AWS open source newsletter #155
May 1st, 2023 - Instalment #155
Welcome
Hello and welcome to the AWS open source newsletter, #155, the newsletter that just keeps on giving….in this case, keeps giving you brand new open source projects to practice your four freedoms on. This week’s new projects include
“aws-cloudformation-controller-for-flux” provides a way to use flux to orchestrate your CloudFormation deployments, “threat-composer” is a nice React based tool to help you create Threat Models for your systems and applications, “cdk-integ-tests-sample” a tool to allow you to do integration tests with your CDK stacks (these three were all featured in the latest episode of Build on Open Source, you can watch it here), “iam-access-key-report” generates reports from your AWS accounts about your AWS access keys, “personalize-kafka-connector” provides an integration into Apache Kafka for this AWS service, and more!
If reading is more your thing, then catch up on the latest posts, that this week include open source projects such as RabbitMQ, Amazon Corretto, Apache Cassandra, Smithy, OpenSearch, Apache Iceberg, Ubuntu, Apache Kafka, PostgreSQL, MicroPython, ROSA, TiDB, Trino, Druid and more!
Feedback
Please please please take 1 minute to complete this short survey and bask in the warmth of having helped improve how we support open source.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Jeff Boudier, Philipp Schmidd, Julien Simon, Bob Tordella, Cícero Joasyo Mateus de Moura, Dipankar Mazumdar, Hayden Baker, Lin Wang, Charlie Yang, Nate Archer, Vikram Sahadevan, Suvendu Kumar Patra, Ranjit Rajan, Alexandre Rezende, Kannan Iyer, Spot Callaway, Mark Sailes, and Lars Jacobsson.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
iam-access-key-report
iam-access-key-report This is a simple tool written in python that will enumerate data about all active IAM access keys across an AWS Organization and will enrich each key with account tag information. The output of the tool is a CSV file that can then be filtered based on the tag information associated with the keys. This allow us to focus on access keys that are used in things like ‘Environment:Production’ accounts or in accounts that are labelled with ‘DataClassification:Restricted’. In addition, the tool performs some basic security checks of the IAM policies of the user accounts the access keys are attached to. It will tell you if a key has administrative permissions or is able to read your data in Amazon S3, Amazon RDS, and Amazon DynamoDB.
iambic
iambic is an open source project that helps you manage your IAM policies as “code”, allowing you to model your permissions and then store these in source control. The project states it is “the Terraform of Cloud IAM”. It certain is feature rich, has good documentation with plenty of examples, and works across other public Cloud providers. The repo states this is still a beta project, so bear that in mind. (hat tip to Corey Quinn’s Last Week in AWS newsletter for bring this repo to my attention)
aws-cloudformation-controller-for-flux
aws-cloudformation-controller-for-flux helps you to store CloudFormation templates in a git repository and automatically sync template changes to CloudFormation stacks in your AWS account with Flux. The AWS CloudFormation Template Sync Controller for Flux is an extension to Flux that lets you store your CloudFormation templates in a Git repository and automatically deploy them as CloudFormation stacks in your AWS account. After installing the CloudFormation Template Sync controller into your Kubernetes cluster, you can configure Flux to monitor your Git repository for changes to CloudFormation template files. When a CloudFormation template file is updated in a Git commit, the CloudFormation controller is designed to automatically deploy the latest template changes to your CloudFormation stack. The CloudFormation controller is also designed to continuously sync the latest template from the Git repository into your stack by re-deploying the template on a regular interval.
threat-composer
threat-composer if you ask any Amazonian about what is the most important job developers do, there is a good chance they will say security. threat-composer is an open source tool that aims to help you brainstorm and consistently compose useful threats to help you with your security planning. From the README:
A key phase of the threat modeling process is the “What can go wrong?” step. Feedback we received is that there are two key challenges in this step, firstly there is little industry guidance on what a ‘good’ threat statement looks like; Secondly, no canonical list of possible things that can wrong hence it necessitates brainstorming and collaboration between the individuals involved in the threat modeling process often starting from a “blank page”.
threat-composer aims to provide prescriptive and flexible threat statement structure that allows a user to create a structured threat statement by supplying their own contextual input into the structure, whilst meeting them where they are by allowing them to start from any input that they desire. The tool encourages the user to be more complete and descriptive to help ensure the threat statement allows for both for prioritisation for mitigation and sufficient information to devise mitigation strategies. In addition, the tools aims to aid the brainstorming and collaboration process by including full threat statement examples and per field examples which a customer can use as inspiration or as a starting point for their own custom and contextual threat statements.
personalize-kafka-connector
personalize-kafka-connector Amazon Personalize is a fully managed machine learning service that uses your data to generate item recommendations for your users. When you import data, you can choose to import records in bulk, or with our real-time APIs. For customers that use Kafka, we’ve set up the Amazon Personalize Kafka Connector to send real-time data from Kafka topics to your Amazon Personalize Dataset.
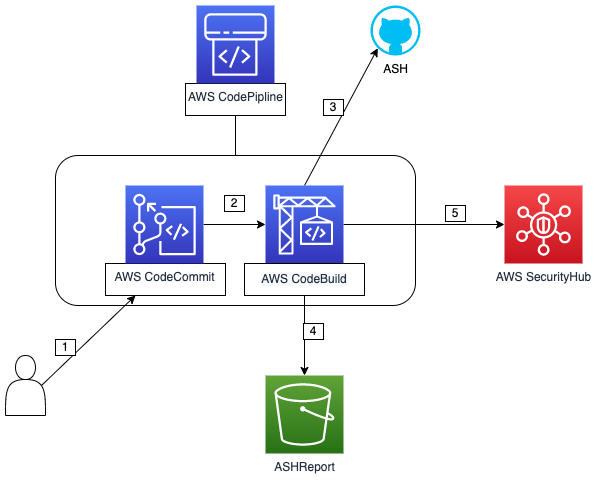
automated-security-helper-pipeline automated-security-helper-pipeline this repo helps you deploy The Automated Security Helper (ASH) a project we featured in #117 last year. It deploys a pipeline CDK template, which can be used to provision an end to end pipeline using CodePipeline, CodeCommit and CodeBuild. The solution will scan new commits using ASH, will save the report into S3 bucket, and will alert to SecurityHub if the scan failed.
Demos, Samples, Solutions and Workshops
cdk-integ-tests-sample
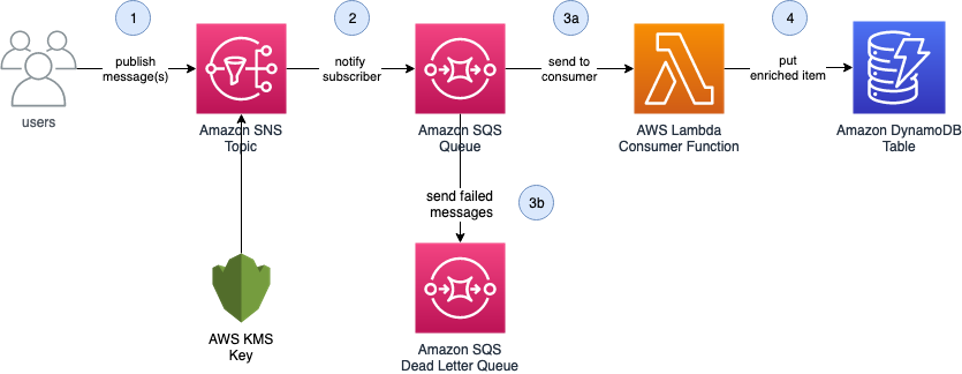
cdk-integ-tests-sample this example repo demonstrates how to write integration tests for your CDK applications using the AWS CDK integ-test CDK construct and integ-runner CLI Tool. The example application is a serverless data enrichment application with persistence shown in Figure 1. CDK integration tests are written for this application under the integ-tests/ folder. When these tests are run, it creates a separate integration test stack (a copy of your operational application) and runs the test against this isolated environment.
service-catalog-engine-for-terraform-os
service-catalog-engine-for-terraform-os this repo, the AWS Service Catalog Terraform Reference Engine (TRE), provides an example for you to configure and install a Terraform open source engine in your AWS Service Catalog administrator account. With the engine installed into your account, you can use Service Catalog as a single tool to organise, govern, and distribute your Terraform configurations within AWS. Dive into the detailed README to find out more about how this works and the underlying architecture. You can also read the blog post by my colleague Danillo, New – Self-Service Provisioning of Terraform Open-Source Configurations with AWS Service Catalog, that will help you get started.

Workshops and Hands on Labs
Fast-Terraform this repo is a great resource learning how to get started with Terraform on AWS, and has a number of different labs covering various AWS services. If you are using this, or try it out, let me know how you get on.
AWS and Community blog posts
Community roundup
We had a great selection of community authored content that caught my eye this week.
First up is the latest post from AWS Community Builder Bob Tordella at Steampipe. I always enjoy reading Bob’s posts, and in Accelerate your AWS Well-Architected assessments with Steampipe he touches upon a growing movement around using open source tools to help with automating activities of the AWS Well-Architected Framework. In this post, he talks about how Steampipe can help accelerate assessments, get deep insights into your environments, and provide tailored recommendations based on the Well-Architected Framework. Another great read from Bob “I’m on Fire” was Visualizing AWS EKS Kubernetes Clusters with Relationship Graphs where he shows a different use case for Steampipe, this time providing visualisations that provide quick context and highlight important information about your resources, in this case AWS Elastic Kubernetes Service (EKS) clusters. Very nice indeed.
I also enjoyed reading AWS Community Builder’s Cícero Joasyo Mateus de Moura’s post, Data Quality at Scale with Great Expectations, Spark, and Airflow on EMR as Data Quality is a hot topic, and I have been meaning to get my hands on Great Expectations so I found this a great post to understand it a little more. The fact it also incorporates my favourite open source project has nothing to do with how much I liked it! Go and read this post, you will not regret it.
Dipankar Mazumdar has put together this blog post, Building a Streamlit app on a Lakehouse using Apache Iceberg & DuckDB which continues an ongoing number of posts featuring Streamlit, an open source project that makes it easier to build data based applications. In this post, Dipankar provides a hands on guide on building a Streamlit application on top of a data lakehouse built on top of the Apache Iceberg table format.
Smithy
Smithy is an open-source Interface Definition Language (IDL) for web services created by AWS. AWS uses Smithy to model services, generate server scaffolding and rich clients in multiple languages, and generate the AWS SDKs. Last week the team behind Smithy launched the Smith CLI, and Hayden Baker put together this post Introducing the Smithy CLI, that provides a hands on guide on how to get started with it.
OpenSearch
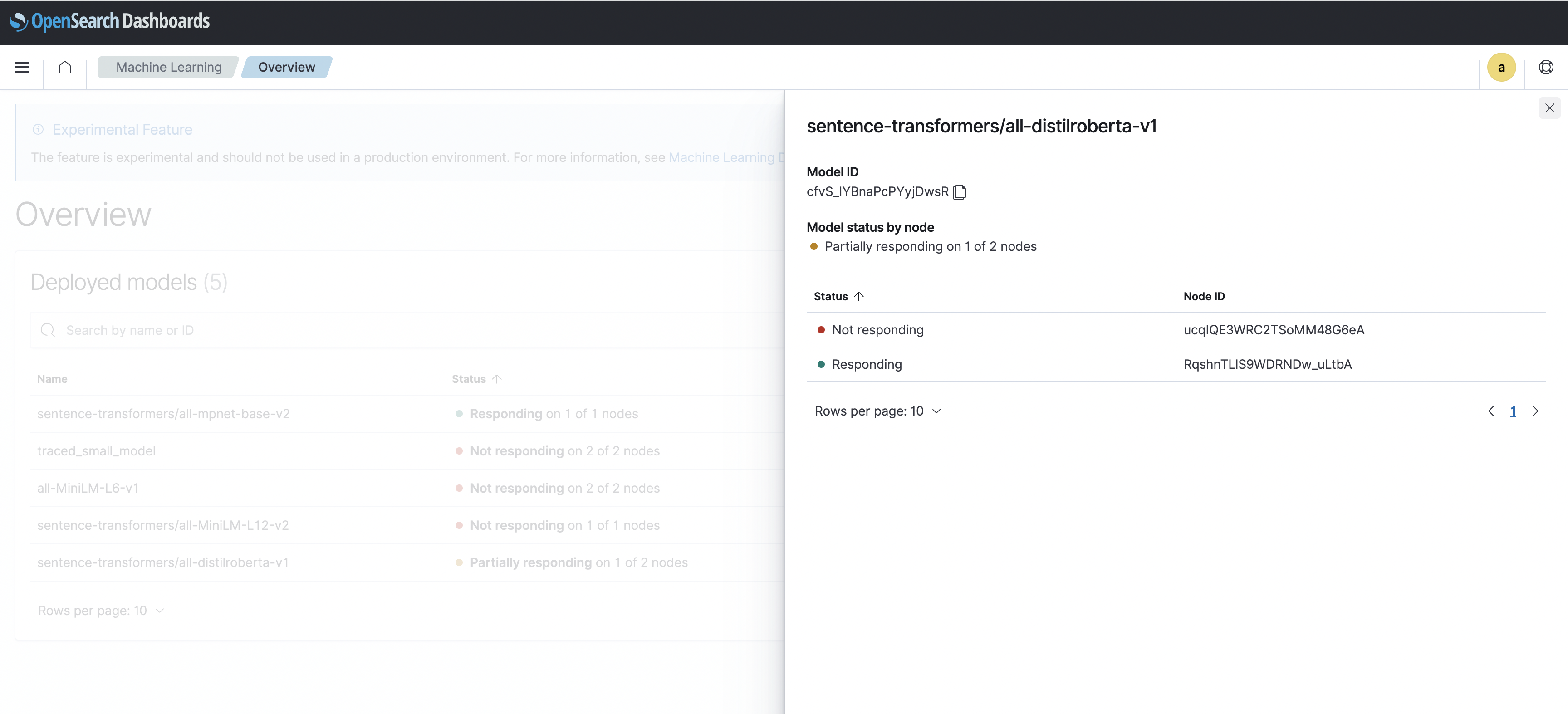
In the post, You can now see ML model status in OpenSearch Dashboards Lin Wang, Charlie Yang, and Nate Archer huddle together to write about the first piece of ML functionality in OpenSearch Dashboards, the deployed models dashboard. This is an experimental feature that gives you a view into the responsiveness of each deployed model on each ML node in your cluster. Very cool.
Apache Iceberg
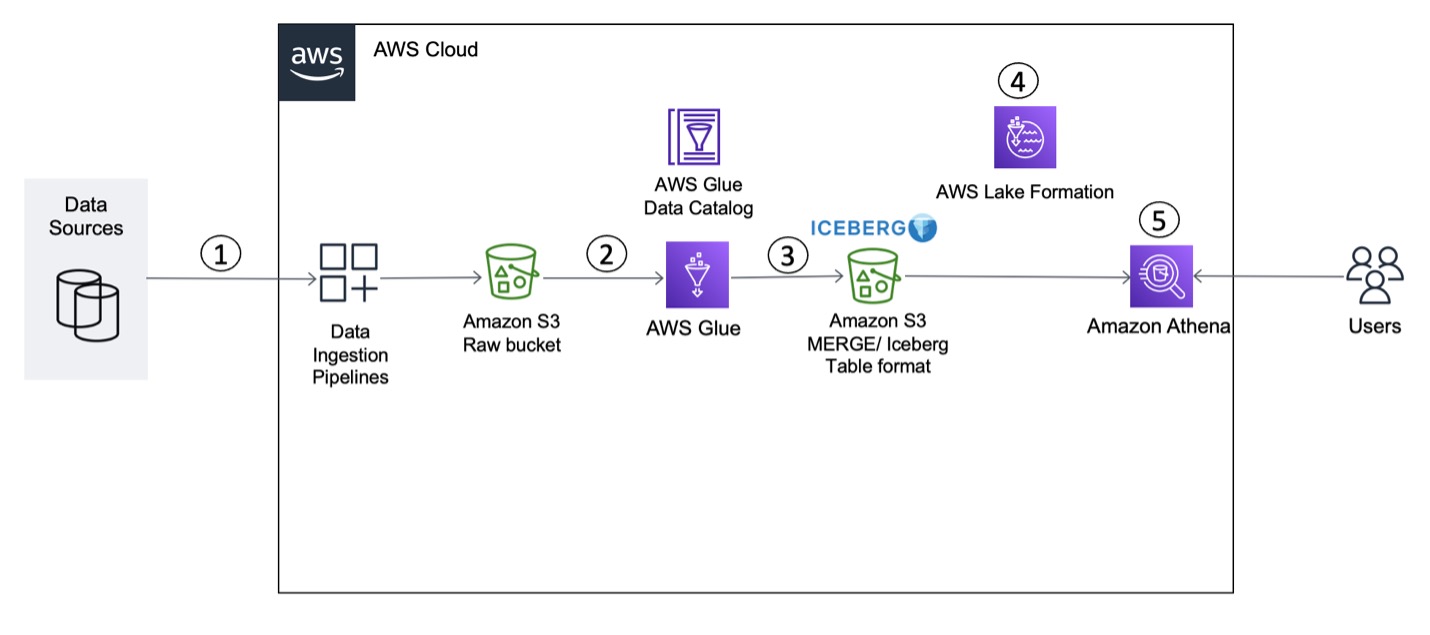
Vikram Sahadevan and Suvendu Kumar Patra have put together this post, Build a transactional data lake using Apache Iceberg, AWS Glue, and cross-account data shares using AWS Lake Formation and Amazon Athena that shows you how to configure AWS Lake Formation using Iceberg table formats. The post goes onto explain how to upsert and merge in an S3 data lake using an Iceberg framework and apply Lake Formation access control using Athena. [hands on]
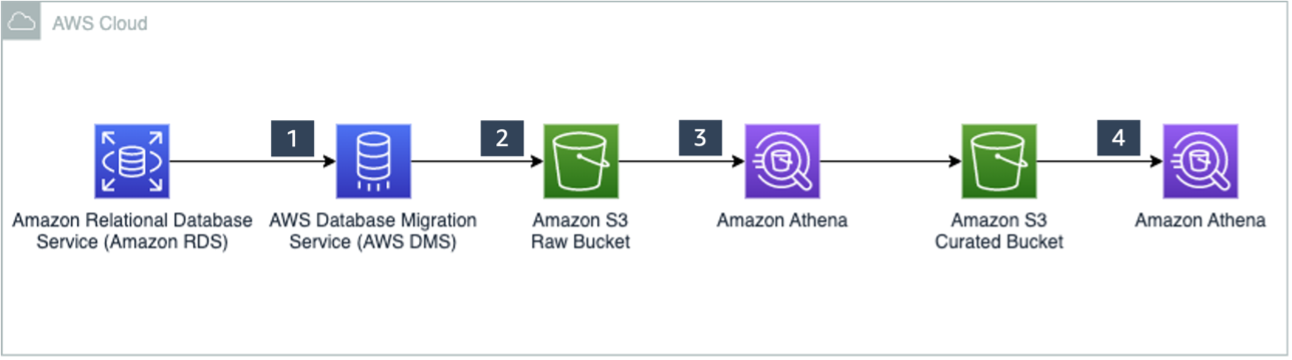
We also had another Apache Iceberg post sneak in just before publication, this time Ranjit Rajan, Alexandre Rezende, and Kannan Iyer collaborating on Perform upserts in a data lake using Amazon Athena and Apache Iceberg, that demonstrates how you can use Athena to apply CDC from a relational database to target tables in an S3 data lake.
Securing Open Source
My colleague Spot put together this fine post, Securing PyPI for the Future that dives deep into how we at AWS are investing to support open source software supply chain security. In this instance, it explores how we are working with the Python community and PyPi to keep PyPI secure for the benefit of all its users.
Amir Montazery, who is the managing director for Open Source Technology Improvement Fund (OSTIF) also tweeted last week about how we collaborated with the SimpleJSON project on an independent review.
Other posts and quick reads
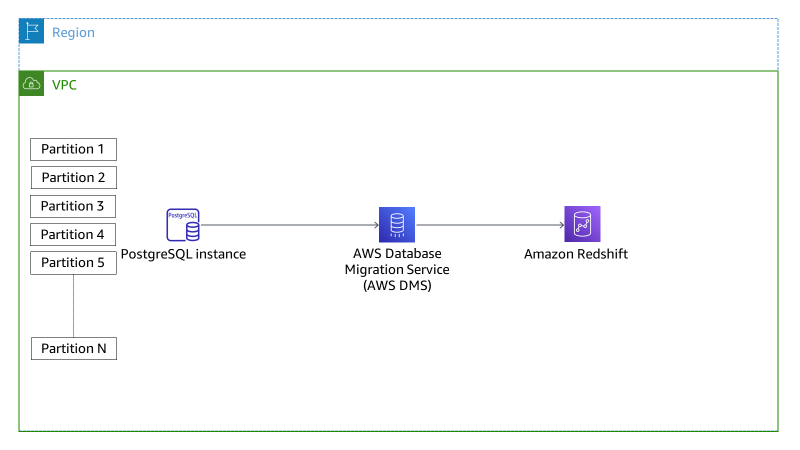
- Migrate data from partitioned tables in PostgreSQL using AWS DMS illustrates how we can migrate data from PostgreSQL partitioned tables to a single table on the target database using AWS Database Migration Service (AWS DMS) [hands on]
- Using MicroPython to get started with AWS IoT Core walks you through how to configure an ESP32 based microcontroller to connect to AWS IoT Core using MicroPython [hands on]
- Benefits of Running Virtual Machines on Red Hat OpenShift for AWS Customers looks at the benefits from running VMs on top of OpenShift Container Platform (OCP) on Amazon Web Services (AWS), such as integrated management, migration and modernisation, and improving developer productivity

- Designing High-Performance Applications Using Serverless TiDB Cloud and AWS Lambda shows you how to build scalable, cost-effective, and serverless micro-services using TiDB, a cloud-native, open-source distributed SQL database with built-in hybrid transactional and analytical processing (HTAP) [hands on]
Case Study
- How Zomato Boosted Performance 25% and Cut Compute Cost 30% Migrating Trino and Druid Workloads to AWS Graviton explores how Zomato, an India-based restaurant aggregator, food delivery, dining-out company with over 350,000 listed restaurants across more than 1,000 cities in India, migrated workloads to Graviton based instances. The post walks you through an overview of Trino and Druid and how they fit into the overall Data Platform architecture, and the migration journey onto AWS Graviton based instances for these workloads. The post looks at challenges faced during migration, and how the Zomato team overcame those challenges, as well as looking at the business gains in terms of cost savings and better performance.

Quick updates
Amazon Corretto
AWS Lambda now supports Java 17 as both a managed runtime and a container base image. Developers creating serverless applications in Lambda with Java 17 can take advantage of new language features including Java records, sealed classes and multi-line strings. The Lambda Java 17 runtime also has numerous performance improvements, including optimisations when running Lambda functions on Graviton 2 processors. It supports AWS Lambda Snap Start (in supported Regions) for fast cold starts, and the latest versions of the popular Spring Boot 3 and Micronaut 4 application frameworks. For more information on Lambda’s support for Java 17, see our blog post at Java 17 runtime now available in AWS Lambda. This runtime is based on the AWS Corretto distribution of OpenJDK. AWS will automatically apply updates to the Java 17 managed runtime and to the AWS-provided Java 17 base image, as they become available.
Make sure to read the launch post from Mark Sailes, AWS Lambda now supports Java 17
RabbitMQ
Amazon MQ now provides support for RabbitMQ version 3.10.20 and RabbitMQ 3.9.27, which include several important fixes and performance optimisations to the previously supported versions. Amazon MQ is a managed message broker service for Apache ActiveMQ and RabbitMQ that makes it easier to set up and operate message brokers on AWS. You can reduce your operational burden by using Amazon MQ to manage the provisioning, setup, and maintenance of message brokers. Because Amazon MQ connects to your current applications with industry-standard APIs and protocols, you can more easily migrate to AWS without having to rewrite code. If you are running a version of RabbitMQ earlier than 3.10.20 or 3.9.27, we encourage you to upgrade to the latest versions to get access to the latest security, performance and feature enhancements. This can be accomplished with just a few clicks in the AWS Management Console. If your broker has automatic minor versions upgrade enabled and is currently running version 3.10.10 or 3.10.17, Amazon MQ will automatically upgrade the broker to version 3.10.20 during a future maintenance window.
Apache Cassandra
Amazon Keyspaces (for Apache Cassandra), a scalable, serverless, highly available, and fully managed Apache Cassandra-compatible database service, now supports the use of the IN operator in SELECT queries of Cassandra Query Language (CQL). Last week we announced that Amazon Keyspaces has now added support for the IN operator in CQL SELECT queries. This support allows Cassandra developers to write queries that are less complex and more compatible with Cassandra. Additionally, support for the IN operator in SELECT queries provides an easier way to filter and access data that is spread over multiple partitions.
MQTT
AWS IoT Core Device Advisor support for MQTT over WebSocket in now generally available. AWS IoT Core Device Advisor is a cloud-based, fully managed test capability that validates AWS IoT device software for reliable and secure connectivity with AWS IoT Core. With this update, customers can run all three test suites of AWS IoT Core Device Advisor - qualification, custom, and long duration tests - using Signature Version 4 for MQTT over WebSocket. Signature Version 4 is a protocol for authenticating inbound API requests to AWS services, in all AWS Regions. In addition, all existing connectivity and security test cases within AWS IoT Device Advisor now support MQTT3.1.1 and MQTT5 over WebSocket, making it easier for customers to validate MQTT functionality during device software development before on-boarding them to AWS IoT Core.
Ubuntu
AWS License Manager announced a new feature to upgrade EC2 instances with Ubuntu LTS (Long Term Support) operating system to Ubuntu Pro. With Ubuntu Pro subscription, customers get five years of Expanded Security Maintenance (ESM) on the Ubuntu LTS releases from Canonical. Using this License Manager feature, customers can upgrade their Ubuntu LTS instances in-place to Ubuntu Pro without needing to migrate to a new Ubuntu Pro Amazon Machine Image (AMI). For the use of upgraded EC2 instances with Ubuntu Pro, you will be charged on a per-second basis at the applicable On-Demand or Savings Plan rates for Ubuntu Pro. In addition to five more years of security maintenance, Ubuntu Pro provides features such as security coverage for approximately 23000+ packages in Ubuntu Universe repository and live kernel patching. For example, Ubuntu 18.04 LTS will reach end of standard support on May 31, 2023. You can upgrade the Ubuntu 18.04 LTS instances to Ubuntu Pro 18.04 LTS in License Manager to receive security updates until April 2028. To learn more about Ubuntu Pro on EC2, please see this announcement.
AWS CDK
Application Manager, a capability of AWS Systems Manager that helps DevOps engineers investigate and remediate issues in the context of their applications, now supports AWS CDK applications. Customers who use CDK to model their cloud infrastructure can view their CDK constructs grouped as applications in the Application Manager console. Application Manager enables customers to monitor the operational status, metrics, and compliance of their applications from a central console through integration with Amazon CloudWatch and AWS Config. The new feature extends this experience to AWS CDK customers. CDK customers can now visualise their application, view application structure including the underlying resources, view alerts, investigate and remediate operational issues, and track costs using Application Manager.
Apache Kafka
Last week the general availability of Apache Kafka receiver and exporter in AWS Distro for OpenTelemetry (ADOT) was announced. ADOT is a secure, production-ready, AWS-supported distribution of the OpenTelemetry project. With this release, customers can use the ADOT collector to collect metrics and traces from Kafka and send metrics and traces to Kafka. The release includes support for Amazon Managed Streaming for Apache Kafka (MSK). Customers can now support new use cases such as large-scale ingestion of historical data via Kafka used as a buffer (to handle backpressure) into Amazon S3, where customers can perform analytics using AWS Glue and AWS Lambda. Furthermore, customers can use the Apache Kafka support in the ADOT collector in Security Information and Event Management (SIEM) monitoring. For example, customers can buffer raw signals (metrics and traces) in Kafka for use cases such as intrusion detection and compliance enforcement.
AWS SAM
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) announced the launch of local testing support for Amazon API Gateway Lambda authorisers making it easier for developers to locally test their applications containing API Gateway. The AWS SAM CLI is a developer tool that makes it easier to build, test, package, and deploy serverless applications. Customers can now use the SAM CLI to locally emulate API Gateway Lambda authorisers on their machine using the sam local start-api command. Previously, customers had to use AWS Console or AWS CLI to test their API Gateway Lambda authorisers. With this launch, SAM CLI users can speed up their iteration cycles by testing their authoriser code locally. sam local start-api command supports testing of both Lambda authorisers, and Lambda V2 authorisers. This feature is available with SAM CLI version 1.80.0+.
Videos of the week
HuggingChat
A new show from the lovely folk at Hugging Face promises to showcase the latest in open source AI goodness. This is the debut show, featuring my old colleague Julien Simon, together with fellow Hugging Facers (not sure if that is the correct term, but I like the sound of it!) Jeff Boudier and Philipp Schmidd, and they take a look at their recently launched HuggingChat (available at hf.co/chat a ChatGPT alternative powered by open source.
Build on Open Source
Episode six of Build on Open Source streamed live on April 28th, with this newsletter being featured (as well as #154). In this episode we had special guest, AWS Community Builder Lars Jacobsson show us some of his open source tools, many of which we have featured in previous newsletters and shows. You can catch the replay here
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Reducing the costs of your openCypher applications Online, May 8th, 4pm UK
openCypher is an open-source project for creating graph applications. Neptune supports openCypher graph query language, and in this webinar you will learn more about the cost benefits for moving openCypher workloads to Neptune serverless. With Neptune serverless, customers can see up to 90% cost savings compared to provisioning for peak capacity. A demo of Neptune in action will be included in this session.
Head over to the You Tube holding page, Reducing the costs of your openCypher applications
Intelligent Document Processing with AWS and Open Source with Hugging Face AWS Office Zurich, May 23rd 8am - 2pm CET
For readers who are based in Zurich, make sure you check out this event. The goal of this in-person event is to learn and share experience on how to get insights from documents, and simplify workflows using document processing and the power of open source. There is a great line up of speakers and an excellent agenda.
Find out more and reserve your space by heading over to, Intelligent Document Processing with AWS and Open Source with Hugging Face
Open source Table Formats with AWS Glue and Amazon EMR Online, 6th June 5PM UK time
Curious about Transactional Data Lakes? Come join our AWS experts as we take you through the most popular open source table formats, how these table formats can help you enable a modern data strategy, and how to build on these formats with Amazon EMR and AWS Glue. In this session, we’ll cover some of the key differences between these different table formats, help you decide which table format may be the best fit for your workloads, and show you how to start building today.
You can join via YouTube live here
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen