AWS open source newsletter #144
Feb 5th, 2023 - Instalment #144
Welcome to edition #144 of the AWS open source newsletter, and another week of great new open source projects for you to try out. Some of the treats in store for you this week include “dynamodb-shell”, a project that provides a cli to your favourite AWS database, “precloud” a tool to help you catch issues with your configuration before you deploy, “node-latency-for-k8s” a tool to analyse your node logs, “stepfunctions-lambda-ec2-ssm” a very nice way of using step functions to overcome the 15 minute timeout of your lambda functions, “terraform-ec2-image-builder-container-hardening-pipeline” a very cool example of how to build an EC2 image hardening pipeline using Terraform, and “cloudtrail-event-fuzzy-viewer” a tool to copy your AWS CloudTrail events and then fuzzy search them on the command line. We also have some great sample code to help you build on AWS, including “aws-deployment-pipeline-reference-architecture”, “aws-eks-quarkus-example”, “gitops-eks-r53-arc”, and more.
Also covered this week are some great open source technologies, including Apache Flink, Terraform, Apache Spark, Delta Lake, Apache Iceberg, Bottlerocket, Ubuntu, Argo Workflows, Argo Events, Apache YuniKorn, Fluent Bit, Quarkus, OpenSearch, Next.js, Grafana, Telegraf, Dask, syft, sbomqs, Cosign, Sigstore, and more. Enjoy!
I am off to Iceland this week, looking forward to exploring this amazing country. This does mean that there will not be a newsletter next week. But don’t worry, I will be back the week after.
Build on Open Source - Series Two
I am excited to announce that the second series of Build on Open Source is currently being scheduled from 17th February, running every two weeks. It will be at the usual time (9am UK, 10am CET, 2:30pm IST, 5pm SST, and 8pm AEDT) on twitch.tv/aws. I hope to see some of you readers on the show, and we are currently looking for guests who want to come on and share their open source projects with the audience. We still have a few slots free, so please get in touch - its first come first serve.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Sebastien Stormacq, Sascha Moellering, Brandon Bush, Ben Cressey, Jayaprakash Alawala, Kyle Davis, Akira Ajisaka, Noritaka Sekiyama, Savio Dsouza, Sekar Srinivasan, Prabu Ravichandran, Victor Gu, Vara Bonthu, Jianwei Li, Samrat Deb, Prabhu Josephraj, Praveen Allam, Vivek Singh, Shimon Tolts, and Brian Hammons.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
precloud
precloud is an open source command line interface that runs checks on infrastructure as code to catch potential deployment issues before deploying. Infrastructure code deployments often fail due to mismatched constraints over resource fields between the infrastructure code, the deployment engine, and the target cloud. For example, you may be able to pass any arbitrary string as a resource name to terraform or AWS CDK, and plan or synth go through fine, but the deployment may fail because that string failed a naming constraint on the target cloud.
{kind=link}
dynamodb-shell
dynamodb-shell is a simple CLI for DynamoDB modeled on isql, and the MySQL CLIs. ddbsh presents the user with a simple command line interface. Here the user can enter SQL-like commands to DynamoDB. The output is presented in the same window. ddbsh supports many Data Definition Language (DDL) and Data Manipulation Language (DML) commands.
aws-deployment-pipeline-reference-architecture
aws-deployment-pipeline-reference-architecture this repo contains support code for the Deployment Pipeline Reference Architecture (DPRA), that describes best practices for building deployment pipelines. A deployment pipeline automates the building, testing and deploying of software into AWS environments. With DPRA, developers can increase the speed, stability, and security of software systems through the use of deployment pipelines. You can find out more about this in my colleague Sebastien Stormacq’s post, New – Deployment Pipelines Reference Architecture and Reference Implementations.
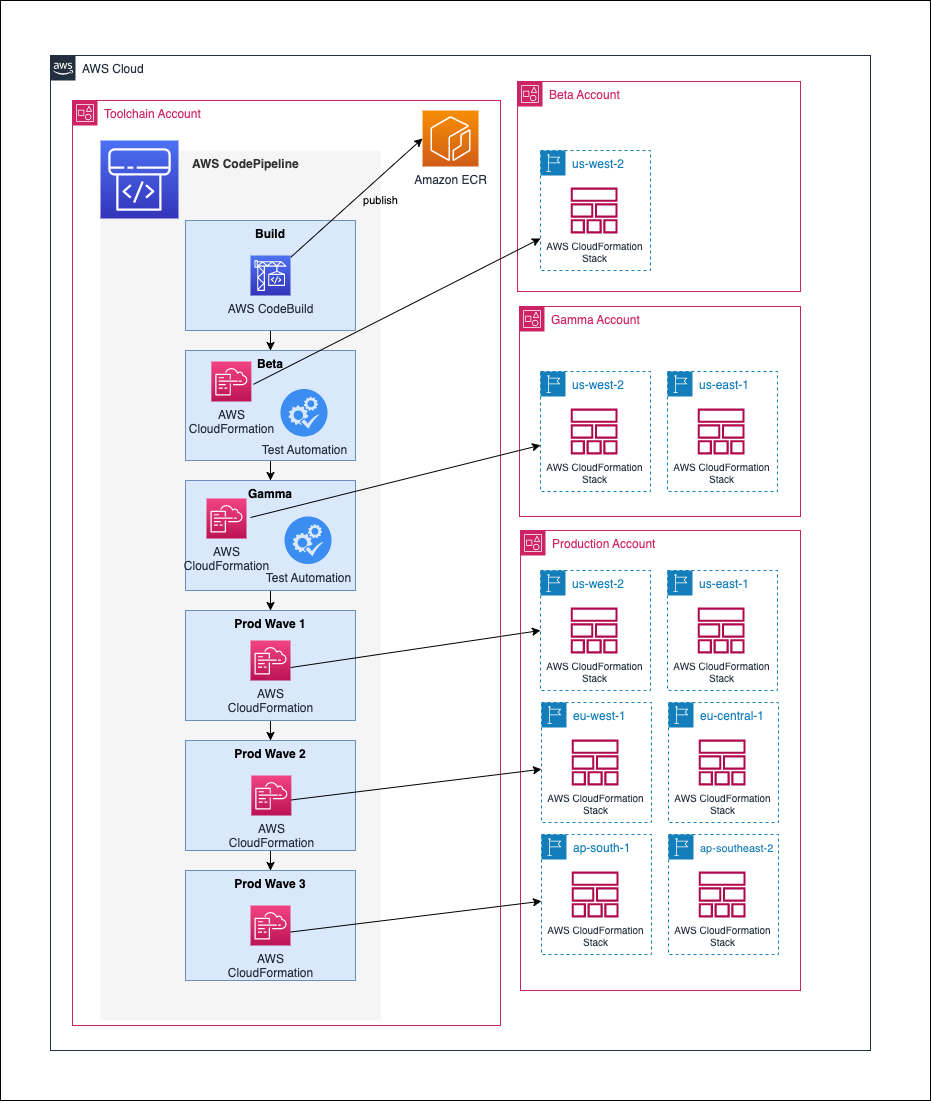
stepfunctions-lambda-ec2-ssm
stepfunctions-lambda-ec2-ssm This repo holds the stepfunction workflow for creating EC2 instance and execute remote powershell script for configuration of EC2 using Systems Manager (Run Command). There are scenarios where EC2 instances has to be created and need to be configured using Systems Manager powershell script. The script may take a long time depending upon the configuration and it may exceed lambda time limit of 15 mins.This solution provides a serverless approach using stepfunctions and lambda to create EC2 instance, execute the configurations from powershell script, wait for the script to complete by periodically checking the runCommand status. The workflow also deletes the created EC2 instance irrespective of runCommand execution result.
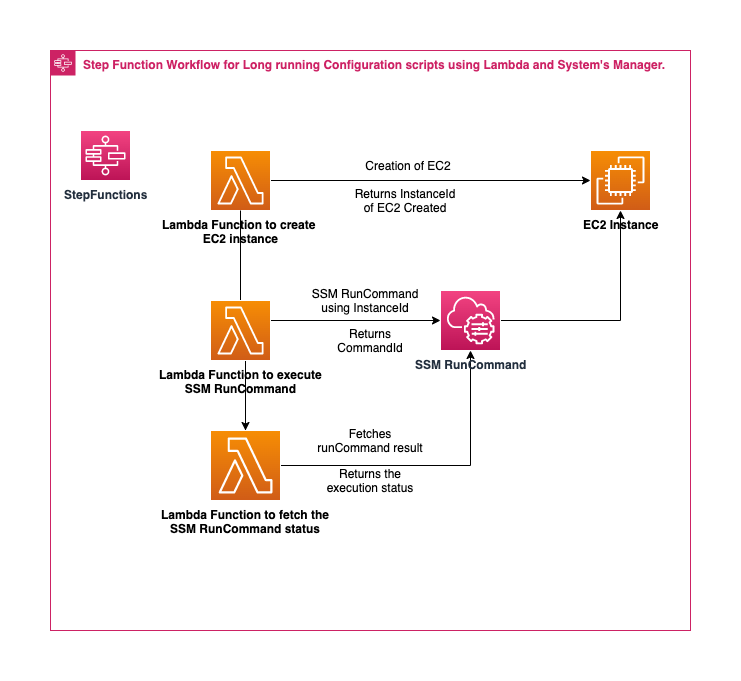
terraform-ec2-image-builder-container-hardening-pipeline
terraform-ec2-image-builder-container-hardening-pipeline This solution builds an EC2 Image Builder Pipeline with an Amazon Linux 2 Baseline Container Recipe, which is used to deploy a Docker based Amazon Linux 2 Container Image that has been hardened according to RHEL 7 STIG Version 3 Release 7 - Medium. See the “STIG-Build-Linux-Medium version 2022.2.1” section in Linux STIG Components for details. This is commonly referred to as a “Golden” container image. The solution includes two Cloudwatch Event Rules. One which triggers the start of the Container Image pipeline based on an Inspector Finding of “High” or “Critical” so that insecure images are replaced, if Inspector and Amazon Elastic Container Registry “Enhanced Scanning” are both enabled. The other Event Rule sends notifications to an SQS Queue after a successful Container Image push to the ECR Repository, to better enable consumption of new container images.
node-latency-for-k8s
node-latency-for-k8s The node-latency-for-k8s tool analyses logs on a K8s node and outputs a timing chart, cloudwatch metrics, prometheus metrics, and/or json timing data. This tool is intended to analyse the components that contribute to the node launch latency so that they can be optimised to bring nodes online faster. NLK runs as a stand-alone binary that can be executed on a node or on offloaded node logs. It can also be run as a K8s DaemonSet to perform large-scale node latency measurements in a standardised and extensible way.
cloudtrail-event-fuzzy-viewer
cloudtrail-event-fuzzy-viewer is a cli tool from Paolo Lazzardi that allows you to search for AWS CloudTrail events using fuzzy search. The binary installation works on Mac and Linux (that is what I tried) and the README provides guidance on how to get up and running quickly (don’t forget to install the dependencies).
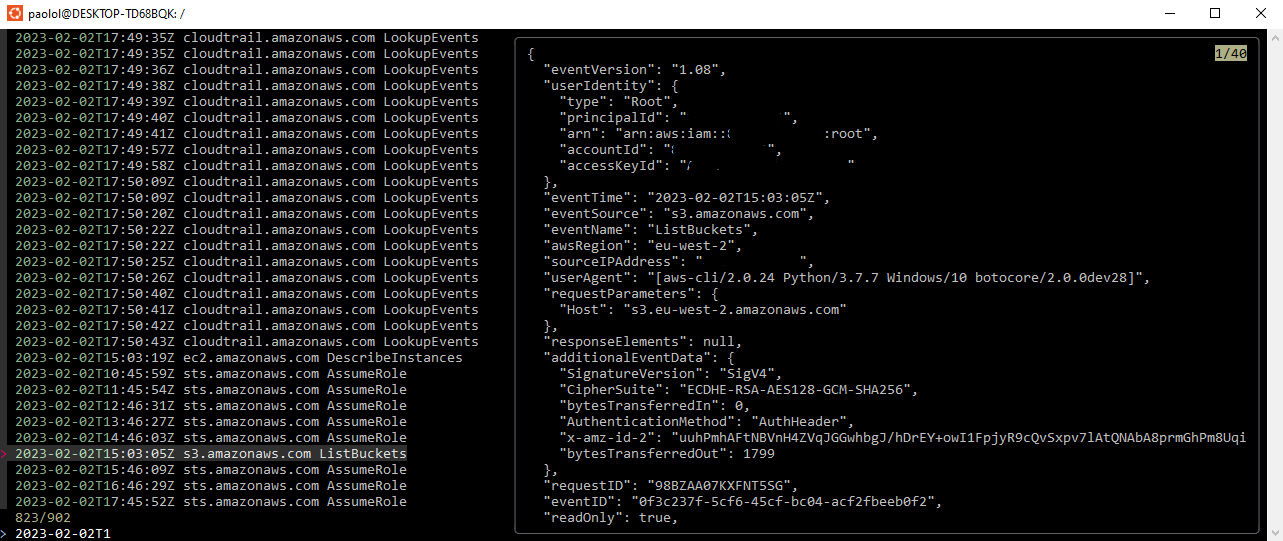
I was able to run this on my Linux machine, but I did get date formatting errors on my Mac. I also encountered ThrottlingException errors, so use carefully.
Demos, Samples, Solutions and Workshops
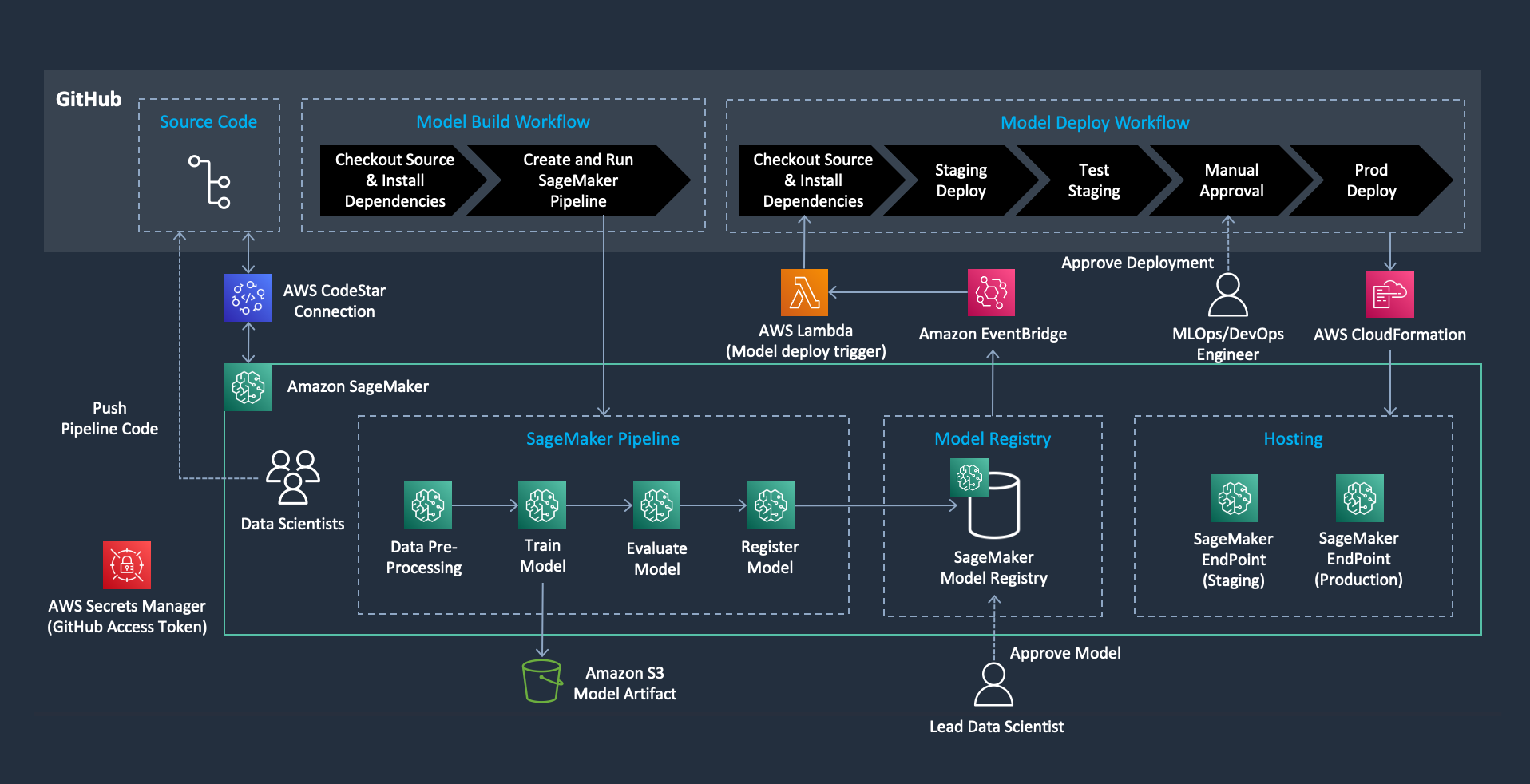
mlops-sagemaker-github-actions
mlops-sagemaker-github-actions This repository provides an example of MLOps implementation using Amazon SageMaker and GitHub Actions. The code automates a model-build pipeline that includes steps for data preparation, model training, model evaluation, and registration of that model in the SageMaker Model Registry. The resulting trained ML model is deployed from the model registry to staging and production environments upon the approval.
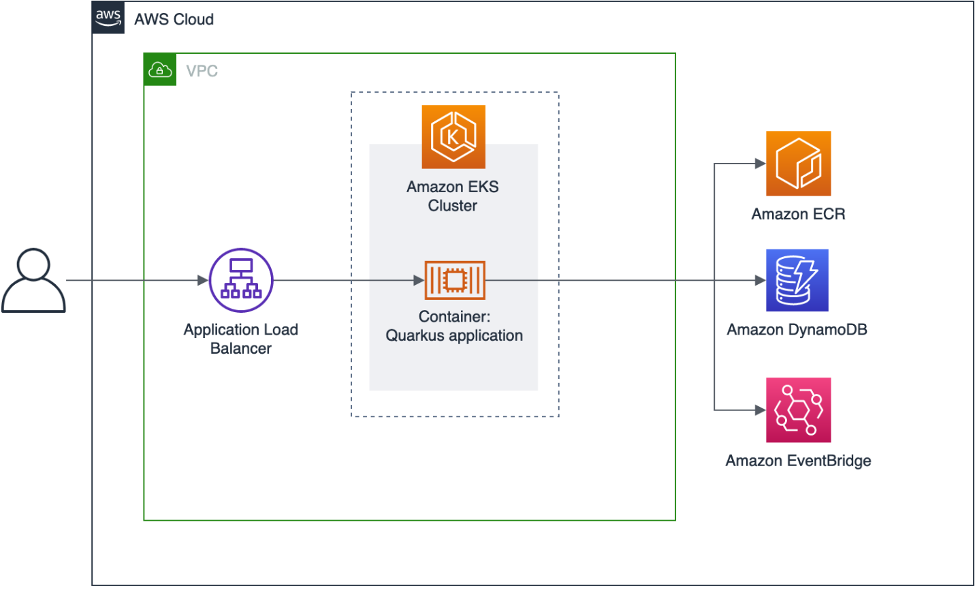
aws-eks-quarkus-example
aws-eks-quarkus-example this repo shows you how you can deploy Quarkus on Amazon EKS. Quarkus was designed to enable Java developers to write Java-based cloud-native micro services. Sascha Moellering has put together a blog post to support this repo and help get you going, so make sure you check out How to deploy your Quarkus application to Amazon EKS when you dive into the code.
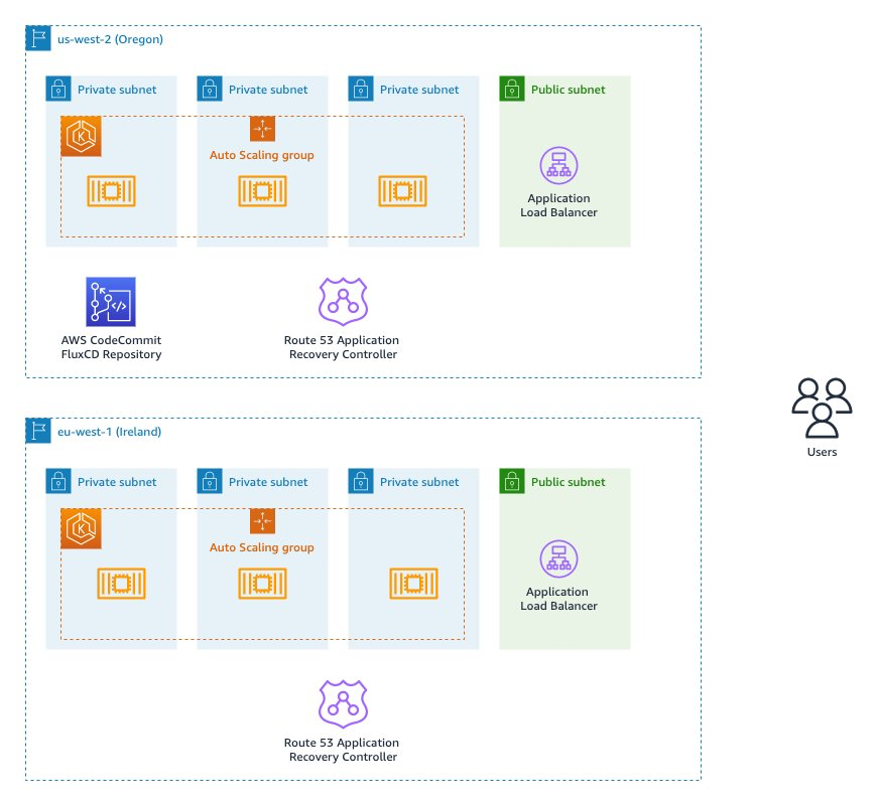
gitops-eks-r53-arc
gitops-eks-r53-arc this repo has code that will let you deploy an application that survives widespread operational events within an AWS Region by leveraging Amazon Route 53 Application Recovery Controller in conjunction with Amazon Elastic Kubernetes Service (Amazon EKS). It uses an open-source CNCF project called Flux to keep the application deployments synchronised across multiple geographic locations. You can follow along in the blog post that accompanies this code repo, GitOps-driven, multi-Region deployment and failover using EKS and Route 53 Application Recovery Controller.
AWS and Community blog posts
Bottlerocket
In the post, Validating Amazon EKS optimized Bottlerocket AMI against the CIS Benchmark, Brandon Bush, Ben Cressey, Jayaprakash Alawala, and Kyle Davis have come together to provides detailed, step-by-step instructions on how customers can bootstrap an Amazon EKS optimised Bottlerocket Amazon Machine Image (AMI) for the requirements of the CIS Bottlerocket Benchmarks. [hands on]
Apache Spark
We have some great posts this week for Apache Spark developers.
Kicking off with Introducing native support for Apache Hudi, Delta Lake, and Apache Iceberg on AWS Glue for Apache Spark, Part 1: Getting Started Akira Ajisaka, Noritaka Sekiyama, and Savio Dsouza demonstrates how AWS Glue for Apache Spark works with Hudi, Delta, and Iceberg dataset tables, and describes typical use cases to help you decide which is the right approach for you.
Next we have Sekar Srinivasan and Prabu Ravichandran who have collaborated on this post, Run Apache Spark workloads 3.5 times faster with Amazon EMR 6.9 where they analyse the results from benchmark tests running a TPC-DS application on open-source Apache Spark and then on Amazon EMR 6.9. No spoilers, you are going to have to read the post to get all the details.

The final post this week on Apache Spark is this one, Dynamic Spark Scaling on Amazon EKS with Argo Workflows and Events where Victor Gu and Vara Bonthu demonstrate how to build and deploy a data processing platform on Amazon EKS with Data on EKS Blueprints. The platform includes all the necessary Kubernetes add-ons like Argo Workflows, Argo Events, Spark Operator for managing Spark jobs, Apache YuniKorn for Batch Scheduler, Fluent Bit for logging, and Prometheus for metrics. They also show how to build data processing jobs and pipelines using Argo Workflows and Argo Events, and show how to trigger workflows on-demand by listening to Amazon Simple Queue Service (Amazon SQS). Very nice post! [hands on]
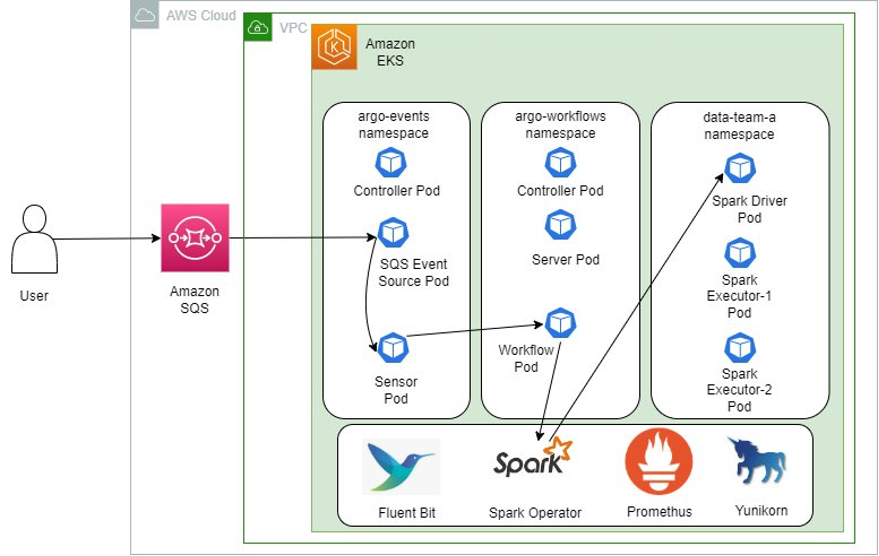
One final note, if you have not checked out the Data on EKS blueprints, make sure you head over to the GitHub repo as there is lots of great sample code to show you how you can build and scale data platforms using Amazon EKS.
Apache Flink
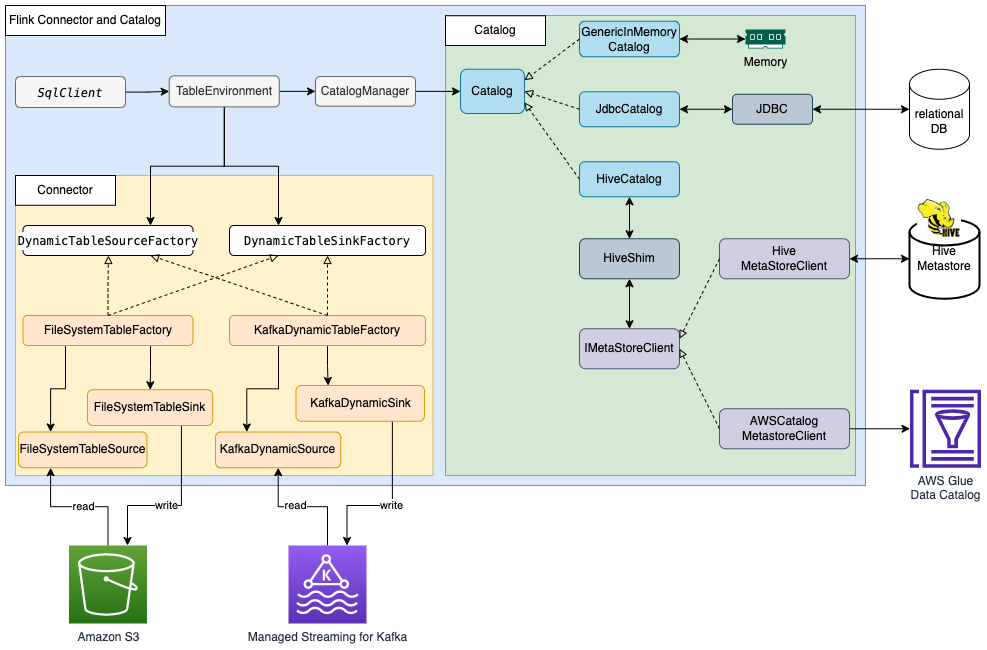
In the post, Build a data lake with Apache Flink on Amazon EMR, Jianwei Li, Samrat Deb, and Prabhu Josephraj show you how to integrate Apache Flink in Amazon EMR with the AWS Glue Data Catalog so that you can ingest streaming data in real time and access the data in near-real time for business analysis. [hands on]
Delta Lake
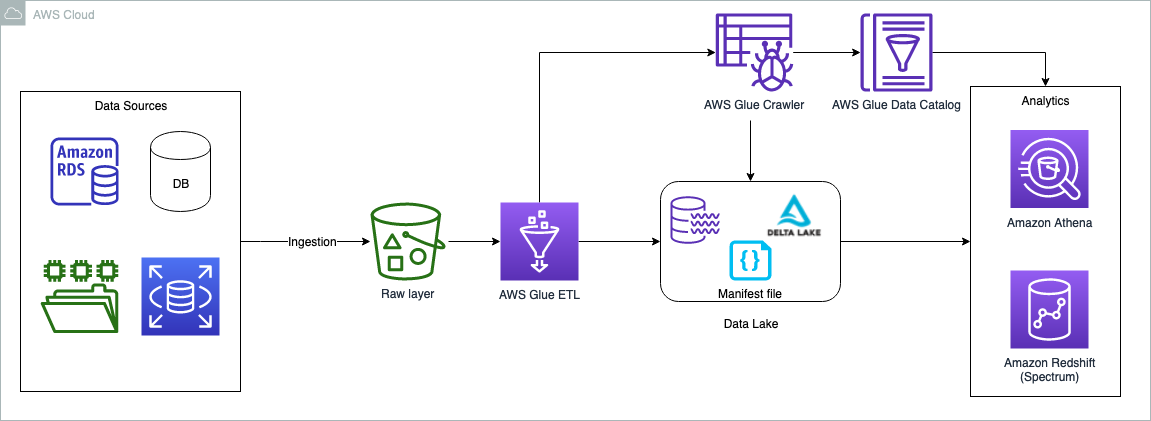
Delta Lake is an open-source project that helps implement modern data lake architectures commonly built on Amazon S3 or other cloud storage. This includes supporting ACID transaction (atomic, consistent, isolated, durable) and log change data capture (CDC) from operational data sources - including how you can do UPSERTS (updates and inserts). Praveen Allam and Vivek Singh have written Handle UPSERT data operations using open-source Delta Lake and AWS Glue and show you how to build data lakes for UPSERT operations using AWS Glue and native Delta Lake tables, and how to query AWS Glue tables from Athena. [hands on]
Supply Chain Security
I have been putting together some content that will form a larger body of work around what developers need to know about building is good practices when using open source software in the applications they build. I would love to hear from developers what your current pain points are and what content you think is currently missing. In the meantime, I have put together a few posts. Starting off with Getting hands on with Sigstore Cosign on AWS that looks at how you can use Cosign to sign and verify artefacts in your development workflows. The next post was a look at using an open source tool called syft to generate software bill of materials in the post, Building a software bill of materials (SBOM) using open source tools. Finally I took a look at a new open source tool that helps you quality check your SBOMS in the post, sbomqs, an open source tool to quality check your SBOMS.
Other posts and quick reads
- Best Practices from SoftServe for Using Kubernetes on AWS in Enterprise IT shares best practices on how to run Kubernetes in an enterprise IT environment
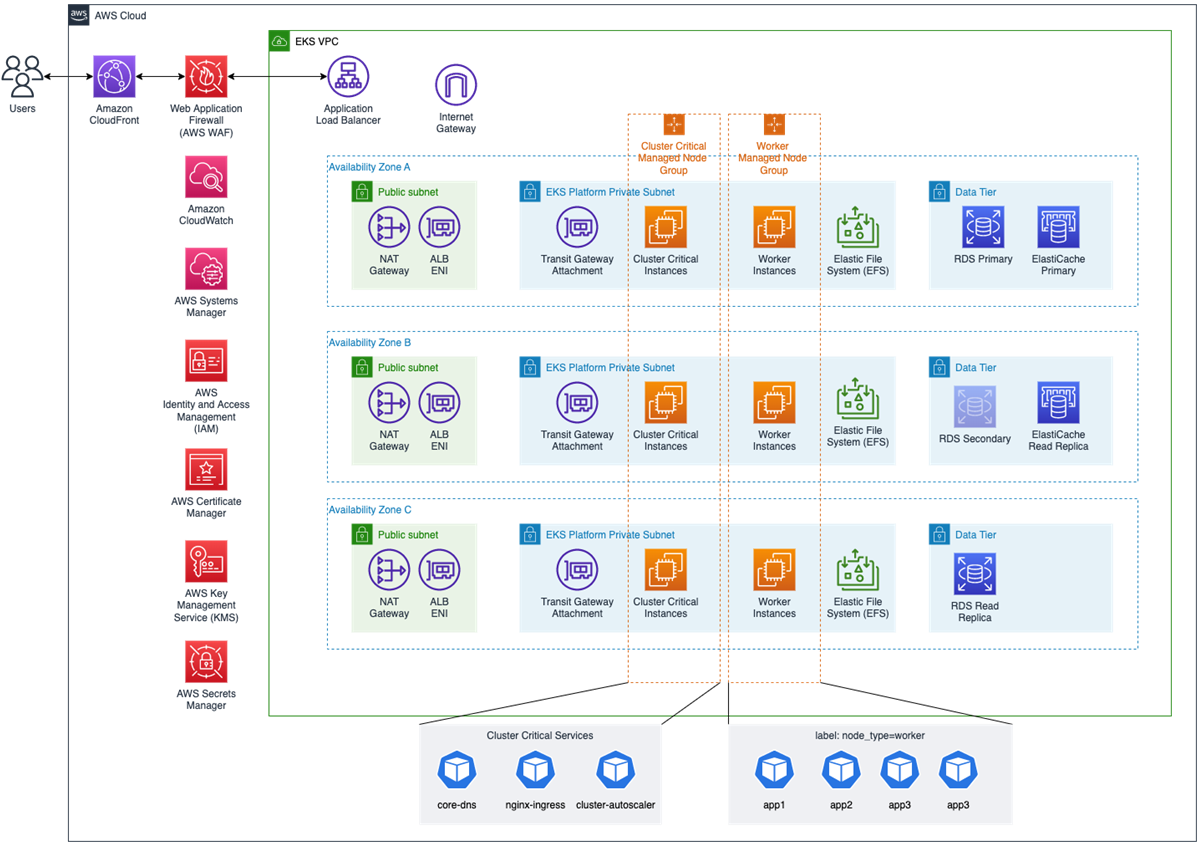
- Scale from 100 to 10,000 pods on Amazon EKS who doesn’t like a good case study on scaling, this one shows how ORION scaled Amazon EKS clusters from 100 to more than 10,000 pods [hands on]
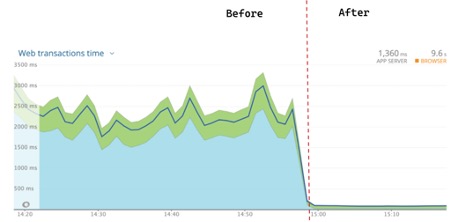
- How to rapidly scale your application with ALB on EKS (without losing traffic) demonstrates how to use a separate application endpoint as an Amazon Load Balancer health check along with Kubernetes readiness probe and PreStop hooks that together enable graceful application termination [hands on]

- Build a Product Roadmap with Next.js and Amplify walks you through how you can build an admin interface for product managers to add features to a roadmap [hands on]
- One-time Password Authentication with the Amplify Libraries for Swift shows you how to create an OTP auth flow for an iOS app using Amazon Simple Email Service (SES) to send an email containing a 6-digit code and authenticate the user using the Auth and Function categories with the AWS Amplify Libraries for Swift.
- Improve observability by using Amazon RDS Custom for SQL Server with Telegraf and Amazon Grafana explain how to implement this solution and improve observability for Amazon RDS Custom for SQL Server with open source tools such as with Telegraf and Amazon Grafana [hands on]
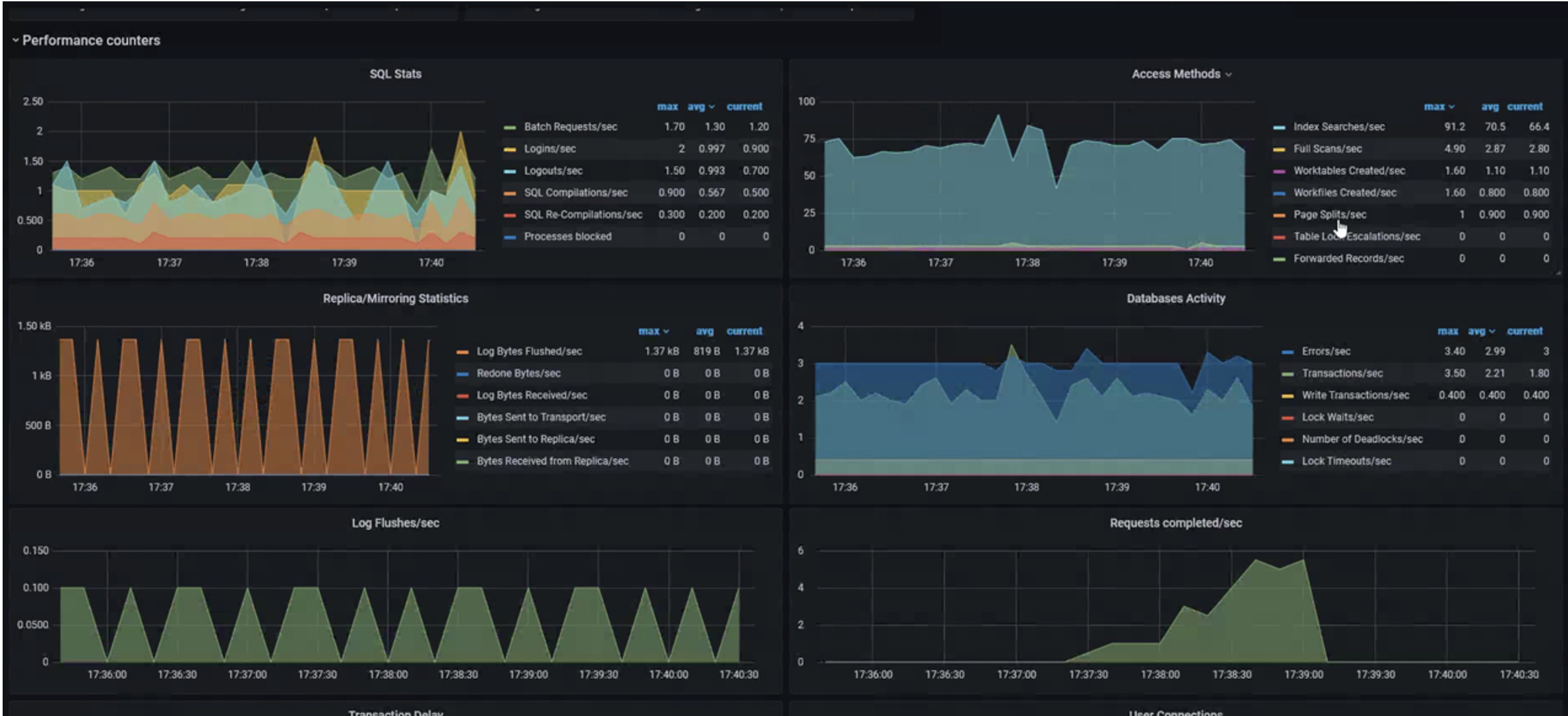
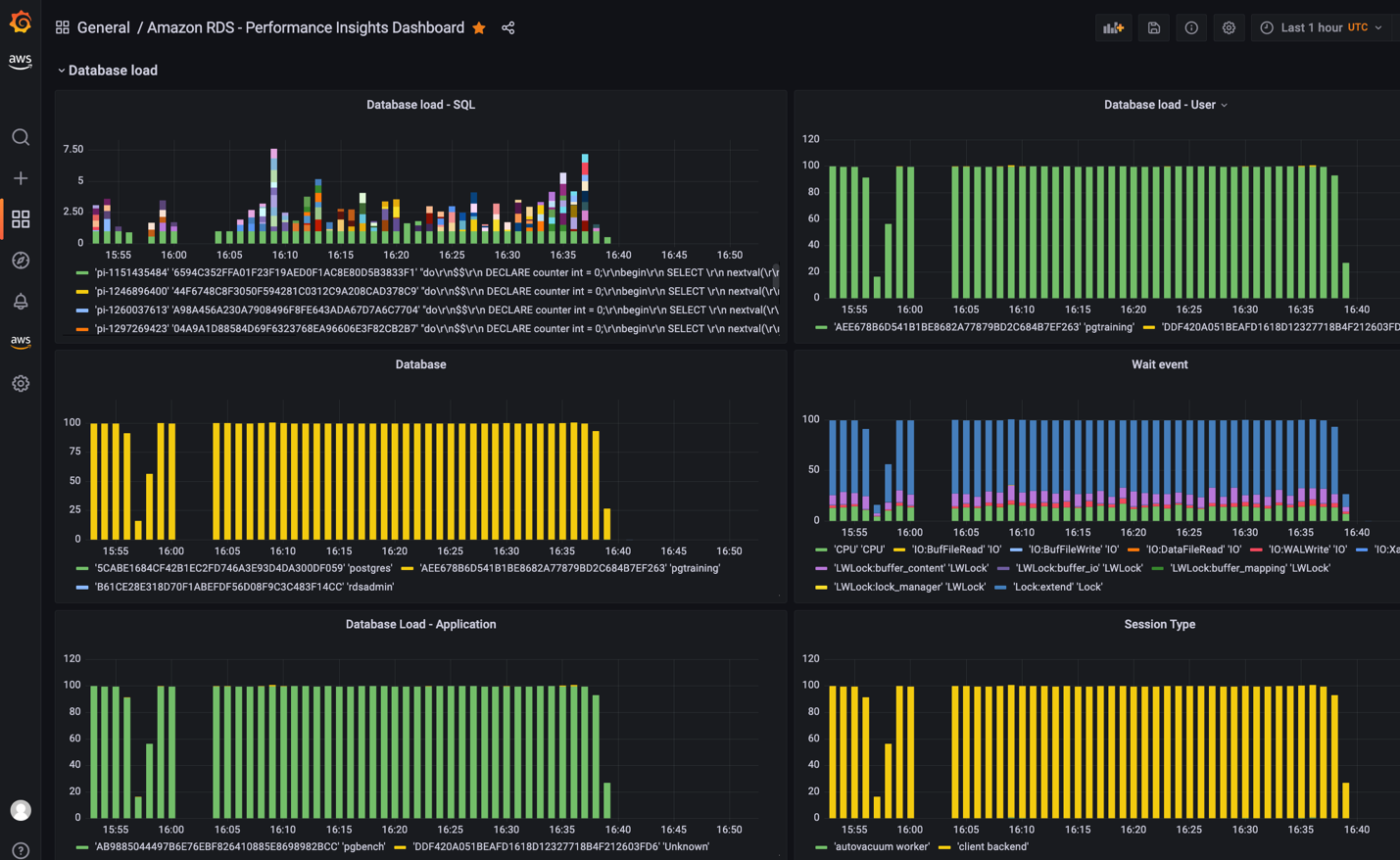
- Monitoring Amazon RDS and Amazon Aurora using Amazon Managed Grafana looks at how you can monitor your Amazon RDS and Amazon Aurora database clusters including Performance insight metrics using Amazon Managed Grafana [hands on]
- Amazon SageMaker built-in LightGBM now offers distributed training using Dask looks at how SageMaker LightGBM algorithm now offers distributed training using the Dask framework for both tabular classification and regression tasks [hands on]
Quick updates
Matano
Matano is an open source cloud-native security lake platform (SIEM alternative) for threat hunting, detection & response, and cybersecurity analytics at petabyte scale on AWS. Last week, Samrose Ahmed wrote Matano now supports 10+ AWS managed log sources, sharing that they now support some additional AWS sources that you can integrate.
Ubuntu
AWS Snow Family now supports Ubuntu 20.04 Long Term Support (LTS) and Ubuntu 22.04 LTS on AWS Snowcone, AWS Snowball Edge Compute Optimized, and AWS Snowball Edge Storage Optimized devices. Ubuntu operating systems on Snow devices enable customers to deploy their edge compute workloads such as IoT, AI/ML, and Container workloads on Ubuntu 20.04 LTS and Ubuntu 22.04 LTS versions.
Bottlerocket
Bottlerocket, a Linux-based operating system that is purpose built to host container workloads, now supports network bonding and VLAN tagging when used with Amazon Elastic Kubernetes Anywhere (Amazon EKS Anywhere) bare metal deployments. The added functionality allows customers using Bottlerocket on bare metal to avoid a single point of failure in the network stack and improves network performance.
Network bonding is a process of combining two or more network devices to act as one network interface. This process can improve network performance and availability because there is now more than one interface available to communicate. Bonding interfaces together is a common strategy to provide high availability for bare metal servers. VLAN tagging adds the ability to use the same network hardware but logically separates networks based upon VLAN tags.
Network bonding is available on Bottlerocket versions starting from 1.12.0 when used with Amazon EKS Anywhere.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports PostgreSQL minor versions 14.6, 13.9, 12.13, 11.18, and 10.23. We recommend you upgrade to the latest minor version to fix known security vulnerabilities in prior versions of PostgreSQL, and to benefit from the bug fixes, performance improvements, and new functionality added by the PostgreSQL community.
With this release, RDS for PostgreSQL adds two new extensions: (1) tcn - an extension that provides a trigger function that sends an asynchronous notification for every write on a table, and (2) seg - an extension that provides the “seg” data type used for storing and querying line segments. This release also includes updates for existing supported PostgreSQL extensions: orafce is updated to 3.24, rdkit is updated to 4.2.0, and wal2json is updated to 2.5.
OpenSearch
A few updates this week.
First up, OpenSearch has a new newsletter. Check out the first edition, OpenSearch Project Newsletter - Volume 1, Issue 1
OpenSearch 1.3.8 also shipped last week. You can find the release over on the OpenSearch Downloads page, and check out what you can expect over on the release notes.
Amazon OpenSearch Service now supports enabling Security Assertion Markup Language (SAML) authentication for OpenSearch Dashboards during domain creation. SAML authentication for OpenSearch Dashboards enables users to integrate directly with identity providers (IDPs) such as Okta, Ping Identity, OneLogin, Auth0, Active Directory Federation Services (ADFS) and Azure Active Directory. Previously this authentication method could be configured only after domain creation. Now, this feature can be enabled at domain creation using AWS Console/SDK or using AWS CloudFormation templates, giving you the ability to enable programmatically in fewer steps. With this feature, users can leverage their existing usernames and passwords to log in to OpenSearch Dashboards, and roles from your IDP can be used for controlling privileges, including what operations they can perform and what data they can search and visualise.
Also new last week was news that Amazon OpenSearch Service has added a new connection mode for cross-cluster connection, simplifying the setup required to remote reindex between a local domain and remote VPC domains. Remote reindex enables you to migrate data from a source domain to a target domain. Remote reindex is also useful when you have to upgrade your clusters across multiple major versions. Previously, to use remote reindex, you needed to confirm that the source domain was accessible from the target domain. If the remote domain was VPC enabled, you set up a publicly accessible reverse proxy for the remote domain, even when the domains were located within the same VPC.
With this release, you can create a new connection between a local domain and a remote VPC domain using the connection mode ‘VPC endpoint’, and then use the provided endpoint in the remote reindex operation. You do not need a proxy, and the traffic between domains remains within the Amazon Networking Backbone–at no extra cost. The new connection mode is available for local domains running OpenSearch versions 1.3 and above.
Redis
Amazon Elasticache for Redis now offers an availability Service Level Agreement (SLA) of 99.99% when using a Multi-Availability Zone (Multi-AZ) configuration. Previously, ElastiCache for Redis offered an SLA of 99.9% for Multi-AZ configurations. With this launch, ElastiCache for Redis has updated its Multi-AZ SLA to provide 10x higher levels of availability.
PlantUML
PlantUML is an open-source tool allowing users to create diagrams from a plain text language. If you are a user, then release 15.0 of the aws-icons-for-plantuml was released last week. This releases features a number of updates and new icons in Analytics, Application Integration, Business Applications, Compute, Containers, Database, Developer Tools, End User Computing, Internet Of Things, Machine Learning, Management Governance, Migration Transfer, Networking Content Delivery, Security Identity Compliance, and Storage categories.
Videos of the week
Amazon EKS Security Best Practices
AWS Hero Shimon Tolts has put together this video and blog post to show you how to enforce the Amazon EKS Security Best Practices Guide on your own EKS. Check out the blog post, EKS Security Best Practices - Practical Enforcement Guide that supports this video.
Building a Modern Data Platform on Amazon EKS
This weeks edition has featured a number of open source data tools running in Kubernetes. In this video, Brian Hammons explores several advantages and challenges of building data platforms on Kubernetes, and introduce Data on EKS - a global initiative offering IaC patterns in Terraform and CDK, benchmark reports, best practices, and sample code to simplify and accelerate the journey for users who want to run applications like Spark, Kafka, Kubeflow, Ray, Airflow, Presto, and Cassandra on EKS.
Terraform
Join Rob as he provides an introductory guide on Terraform and AWS.
If you are working with Terraform and AWS, you will almost certainly come across AWS Hero Anton Babenko. He runs a regular Terraform live coding session on YouTube which I recommend you check out. If you want to talk about any topics on Terraform/AWS, this is a great livestream to join.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
State of Open Con 23 Feb 7-8th, 2023 in London
OpenUK will be hosting a 1000 person plus two day conference in Central London, “State of Open Con 23” in association with IEEE, the headline sponsor. Check out more info and sign up here.
PGConf India Feb 22nd to 24th, Radisson Blu Bengaluru, India
If you are in or can get to Bengaluru, then checkout this conference for PostgreSQL developers and enthusiasts. Check out the session line up and get your tickets here.
Everything Open March14-15th Melbourne, Australia
A new event for the fine folks in Australia. Everything Open is running for the first time, and the organisers (Linux Australia) have decided to run this event to provide a space for a cross-section of the open technologies communities to come together in person. Check out the event details here. The CFP us currently open, so why not take a look and submit something if you can.
Cortex Every other Thursday, next one 16th February
The Cortex community call happens every two weeks on Thursday, alternating at 1200 UTC and 1700 UTC. You can check out the GitHub project for more details, go to the Community Meetings section. The community calls keep a rolling doc of previous meetings, so you can catch up on the previous discussions. Check the Cortex Community Meetings Notes for more info.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen