AWS open source newsletter #167
July 31st, 2023 - Instalment #167
Welcome to #167 of the AWS open source newsletter, and another edition packed with new open source projects for you to explore. Whether you are new to this newsletter, or returning (we thank you!) there is something for you. This week we have projects that will help use Terraform to deploy your monolith applications, a tool to accelerate your GraphQL building when working with Amazon DynamoDB, a project that will help you introduce chaos without changes to your code, and a couple of really nice demos of using generative AI that allows you to use natural language to query your data.
This edition is also packed with open source goodness, covering topics across Terraform, Rust, LangChain, Streamlit, PostgreSQL, Supabase, OpenSearch, Powertools for AWS Lambda, Open Application Model, Traefik, Keycloak, FastAPI, PyTorch, IAM Roles Anywhere, Apache Iceberg, Amazon EMR, Apache Hudi, Go, Cedar, RabbitMQ, Pacu, and many more. Make sure to check out the events section too, I am adding new events weekly, so make sure you don’t miss out.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Chuong Tran (Chris), Gary Stafford, Efi Merdler-Kravitz, Matt Carey , Sreekesh Iyer, Dejanu Alex, Lars Jacobsson, Mark Sailes, Tsahi Duek, Andreas Lindh, Siva Guruvareddiar, Cameron Senese, Joseph Keating, Dinuth De Zoysa, Virginia Chu, Sarat Vemulapalli, Dan Widdis, Owais Kazi, Daniel (dB.) Doubrovkine, Dagney Braun, Minal Shah, Fanit Kolchina, Ravi Kumar Singh, Kevin Wikant, Micah Walter, Yanko Bolanos, Ramesh Mathikumar, and Francesco Vergona.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
aws-terrajet
aws-terrajet is a project from Chuong Tran (Chris) that aide from having a really cool project name, aims to help Developers deploy their monolith application to AWS in the easiest and fastest way. From the README we can see that “TerraJet follows AWS best practices to help your infrastructure archives reliability, security, performance, and cost optimisation”. Certainly looks interesting, and got a lot of interest on Reddit.
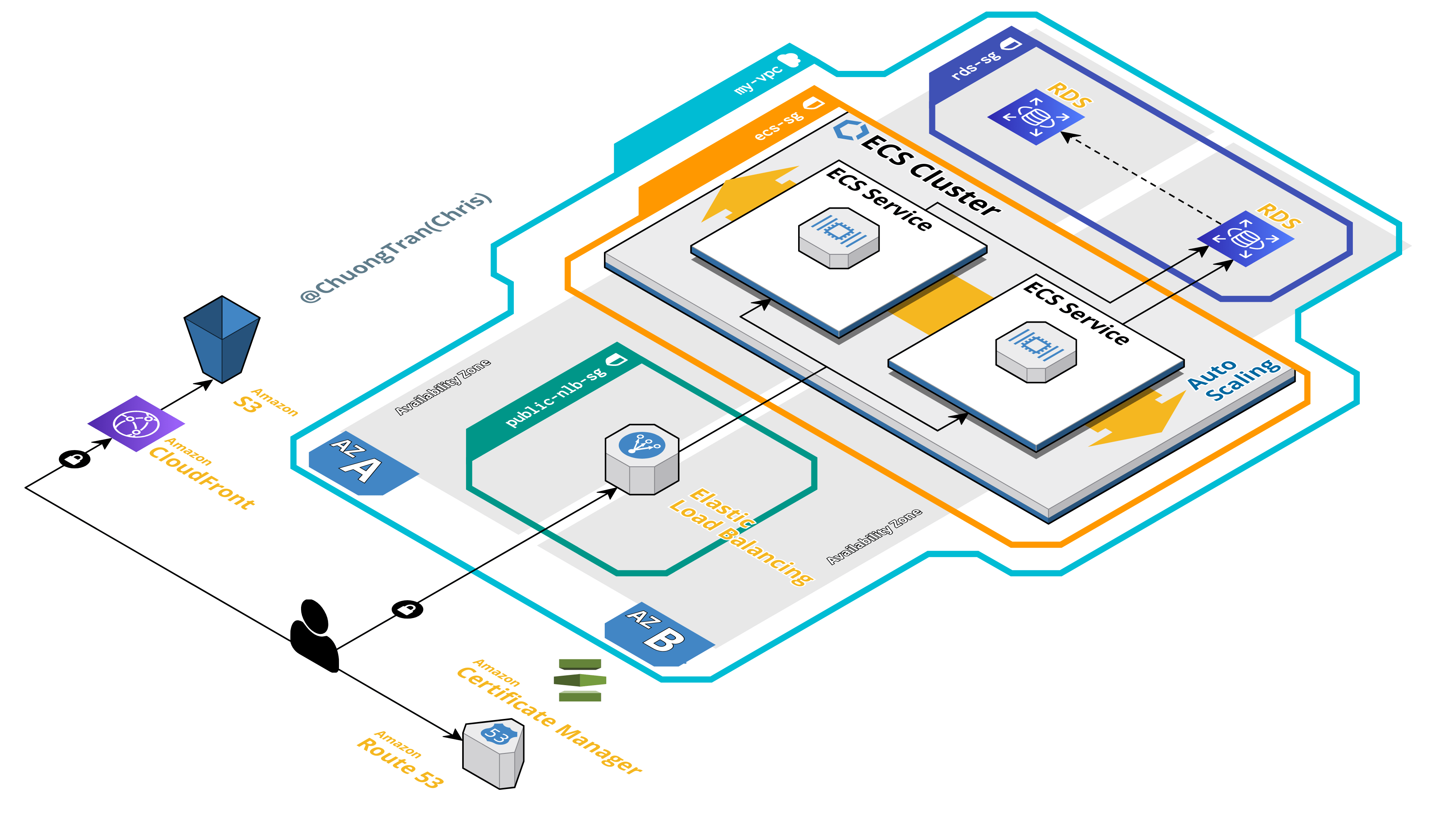
aws-dynasync
aws-dynasync is fresh from the open source forge at awslabs, and this project helps you create an AWS AppSync GraphQL API and an Amazon DynamoDB database with a single command. You can automate the building and provisioning of a GraphQL API using a single config file with AWS AppSync and Amazon DynamoDb to store the data. Nicely details documentation with examples means that if you are working in AWS AppSync and Amazon DynamoDB, you have to try this out.
chaos-lambda-extension
chaos-lambda-extension AWS Hero Efi Merdler-Kravitz is back with another tool that allows you to inject faults into Lambda functions without modifying the function code. Unlike previous chaos implementations that required tight coupling with the Lambda runtime, this extension is runtime-agnostic. It can operate with any runtime that utilises Amazon Linux 2. The chaos extension is publicly available as a layer and you can easily incorporate the layer using the AWS Console, or your preferred IAC solution. Efi is on a mission to create Rust based tools that help AWS developers, so check this out and let him know what you think. Efi reach out and added:
“It’s a Rust-written Lambda extension that introduces chaos, but here’s the kicker – no code changes needed. It’s a bit of a game-changer compared to other chaos utilities for Lambda."
Also, Efi is looking for your feedback. He told me:
… “I’ve been diving deep into Rust to boost the performance of some AWS CLI tools. I’m on the lookout for tools in the AWS ecosystem that might either need a revamp or simply don’t exist yet but could greatly benefit from that Rust speed magic. Got any pain points or gaps you’ve noticed that I might tackle? I’d love to hear your thoughts."
Demos, Samples, Solutions and Workshops
guidance-for-natural-language-queries-of-relational-databases-on-aws
guidance-for-natural-language-queries-of-relational-databases-on-aws demonstrates how to build an application enabling users to ask questions directly of relational databases using natural language queries (NLQ). The architecture uses LangChain’s SQL Database Chain, a Streamlit framework, and an Amazon SageMaker JumpStart Foundation Model (FM). With this Guidance, your NLQ will be converted into a natural language answer as part of the NLQ process. After submitting the converted SQL query and compiling the results, the results will be converted using generative artificial intelligence (AI) into a text explanation written in NLQ. The translation from SQL to NLQ is supported by a foundation model (FM) that translates the natural language question to SQL and back to a natural language answer. Gary Stafford who features regularly in this newsletter, wrote:
“This solution is first in a set of Generative AI Guidance from AWS to help our customers accelerate development of Generative AI use cases on AWS. Natural Language Query (NLQ) of structured data in relational, NoSQL, timeseries, and graph databases is of huge industry interest.”

llm-langchain-sql-demo
llm-langchain-sql-demo this repo provides code to enable you to follow along in the excellent post from colleague and regular face within this newsletter, Gary Stafford. In Generative AI for Analytics: Performing Natural Language Queries on Amazon RDS using SageMaker, LangChain, and LLMs, Gary shows you how you can use LangChain’s SQL Database Chain and Agent with large language models to perform natural language queries (NLQ) of Amazon RDS for PostgreSQL database. You will need access to OpenAI and Anthropic API keys to use this code.
AWS and Community blog posts
Community round up
Lots of really interesting content from the AWS Community this week, but starting us off is AWS Community Builder Sreekesh Iyer with his post, Self Hosting Supabase on AWS. Supabase is a well loved open source backend as a service that allows web and app developers to simplify common functionality they need (authentication and authorisation, storage, API generation, etc), and in this post Sreekesh provides a quick guide to get this up and running in your AWS environment so you can try it out for yourself. I somehow missed this post when it first came out, but AWS Hero Efi Merdler-Kravitz put together Migrating a Web App to AWS Lambda with Lambda Web Adapter that looked at how to use a project featured in #146 of this newsletter, aws-lambda-web-adapter, to migrate a sample web application. If you missed this project the first time, read Efi’s post and check out the project, it is super interesting. Vector databases and Large Language Models (LLMs) are everywhere it seems, so it is handy that AWS Community Builder Dejanu Alex has put together OpenSearch as Vector DB: Supercharge Your LLM, which provides a quick post on how Amazon OpenSearch can help you as well as showing you how to get this up and running. To finish up this Community roundup we have a regular face, AWS Community Builder Lars Jacobsson. He is back with a blog post this time, Introducing samp-cli for local Lambda debugging of SAM and CDK stacks looking at how one of this projects can help you dear developer, to improve the local developer experience when using AWS SAM and CDK. It is a must read this week.
Powertools for AWS Lambda
Whether you are new to Powertools for AWS Lambda, or a seasoned user, Mark Sailes tweeted last week details about the Discord server that you should join in order to meet the broader Powertools community and stay up to date with all the latest news.
Open Application Model (OAM)
Open Application Model (OAM) is an open-source specification for building cloud-native applications. It provides a declarative way to define the components of an application, including its services, configuration, and dependencies. In the post, Application first delivery on Kubernetes with Open Application Model Daniel Higuero, CTO of Napptive collaborates with Tsahi Duek, Andreas Lindh, and Siva Guruvareddiar on a hands on guide on how to implement the OAM using KubeVela, an open-source project, which implements the Open Application Model. Great post, well worth checking out. [hands on]
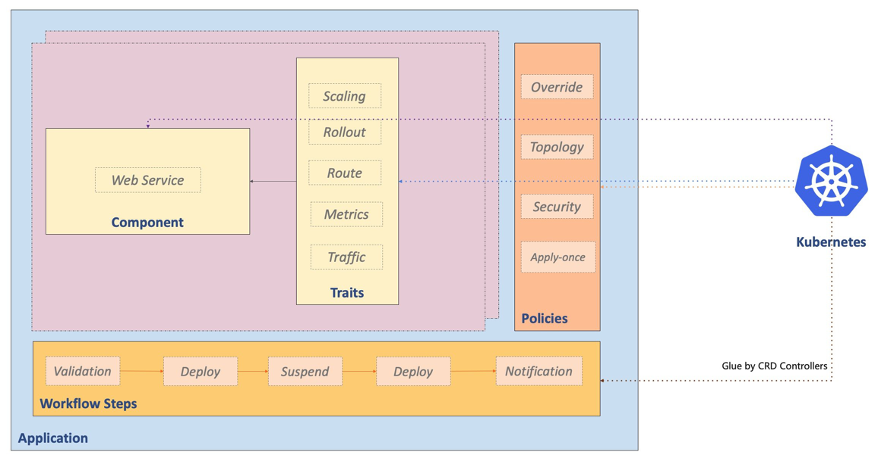
Traefik
Traefik is an open-source cloud-native load balancer and reverse proxy application developed by the software company Traefik Labs. In the post, Implementing application load balancing of Amazon ECS Anywhere workloads using Traefik Proxy, Cameron Senese demonstrates how to deploy and load balance a web application across multiple Amazon ECS Anywhere external instances, using Traefik Proxy (Traefik) [hands on]
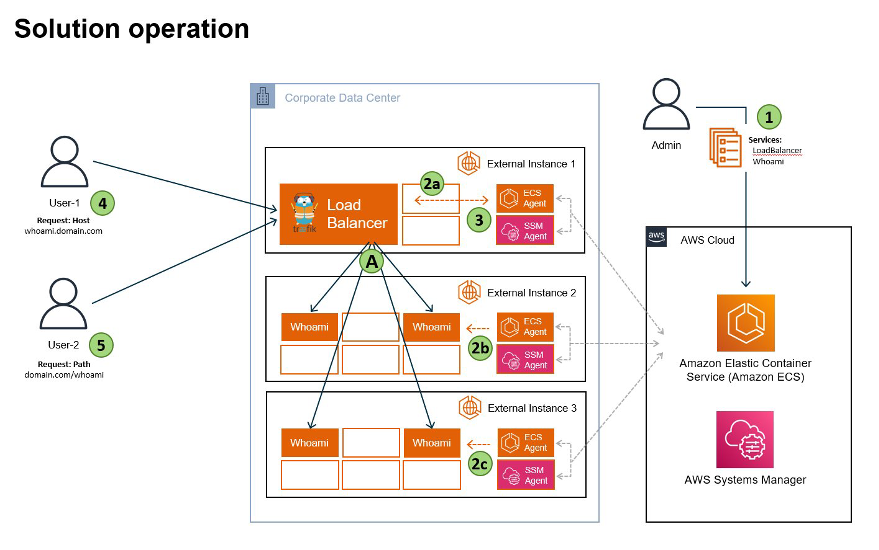
Keycloak
After blogging recently about how to use the CDK construct to deploy Keycloak into your AWS environment, I was delighted to see this post from Joseph Keating, Dinuth De Zoysa, and Virginia Chu. Configure Keycloak on Amazon Elastic Kubernetes Service (Amazon EKS) using Terraform helps you to deploy Keycloak into your AWS environment, using Terraform. Whereas my post helped you deploy on ECS, this one deploys into your Kubernetes clusters. Very nice post, with all the source code you need to deploy provide in the GitHub repo. [hands on]

Other posts and quick reads
- Building better container images shows you how to build better container images using best practices [hands on]
- The role of vector datastores in generative AI applications describes the role of vector databases in generative AI applications
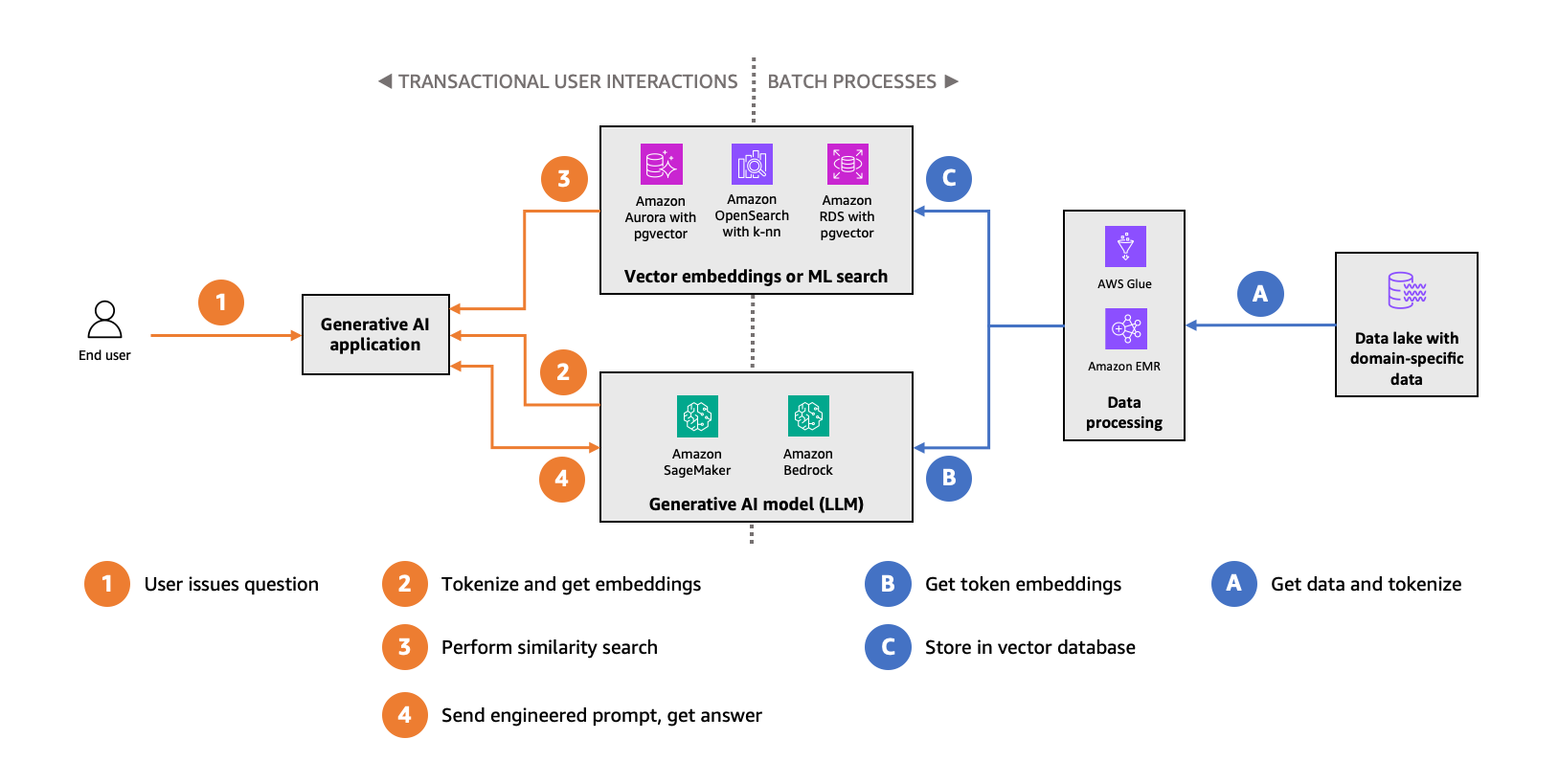
- Revolutionize retail recommendations for ecommerce with Amazon RDS for PostgreSQL and GenAI explores the significance of vector databases in retail recommendations, and how they are revolutionising the ecommerce landscape
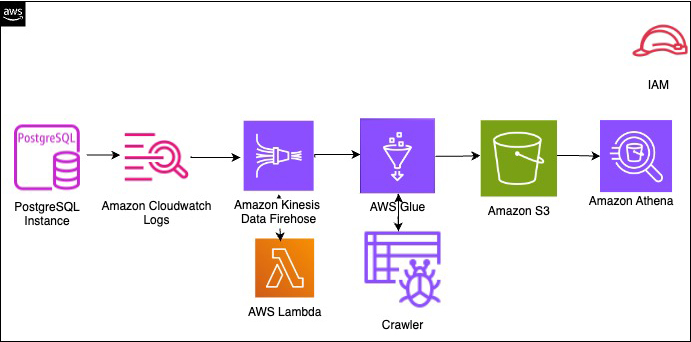
- Build a centralized audit data collection for Amazon RDS for PostgreSQL using Amazon S3 and Amazon Athena is a hands on guide that shows you how to capture and store audit data from an Amazon RDS for PostgreSQL database, store it in Amazon S3, and then process the data so you can query it with Amazon Athena [hands on]
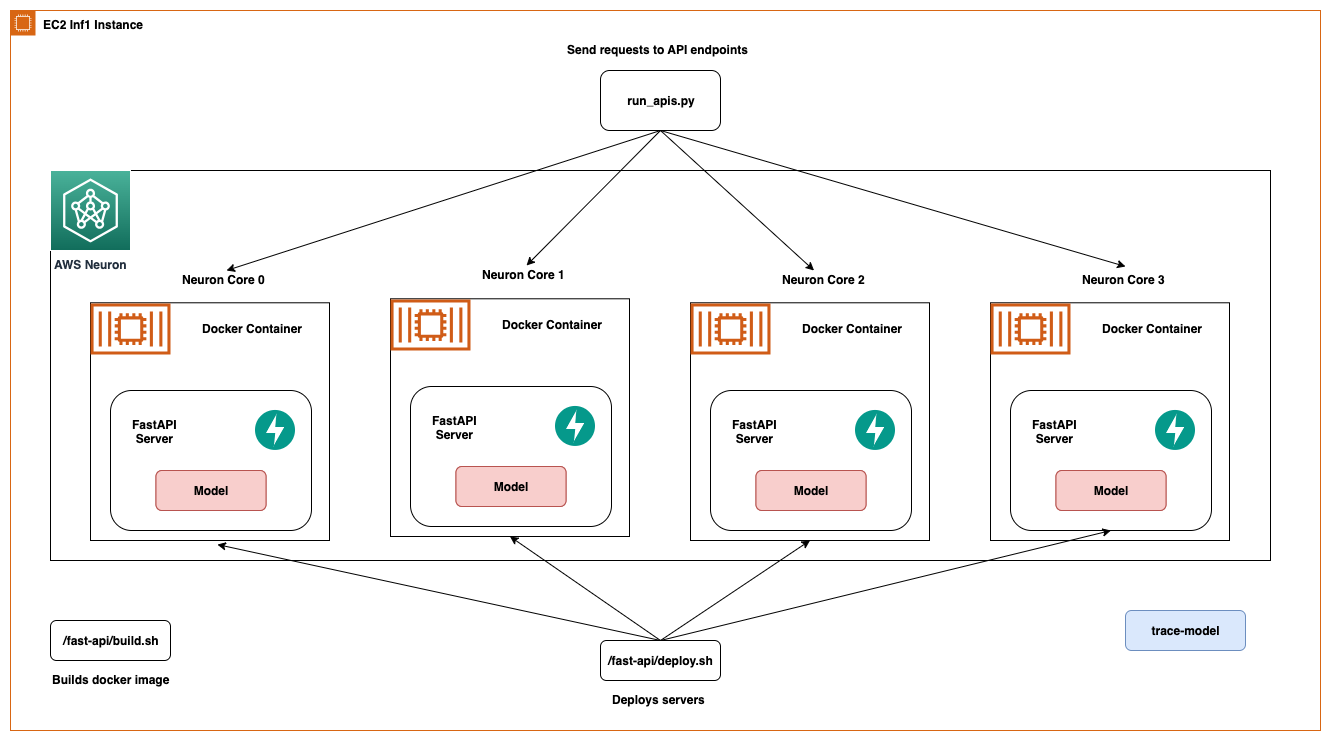
- Optimize AWS Inferentia utilization with FastAPI and PyTorch models on Amazon EC2 Inf1 & Inf2 instances helps you get started in deploying FastAPI model servers on AWS Inferentia devices, ready to start serving up your PyTorch models [hands on]
Quick updates
OpenSearch
Last week the OpenSearch community posted, Introducing OpenSearch 2.9.0 with new features designed to help you build better search solutions and integrate more machine learning (ML) into your applications, along with updates for security analytics workloads, geospatial visualisations, and more. Read the post to get all that OpenSearch goodness.
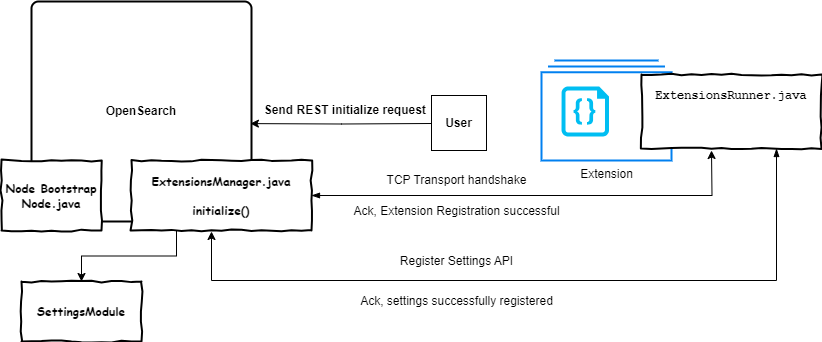
One of the interesting experimental features in this release are Extensions. In the post, Introducing extensions for OpenSearch Sarat Vemulapalli, Dan Widdis, Owais Kazi, Daniel (dB.) Doubrovkine, Dagney Braun, Minal Shah, and Fanit Kolchina dive deeper and walk you through what Extensions in OpenSearch are and why it was needed.
MySQL
Amazon Aurora MySQL-Compatible Edition 2 (with MySQL 5.7 compatibility) now supports MySQL 5.7.40. In addition to several security enhancements and bug fixes, this release is fully compatible with MySQL 5.7.40. Previous Aurora MySQL 2.x versions were compatible with MySQL 5.7.12.
IAM Roles Anywhere
AWS Identity and Access Management (IAM) Roles Anywhere is an open source project that enables workloads that run outside of AWS, such as servers, containers, and applications, to use X.509 digital certificates to obtain temporary AWS credentials and access AWS resources using the same IAM roles and policies that you have configured for your AWS workloads to access AWS resources.
IAM Roles Anywhere released credential helper version 1.0.5 to include support for X.509 certificates and private keys that are stored in macOS and Windows certificate stores. IAM Roles Anywhere credential helper is a tool that manages the process of signing the CreateSession API with the private key associated with an X.509 end-entity certificate and calls the endpoint to obtain temporary AWS credentials. With this release, you can now use IAM Roles Anywhere credential helper to delegate signing operations to keys stored within those OS-specific certificate stores, without those keys ever leaving those stores; which can improve your security posture. In Windows, both CryptoAPI and Cryptography API: Next Generation (CNG) are supported; in macOS, Keychain is supported.
MQTT
AWS IoT Core MQTT now supports Device Location. IoT Core Device Location feature allows customers to obtain devices’ location data and build location based applications even when devices don’t have a built in GPS. With IoT Core Device Location feature, customers can use advanced cloud based location solvers, such as Wi-Fi scan, Cellular scan, Global Navigation Satellite System (GNSS) scan, and reverse IP look-up to determine geo-coordinates of their IoT devices for use cases such as map visualisation, historical route tracking, and Geo-fencing. Now, with MQTT support for Device Location, customers can use their MQTT devices’ existing connection and data path with AWS IoT Core to obtain devices’ geo-coordinates and send them to 20+ AWS services, including Amazon Location Service. The added support for MQTT devices eliminates the need of maintaining multiple data paths between IoT devices and AWS IoT Core, simplifying customer’s development process when building location based IoT solutions.
Amazon EMR
A few of updates this week.
First up is news that you can now store logs for your EMR Serverless Spark and Hive applications in Amazon CloudWatch. Amazon EMR Serverless is a serverless option that makes it simple for data analysts and engineers to run open-source big data analytics frameworks like Apache Spark and Apache Hive without configuring, managing, and scaling clusters or servers. When you submit a job to an EMR Serverless application, you can decide where to store your application logs - in a managed storage system, an Amazon S3 location, or both. Now, you can choose Amazon CloudWatch as an option as well. This feature allows you to take advantage of CloudWatch log analysis features such as CloudWatch Logs Insights, Live Tail etc. as well as stream logs from CloudWatch to other systems such as Amazon OpenSearch for further analysis. When storing logs in Amazon CloudWatch, log data is always encrypted but you can choose to use your own encryption keys as well.
From Amazon EMR Serverless to Amazon EMR on EC2. Announced last week was a new feature that enables user authentication to EMR on EC2 clusters using Lightweight Directory Access Protocol (LDAP) based credentials. This feature allows administrators to configure EMR on EC2 clusters to authenticate corporate identities in their Active Directory (AD) using LDAP. With this launch, AD users are synced to the EMR on EC2 cluster automatically when LDAP authentication is enabled. This simplifies authentication to EMR clusters for administrators by eliminating the manual steps to sync users and/or implementing application-specific LDAP configuration. Amazon EMR on EC2 customers create and manage their corporate user identities and groups in an LDAP directory based service such as AD or openLDAP. With native LDAP integration, end users can authenticate to EMR clusters using their AD credentials and use applications such as Hue, Presto and Livy to run jobs as themselves. This simplifies user authentication with EMR on EC2 clusters using AD and allows corporate users to launch queries and sessions on applications such as Hue, Presto using their LDAP based credentials. Prior to this launch, administrators configured Kerberos to authenticate AD users which is manual and effort-intensive. With this launch, administrators can also enforce fine-grained access control (FGAC) for AD users through Apache Ranger authorisation for Hive Metastore database and tables.
Next, and sticking with Amazon EMR on EC2 was news that two new capabilities that enhances the scaling experience for Amazon EMR on EC2 clusters: a new retry mechanism for faster scaling of your Amazon EMR on EC2 clusters running Presto or Trino; and faster scale-down of Amazon EMR on EC2 clusters by enforcing the data redundancy requirements. These capabilities are automatically enabled for clusters running Amazon EMR 6.12 or higher releases and no action is needed from your end.
Finally, from Amazon EMR on EC2 to Amazon EMR on EKS. Apache Spark with Java 17 in EMR on EKS is now supported. AWS customers can now leverage Java 17 as a supported Java runtime to run Spark workloads on Amazon EMR on EKS, and benefit from Java 17’s language enhancement and performance improvement. Amazon EMR on EKS enables customers to run open-source big data frameworks such as Apache Spark on Amazon EKS. Up until this update, Amazon EMR on EKS ran Spark with Java 8 as the default Java runtime with Java 11 as an option. In order to run Spark on EMR on EKS with Java 17, it requires an additional effort to the customer by creating a custom image, and replacing the default Java 8 runtime with Java 17. With this new feature, customers can now select Java 17 as a supported runtime to run Spark jobs on EMR on EKS.
Bonus material
Check out the post, Improved scalability and resiliency for Amazon EMR on EC2 clusters, where Ravi Kumar Singh and Kevin Wikant dive into improvements that AWS has made in Amazon EMR on EC2 with the goal to make your EMR clusters more resilient and stable.
Apache Iceberg
Amazon Redshift today announces the preview release of Apache Iceberg support, enabling users to run analytics queries on Apache Iceberg tables within Redshift. Apache Iceberg, one of the most recent open table formats, has been used by many customers to simplify data processing on rapidly expanding and evolving tables stored in data lakes. You can now use Amazon Redshift to query your Apache Iceberg tables in AWS Glue Data Catalog while other users or applications can safely conduct data manipulation on your tables using ACID (atomicity, consistency, isolation and durability) compliant services like Amazon EMR, Amazon Athena, and AWS Glue.
Apache Hudi
AWS Glue Crawlers now supports Apache Hudi tables, allowing customers to query data in Apache Hudi tables directly from AWS analytics services like Amazon Athena. Apache Hudi is an open-source table format that brings database and data warehouse capabilities to the data lake. Apache Hudi helps data engineers manage continuously evolving data sets while maintaining query performance. To query data from Apache Hudi tables, previously Amazon Athena users had to manually create a table within the Glue Data Catalog and update partition changes to ensure the query results were current. With today’s launch, users can automatically register Apache Hudi tables into the Glue Catalog by running the Glue Crawler. Glue Crawler supports partitioned and non-partitioned Copy on write (CoW) and Merge on read (MoR) Hudi tables. Users can then query Glue Catalog Hudi tables across various analytics services and apply Lake Formation fine-grained permissions. With Glue Crawlers, users can also migrate data from other Hudi Catalogs to the Glue Catalog.
Go
If you are a Go developer, then make sure you check out Migrating AWS Lambda functions from the Go1.x runtime to the custom runtime on Amazon Linux 2 where Micah Walter, Yanko Bolanos, and Ramesh Mathikumar describes our plans to improve performance and streamline the user experience for customers writing AWS Lambda functions using Go.
Python
On a related note, you can now use Python 3.11 in AWS Lambda. Ramesh Mathikumar, and Francesco Vergona put together Python 3.11 runtime now available in AWS Lambda that explores this in more details.
Videos of the week
Cedar
I shared details about this community meetup in previous issues of the newsletter. If you were not able to attend, you can now watch the recording which is available on permit.io’s YouTube channel. One of the great things in this video was a look at how you as developers can implement Cedar into your applications.
RabbitMQ
Take a peek at this discussion in the RabbitMQ community, where AWS talk about recent changes to quorum queues.
Pacu
Pacu is an open source tool which is used for ethical offensive security . In this video, you’re going to learn how to ethically hack AWS cloud environments that you have explicit permissions for so that you can find exploitable vulnerabilities in your own AWS accounts or for your clients as a pentester, before the bad threat actors do.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS User Group UK Meetup #61 London, August 16th
AWS User groups regularly meet across the world, and in this London chapter of the AWS User group, Matt Carey will be sharing his talk “Building a Viral Open Source AI Chatbot: A Journey from Concept to Reality”. From the extract:
“Learn how we built Quivr - the open-source virtual brain. In 2.5 months we achieved 8k active users of the demo app and a whopping 18k stars on GitHub. We were number 1 on the GitHub trending page for multiple days in a row. This is the story of how Quivr went viral and how our tiny dev team struggled to build all the features our user base wanted. We will talk about the challenges we faced scaling a generative AI-powered app without it costing the earth on ECS Fargate, and the extra tooling we had to build along the way. We will cover how we solved the problems of keeping the project open source and super easy to both use and contribute whilst leveraging AWS services in a different way to most.”
Find out more about the other talk and details of how to register, over at the meetup page AWS User Group UK Meetup
RADIUSS AWS Tutorials: Learn how to use a modern HPC software stack Online, throughout August 2023
Check out this series of online tutorials happening throughout August demonstrating how to use several GPU-ready projects in the cloud and on premises. Follow along on your own EC2 instance (provided). No previous experience necessary. Lots of open source technologies are covered in this series, so if you are looking to get started in this space, check out the details on the information page, Learn how to use a modern HPC software stack. Brenden Bouffler has also put together a great blog post, Call for participation: RADIUSS Tutorial Series 2023 that dives deeper into some of these topics and provides further information.
Building ML capabilities with PostgreSQL and pgvector extension YouTube, 14th September 4pm UK time
Generative AI and Large Language Models (LLMs) are powerful technologies for building applications with richer and more personalised user experiences. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Register now to learn more about this powerful technology.
Watch it live on YouTube.
Build ML into your apps with PostgreSQL and the pgvector extension YouTube, 21st September 4pm UK time
This office hours session is a follow up for those who attended the fireside chat titled “Building ML capabilities into your apps with PostgreSQL and the open-source pgvector extension”. Others are also welcome. Office hours attendees can ask questions related to this topic. Application developers who use Amazon Aurora for PostgreSQL or Amazon RDS for PostgreSQL can use pgvector, an open-source extension for PostgreSQL, to harness the power of generative AI and LLMs for driving richer user experiences. Join us to ask your questions and hear the answers to the most frequently asked questions about the pgvector extension for PostgreSQL.
Watch it live on YouTube.
Open Source Summit, Europe September 19th-21st, Bilboa Spain
“Open Source Summit is the premier event for open source developers, technologists, and community leaders to collaborate, share information, solve problems, and gain knowledge, furthering open source innovation and ensuring a sustainable open source ecosystem. It is the gathering place for open-source code and community contributors.” You will find AWS as well as myself at Open Source Summit this year, so come by the AWS booth and say hello - from the glimpses I have seen so far, it is going to be awesome! Find out more at the official site, Open Source Summit Europe 2023.
2023 UC Santa Cruz Open Source Symposium University of California, Santa Cruz
This three day event in Santa Cruz, California will provide the opportunity to learn about the cutting edge open source research being done throughout the University of California. To find out more and to register your interest, sign up here.
OpenSearchCon Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Open Source India October 12-13th, NIMHANS Convention Center, Bengaluru
One of the most important open source events in the region, Open Source India will be welcoming thousands of attendees all to discuss and learn about open source technologies. I will be there too, doing a talk so I would love to meet with any of you who are also planning on attending. Check out more details on their web page, here.
All Things Open October, 15th-17th, Raleigh Convention Center, Raleigh, North Carolina
I will be attending and speaking at All Things Open, looking at Apache Airflow as an container orchestrator. I will be there with a bunch of fellow AWS colleagues, and I hope to meet some of you there. Check us out at the AWS booth, where you will find me and the other AWS folk throughout the event. Check out the event and sessions/speakers at the official webpage for the event, AllThingsOpen 2023
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen