AWS open source newsletter #149
March 20th, 2023 - Instalment #149
Welcome
Hello and welcome to edition #149 of the AWS open source newsletter, the only newsletter on the planet that serves you up a weekly dose of the freshest, latest open source projects on AWS. I hope some of you were able to catch this episode reviewed on our last Build on Open Source livestream. If not, you can catch the replay here. This week we have projects such “mountpoint-s3”, “s3-access-for-squash”, and “amazon-s3-tar-tool” which provide some useful tools for managing your files on S3, “aws-serverless-ai-stories” a creative masterclass in storytelling, “earthquake-notifier” a serverless solution to keep you alerted and ready, and more!
We also feature some of your favourite open source projects, this week covering Apache Cassandra, OpenSearch, Amazon EMR, Amazon Linux, Apache Airflow, Apache Hudi, Apache Iceberg, Nextcloud, Apache Kafka, Avalanche, AWS Parallel Cluster, Babelfish for Aurora PostgreSQL, and many more!
Feedback
Please please please take 1 minute to complete this short survey and get some exclusive content as a thank you.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Alvaro Hernandez, Namrata H Shah, John “Preston” Mille, Dan Gross, Nenand Ilic, Alina Dima, Syed Rehan, Dr. Aparna Sundar, Helge Aufderheide, Herbert-John Kelly, Andrew Gargan, Ali Alemi, Houssem Chihoub, Sebastien Stormacq, and David Boyne
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
mountpoint-s3
mountpoint-s3 was the big news last week, a new project that provides a simple, high-throughput file client for mounting an Amazon S3 bucket as a local file system. One thing to note however, is Mountpoint for Amazon S3 is currently an alpha release and should not be used in production. I enjoyed reading the launch post, The inside story on Mountpoint for Amazon S3, a high-performance open source file client where James Bornholt, Devabrat Kumar, and Andy Warfield show you how you can get started, some of the considerations you need to think about before using it, and then a look behind the scenes at how this tool was developed.
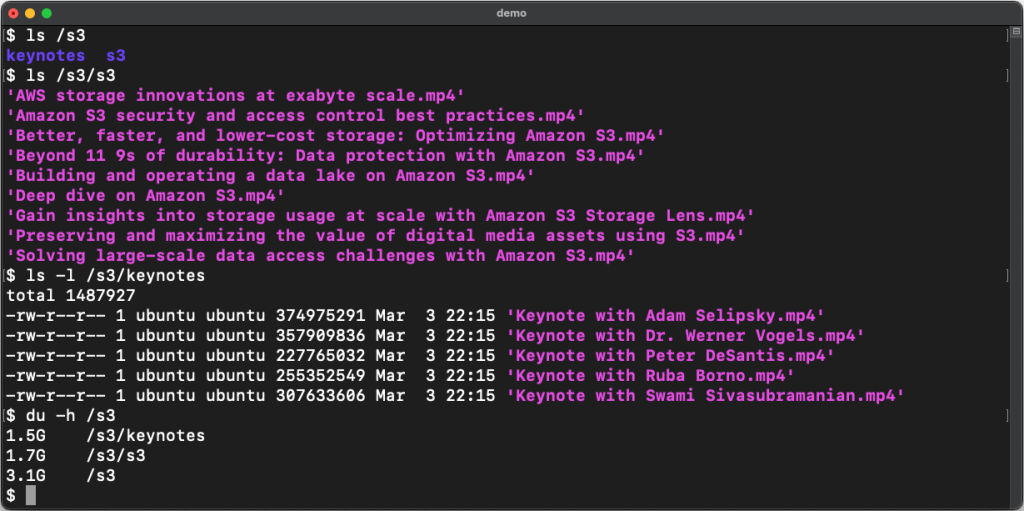
s3-access-for-squash
s3-access-for-squash is a great tool if you find yourself working with thousands (or more) small files and Amazon S3. Tools to allow user access files squashed in S3 archive object on demand. If we take an example of a massive small text files archive use case, it is likely you have a large local source code tree wants to be archived to S3. It will be inefficient and costly if you were to inject/ingest tens of thousands files direct to/from S3. With this tool, you can compress and aggregate small files into a single big archive object before upload to S3. Then, when a individual file needs to be accessed later, you can fetch through S3 GetObject API which in behind a S3 Object Lambda function will automatically locate file contents inside of archive object in S3 and extract the only necessary bytes back to user. Very cool indeed.
Make sure you check the notice in the README though, as it does provide additional guidance on how/when to use this:
S3 Squash Archive target for massive small files archive use case, typically once injected seldom access. if your use case need high frequency access full dataset, please upload your file to S3 Object as normal way, by doing this file to S3 object 1x1 mapping, you can get MAX throughput from S3 and it’s most cost effective way.
amazon-s3-tar-tool
amazon-s3-tar-tool or s3tar, is utility tool to create a tarball of existing objects in Amazon S3. s3tar allows customers to group existing Amazon S3 objects into TAR files without having to download the files. This cli tool leverages existing Amazon S3 APIs to create the archives on Amazon S3 that can be later transitioned to any of the cold storage tiers. The files generated follow the tar file format and can be extracted with standard tar tools.
Make sure you read the README as it contains more details around how it works under the hood, some details around pricing considerations, and then some limitations you should be aware of.
aws-serverless-ai-stories
aws-serverless-ai-stories this a new project from AWS Serverless Advocate (and open source bar raiser) David Boyne. I really love the idea behind this, and if you have been following David on social media, you will have seen how this project developed. This project is an example of an event-driven application that generates a new bed time story for your children every night using Lambda, EventBridge, DynamoDB, App Runner, ChatGPT and DALL-E.
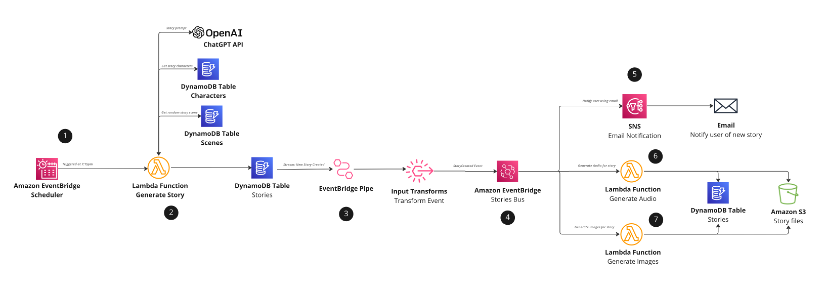
I am happy to say that along with the code, he has put together a blog post, Implementing an event-driven serverless story generation application with ChatGPT and DALL-E, that guides you through implementing this for yourself. This weeks essential read.

earthquake-notifier
earthquake-notifier is an example serverless solution based on Lambda (in Rust), EventBridge and SNS to monitor for earthquakes and send email notifications. Under the hood, it uses the National Institute of Geophysics and Volcanology public APIs (INGV) and scans them every hour.
amazon-keyspaces-python-util-scripts
amazon-keyspaces-python-util-scripts if you are looking to investigate Amazon Keyspaces for Apache Cassandra, then these scripts accompany a tutorial (Scalability and familiarity with Amazon Keyspaces )that will help you gain familiarity with this service. I often find that these scripts that are put together for workshops and tutorials are super helpful, so sharing this project for that reason.
Demos, Samples, Solutions and Workshops
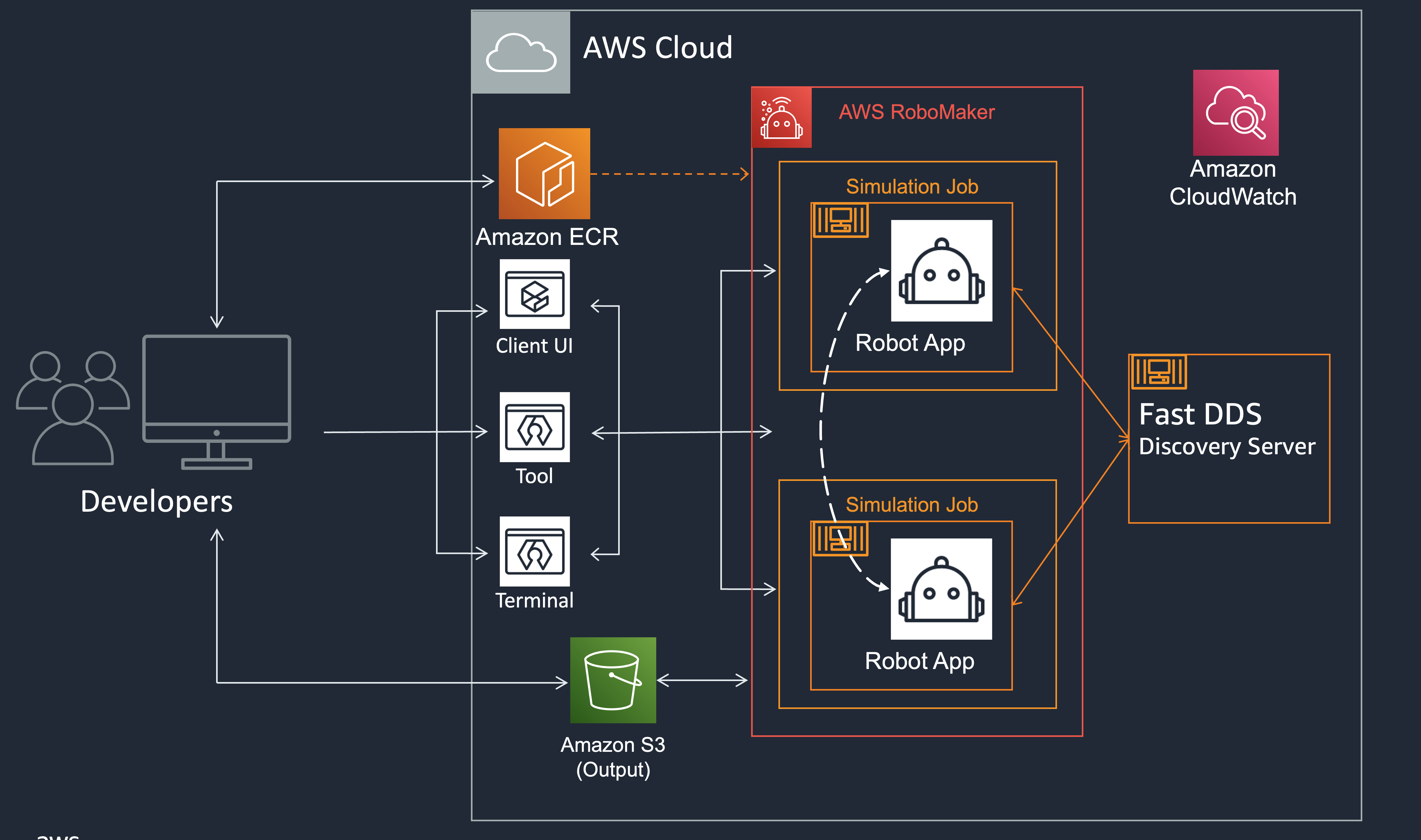
multi-simulation-jobs-aws-robomaker-demo
multi-simulation-jobs-aws-robomaker-demo is a demo that shows how you can enable communication between ROS2 applications deployed in AWS RoboMaker’s multiple simulation jobs. This demo sets up a Docker container format Talker and Listener to do TCP communication through Fast DDS Discovery Server. The source code provides a setting template that can be used when you want to communicate and work with multiple simulation jobs simultaneously using AWS RoboMaker.
AWS and Community blog posts
Amazon Linux 2023
As a big user of Amazon Linux distributions for a while, I am happy that we have now launched the next version, Amazon Linux 2023. In the post, Amazon Linux 2023, a Cloud-Optimized Linux Distribution with Long-Term Support, my colleague Sebastien Stormacq provides a great overview of some of the features, with a focus on security and long term support planning.
Apache Iceberg
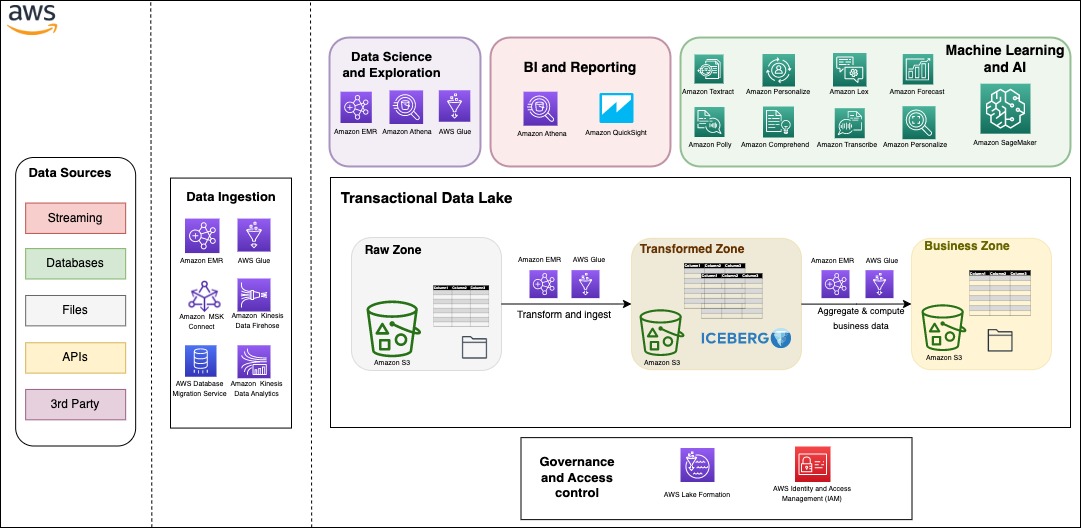
In the post, Build a serverless transactional data lake with Apache Iceberg, Amazon EMR Serverless, and Amazon Athena, Houssem Chihoub provides a hands on guide on how you can build a serverless transactional data lake with Apache Iceberg on Amazon Simple Storage Service (Amazon S3) using Amazon EMR Serverless and Amazon Athena [hands on]
Apache Kafka
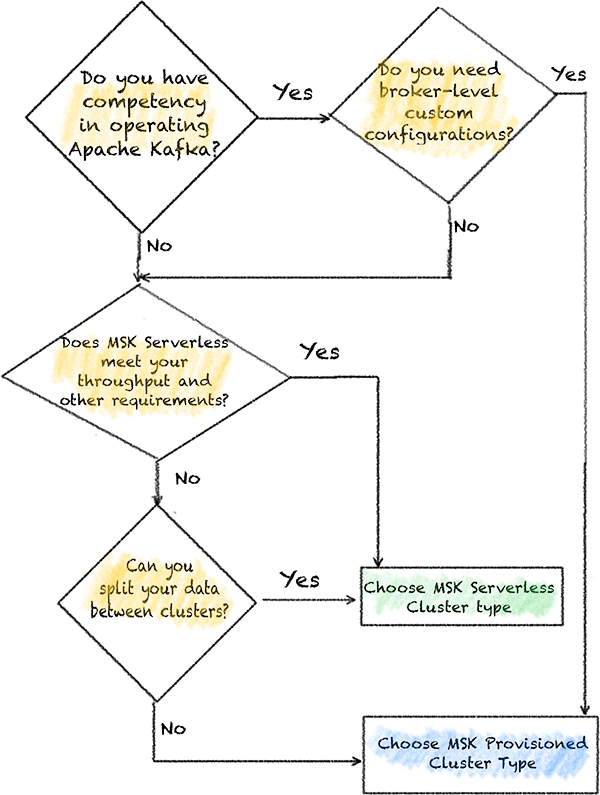
There are many options you have when it comes to how you run your Apache Kafka. In this post, How to choose the right Amazon MSK cluster type for you, Ali Alemi shows you his process that may help you work backward from your application’s requirements and the resources available to you, to find the right choice for you.
Kubernetes
Having spent an increasing amount of time immersed in the world of Kubernetes, I found this next post very helpful. Herbert-John Kelly and Andrew Gargan have penned Automate prework to save time deploying an Amazon EKS Kubernetes cluster, that shows you how you can automate a lot of the configuration work you need to do when setting up your Kubernetes clusters - in this particular case, using CloudFormation. [hands on]
Nextcloud
Nextcloud is an open source platform to store, share and manage files over the web. Following on from a previous post on this project, Helge Aufderheide this time writes, Advanced Nextcloud Workflows with Amazon Simple Storage Service (Amazon S3) that build on that idea and demonstrate advanced functionalities and optimisations, such as starting workflows when you upload a file and optimising your Amazon S3 usage for cost. [hands on]
Other posts and quick reads
- Client-side T-SQL assessment for SQL Server to Babelfish for Aurora PostgreSQL migration shows you how to evaluate the T-SQL queries within the client applications, for assessing the complexity of SQL Server to Babelfish migration [hands on]
- Building Automation for Fraud Detection Using OpenSearch and Terraform shows how you can use OpenSearch reduces the time financial analysts would take to access transactional data by automating data ingestion and replication [hands on]

- Install optimized software with Spack configs for AWS ParallelCluster takes a look at how Spack configs for AWS ParallelCluster make it easy to build tuned versions of several important HPC applications using best practices developed by the AWS HPC Performance Engineering Team [hands on]
- Automate Avalanche node deployment using the AWS CDK: Part 1 looks at operational challenges using AWS primitives and the Rust SDK, and showcases how to do a single-command deployment of Avalanche node using the AWS Cloud Development Kit (AWS CDK) [hands on]

Case Studies
- How Infomedia built a serverless data pipeline with change data capture using AWS Glue and Apache Hudi looks at how Infomedia built a serverless data pipeline with change data capture (CDC) using AWS Glue and Apache Hudi.

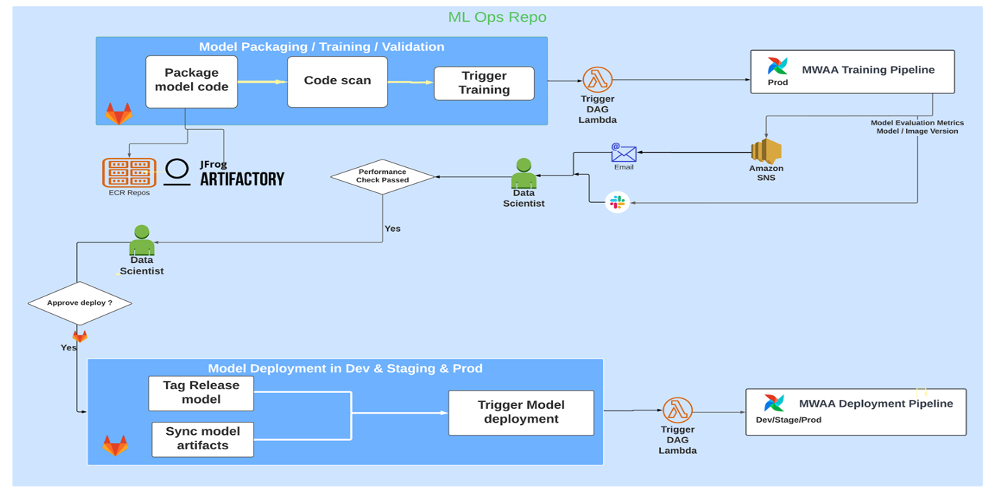
- How VMware built an MLOps pipeline from scratch using GitLab, Amazon MWAA, and Amazon SageMaker shares how VMware Carbon Black and AWS architects built and managed custom ML workflows using Gitlab, Amazon MWAA, and SageMaker.
Quick updates
OpenSearch
The OpenSearch community survey reports were published last week, and Dr. Aparna Sundar put together a post, OpenSearch Project Q1 community survey results, that walked through the highlights. I would encourage you all to check this post out.
Also, have you signed up for the OpenSearch newsletter? Check the latest edition, OpenSearch Project Newsletter - Volume 1, Issue 2 and make sure you bookmark/subscribe to keep up to date with the latest OpenSearch news.
Apache Cassandra
Amazon Keyspaces (for Apache Cassandra) is a scalable, serverless, highly available, and fully managed Apache Cassandra-compatible database service. Amazon Keyspaces now supports client-side timestamps. Client-side timestamps are Cassandra-compatible timestamps that are persisted for each cell in your table. You can use client-side timestamps for cell level conflict resolution by letting applications determine the order of writes. For example, when multiple applications make updates to the same data or when write operations arrive out of order due to variable network latency, Amazon Keyspaces uses these timestamps to process the writes based on the write timestamps of individual cells within rows. To use client-side timestmaps, use the USING TIMESTAMP clause in your Data Manipulation Language (DML) CQL query. With this launch, you can also use the WRITETIME function to see the timestamp value that is stored for a specific cell on tables using client-side timestamps.
Linux
AWS License Manager extends support for delegated administrator to Linux subscriptions discovery and governance capabilities. Using delegated administrator, your management account can give access to another account in your organisation to track Linux subscriptions on AWS. Delegated administrator gives you the flexibility to separate subscription management from billing and other central management tasks.
You can configure AWS License Manager in your central payer or management account and pick another AWS account as the delegated administrator. Once the delegated administrator account is configured, you can discover Linux subscriptions across Regions and accounts, and perform governance tasks such as viewing CloudWatch metrics or setting up alarms.
Amazon EMR
You can now get customer-level metrics when running interactive Spark workloads via managed endpoints. Amazon EMR on EKS enables customers to run open-source big data frameworks such as Apache Spark on Amazon EKS. Amazon EMR on EKS customers can setup and use a managed endpoint (available in preview) to run interactive workloads using integrated development environments (IDEs) such as EMR Studio.
Until now, customers running managed endpoints did not have a mechanism to monitor or visualise kernel-based execution behaviour for them. Without visibility into metrics such as failures, latency or successful launches, customers might experience difficulty troubleshooting and understanding what is happening with a managed endpoint. With this release, customers will be able to monitor, create alarms and better troubleshoot issues in their managed endpoints, by leveraging metrics via Amazon CloudWatch for kernel lifecycle operations such as request counts, request latency, request errors and kernel launch failures.
Videos of the week
IoT Builders Live from Embedded World 2023
The IoT team streamed live from Embedded World 2023 last week, and if you were not able to view live, then you can watch them on replay.
Day One
Day Two
Dyna53
In a previous episode of Build on Open Source, AWS Hero Alvaro Hernandez shared with us a new project he was working with, Dyna53. This project allows you to use Route53 as a database! If that got your attention, great, now find out more by watching your host Namrata H Shah speak with Alvaro.
MEND and CodeCatalyst
This short tutorial from the lovely folk at Mend show you how you can integrate with your source control and quickly detect open source artefacts and their known vulnerabilities and licensing risks. Mend also provides all the information you need to fix these artefacts automatically.
Build on Open Source
If you missed the latest episode of Build on Open Source, Episode 3 looked at this and the previous newsletter, and had special guest, AWS Community Builder John “Preston” Mille to talk about his project, ecs-compose-x. If you missed it, don’t worry you can catch it on replay here
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Empowering Developers using AWS Proton and Backstage AWS User Group Liverpool, Thursday 23rd March
Backstage is an open source project that enables you to build developer friendly portals. “Building Self Service DevOps Platform using Proton and Backstage” discusses in detail about the advantages of leveraging a self service platform for building infrastructure and applications in a Kubernetes application and how to optimise to accelerate developer velocity and best practice adoption in an enterprise container platform.
If you can get to the Liverpool AWS User Group, then this promises to be a great event. Find out more and register here
Build on Open Source March 31st, twitch.tv/aws
The fourth episode of Build on Open Source features special guests Devansh Bawari and Saurav Pathak from Bagisto, a leading open source e-commerce technology. See you there on twitch.tv/aws, Friday 31st March at 9am GMT, 10am CET.
FOSSASIA April 13th-15th, Singapore
FOSSASIA Summit 2023 returns as an in-person and online event, taking place from Thursday 13th April to Saturday 15th April at the Lifelong Learning Institute in Singapore.
If you are interested in attending in person, or virtually, find out more about the event at the FOSSASIA Summit 2023 page.
AWS Community Nordics April, 20th Helsinki
The AWS Community Day Nordics is a free full day event for AWS users to come together to network, learn from each other and get inspired. The event is organised by the community - for the community. The cfp is currently open, so if you are in the area and want to talk then here is your chance. Check out the full event details and save your space here, AWS Community Nordics registration page
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen