AWS open source newsletter #165
July 17th, 2023 - Instalment #165
Welcome to #165 of the AWS open source newsletter, the only* newsletter that brings you the best and latest open source content. We have some great new projects this week, including a tool for IoT developers to help you validate your SQL statements, a command line interface tool for Amazon Verified Permissions, an Amazon DynamoDB estimation tool, and more. Also featured this week is content on Apache Iceberg, OpenSearch, PostgreSQL, Kubernetes, Power Tools for AWS Lambda, Spring Boot, Babelfish for Aurora PostgreSQL, Karpenter, Apollo GraphQL, JupyterHub, dbt, Apache Airflow, Cedar, and Apache Flink.
We have added quite a few new events this week, so make sure you check those out as well as the Video section for some must watch videos this week.
(*from me at least!)
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Alina Dima, Daniel Aniszkiewicz, Gabe Hollombe, Salman-Sali, Tomasz Dudek, Rafał Mituła, Rafal Gancarz, Sylvia Lin, Heitor Lessa, Zygimantas Koncius, Sudhir Gupta, Alok Srivastava, Wanchen Zhao, Anjali Dhanerwal, Mohammed Asadulla Baig, Aychin Gasimov, Johannes Koch, David Nalley, Mike Hicks, Oleg Z, and Mark Sailes.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution. The projects mentioned here do not represent any formal recommendation or endorsement, I am just sharing for greater awareness as I think they look useful and interesting!
Tools
validation-tool-for-aws-iot-rules
validation-tool-for-aws-iot-rules is a tool that enables developers to test and validate IoT Rules SQL Statements without the heavy lifting of having to set up the infrastructure themselves. The goal of this framework is to provide developers with a “Closed-box” - type of validation tool, where only input payload, SQL statement and expected output need to be configured. If the Rules Engine parses the input as expected with the expected output, tests will succeed, if not they will fail. Expected versus actual output payload will be printed for references.
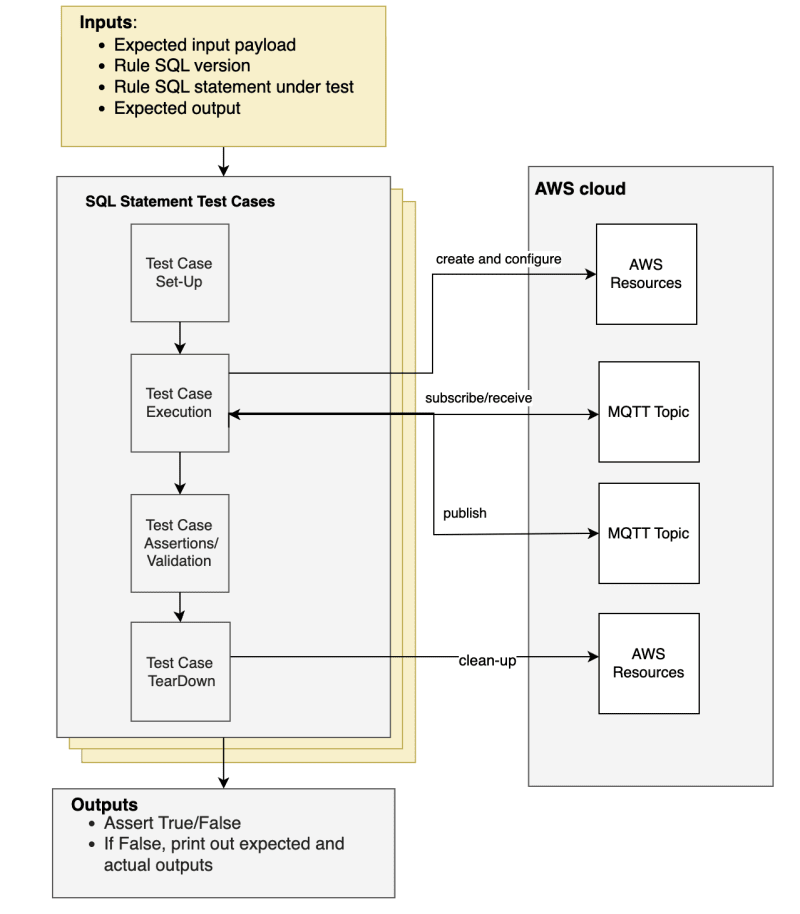
To find out more, be sure to read Alina Dima’s post, A Tool to Validate AWS IoT Rules SQL Statements where she dives deeper into this topic and shows you how this tool can help. You can also check out this video she put together which is super helpful.
avp-cli
avp-cli is a handy command line tool from AWS Community Builder Daniel Aniszkiewicz, designed to interact with the AWS Verified Permissions (AVP) service. You can use it to create, manage, and delete policy stores, schemas, and policies. Comprehensive documentation and examples are just another reason why I like this project, so thank you Daniel for putting this together. If you like this, make sure you star the project and let Daniel know for yourself.
WebTruss.EntityFrameworkCore.DynamoDb
WebTruss.EntityFrameworkCore.DynamoDb is an entity framework like library for AWS DynamoDb for .NET developers from Salman-Sali. His goal is to provide a very easy to use, pick up and go library for dynamoDb. Currently these are some of the functions that are supported (FirstOrDefault, Any, ExecutePut, ExecuteDelete, PagedList, ScannedList) but he will be adding more functions. Please feel free to raise an issue or pr for a feature. He also provides an example of how to use this framework in the repo.
dynamodb-scaling-simulator
dynamodb-scaling-simulator is a tool from my good friend and former colleague Gabe Hollombe that helps you plan appropriate configs for DynamoDB provisioned capacity with auto-scaling. It helps you to simulate how a provisioned-capacity DynamoDB table will perform (will it throttle requests or not?) under different auto-scaling configurations. It will also try to calculate the best config for you that results in the lowest cost and no throttles.
Demos, Samples, Solutions and Workshops
saas-boilerplate
saas-boilerplate is an opinionated full stack web app’s boilerplate, ready to be deployed to AWS platform. It includes essential features that every SaaS application requires, such as frontend, backend API, admin panel, and workers. With a scalable AWS-based architecture and continuous deployment, you can easily deploy multiple environments representing different stages in your pipeline. It looks very comprehensive, and provides lots of features including (but not limited to) payments, authentication and authorisation, notifications, emails, and many more.

aws-sam-swift
aws-sam-swift This project contains a Cookiecutter template to create a serverless application based on the AWS Serverless Application Model (SAM) and Swift. This project is intended to be used as a template location for the SAM Command Line Utility (CLI). SAM generates a project on your local machine based on this template. You can learn more about this by checking out the documentation, Swift Server Templates.
bespoke
bespoke is an open source Personalized Marketing Platform that combines the functionality of Mailchimp, Kalviyo’s automation, Substack’s newsletter and Typeform for surveys. The repo provides deployment guidelines on how to get this up and running on your AWS environment. If this looks interesting to you, get in touch. I might be persuaded in putting together a blog post if enough people are interested. (Hat Tip to my colleague Gunnar for sharing this with me!)
AWS and Community blog posts
Community round up
As regular readers will know, Apache Airflow is one of my favourite open source projects, and I love reading community posts on this technology. I was delighted therefore when AWS Community Builders Tomasz Dudek and Rafał Mituła wrote Dynamically create AWS ECS Task Definitions to simplify IaC and Semantic Versioning in AWS MWAA (Apache Airflow) which looks at how they were able to use Airflow orchestration capabilities together with Amazon ECS to run their data engineering workflows at scale. Great post, and a must read this week.

The post Instacart Creates a Self-Serve Apache Flink Platform on Kubernetes from Rafal Gancarz pointed me back to the original post from Sylvia Lin which I missed when it was originally posted back in April. In Building a Flink Self-Serve Platform on Kubernetes at Scale Sylvia explains how Instacart took the decision to move to a self managed Apache Flink running on Amazon EKS, and how this able to help them with their mission of providing a robust self-serve Flink platform for their teams.
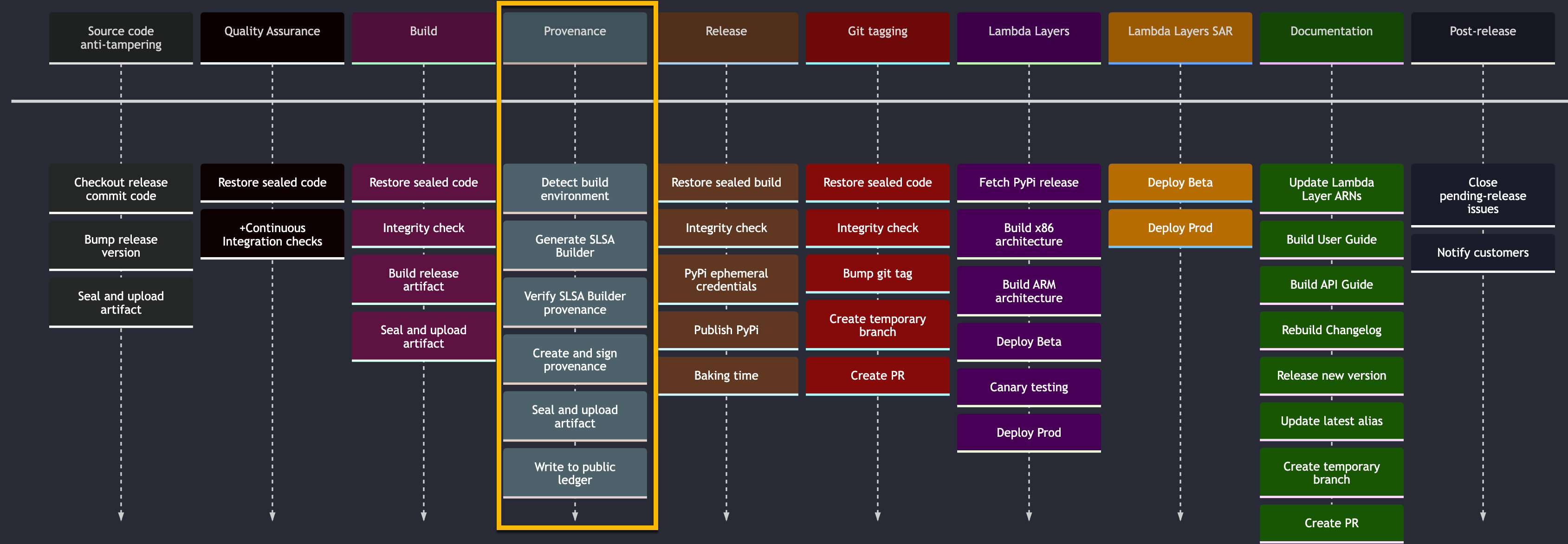
Powertools for AWS Lambda
Starting from v2.20.0 releases, Powertools for AWS Lambda builds are reproducible and signed publicly. You can take a look at the documentation on the Security section of the documentation site, which documents how they are using the SLSA framework to follow supply chain security best practices. You can now verify releases using the SLSA verifier, and check the public attestation details in the public repository on rekor.

This is a hot topic for all projects, and Heitor has put together very detailed documentation which you can study and see how you can apply to your own projects. This is essential reading this week folks, so make sure you do not skips this one.
JupyterHub
Check out JupyterHub on EKS which provides an emerging EKS Blueprint that combines the versatility of JupyterHub with the scalability and flexibility of Kubernetes. The blueprint leverages the Data on EKS project and simplifies how you can deploy this. Check out the documentation and code on the GitHub repo to get started. [hands on]
dbt
In the post, Configure end-to-end data pipelines with Etleap, Amazon Redshift, and dbt, Zygimantas Koncius from Etleap collaborates with Sudhir Gupta from AWS to show how Etleap’s end-to-end pipelines enable data teams to simplify their data integration and transformation workflows as well as achieve higher data freshness.
PostgreSQL
A few posts of note this week on all things PostgreSQL. Kicking things off we have, Cross-account Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL migration with reduced downtime using AWS DMS where Alok Srivastava and Wanchen Zhao provide a practical, hands on guide on the various steps involved in migrating your Aurora PostgreSQL or RDS for PostgreSQL database from one AWS account to another. [hands on]

Following that Anjali Dhanerwal and Mohammed Asadulla Baig have put together this post, Improve app performance through pipelining queries to Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL that shows you how pipelining PostgreSQL queries can help improve overall application performance by reducing query latency over the network. [hands on]

To finish up this collection, we had the post Migrate PostgreSQL from Google Cloud Platform to Amazon RDS with minimal downtime that shows you a procedure to migrate the PostgreSQL database from Google Cloud Platform (GCP) Cloud SQL to Amazon Relational Database Service (Amazon RDS) for PostgreSQL. The author, Aychin Gasimov, explores how you can the AWS Database Migration Service to enable this, and how it is not limited to this one Cloud provider.

Other posts and quick reads
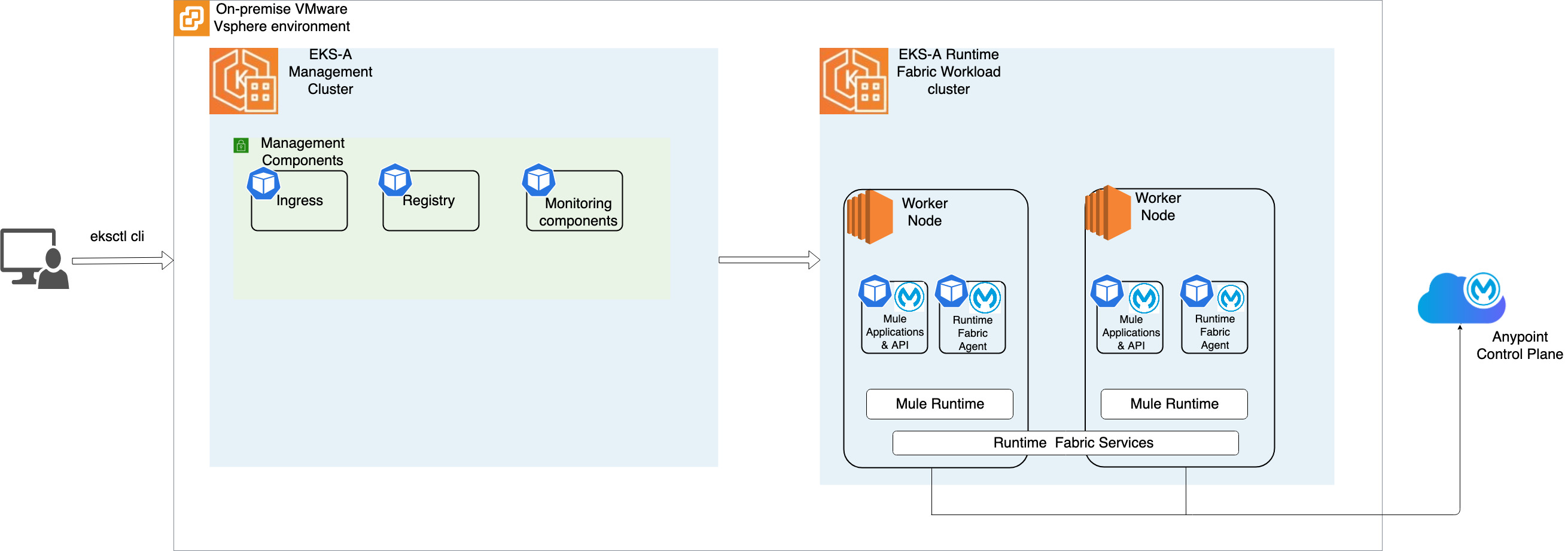
- MuleSoft Anypoint Runtime Fabric Deployment On Amazon EKS Anywhere looks at how to deploy MuleSoft Anypoint Runtime Fabric on Amazon EKS Anywhere to bring the power and flexibility of MuleSoft’s runtime environment to on-premises and edge locations [hands on]
- Apollo GraphQL Federation with AWS AppSync is an update to this post that I shared early in 2022, updated to comply with the new Apollo Federation spec v2.0
- New Solution – Clickstream Analytics on AWS for Mobile and Web Applications provides a supporting blog post on the clickstream project I shared in #164 of the newsletter, that will walk you through everything you need to know to get started [hands on]
- Better Together – Graviton 2 and GP3 with Amazon OpenSearch Service looks at the cost savings you might see by running Amazon OpenSearch Service on Graviton2 based instances with gp3 based EBS storage, compared to running OpenSearch on traditional x86 based instances with gp2 based EBS storage [hands on]
Case Studies
- Leveraging Open Source at Barclays to Enable Lambda Event Filtering with AWS Glue Schema Registry dives into how Barclays achieved AWS Glue Schema Registry integration with AWS Lambda event filtering by leveraging the open source library.
- Best Practices for Optimizing Kubernetes Costs on AWS with StormForge and Karpenter looks at how this AWS Partner can help businesses leverage Karpenter to optimise both application and infrastructure configurations to reduce Kubernetes costs.
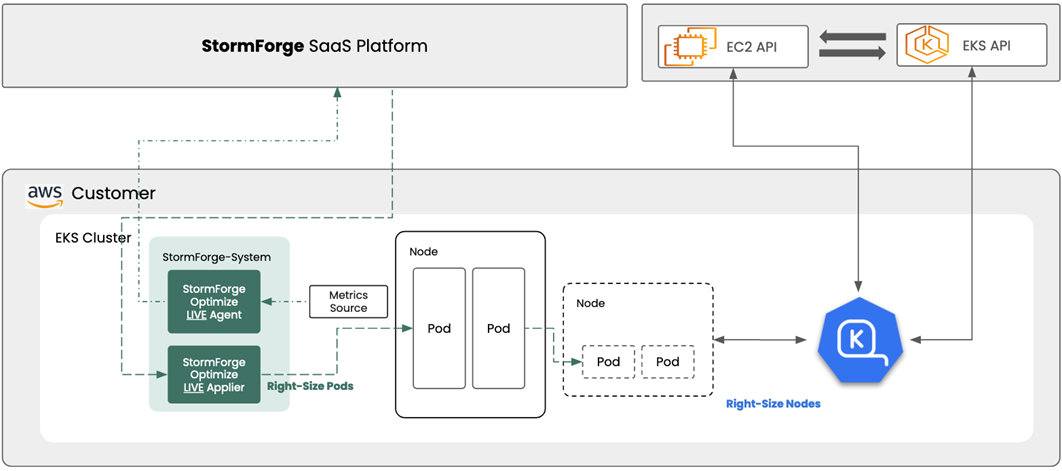
- How Amazon EKS and Precisely’s Geo Addressing SDK Power Real-Time Decisions looks at how geo addressing capabilities can be deployed on AWS infrastructure to accelerate analysis and power real-time decision making.
Quick updates
Apache Iceberg
AWS Glue Crawlers now supports Apache Iceberg tables, simplifying the adoption of AWS Glue Data Catalog as catalog for Iceberg tables and migrating from other Iceberg catalogs. Apache Iceberg is an open-source table format for data stored in data lakes that helps data engineers manage complex challenges, such as managing continuously evolving data sets while maintaining query performance. With today’s launch, you can automatically register Iceberg tables into Glue Catalog by running the Glue Crawler. You can then query Glue Catalog Iceberg tables across various analytics engines and apply Lake Formation fine-grained permissions when querying from Amazon Athena.
When migrating from other Iceberg Catalogs, you can create and schedule a Glue Crawler and provide one or more Amazon S3 paths where the Iceberg tables are located. You have the option to provide the maximum depth of S3 paths that the Glue Crawler can traverse. With each run, Glue Crawler will extract schema information and update Glue Catalog with the schema changes. Glue Crawler supports schema merging across snapshots and updates the latest metadata file location in the Glue Catalog that AWS analytical engines can directly use.
OpenSearch
You can now run OpenSearch version 2.7 in Amazon OpenSearch Service. With OpenSearch 2.7, we have made several improvements to observability, security analytics, index management, and geospatial capabilities in OpenSearch Service. The new version includes features that were launched as part of open source OpenSearch versions 2.6 and 2.7. Some of the key improvements include introduction of Simple Schema for Observability, providing a unified schema for OpenSearch, ability to add map visualisations to Dashboard panels and ability to filter geospatial data against geospatial field types, support in security analytics for five new log types and the ability to define threat detectors with multiple indexes or index patterns. This release also includes improvements to the Dashboards user interface (UI) such as the ability to manage data streams from the Index Management UI, perform manual rollover and force merges for indices or data streams, and the ability to manage multiple index templates using component templates. The UI improvements also include support for dynamic tenant management, ability to access observability features from the Dashboards main menu, and the ability to add event analytics visualisations to dashboards. Other improvements include support for flat object field type, and support for replication of kNN indices in cross-cluster replication.
Kubernetes
Amazon GuardDuty EKS Runtime Monitoring continuously monitors and profiles container runtime activity to identify malicious or suspicious behavior within container workloads. Using a lightweight, fully-managed eBPF security agent, GuardDuty monitors on-host operating system-level behavior, such as file access, process execution, and network connections. Once a potential threat is detected, GuardDuty generates a security finding that pinpoints the specific container, and includes details such as pod ID, image ID, EKS cluster tags, executable path, and process lineage.
The Amazon GuardDuty EKS Runtime Monitoring eBPF security agent now supports Amazon Elastic Kubernetes Service (Amazon EKS) workloads that use the Bottlerocket operating system, AWS Graviton processors, and AMD64 processors. Additionally, the new agent version (1.2.0) introduces performance enhancements, built-in CPU and memory utilisation limits, and support for Amazon EKS 1.27 clusters.
PostgreSQL
Following the announcement of updates to the PostgreSQL database by the open source community, we have updated Amazon Aurora PostgreSQL-Compatible Edition to support PostgreSQL 15.3, 14.8, 13.11, 12.15, and 11.20. These releases contains product improvements and bug fixes made by the PostgreSQL community, along with Aurora-specific improvements. This release also contains new features and improvements for Babelfish for Aurora PostgreSQL version 3.2 and improved support for Amazon Web Services Database Migration Service version 3.5.1 Aurora PostgreSQL target endpoint Babelfish data types.
Videos of the week
AWS On Air ft. Open Source Security at AWS
AWS is committed to raising standards for open source security by developing key security-related technologies with community support and by contributing code, resources, and talent to the broader open source ecosystem. We recently launched the open source Cedar policy language and SDK, the technology that powers Amazon Verified Permissions, for writing and enforcing authorisation policies for your applications using automated reasoning. By open sourcing Cedar, we are providing transparency into Cedar’s development, inviting community contributions, and hoping to build trust in Cedar’s security. David Nalley and Mike Hicks talk more about open source security at AWS and the Cedar project in this discussion and demo.
Powertools for AWS Lambda
This is the follow up video from the first episode shared in #164, where AWS Hero Johannes Koch and Heitor Lessa look at the Continuous Deployment Pipeline for the Powertools for AWS Lambda (for Python). It explores areas such as “sealed” source code, automated testing and publishing and a cross-regional roll-out. A must watch session, as Heitor has really been raising the bar in architecting the infrastructure used to build this project.
Spring Cloud Function and AWS: Performance, Portability, and Productivity
Spring Cloud Functions enables you to write simple Java Functions that, combined with Spring Boot, can easily be realised in a serverless environment such as AWS Lambda. Implementing business logic as functions is a perfect fit for AWS Lambda’s event-driven architecture. How to get the most from both of these technologies and its features? Are there any useful tricks? What about Spring Native and AOT? In this video Oleg Z and Mark Sailes discuss and demonstrate these features and enhancements with a single function handling 10,000 requests a second.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS Go Build On EKS Series: Cost Online, July 19th 10am UK time
This is L300 event that is split into two sessions. How to reduce costs is a topic on most peoples minds today, in the first session, that will cover how to reduce costs in your EKS workload by first covering common cost factors and easy fixes to bring down your overall spend. You will also look at how to think about efficiency for your workload and how to calculate your costs down to the pod level. You will also see a demo with Kubecost and what factors to think about when installing and setting it up. In the second session, you will see practical examples that combine different techniques to help you build for sustainability on Amazon EKS by making use of Graviton, EC2 Spot, effective autoscaling with Karpenter, among other topics.
Register to save your space on the page, AWS Go Build On EKS Series: Cost
ElastiCache for Redis: Boost Your Startup’s Performance with Lightning-Fast Data Online, July 19th 1pm UK time
In this online webinar, you will learn more about some of the advanced features of Amazon ElastiCache and MemoryDB. You will dive deep into the features of ElastiCache and MemoryDB, explore Redis topologies and features, look at ElastiCache and MemoryDB Use Cases, find out about best practices for Highly Available architecture, and hear about monitoring, sizing, and other best practices.
This is a L200 session, and you can sign up to save your place on the registration page, ElastiCache for Redis: Boost Your Startup’s Performance with Lightning-Fast Data
Building Scalable Microservices with TiDB and AWS Lambda AWS Offices in New York, July 24th, 10am - 2pm
TiDB is an open-source New SQL database that supports Hybrid Transactional and Analytical Processing workloads. It is MySQL compatible and can provide horizontal scalability, strong consistency, and high availability. Join PingCAP and AWS for an in-person workshop where you’ll learn about TiDB Serverless and AWS Lambda. You’ll explore how to combine them to build scalable, highly-available microservices while generating real-time insights directly from raw application data.
You will need to register to save your place, so head over to Building Scalable Microservices with TiDB and AWS Lambda and find out more.
Discover AWS' Cedar With its Creator and Community Leaders Online, July 26th, 11:00 EST / 15:00 GMT
If you are interested in Cedar, then make sure you check out this must attend online event where discussing AWS’ new open-source policy language and engine Cedar! Learn more about its benefits, ecosystem, integrations, and this new breakthrough in the IAM space! Plenty of familiar faces including Mike Hicks, Or Weis, Daniel Aniszkiewicz, and Filip Grebowski will be covering the Cedar policy language and how it works, and you can expect plenty of demos.
Sign up and register your spot over at the Discover AWS' Cedar With its Creator and Community Leaders page.
OpenSearchCon Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen