AWS open source newsletter #161
June 19th, 2023 - Instalment #161
Welcome to #161 of the AWS open source newsletter, and another week for fresh, new open source projects and code for you to practice your four freedoms. This weeks projects include tools that will help you create temporary elevated credentials, a new Java library that provides methods for encrypting and decrypting cryptographic materials, an AWS DynamoDB wrapper for Node/TypeScript developers, and a solution to help you find and visualise data assets. We also have some great demo code that shows you how you can deploy an AWS managed Active Directory, Keycloak, a tool to help automate the creation of transcripts for your prod casts, and a great project that helps you to build continuous deployment pipelines following current good practices.
This weeks newsletter is also filled with lovely content on some of your favourite open source projects, featuring Falcon, Keycloak, Cedar, FreeRTOS, Apache Airflow, Apache Spark, Apache Hudi, Apache Iceberg, and Delta Lake, Apache Flink, OpenChatkit, Pinniped, Kubecost, Karpenter, ONNX, Apache Kafka, Babelfish for Aurora PostgreSQL, AWS Amplify, Next.js, OpenSearch, Flux, ArgoCD, KVM, and more.
I have added a few events that are happening this week and next, so make sure you do not miss those too.
Feedback
Before you dive in however, I need your help! Please please please take 1 minute to complete this short survey and bask in the warmth of having helped improve how we support open source.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: David Krohn, Marcell Jobs, Nicholas Saenz Julienne, Anel Orazgaliyeva, Carlos Santana, Sai Vennam, Suraj Narwade, James McIntyre, Siva Guruvareddiar, Elamaran Shanmugam, Re Alvarez-Parmar, Adam McLean, Ashok Srirama, Hemanth AVS, Giacomo Margaria , Lotfi Mouhib, Hamza Mimi, Vikram Elango, Andrew Smith, Dhawalkumar Patel, Nir Tsruya, and Ankit Gupta, Daniel Arenhage, Kalaiarasu M, Shana Schipers, Ian Meyers, Carlos Rodrigues, Damon Cortesi, Vincent Beck, Tony Smith, Darin McAdams, Daniel Bass, Lee Gilmore, and Johannes Koch.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
iam-identity-center-team
iam-identity-center-team this repository contains the source code for the deploying temporary elevated access management (TEAM) application. TEAM is an open source solution that integrates with AWS IAM Identity Center and allows you to manage and monitor, time-bound elevated access to your multi-account AWS environment at scale. The solution is a custom application that allows users to request access to an AWS account only when it is needed and only for a specific period of time. Once the time period has elapsed, elevated access is automatically removed. Very nice project with great documentation.

aws-cryptographic-material-providers-library-java
aws-cryptographic-material-providers-library-java provides methods for encrypting and decrypting cryptographic materials used in higher level client side encryption libraries. The AWS Cryptographic Material Providers Library abstracts lower level cryptographic materials management of encryption and decryption materials. It uses cryptographic best practices to protect the data keys that protect your data. The data key is protected with a key encryption key called a wrapping key or master key. The encryption method returns the data key and one or more encrypted data keys. Supported libraries use this information to perform envelope encryption. The data key is used to protect your data, and the encrypted data keys are stored alongside your data so you don’t need to keep track of the data keys separately. You can use AWS KMS keys in AWS Key Management Service(AWS KMS) as wrapping keys. The AWS Cryptographic Material Providers Library also provides APIs to define and use wrapping keys from other key providers.
Note The AWS Cryptographic Material Providers Library is released as a developer preview and is subject to change. The current release is not intended to be used in production environments.
tinymo
tinymo is a nice AWS DynamoDB wrapper for Node/TypeScript developers. It simplifies constructing DynamoDB’s JSON-based command inputs within your code, and should make the experience a lot less annoying. Repo has plenty of examples to get you started too.
cdk-aws-ad-connect
cdk-aws-ad-connect from AWS Community Builder and Ambassador David Krohn and Marcell Jobs that makes it easy to deploy and configure an Active Directory Connector using AWS Step Functions.
sensitive-data-protection-on-aws
sensitive-data-protection-on-aws this solution allows enterprise customers to create data catalogs, discover, protect, and visualise sensitive data across multiple AWS accounts. The solution eliminates the need for manual tagging to track sensitive data such as Personal Identifiable Information (PII) and classified information.
Demos, Samples, Solutions and Workshops
cicdonaws-example-projects
cicdonaws-example-projects - AWS Hero Johannes Koch shares with you a new project he is working on that shows you how to implement a simple, end to end CI/CD pipelines that contains all of the steps that follow “best practices”. With the project, Johannes wants to be able to give Builders around the globe the possibility to understand the difference between certain CI/CD tools while at the same time following best practices.
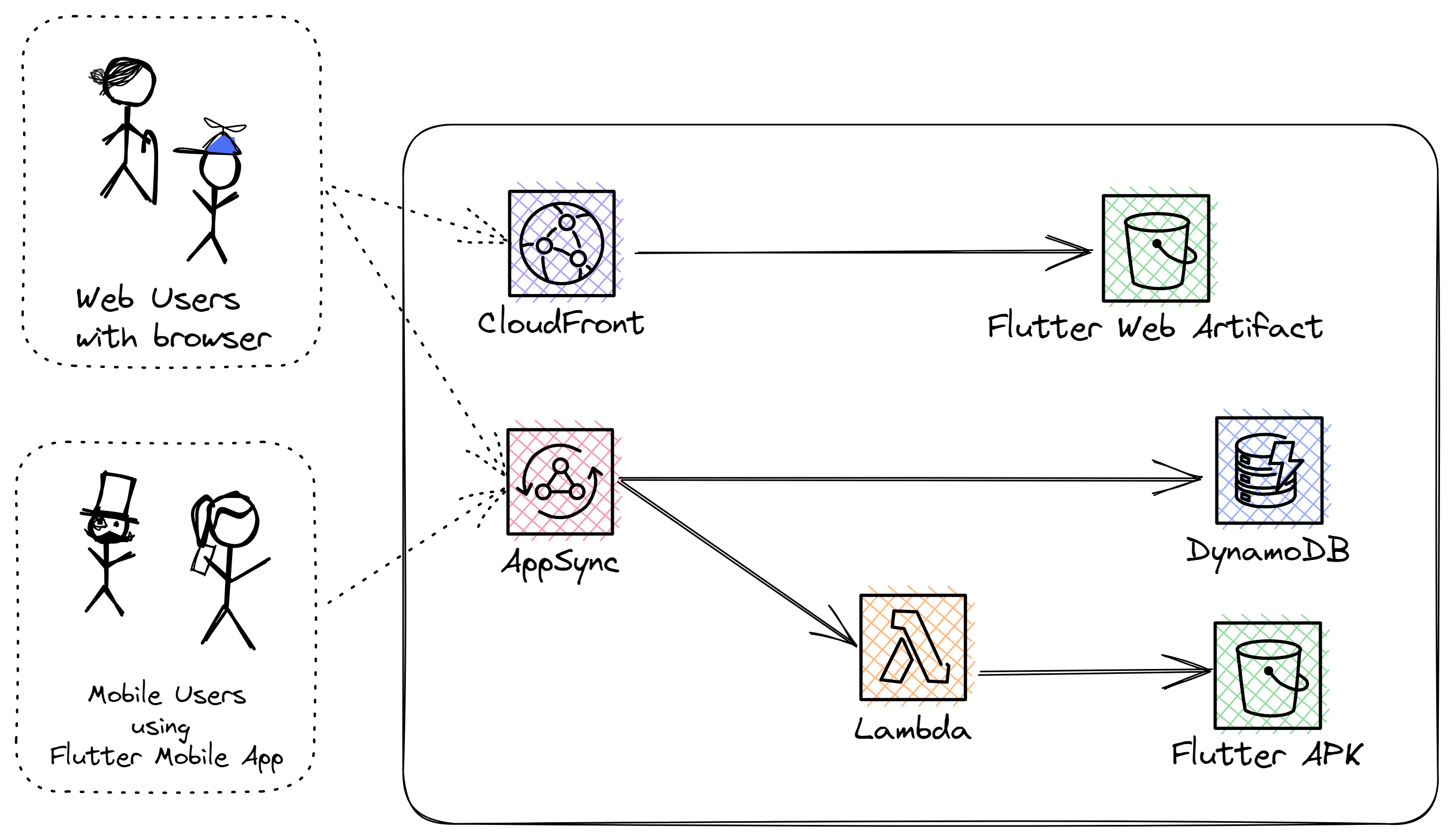
He is looking for feedback on his project, so make sure you check it out. He has also put together a helpful video to walk you through the different components.
active-directory-on-aws-cdk
active-directory-on-aws-cdk this is a sample repo that will help you deploy an AWS managed Active Directory server (with additional supporting resources and configurations) using AWS CDK. I put this together as I could not find one, and I needed it for a demo I am putting together. I also put together a blog post that walks you through using it. Check that out here, Using CDK to deploy AWS managed Active Directory
keycloak-aws
keycloak-aws this repo provides a working example of how you can use the keycloak-cdk construct to deploy a later version of Keycloak. Most of the solutions out there seem to work for versions of Keycloak v16 or older, and I needed to bootstrap a newer version. I put together a post that provides a walk through of how you can use it. Let me know what you think, and read the post here, Integrating Keycloak as my Identity Provider for IAM Identity Centre: Part one, deploying Keycloak on AWS (with a follow on part here)
podwhisperer
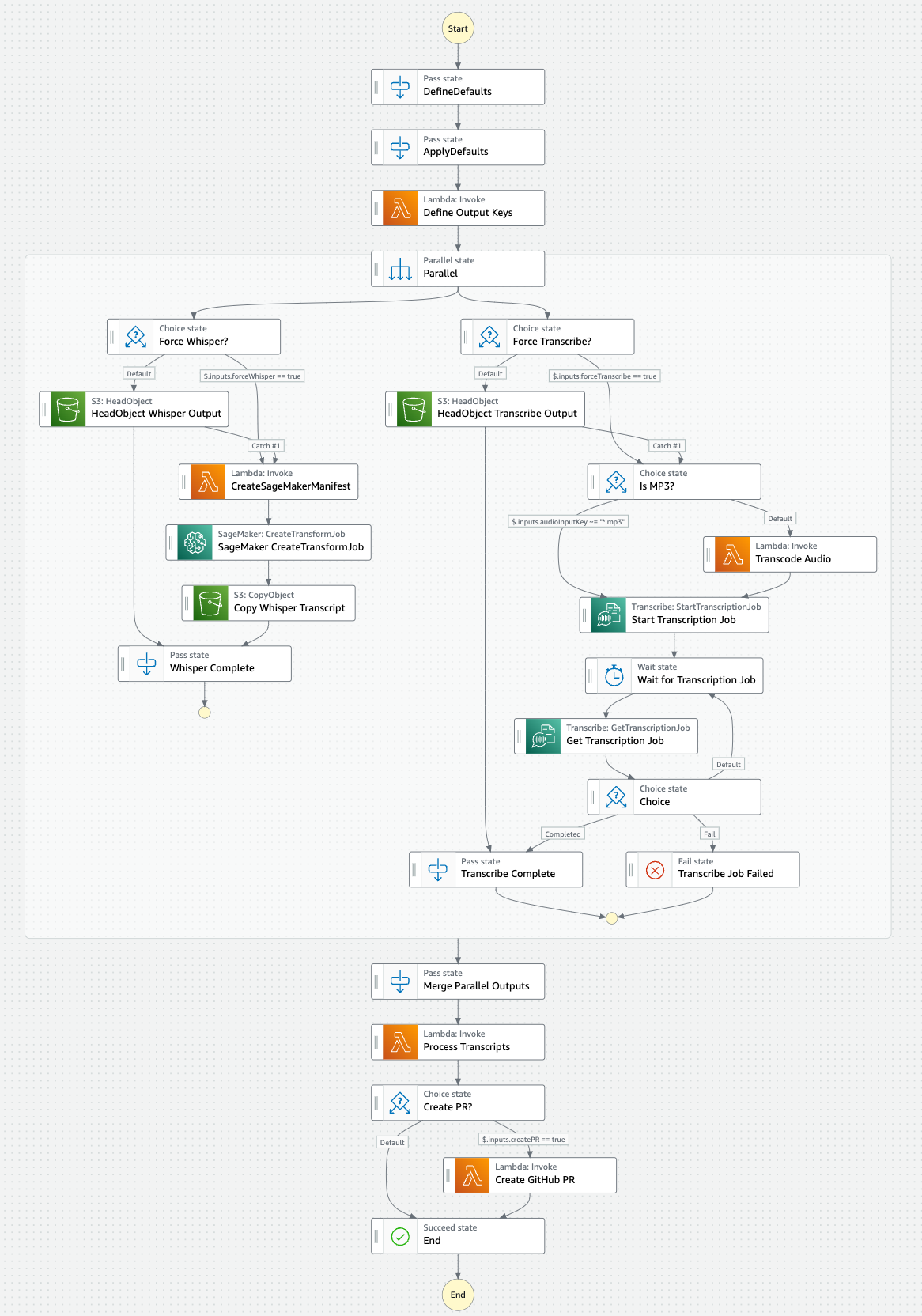
podwhisperer A completely automated podcast audio transcription workflow with super accurate results (according to the developers ;-) This project uses AWS SAM with nested stacks to deploy a number of tools, and the solution uses a number of additional services such as OpenAI Whispher and Amazon Transcribe. Check out the architecture.
Falcon-40B
Falcon-40B this repo provides notebooks that will help know how to host Falcon-40B using DeepSpeed on SageMaker using LMI DLCs. There is an accompanying blog post, Deploy Falcon-40B with large model inference DLCs on Amazon SageMaker that walks you through the process.
Serverless-AWS-CDK-Best-Practices-Patterns-Part-4
Serverless-AWS-CDK-Best-Practices-Patterns-Part-4 Lee Gilmore provides an example of creating immutable builds using the AWS CDK and progressing them through environments to production using CDK Pipelines. There is an accompanying blog post series that dives deeper into the code which you can check out. Here is the fourth instalment, Serverless AWS CDK Pipeline Best Practices & Patterns — Part 4, but make sure you check out the others.
Bonus
Lee has also put together videos from parts one and two of the series, so check them out here.
Part One
Part Two
AWS and Community blog posts
Community roundup
I love exploring the many and varied posts that the community creates, and last week there was so many great that I enjoyed reading. Kicking off with an open source project I am spending time getting to know, Cedar. Open Source is all about scratching that itch, and Darin McAdams posted Why was Cedar created? and explores why Cedar was created. Keeping with the Cedar theme, Daniel Bass has put together a very nice post, Implementing Role-Based Access Control (RBAC) with AWS’ Cedar, that provides a nice overview of how (and why) should you implement Role Based Access Control (RBAC) using the Cedar policy engine.
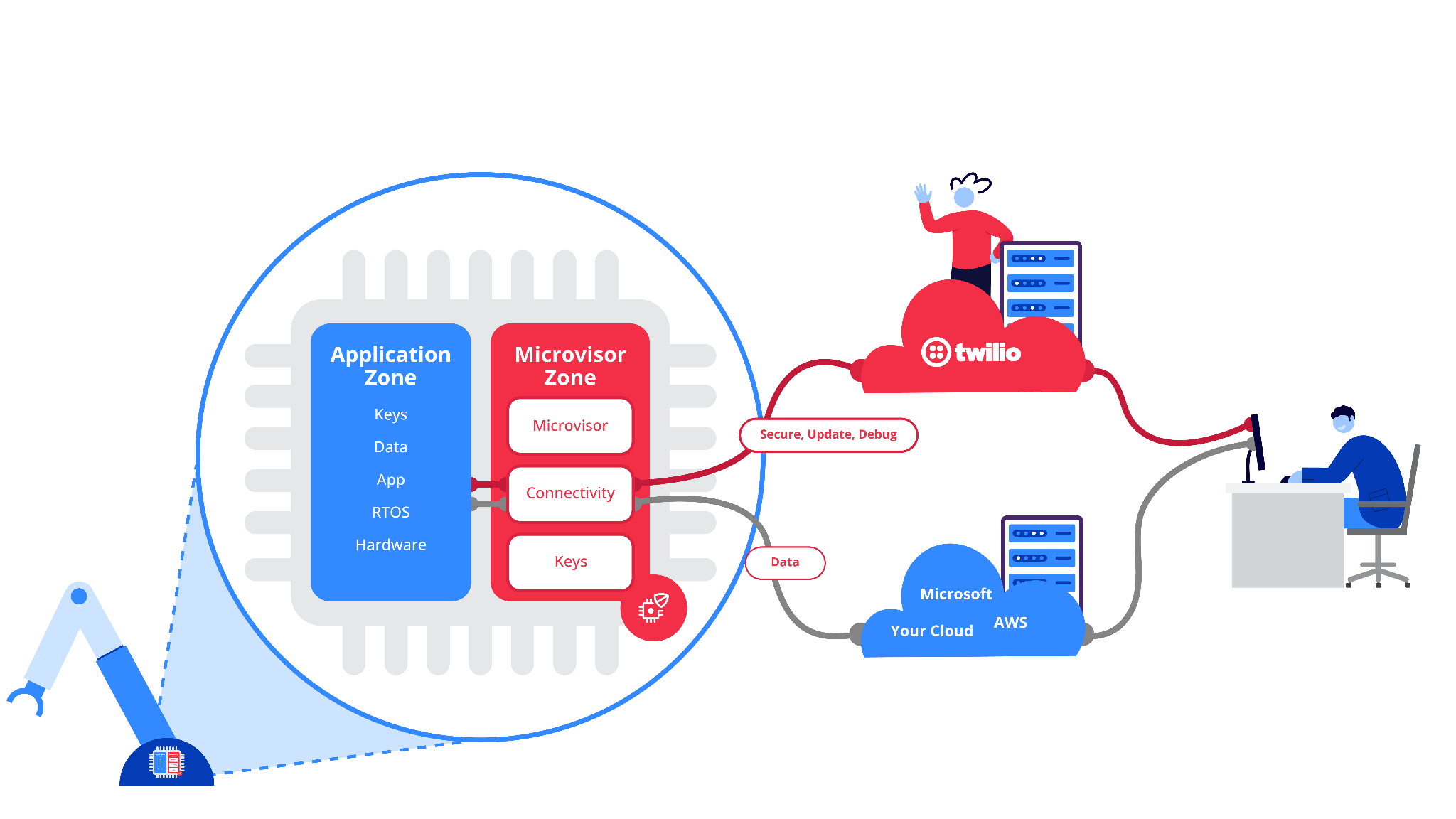
I love hacking around with various IoT devices, and have various ESP32 and other devices lying around so I was super interested in reading Tony Smith’s post, Achieving Unbrickable MCU FOTA for your FreeRTOS-powered Firmware: The Microvisor IoT Approach showing how you can use Twilio Microvisor together with FreeRTOS to reduce the risk of bricking devices during over-the-air (OTA) updates.
If you are using Managed Workflows for Apache Airflow (MWAA) and integrating it with AWS Secrets manager, then this post, Setting up AWS secrets backends with Airflow in a cost-effective way, is an essential read from Vincent Beck. The post dives deep into how the integration works, and takes a look at how you can optimise your costs. On a related note, if you missed How Apache Airflow Better Manages Machine Learning Pipelines that was published on The New Stack last week, then check it out as it speaks with a number of the AWS folks working upstream in the Apache Airflow community to help improve the Apache Airflow user experience.
Apache Spark
Damon Cortesi has put together a very nice post, Deploy Serverless Spark Jobs to AWS Using GitHub Actions, that shows how to deploy an end-to-end Spark ETL pipeline to Amazon EMR Serverless with GitHub Actions.
Apache Hudi, Apache Iceberg, and Delta Lake
Apache Hudi, Apache Iceberg, and Delta Lake are open-source transactional table formats (or open table formats) can help you solve advanced use cases around performance, cost, governance, and privacy in your data lakes. In the post, Choosing an open table format for your transactional data lake on AWS Shana Schipers, Ian Meyers, and Carlos Rodrigues provide a super helpful guide shows how open-source transactional table formats (or open table formats) can help you solve advanced use cases around performance, cost, governance, and privacy in your data lakes. These table format each have their own unique strengths for specific requirements, so it is important to determine which requirements and use cases are most crucial and select the table format that best meets those needs. This post helps you with that, so an essential read this week.
Apache Flink
In the post, How Klarna Bank AB built real-time decision-making with Amazon Kinesis Data Analytics for Apache Flink Nir Tsruya from Klarna Bank AB, and Ankit Gupta, and Daniel Arenhage from AWS look at a reference architecture for real-time queries and decision-making on AWS using Amazon Kinesis Data Analytics for Apache Flink, and looks at why the Klarna Decision Tooling team selected Apache Flink for their first real-time decision query service.
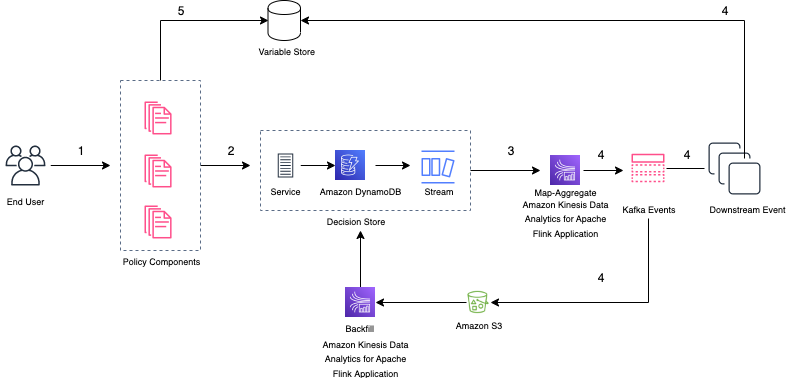
A late addition to the newsletter was this post from data engineer Kalaiarasu M who wrote, RealTime Data Processing — Integrate Kafka with Flink To S3 that explores how to leverage Apache Flink and Python to push data to Amazon S3, where you have an Apache Kafka data source. [hands on]
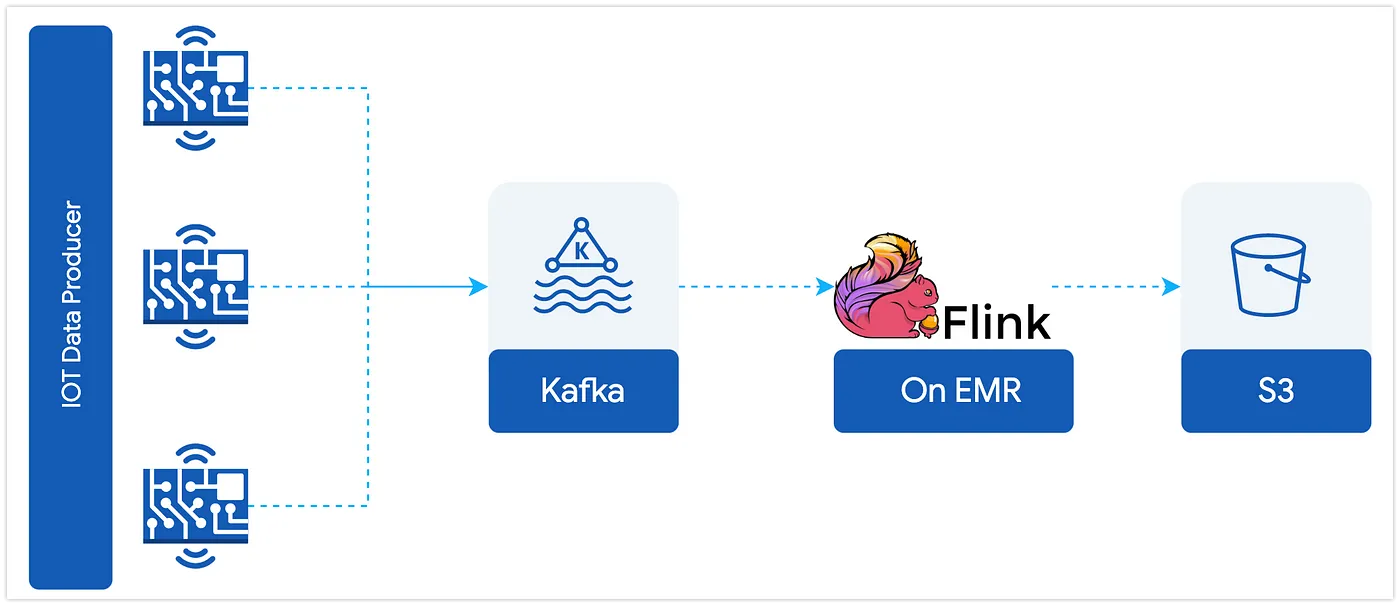
OpenChatkit
OpenChatKit is an open-source LLM used to build general-purpose and specialised chatbot applications, released by Together Computer under the Apache-2.0 license. Vikram Elango, Andrew Smith, and Dhawalkumar Patel have collaborated on the post, Build custom chatbot applications using OpenChatkit models on Amazon SageMaker that looks at the importance of open-source LLMs and provides a hands on guide on how to deploy an OpenChatKit model on SageMaker to build next-generation chatbot applications. They look at how you can deploy OpenChatKit models (GPT-NeoXT-Chat-Base-20B and GPT-JT-Moderation-6B) models on Amazon SageMaker using DJL Serving and open-source model parallel libraries like DeepSpeed and Hugging Face Accelerate. [hands on]
Kubernetes
We had lots of great posts this week on Kubernetes. So diving straight in, we had Ashok Srirama and Hemanth AVS show you how to streamline Amazon EKS multi-cluster authentication using Pinniped and Okta as an identity provider in their post, Simplify Amazon EKS Multi-Cluster Authentication with Open Source Pinniped [hands on]
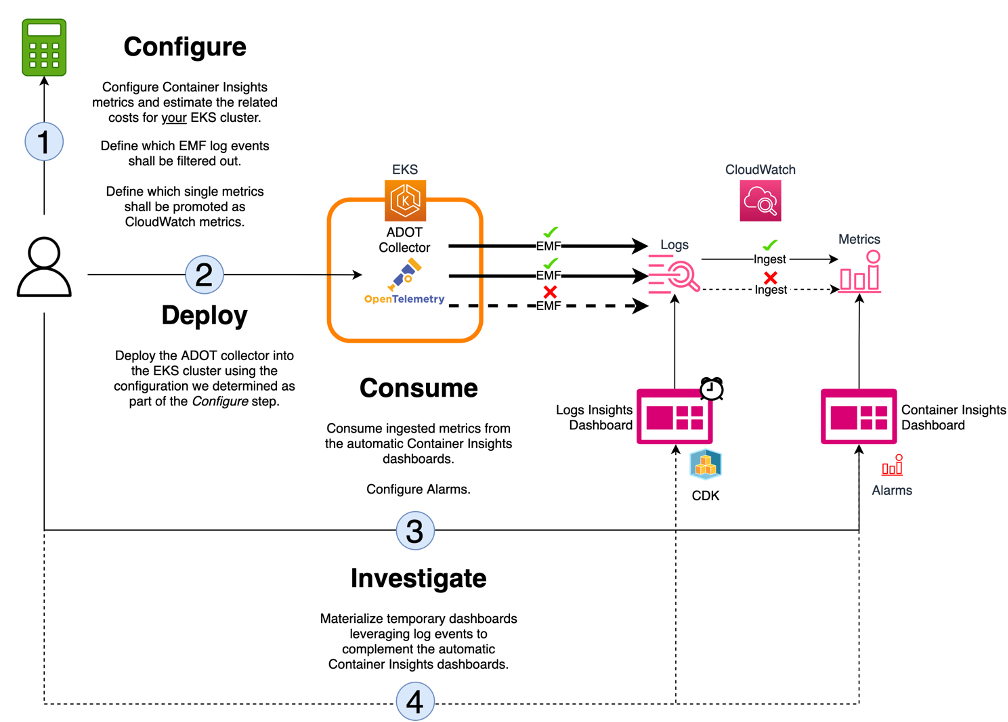
Next up we had Giacomo Margaria who put together, Diving into Container Insights cost optimizations for Amazon EKS who provides a super detailed post that shows you how to configure, deploy, consume, and investigate Container Insights metrics to significantly optimise the associated ownership costs.
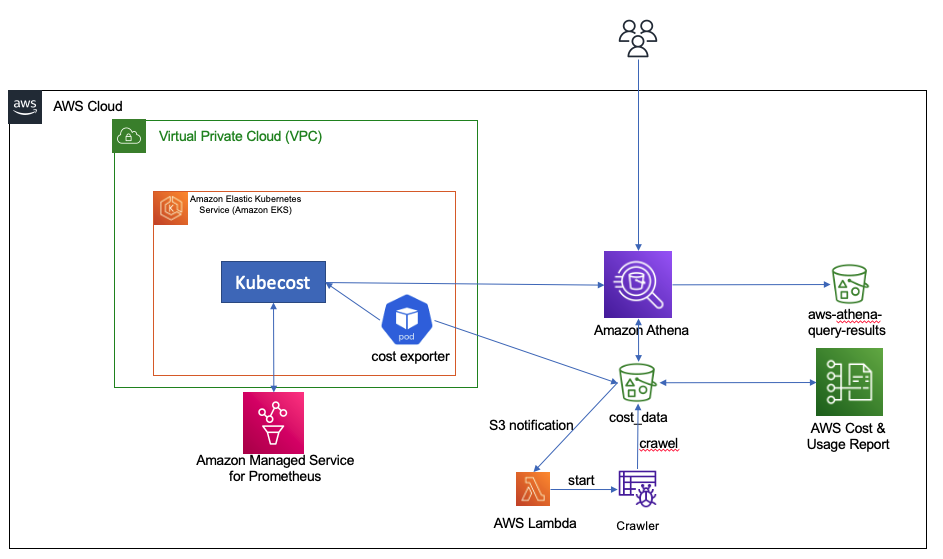
On a similar note, we had Cost monitoring for Amazon EMR on Amazon EKS where Lotfi Mouhib and Hamza Mimi present a cost chargeback solution for EMR on EKS that combines the AWS-native capabilities of AWS Cost and Usage Reports (AWS CUR) alongside the in-depth Kubernetes cost visibility and insights using Kubecost on Amazon EKS.
From cost to storage with Choosing the right storage for cloud native CI/CD on Amazon Elastic Kubernetes Service, where Adam McLean shares his approach for selecting the right storage for a Cloud Native CI/CD system powered by Amazon EKS.
Finally, to wrap up this weeks Kubernetes content we have this post, Simulating Kubernetes-workload AZ failures with AWS Fault Injection Simulator where Siva Guruvareddiar, Elamaran Shanmugam, and Re Alvarez-Parmar show you how to use an AWS FIS to simulate an AZ failure for Kubernetes workloads, and in the process also show how Karpenter performs better and recovers quicker from network disrupt connectivity than Cluster Autoscaler.

Open Source machine learning and AI
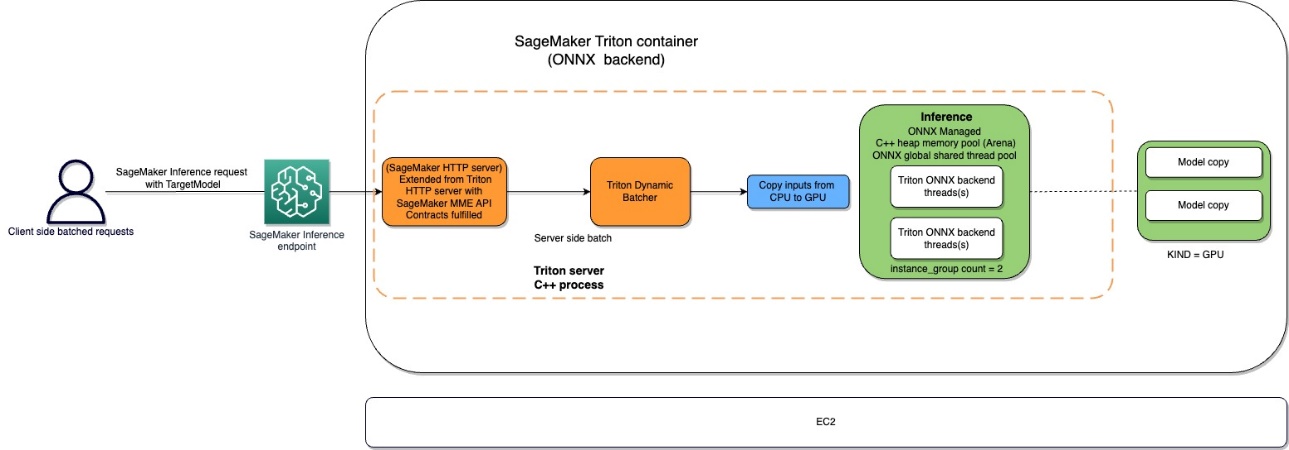
- Host ML models on Amazon SageMaker using Triton: ONNX Models showcases how to deploy ONNX-based models for multi-model endpoints (MMEs) that use GPUs [hands on]
- Get started with the open-source Amazon SageMaker Distribution show you how you can use the SageMaker open-source distribution to quickly experiment on your local environment and easily promote them to jobs on SageMaker, training an image classification model using PyTorch [hands on]
Other posts and quick reads
- Best practices for running production workloads using Amazon MSK tiered storage is a follow up to a previously shared post, and focuses on how to properly size your MSK tiered storage cluster, which metrics to monitor, and the best practices to consider when running a production workload [hands on]

-
Migrate your SQL Server database to Babelfish for Aurora PostgreSQL using the Bulk Copy Program utility explores an alternative option for data migration using the Bulk Copy Program (bcp) utility that looks beyond the traditional approaches of using AWS DMS, SSIS, or customised scripts [hands on]
-
Federate Amazon QuickSight access with open-source identity provider Keycloak is a nice, detailed walk through of the steps you need to configure federated single sign-on (SSO) between QuickSight and open-source IdP Keycloak demonstrating ways to to assign QuickSight roles based on Keycloak membership [hands on]
-
Next.js API Routes with AWS Amplify explains what Next.js API routes are and how they can simplify your stack, speed up development, and provide an optimized API experience – all from directly within your Next.js app [hand on]
-
5 Next.js features that are better with AWS Amplify looks at five Next.js features that are enhanced by AWS Amplify
Quick updates
OpenSearch
A couple of important updates this week.
First up was news that OpenSearch 2.8 is now here. James McIntyre shared all the details in his post, OpenSearch 2.8 is here!. This release brings a host of new features and enhancements and experimental functionality including new tools for machine learning, search, and observability workloads and several enhancements to better manage your indexes and data.
OpenSearch now has a performance benchmarking page. This page displays the results of ongoing performance testing for recent and upcoming versions of the OpenSearch software. You can view key performance metrics across different workloads with the dashboard visualisations below.
Apache Spark
Amazon Athena for Apache Spark is a feature of Amazon Athena lets you run interactive analytics on Apache Spark in under a second to analyse petabytes of data.
Amazon Athena for Apache Spark now allows you to use your own Java libraries and customise the Spark configurations for your Spark workloads. You can use Java libraries as custom JARs with Athena Spark to analyse data from multiple sources or use functions in custom jars for more flexibility with calculations.
Amazon Athena for Apache Spark now supports open-source data lake storage frameworks Apache Hudi 0.13, Apache Iceberg 1.2.1, and Linux Foundation Delta Lake 2.0.2. These frameworks simplify incremental data processing of large data sets using ACID (atomicity, consistency, isolation, durability) transactions and make it simpler to store and process large data sets in your data lakes.
kubectl-eks
kubectl-eks this project from AWS Community Builder Suraj Narwade, was featured in a previous newsletter last year ( #125 ) had a new release last week (v.0.3.0). Check the docs for the changes and new features added.
AWS Neuron
AWS Neuron is the SDK used to run deep learning workloads on AWS Inferentia and AWS Trainium based instances, and includes a deep learning compiler, runtime, and tools that are natively integrated into TensorFlow, PyTorch and Apache MXNet (incubating). 2.11.0 released last week. This release introduces Neuron Distributed, a new python library to simplify training and inference of large models, improving usability with features like S3 model caching, standalone profiler tool, support for Ubuntu22, as well as other new features, performance optimisations, minor enhancements and bug fixes. Check out the full release notes for all the good stuff.
Videos of the week
GitOps with Amazon EKS Workshop | Flux and ArgoCD
Carlos Santana and Sai Vennam provide an interactive walk through of automation module of the updated Amazon EKS workshop, specifically introducing concepts like GitOps and then looking at open source tools like Flux and ArgoCD.
KVM Forum 2023
Check out this video from KVM Forum where Nicholas Saenz Julienne and Anel Orazgaliyeva from AWS talk about porting and upstreaming the Virtual Secure Mode (VSM) implementation (which is the core feature needed to support Credential Guard) that’s part of the Nitro Hypervisor to the Linux kernel.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (sixteen) of the episodes of the Build on Open Source show. Build on Open Source playlist.
We are currently planning the third series - if you have an open source project you want to talk about, get in touch and we might be able to feature your project in future episodes of Build on Open Source.
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Build On Live | Open Source ML Online, June 22nd at 8am - 1pm PST
Join the second Build On Live Event of 2023: Build On Live | Open Source ML! The Developer Advocate hosts will be chatting with expert guests about various top of mind topics from the open source and machine learning worlds. By tuning into this event you can expect to learn about key areas like: building applications & tools using AI, how to use AI to boost your productivity, how to use AI responsibly, & much more.
Watch live on YouTube or Twitch, check out the full agenda and links to the show over at Build On Live | Open Source ML - Jump on the Generative AI Bandwagon!
Live AWS and Apache Hudi Workshop Online, June 22nd at 8am PST
Nadine Farah and Soumil S are teaming up to deliver a live workshop that will mimic a typical use case, in this instance, building near real time dashboards for a fictional ride sharing company.
.jpg)
Make sure you reserve your place by going to the registration page, Live AWS and Apache Hudi Workshop: Build a ride share lakehouse platform
Apache Kafka London Sainsbury’s HQ, 33 Holborn, London EC4A1AA, 26th June 2023 5.45 - 8:30 pm
OSO are teaming up with Sainsbury’s, special sponsor for this event, to deliver an exciting program of talks that include AWS Community Builder John Mille whose talk, Kafka enterprise strategy to evolve with demand, will go over insights of early days, lessons learnt and successful governance patterns which made the onboarding smoother as time went. He will also review the different tooling involved in making this journey successful not only for business but for developers, along with leveraging Kafka community driven projects such as Kafka Connect.
If you are about and want to learn more about Apache Kafka, there is nothing better than attending a user group. Head over to the meetup page and sign up: IN-PERSON: Kafka Enterprise Strategies: Best Practices
CNCF Maintainer Circle - Community Management June 28th, 2023 @ 10:00am PT / 17:00 UTC
Managing a project is hard work. Maintainers are expected to wear many hats. Defining those hats early on can help a project grow and ultimately be sustainable enough to not rely on a few maintainers to do it all. Let’s deep dive in one role around - community and contributor management.
In this session, we will discuss strategies on how to build out strategy around intentional community roles, groups, and more so you aren’t doing everything. What’s everything?
- Creating, maintaining, and moderating mailing lists, slacks, forums, and more
- Recruiting and onboarding new contributors: outreach, their documentation, workflows, and processes
- Maintaining current contributors: swag, recognition programs, events, and more
- Social media
- User adoption strategies and operations
- Governance operations
- Website updates
- Documentation
Sounds interesting and very useful right? Check out more and add this to your calendar by checking out the event page
Yocto Project Developer Day 2023 EOSS, Prague, Czech Republic, Mon, Jun 26, 8 AM - 4 PM
The Yocto Project DevDay is a technical conference for engineers, open source technologists, students and academia in the OSS space. This 1-day event is where individuals will learn about Yocto Projects’ direction – including, but not limited to, new releases, development tools, features – get training on the next wave of embedded Linux technologies (segment previously known as Yocto Project Developer Day), and network with their industry peers, Yocto Project maintainers, OpenEmbedded maintainers and experts.
Check out more here and if you are going to be in Prague, why not pop along…after registering of course!
Amplify Your Ideas: Hack, Host, and Share with Hashnode & AWS July 1st — July 31, 2023
This hackathon presents an opportunity for you to quickly transform your ideas into reality, easily build and ship feature-rich, fullstack apps using AWS Amplify, and share your experience on Hashnode. Prizes and complete details on how to participate will be announced on June 26th. Register now for early notifications.
CDK Day, 2023 Online, 29th September 2023
Back for the fourth instalment, this Community led event is a must attend for anyone working with infrastructure as code using the AWS Cloud Development Kit (CDK). It is intended to provide learning opportunities for all users of the CDK and related libraries. The CFP is open, so if you have some ideas for some talks then make sure you check that section out. Also, this year they are accepting talks in Espanol! Woohoo, love it!
Check more at the website, CDK Day
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen