AWS open source newsletter #168
August 7th, 2023 - Instalment #168
Welcome to #168 of the AWS open source newsletter, the only newsletter that features the freshest open source and AWS content*
New projects for you to feast on in this issue include the obligatory projects that look at how Generative AI can help developers be more productive, in this case by making documentation more relevant and easier to find and to help with code reviews, a nice tool to help you query your AWS Identity Access Management (IAM) policies, and a security focused tool to help you search for potentially incorrect configured S3 buckets. We have some nice demos on how to use OpenSearch’s kNN feature, how to use DynamoDB Local for local development and test, an example architecture for streaming gaming workloads with Pixel Streaming, and more!
If that was not enough, then you can check out the community and AWS content covering some of your favorite open source technologies, which this week include Karpenter, Bottlerocket, AWS Amplify, Amazon EMR, Apache Spark, Apache Hudi, Apache Flink, Apache Kakfa, Localstack, Apache Iceberg, Kubernetes, Amazon EKS, MariaDB, MySQL, CoreWCF, Prometheus, Grafana, Babelfish for Aurora PostgreSQL, OpenSearch, Smithy, and AWS CDK.
Finally, don’t forget the Events section. August and September has some interesting events to check out, and whether they are in person or online, you do not want to miss those.
*if you know of any others, please let me know!
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Alex Sima, Matt Carey, Dan Salmon, Anna Geller, Matano, Abhishek Gupta, Victor Dorneanu, Daniel Genezini, Liz Duke, Deepthi Mohan, Karthi Thyagarajan, Raj Ramasubbu, Sundeep Kumar, Rahul Sonawane, Danny Banks , Wesley, Abhi Karode, Vijay Pawar, Ophir Zahavi, Abdallah Shaban, and Ric Harvey
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
IAMActionHunter
IAMActionHunter is an open source tool from Rhino Security that is an IAM policy statement parser and query tool. It aims to simplify the process of collecting and understanding permission policy statements for users and roles in AWS Identity and Access Management (IAM). Although its functionality is straightforward, this tool was developed in response to the need for an efficient solution during day-to-day AWS penetration testing. Check out the linked blog post, IAMActionHunter: Query AWS IAM permission policies with ease where David Yesland provides a hands on guided walk through how you can use it.
smithy-python
smithy-python Smithy is an interface definition language and set of tools that allows developers to build clients and servers in multiple languages. A Smithy model enables API providers to generate clients and servers in various programming languages, API documentation, test automation, and example code. This repo provides an early stages of beginning work on low-level Python SDK modules that aim to provide basic, reusable, and composable interfaces for lower level SDK tasks. Using these modules customers should be able to generate asynchronous service client implementations based on services defined using Smithy. Other programming languages are supported by Smithy, and there is a growing list of resources and tutorials to help get you started.
Smithy can be used by anyone, and is not tied to AWS. Smithy can be used with any kind of service. All AWS-specific metadata in Smithy is implemented as decoupled packages. Check out the Smithy docs for more info.
cdk-appsync-typescript-resolver
cdk-appsync-typescript-resolver is a newly published AWS CDK construct to build AppSync JS resolvers using Typescript, which you can also check out on the CDK Construct Hub
awsdocsgpt
awsdocsgpt is an interesting project from Alex Sima that provides an AI-powered search and chat for AWS Documentation. This provides two things: First, a search interface for AWS documentation, and Second, a chat interface. Check out the README for more details as to how this works. You will need an OpenAI key to run this though. You will need to do some work though, as you have to configure the documentation URLs within the repo, but looks like this would be a really interesting experiment to see how well it provides a better documentation search. It is on my weekend to do list.
code-review-gpt
code-review-gpt this project from AWS Community Builder Matt Carey (see his post below on a different topic) is a personal code reviewer powered by LLMs (OpenAI GPT-3.5/4, Llama, Falcon, Azure AI) & Embeddings. Code Review GPT uses Large Language Models to review code in your CI/CD pipeline. It helps streamline the code review process by providing feedback on code that may have issues or areas for improvement. Check out the repo that provides a nice video demo of this working inside VSCode. This project is “hot” so make sure you check it out.
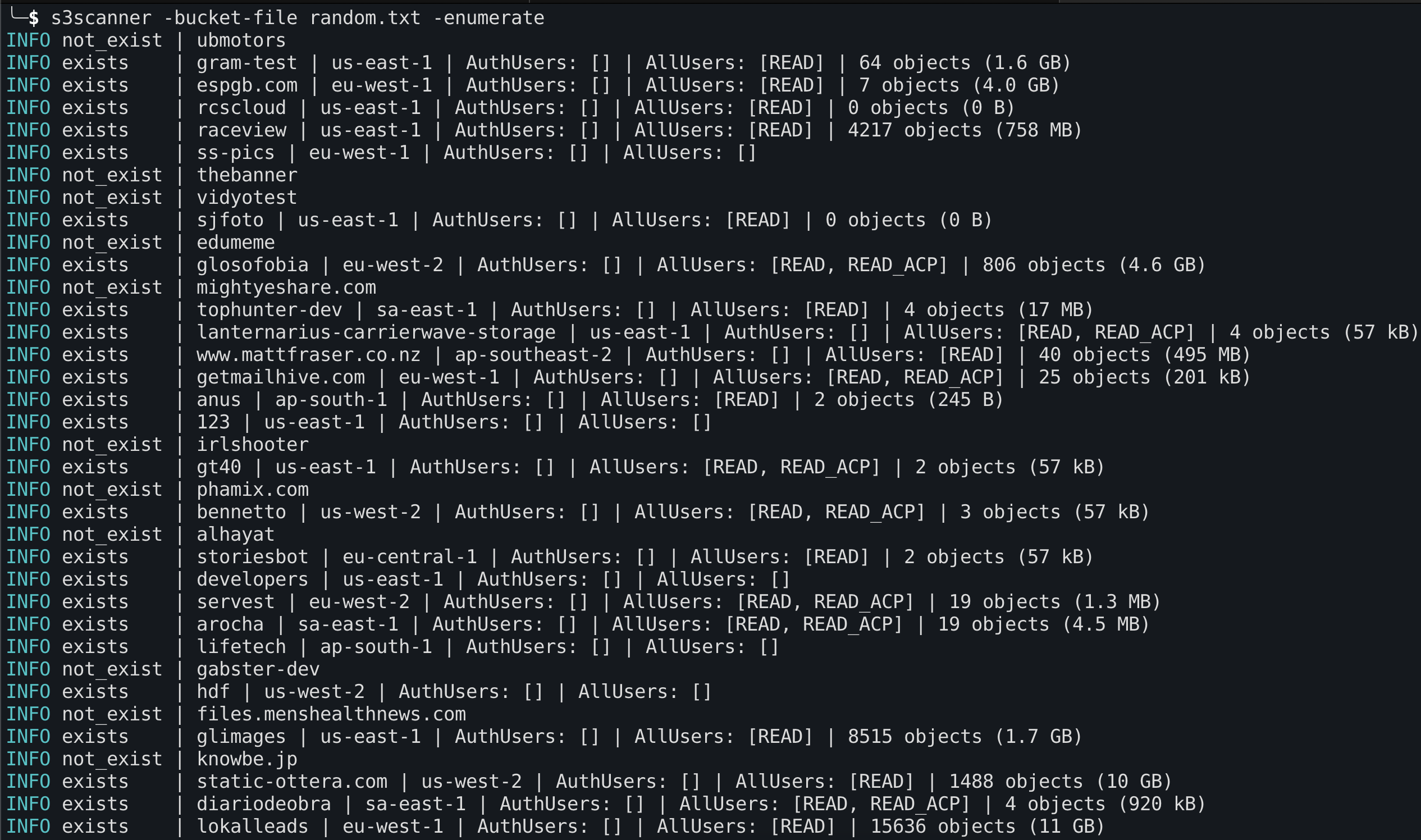
S3Scanner
S3Scanner is a very nice tool from Dan Salmon that helps you scan for misconfigured S3 buckets across Amazon S3-compatible APIs. Very nice documentation with clear examples make this a project that you should all be checking out.
Demos, Samples, Solutions and Workshops
amazon-dynamodb-local-samples
amazon-dynamodb-local-samples is a sample Java project that demonstrates how to use DynamoDB Local for local development and testing. DynamoDB Local is a downloadable version of DynamoDB that enables you to develop and test applications without connecting to the actual DynamoDB service provided by AWS. This project showcases multiple approaches to set up and use DynamoDB Local, including downloading JAR files, running it as a Docker image, and using it as a Maven dependency.
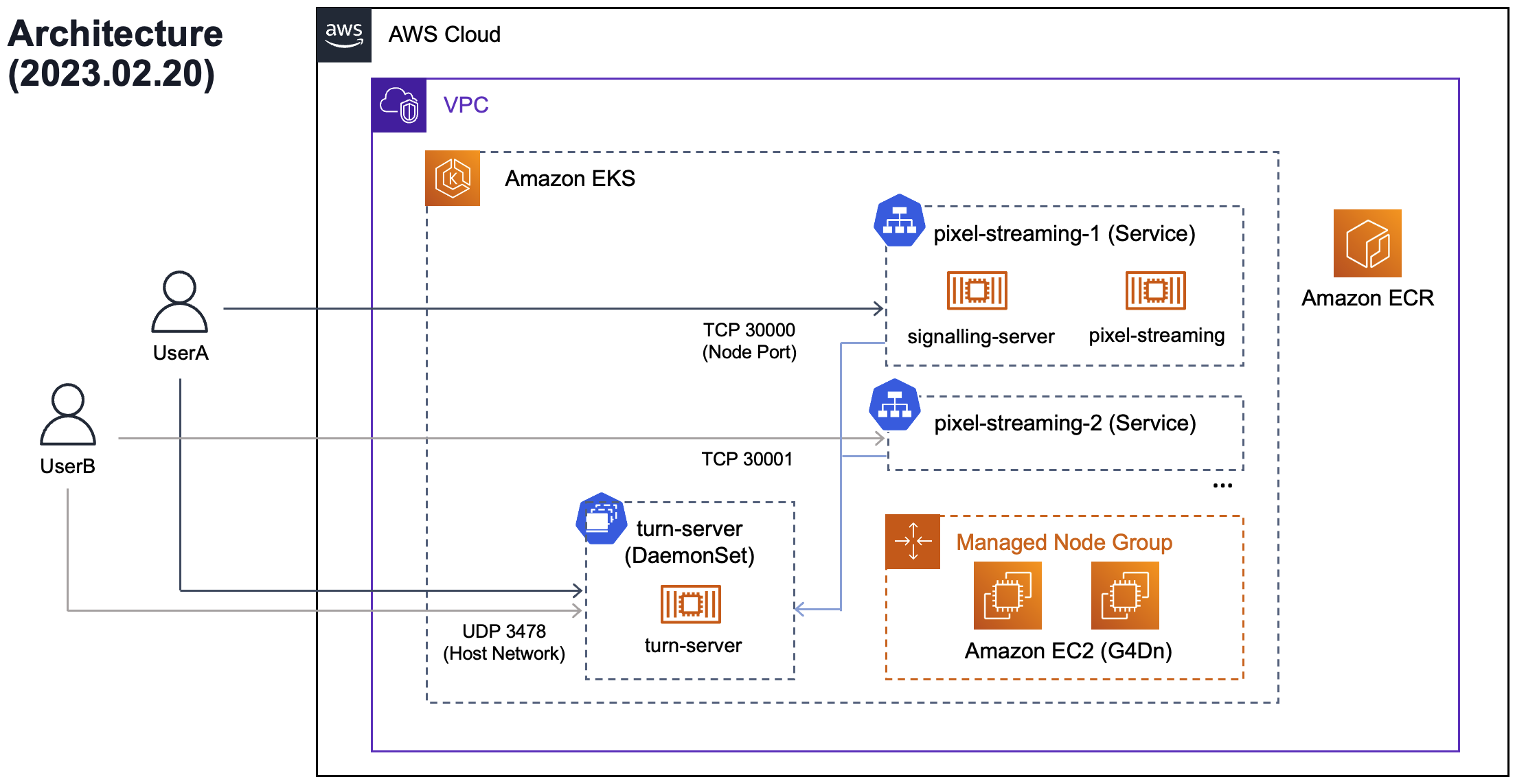
pixel-streaming-on-eks
pixel-streaming-on-eks provides sample code for deploying Pixel streaming on Amazon EKS. What is Pixel streaming I can hear some of you asking (or was that just me?). I didn’t know, so I asked a few people. With Pixel Streaming, you can run a packaged Unreal Engine application on a desktop PC or a server in the cloud, along with a small stack of web services that are included with the Unreal Engine.
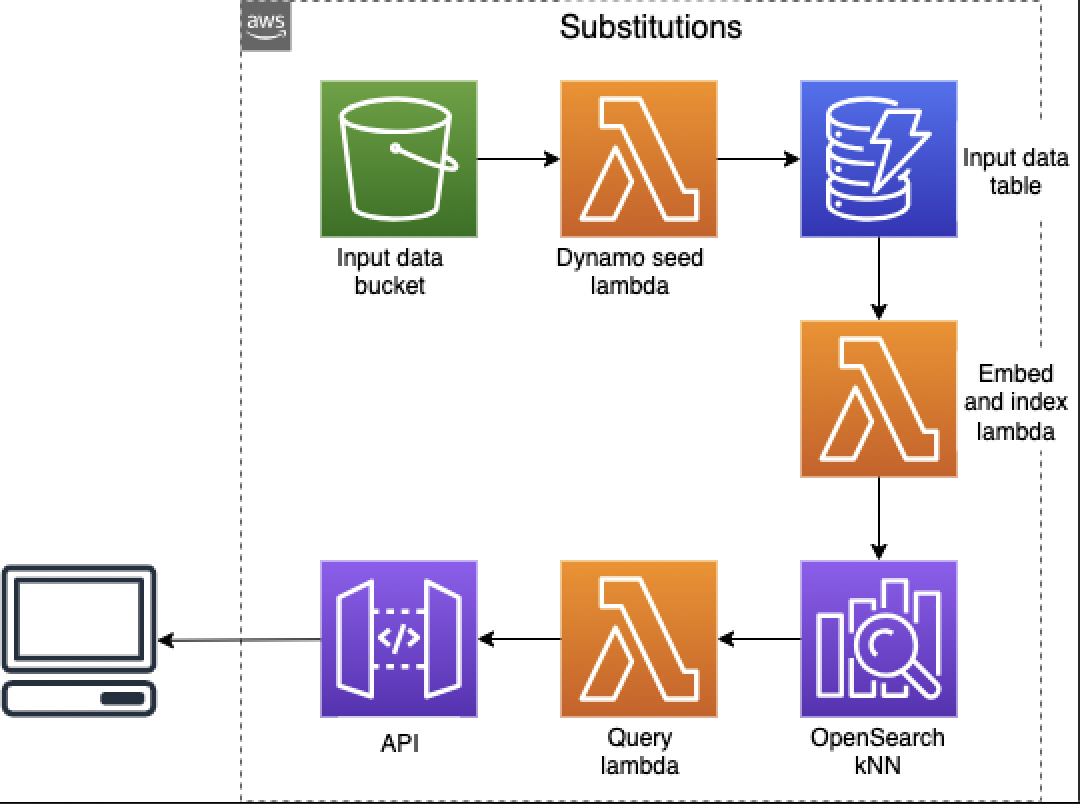
product-substitutions
product-substitutions is an example of how one can use OpenSearch’s kNN feature in combination with Natural Language Processing to produce recommendations for replacing out of stock grocery store products. In this solution, grocery store product names and descriptions are converted into embeddings using the all-MiniLM-L6-v2 sentence transformer, and stored in a kNN index. When querying for product recommendations, neighbouring products are located within the kNN index and returned to the user. The relevance of returned products is increased with additional optional category and price-based pre-filtering. The project used AWS CDK to make it super easy to try out.
AWS and Community blog posts
Community round up
As always I like to kick off with a round up of my highlights from the AWS community, and this week we have another line up of great content. Kicking things off we have Anna Geller with Apache Iceberg Crash Course for AWS users: Amazon S3, Athena & AWS Glue ❤️ Iceberg which is one of the nicest tutorials on how to get started with Apache Iceberg on AWS that I have looked at. Make sure you check this out, amazing stuff. Sticking with Apache Iceberg we have Vacuuming Amazon Athena Iceberg with AWS Step Functions from the lovely folks at Matano. If you have every seen “ICEBERG_VACUUM_MORE_RUNS_NEEDED” when working with Amazon Athena Iceberg tables, then you need to check out this post (and code) that provides a solution to these errors by using AWS Step Functions to retry vacuuming Amazon Athena Iceberg tables until they are clean. From Apache Iceberg to Apache Kafka and OpenSearch, and this time it is my colleague Abhishek Gupta who has put together a great tutorial for Go developers. In Ingesting Data into OpenSearch using Apache Kafka and Go Abhishek looks at how to create custom integrations (in Go) that will let you ingest data from Apache Kafka into OpenSearch.
Victor Dorneanu has become a big fan of PlantUML, an open source project that helps you create diagrams through markdown. I agree, and so I really enjoyed reading Documentation as Code for Cloud - PlantUML. It is a lovely detailed post, so make sure you grab a cup of your favourite drink whilst you enjoy going through this. Next up is Daniel Genezini who put together Integration tests with AWS S3 buckets using Localstack and Testcontainers, which is part of a series of posts Daniel is putting together on how to use Localstack, together with Testcontainers, to emulate AWS for use in integration tests. Wrapping up this weeks community round up is AWS Community Builder Matt Carey who shares news of a new project he has been working on. In Unifying AI endpoints with Genoss, powered by LangChain that makes it easier to switch out and use different models when working with large language models (LLMs).
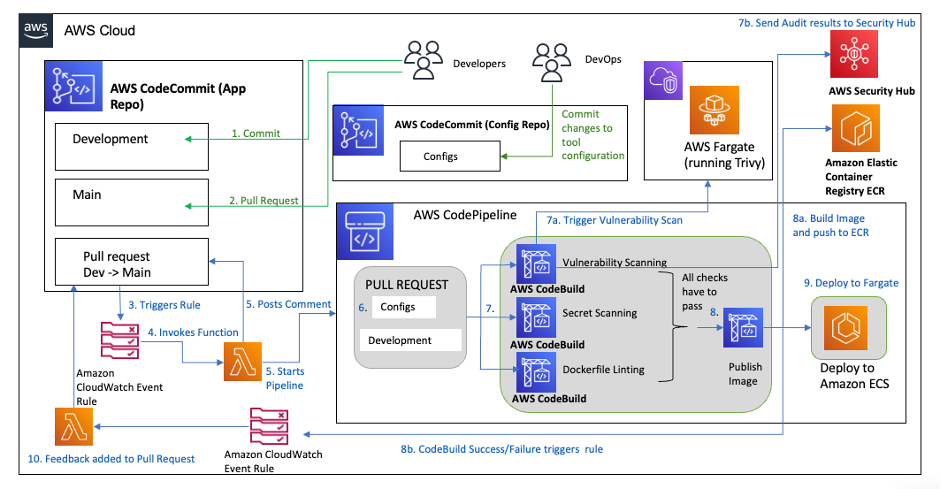
Supply Chain Security
Fabulous post from Liz Duke that takes a look at how you can create a DevSecOps pipeline and start finding issues earlier. In Shift left to secure your container supply chain Liz shows you how you can create pipeline that performs three different types of security checks on container images, tags the images and then deploys them onto Amazon ECS on AWS Fargate. The post also looks at how you can create an audit log of any images that have Common Vulnerabilities and Exposures (CVEs) listed as HIGH, MEDIUM or below. Great post and a must read this week.
Apache Spark and Apache Flink
Great post from Deepthi Mohan and Karthi Thyagarajan that will help you make better decisions when it comes to deciding which open source technology is a better fit for your specific streaming use case. In A side-by-side comparison of Apache Spark and Apache Flink for common streaming use cases they provide a comparative study of streaming patterns that are commonly used to build stream processing applications, how they can be solved using Apache Spark (primarily Spark Structured Streaming) and Apache Flink, and the minor variations in their approach. Great post and a must read this week. [hands on]
Apache Hudi
Apache Hudi is an open-source data management framework used to simplify incremental data processing and data pipeline development. In the post, Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight Raj Ramasubbu, Sundeep Kumar, and Rahul Sonawane demonstrate how you can stream data, not only new records, but also updated records from relational databases, to Amazon S3 using an AWS Glue streaming job to create an Apache Hudi-based near-real-time transactional data lake. [hands on]

AWS Amplify
It seems like every week we have a new social media app, so I have the perfect post for you. Create your own social networking app by following along with Danny Banks and Wesley in their post, Building a social network app with Amplify Form Builder and Storage. In this post you will learn how to set up an Amplify project with Storage and Data, and use Amplify Studio’s Form Builder to build a basic social network feed app. Users can create posts with an image and those posts are shown in a feed. Cats optional. [hands on]
Other posts and quick reads
- Best strategies for achieving high performance and high availability on Amazon RDS for MySQL with Multi-AZ DB Clusters explores key considerations and migration best practices when upgrading Amazon RDS for MySQL 5.7.x to MySQL 8.0.x [hands on]

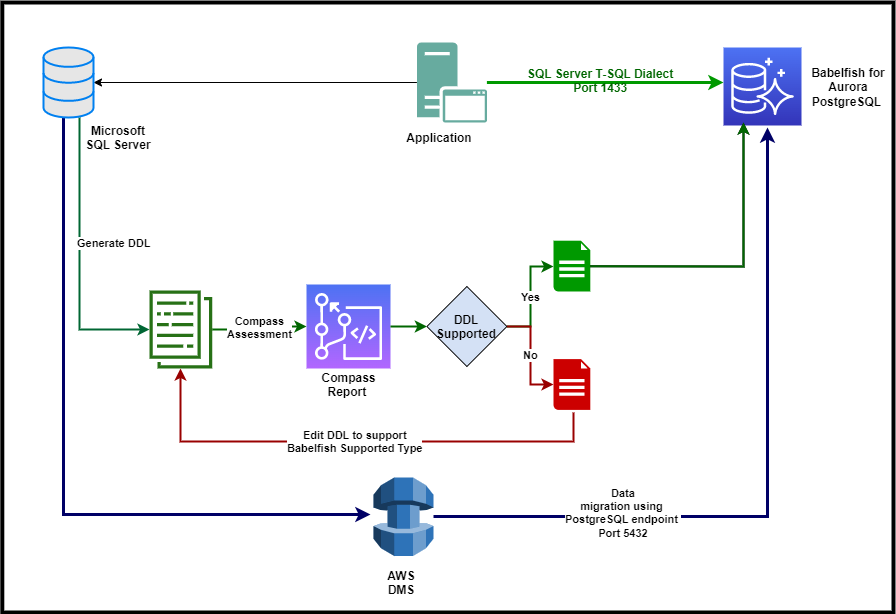
- Migrate Microsoft SQL Server to Babelfish for Aurora PostgreSQL with minimal downtime using AWS DMS is a hands on guide on how you can use Amazon Aurora PostgreSQL-Compatible Edition as the target engine for continuous migration from a source SQL Server database using Babelfish for Aurora PostgreSQL [hands on]
- Automating custom networking to solve IPv4 exhaustion in Amazon EKS looks at how you can address IP exhaustion by using custom networking pattern defined in Amazon EKS blueprints [hands on]
- Migrating to Amazon Managed Service for Prometheus with the Prometheus Operator provides a detailed guide to the basics of the Prometheus Operator and how you can use this operator to begin to use Amazon Managed Service for Prometheus [hands on]
- Make your dashboards faster and more cost-effective with Grafana query caching and Amazon Timestream demonstrates how to create a Grafana dashboard with your data in Timestream and how to configure a query cache using Grafana query caching [hands on]

- Modernizing a WCF service to CoreWCF: Lessons learned shares all the steps taken and lessons learned in modernising WCF services to open source CoreWCF [hands on]

Case Studies
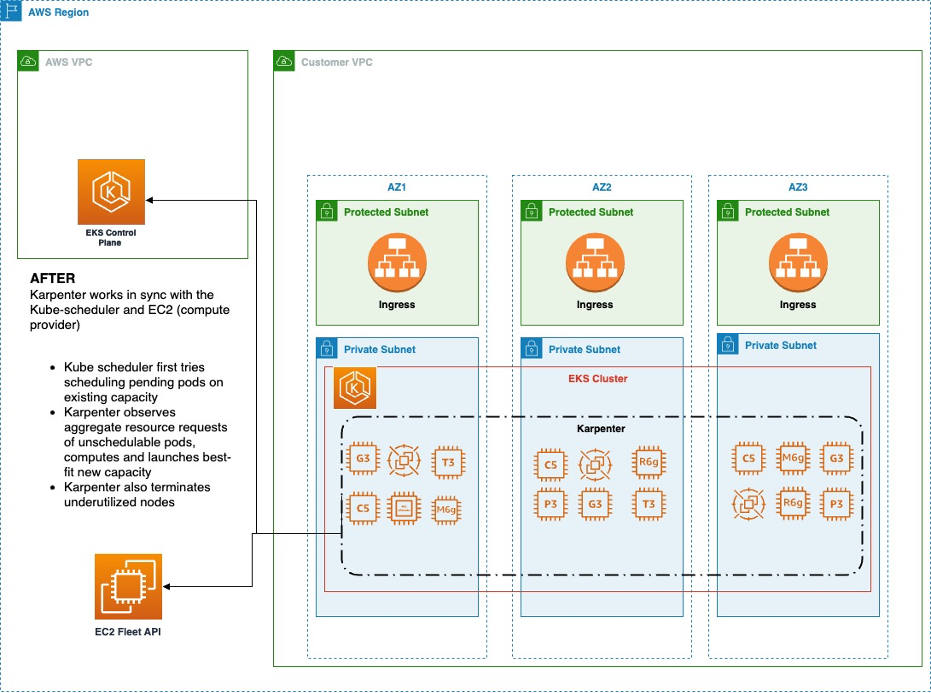
Abhi Karode and Vijay Pawar, together with Ophir Zahavi, Cloud Engineering Manager, H2O.ai have collaborated on How H2O.ai optimized and secured their AI/ML infrastructure with Karpenter and Bottlerocket and talks about how H20.ai use Karpenter, an AWS open-sourced just-in-time Kubernetes autoscaler, and Bottlerocket, a secure, lightweight, purpose-built Linux-based operating system to run containers in the Amazon Elastic Kubernetes Service (Amazon EKS) clusters
Quick updates
aws-docker-toolkit
AWS Toolkit is a dockerised version of the awscli, a tool that helps you run the tool without directly installing it on your system. Version 2.3.15 was released last week. It’s simple to map your AWS credentials to this container and even set up a .bash_profile so you can just type aws in the command line. The image is auto-built daily to ensure the Linux base image is constantly updated in the background and that you have the latest awscli version.
Apache Spark
AWS open sourced the Amazon Redshift integration for Apache Spark to help Apache Spark developers seamlessly build and run Apache Spark applications on Amazon Redshift data. Last week saw an updated release of this project. In addition to the expanded pushdown functionality, this release also has support for AWS Secrets Manager integration and support for Parquet writes. Amazon Redshift integration for Apache Spark builds on an existing open source connector project and enhances it for performance and security, helping customers gain up to 10x faster application performance. We acknowledge all the contributors to the project, some of whom collaborated with us to make this happen. As we make further enhancements to the connector, we will continue to contribute back to the open source project. To get started with using the open sourced Spark Redshift connector, go to your favourite open source Apache Spark service. From there, use data frame or Spark SQL code in an Apache Spark job or Notebook to connect to the Amazon Redshift data warehouse, and start running queries in minutes.
Amazon EMR
A couple of updates for folk who are using or interested in Amazon EMR Serverless. Amazon EMR Serverless is a serverless option that makes it simple for data analysts and engineers to run open-source big data analytics frameworks like Apache Spark and Apache Hive without configuring, managing, and scaling clusters or servers.
Announced last week was news that you can now call the EMR Serverless APIs to view the Application UIs e.g. the live Spark UI or Tez UI for running jobs and the Spark History Server or the persistent Tez UI for completed jobs. Spark or Hive workloads are often submitted using orchestration tools like Apache Airflow, AWS Step Functions etc. To monitor such pipelines it is useful to be able to navigate to the live application UIs for running jobs and the persistent application UIs for completed jobs. The EMR Serverless application UIs are available from the EMR Studio UI but for users who prefer an API, they can now use the get-dashboard-for-job-run API to get a secure URL to view the application UIs.
Also announced last week was news that you can now retrieve secrets from AWS Secrets Manager on Amazon EMR Serverless from your Spark and Hive jobs. Amazon EMR Serverless is a serverless option that makes it easy for data analysts and engineers to run open-source big data analytics frameworks such as Apache Spark and Apache Hive without configuring, managing, and scaling clusters or servers. Spark or Hive jobs often need to access sensitive information such as database credentials and API keys to connect to other systems. It is a good practice to decouple the management of such sensitive information from application configuration to improve code re-usability and reduce operational overhead of updating application configuration when updating secrets. Now, you can securely specify references to secrets stored in Secrets Manager as part of EMR Serverless job configurations or classifications and during runtime those references will be replaced by secret values. This feature is especially useful for use cases that need to specify credentials for external Hive metastore databases in application configuration.
Kubernetes
A couple of storage related updates this week.
AWS Fargate for Amazon EKS removes the need to provision and manage servers, lets you specify and pay for resources per application, and improves security through application isolation by design. 20 GiB of ephemeral storage is included with every EKS Fargate pod. AWS Fargate for Amazon EKS now lets customers configure the size of ephemeral storage for their workloads up to a maximum of 175 GiB. This enables customers with data intensive workloads to utilise AWS Fargate for Amazon EKS. Customers can now specify the size (in GiB) of ephemeral storage that their workloads require using the storage parameter in their pod spec. Additional ephemeral storage requested, up to 175GB, is charged in GB increments for the duration that the pod is running.
Amazon EKS now supports the Amazon Elastic File System (EFS) Container Storage Interface (CSI) driver as an EKS add-on, making it simpler and easier to use EFS shared file storage with your EKS clusters. The EFS CSI driver provides a container storage interface so that you can attach persistent, fully elastic EFS shared file storage to your Kubernetes clusters running on Amazon EKS. With this launch, Amazon EKS now supports the EFS CSI driver as an EKS add-on, enabling you to install, configure, and update the EFS CSI driver with just a few clicks in the EKS Console, or using the AWS CLI, EKS API, or IAC tools. This capability eliminates the need to manually install and configure the EFS CSI driver using command line tools such as kubectl or helm, and makes it easy to keep your cluster up-to-date with the latest version of this driver: All EKS add-ons, including the EFS CSI driver add-on, automatically include the latest security patches, bug fixes, and are validated by AWS to work with EKS.
MariaDB
AWS Database Migration Service (DMS) makes homogeneous migrations simpler with built-in native database tooling. Today, in addition to supporting MySQL and PostgreSQL, this feature now supports MariaDB. Built-in native database tooling with homogeneous data migrations provides simple and performant like-to-like migrations with minimal downtime. Homogeneous data migrations now support MariaDB 10.1 and higher with both full load and ongoing replication options. Supported sources include on-premises, Amazon EC2, or Amazon Relational Database Service (RDS) for MariaDB databases and supported targets include Amazon RDS for MariaDB.
MySQL
Now available is Local Write Forwarding for Amazon Aurora MySQL-Compatible Edition 3 (with MySQL 8.0 compatibility). This new capability makes it simple to scale read workloads which require read after write consistency. Customers can now issue transactions containing both reads and writes on Aurora read replicas and the writes will be automatically forwarded to the single writer instance for execution. Applications requiring read scale can utilise up to 15 Aurora Replicas for scaling reads without the need to maintain complex application logic that separates reads from writes. Check out this blog to find out how local write forwarding can help reduce the complexity of your application code. Local write forwarding is available on Aurora MySQL versions 3.04 and higher. This feature can be enabled in either AWS Management Console, Command Line Interface (CLI), or RDS API by turning on the “enable local write forwarding” option.
AWS Amplify
Last week saw the launch of a new CloudWatch Logger feature with AWS Amplify, which is available now for Swift and Android developers. This feature empowers developers to log errors from the Amplify libraries to CloudWatch, enhancing the ability to detect production issues. It also enables developers to write custom logs to detect failures in different parts of their applications. Developers using the Amplify Logger will have increased visibility into issues that are affecting their production apps. Developers can also remotely configure their logging levels, and add an allow-list of users to granularly detect issues impacting their experience.
Read more about this from Abdallah Shaban in the post, AWS Amplify enables CloudWatch Logging Support for Swift and Android
Videos of the week
Iambic
Iambic is a project that I featured in a previous newsletter (#155) is an open source project that helps you manage your IAM policies as “code”, allowing you to model your permissions and then store these in source control. In this video, learn more about what the project does, the problems it helps you solve, and then get hands on with some demos of it in action.
AWS Open Source Brief
Appearing every week on the AWS Community Radio show that is run by all round open source good guy, Ric Harvey, is the AWS Open Source Brief. In this short, five minute video, I take a look at this weekly newsletter and dive a little deeper into some of the projects, content, and other open source topics covered. You can catch the playlist here, and am sharing last weeks episode here.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group UK Meetup #61 London, August 16th
AWS User groups regularly meet across the world, and in this London chapter of the AWS User group, Matt Carey will be sharing his talk “Building a Viral Open Source AI Chatbot: A Journey from Concept to Reality”. From the extract:
“Learn how we built Quivr - the open-source virtual brain. In 2.5 months we achieved 8k active users of the demo app and a whopping 18k stars on GitHub. We were number 1 on the GitHub trending page for multiple days in a row. This is the story of how Quivr went viral and how our tiny dev team struggled to build all the features our user base wanted. We will talk about the challenges we faced scaling a generative AI-powered app without it costing the earth on ECS Fargate, and the extra tooling we had to build along the way. We will cover how we solved the problems of keeping the project open source and super easy to both use and contribute whilst leveraging AWS services in a different way to most.”
Find out more about the other talk and details of how to register, over at the meetup page AWS User Group UK Meetup
Developer eXperience and serverless Sigma Technology Cloud, Malmö, Sweden, August 29th 5:30pm
The AWS Skåne Meetup features a great line up as always, but of interest to open source developers will be the session on Powertools for AWS Lambda that none other than Heitor Lessa will be delivering, and our good friend and AWS Community Builder Lars Jacobsson who will be demonstrating his tool samp-cli. If you are in the area, make sure you reserve your spot. You can find more on the meetup page for Developer eXperience and serverless
RADIUSS AWS Tutorials: Learn how to use a modern HPC software stack Online, throughout August 2023
Check out this series of online tutorials happening throughout August demonstrating how to use several GPU-ready projects in the cloud and on premises. Follow along on your own EC2 instance (provided). No previous experience necessary. Lots of open source technologies are covered in this series, so if you are looking to get started in this space, check out the details on the information page, Learn how to use a modern HPC software stack. Brenden Bouffler has also put together a great blog post, Call for participation: RADIUSS Tutorial Series 2023 that dives deeper into some of these topics and provides further information.
Building ML capabilities with PostgreSQL and pgvector extension YouTube, 14th September 4pm UK time
Generative AI and Large Language Models (LLMs) are powerful technologies for building applications with richer and more personalized user experiences. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Register now to learn more about this powerful technology.
Watch it live on YouTube.
Build ML into your apps with PostgreSQL and the pgvector extension YouTube, 21st September 4pm UK time
This office hours session is a follow up for those who attended the fireside chat titled “Building ML capabilities into your apps with PostgreSQL and the open-source pgvector extension”. Others are also welcome. Office hours attendees can ask questions related to this topic. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Join us to ask your questions and hear the answers to the most frequently asked questions about the pgvector extension for PostgreSQL.
Watch it live on YouTube.
Open Source Summit, Europe September 19th-21st, Bilboa Spain
“Open Source Summit is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem. It is the gathering place for open-source code and community contributors.” You will find AWS as well as myself at Open Source Summit this year, so come by the AWS booth and say hello - from the glimpses I have seen so far, it is going to be awesome! Find out more at the official site, Open Source Summit Europe 2023.
OpenSearchCon Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Open Source India October 12-13th, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
All Things Open October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen