint has detailed documentation where you will find here details of why configuring the Karpenter and Kubernetes objects in such a way is important when using Karpenter on EKS.
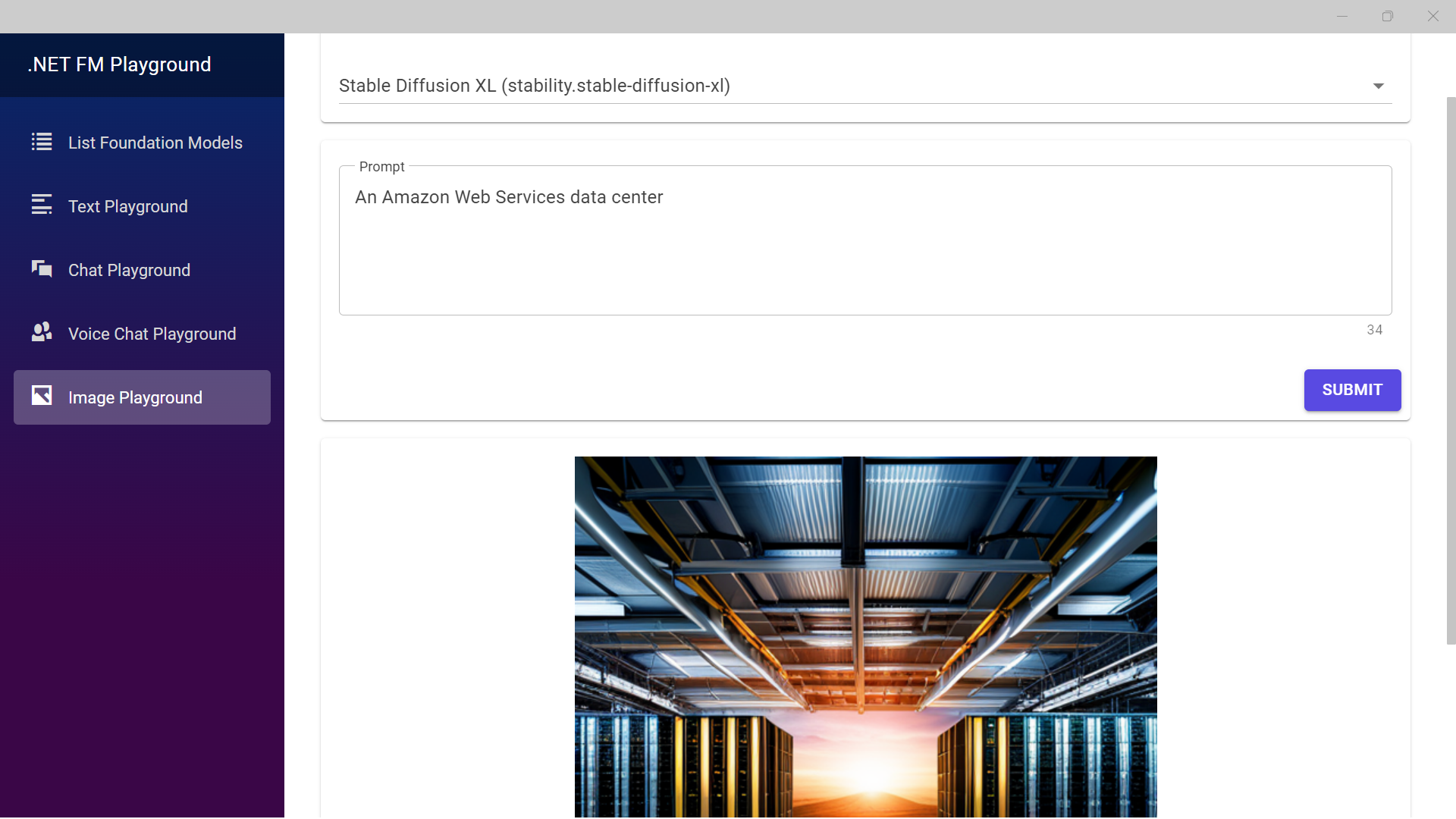
dotnet-fm-playground
dotnet-fm-playground is a .NET MAUI Blazor sample application from my colleague François Bouteruche showcasing how to leverage Amazon Bedrock from C# code. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API.
amazon-bedrock-with-builder-and-command-patterns
amazon-bedrock-with-builder-and-command-patterns is a simple, yet powerful implementation in Java from my colleague Ricardo Ferreira, that allows developers to write a rather straightforward code to create the API requests for the different foundation models supported by Amazon Bedrock. https://github.com/build-on-aws/amazon-bedrock-with-builder-and-command-patterns
amazon-bedrock-java-examples
amazon-bedrock-java-examples is a new repo from another colleague, Dennis Traub, that provides hands-on examples demonstrating the use of the Java SDK for Amazon Bedrock. Make sure you watch this repo as I know Dennis is working hard on growing the number of examples you can learn from and use.
quarkus-bedrock
quarkus-bedrock is a new demo repository from colleague Vinicius Senger that provides an example of how to access Amazon Bedrock from a Quarkus application deployed on AWS Lambda as a fat jar app.
llm-rag-vectordb-python
llm-rag-vectordb-python is the final repo this week from my colleague and regular open source contributor, Suman Debnath that provides sample applications and tutorials demonstrating the prowess of Amazon Bedrock with Python. Learn to integrate Bedrock with databases, use RAG techniques, and showcase experiments with langchain and streamlit.
AWS and Community blog posts
Open Source Databases
Great post from my colleagues in the open source team, who have put together this weeks must read post. In Behind the Scenes on AWS Contributions to Open Source Databases Libby Clark, Colleen Betik, and Madelyn Olson look at some of the ways AWS is investing in upstream open source database projects, including Redis, MariaDB, and PostgreSQL to help ensure the long term sustainability of the projects.
Cloud Native Operational Excellence (CNOE)
Platform engineering and developer portals are hot topics these days. In this post Cloud Native Operational Excellence (CNOE): A Joint Effort to Share Internal Developer Platform Tools and Best Practices, Nima Kaviani, Brian Hammons, Manabu McCloskey, and Paul Roberts, look at how organisations have come together to launch an open source initiative for building internal developer platforms (IDPs). Cloud Native Operational Excellence (aka, CNOE, pronounced Kuh.noo) is a joint effort to share developer tooling, thoughts, and patterns to help organisations make informed technology choices and resolve common pain points. Check out the blog post for more details on this.
On a related note, Christina Andonov, Boyan Dimitrov, Carlos Santana, and Apoorva Kulkarni published Enhancing an Internal Developer Platform (IDP) with Crossplane on EKS at SIXT, where they share how they were able to improve developer velocity by enhancing their IDP using open source tools.

Apache Airflow
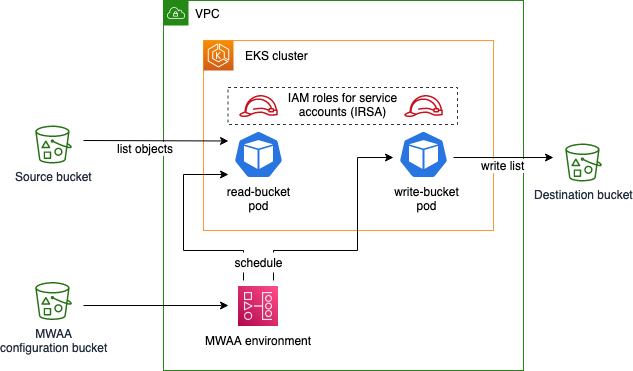
In the post, Set up fine-grained permissions for your data pipeline using MWAA and EKS, Ulrich Hinze, Johannes Gunther, and Patrick Oberherr show how you can improve security in a data pipeline architecture based on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by setting up fine-grained permissions. In this example, they use the EksPodOperator within Apache Airflow, as well as showing how you can use XComs to pass information between the tasks. [hands on]
Apache Flink
Open source your way, means providing customers the choice on how they want to run their open source workloads. Apache Flink is an open-source framework that customers use to run real-time stream processing on high throughput data sources. We recently renamed our managed Apache Flink offering (Managed Service for Apache Flink), but sometimes customers prefer to manage their own Apache Flink workloads.
This week we have posts and updates for both, starting off with Financial Services Spotlight – Amazon Managed Service for Apache Flink, where Mohan CV, Diego Colombatto, and Muthuvelan Swaminathan share part of a regular monthly spotlight into the Financial Services Industry and looks at some of the use cases where Apache Flink is bringing value, and looking in more details at the Amazon Managed Service for Apache Flink.
Also published last week was Modernize a legacy real-time analytics application with Amazon Managed Service for Apache Flink, where Bhupesh Sharma and Devika Singh look at ways to modernize a legacy, on-premises, real-time analytics architecture and build a serverless data analytics solution on AWS using Amazon Managed Service for Apache Flink [hands on]
Apache Flink on Amazon EMR on EKS
To finish up our Apache Flink roundup, last week we announced that Amazon EMR on EKS now supports Apache Flink, available in public preview. With this launch, customers who already use EMR can run their Apache Flink application along with other types of applications on the same Amazon EKS cluster, helping improve resource utilisation and simplify infrastructure management. For customers who already run big data frameworks on Amazon EKS, they can now let Amazon EMR automate provisioning and management.
Prior to today’s launch, customers could run self-managed Apache Flink applications on EKS, but they would be required to manually install and configure Apache Flink which requires in-depth understanding. With today’s launch, customers are only required to install the Flink Kubernetes operator and can use the operator to submit jobs directly to their EKS cluster while letting EMR on EKS manage the lifecycle of the Apache Flink application. This allows customers to share resources across their applications and use a single set of Kubernetes tools to centrally monitor and manage their infrastructure. Additionally, with this launch, customers also get access to key accessibility and monitoring features such as launching Flink application using jars in Amazon S3, monitoring integration with Amazon S3 and Amazon CloudWatch and container log rotation.
Powertools for AWS Lambda
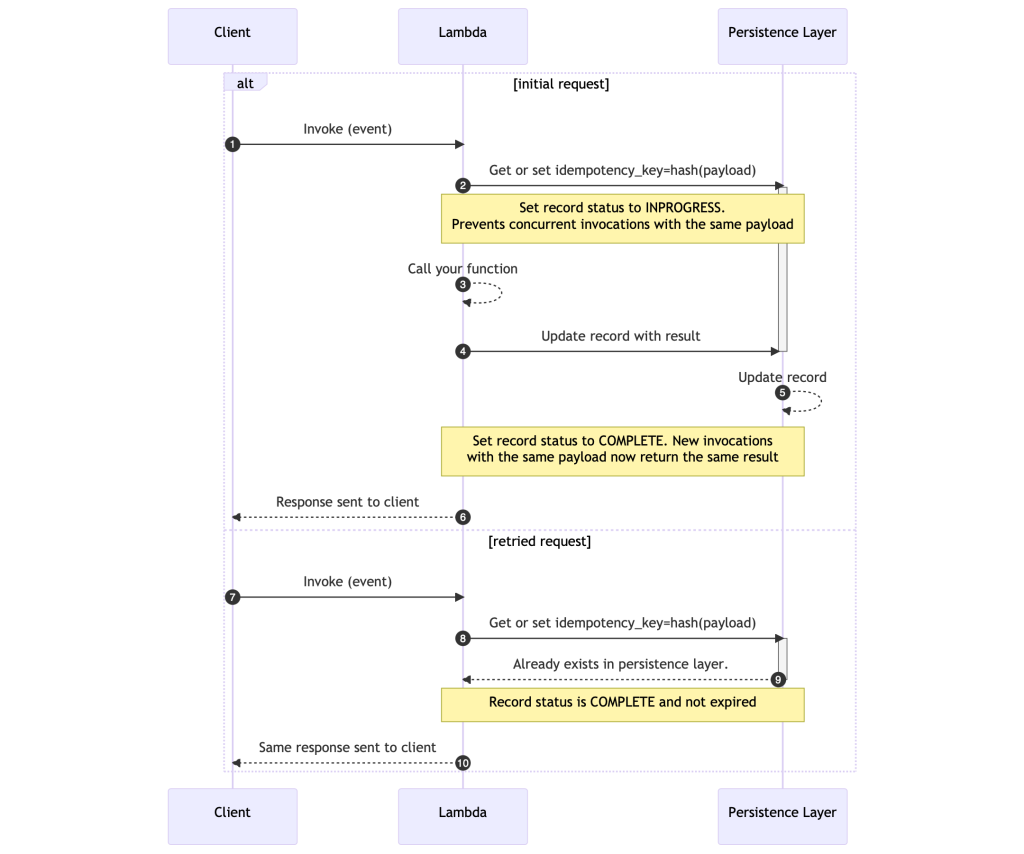
In Implementing idempotent AWS Lambda functions with Powertools for AWS Lambda (TypeScript), Pascal Vogel explains what idempotency is and how to make your Lambda functions idempotent using the idempotency utility for Powertools for AWS Lambda (TypeScript). [hands on]
Cloud native roundup
There was a lot of great cloud native content produced over the past couple of weeks, here are my highlights:
- Operating resilient workloads on Amazon EKS is an essential read this week that helps you build systems that are highly available, fault tolerant, and withstand interruptions to maintain business continuity by understanding and using failover mechanisms [hands on]

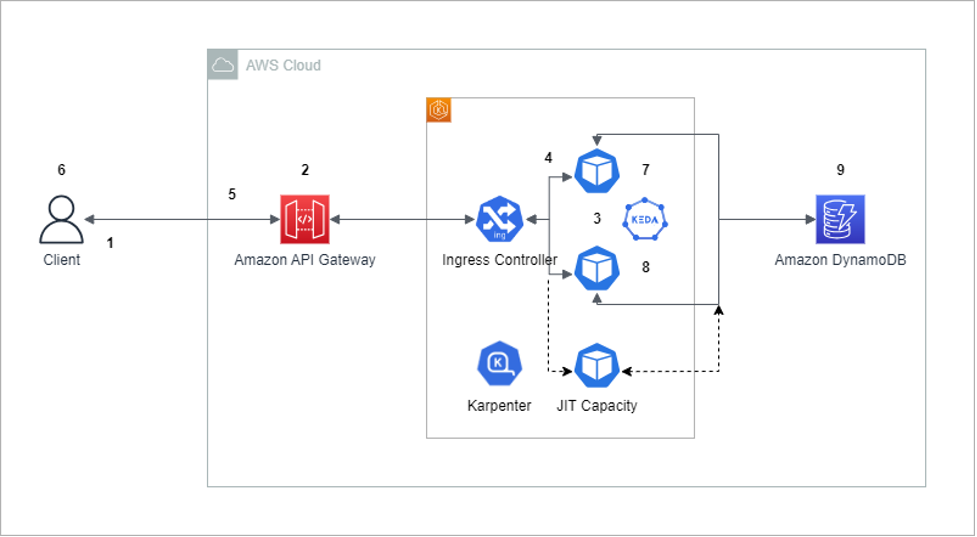
- Optimize webSocket applications scaling with API Gateway on Amazon EKS demonstrates how to redesign a web application to achieve auto scaling even for long-running clients, with minimal changes to the original application [hands on]
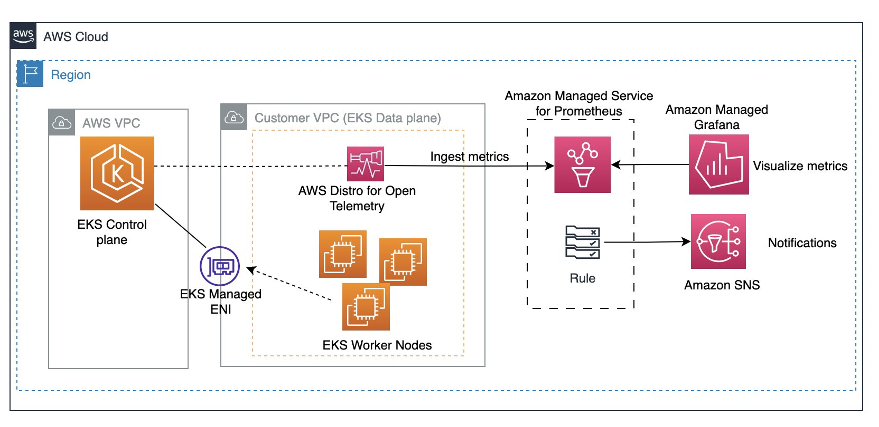
- Monitor Amazon EKS Control Plane metrics using AWS Open Source monitoring services explains why monitoring the Kubernetes control plane is important and then helps you through the steps to set up monitoring and alerting for Amazon EKS control plane metrics using AWS Distributed OpenTelemetry(ADOT), Amazon Managed Service for Prometheus, and Amazon Managed Grafana [hands on]
- How to reduce Istio sidecar metric cardinality with Amazon Managed Service for Prometheus explores strategies for optimising Istio sidecar metrics by streamlining cardinality and effectively managing high-volume data using Amazon Managed Service for Prometheus [hands on]
- How to upgrade Amazon EKS worker nodes with Karpenter Drift describes the mechanism for patching Kubernetes worker nodes provisioned with Karpenter through a gated Karpenter feature called Drift [hands on]
- Recent changes to the CoreDNS add-on looks at the new features are available in the coredns add-on and how you can use them
- Explore etcd Defragmentation in Amazon EKS delves into the defragmentation functionality in etcd (the primary data store in Amazon EKS, which stores cluster configuration, state, and metadata) and looks at the intricacies of the process and the strategies to minimise its impact on Amazon EKS components [hands on]
Other posts and quick reads
- The Safe SUSE Upgrade: Avoiding Pitfalls When Upgrading AWS Instances looks at how to upgrade SUSE Linux Enterprise Server (SLES) to the next service pack and how to perform a major version upgrade from SLES 12 to SLES 15 [hands on]
- AWS-LC is now FIPS 140-3 certified goes into more detail about the recent Federal Information Processing Standards (FIPS) 140-3 certification awarded by the National Institute for Standards and Technology (NIST) to AWS-LC, an open source cryptographic library
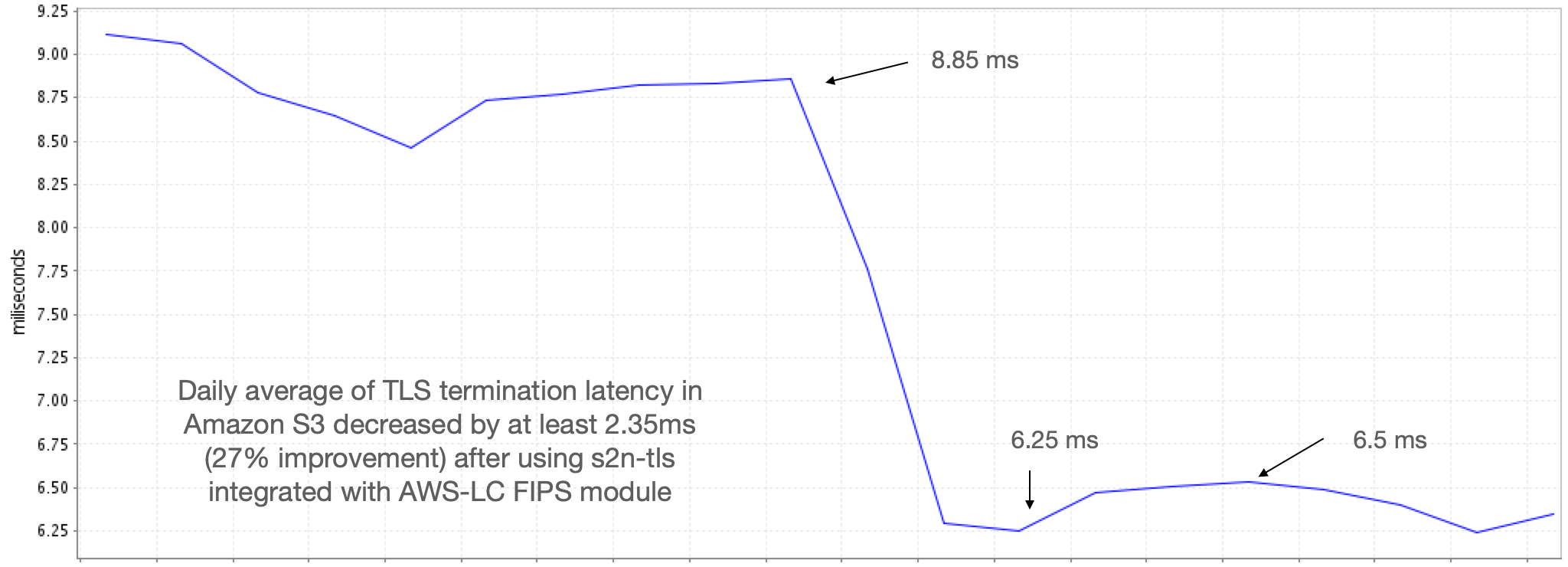
- Start Spring Boot applications faster on AWS Fargate using SOCI dives deep into techniques you can use to optimise your Java applications using SOCI that don’t require you to change a single line of Java code [hands on]

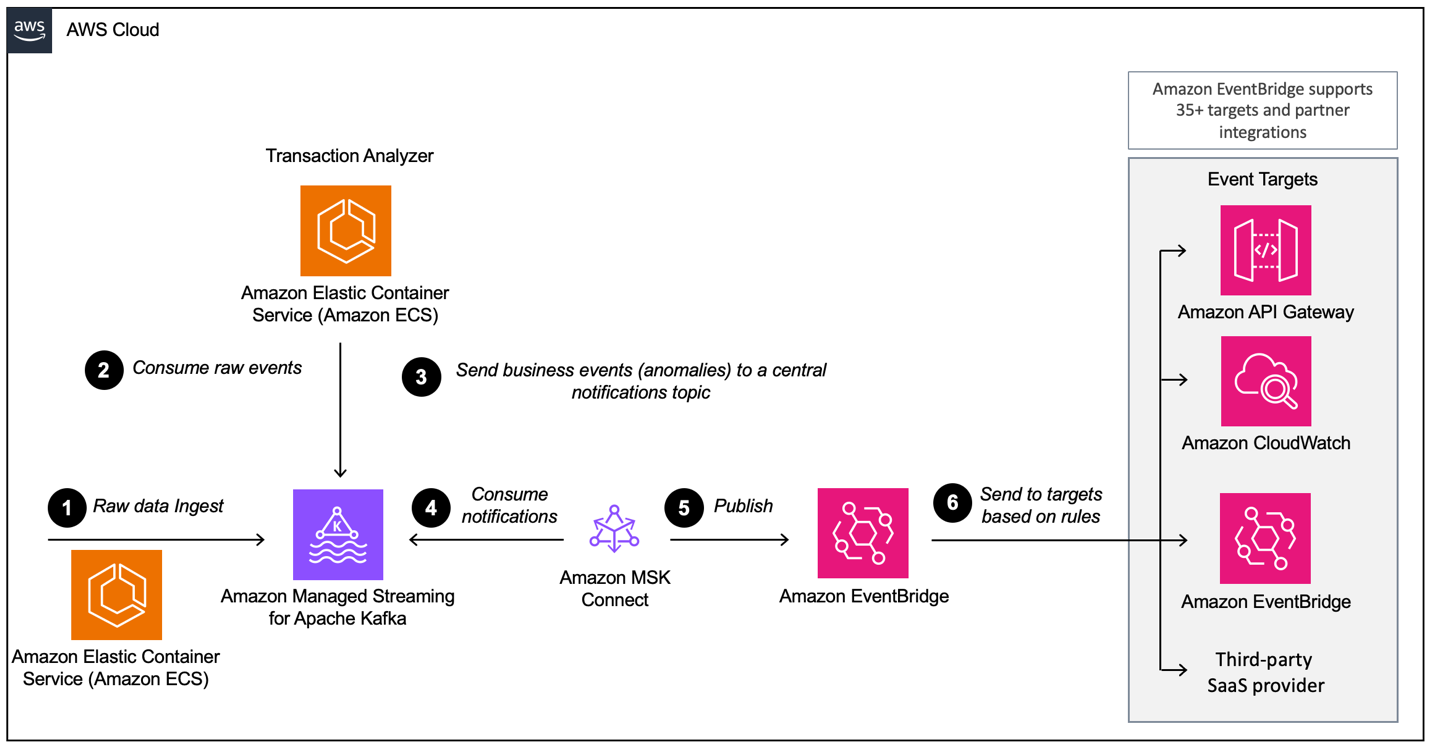
- Build event-driven architectures with Amazon MSK and Amazon EventBridge is a hands on guide on how you can use MSK Connect to run the AWS open-sourced Kafka connector for EventBridge, how to configure the connector to forward a Kafka topic to EventBridge, and how to use EventBridge rules to filter and forward events to CloudWatch Logs and a webhook [hands on]
- Amazon MSK Introduces Managed Data Delivery from Apache Kafka to Your Data Lake looks at a new capability of Amazon Managed Streaming for Apache Kafka (Amazon MSK) that allows you to continuously load data from an Apache Kafka cluster to Amazon Simple Storage Service (Amazon S3) [hands on]
Quick updates
Amazon Corretto
Amazon Corretto is a no-cost, multi-platform, production-ready distribution of OpenJDK. Corretto is distributed by Amazon under an open source license. Amazon Corretto 21 is now generally available. This Long Term Support (LTS) version supports the latest Java release, OpenJDK 21, and is available on Linux, Windows, and macOS. You can download Corretto 21 from our downloads page.
Some highlights of OpenJDK 21 include:
- Virtual Threads. Lightweight threads not bounded by OS threads.
- DNS stale caching. Reuses stale data to improve DNS resolver resiliency.
- Generational ZGC. Extension to Z Garbage Collector to maintain separate object generations.
- Record Patterns and Pattern Matching for Switch. New record-based objects and switch expressions.
- Sequenced Collections. These new interfaces represent collections with a defined encounter order.
- Key Encapsulation Mechanism API. An encryption technique for securing symmetric keys using public key cryptography.
There are also several preview features in OpenJDK 21:
- Foreign Function & Memory (FFM). An easier, cleaner and safer way to interoperate with native code.
- Structured Concurrency. Treats groups of related tasks running in different threads as a single unit of work.
- Vector API. Provides performance improvements using optimal vector instructions on supported CPU architectures.
- Scoped Values. Values may be safely and efficiently shared to methods without using method parameters.
- Unnamed Classes and Instance Main Methods. Makes it easier to get started with Java.
- String Templates. Couples literal text with embedded expressions and template processors to produce specialized results.
AWS CDK
A new feature of the CDK cli, cdk migrate caught my eye this week. This new cli option allows you to generate CDK apps, in Python and TypeScript, from existing CloudFormation code. There are some caveats and limitations, so make sure you check out the details. Certainly something I am going to try out and see how useful it is. Read more by checking out the PR in the project repo, cdk migrate
Amazon Linux
The availability of Ansible and Corretto 21 on Amazon Linux 2023 as a part of second quarterly update was announced last week. Starting with AL2023.2, customers can utilize Ansible’s core set of features, as well as a curated set of community supported Ansible collections. Ansible is a popular model-driven configuration management, multi-node deployment, and remote task execution system. Customers running Ansible on Amazon Linux can simply use it over SSH without additional software or daemons. With Corretto, you can develop and run Java applications on operating systems such as Linux, Windows, and macOS. Corretto comes with long-term support that will include performance enhancements and security fixes. Amazon Corretto is certified as compatible with the Java SE standard. Starting with AL2023.2, Amazon Corretto 21 is available for installation.
Bottlerocket
Bottlerocket, a Linux-based operating system that is purpose built to host container workloads, announced a new ECS-optimized AMI featuring version 6.1 of the Linux kernel. Customers using Bottlerocket with Amazon Elastic Container Service (Amazon ECS) can now benefit from additional features offered in this new AMI as well as the option to specify the needed Bottlerocket AMIs directly from the Amazon ECS console. In addition to the new kernel, the new Bottlerocket AMI includes a set of new features to enhance security (Secure Boot to ensure that every binary executed during boot has been signed) and improve resource management (support for cgroups v2 and support for specifying kernel command line parameters). The AMIs also support all the features added to Bottlerocket since May 2023, such as AppMesh, ECS Exec, and use of XFS for data partition. Now, customers can also select a wider variety of Bottlerocket AMIs directly from the ECS console. The available options include Bottlerocket x86_64, Bottlerocket arm64, Bottlerocket GPU x86_64, Bottlerocket GPU arm64.
Kubernetes
We had a few updates this week to share.
Amazon EKS Extended Support for Kubernetes Versions is now available in preview. Starting with Kubernetes v1.23, you can now use a Kubernetes version for up to 26 months from the time the version is generally available from Amazon EKS. Amazon EKS follows the Kubernetes project release cycle. For the first 14 months after a minor version is released as generally available, it is covered under standard support. Now, Amazon EKS Extended Support gives an 12 additional months of support for each Kubernetes minor version, for a total of 26 months of support. During the Extended Support period, Amazon EKS will continue to provide security patches for the Kubernetes control plane. In addition, Amazon EKS will release critical patches for the Amazon VPC CNI, kube-proxy, and CoreDNS add-ons, AWS-published EKS Optimized AMIs for Amazon Linux and Bottlerocket, and EKS Fargate nodes. Amazon EKS Extended Support for Kubernetes versions is available in preview starting with Kubernetes version 1.23 in all AWS commercial regions. Clusters automatically enter Extended Support, so there is no additional action you need to take for your EKS clusters running version 1.23 or higher.
Check out Amazon EKS extended support for Kubernetes versions available in preview, where Arnav Mediratta provides more info for you.
On a related note was Amazon EKS now supports Kubernetes version 1.28, where Leah Tucker and Sheetal Joshi walk you through everything you need to know.
cdk8s
Sticking with Kubernetes, if you are using cdk8s to write infrastructure as code for your Kubernetes workloads, then last week saw new capabilities for cdk8s; allowing seamless synthesis of applications into Helm charts, and native import of existing Helm charts into cdk8s applications on the other. cdk8s can now interpret deploy-time tokens of the AWS CDK and CDK For Terraform, all during the cdk8s synthesis phase. Helm stands out as a widely embraced solution for the deployment and management of Kubernetes applications. By converging cdk8s and Helm, users can enjoy a unified workflow for creating and deploying Kubernetes manifests. With the recent addition to the “cdk8s synth” command, you can transform a cdk8s app directly into a Helm Chart, ready to be integrated with Helm deployments.
We’ve expanded the capabilities of the “cdk8s import” command, simplifying the process to incorporate Helm charts into cdk8s applications. Providing a Helm Chart URL to the “cdk8s import” command will auto-generate a custom type-safe construct for you that represents the Helm Chart in question.
In Kubernetes applications, dependency on cloud infrastructure is common. However, if cloud resource names aren’t explicitly defined in manifests, since they are unknown at the synth time, it can hinder deployment. cdk8s introduces a feature to handle this by interpreting deploy-time tokens and retrieving their values during synthesis, resolving deployment challenges.
PostgreSQL
pgvector
Amazon Relational Database Service (RDS) for PostgreSQL now supports v0.5.0 of the pgvector extension to store embeddings from machine learning (ML) models in your database and to perform efficient similarity searches. This version of the extension introduces pgvector introduces HNSW indexing support, parallelization of ivfflat index builds, and improves performance of its distance functions.
Embeddings are numerical representations (vectors) created from generative AI that capture the semantic meaning of text input into a large language model (LLM). pgvector can store and search embeddings from Amazon Bedrock, Amazon SageMaker, and more. With pgvector on Amazon RDS, you can simply set up, operate, and scale databases for your GenAI applications. pgvector 0.5.0 adds support for HNSW indexing, which lets you execute similarity searches with low latency and produces highly relevant results. Additionally, HNSW in pgvector supports concurrent inserts, and updating/deleting vectors from the index. You can integrate your GenAI applications with pgvector using open-source frameworks like LangChain, simplifying how you use Amazon RDS for searching over your vector data.
The pgvector extension version 0.5.0 is available on database instances in Amazon RDS running PostgreSQL 15.4-R2 and higher, 14.9-R2 and higher, 13.12-R2 and higher, and 12.16-R2 and higher.
PostgreSQL 16.0
Amazon Relational Database Service (Amazon RDS) for PostgreSQL 16.0 is now available in the Amazon RDS Database Preview Environment, allowing you to evaluate PostgreSQL 16.0 on Amazon RDS for PostgreSQL. You can deploy PostgreSQL 16.0 in the Preview Environment and have the same benefits of a fully managed database, making it simpler to set up, operate, and monitor databases. PostgreSQL 16.0 in the Preview Environment also includes support for logical decoding on read replicas, AWS libcrypto (AWS-LC), and over 80 PostgreSQL extensions such as pgvector, pg_tle, h3-pg, pg_cron, and rdkit.
The PostgreSQL community released PostgreSQL 16.0 on September 14, 2023 that enables logical replication from standbys and includes numerous performance improvements. PostgreSQL 16 also adds support for SQL/JSON constructors and identity functions, more query types that can use parallelism, introduction of SIMD CPU acceleration, and the ‘pg_stat_io’ view that provides statistics on I/O usage.
AWS Amplify
There have been a few important updates over the past couple of weeks.
First up is news that AWS Amplify announced an AWS Cloud Development Kit (CDK) construct for building GraphQL APIs backed by data sources such as Amazon DynamoDB tables or AWS Lambda functions using a single GraphQL schema definition. Launching an API for application frontends requires developers to author thousands of lines of repetitive, undifferentiated code to build and wire together API endpoints, custom business logic, and data sources. AWS Amplify removes this heavy-lifting by allowing developers to define their application data model in a single definition file and automatically generate the required AWS cloud resources to support common API operations like create, update, list, read, subscribe, and delete for their data sources. Today, we’re extending this capability, previously only available using the Amplify CLI to AWS CDK. With the new Amplify GraphQL API construct, CDK developers can simply define their data model in the GraphQL Schema Definition Language and enhance them with “directives” to generate accompanying data sources, such as DynamoDB tables (“@model”), Lambda functions (“@function”), or OpenSearch clusters (“@searchable”). The CDK construct has full feature parity with the existing GraphQL Transformer capabilities in the Amplify CLI. Developers can also secure their API and data using the “@auth” directive that provides deny-by-default authorisation, as well as the ability to configure global, model-level, and field-level authorisation rules. The new CDK construct is fully extensible as well with capabilities to access and customise all resources generated by Amplify from within their CDK code.
You can dive deeper by reading the post from Rene Brandel, NEW AWS Amplify GraphQL API CDK construct: deploy a real-time GraphQL API and data stack on AWS
Following that was the announcement of the developer preview of the AWS Amplify JavaScript Library v6 which includes reduced bundle sizes, richer TypeScript support, and integrations with Next.js server-side features. The AWS Amplify JavaScript Library enables frontend developers to connect their web and React Native apps to AWS cloud backends. In this developer preview, Amplify JavaScript now offers richer TypeScript support for the Auth, Analytics, and Storage categories. Apps using this developer preview will be served with smaller bundle sizes. Amplify JavaScript v6 also introduces an integration with Next.js server-side features such as App Router, Middleware, API routes, and server functions. With this developer preview, you can build web apps leveraging improved TypeScript interfaces for a more intuitive development experience, including syntax highlighting, code completion, and type checking. The smaller bundle sizes served make your web apps load faster. This version allows Amplify JavaScript to be used in Next.js apps client-side or server-side, such as in Middleware, API routes, and with the new App Router.
Rene has you covered again, writing AWS Amplify JavaScript’s NEW developer preview with reduced bundle size, improved TypeScript and Next.js support to dive deeper into this.
The final AWS Amplify update this week comes from Wesley and Danny Banks who have written, AWS Amplify UI: 10 new and updated components who walk you over some of the new and updated components that you can use within your AWS Amplify applications.
Videos of the week
Reducing compute capacity by 40% on EKS with Bottlerocket and Karpenter
Follow Gazal’s journey as he shares the lessons learned in adopting, rolling out and scaling EKS clusters at Target Australia over seven years. You will learn:
- What is Bottlerocket OS
- How Bottlerocket helps with securing your workloads
- Karpenter as an alternative to the Cluster Autoscaler
- How Karpenter can efficiently schedule and de-provision workloads
Gazal hinted at a 40% reduction in compute capacity when combining Bottlerocket OS and Karpenter (and 30% lower response times).
Fine tuning Stable Diffusion for Pokemon creation
A great video from my old pal Julien Simon from Hugging Face, who shows you that it doesn’t have to be complicated and expensive to can fine-tune large models. In this tutorial, Julien provides a step-by-step demonstration of the fine-tuning process for a Stable Diffusion model geared towards Pokemon image generation. Utilising a pre-existing script sourced from the Hugging Face diffusers library, the configuration is set to leverage the LoRA algorithm from the Hugging Face PEFT library. The training procedure is executed on a modest AWS GPU instance (g4dn.xlarge), optimising cost-effectiveness through the utilisation of EC2 Spot Instances, resulting in a total cost as low as $1.
Quickly Deploy your NextJS app with the AWS CDK
Discover how a solo founder or indie hacker can host a full stack application using Amplify Hosting. Join Michael Liendo as he dives in to tackle a new aspect of deploying real world solutions with frontend hosting.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
All Things Open October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
RabbitMQ Summit October 20th, Estrel Congress Center Berlin, Germany
If you are using RabbitMQ, or perhaps thinking and evaluating it, make sure you check out the RabbitMQ Summit happening in Berlin in October. This event will bring together experts and sessions covering everything you ever wanted to know about this open source project.
Find out more by checking out the event webpage, RabbitMQ Summit.
Open Source India October 19th-21st, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen