AWS open source newsletter #169
August 14th, 2023 - Instalment #169
Welcome to #169 of the AWS open source newsletter, featuring the latest and greatest open source news, projects, videos, and community content that you need to know about. Featured in this weeks edition we have more great projects, including a new ODBC driver for Amazon Timestream database, a nice tool to simplify your ssh tunnelling, an essential VSCode extension for working with Cedar policies, a couple of projects that help you shift left and validate / monitor your policies, a solution to help you monitor your Apache Kafka environments, as well as some great sample applications.
If that was not enough, then you can immerse yourself into the written and video content produced by the AWS community, which this week features open source technologies such as Firecracker, OpenSearch, AWS CDK, Juypter AI, dbt, Apache Airflow, Cedar, cfnguard, Grafana, Prometheus, Apache Kafka, Open Cybersecurity Schema Framework, AWS Lambda Web Adapter, Smithy, Apache Spark, AWS ParallelCluster, PostgreSQL, Spring Boot, Kubernetes, Mountpoint for Amazon S3, MySQL, Lustre, OpenZFS, Redis, Karpenter, Seekable OCI (SOCI), and more.
I have added more events to the calendar, and if you are in London this week, make sure to check out the AWS User Group that is happening later on this week.
Do you use the AWS SAM CLI with Homebrew?
If you are a user of the AWS Serverless Application Model (SAM) command line interface tool, and have been using Homebrew to install this (I guess this will mostly be Mac users, although some might also be using this on Linux) then you should be aware of this notice that appeared on the SAM CLI documentation page here.
NOTE! Starting September 2023, AWS will no longer maintain the Homebrew installer for the AWS SAM CLI (aws/tap/aws-sam-cli). To continue using Homebrew, you can use the community managed installer (aws-sam-cli) at your discretion. Any Homebrew command that references aws/tap/aws-sam-cli will redirect to aws-sam-cli.
Check out the page for details of the alternative methods for installing and updating the SAM CLI.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude! The first thirty responses will grab yourself an AWS Credit voucher as a thank you.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Colin Percival, Ganesh Sambandan, Siva Guruvareddiar, Yoginder Sethi, Olly Pomeroy, Himanshu Kohli, Thomas Poignant, Banjo Obayomi, alias454, Matthew Bonig, Nathan Fries, Richard Elberger, Jason Weill, Alex Driedger, Jon Ramsey, Keith Gilbert, Aish Gunasekar, Prashant Agrawal, Harold Sun, Xue Jiaqing, Su Jie, Jordon Phillips, Jeff Barr, Veliswa Boya, John Hashem and Andy Suderman.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
farssh
farssh provides secure on-demand connections into AWS VPCs. Using this tool you can easily connect to in-VPC resources like RDS and OpenSearch endpoints, using tools installed on your local machine. FarSSH features a SOCKS proxy mode, enabling your browser to be “in” the target VPC; this works both for accessing VPC resources and as a quick way to tunnel all your browser traffic, so your browser’s connections will appear to come from this AWS region’s public IP addresses (like a VPN). Check out the README for additional information on how much using this tool might cost.
amazon-timestream-odbc-driver
amazon-timestream-odbc-driver is the ODBC driver for the Amazon Timestream serverless time series database provides an SQL-relational interface for developers and BI tool users. This was announced last week, and This new driver allows applications such as Excel, PowerBI, JMP, and more to seamlessly integrate with Timestream’s powerful query engine. The ODBC driver is available under the Apache-2.0 license.
vscode-cedar
vscode-cedar is the Cedar policy language extension for Visual Studio Code supports syntax highlighting, formatting, and validation. You might have seen me using this in my demos of the TinyToDo Cedar example app, so I am super happy this VSCode extension is now available on the VSCode Marketplace. Check the README that shows how you can configure the plugin, which was the only thing I needed to tweak for my setup. If you are using or experimenting with Cedar, make sure you check this out.
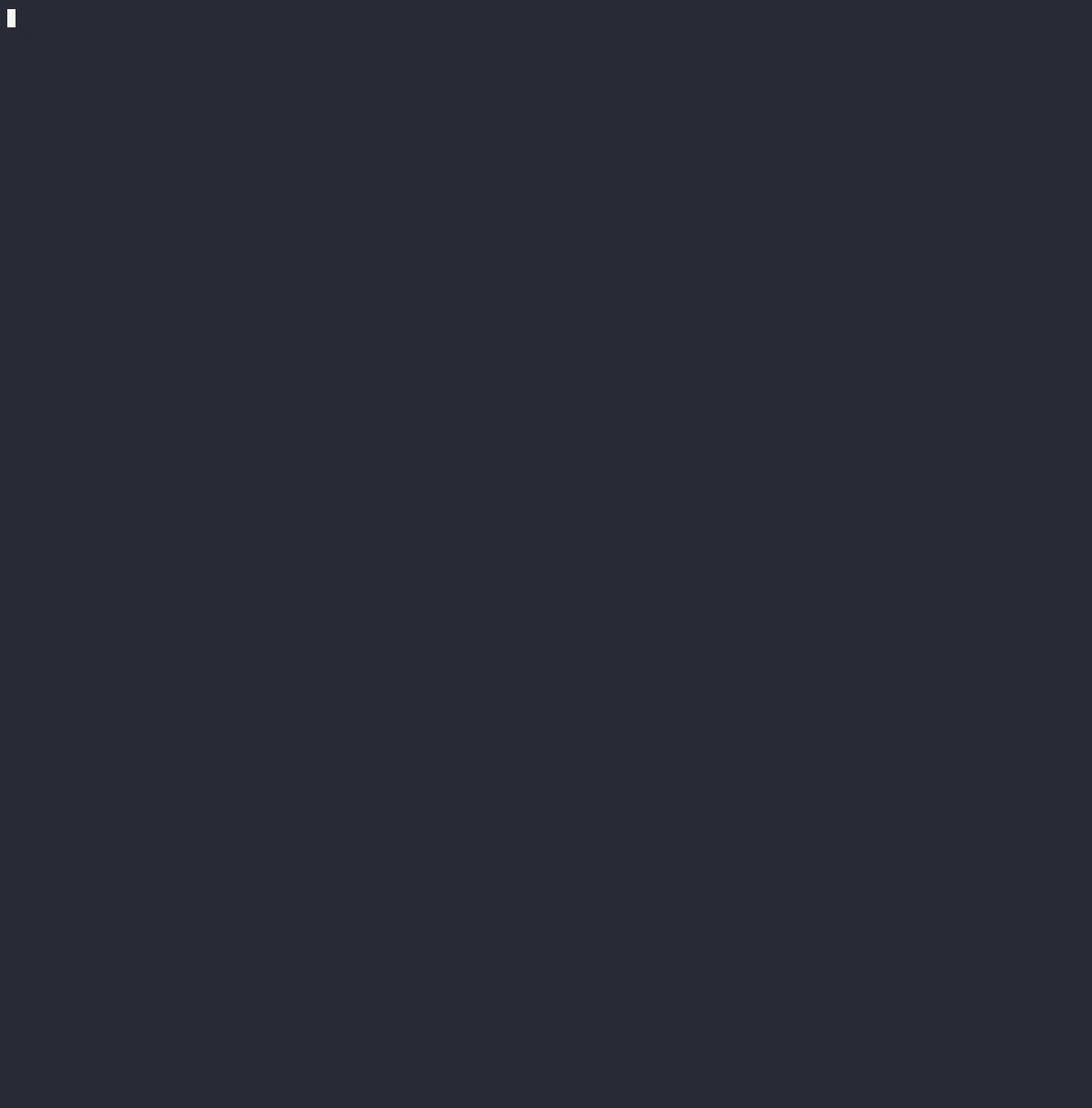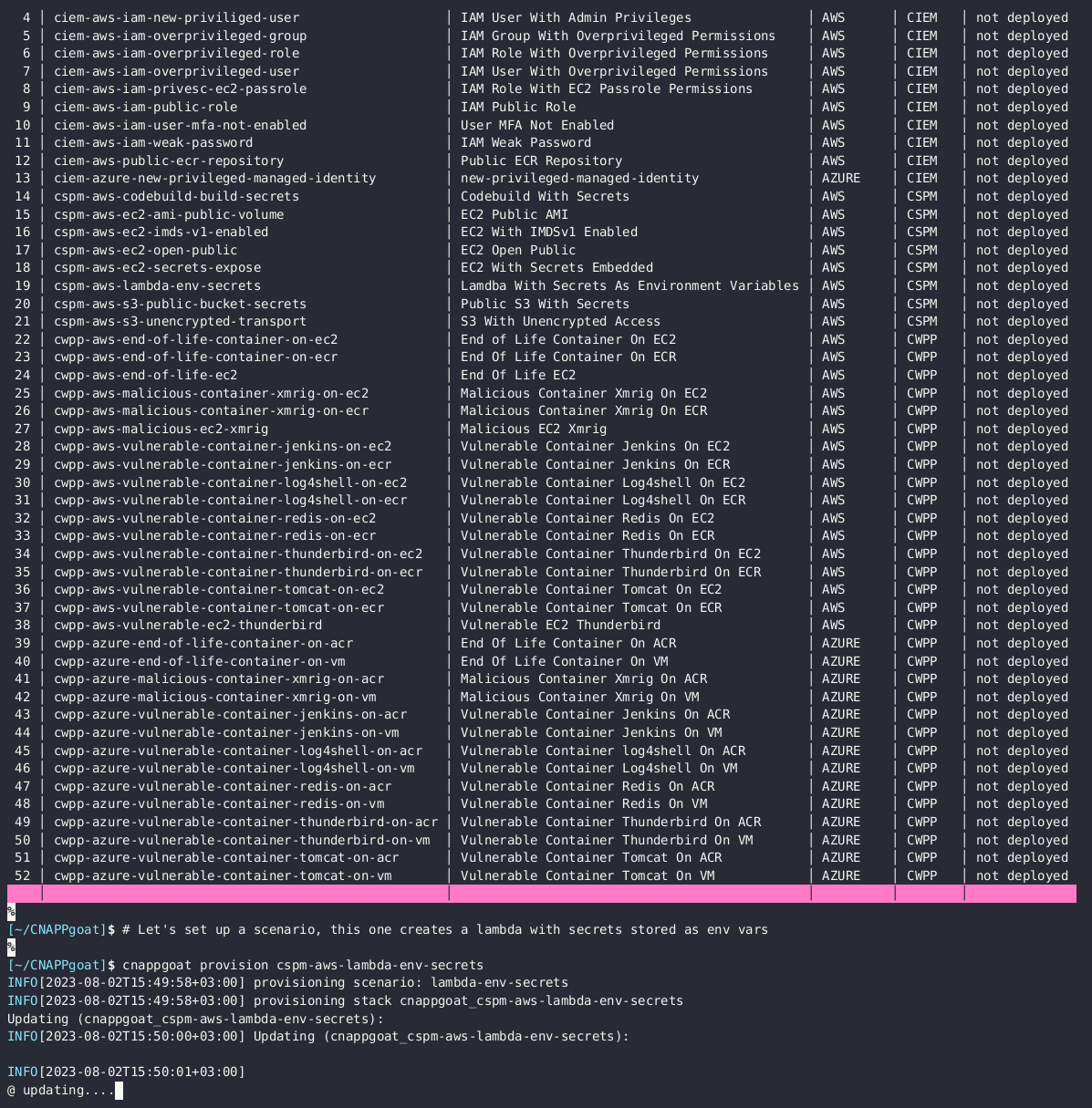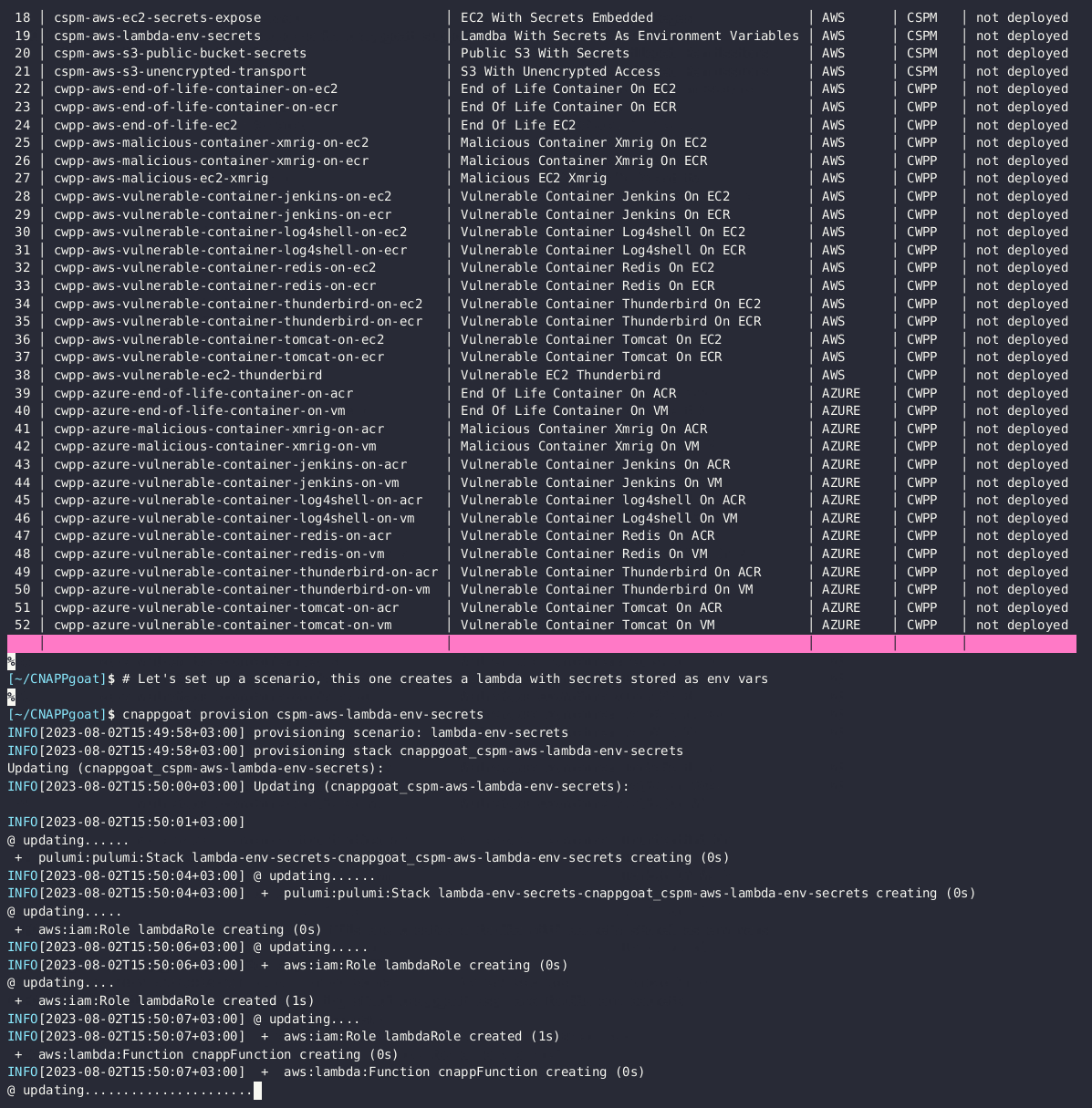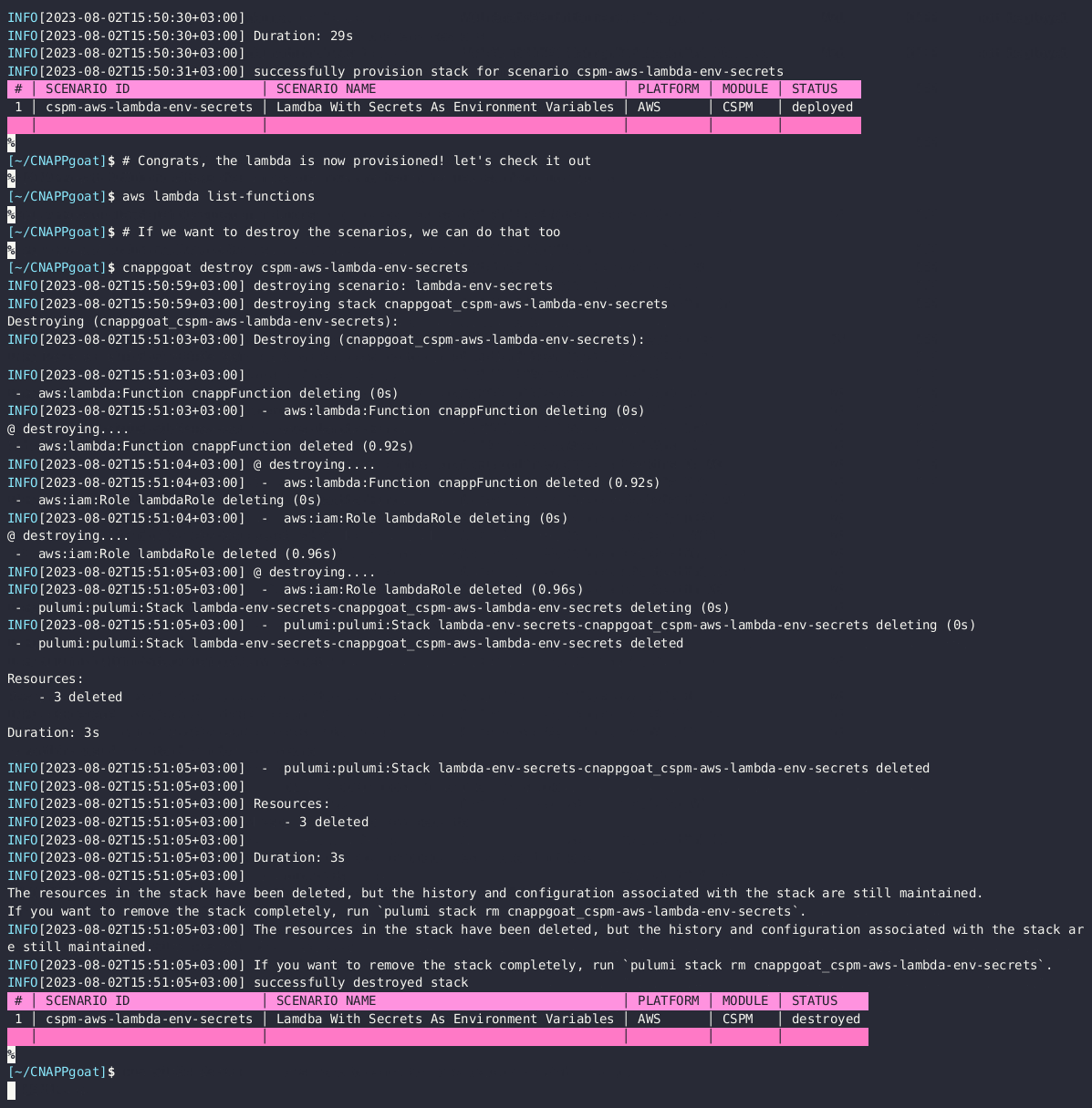
cnappgoat
cnappgoat is an open source vulnerable-by-design environment deployment tool specifically engineered to facilitate practice arenas for defenders and pen testers. Its main function is to deploy intentionally vulnerable environments across multiple cloud service providers, to help you sharpen your skills in exploiting, detecting, and preventing such vulnerabilities. Make sure you read through the README carefully, it provides examples of how to get started. I also liked how the project acknowledges other similar related open source projects (some of which I have featured in this newsletter).
validate-policy
validate-policy this project creates Lambda function that automatically validates policy document defined when a policy or role is created or updated. Use cases include be notified when a policy contains error or security warnings. For example, when it is created via infrastructure as code (IaC). Be aware though, that the resources are created or updated in the region where the CloudFormation stack is created.
+-----------------+
| Lambda |
| Execution Role |
+--------+--------+
|
| +---------------------+
+--------------------+ +--------+--------+ | |
|EventBridge +--->+ Lambda function +------->+Access Analyzer |
|Rule | +--------+--------+ | |
+--------------------+ | +---------------------+
|
v
+--------+--------+
| CloudWatch Logs |
+-----------------+
msk-open-monitoring
msk-open-monitoring provides code to help you deploy an integrated solution that combines Amazon Managed Streaming for Apache Kafka (Amazon MSK) with the power of Amazon Managed Service for Prometheus (AMP) and Amazon Managed Grafana (AMG). You can monitor your MSK cluster with Prometheus, an open-source monitoring system for time-series metric data. You can publish this data to Amazon Managed Service for Prometheus using Prometheus’s remote write feature. You can also use tools that are compatible with Prometheus-formatted metrics or tools that integrate with Amazon MSK Open Monitoring.
Ganesh Sambandan, Siva Guruvareddiar, and Yoginder Sethi have put together a blog post, Gain actionable business insights with monitoring of Amazon MSK with Amazon Managed Service for Prometheus and Amazon Managed Grafana walks you through how to deploy this project, providing comprehensive insights into the performance and health of your Kafka clusters [hands on]

cdk-validator-cfnguard
cdk-validator-cfnguard is a CDK experimental plugin allows you to shift left and by using AWS CloudFormation Guard to perform policy validations. Check out the documentation page AWS CDK policy validation at synthesis time, that provides an overview and some examples to help you understand how you can use this and the uses cases it might be helpful for.
go-feature-flag
go-feature-flag is a new tool from AWS Community Builder Thomas Poignant that provides a lightweight and open-source solution that provides a simple and complete feature flag implementation. The tool allows you to store your feature flags in various locations (for example, an S3 bucket), in a number of different file formats, and supports complex rules to help you target when to apply a flag. Nice documentation in the README complete with demo video, so why not check this out.
Demos, Samples, Solutions and Workshops
tinytodo
tinytodo is an example project from Permit.io, that shows how you can use the Cedar Agent together with a copy of the original demo application within the Cedar repository, the TinyTodo example. In this repo, it uses OPAL and Cedar Agent to control who has access to what. The README helpfully shows how this example has been updated from the original, so make sure you read that. If you are experimenting with Cedar, definitely a project to check out.
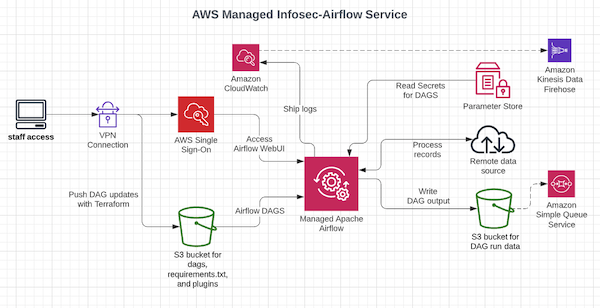
sec-airflow-ingester
sec-airflow-ingester this repo from alias454 provides an example of how you can use Apache Airflow to pull in remote data via API, pub/sub, kinesis, s3 etc. and then store it in s3 for later consumption by other services. The repo uses Terraform to simplify how you can get this example up and running in your own AWS environment.
aws_well_arch_chatbot
aws_well_arch_chatbot this repo from my colleague Banjo Obayomi provides the code to stand up your own Chatbot that can awnser questions using the text from the Well-Architected Framework. To help you get started, read along his post Building an AWS Well-Architected Chatbot with LangChain . NOTE: You must have your own OpenAI API Key to use the Chatbot
supply-chain-simulator-on-aws
supply-chain-simulator-on-aws is a low-code solution that you can use to create a digital replica of your physical supply chain. With this digital replica, you can evaluate alternate network configurations and operational strategies to optimise your supply chains. For example, you can use this solution’s models to help you evaluate how disruptions in your network impact order fill rates and supply chain costs. You can also model changes in demand forecasts, facility closures, labor or machine capacity constraints, and relative costs of different modes of transport. The repo provides CDK and CloudFormation scripts to help you deploy into your AWS environment.

AWS and Community blog posts
Community round up
I like to start each newsletter with a round up of what community posts caught my eye, and as always, this week we have some great reads. Starting off with Matthew Bonig’s post, Announcing my Advanced CDK Course, is a short post where Matt shares an new CDK training course which he has put together. Matt starts off with a fantastic opening which I urge everyone to check out, it is always nice when someone shares their origin story like Matt does. Following that is Nathan Fries with this post, Neural Search Quickstart for OpenSearch. Nathan provides a very nice guided post to help you understand the basics of the Neural Search feature within OpenSearch, and whether or not it would be useful for your applications. This is another must read this week, great stuff. Richard Elberger has put together Three key factors in choosing a real-time operating system (RTOS) which is essential reading if you are currently looking at realtime operating systems in the IoT space.
With Generative AI tools like AWS CodeWhisperer helping developers create code faster, it is nice to see that data scientists can now use similar tools to help them in their Juypter notebooks. Jason Weill writes about a new plugin in his post, Generative AI in Jupyter. Jupyter AI is an official subproject of Project Jupyter, that provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. It features a native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. It support for a wide range of generative model providers and models (AI21, Anthropic, Cohere, Hugging Face, OpenAI, SageMaker, and more). Read the post for more details including a walk through.
The last post featured in this round up is from Alex Driedger over at Hootsuite. Alex writes, Automating DBT + Airflow and shares why they chose dbt and provide details on how they use this, running DBT core on AWS Fargate.
Open Cybersecurity Schema Framework (OCSF)
The Open Cybersecurity Schema Framework is an open-source project, delivering an extensible framework for developing schemas, along with a vendor-agnostic core security schema. Vendors and other data producers can adopt and extend the schema for their specific domains. Data engineers can map differing schemas to help security teams simplify data ingestion and normalisation, so that data scientists and analysts can work with a common language for threat detection and investigation. The goal is to provide an open standard, adopted in any environment, application, or solution, while complementing existing security standards and processes. In Celebrating One Year of OCSF: Simplifying Security Telemetry for a Stronger Defense Jon Ramsey and Keith Gilbert provide a retrospective over the past year and share how "…By investing in open source initiatives, we’re helping to ensure that the projects and technologies that we, our customers, and the world depend on remain secure and reliable for the long term…"
OpenSearch
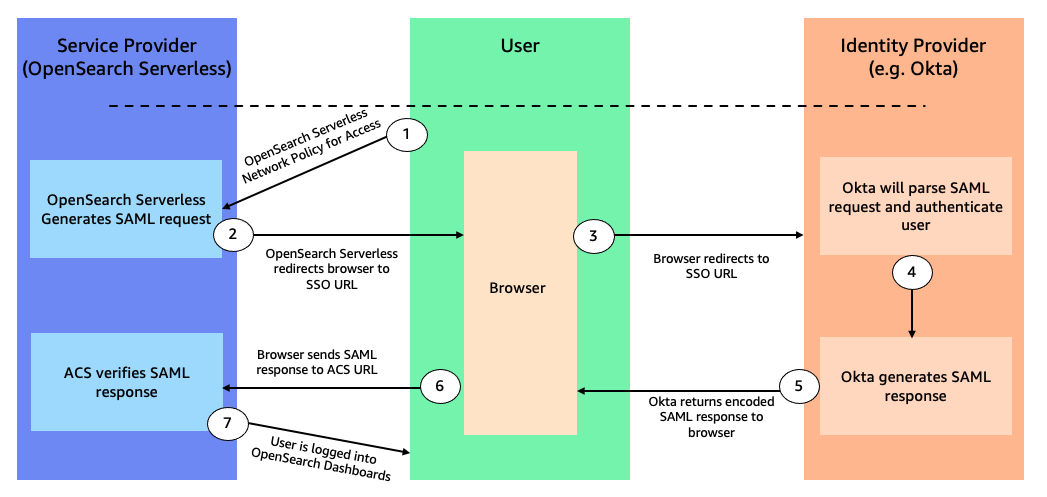
In Configure SAML federation for Amazon OpenSearch Serverless with Okta Aish Gunasekar and Prashant Agrawal provide a hands on guide on how to use Okta as your IdP and integrate it with OpenSearch Serverless to securely manage your users and groups for secure access to your data.
AWS Lambda Web Adapter
The AWS Lambda Web Adapter, is an open source project written in Rust that I featured when it was first published in #146. The project serves as a universal adapter for Lambda Runtime API and HTTP API. It allows developers to package familiar HTTP 1.1/1.0 web applications, such as Express.js, Next.js, Flask, SpringBoot, or Laravel, and deploy them on AWS Lambda. In the post, Using response streaming with AWS Lambda Web Adapter to optimize performance, Harold Sun, Xue Jiaqing, and Su Jie show you how developers can more easily package web applications that support Lambda response streaming, enhancing the user experience and performance metrics of their web applications. What is Lambda response streaming? Lambda response streaming, which introduces a new invocation mode accessible through the Lambda Function URLs. This feature enables Lambda functions to send response content in sequential chunks to the client. [hands on]

Smithy
Last week we shared the repo for Smithy for Python, and this week I am happy to share the official blog post from Jordon Phillips, Introducing Smithy for Python that looks more closely at this project and shows how you can get started.
Other posts and quick reads
- Host the Spark UI on Amazon SageMaker Studio provides a solution for installing and running Spark History Server on SageMaker Studio and accessing the Spark UI directly from the SageMaker Studio IDE, for analysing Spark logs produced by different AWS services (AWS Glue Interactive Sessions, SageMaker Processing jobs, and Amazon EMR) [hands on]

- Announcing additional Linux controls for Amazon ECS tasks on AWS Fargate dives deep into System Controls and PID namespace sharing on AWS Fargate [hands on]
- Running quantum chemistry calculations using AWS ParallelCluster provides an introduction to HPC on AWS for quantum computing researchers who are seeking to compare their quantum or hybrid algorithms against classical calculations [hands on]
- Amazon Aurora PostgreSQL: cross-account synchronization using logical replication shows you how to set up cross-account logical replication using Amazon Aurora PostgreSQL-Compatible Edition so you can achieve near real-time synchronisation between a source and a target database in different AWS accounts [hands on]
- Developing with Java and Spring Boot using Amazon CodeWhisperer explores how to leverage CodeWhisperer in Java applications specifically using the Spring Boot framework [hands on]
- Monitoring version compliance of Amazon Elastic Kubernetes Service by using AWS Config demonstrates how you can track your EKS Version both at the control and data plane level by leveraging AWS Config rules (managed and custom), so that you can automate the effort needed to track effective version [hands on]

Quick updates
Data on EKS
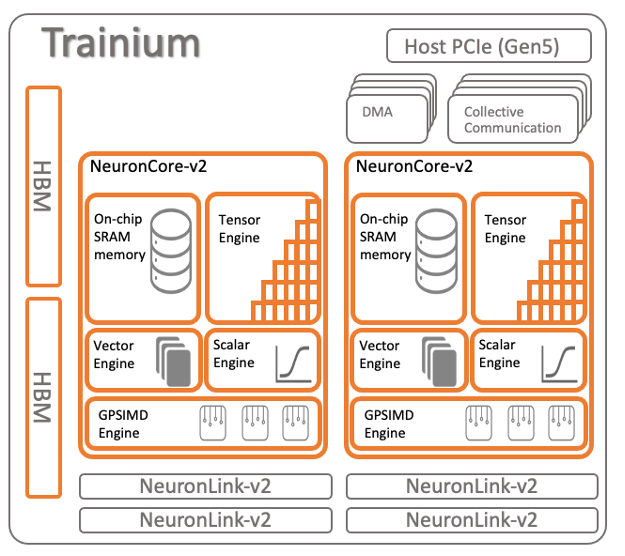
AWS Trainium is an advanced ML accelerator that transforms high-performance deep learning(DL) training. Trn1 instances, powered by AWS Trainium chips, are purpose-built for high-performance DL training of 100B+ parameter models. In this post, AWS Trainium on EKS you will be guided in how to securely deploy an Amazon EKS Cluster with Trainium Node groups (Trn1.32xlarge and Trn1n.32xlarge) and all the required plugins(EFA Package for EC2, Neuron Device K8s Plugin and EFA K8s plugin). Once the deployment is complete, we will learn how to train a BERT-large(Bidirectional Encoder Representations from Transformers) model with Distributed PyTorch pre-training using the WikiCorpus dataset. For scheduling the distributed training job, we will utilize TorchX with the Volcano Scheduler. Additionally, we can monitor the neuron activity during training using neuron-top.
Mountpoint for Amazon S3
Last week we announced the general availability of Mountpoint for Amazon S3, a new open source file client that delivers high-throughput access to Amazon Simple Storage Service (Amazon S3), lowering processing times and compute costs for data lake applications. Mountpoint for Amazon S3 is a file client that translates local file system API calls to S3 object API calls such as GET and PUT.
Mountpoint for Amazon S3 is ideal for workloads that read large datasets (terabytes to petabytes in size) and require the elasticity and high throughput of Amazon S3. Common use cases include machine learning training as well as reprocessing and validation in autonomous vehicle data processing. These workloads read large datasets over several compute instances and write sequentially to a file from a single process or thread. Mountpoint for Amazon S3 supports sequential and random read operations on existing files and sequential write operations for creating new files.
My colleague Jeff Bar put together a great walk through that looks at a fun example of how you can use this in his post, Mountpoint for Amazon S3 – Generally Available and Ready for Production Workloads. It’s ferry good! (sorry, regular readers know that I cannot resist a good opportunity for a pun!)

MySQL
Amazon Relational Database Service (Amazon RDS) for MySQL now supports MySQL minor versions 5.7.43 and 8.0.34. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MySQL, and to benefit from the bug fixes, performance improvements, and new functionality added by the MySQL community.
OpenSearch
You can now use Terraform to help you with your Amazon OpenSearch Serverless deployments. OpenSearch Serverless is the serverless option for Amazon OpenSearch Service that makes it easier for you to run search and analytics workloads without having to think about infrastructure management. Terraform enables OpenSearch Serverless deployments as infrastructure as code(IaC). Using Terraform for deployments, you can ensure that the configurations are measured and validated, minimising the chances of errors caused by human oversight.
Lustre
Amazon FSx for Lustre, a fully managed service that makes it easy and cost effective to launch, run, and scale the world’s most popular high-performance file system, now supports the ability to free up storage capacity on an FSx file system that has data synchronised with Amazon S3. FSx for Lustre integrates natively with Amazon S3, synchronising changes in both directions with automatic import and export, so that you can access your S3 data lakes through a high-performance POSIX-compliant file system on demand. Starting today, you can use the FSx API to release inactive data that is on the file system and has already been exported to S3. You can choose to only release data from files that have not been accessed for a minimum amount of time and to only release data within a specified directory path. When a file is released, the file data is removed from your file system (and retained on S3) and the metadata remains on your file system. If a user or application accesses a released file, the data is automatically and transparently loaded back onto your file system from your S3 bucket. To release data on a regular interval, you can schedule the FSx API using Amazon EventBridge.
Find out more by reading New — File Release for Amazon FSx for Lustre, where my colleague Veliswa Boya shows you this new capability in action.
OpenZFS
Amazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system, and is designed to deliver sub-millisecond latencies and up to 10 GB/s of throughput along with rich ZFS-powered data management capabilities (like snapshots, data cloning, and compression).
You can now use a Multi-AZ deployment option when creating file systems on Amazon FSx for OpenZFS, making it easy to deploy file storage that spans multiple AWS Availability Zones (AZs) to support business-critical workloads that require high availability and enhanced durability. The new Multi-AZ file systems are built with a high-availability pair of file servers (active/passive file servers) spread across AZs. They’re configured to synchronously replicate data across AZs to provide enhanced durability, and are designed to automatically fail over between file servers to provide continuous availability to data in the event that the active file server or even an entire AZ becomes unavailable. With this launch, customers can leverage the power, agility, and simplicity of Amazon FSx for OpenZFS for a broader set of workloads, including business-critical workloads like database, line-of-business (e.g., core banking, retail platforms, semiconductor chip design), and web-serving applications that require highly available shared storage that spans multiple AZs.
Redis
Amazon ElastiCache for Redis now supports online migration from self-managed Redis clusters to ElastiCache for Redis clusters running in cluster mode. Online migration simplifies moving data from self-managed Redis clusters to ElastiCache with minimal application disruption. During the migration, ElastiCache replicates cache data from each self-managed Redis source shard to the target ElastiCache cluster. Once initial replication is complete, the two clusters will be kept in sync until you are ready to update your application configuration to use ElastiCache. ElastiCache for Redis online migration is supported for target clusters running ElastiCache for Redis version 5.0.6 and above.
Amazon EMR
EMR Studio is an integrated development environment (IDE) that makes it easy for data scientists and data engineers to develop, visualise, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter Notebooks and tools such as Spark UI and YARN Timeline Service.
EMR Studio workspaces now supports applying fine-grained data access control with AWS Lake Formation when accessing data through EMR on EC2 clusters. When you connect to EMR clusters from EMR Studio workspaces, you can now choose the IAM role (called runtime IAM Role) that you want to connect with. Apache Spark interactive notebooks will access only the data and resources permitted by policies attached to this runtime role. When data is accessed from data lakes managed with AWS Lake Formation, you can enforce table and column-level access using policies attached to this runtime role. With this new capability, multiple users can connect to the same EMR cluster from their EMR Studio workspaces, each using a runtime role scoped with customised data access permissions. User sessions are completely isolated from one another on the shared cluster. This can also simplify provisioning of EMR clusters for interactive use cases, thus reducing operational overhead and saving costs.
Videos of the week
Firecracker
AWS Hero Colin Percival did a recent talk about the work that went into getting FreeBSD working as a guest in the Firecracker VMM – features added, bugs uncovered, workarounds added – and also some of the boot performance improvements which resulted from the ability to run FreeBSD in a very minimalist VM environment.
{% youtube MT3cdeuRTzs %}
Karpenter
AWS Karpenter is an open-source, flexible, high-performance Kubernetes cluster autoscaler built with AWS. Launched almost a year ago, the open source tool is seeing momentum. It helps improve your application availability and cluster efficiency by rapidly launching right-sized compute resources in response to changing application load. In this webinar from the lovely folks at Fairwinds, John Hashem and Andy Suderman provide an overview of this open source project before sharing some important tips on how to make the most effective use of this within your Kubernetes clusters.
Speeding up container image launches in AWS Fargate - Seekable OCI
Seekable OCI (SOCI), is an open source technology that enables container runtimes to implement lazy loading the container image to start applications faster without modifying the container images. Join Olly Pomeroy and Himanshu Kohli as they dive into this new feature, on the Containers from the Couch show.
Developing and testing with Amazon Managed Workflows for Apache Airflow on Amazon ECS
Another video from the vaults of the Containers from the Couch, and this is a good one. If you missed this when it first aired, now is your chance to hear from John Jackson as he walks you through one of my favourite AWS repos, mwaa-local-runner, and shows you running local runner for Amazon Managed Workflows for Apache Airflow on Amazon ECS.
Open Source Brief
Now featured every week in the AWS Community Radio show, grab a quick five minute recap of the weekly open source newsletter from yours truely.
Check out the playlist here.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group UK Meetup #61 London, August 16th
AWS User groups regularly meet across the world, and in this London chapter of the AWS User group, Matt Carey will be sharing his talk “Building a Viral Open Source AI Chatbot: A Journey from Concept to Reality”. From the extract:
“Learn how we built Quivr - the open-source virtual brain. In 2.5 months we achieved 8k active users of the demo app and a whopping 18k stars on GitHub. We were number 1 on the GitHub trending page for multiple days in a row. This is the story of how Quivr went viral and how our tiny dev team struggled to build all the features our user base wanted. We will talk about the challenges we faced scaling a generative AI-powered app without it costing the earth on ECS Fargate, and the extra tooling we had to build along the way. We will cover how we solved the problems of keeping the project open source and super easy to both use and contribute whilst leveraging AWS services in a different way to most.”
Find out more about the other talk and details of how to register, over at the meetup page AWS User Group UK Meetup
Developer eXperience and serverless Sigma Technology Cloud, Malmö, Sweden, August 29th 5:30pm
The AWS Skåne Meetup features a great line up as always, but of interest to open source developers will be the session on Powertools for AWS Lambda that none other than Heitor Lessa will be delivering, and our good friend and AWS Community Builder Lars Jacobsson who will be demonstrating his tool samp-cli. If you are in the area, make sure you reserve your spot. You can find more on the meetup page for Developer eXperience and serverless
RADIUSS AWS Tutorials: Learn how to use a modern HPC software stack Online, throughout August 2023
Check out this series of online tutorials happening throughout August demonstrating how to use several GPU-ready projects in the cloud and on premises. Follow along on your own EC2 instance (provided). No previous experience necessary. Lots of open source technologies are covered in this series, so if you are looking to get started in this space, check out the details on the information page, Learn how to use a modern HPC software stack. Brenden Bouffler has also put together a great blog post, Call for participation: RADIUSS Tutorial Series 2023 that dives deeper into some of these topics and provides further information.
Developer Webinar Series, Open Source At AWS Online, 7th September 11am - 2pm AEST
As part of the Developer Webinar series, we are delighted to showcase three sessions that look at open source on AWS. We have Aish Gunasekar who will be talking about “Leveraging OpenSearch for Security Analytics”. I will be doing a talk on Cedar, in my session “Next generation Authz with Cedar”, and to wrap things up we have Keita Watanabe who will be looking at “Scaling LLM/GenAI deployment with NVIDIA Triton on Amazon EKS”. The sessions are technical deep dives, and there will be Q&A as well.
Jump over to the registration page and sign up, and hope to see many of you there.
Building ML capabilities with PostgreSQL and pgvector extension YouTube, 14th September 4pm UK time
Generative AI and Large Language Models (LLMs) are powerful technologies for building applications with richer and more personalized user experiences. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Register now to learn more about this powerful technology.
Watch it live on YouTube.
Build ML into your apps with PostgreSQL and the pgvector extension YouTube, 21st September 4pm UK time
This office hours session is a follow up for those who attended the fireside chat titled “Building ML capabilities into your apps with PostgreSQL and the open-source pgvector extension”. Others are also welcome. Office hours attendees can ask questions related to this topic. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Join us to ask your questions and hear the answers to the most frequently asked questions about the pgvector extension for PostgreSQL.
Watch it live on YouTube.
Open Source Summit, Europe September 19th-21st, Bilboa Spain
“Open Source Summit is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem. It is the gathering place for open-source code and community contributors.” You will find AWS as well as myself at Open Source Summit this year, so come by the AWS booth and say hello - from the glimpses I have seen so far, it is going to be awesome! Find out more at the official site, Open Source Summit Europe 2023.
OpenSearchCon Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Open Source India October 12-13th, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
All Things Open October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen