AWS open source newsletter #164
July 10th, 2023 - Instalment #164
Welcome to #164 of the AWS open source newsletter. As always, we search high and low for the best and latest open source content, and I think you will love what we have lined up this week.
New projects this week will help you implement single table designs easily on Amazon DynamoDB, an experimental project to help you get to grips with Cedar, a comprehensive clickstream analytics project for your applications, web sites, and mobile applications, and some cool projects to help you with edge and hybrid use cases. This week we have content covering open source technologies that include Apache Flink, Apache Airflow, Kubernetes, AWS Lambda Powertools, Spring Boot, Linux, Apache Parquet, OpenZFS, OpenSearch, Mountpoint for Amazon S3, PostgreSQL, AWS Amplify, Next.js, AWS Distro for OpenTelemetry, Grafana, Babelfish for Aurora PostgreSQL, AWS ParallelCluster, Consul, Apache Iceberg, Cedar, Steampipe, VS Code Server, and Nomad.
Also, be sure to check out the events section as there are a few events happening this week.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and you will forever have my gratitude! The first 25 will get a $50 AWS Credit voucher as a thank you.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Ian Mckay, Andrew ‘mrpackethead’, Dan Vega, Johannes Koch, Heitor Lessa, Harsh Rawat, Purvi Goyal, Jie Chen, John Jackson, Anil Raut, Nataizya Sikasote, Marine Haddad, Tom Palmer, Tony Phan, George Agiasoglou, Guy Bachar, Boris Litvin, Amogh Jahagirdar, Noam Ouaknine, Sercan Karaoglu, Jack Ye, Nicholas Tunney, Sid Sijbrandij, Bob Tordella, and Or Weis.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
deez
deez is a DynamoDB abstraction written in Rust for implementing Single Table Design easily, inspired by ElectroDB.
polai
polai is a new experimental project from AWS Hero Ian Mckay, to help understand the complexity of the Cedar policy language. The project is incomplete and doesn’t feature the automated reasoning guarantees that the official engine has.
clickstream-analytics-on-aws
clickstream-analytics-on-aws is an end-to-end solution to collect, ingest, analyze, and visualise clickstream data inside your web and mobile applications. With this solution, you can quickly configure and deploy a data pipeline that fits your business and technical needs. It provides purpose-built software development kits (SDKs) that automatically collect common events and easy-to-use APIs to report custom events, enabling you to easily send your customers’ clickstream data to the data pipeline in your AWS account. The solution also offers pre-assembled dashboards that visualise key metrics about user lifecycle, including acquisition, engagement, activity, and retention, and adds visibility into user devices and geographies. You can combine user behaviour data with business backend data to create a comprehensive data platform and generate insights that drive business growth.
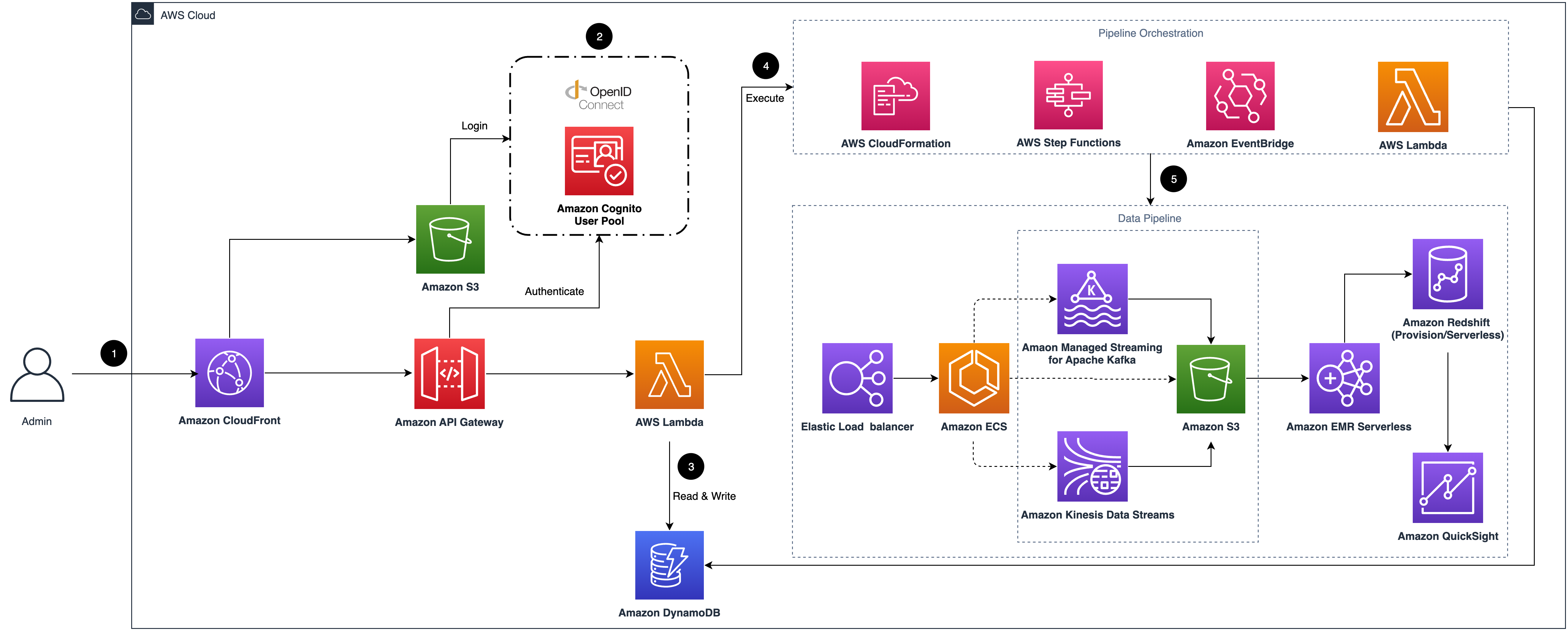
clickstream-android
clickstream-android this repo (Clickstream Android SDK) can help you easily collect and report in-app events from Android devices to AWS. This SDK is part of an AWS solution - Clickstream Analytics on AWS (see previous project), which provisions data pipeline to ingest and process event data into AWS services such as S3, Redshift. The SDK relies on the Amplify for Android SDK Core Library and is developed according to the Amplify Android SDK plug-in specification. In addition, we’ve added features that automatically collect common user events and attributes (e.g., screen view, first open) to simplify data collection for users.
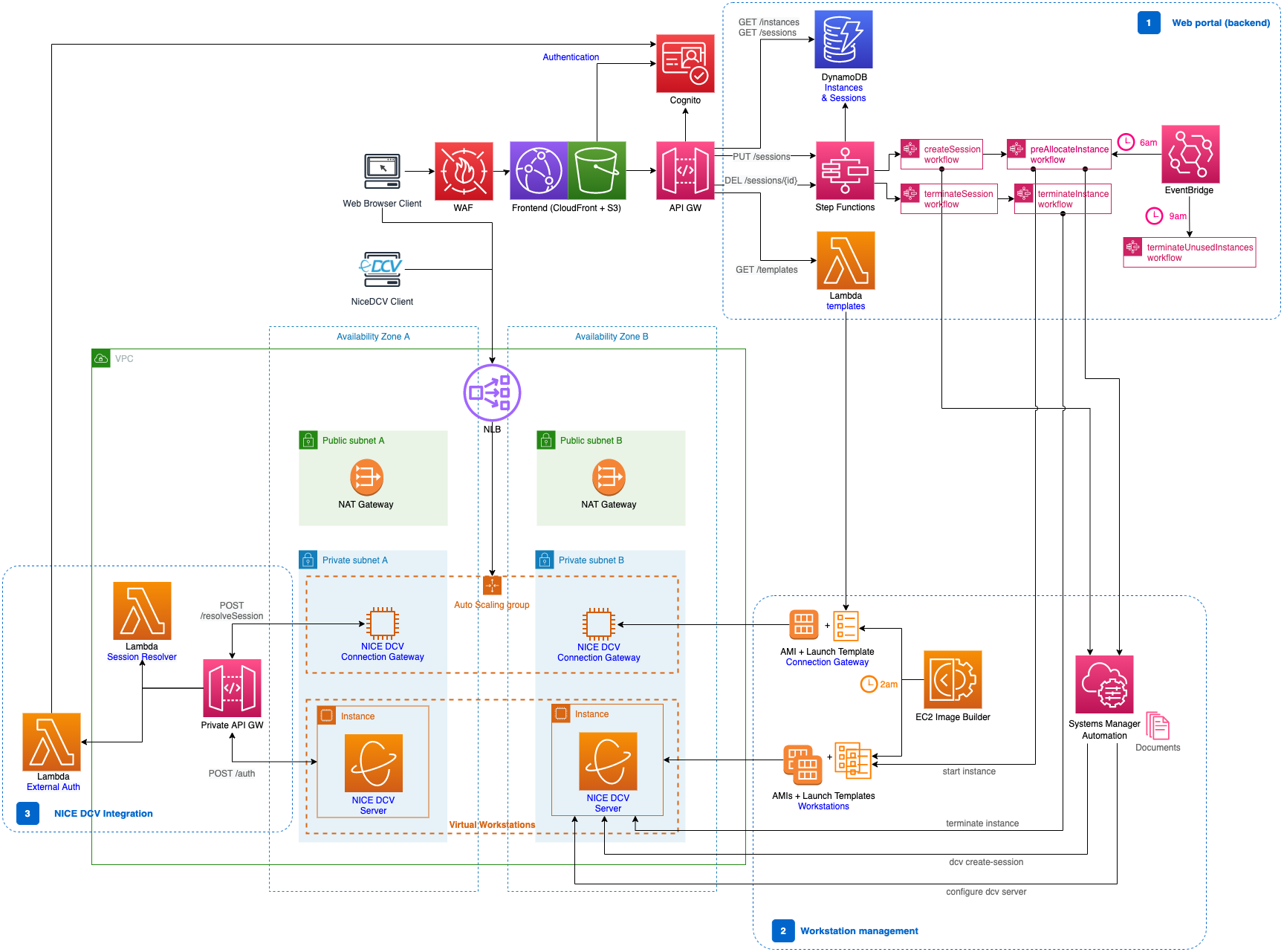
dcv-web-portal
dcv-web-portal The solution leverages the NICE DCV protocol to provide a secure and customisable Virtual Desktop Infrastructure (VDI) deployable in a VPC on an AWS account. This solution also includes a simple and intuitive web portal, that allows users to access their workstation and administrators to provision new workstations and create new sessions.
Demos, Samples, Solutions and Workshops
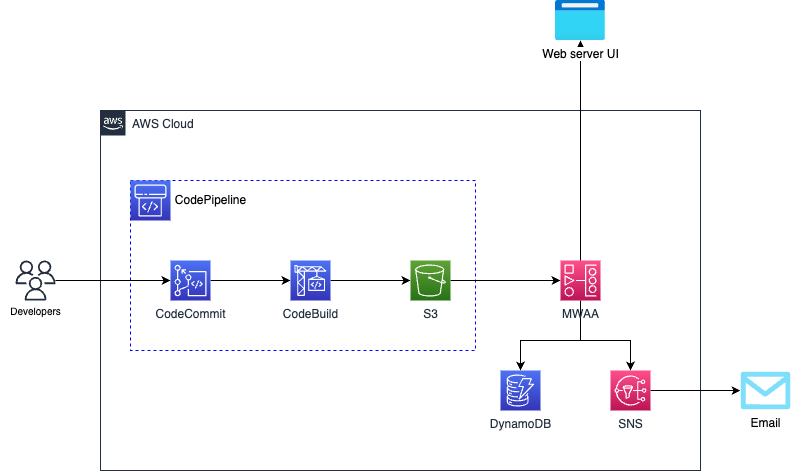
aws-managed-apache-airflow-cicd
aws-managed-apache-airflow-cicd this repo contains code that will help you assemble a simple CI/CD pipeline to help automate your workflow development and deployment to Managed Workflows for Apache Airflow.
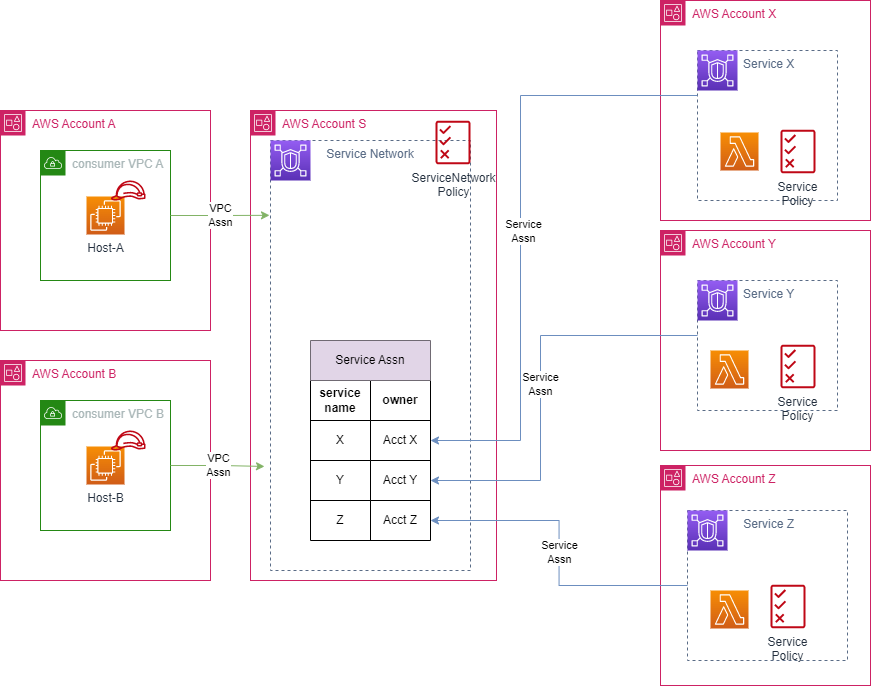
vpclattice-prealpha-demo
vpclattice-prealpha-demo this is an early peek at using vpclattice with cdk from Andrew, better known as mrpackethead. Its a very much in progress piece of work, and there is a 99.99% chance that there will be breaking changes before this goes GA. Please be aware of this, when you use it. It is also an opportunity to provide feedback while the API is solidified. You can read the supporting blog post, vpclattice – the network* when you’re not having a network. with aws cdk.
pytest-lambda-workshop
pytest-lambda-workshop is a new Python based workshop based on a fun and engaging scenario, “Crisis at the Concert”, where you will play the role of an engineer tasked with fixing a malfunctioning concert event management system just before the big event. The concert management system is a Serverless Application Model (SAM) application with features like ticket sales, event scheduling, and artist information. However, it’s currently experiencing various “problems” that need to be addressed. Your goal is to “save the concert” by identifying and fixing these issues using a range of testing and debugging tools.
hybrid-eks-cp-localzone
hybrid-eks-cp-localzone This solution enable you to simplify and centralise the management of your infrastructure and applications on AWS Region and on AWS Local Zones. You can extend the AWS cloud operations experience across hybrid and Local Zones for secure and seamless management, compliance, and observability. AWS Hybrid Cloud Solutions enable you to deliver a consistent AWS experience wherever you need it—from the cloud, to the edge.
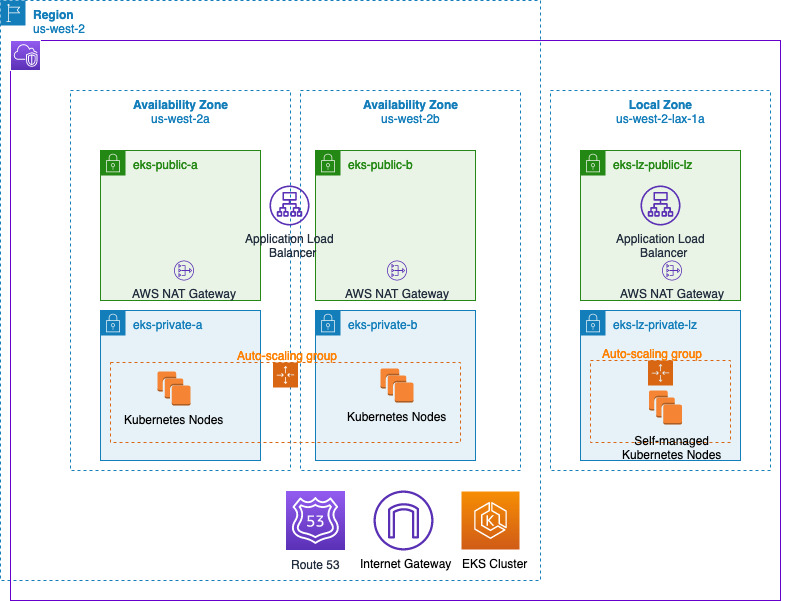
aws-edge-native-nomad
aws-edge-native-nomad this repository helps you to deploy a containerised edge native application, that uses HashiCorp Nomad deployed on AWS
AWS and Community blog posts
Community round up
Cedar is an open source project that I am spending time to learn, and is an open source language you use to define access permissions using policies. There were a couple of great posts that you should check out if you also are checking out this project. First up is AWS Hero Ian Mckay with Cedar: Avoiding the cracks where he shares his experiences in where policy authoring can go wrong, and the steps you can take to overcome these issues. Or Weis from Permit.io put together Everything You Need to Know about AWS’ Cedar Policy Language, where he shares his thoughts on Cedar.
From our friends at Steampipe, Bob Tordella has put together a summary of the changes with the Center for Internet Security (CIS) v2.0 that was recently updated in his post, What’s new in the CIS v2.0 benchmark for AWS. From compliance to code, specifically how you can deploy VS Code on AWS. AWS Community Builder Jimmy Dahlqvist has put together Running VS Code server on AWS, where he shows you everything you need to get your own VS Code Server up and running.
To wrap up this section I wanted to share a post that is something a little different. In a moment where it seems impossible to escape Generative AI, this post AI weights are not open “source”, from Sid Sijbrandij got me thinking about what this space and open source means. Whilst I might not agree with some of the ideas in the post, what I did think was important was surfacing up the open washing that I am seeing a lot of in this space. Let me know your thoughts on this.
Apache Flink
In the post, Migrate from Amazon Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics Studio Nicholas Tunney look at why he recommends moving from Kinesis Data Analytics for SQL Applications to Amazon Kinesis Data Analytics for Apache Flink to take advantage of Apache Flink’s advanced streaming capabilities. [hands on]
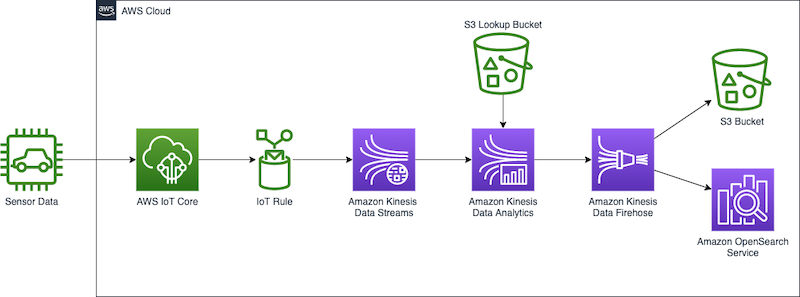
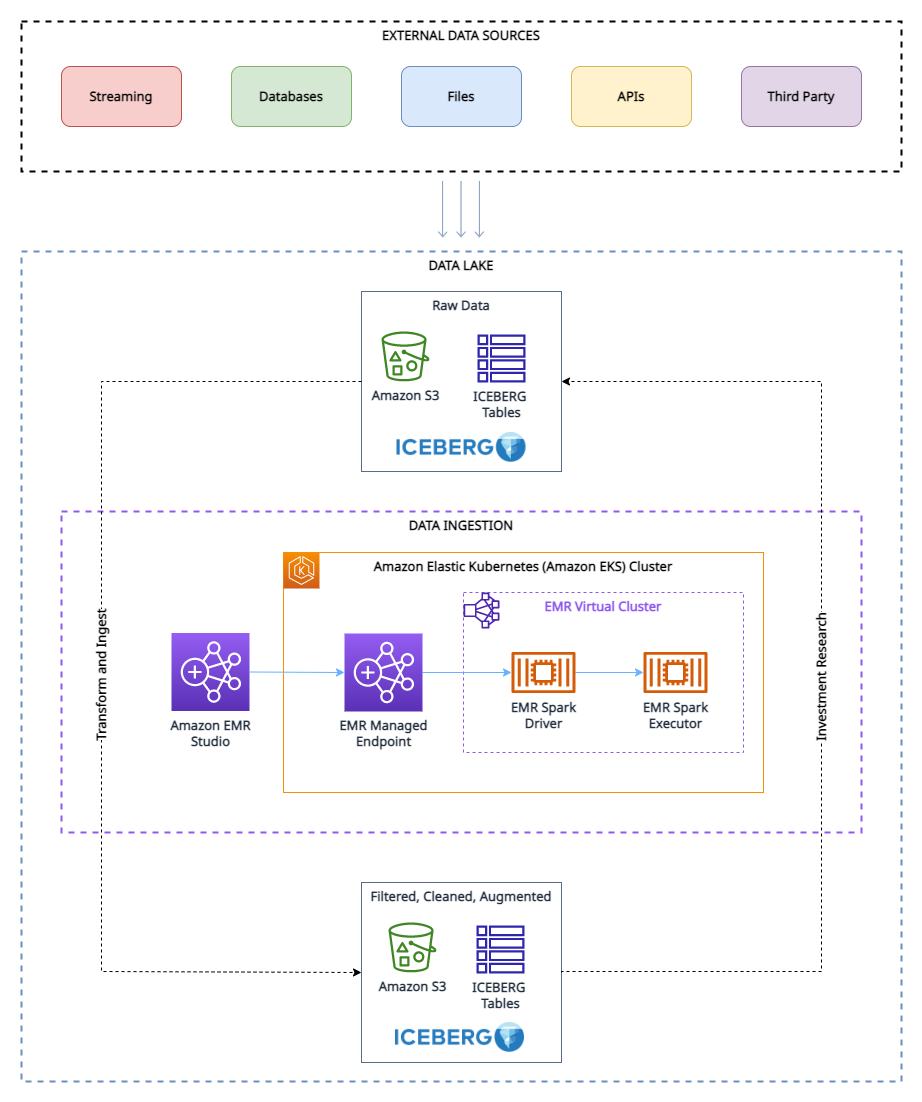
Apache Iceberg
Guy Bachar, Boris Litvin, Amogh Jahagirdar, Noam Ouaknine, Sercan Karaoglu, and Jack Ye have collaborated on a new post, Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg look into the process of using backtesting to evaluate the performance of an index arbitrage profitability strategy. What is that I can hear some of you asking. Well read the post to find out, and I am sure you will thank me after! [hands on]
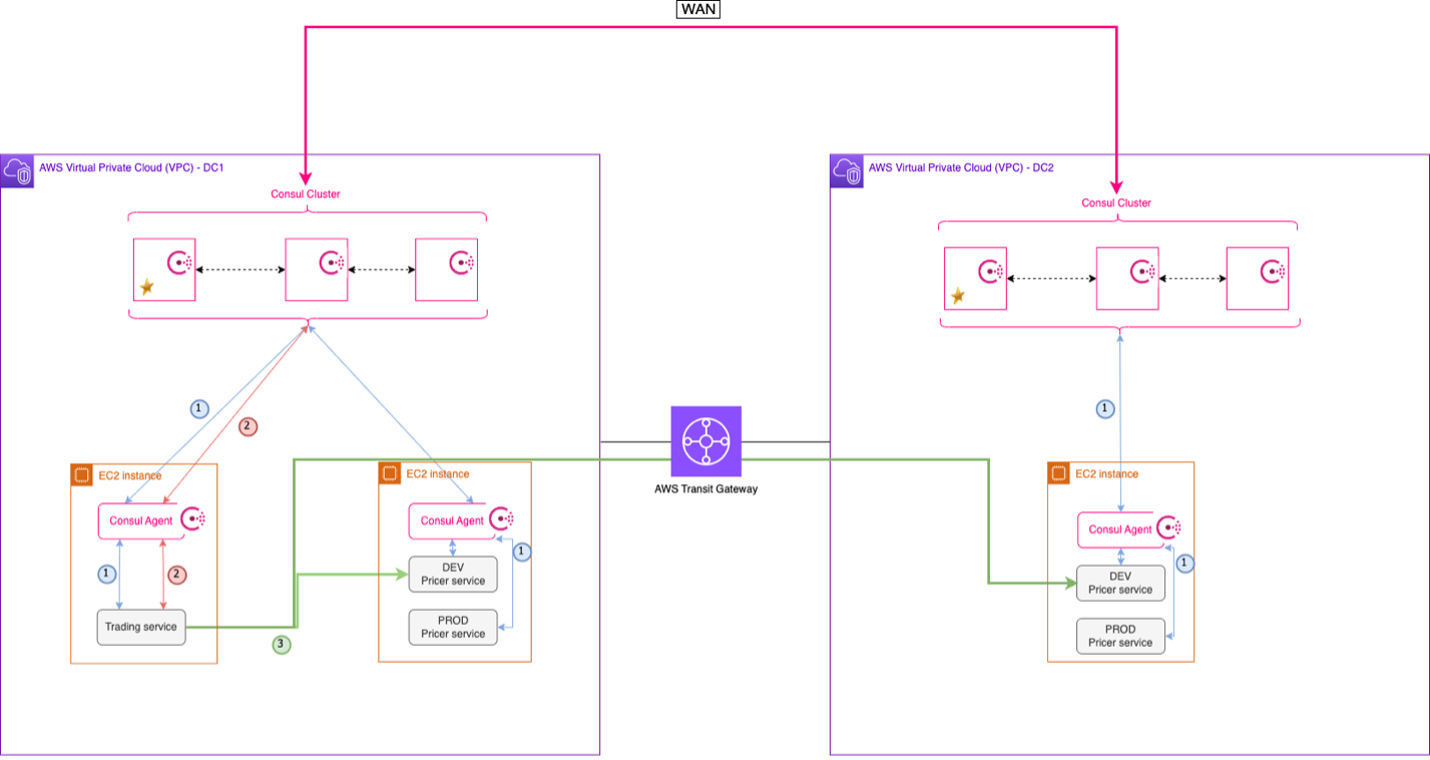
Consul
Consul is an open source distributed, highly available, and data centre aware solution to connect and configure applications across dynamic, distributed infrastructure. In the post, Microservices discovery using Amazon EC2 and HashiCorp Consul, Marine Haddad, Tom Palmer, Tony Phan, and George Agiasoglou demonstrate how you can build a hierarchical service discovery mechanism to support complex globally distributed micro service architectures using a combination of Amazon EC2 service and open source software such as SpringBoot and Consul. [hands on]
Apache Airflow
Great post from one of my favourite AWS services, Amazon Managed Workflows for Apache Airflow (MWAA). John Jackson, Anil Raut, and Nataizya Sikasote have put together Hosting Amazon Managed Workflows for Apache Airflow (MWAA) Local-runner on Amazon ECS Fargate for development and testing that shows you how to configure Amazon MWAA open-source local-runner container image on Amazon ECS Fargate containers to provide a development and testing environment, using Amazon Aurora Serverless v2 as the database backend and execute-command on the AWS Fargate task to interact with the system. Essential reading this week! [hands on]
Other posts and quick reads
- Automate your clusters by creating self-documenting HPC with AWS ParallelCluster is the first in a series of posts covering you how you can use AWS and DevOps with AWS ParallelCluster to automate your HPC infrastructure [hands on]
- Working with accent-insensitive collations with Babelfish for Aurora PostgreSQL provides a hands on post that shows you how to use CI_AI and CS_AI collations on Babelfish for Aurora PostgreSQL, allowing you to keep the support for Latin-based languages or any other language with accents [hands on]
- Retrieving parameters and secrets with Powertools for AWS Lambda (TypeScript) introduces the Powertools for AWS Lambda (TypeScript) Parameters utility and demonstrates how it is used with different parameter stores (SSM Parameter Store, Secrets Manager, AppConfig, DynamoDB, and custom parameter stores) [hands on]
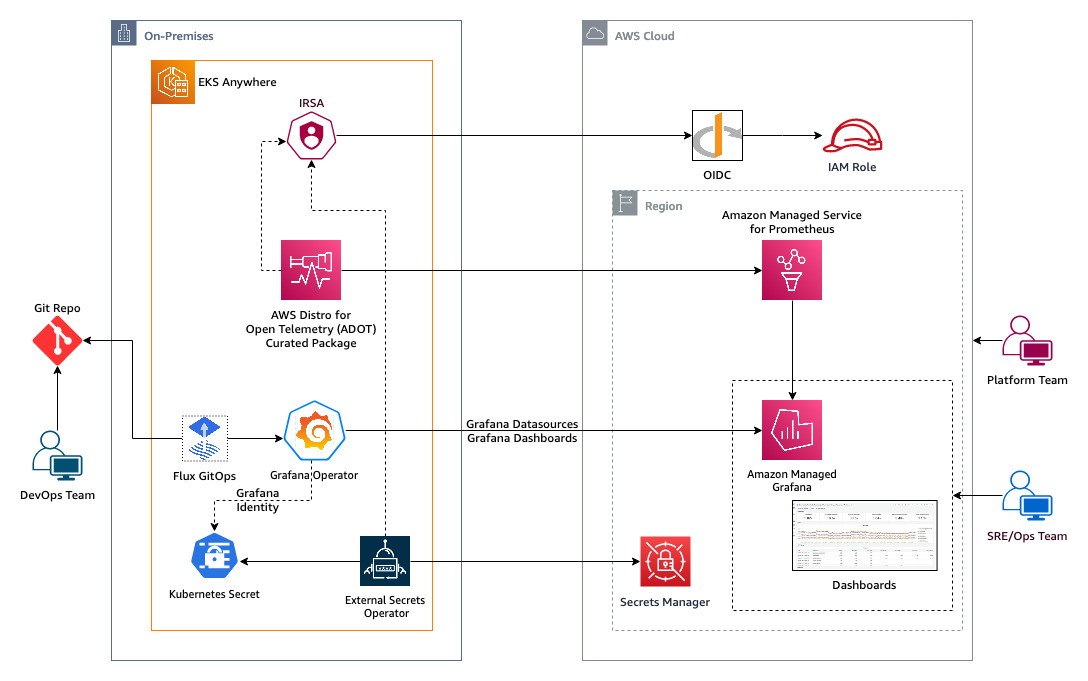
- Using Curated Packages and AWS managed Open Source services to observe your On Premises Kubernetes environment is a must read post that shows you how to use AWS Distro for OpenTelemetry (ADOT) EKS-A curated package, AWS managed open source services and Grafana-operator to observe your on-premises Kubernetes cluster [hands on]
- Client-side Caching Strategies for a Next.js app with AWS Amplify provides a hands on tutorial on how you can add a caching layer using TanStack React Query wrapped around the Amplify GraphQL API to enhance the user experience of the application [hands on]
Case Studies
- How CoStar uses Karpenter to optimize their Amazon EKS Resources looks at how this customer, CoStar were able to use Karpenter to consolidate the Amazon EC2 Spot Capacity they were running in their Dev and Test environments and moved workloads to the lowest cost instance type while still effectively runs their workloads.
Quick updates
AWS Amplify
AWS Amplify Hosting mow supports monorepo frameworks for npm workspaces, Yarn workspaces, pnpm workspaces, Turborepo and Nx. With this release, AWS Amplify Hosting offers fully managed CI/CD deployments and hosting for apps contained within a monorepo (aka monorepository, multi-package repository, multi-project repository, or monolithic repository). In addition to supporting popular monorepo frameworks, AWS Amplify Hosting automatically applies build settings for apps in a npm workspace, Yarn workspace or Nx, enabling zero-configuration deploys.
Kevin Old looks at this in more detail in his post, Share code between Next.js apps with Nx on AWS Amplify Hosting
Mountpoint for Amazon S3
You can now use Mountpoint for Amazon S3 to create new files in Amazon S3. Mountpoint for Amazon S3 is a file client that translates local file system API calls to S3 object API calls like GET and PUT. It is ideal for workloads that read large datasets (terabytes to petabytes in size) and write sequentially to a file from a single process or thread. Common use cases include machine learning training as well as rendering and transcoding in media applications. Mountpoint for Amazon S3 supports sequential and random read operations on existing files, and sequential write operations for creating new files.
Mountpoint for Amazon S3 is an open source project and is available as an alpha release. We have made the alpha release of Mountpoint for Amazon S3 available to the community to collect feedback early and incorporate your input into the design and implementation. We welcome your contributions and your feedback on our roadmap which outlines the plan for adding new capabilities to Mountpoint for Amazon S3.
PostgreSQL
A couple of quick but important updates this week.
Amazon Relational Database Service (Amazon RDS) for PostgreSQL 16 Beta 2 is now available in the Amazon RDS Database Preview Environment, allowing you to evaluate the pre-release of PostgreSQL 16 on Amazon RDS for PostgreSQL. You can deploy PostgreSQL 16 Beta 2 in the Preview Environment that has the benefits of a fully managed database, making it simpler to set up, operate, and monitor databases. PostgreSQL 16 Beta 2 in Preview Environment also includes support for logical decoding on read replicas and over 70 PostgreSQL extensions. The PostgreSQL community released PostgreSQL 16 Beta 2 on June 29, 2023 that enables logical replication from standbys and includes numerous performance improvements. PostgreSQL 16 also adds support for SQL/JSON constructors and identity functions, more query types that can use parallelism, introduction of using SIMD CPU acceleration, and the ‘pg_stat_io’ view that provides statistics on I/O usage.
Following that was news last week that Amazon RDS for PostgreSQL now supports logical replication. With logical replication, you can stream data changes from Amazon RDS for PostgreSQL to other databases for use cases such as data consolidation for analytical applications, change data capture (CDC), replicating select tables rather than the entire database, or for replicating the data between different major versions of PostgreSQL. Amazon RDS for PostgreSQL supports the streaming of data changes using PostgreSQL’s logical replication. You can now set up logical replication to send data from your Amazon RDS for PostgreSQL Multi-AZ deployments with two readable standbys to other data systems, or receive changes from other systems into your Amazon RDS for PostgreSQL Multi-AZ deployments with two readable standbys. In addition to the native PostgreSQL logical replication, Amazon RDS for PostgreSQL Multi-AZ deployments with two readable standbys supports the pglogical and wal2json extensions for streaming changes for use in other systems.
Logical replication for Multi-AZ Deployments with two readable standbys is supported on Amazon RDS for PostgreSQL version 14.8-R2 and higher, and 15.3-R2 and higher.
Kubernetes
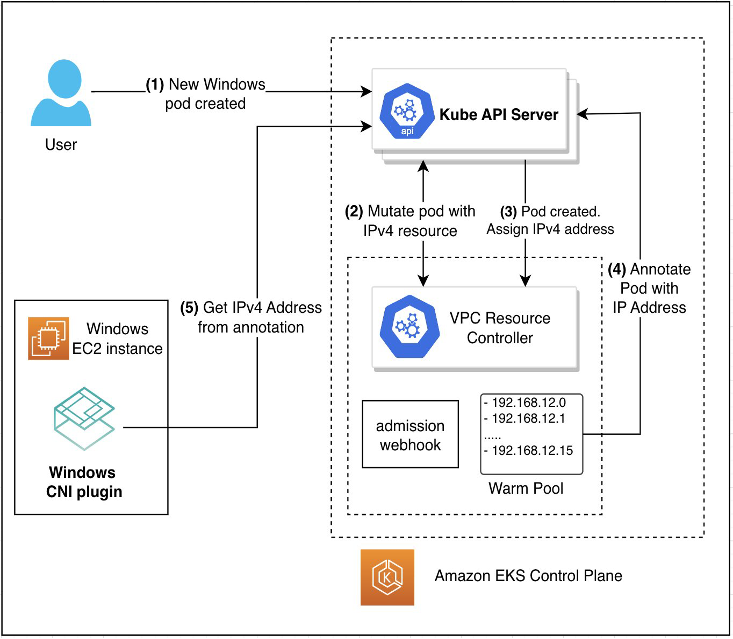
Amazon Elastic Kubernetes Service (EKS) now allows running more pods per windows node using IPv4 prefix delegation mode for Windows containers. Prefix delegation mode expands the number of secondary IPv4 addresses which could be assigned to the Elastic Network Interface (ENI) by up to 16x. With this feature, customers can run up to 250 pods on a single Windows Server node, depending upon the chosen instance type and size. Amazon EKS supports a single ENI per Windows Server node, and with prefix delegation, customers can now assign /28 IPv4 prefixes (or 16 IP addresses), allowing them run up to 16x more Windows pods on a single EKS node.
You can dive deeper by checking out the supporting blog post from Harsh Rawat, Purvi Goyal, and Jie Chen, Increasing pod density for Windows nodes on Amazon EKS.
OpenSearch
Amazon OpenSearch Service now lets you provision up to 16,000 IOPS and 1000 MiB/s throughput for every 3 TiB gp3 volume size provisioned per data node, enabling you to achieve better search and indexing performance. Previously, customers were allowed to provision a maximum of 16,000 IOPS and up to 1000 MiB/s throughput per data node for their gp3 volume type, irrespective of the provisioned volume size. These provisioning limits worked for the majority of workloads. However, a few workloads, especially those with large data volumes or high search traffic, required the ability to provision higher IOPS and throughput to address their performance bottlenecks. Now, you can provision up to 16,000 IOPS and 1000 MiB/s throughput for every 3 TiB volume size provisioned per data node.
OpenZFS
Amazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system, and is designed to deliver sub-millisecond latencies and up to 10 GB/s of throughput along with rich ZFS-powered data management capabilities (like snapshots, data cloning, and compression).
The Amazon FSx for OpenZFS Container Storage Interface (CSI) Driver is now available as an open-source project. The CSI driver makes it easy for developers to use Amazon FSx for OpenZFS with their Kubernetes containers running on Amazon Elastic Kubernetes Service (EKS) or on self-managed Kubernetes clusters running on Amazon EC2. Previously, customers wanting to run stateful workloads on their Kubernetes clusters with FSx for OpenZFS needed to manually provision the file systems, connect them to their Kubernetes pods, and maintain the connection as the service scaled and changed. With the FSx for OpenZFS CSI driver, they can dynamically provision and mount an FSx for OpenZFS file system to containers, so that their containerised workloads can natively access and process data stored in the file system. They can use the CSI driver to mount and share the FSx file system across multiple pods from different nodes.
Apache Parquet
Amazon SageMaker Canvas now supports the Apache Parquet file format, enabling additional file formats for tabular, time-series forecast, and NLP datasets. SageMaker Canvas is a visual interface that enables business analysts to generate accurate ML predictions on their own — without requiring any machine learning experience or having to write a single line of code.
Amazon Linux 2023
Amazon GameLift now supports Amazon Linux 2023 (AL2023), a new Linux-based operating system for AWS that is designed to provide a secure, stable, high-performance environment to develop and run your cloud applications. Amazon GameLift is a fully managed service that allows you to manage and scale dedicated game servers for multiplayer games. With this release, Amazon GameLift now supports new game servers that run on Windows 2016, Amazon Linux 2 (AL2) and AL2023.
Videos of the week
AWS Lambda Power Tools
You want to understand how the Lambda Power Tools team does their Continuous Integration Process? Take a detailed look at this recording from AWS Hero Johannes Koch did together with Heitor Lessa. A must watch episode, with more coming next week.
Where to deploy those Spring Boot Personal Projects
In this video, Dan Vega shows you when, why and how to deploy entire Spring Boot applications to AWS Lambda.
How to deploy LLMs (Large Language Models) as APIs using Hugging Face + AWS
This tutorial from Data Science in Everyday Life goes through how to deploy your own open-source LLM API using Hugging Face on AWS.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
OpenSearchCon Seattle, September 27-29, 2023
Registration is now open source OpenSearchCon. Check out this post from Daryll Swager, Registration for OpenSearchCon 2023 is now open! that provides you with what you can expect, and resources you need to help plan your trip.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen