AWS open source newsletter #158
May 30th, 2023 - Instalment #158
Welcome
Hello and welcome to the AWS open source newsletter, #158. I hope some of you were able to catch the last episode of season two of Build on Open Source where we looked at some of the projects featured in this newsletter (specctl, eksdemo, and ec2-spot-placement-score-tracker). As always we pride ourself on this newsletter on giving you the newest, shiniest open source projects and this week we have some really great ones to share with you. “specctl” provides a tool to help you deploy resources between ECS and Kubernetes, “eksdemo” might be the simplest way to try out Amazon EKS, “cookiecutter-serverless-python” is a new tool to help you scaffold serverless applications using good practices, “cdk-aws-app-runner-scheduler” is a nice tool to help schedule container workloads running on AppRunner, “ec2-spot-placement-score-tracker” helps you track and predict AWS Spot prices and instance availability, and many more projects so make sure you check them all out.
We also have content this week covering projects including Apache Iceberg, Apache Airflow, Spinnaker, OpenTelemetry, Apache HBase, Terraform, MySQL, PostgreSQL, AWS Amplify, AWS CDK, AWS ParallelCluster, Amazon Corretto, Micronaut, OpenSearch, Faker, and more.
Make sure you check out the events section, as there are a couple of events coming up over the next few weeks that you do not want to miss out on. Before diving into the newsletter, please take a few minutes to read the next couple of items (thank you!)
OpenUK Survey
OpenUK have been running an annual survey for a number of years now, collecting data and then producing and sharing reports that are widely cited. They are looking for more folk to respond, so please take a few minutes to complete the survey and provide your feedback on the state of open source in the UK.
Read more and find the link to the survey over at, State of Open: The UK 2023 Survey
SLSA
SLSA is a set of incrementally adoptable guidelines that helps you work towards greater security in your software supply chain. It is gaining in interest and adoption, and I am would love to hear from folk who have started working towards SLSA certification levels. Please contact me via ricsue@amazon.com if you would be willing to share what you have found so far. I am looking to put some content together in the near future, so if you would like to collaborate on that, please get in touch.
Feedback
Please please please take 1 minute to complete this short survey and bask in the warmth of having helped improve how we support open source.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: David Venable, Damon Cortesi, Will Dady, Ran Isenberg, Sheetal Joshi, Leah Tucker, Jonathan Katz, Aditya Samant, Adam Levin, Mickael Derriey, Praseeda Sathaye, Fernando Freire, Puneet Singh, Avijit Goswami, Prashant Singh, Rajarshi Sarkar, Rushabh Lokhande, Vishwa Gupta, Ryan Gomes, Ramesh Kumar Venkatraman and Neha Gupta
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
cookiecutter-serverless-python
cookiecutter-serverless-python is the latest project from AWS Community Builder Ran Isenberg. This project can serve as a cookiecutter template for new Serverless services - CDK deployment code, pipeline and handler are covered with best practices built in. After installing the tool using pip, you are provided with a guided cli experiences before the tool helpfully setups up all the resources you need. Great stuff, so be sure to check this out.
cdk-aws-app-runner-scheduler
cdk-aws-app-runner-scheduler is a new project from Will Dady that provides a reference AWS CDK application for scheduling the pausing and resuming of AWS App Runner services. Useful for dev environments where you want to pause AWS App Runner services out-of-hours to save money. Very cool and useful indeed!
specctl
specctl is a command-line based tool to extract and transform Kubernetes objects to ECS and vice versa. It has two modes, -m k2e (default) convert Kubernetes to ECS and -m e2k for ECS to Kubernetes. Currently, only ECS Fargate is supported. For Kubernetes to ECS conversion, specctl can read and convert Kubernetes objects either from Kubernetes YAML specification files or from Kubernetes clusters. The tool uses Terraform to create all the necessary AWS resources needed to run services and tasks on ECS. For ECS to Kubernetes, specctl can read and convert ECS and related AWS objects from an AWS account where the ECS cluster is running. Once the Kubernetes YAML specifications are generated, you can simply use kubectl on the generated spec.
Check out the docs to find out more about what resources are translated, a look at all the command options, and how you can get started. Very cool tool, and something I will be sure to be trying out very soon.
faker-cli
faker-cli is the latest tool from colleague Damon Cortesi that helps you quickly generate JSON or CSV “test” data. You can use predefined templates (for example S3 Access or Cloudfront format data) or specify your own. The tool uses Faker under the covers.
volume-modifier-for-k8s
volume-modifier-for-k8s this repo provides a sidecar deployed alongside CSI drivers to enable volume modification through annotations on the PVC.
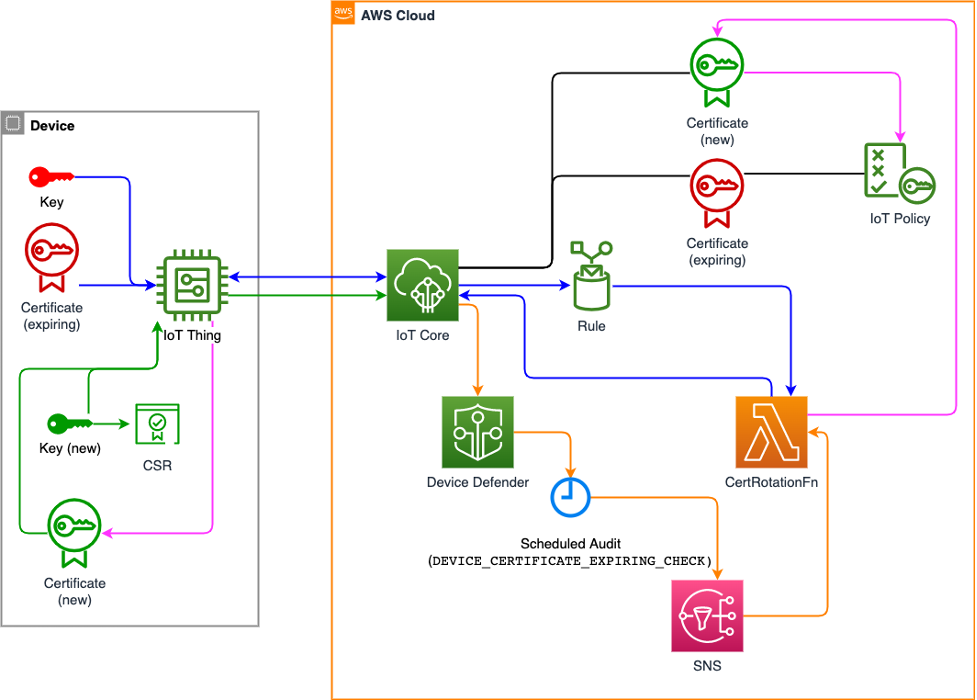
aws-greengrass-labs-certificate-rotator
aws-greengrass-labs-certificate-rotator this repo provides a Greengrass component and companion cloud backend for rotating the core device certificate and private key. Device certificate and private key rotation is a security best practice defined in the IoT Lens for the AWS Well-Architected Framework. At the time of writing however, AWS IoT does not offer a device certificate rotation service or feature. It’s left to customers and application builders to implement both the device software and the cloud backend to achieve device certificate rotation. This repo will help you address that. Check out the blog post, How to manage IoT device certificate rotation using AWS IoT that helps you walk through this solution.
sagemaker-distribution
sagemaker-distribution is a set of Docker images that include popular frameworks for machine learning, data science and visualisation. T hese images come in two variants, CPU and GPU, and include deep learning frameworks like PyTorch, TensorFlow and Keras; popular Python packages like numpy, scikit-learn and pandas; and IDEs like Jupyter Lab. The distribution contains the latest versions of all these packages such that they are mutually compatible. If you use Conda, then you can use these directly so no need for Docker - check the README for how you can do that.
amazon-codeguru-jupyterlab-extension
amazon-codeguru-jupyterlab-extension is an Amazon CodeGuru extension for JupyterLab and SageMaker Studio. This extension runs scans on your notebook files and provides security recommendations and quality improvements to your code.
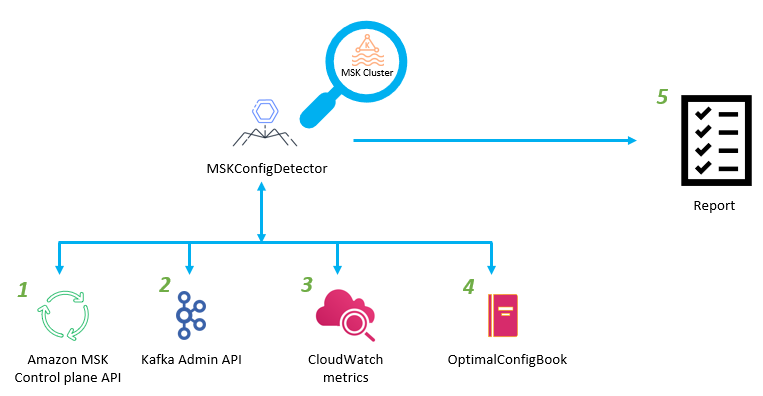
amazon-msk-config-detector
amazon-msk-config-detector is a tool that analyses your Kafka cluster configuration and makes recommendations based on the instance type, storage configuration and topic configuration. Using Amazon MSK best practices guideline, the tool clearly indicates which configuration changes are necessary, taking into account factors such as instance type, local storage, tiered storage, segment size and retention period of your Kafka cluster running with Amazon Managed Streaming for Apache Kafka (MSK). Additionally, the tool can detect storage and partition imbalances on your cluster, and provide specific recommendations for correcting these imbalances.
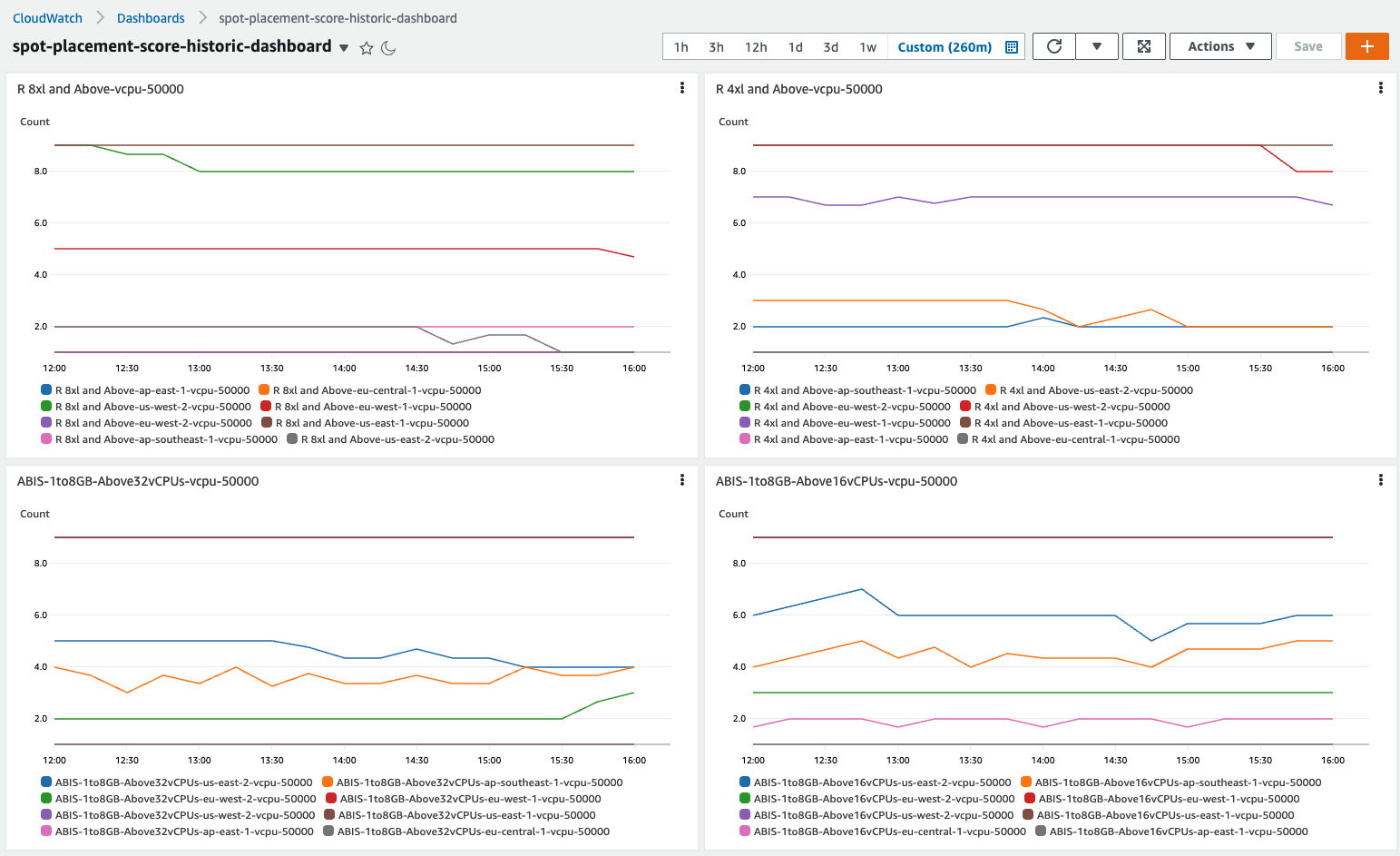
ec2-spot-placement-score-tracker
ec2-spot-placement-score-tracker This project automates the capture of Spot Placement Scores and stores SPS metrics in CloudWatch. Historic metrics can be then be visualised using CloudWatch Dashboards. CloudWatch can also be used to trigger Alarms and automation of events such as moving your workload to a region where capacity is available. Spot can be used to optimize the scale, cost and execution time of Workloads such as Containers (K8s, EKS, ECS, etc), Loosely coupled HPC and high throughput computing (AWS Batch, Parallel Cluster), Data & Analytics using Spark, Flink, Presto, CICD, Rendering, and in general any workload that is retryable, scalable and stateless.
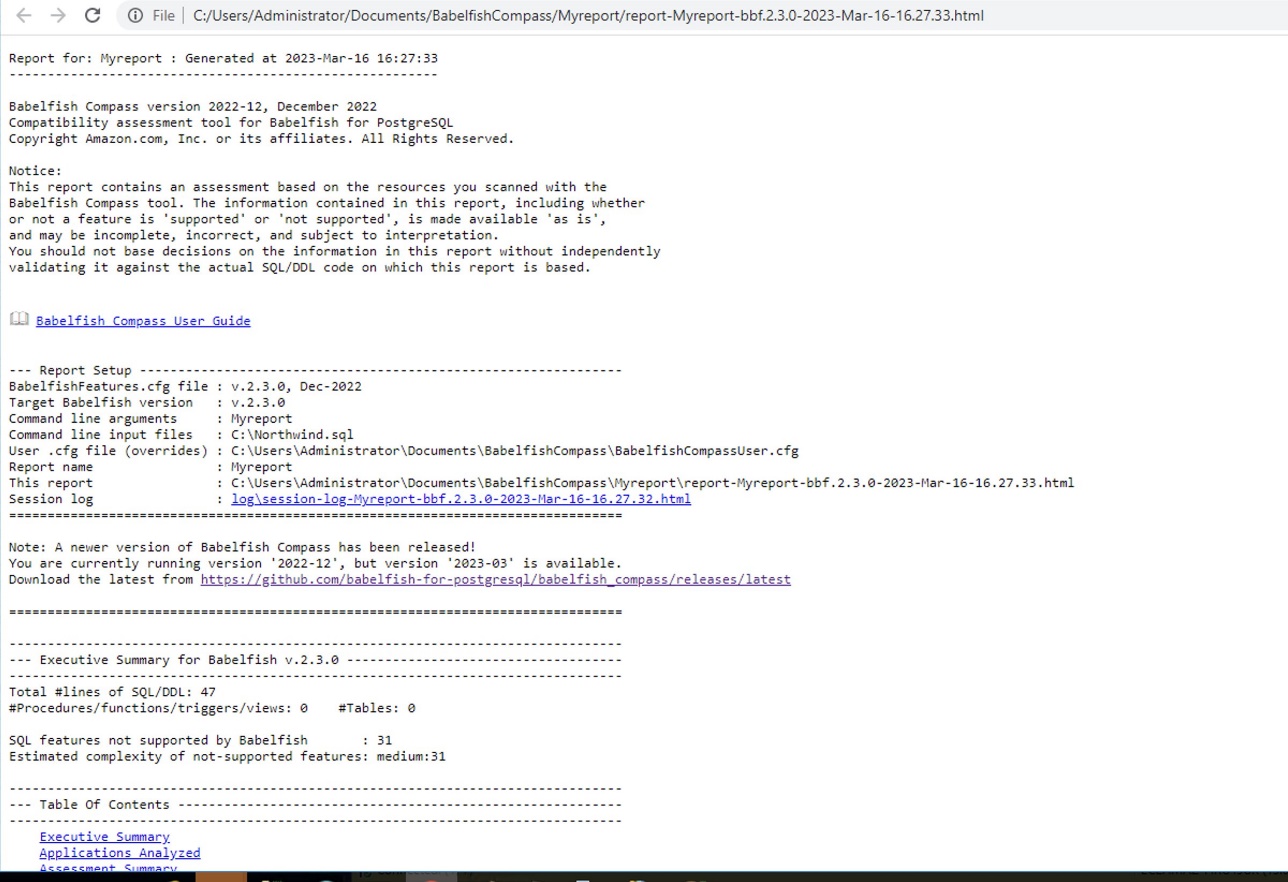
babelfish_compass
babelfish_compass is a compatibility assessment tool for Babelfish for PostgreSQL. With Babelfish Compass, users can quickly analyse T-SQL DDL/SQL scripts for compatibility with Babelfish. Babelfish Compass identifies the SQL features that aren’t supported by the current version of Babelfish and creates an assessment report on the SQL/DDL. The purpose of such analysis is to inform a go/no-go decision about whether it makes sense to consider starting a migration project from SQL Server to Babelfish and to estimate the efforts required for the migration. The README provides some information on how you can get started, including a YT video. You can also check out this new blog post, Deep dive into Babelfish Compass where Ramesh Kumar Venkatraman and Neha Gupta walk you through using the tool.
LightGPT
LightGPT is an open source (Apache 2.0) language model based on the awesome EleutherAI/GPT-J-6B (Apache 2.0). LightGPT was instruction fine-tuned on the OIG-small-chip2 dataset (Apache 2.0). The repo provides details on how you can quickly get this up and running on Amazon SageMaker.
Demos, Samples, Solutions and Workshops
aws-batch-operational-dashboards
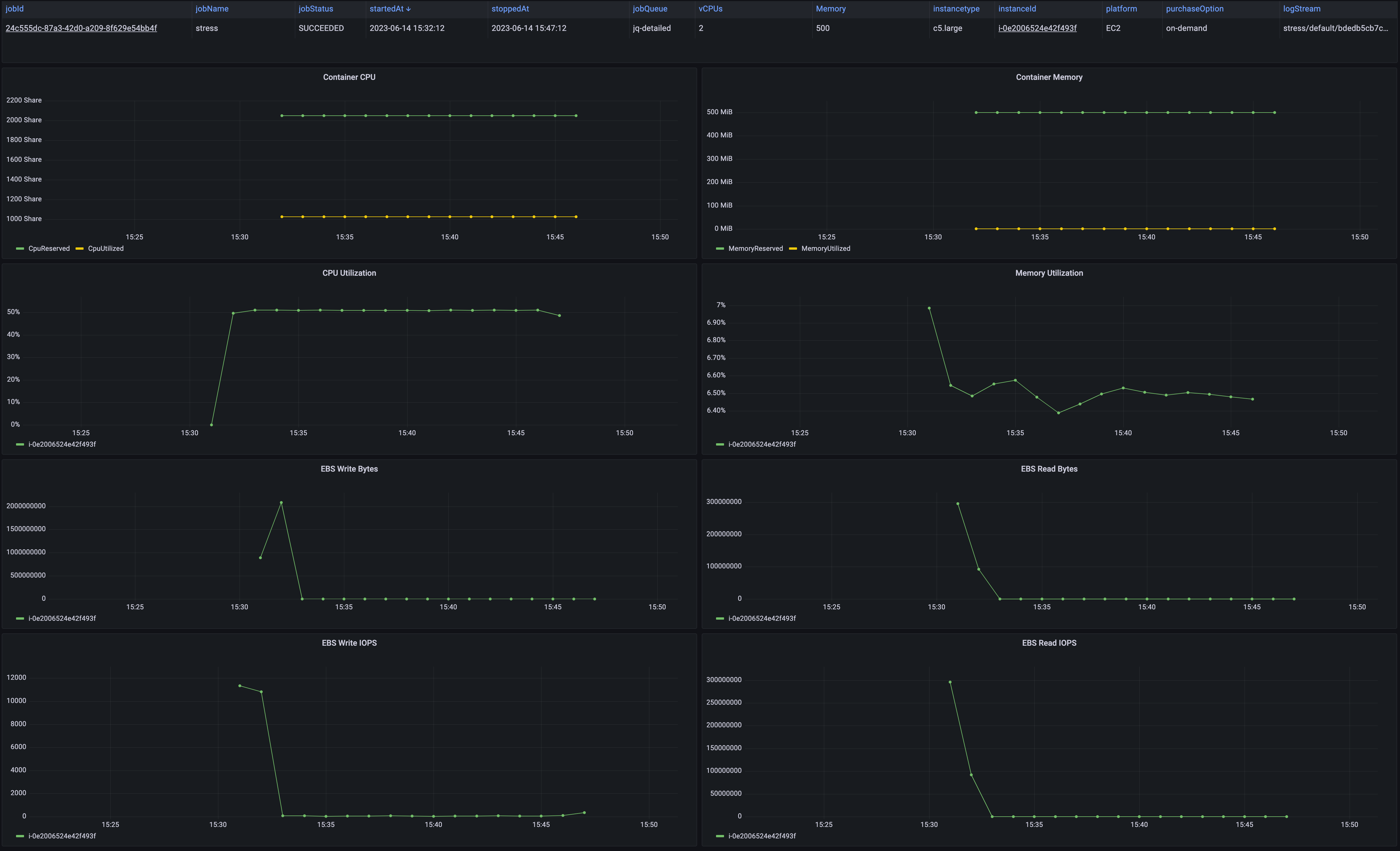
aws-batch-operational-dashboards provides a code sample to deploy a solution to show Amazon EC2 resources and Container resource usage by AWS Batch jobs. This solution relies on a serverless architecture to create a Grafana dashboard to visualise compute and memory resources usage by AWS Batch jobs. It provides better insights at the jobs level on how Amazon EC2 resources are used.
This application is designed to be scalable by collecting data from events and API calls using Amazon EventBrige and does not make API calls to describe your resources. Data collected through events and API are partially aggregated to DynamoDB to recoup information and generate Amazon CloudWatch metrics with the Embedded Metric Format. The application also deploys a several of dashboards displaying the job states, Amazon EC2 instances belonging your Amazon ECS Clusters (AWS Batch Compute Environments), ASGs across Availability Zones.
eksdemo
eksdemo this repo is perfect for anyone wanting to get started with Kubernetes on AWS. It provides an easy button for learning, testing, and demoing Amazon EKS. Here are some of the features from the README:
- Install complex applications and dependencies with a single command
- Extensive application catalog (over 50 CNCF, open source and related projects)
- Customise application installs easily with simple command line flags
- Query and search AWS resources with over 60 kubectl-like get commands
redshift-roles
redshift-roles this repo contains scripts, SQL, and Stored Procedures that are useful in using and adopting the use of using ROLE for security access in Redshift.
AWS and Community blog posts
Apache Iceberg
In Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes, Avijit Goswami, Prashant Singh, and Rajarshi Sarkar show you how to improve operational efficiencies of your Apache Iceberg tables built on Amazon S3 data lake and Amazon EMR big data platform. [hands on]
Apache Airflow
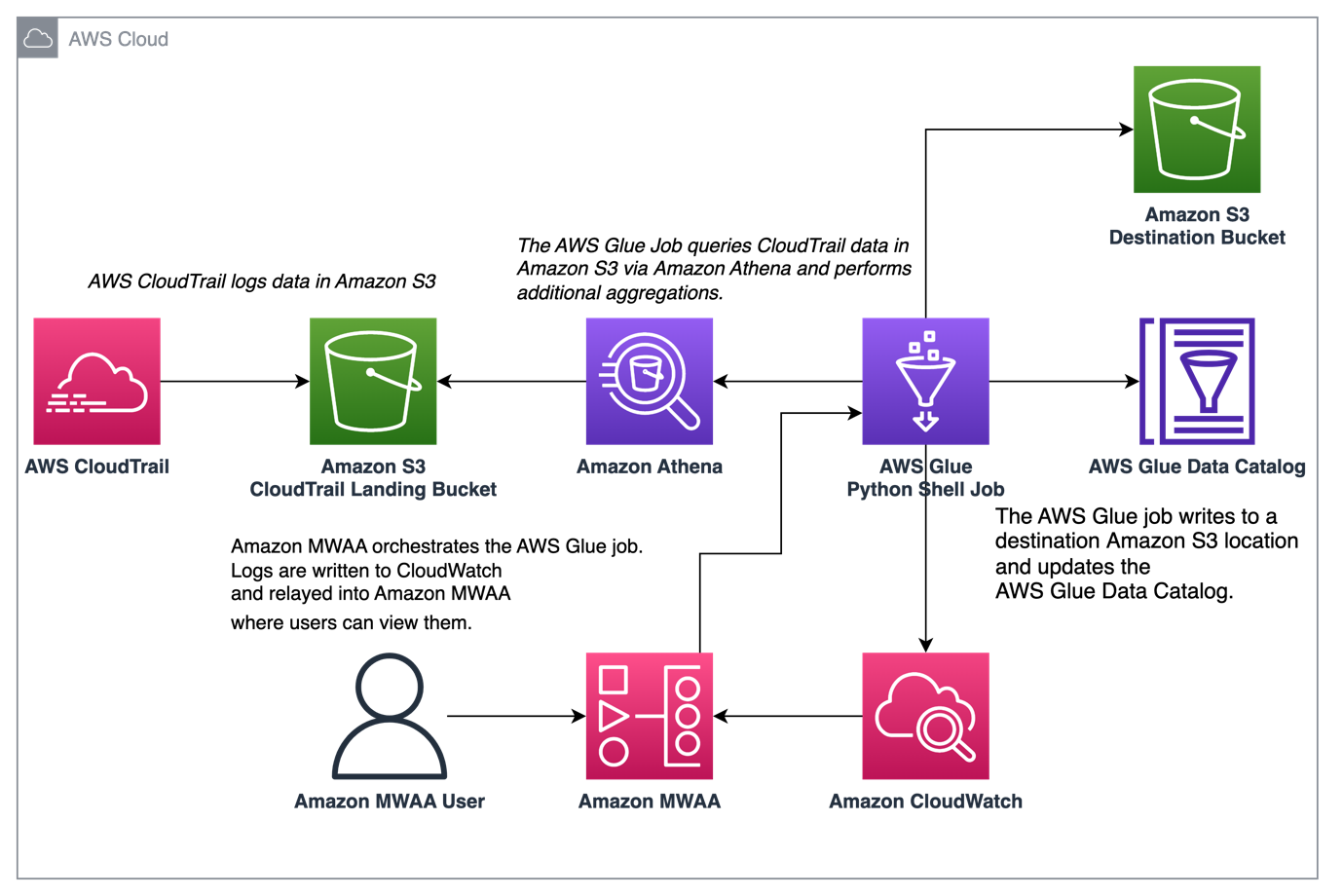
Using Apache Airflow to orchestrate the running of AWS Glue jobs is a common use case, and so this post, Simplify AWS Glue job orchestration and monitoring with Amazon MWAA is perfect for those of you who are doing this. Rushabh Lokhande, Vishwa Gupta, and Ryan Gomes look at how to simplify monitoring an AWS Glue job orchestrated by Airflow using the latest features of Amazon MWAA. [hands on]
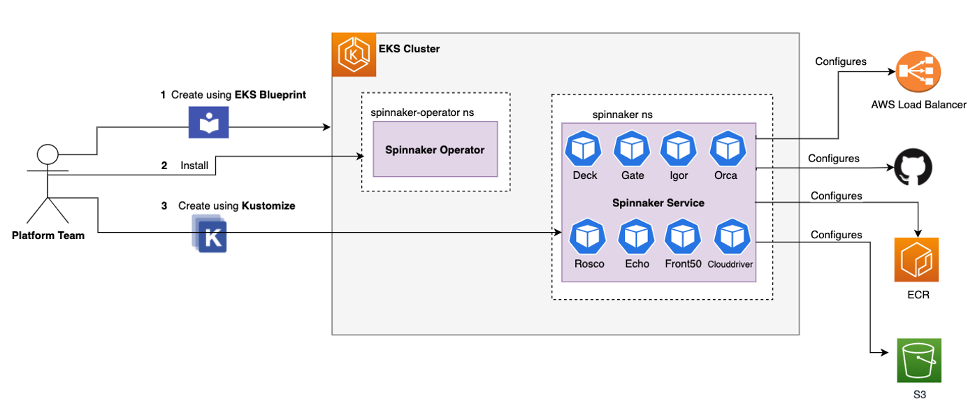
Spinnaker
Spinnaker is a cloud native continuous delivery platform that provides fast, safe, and repeatable deployments for every enterprise. In the post, Configure Continuous Deployment Using Kustomize Components and Spinnaker Operator in Amazon EKS, Praseeda Sathaye, Fernando Freire, and Puneet Singh collaborate to show you how you can install a Spinnaker Service using Spinnaker Operator and Kustomize. The posts walks you through the process of setting up a sample application in Spinnaker service using Kustomize, building a Spinnaker CD pipeline which used Kustomize to overlay the test and prod environment during the deployment stage. [hands on]
OpenSearch
If you are using Logstash with OpenSearch then make sure you read Discontinuing the custom Logstash distribution. David Venable talks about why the OpenSearch community has decided to discontinue the custom distribution and your options.
Community Roundup
Check out this post from Mickael Derriey, Traces to logs correlation in AWS with Node.js where he looks at a project he worked on was hosted in AWS using Fargate to run containers, CloudWatch for logs, and X-Ray for OpenTelemetry traces.
Other posts and quick reads
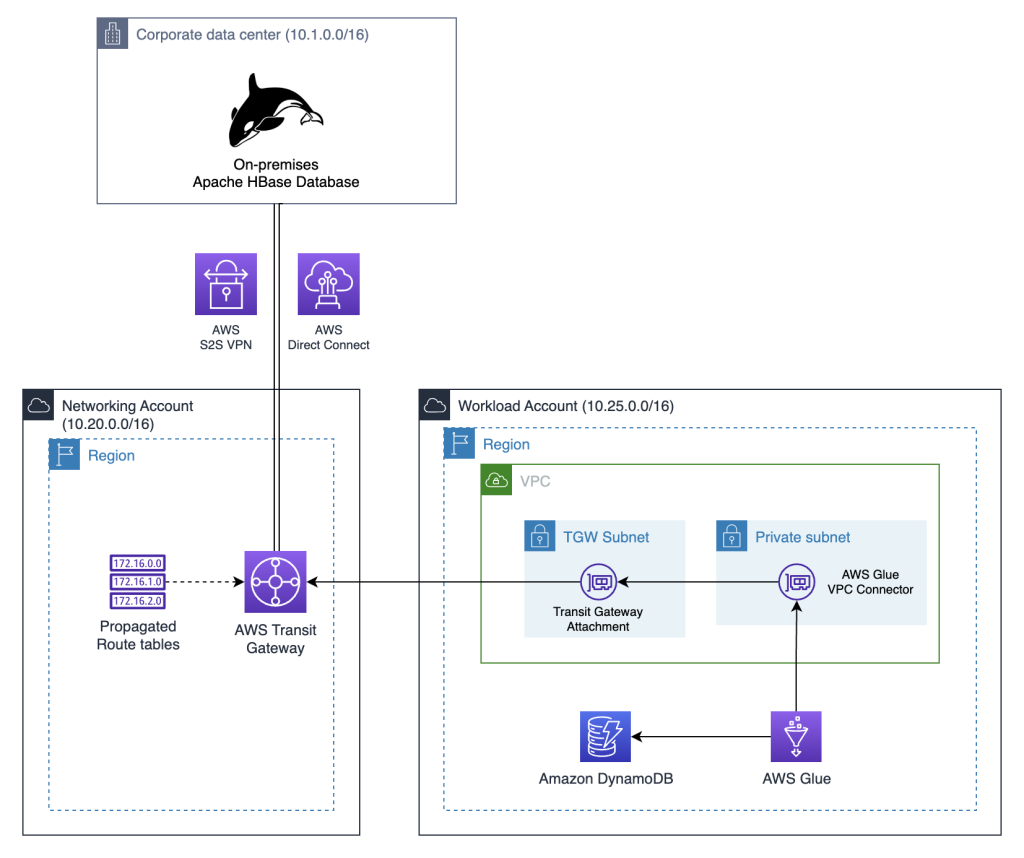
- Migrate data from Apache HBase to Amazon DynamoDB describes how you can migrate data from your on-premises Apache HBase database to Amazon DynamoDB [hands on]
- Automate Security and Monitoring with Amazon EKS Blueprints, Terraform, and Sysdig looks at Kubernetes adoption difficulties and how to use the blueprints to reduce those gaps
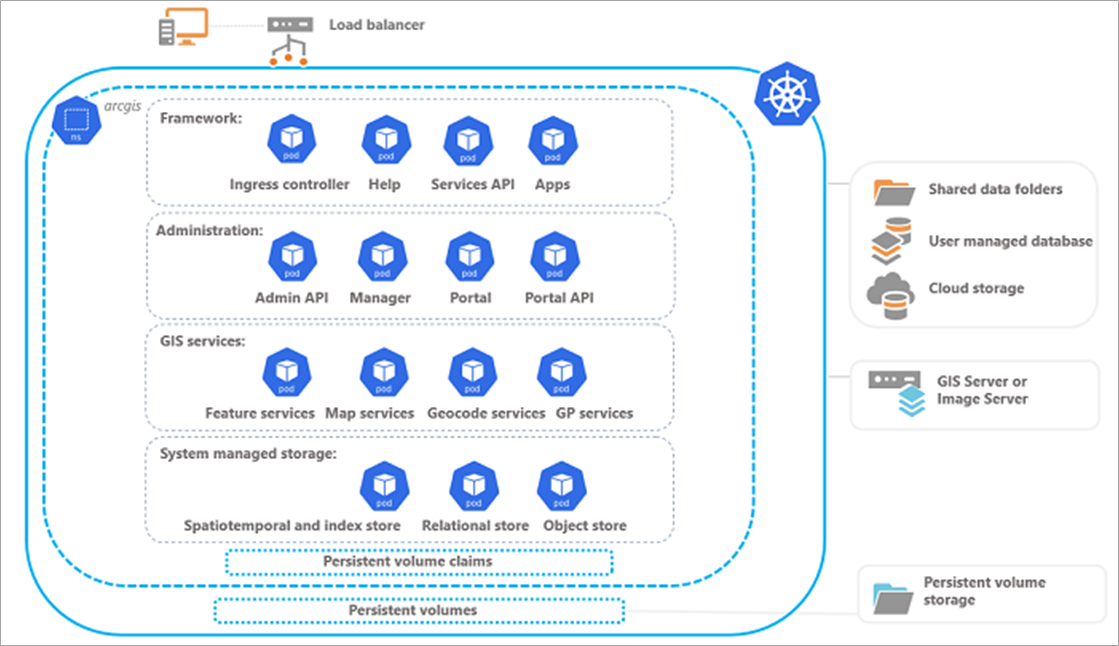
- Leveraging the Power of Esri’s ArcGIS Enterprise on Kubernetes Through Amazon EKS shows you how to deploy ArcGIS Enterprise (a powerful mapping and spatial analytics technology) on Amazon Elastic Kubernetes Service (Amazon EKS) [hands on]
- HardenEKS: Validating Best Practices For Amazon EKS Clusters Programmatically provides a hands on guide on how you can programmatically validate Amazon EKS clusters against best practices defined in AWS’ EKS Best Practices Guide (EBPG) [hands on]
Quick updates
Apache Airflow
Amazon Managed Workflows for Apache Airflow (MWAA) is a managed orchestration service for Apache Airflow that makes it easier to set up and operate end-to-end data pipelines in the cloud. You can now use MWAA for use cases that are subject to Service Organisation Control (SOC) requirements. MWAA is now SOC 1, 2 and 3 compliant, allowing you to get deep insight into the security processes and controls that protect customer data. AWS maintains SOC compliance through extensive third-party audits of AWS controls. These audits ensure that the appropriate safeguards and procedures are in place to protect against security risks that may affect the confidentiality, integrity, and availability of customer and company data. AWS SOC reports are independent third-party examination reports that you can download in AWS Artifact.
Being in scope for SOC means that customers can now use Amazon MWAA to manage workflows that require audited evidence of the controls in AWS SOC reporting.
MySQL
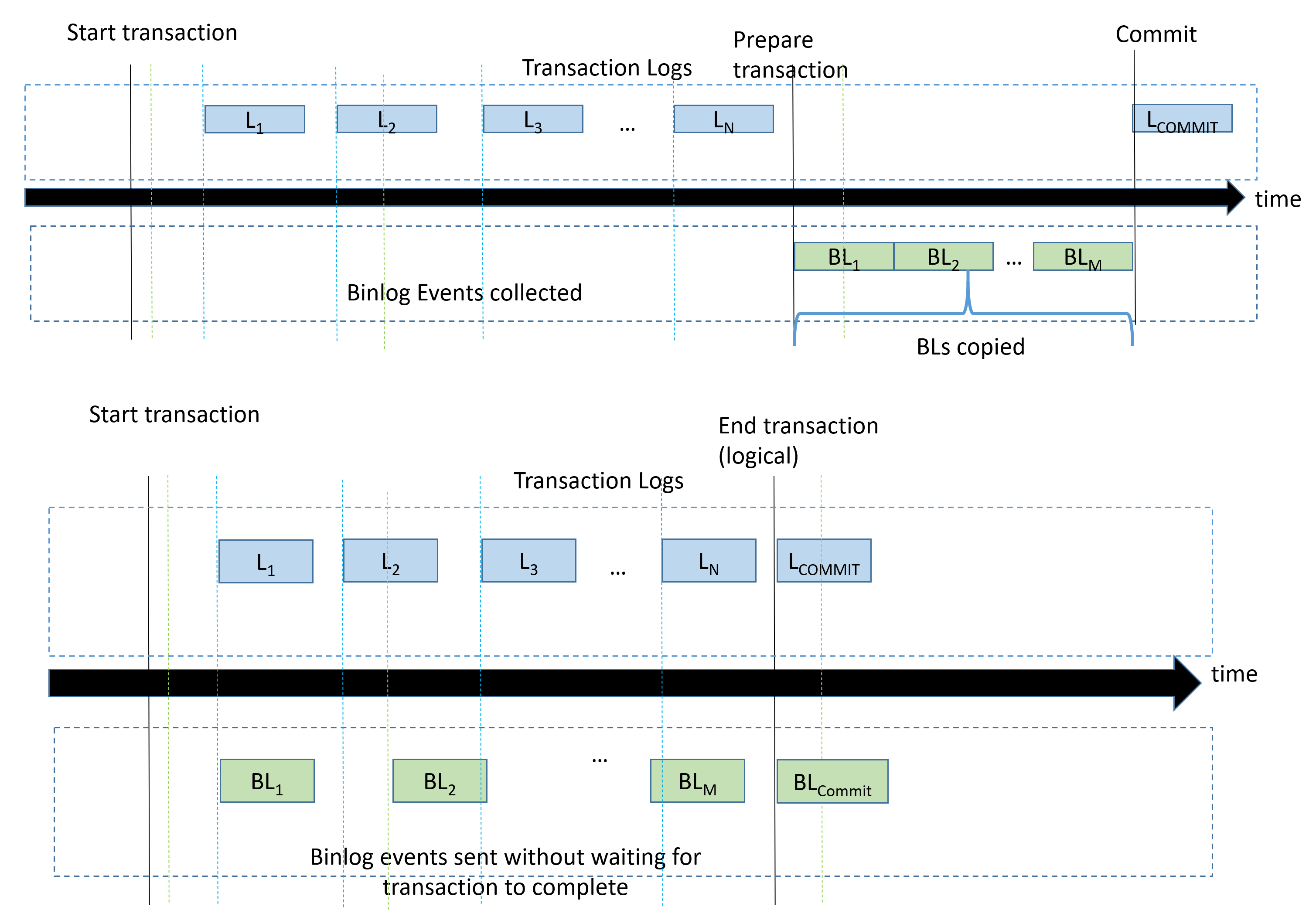
Amazon Aurora MySQL-Compatible Edition now supports a new, enhanced binary log (binlog). The enhanced binlog reduces the compute performance overhead caused by enabling binlog, which, in certain cases, can reach up to 50%, down to 13%. The enhanced binlog also improves database recovery time by up to 99% after restarts and failovers, as compared to when native MySQL binlog is enabled.
One of the most commonly used features of MySQL is the binlog. The binlog is a record of all activity made to the database and is used for a variety of scenarios, including logical read replicas, data pipelines, ETL processing, loading data into data lakes and data warehouses, and event driven architectures. The enhanced binlog capability is compatible with existing workloads and you interact with it the same way you interact with native MySQL binlog.
Check out the blog post, Introducing Amazon Aurora MySQL enhanced binary log (binlog), where Aditya Samant and Adam Levin look at these improvements in more detail.
PostgreSQL
A couple of updates this week.
First up is news that Amazon Relational Database Service (RDS) for PostgreSQL now supports the Rust programming language as a new trusted procedural language. This allows you to build high performance user defined functions to extend PostgreSQL for compute-intensive data processing. Rust combines the performance and resource efficiency of compiled languages like C with mechanisms that limit the risks from unsafe memory use. As a PostgreSQL trusted procedural language, PL/Rust provides memory safety so that an unprivileged user can run code in the database without the risk of crashing the database due to a software defect that corrupts memory. Developers can also package PL/Rust code as Trusted Language Extensions for PostgreSQL to run on Amazon RDS. PL/Rust is available on all database instances in Amazon RDS running PostgreSQL 15.2 and higher in all AWS Regions, including the AWS GovCloud (US) Regions.
Make sure you check out Jonathan Katz’s post, Build high-performance functions in Rust on Amazon RDS for PostgreSQL that shows how to deploy an RDS for PostgreSQL instance with PL/Rust enabled, and reviews several examples for how to write high-performance Rust code directly in your database.
Following that is news that Amazon RDS for PostgreSQL now supports up to 15 asynchronous read replicas from Amazon RDS Multi-AZ deployments with two readable standbys delivering up to 8x the previous read capacity.
Amazon RDS Multi-AZ deployments with two readable standbys have one writer instance and two readable standby instances across three availability zones. You can now create 15 additional asynchronous read replicas outside the cluster in addition to the two reader instances thereby scaling up your read capacity to 17 instances. Amazon RDS Read Replicas provide enhanced performance and durability for RDS database (DB) instances. For read heavy database workloads, the additional read replicas provide the option to elastically scale out beyond the capacity constraints of the two readable instances inside the Multi-AZ deployment with two readable standbys. You can create one or more read replicas and serve high-volume application read traffic from multiple copies of your data, thereby increasing aggregate read throughput. Read replicas can also be promoted and modified to be a Multi-AZ deployment option with two readable standbys when needed. Amazon RDS Multi-AZ deployments with two readable standby database instances supports up to 2x faster transaction commit latencies than a Multi-AZ deployment with one standby instance. In this configuration, automated failovers typically take under 35 seconds. In addition, the two readable standbys can also serve read traffic.
Kubernetes
Kubernetes 1.27 introduced several new features and bug fixes, and AWS announced last week that you can now use Amazon EKS and Amazon EKS Distro to run Kubernetes version 1.27. Starting today, you can create new 1.27 clusters or upgrade your existing clusters to 1.27 using the Amazon EKS console, the eksctl command line interface, or through an infrastructure-as-code tool.
This release of Kubernetes 1.27 includes stable support for Seccomp Profile defaulting and scheduling improvements such ability to control when a pod is ready to be considered for scheduling using Pod Scheduling Readiness and allowing custom queue controllers to influence pod placement for suspended jobs. As a reminder, Kubernetes 1.27 will not be published on the old k8s.gcr.io image registry, to use the latest Kubernetes images and patch releases, you will need to use registry.k8s.io image registry.
You can dive deeper into this update by checking out this post, Amazon EKS now supports Kubernetes version 1.27 where Sheetal Joshi and Leah Tucker go through these in more detail.
AWS Amplify
AWS Amplify announced the Authenticator UI component for Swift and Android last week. Developers can now use the Authenticator UI component to build end to end login/registration workflows for their Amplify powered Swift and Android projects in minutes. Moreover, the Authenticator UI component sets up the sign in and sign up workflows based on the existing auth configuration right out of the box. This UI component is built entirely using native SwiftUI and Android Jetpack Compose components, so developers can provide a user experience tailored to the Swift and Android platforms that their users feel most comfortable with. The Authenticator UI component automatically handles the login fields like email, username, and phone number based on the Auth configuration set up via the Amplify Command Line Interface (CLI). Developers can also apply custom theming to the Authenticator UI component.
Check out the blog post from my colleague Sebastien, New – Amplify SwiftUI-based Authenticator Component where he provides a hands on guide to getting started with this.

AWS ParallelCluster
AWS ParallelCluster is a fully-supported and maintained open-source cluster management tool that enables R&D customers and their IT administrators to operate high-performance computing (HPC) clusters on AWS. ParallelCluster is designed to automatically and securely provision cloud resources into elastically-scaling HPC clusters capable of running scientific, engineering, and machine-learning (ML/AI) workloads at scale on AWS.
AWS ParallelCluster 3.6 is now generally available. Key new features include support for automatic health checks for GPU instances and support for Red Hat Enterprise Linux (RHEL8). Other important features in this release include:
- Ability to customize Slurm settings not managed by ParallelCluster
- A programmatic interface to manage ParallelCluster using AWS CloudFormation
- Support for up to 50 queues and a total of 50 compute resources per cluster
- Tag-based cost monitoring in ParallelCluster UI
- Support for custom resource tags for queues, head node, and ParallelCluster-managed storage
- Extended Amazon CloudWatch metrics for disk usage, idle instances, and errors
- Improved head node resiliency with configurable log rotation
For more details on the release, review the AWS ParallelCluster 3.6 release notes. and you can also read the post Introducing GPU health checks in AWS ParallelCluster 3.6, where Matt Vaughn shows you how you can get started.
Videos of the week
Reducing Latencies with Micronaut and Amazon Corretto
This deep dive from Alvaro Sanchez-Mariscal looks at techniques you can use to reduce your application latencies using Amazon Corretto and the Micronaut framework.
Open Source Summit
Check out David Nalley as he speaks with John Furrier on theCUBE providing a look forward at Open Source Summit NA.
Build on Open Source
Last Friday was the last episode (eight) of season two, and we featured Cristian Măgherușan-Stanciu who walked us through his open source tools that helps you to save money running your EC2 fleets with his autospotting tool. You can check out the replay
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
AWS Open Source Symposium RSA House Durham Street Auditorium, London, June 6th
The AWS Open Source Symposium will focus on the two themes of Data Analytics and Developer Platforms built with CNCF technologies.
For Developer Platforms, the following will be discussed: 1/Components of a Developer Platform, 2/Building or Assembling Developer Platforms, 3/Operating Developer Platforms, and 4/Existing Tooling and Technologies.
For Data Analytics and AI/ML, the discussion will focus on customers' open source implementations on Kubernetes and their integration with AWS services, such as Open Source Spark, Iceberg, Hudi, Trino, JupyterHub, and more.
There will also be a focus on running scalable data workloads on Kubernetes and discussing Cloud Native Batch Systems, such as Apache YuniKorn and Volcano batch schedulers, as well as any multi Kubernetes cluster batch schedulers like Armada.
The goal of the symposium is to bring customers together to share thoughts on how they are using these solutions to solve big data and observability use cases, as well as to discuss lessons learned and mistakes to avoid.
Register and save your spot via the AWS Open Source Symposium link.
Open source Table Formats with AWS Glue and Amazon EMR Online, 6th June 5PM UK time
Curious about Transactional Data Lakes? Come join our AWS experts as we take you through the most popular open source table formats, how these table formats can help you enable a modern data strategy, and how to build on these formats with Amazon EMR and AWS Glue. In this session, we’ll cover some of the key differences between these different table formats, help you decide which table format may be the best fit for your workloads, and show you how to start building today.
You can join via YouTube live here
London Open Source Data Infrastructure Meetup Huckletree Shoreditch, 6:30PM - 9:30PM
As part of London Tech Week Aiven are co-hosting the ‘London Open Source Data Infrastructure Meetup’ on the 14th of June. This event is in collaboration with Hugh Evans from Daemon the ‘AI and Deep Learning for Enterprise’ group. The speaker panel includes Ricardo Sueiras from Amazon Web Services (AWS) discussing the wonders of Apache Airflow, Davies Oludare from Confluent shedding light on the intricate world of Kafka, and Ed Shee from Seldon breaking down the nuances of ML-powered summarisation.
Spaces are limited, so make sure you reserve your spot by checking and out the meetup page
Open Source Festival Lagos, Nigeria - June 15th-17th
An established and essential event for all open source developers, Open Source Festival promises to be even bigger and better than previous years. I feel very privileged to have spoken at this event in 2020, and so make sure you check this out if you are in the region or perhaps if you are maybe looking to sponsor an open source event, then maybe this is the one you should check out.
Check out more on their homepage, Open Source Festival
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen