AWS open source newsletter #145
Feb 20th, 2023 - Instalment #145
Welcome to edition #145 of the AWS open source newsletter. I hope some of you were able to catch the new Build on Open Source show we live streamed last Friday. You can catch up and replay the session by clicking on this link, where we went over a number of projects from this and a few previous newsletters, and we had special guest Valter who walked us through his project terraform-dev-containers. During this episode we asked viewers to provide some quick feedback as to let me know what you find most useful from reading this newsletter. Please take 10 seconds to let me know by clicking on the Twitter Poll here
It has been two weeks since the last newsletter, so this week we have a bumper edition with plenty of great new open source projects for you to try out. We have “ses-sidecar” which provides a way of using IAM Roles with Amazon SES, “centralized-logs” a tool to help you replicate your CloudWatch logs, “ccExplorer” a cli tool to show your AWS resource costs, “boto-formatter” a neat tool that provides additional output formats for boto3, “redshift-migrate-db” a tool to simplify migrations in Amazon RedShift, “aws-break-glass-role” a nice example of implementing this control in your secure environments, “dynamic-ec2-budget-control” a tool to help cost optimisation for HPC workloads, “visualize-iam-access-analyzer-policy-validation-findings” does what it says on the tin, “amazon-kinesis-data-streams-health-check” a tool that helps you ensure your Amazon Kinesis streams are what you expect, and many more!
Also covered this week are some great open source technologies, including Apache Flink, Apache Spark, Kubernetes, Amazon EKS, Apache Iceberg, Argo Workflows, Quarkus, OpenSearch, PostgreSQL, AWS Amplify, AWS ParallelCluster, AWS SAM, AWS CDK, Apache Airflow, Amazon EMR, Redis, OCSF, HBase, Grafana, Prometheus, Karpenter, and more!
Before you dive into the newsletter, check out the following information in how you can possible help with the recent Turkey/Syria Earthquake disaster.
VOLUNTEERS NEEDED - Active disaster volunteer opportunities
Turkey/Syria Earthquake 2023 | Humanitarian Mapping Opportunity
HOW YOU CAN HELP? Volunteers will use HOT’s Map Tasking Manager to trace satellite imagery that helps responders identify priority areas and more efficiently plan aid to people in need. HOT runs on AWS and is built on top of OpenStreetMap data. OSM is a free, editable map of the world, created and maintained by volunteers and available for use under an open license.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Aidan Steel, Colin Dugan, Syed Rehan, Lukonde Mwila, Paul Hidalgo, Rupal Mahajan, Joshua Bright, Anirudha Jadhav, Joshua Li, and Sayali Gaikawad, Fabio Oliveira, Petri Kallberg, George Zhao, Kalen Zhang, Jiseong Kim, SungYoul Park, Luis Gerardo Baeza, SaiKiran Reddy Aenugu, Narendra Merla, Subhro Bose, Eva Fang, and Ketan Karalkar, Andriy Redko, Francesco Tisiot, and Payal Singh.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
ses-sidecar
ses-sidecar the first of two tools from Aidan Steel. This repo contains code that allows you to deploy an SMTP server sidecar to allow AWS SES usage with IAM roles. AWS SES has an SMTP interface, but it doesn’t support IAM roles, so this proof of concept helps fix that. As Aidan says:
“I’m on a personal crusade against IAM users, so I made an SMTP server designed to run as a sidecar to your legacy app that speaks SMTP, but needs to use IAM role credentials. "
centralized-logs
centralized-logs another tool from Aidan Steel that provides a code-less solution to aggregating AWS CloudWatch log subscriptions across multiple AWS accounts and regions. It uses Kinesis Firehose (for aggregation and forwarding), EventBridge (for notifications about new log group creation) and Step Functions (for assuming roles cross-account and calling the AWS SDK).
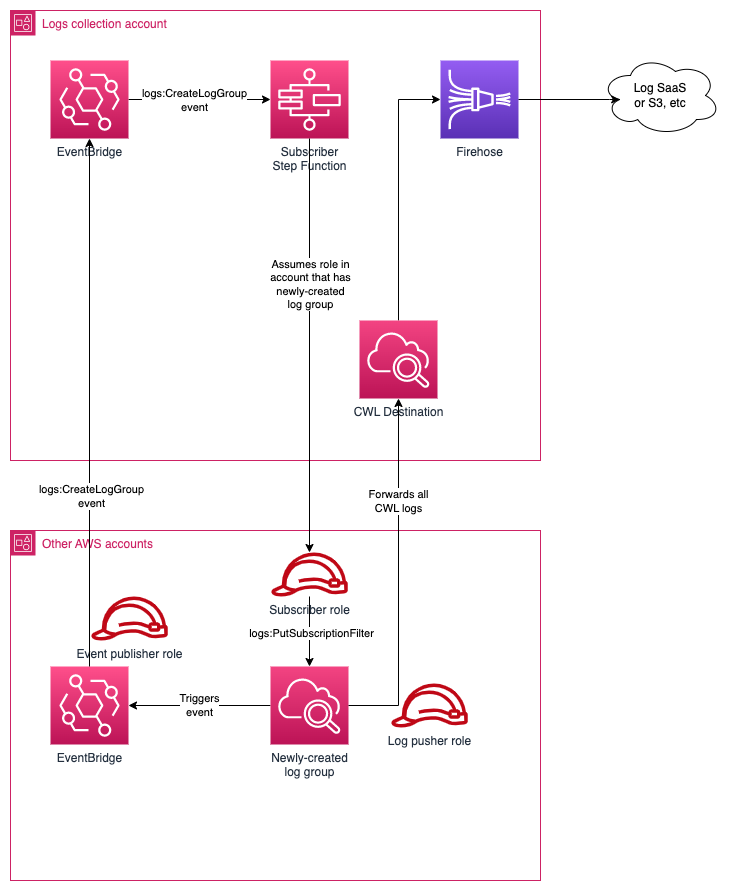
aws-cloudwatch-dashboard-generator-for-infrastructure-event-management
aws-cloudwatch-dashboard-generator-for-infrastructure-event-management is a command line tool is to generate a CloudWatch Dashboard which is based on a list of resources you provide and contains predefined useful CloudWatch metrics selected by AWS Support engineers for monitoring AWS resources during special events or IEM (AWS Infrastructure Event Management) scenarios.
The tool is quite simple. It reads a CSV file to get your resource IDs, then output the dashboard JSON to the directory you specified. The README provides examples on how to create the CSV input file, the supported AWS resource types, and more.
ccExplorer
ccExplorer (Cloud cost explorer) is a simple command line tool from Colin Duggan to help you explore the cost of your cloud resources. It’s built on open source tools like cobra, go-echarts, and go-pretty. It lets you quickly surface cost and usage metrics associated with your AWS account and visualise them in a human-readable format like a table, csv file, or chart. It was created so I could quickly explore and reason about service costs without switching context from the command line. It’s not designed as a replacement for the official AWS COST Explorer CLI but does provide some nice features for visualisation and sorting. I deployed this using the information in the README and it was easy to get started. There are also plenty of example recipes to get you going. For folk who love living in the terminal, this project is a must check out.
boto-formatter
boto-formatter is decorator that convert standard boto3 function response (returned as python list) in flattened JSON or tabular CSV formats for list of supported services and functions. You can output the response to print, file or send flattened columnar JSON list to another function to continue your process. boto_formatter simplifies the process and reduce the need of writing custom codebase potentially of 100s of line of code to 4-5 lines of code for simple use cases like generating list of lambda functions or list of cloudfront distriubtions with all the attributes that AWS Python SDK provides.
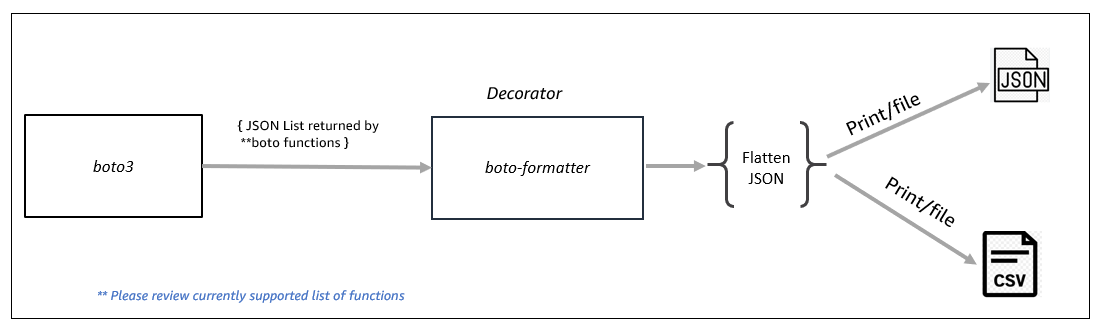
redshift-migrate-db
redshift-migrate-db this tool helps you to migrate a single database within an Amazon Redshift cluster to another cluster via Datasharing. Datasharing is a capability within Amazon Redshift where you can share live data with relative security and ease across Amazon Redshift clusters, AWS accounts, or AWS Regions for read purposes.
aws-break-glass-role
aws-break-glass-role this repo helps you create a break glass role for emergency use in order to limit production console access. Why would you need such a thing I can hear you all thinking (my Jedi skills are strong!).
Often when undergoing security reviews for applications in a full CI/CD deployment environment, it is recommended to restrict console access to the AWS account that hosts the production environment. A popular way to implement this recommendation is to remove all production write access completely from user and role policies. In these cases it may be necessary to provision a user or role with elevated permissions to be used only in emergency cases. This type of role is typically called a “Break Glass Role” and is usually used in On Call situations or other circumstances when quick mitigating action is needed.
Read the rest of the README to help you understand more how you can go about implementing this approach in your own environments.

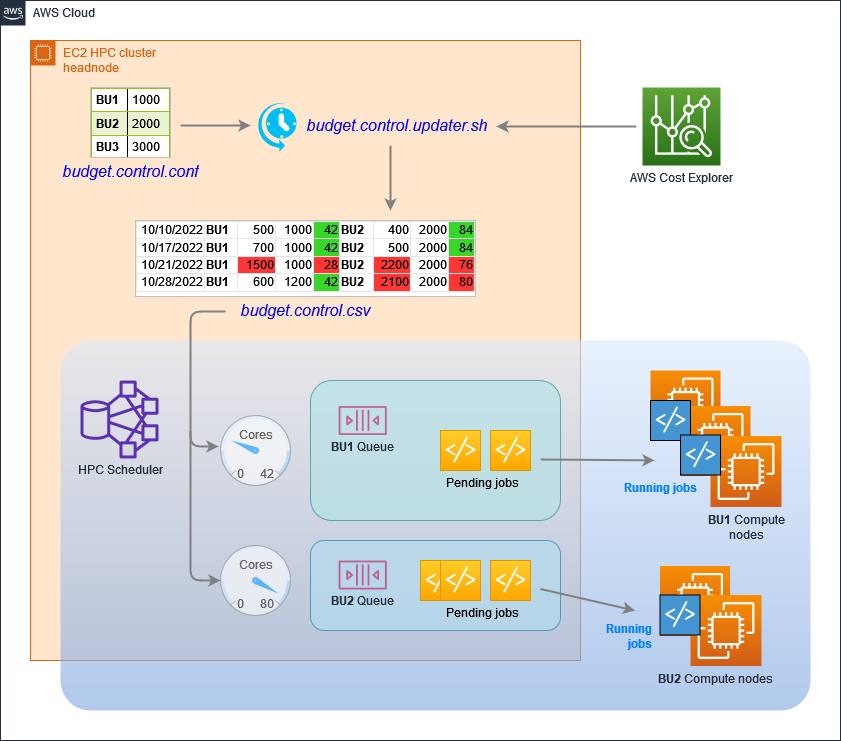
dynamic-ec2-budget-control
dynamic-ec2-budget-control is a project for those running HPC workloads that will provide you with some more options to help manage costs. This solution uses a dynamic EC2 cores allocation limit for each business unit (BU), automatically adapted according to a past time frame (e.g. one week) spending, that can be adapted anytime according to workload spikes or priorities. EC2 cores allocation limit is enforced in the HPC workload scheduler itself, with the use of its dynamic resources. HPC jobs breaking the limit will be kept in queue/pending status until more cores are released by completed, older jobs. With this approach, a related job pending reason is also provided to both business or job owners, making them aware of their spending implications.
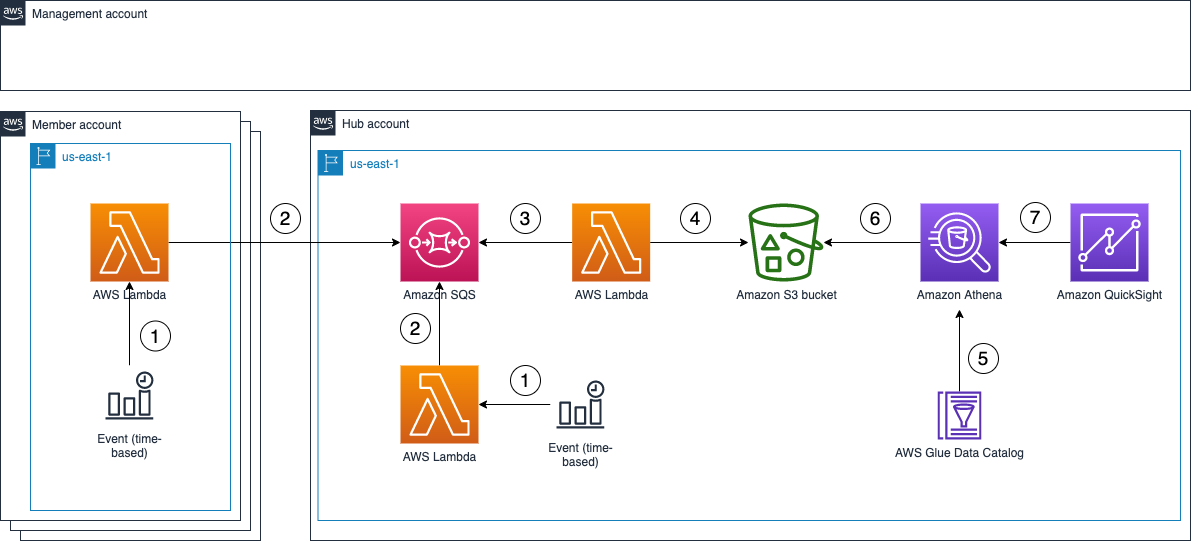
visualize-iam-access-analyzer-policy-validation-findings
visualize-iam-access-analyzer-policy-validation-findings how to create an Amazon QuickSight dashboard to visualise the policy validation findings from AWS Identity and Access Management (IAM) Access Analyser. You can use this dashboard to better understand your policies and how to achieve least privilege by periodically validating your IAM roles against IAM best practices.
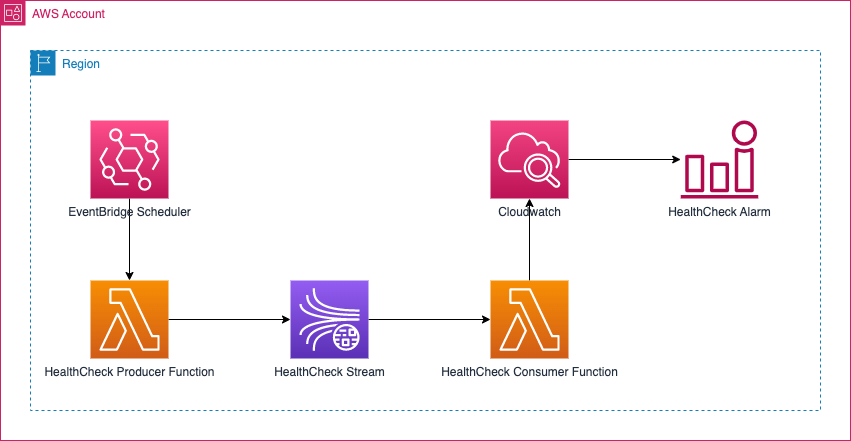
amazon-kinesis-data-streams-health-check
amazon-kinesis-data-streams-health-check provides an example approach to demonstrate health checking the Kinesis Data Streams service by producing a tracer message to a health-check stream and consuming it, to produce a realtime custom metric to CloudWatch. The custom metric can in turn be used to setup an Alarm for immediate alerting in case producing and consuming capabilities to the service are impaired.
Demos, Samples, Solutions and Workshops
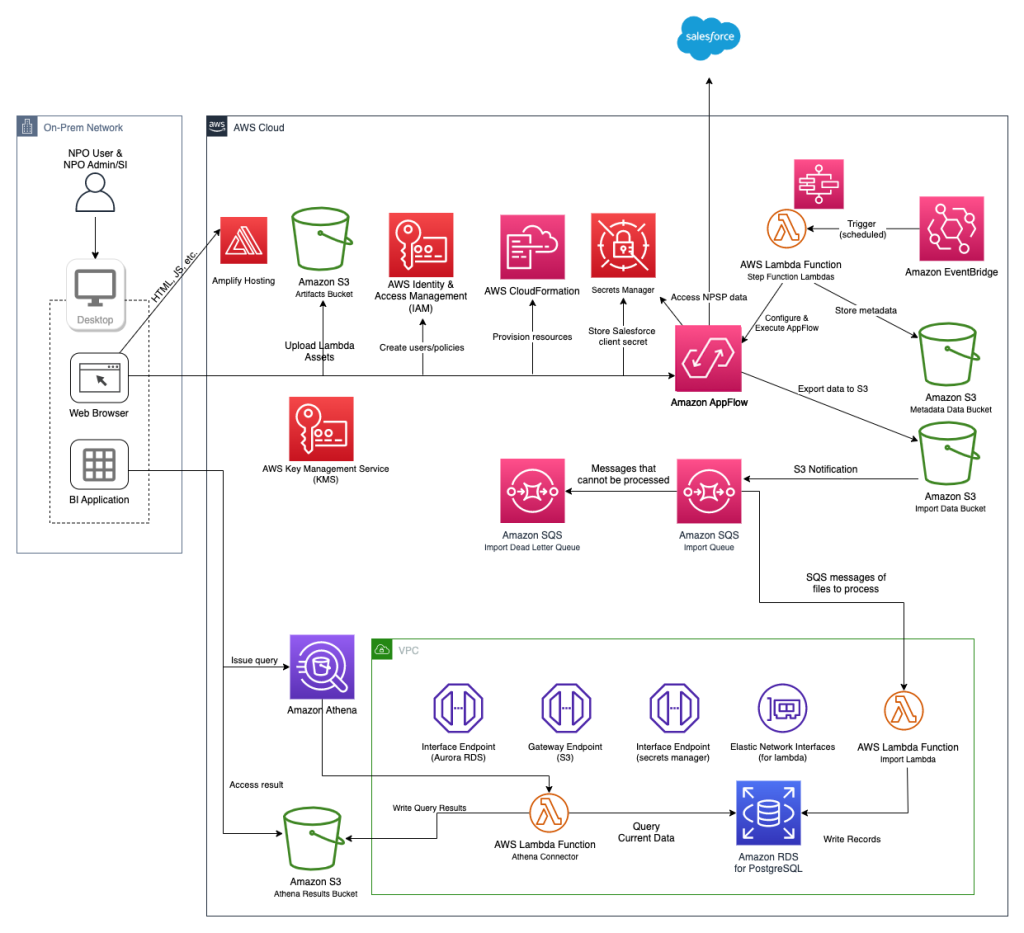
Data-Lake-for-Nonprofits
Data-Lake-for-Nonprofits is an open source application that helps nonprofit organisations set up a data lake in their AWS account and populate it with the data that they have in the Salesforce Non Profit Success Pack (NPSP) schema. It uses AWS Amplify to provide a nice easy to use front end, and you can see what this looks like and dive deeper by reading the post, Dive Deeper into Data Lake for Nonprofits, a New Open Source Solution from AWS for Salesforce for Nonprofits
spark-on-aws-lambda
spark-on-aws-lambda is a standalone installation of Spark running on AWS Lambda. The Spark is packaged in a Docker container, and AWS Lambda is used to execute the image along with the PySpark script. Currently, heavier engines like Amazon EMR, AWS Glue, or Amazon EMR serverless are required for event driven or streaming smaller files to use Apache Spark. When processing smaller files under 10 MB in size per payload, these engines incur resource overhead costs and operate more slowly(slower than pandas). This container-based strategy lowers overhead costs associated with spinning up numerous nodes while processing the data on a single node. Use Apache Spark on AWS Lambda for event-based pipelines with smaller files if you’re seeking for a less expensive choice, according to customers.
multi-pipeline-serverless-web-application-with-cdk
multi-pipeline-serverless-web-application-with-cdk This project allows you to build a serverless web application with multiple pipelines managed separately by your infrastructure and development teams. By provisioning this project, you can see and experience whether a serverless architecture will behave the same as a traditional architecture. Detailed and comprehensive README will help you navigate this sample.
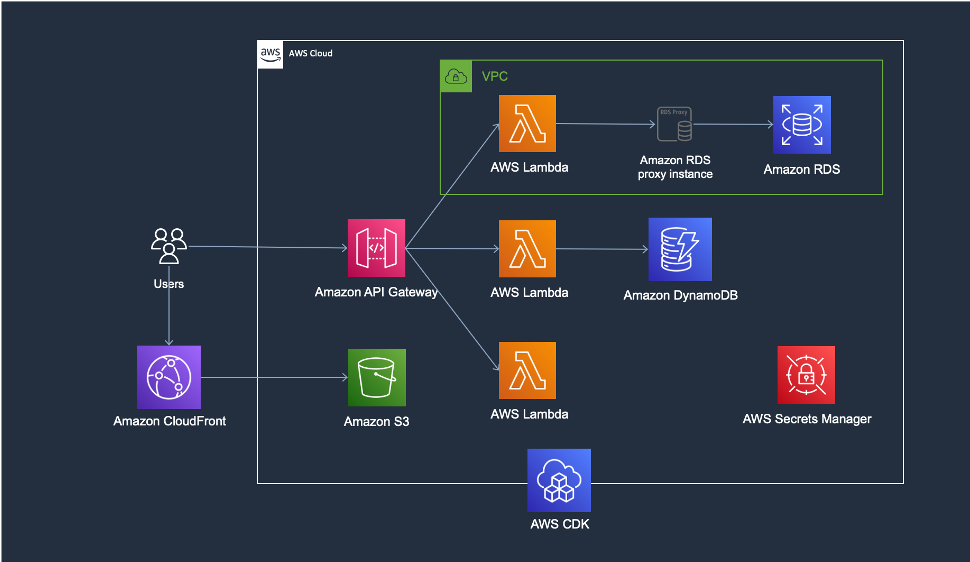
eks-container-pipeline-cdk-template
eks-container-pipeline-cdk-template is a CDK TypeScript project that packages a sample application into a container. This does require you have an existing Amazon EKS Cluster up and running before hand, but the README shares a link to help you. The code sample deploys the following resources:
- CodeCommit repository to store the Sample App
- ECR registry to store the Sample App image
- CodeBuild project to build Sample App images on ARM or x86
- SNS Notifications to update end users on the status of the build
- CodePipeline to perform the build stages and release to production
- Unit tests definition and a report group to display unit tests results in CodeBuild
- CodeBuild project to deploy a container to EKS
breweries-sitewise-simulator
breweries-sitewise-simulator This repository contains a Python based simulation of a Brewery manufacturing process. The code produces factory like data exposed via an OPC UA Server (a cross-platform, open-source, IEC62541 standard for data exchange from sensors to cloud applications developed by the OPC Foundation) for consumption by an OPC UA Client (like the IoT SiteWise OPC UA Collector). In addition, you can configure the publishing of values directly to IoT SiteWise at a specified interval. You can then if you want use it to exercise the capabilities of IoT SiteWise (Monitor), IoT Greengrass, IoT TwinMaker, and other IoT based AWS services.
serverless-patient-engagement-stack
serverless-patient-engagement-stack is a simple implementation that leverages the powers of Amazon Pinpoint and Amazon Connect to influence positive healthcare outcome through timely notifications to the patients about their upcoming events related their health protocol. The assignment of health protocol begins when the patient meets their physician/health care provider. The care provider develops a health protocol that is inline with patient care events and activities; Then the physician assigns that protocol with a specific patient. As someone who has recently started to take blood pressure medication, I might give this a try.
employee-shift-scheduling-optimization-cdk
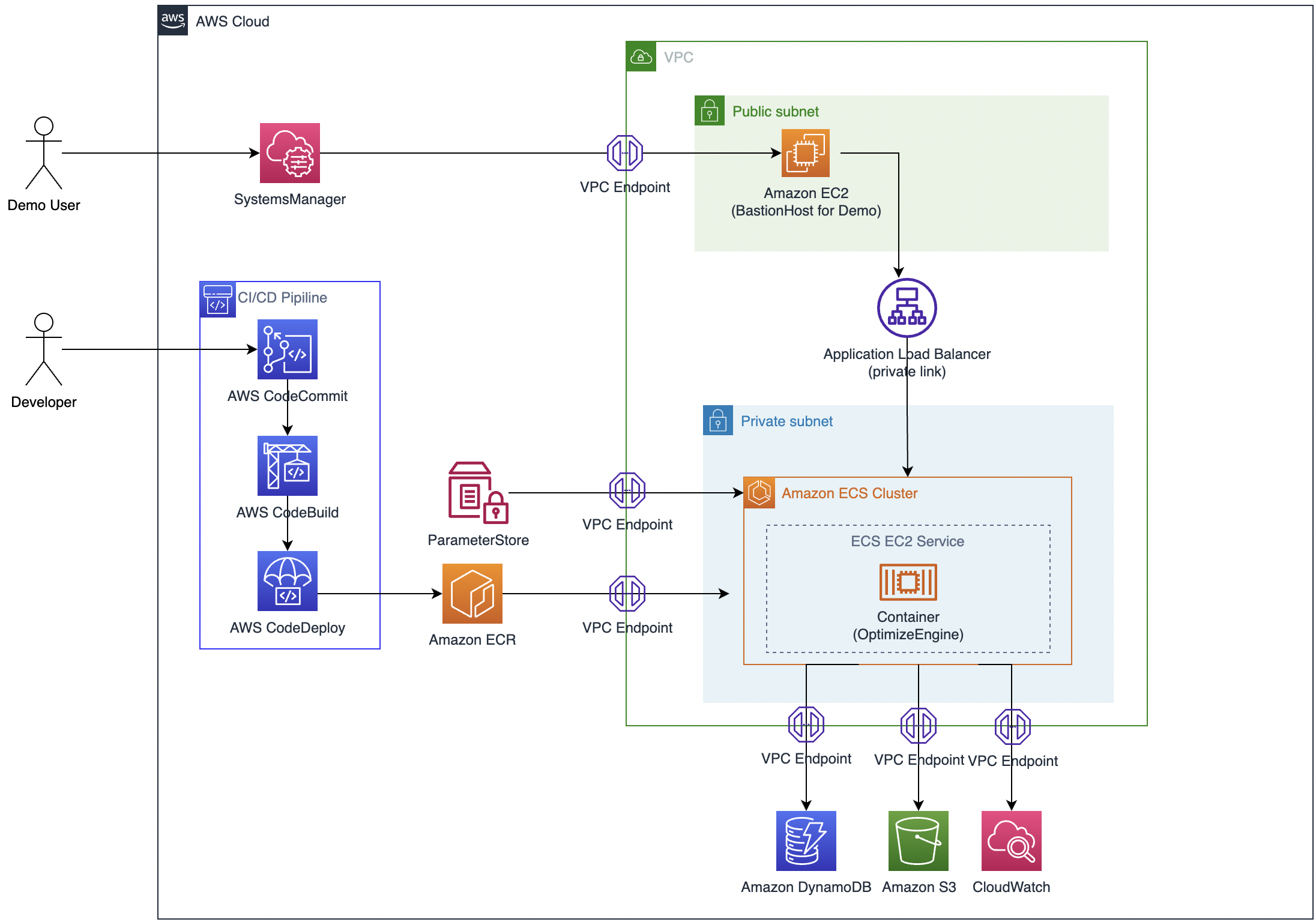
employee-shift-scheduling-optimization-cdk this project let you provision an example employee shift scheduling application using Amazon ECS. The application provides REST API using a private load balancer.
AWS and Community blog posts
Sustainable open source
Essential reading this week is this post from David Nalley, AWS: Why We Support Sustainable Open Source. David covers the three key areas on why AWS invests heavily in open source, and how these combine to help ensure sustainable open source. On a related note, also published last week was this post, AWS Teams with OSTIF on Open Source Security Audits, where Mark Ryland announced that AWS is sponsoring open source software security audits by the Open Source Technology Improvement Fund (OSTIF), a non-profit dedicated to securing open source. This funding is part of a broader initiative at AWS to support open source software supply chain security.
Apache Airflow
In the post, Improve observability across Amazon MWAA tasks Payal Singh provides an overview of logging enhancements when working with Amazon MWAA, and then discuss a solution to further enhance end-to-end observability by modifying the task definitions that make up the data pipeline. This is a very cool post and solution, so if you are using Apache Airflow then this is a must read! [hands on]

Apache Flink and OpenSearch
Great post from Andriy Redko and Francesco Tisiot, taking a look at how the Apache Flink Connector for OpenSearch bridges both by enabling you to push the outcome of data transformations directly to an OpenSearch index. Sound interesting? If so, read on in Apache Flink Connector for OpenSearch [hands on]
Apache Hudi
Apache Hudi is a transactional data lake platform that brings database and data warehouse capabilities to the data lake. As your data changes, often this will lead to updating of your table structure. Schema evolution is the addition of new columns, removal of existing columns, update of column names, and so on. In the post, Automate schema evolution at scale with Apache Hudi in AWS Glue Subhro Bose, Eva Fang, and Ketan Karalkar focus on how you can drive those schema changes automatically between your databases and data lakes in a cost effective way.
Apache Iceberg
In the post, Automate replication of relational sources into a transactional data lake with Apache Iceberg and AWS Glue, Luis Gerardo Baeza, SaiKiran Reddy Aenugu, and Narendra Merla show you how you how to easily replicate all your relational data stores into a transactional data lake in an automated fashion with a single ETL job using Apache Iceberg and AWS Glue.
Hadoop
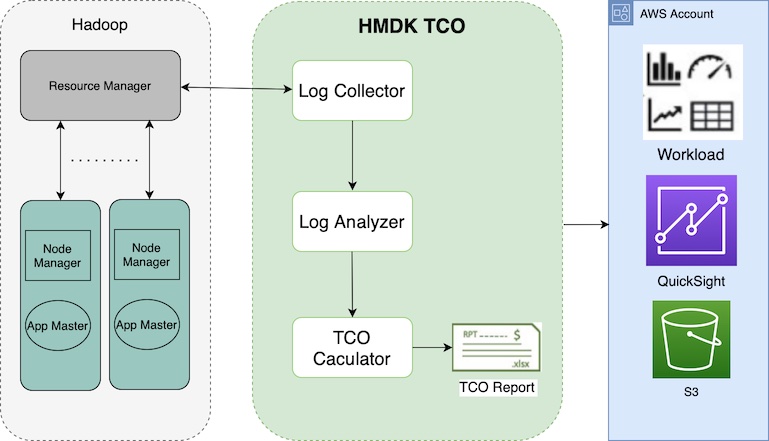
In the AWS open source newsletter #139 I shared a project called migration-hadoop-to-emr-tco-simulator, that provides you with help if you are looking to move off self managed Hadoop, and migrate onto a managed service like Amazon EMR. You can now read this post, Introducing the AWS ProServe Hadoop Migration Delivery Kit TCO tool where George Zhao, Kalen Zhang, Jiseong Kim, and SungYoul Park look at the use case and the functions and components of the tool, share case studies to show you the benefits of using the tool, and finally show you the technical information to use the tool.
Quarkus
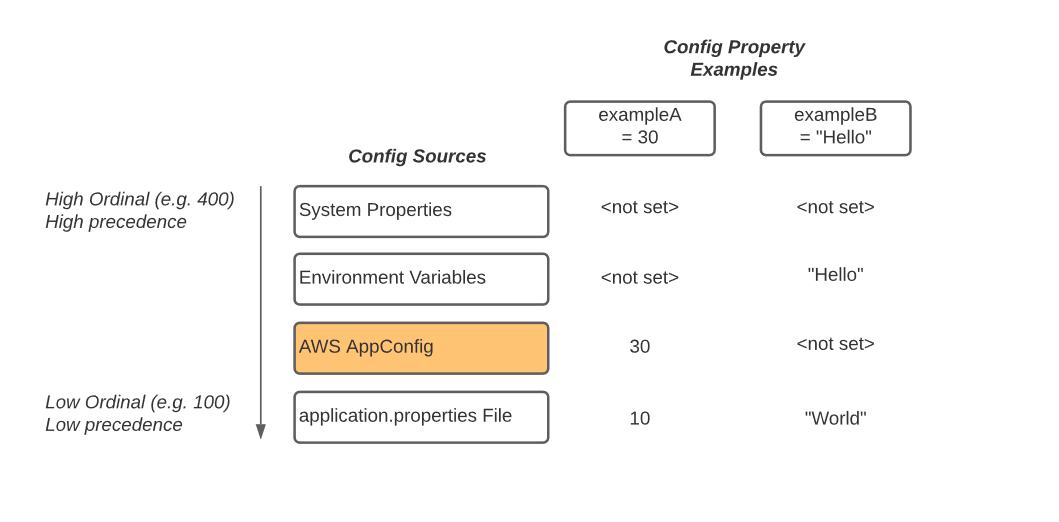
In the post, Implementing a custom ConfigSource in Quarkus using AWS AppConfig, Fabio Oliveira and Petri Kallberg show you how the configuration mechanism in Quarkus can be extended and how we can access configuration stored in AWS AppConfig over the standard @ConfigProperty API available in Quarkus, so developers can enjoy the smooth developer experience they are used to in Quarkus. [hands on]
Karpenter
Karpenter is an open source project built to solve issues pertaining to optimal node selection in Kubernetes. Karpenter’s what-you-need-when-you-need-it model simplifies the process of managing compute resources in Kubernetes by adding compute capacity to your cluster based on a pod’s requirements. In this post, Optimizing your Kubernetes compute costs with Karpenter consolidation, Lukonde Mwila explores Karpenter’s consolidation capabilities and walks through the impact it can have on optimising Kubernetes data plane costs with a hands-on example. [hands on]
Other posts and quick reads
- Driving Action and Communication in AWS Amplify Open Source Projects looks at some processes and tools that the AWS Amplify team use to help build a vibrant and responsive open source community
- Achieve up to 27% better price-performance for Spark workloads with AWS Graviton2 on Amazon EMR Serverless discusses the performance improvements observed while running Apache Spark jobs using AWS Graviton2 on EMR Serverless
- Announcing General Availability of Amazon EKS Anywhere on Snow provides a hands on guide on getting EKS Anywhere up and running on AWS Snowball Edge devices [hands on]

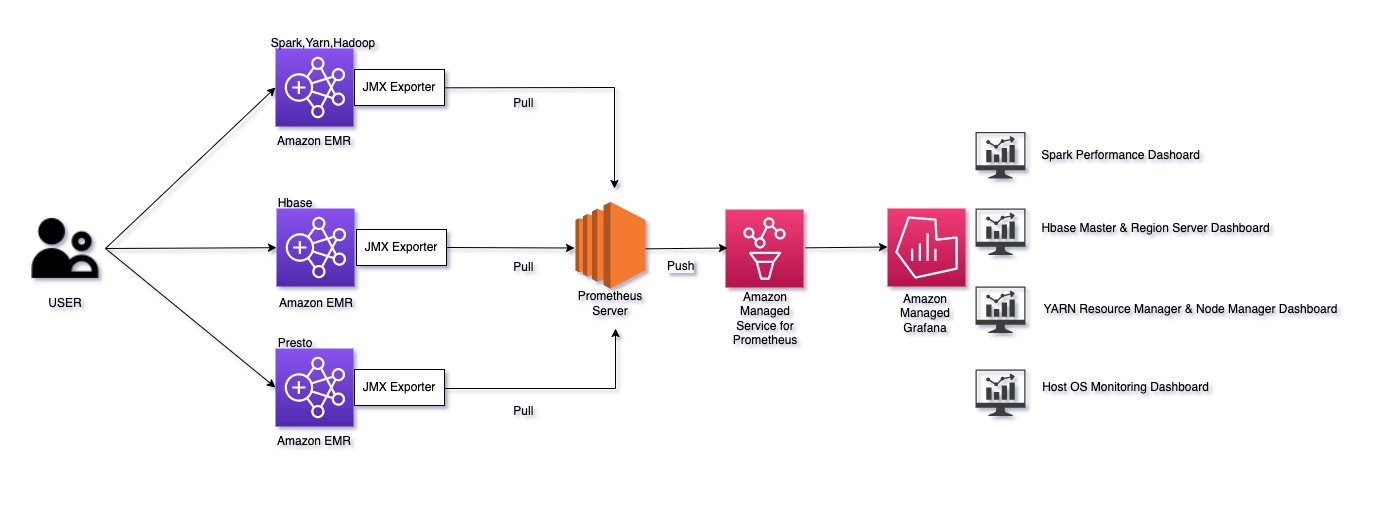
- Monitor Apache HBase on Amazon EMR using Amazon Managed Service for Prometheus and Amazon Managed Grafana shows how to use Prometheus exporters to monitor EMR HBase clusters and set up dashboards to visualise key metrics in Grafana [hands on]
- Analyze healthcare FHIR data with Amazon Neptune looks at how you can reduce the complexity of analysing healthcare Fast Healthcare Interoperability Resources (FHIR, an open industry standard for passing healthcare data between systems) data, using SPARQL to perform different queries on the data [hands on]

- Manage collation changes in PostgreSQL on Amazon Aurora and Amazon RDS explores how text collations work in PostgreSQL, the effect on PostgreSQL when the collation changes, and how to detect these changes [hands on]
Quick updates
Kubernetes
If you were a fan and user of the Amazon EKS Workshop, then you will be happy to hear that this has been redesigned and relaunched. You can still access the old workshop if you want. Find out more by reading the announcement, Introducing the Amazon EKS Workshop
AWS SDK for Java 2.x
Announced last week was the AWS Common Runtime (CRT) HTTP Client in the AWS SDK for Java 2.x. With release version 2.20.0 of the SDK, the AWS CRT HTTP Client can now be used in production environments.
The AWS CRT HTTP Client is an asynchronous, non-blocking HTTP client that can be used by AWS service clients to invoke AWS APIs. You can use it as an alternative to the default Netty implementation of the SdkAsyncHttpClient interface. It offers faster SDK startup time and smaller memory footprint, which is especially important with AWS Lambda, as well as lower P90 latency and enhanced connection management.
Dive deeper by reading the post, Announcing availability of the AWS CRT HTTP Client in the AWS SDK for Java 2.x
AWS ParallelCluster
Previous versions of AWS ParallelCluster enabled HPC clusters in a single Amazon EC2 Availability Zone. With AWS ParallelCluster 3.4.0, you can now create clusters that use multiple Availability Zones in a Region. This gives you more options to provision computing capacity for your HPC workloads.
You can find out more by reading the post, Multiple Availability Zones now supported in AWS ParallelCluster 3.4
MySQL
Amazon Relational Database Service (Amazon RDS) for MySQL now supports MySQL minor versions 5.7.41 and 8.0.32. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MySQL, and to benefit from the numerous fixes, performance improvements, and new functionality added by the MySQL community.
PostgreSQL
PostgreSQL extensions are libraries that supply extra functions, operators, or data types to the core database engine. Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports the tcn extension which provides a trigger function that allows you to asynchronously notify listeners of changes to a table. tcn, or triggered change notification, is a function that generates NOTIFY events on changes to data in specified tables. This is useful for applications that need to take action on data changes in near-real time such as updating displays of information or cached data.
Another extension that was also added last week was the seg extension which provides the “seg” data type for representing line segments or floating point intervals.The seg extension provides a data type with operators that allow for storing and querying of line segments or intervals with arbitrary variable precision. This is useful for applications needing to represent laboratory measurements.
OpenSearch
The OpenSearch Project announced last week the release of the Reporting CLI, making it convenient to generate reports externally without logging in to OpenSearch Dashboards. This gives you the flexibility to programmatically generate reports and connect them to your preferred messaging system. You can now schedule and transport reports efficiently through email.
Check out the post, What’s new: OpenSearch Reporting CLI where Rupal Mahajan, Joshua Bright, Anirudha Jadhav, Joshua Li, and Sayali Gaikawad dive deeper into this new release.
Amazon EMR
Last week a new capability was announced for Amazon EMR on EKS to increase job execution resiliency. Until now, users had to build their own custom job execution retry mechanism outside of Amazon EMR on EKS, to make sure their Spark jobs keep running in case of failure. With this feature, users can now save time and keep their business-critical and long-running streaming workloads running, by having Amazon EMR on EKS automatically re-submit jobs in case of failure. With job retries, once you define a retry policy by providing the amount of attempts to limit executions to, Amazon EMR on EKS will enforce and monitor this policy during each job execution, giving you visibility via the DescribeJobRun API and AWS CloudWatch events of each retry being performed.
Also announced was an update to Amazon EMR Serverless. Previously, the largest worker configuration available on EMR Serverless was 4 vCPUs with up to 30 GB memory. Today, we are excited to announce that EMR Serverless now offers worker configurations of 8 vCPUs with up to 60 GB memory and 16 vCPUs with up to 120 GB memory, allowing you to run more compute or memory-intensive workloads on EMR Serverless. You can read more about this by checking out the blog post, Amazon EMR Serverless supports larger worker sizes to run more compute and memory-intensive workloads
Redis
Amazon ElastiCache for Redis 7 now includes enhanced I/O multiplexing, which delivers significant improvements to throughput and latency at scale. Enhanced I/O multiplexing is ideal for throughput-bound workloads with multiple client connections, and its benefits scale with the level of workload concurrency. As an example, when using r6g.xlarge node and running 5200 concurrent clients, you can achieve up to 72% increased throughput (read and write operations per second) and up to 71% decreased P99 latency, compared with ElastiCache for Redis 6.
For throughput-bound workloads with multiple client connections, network I/O processing can become a limiting factor in the ability to scale. Since March 2019, ElastiCache for Redis optimizes compute utilization by handling network I/O on dedicated threads, allowing the Redis engine to focus on processing commands. With this launch, each dedicated network I/O thread pipelines commands from multiple clients into the Redis engine, taking advantage of Redis' ability to efficiently process commands in batches.
You can read more about this in the supporting blog post, New for Amazon ElastiCache for Redis 7: Get up to 72% better throughput with enhanced I/O multiplexing
AWS SAM
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) announces the launch of sam list command, helping developers access information about deployed resources while they are testing their SAM applications. The AWS SAM CLI is a developer tool that makes it easier to build, test, package, and deploy serverless applications.
Customers can now use the SAM CLI to inspect resources that are defined in their SAM application or deployed within a CloudFormation stack, including the endpoints, methods and stack outputs required to test the deployed application. Previously, customers had to use AWS Console to retrieve specific values per resource, like endpoint URL, and use these retrieved values in their preferred testing tool to invoke their application. With this launch, SAM CLI users can avoid the context switch during testing their applications and retrieve the information they need via sam list command, speeding up their iteration cycles.
This feature is available with SAM CLI version 1.72.0+
Videos of the week
Open Sourcery Ep. 2: VGV + AWS Amplify
It is always great to see new open source shows on Twitch and You Tube. Open Sourcery started off as a show and tell from VGV, and I am delighted they are going public. Make sure you support these kinds of shows to get even more open source content out there. In this episode, join Felix, Renan, and Jochum and special guests Salih and Abdallah from AWS Amplify as they discuss interesting projects they’re working on and share some of the magic happening in the Flutter community and beyond!
Unifying Your Security Data with Amazon Security Lake and OCSF
Launched at re:Invent, the Open Cybersecurity Schema Framework (OCSF) is an open-source project, delivering an extensible framework for developing schemas, along with a vendor-agnostic core security schema. In this video taken from the AWS User Group in Singapore, Paul Hidalgo looks at how this fits in with Amazon Security Lake, allowing it to normalise and combine data from AWS and a range of other sources.
Protobuf with AWS IoT using Open source tooling
Join Syed Rehan as he look at how we can use binary payload such as Protobuf using open source tools and send that payload to the AWS IoT core and see the decoded data downstream into the Amazon S3 bucket.
Self-Service Kubernetes Development with ArgoCD
If you missed this session from the Containers from the Couch show (Subscribe if you have not already, you can thank me later) in this video, Lukonde Mwila shows you how you can create a self-service model for Kubernetes development, demonstrating how you can create such a workflow with a hands-on example using ArgoCD’s ApplicationSets.
Build on Open Source
Build on Open Source is BACK!! Season Two has kicked off, with the first episode just streamed. I hope some of you were able to catch it. If not, you can watch it on replay here
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
Data Science on AWS Feb 20th, Online
Join regular hosts Antje Barth and Chris Fregly as they are joined by guests to talk about moving from research to production at scale with PyTorch and look at generative AI in action. Find out more and register on the meetup page, Research to Production at Amazon Scale With PyTorch + Generative AI in action
PGConf India Feb 22nd to 24th, Radisson Blu Bengaluru, India
If you are in or can get to Bengaluru, then checkout this conference for PostgreSQL developers and enthusiasts. Check out the session line up and get your tickets here.
Power Up your Kubernetes March 15th, AWS Office Zurich, Switzerland
If you want to improve architecture, scaling and monitoring of your applications that run on AWS Elastic Kubernetes Service, this event is for you. During this event you will learn to scale Kubernetes applications with Karpenter, monitor your workloads, and build SaaS architectures for Kubernetes.
Find out more and save your place by heading over to the registration page, Power up your Kubernetes on AWS
Everything Open March14-15th Melbourne, Australia
A new event for the fine folks in Australia. Everything Open is running for the first time, and the organisers (Linux Australia) have decided to run this event to provide a space for a cross-section of the open technologies communities to come together in person. Check out the event details here. The CFP us currently open, so why not take a look and submit something if you can.
FOSSASIA April 13th-15th, Singapore
FOSSASIA Summit 2023 returns as an in-person and online event, taking place from Thursday 13th April to Saturday 15th April at the Lifelong Learning Institute in Singapore.
If you are interested in attending in person, or virtually, find out more about the event at the FOSSASIA Summit 2023 page.
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen