AWS open source newsletter #141
January 16th, 2023 - Instalment #141
Welcome
Welcome to the AWS open source newsletter of 2023, edition #141.
This week we have more new projects for you to practice your four freedoms, including “distributed-compute-on-aws-with-cross-regional-dask”, a solution to simplify distributed compute using Dask, “amazon-emr-serverless-image-cli” a tool to verify your Amazon EMR custom container images, “serverless-run-watch” a tool to help accelerate your local development if you are using the Serverless Framework, “aws-sso-auto-expand-accounts” a quick browser extension for those using AWS SSO, “basti” a cool Bastion Host alternative, “klotho” generate cloud native code from your code, “amazon-route53-hosted-zone-sync” a nice solution for hybrid DNS use cases, and many more.
We have content featuring Ray, MariaDB, Cedar, Spring Boot, Pulumi, Terraform, Firecracker, Apache Cassandra, OpenSearch, DoWhy, Apache Airflow, MWAA, Apache CloudStack, Dask, Apache Iceberg, Lustre, and more. This weeks videos feature Ray, Apache Iceberg, and Apache Cassandra, and we finish off with events for your diary.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Bohdan Petryshyn, Rajarshi Sarkar, AJ Stuyvenberg, Axel Leroy, Ian Mckay, Vadym Kazulkin, Brian Caffey, Veena Vasudevan, Mark Rogers, Alex Ellis, Dennis Ferruzzi , Dipankar Mazumdar, Patrick Blöbaum, Kailash Budhathoki, and Peter Götz
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
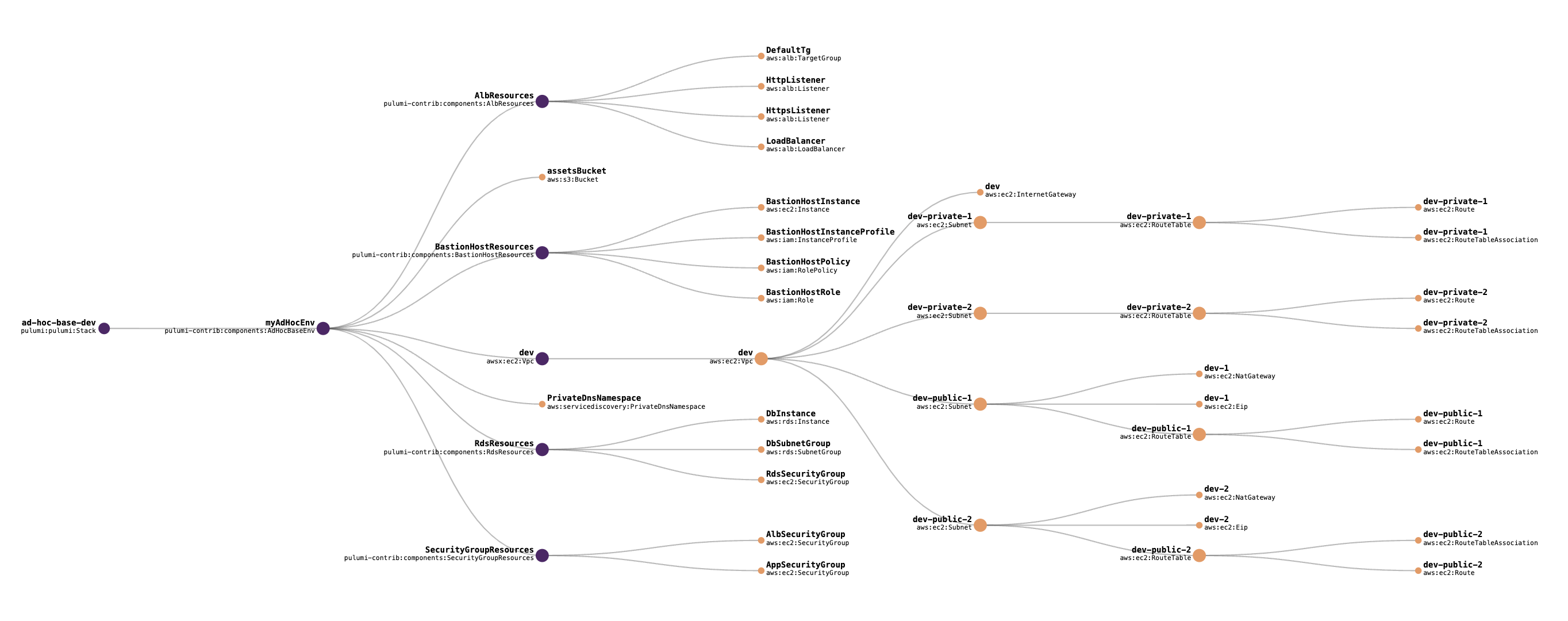
distributed-compute-on-aws-with-cross-regional-dask
distributed-compute-on-aws-with-cross-regional-dask is a distributed computing solution which uses AWS’s global network to not only scale on storage, but minimise data replication across the globe. Extending the capabilities of Dask in combination with libraries such as dask-worker-pools. No longer are data scientist’s having to migrate petabytes of data inter regionally, but instead now have capability in querying/interacting with data at the edge.
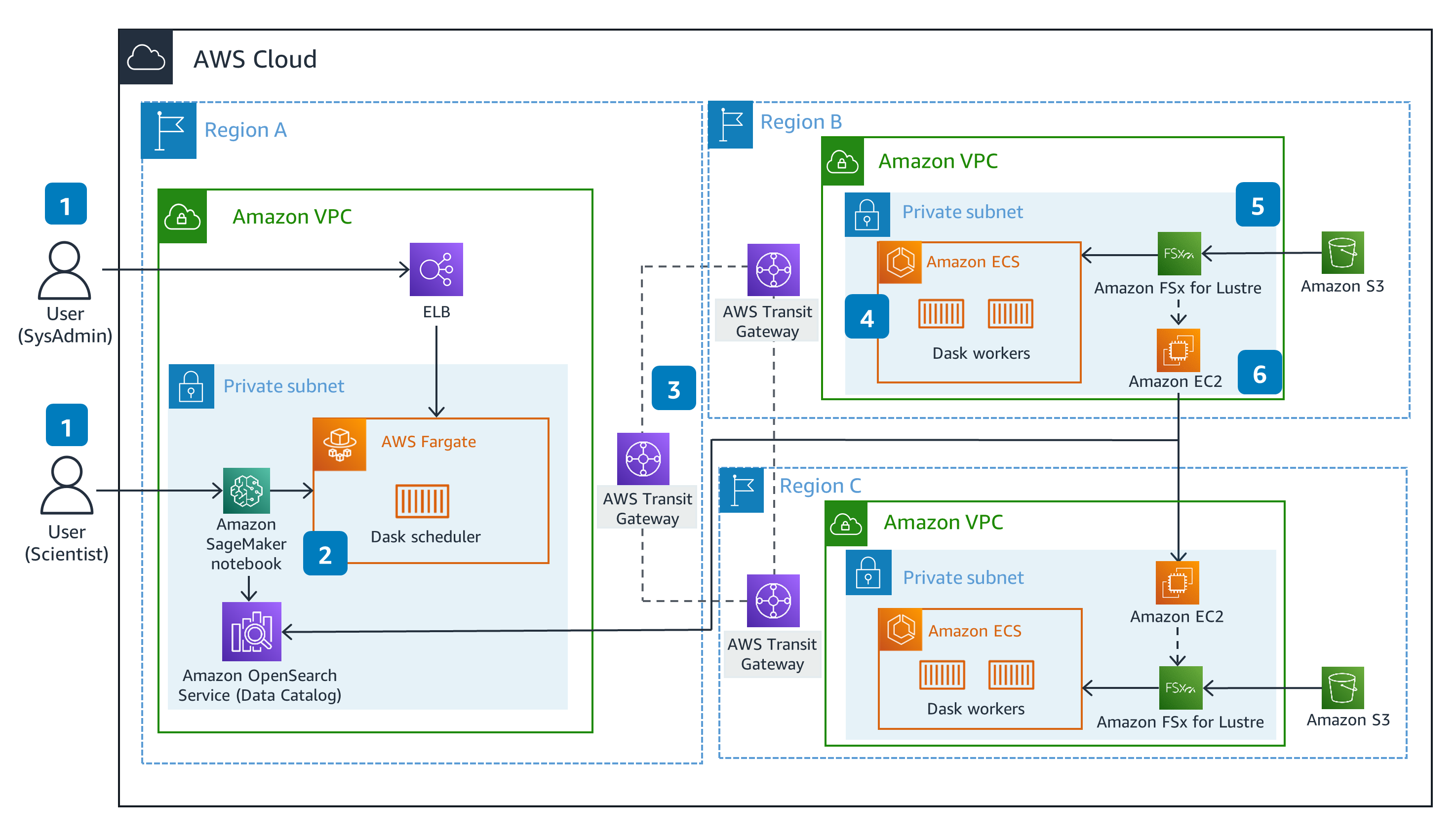
This architecture leverages the Dask framework deployed across multiple AWS regions.
amazon-route53-hosted-zone-sync
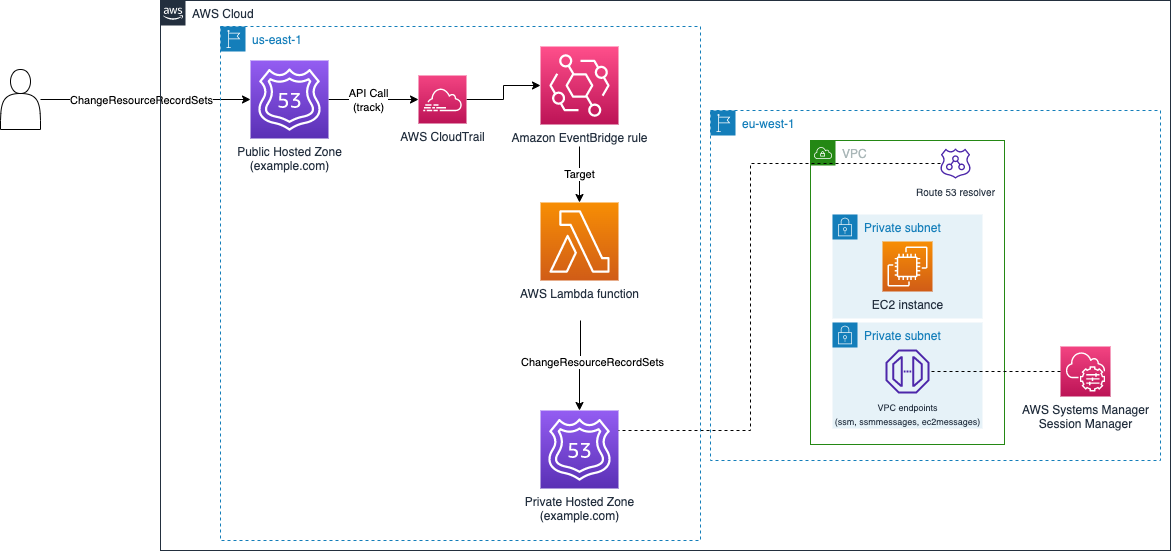
amazon-route53-hosted-zone-sync this repository shows an example of DNS record replication from an Amazon Route 53 public hosted zone to a private hosted zone - both with the same domain name. If you want resources in your VPC to have public resolution as your external users (with a public hosted zone), except you want also specific private resolution using a private hosted zone, this solution will help you do that.
amazon-emr-serverless-image-cli
amazon-emr-serverless-image-cli is a utility to validate the recently launched Amazon EMR custom container image’s file structure. The utility will examine basic required arguments and ensure that the modifications work as expected and prevent job failures due to common misconfigurations. This tool can be integrated into your Continuous Integration (CI) pipeline when you are building your image. You can find out more about this new capability in the Quick Updates section.
serverless-run-watch
serverless-run-watch is a new open source project from AWS Community Builder AJ Stuyvenberg that provides a plugin for the Serverless Framework that helps you accelerate your testing loop.
aws-sso-auto-expand-accounts
aws-sso-auto-expand-accounts is a Chrome extension from Axel Leroy that automatically expanding every accounts on the AWS SSO page allowing you to more quickly access the links. Simple and useful, just why the folks on Reddit love this so much.
klotho
klotho is an open source tool that transforms plain code into cloud native code. It is not specific to AWS, but does support it. Early stages, but take a look at the README for a walk through and demo of how this works.

basti
basti is an open source tool from Bohdan Petryshyn that provides a CLI tool for accessing DB instances and other AWS resources in private networks. The name originates from Bastion Host. Check out the docs for details on what you can use it with and how it works.

Demos, Samples, Solutions and Workshops
amazon-ec2-running-apache-cloudstack
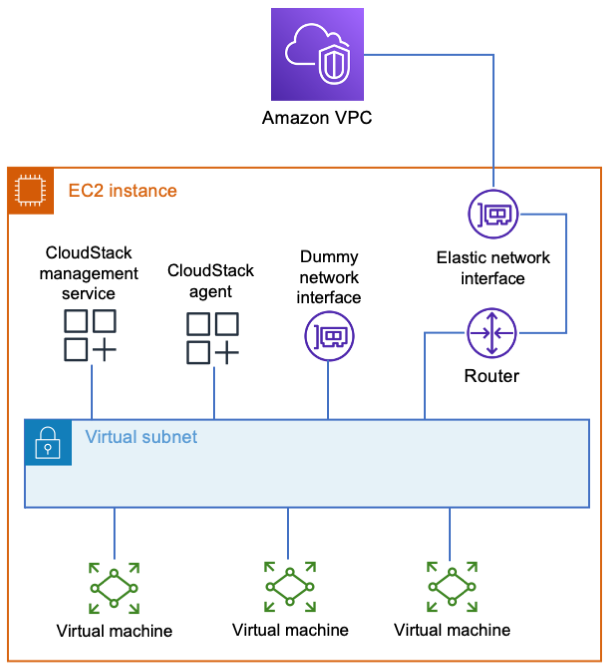
amazon-ec2-running-apache-cloudstack is a collection of AWS CloudFormation templates and bash scripts that demonstrate ways to run Apache CloudStack on Amazon Elastic Compute Cloud (Amazon EC2). Apache CloudStack is an open-source platform for deploying and managing virtual machines (VMs) and the associated network and storage infrastructure. In a two-part post, Building a Cloud in the Cloud: Running Apache CloudStack on Amazon EC2, Part 1 Mark Rogers shows how you can deploy this project on AWS using the code in this repository. Part 2 dives deeper into how you might approach scaling this.
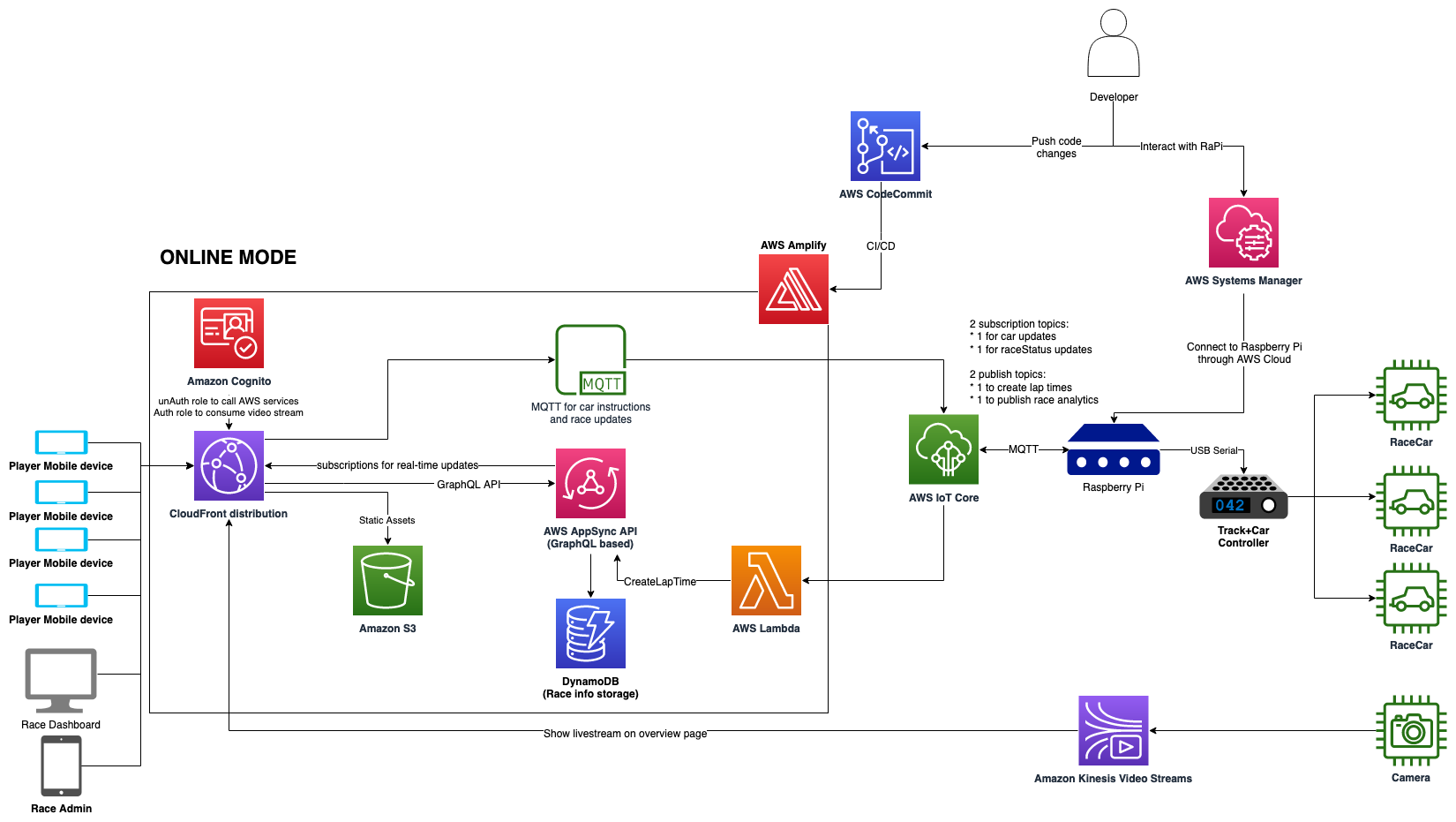
realtime-slot-car-racing-with-aws-amplify-aws-iot-core-and-amazon-kinesis-video-streams
realtime-slot-car-racing-with-aws-amplify-aws-iot-core-and-amazon-kinesis-video-streams if you attended re:Invent 2022 and visited the Builders Fair you might have seen this project in action. Sam and team put together a very cool demo of how you can use AI to control slot cars (or Scaletrix as I always call them). If you have an old set lying about, why not put it to good use with this demo! Check the repo for a video demo of this running.
AWS and Community blog posts
Cedar
Cedar is a new language created by AWS to define access permissions using policies, similar to the way IAM policies work. AWS Hero Ian Mckay has put put together a blog post, Cedar: A new policy language that introduces this new policy language and then walks you through how you can use it with some hands on examples. It is a great way to see in practical terms how Formal Reasoning can help you craft better security. [hands on]
Spring Boot
AWS Community Builder Vadym Kazulkin provides the latest instalment in his series of blog posts looking at the performance impact of using SnapStart, this time looking at the impact on Spring Boot apps. Find out more by reading the post, Measuring Java 11 Lambda cold starts with SnapStart - Part 4 Using Spring Boot Framework [hands on]
Firecracker
I love it when I discover how open source tools are being used in specific use cases or to tackle problems that perhaps the open source project was not perhaps initially intended to address. This is one such post, where Alex Ellis shows how you can speed up QEMU when creating multi-architecture releases in your CI/CD pipeline using MicroVM technology. Find out more by reading his post, Blazing fast CI with MicroVMs [hands on]
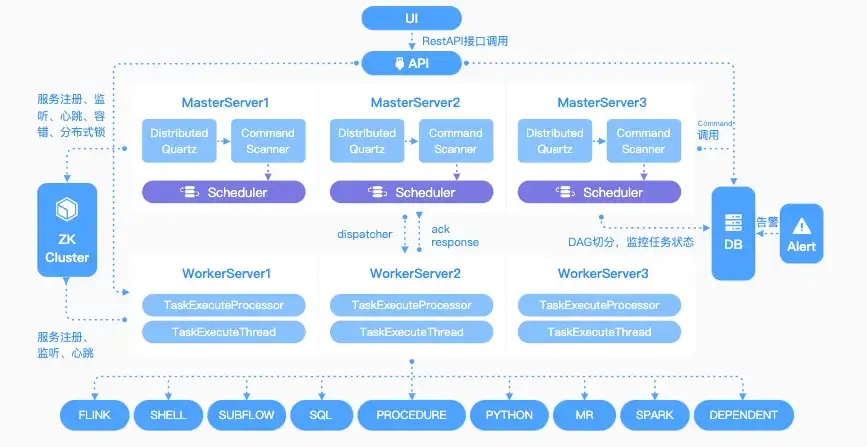
Apache DolphinScheduler
Apache DolphinScheduler is an open source distributed and extensible open-source workflow orchestration platform with a powerful visual interface. Like other workflow orchestration tools, it looks to help you solve complex big data task dependencies. To find out more about this, and how you can run this on AWS, check out this blog post, Deploy the serverless Apache DolphinScheduler task scheduling system on AWS [hands on]
Apache Airflow
The TaskFlow API was introduced in Airflow 2.0 and provides an alternative way to set out your workflow code in Apache Airflow. Dennis Ferruzzi has put together Unleashing the power of TaskFlow API in Apache Airflow that walks you through a side by side comparison of using TaskFlow vs the Python Operator so you can see the benefits for yourself. [hands on]
NOTE! The code in the post ran fine in my MWAA environment running Apache Airflow version 2.2
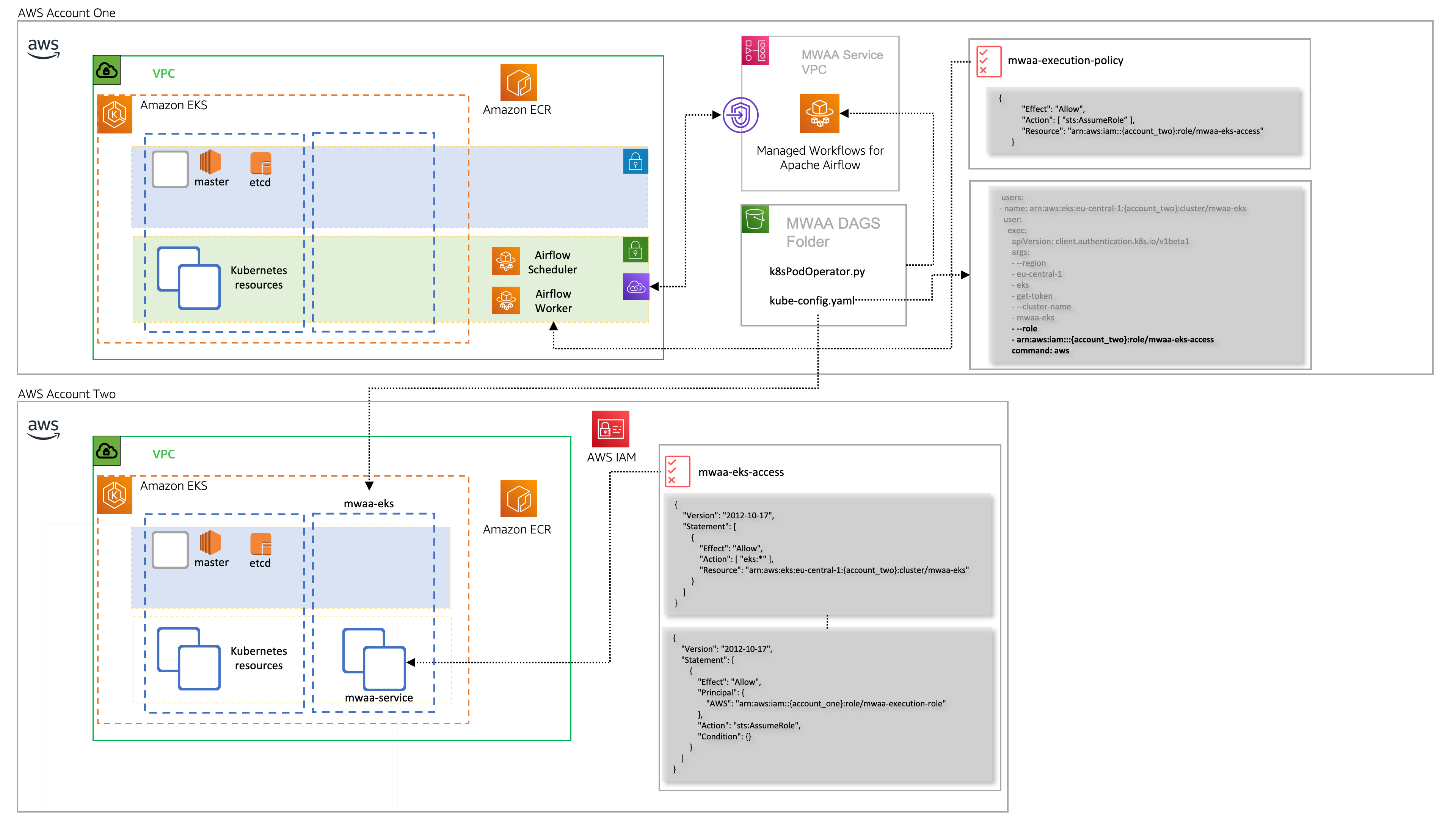
Also last week I put together a quick post on how you use one of the Apache Airflow operators (KubernetesPodOperator) to run your tasks that use this operator in a different AWS account. This means you could have one account where you run Apache Airflow, and then use this to orchestrate tasks on any number of other AWS accounts without having to deploy Apache Airflow multiple times. If you want to find out more, read the post Running KubernetesPodOperator in different AWS accounts
Apache Iceberg
In the post, Improve the performance of Apache Iceberg’s metadata file operations using Amazon FSx for Lustre on Amazon EMR, Rajarshi Sarkar shows you show you can improve the performance of Iceberg’s metadata file operations using Amazon FSx for Lustre and Amazon EMR. [hands on]

DoWhy
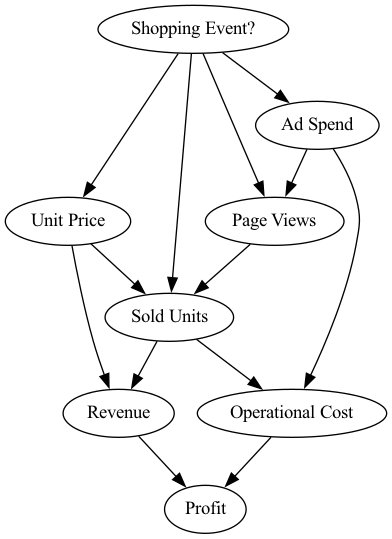
If you have been involved in any operational activities in IT, you will be familiar with doing root cause analysis to understand the underlying issues when you encounter problems. DoWhy is an open source Python library that aims to spark causal thinking and analysis, and can be used to help you tackle and understand root causes. AWS has contributed a large set of novel causal machine learning (ML) algorithms last year, and in this post, Root Cause Analysis with DoWhy, an Open Source Python Library for Causal Machine Learning Patrick Blöbaum, Kailash Budhathoki, and Peter Götz take a closer look at these algorithms. Specifically, they demonstrate their applicability in the context of root cause analysis in complex systems. Super interesting read, well worth a few minutes of your time. [hands on]
Infrastructure as Code
When it comes to which tool to use when creating your Infrastructure as Code (IaC), you have many choices. Choice is great, but how do know which one is the best for your particular use case? Well, Brian Caffey has you covered with his latest post, My Infrastructure as Code Rosetta Stone - Deploying the same web application on AWS ECS Fargate with CDK, Terraform and Pulumi. Taking the same sample application, Brian dives deep and uses these different IaC tools to deploy this on AWS ECS. Even if you currently use a preferred IaC tool, this post is a great way to look at how you might be able to do it elsewhere. [hands on]
Other posts and quick reads
- Alternative JAR Entry Points Using Java Dependency Injection Frameworks demonstrates how to elegantly reuse existing application functionality without requiring significant changes [hands on]
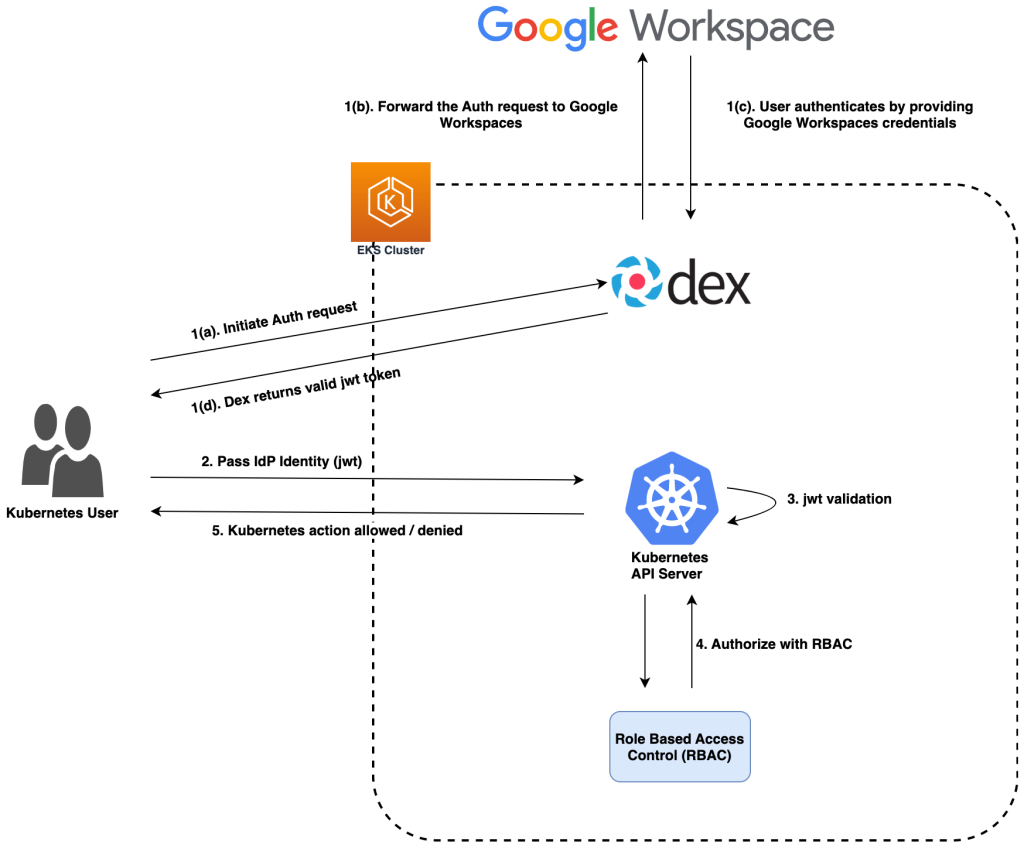
- Authenticate to Amazon EKS using Google Workspace walks you through how to integrate Amazon EKS cluster authentication with Google workspace [hands on]
- Secure CDK deployments with IAM permission boundaries shows how IAM permission boundaries can be integrated in to CDK development, helping ensure developers have the control they need while administrators can ensure that security is managed in a way that meets the needs of the organisation
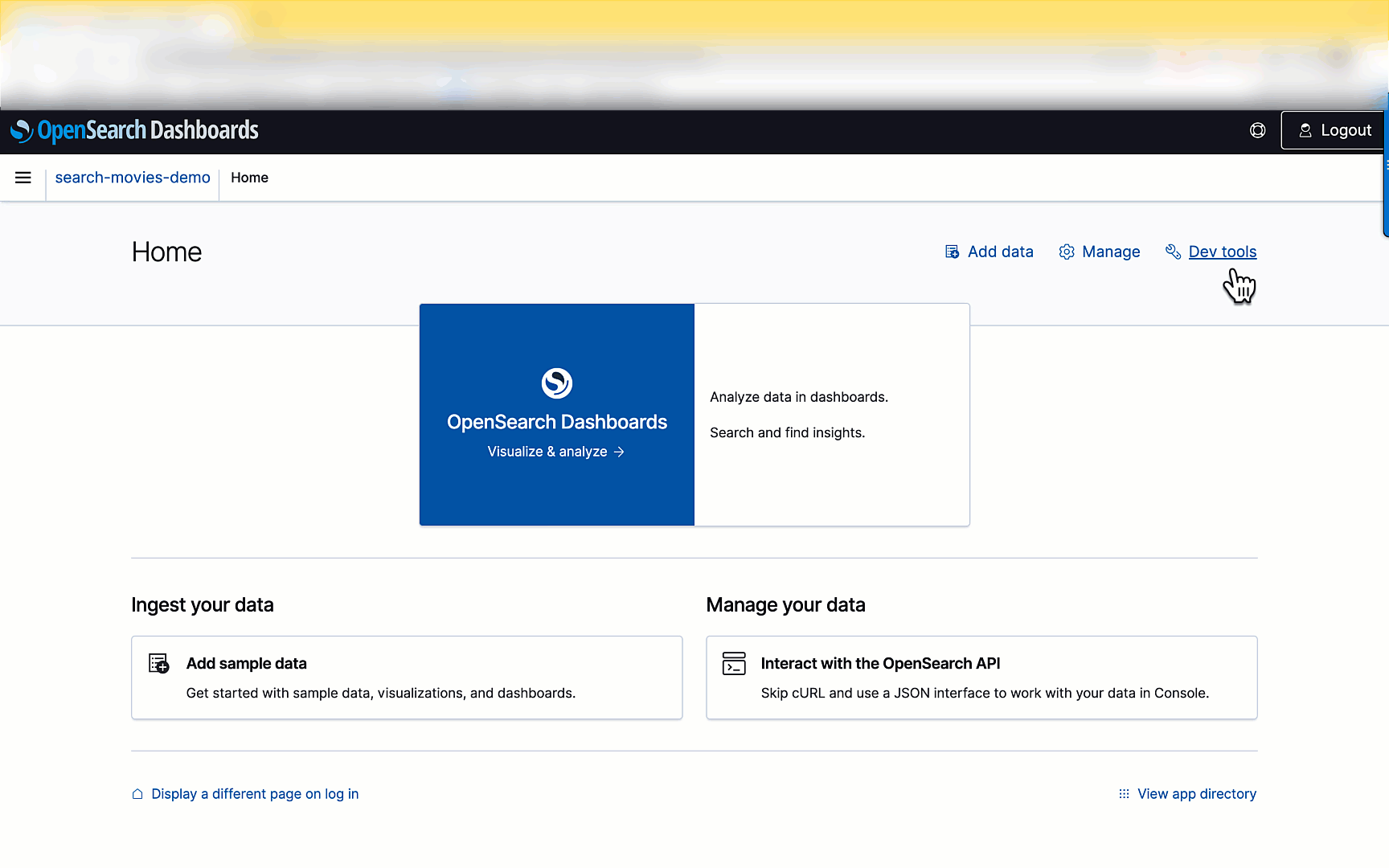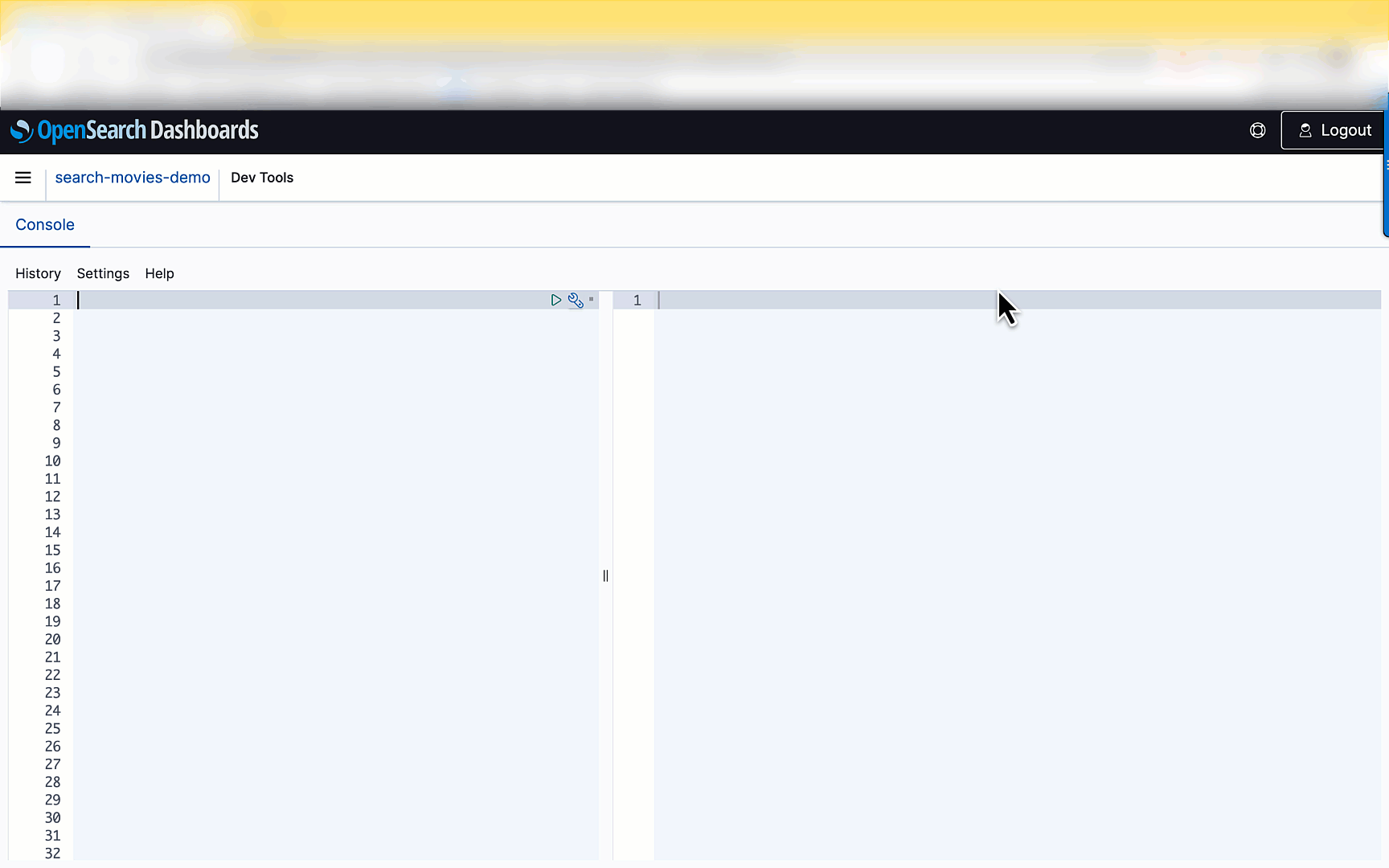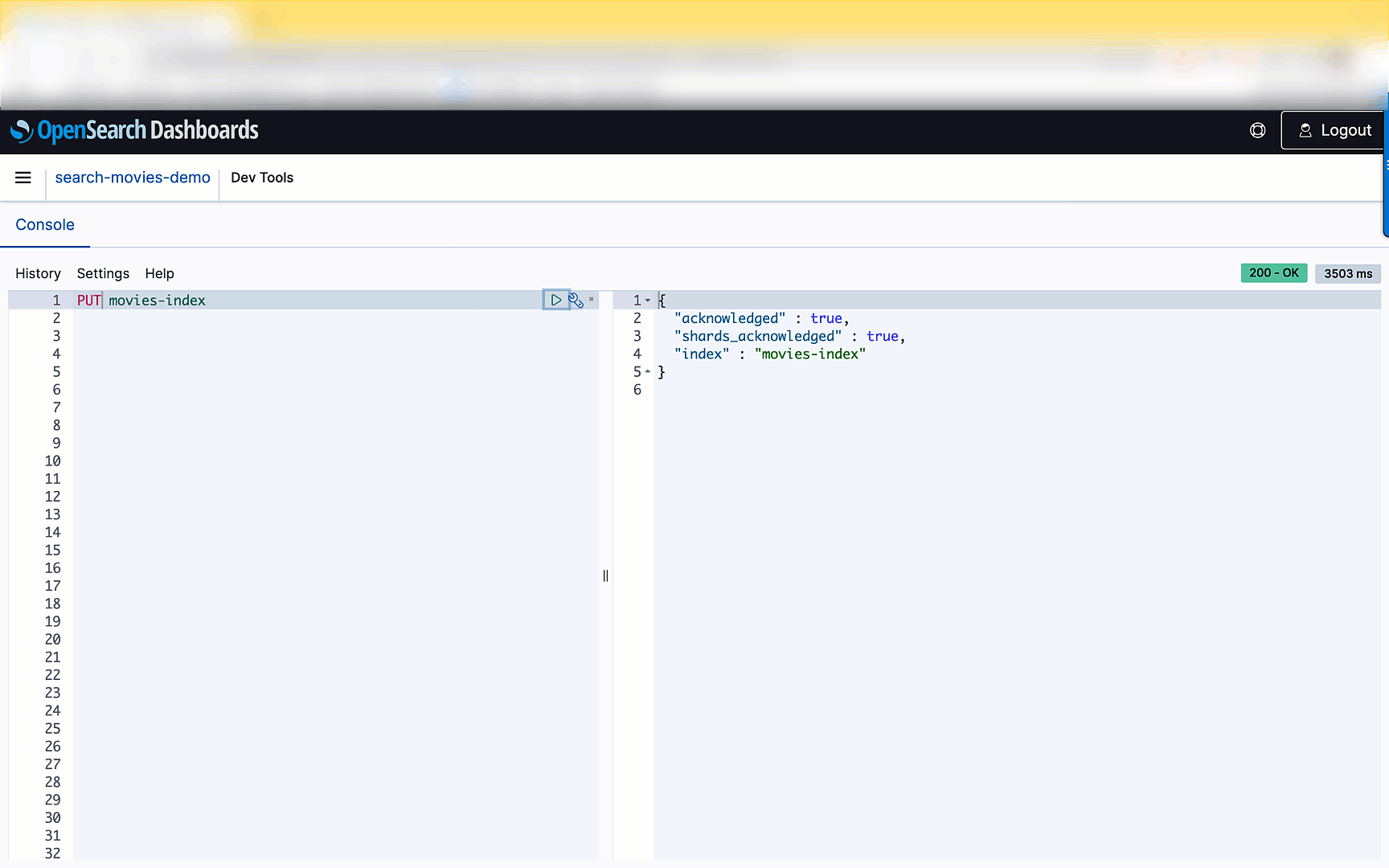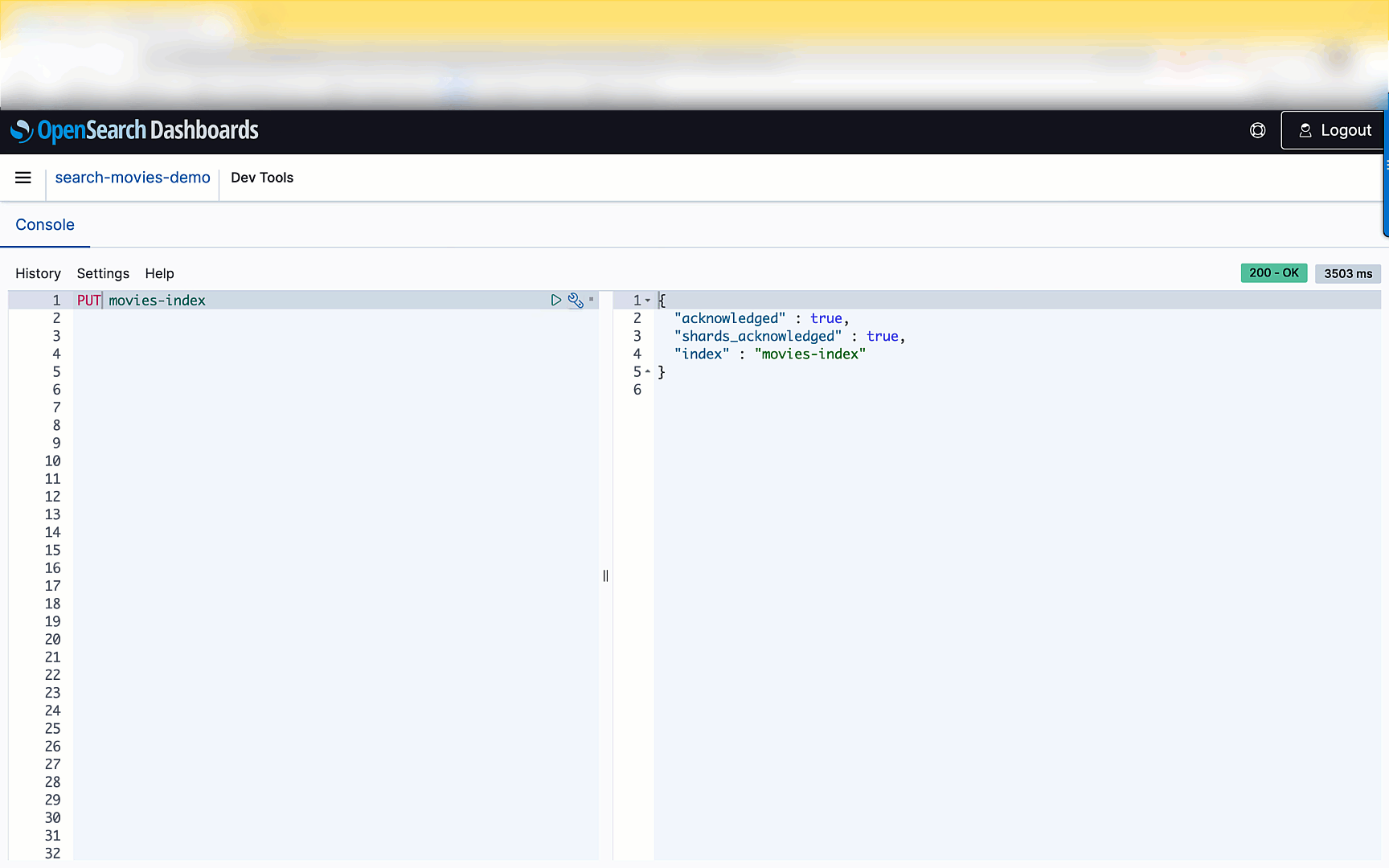
- Build a search application with Amazon OpenSearch Serverless how to build a simple search application using OpenSearch Serverless, but you could adapt for running your own self managed OpenSearch if you wanted
Quick updates
MariaDB
Amazon Relational Database Service (Amazon RDS) for MariaDB now supports Optimised Reads for up to 2X faster query processing compared to previous generation instances. Optimised Read-enabled instances achieve faster query processing by placing temporary tables generated by the MariaDB server on the NVMe SSD-based block-level instance storage that’s physically connected to the host server. Complex queries that utilise temporary tables, such as queries involving sorts, hash aggregations, high-load joins, and Common Table Expressions (CTEs) can now execute up to 2X faster with Optimised Reads on RDS for MariaDB.
Optimised Reads is available by default on RDS for MariaDB version 10.4.25, 10.5.16, 10.6.7 and higher on Intel-based X2iedn, M5d and R5d instances and AWS Graviton2-based M6gd and R6gd database (DB) instances. R5d and M5d DB instances provide up to 3,600 GiB of NVMe SSD-based instance storage for low latency, high random I/O and sequential read throughput. X2iedn, M6gd and R6gd DB instances are built on the AWS Nitro System, and provide up to 3,800 GiB of NVMe-based SSD storage and up to 100 Gbps of network bandwidth.
Amazon EMR
Amazon EMR Serverless is a serverless option in Amazon EMR that makes it simple for data engineers and data scientists to run open-source big data analytics frameworks without configuring, managing, and scaling clusters or servers. Today, we are excited to announce that EMR Serverless now allows you to customise images for Apache Spark and Hive. This means that you can package application dependencies or custom code in the image, simplifying running Spark and Hive workloads.
Running custom images simplifies many big data analytics use cases. For example, data engineers can customise the default release image to package common dependencies, custom code, specific Java or Python versions, or SSL certificates required by workloads. They can then store these customised images in Amazon Elastic Container Repository (ECR), making it easy to run Spark workloads with custom dependencies. Security engineers can scan these images to comply with organisational standards. Data Scientists can customise runtime images to include proprietary libraries or specific Python packages. Further, EMR Serverless releases can directly be integrated with your organisation’s Docker build, test and deployment processes, simplifying continuous integration and continuous delivery (CI/CD) of applications.
To find out more, read the blog post Add your own libraries and application dependencies to Spark and Hive on Amazon EMR Serverless with custom images where Veena Vasudevan provides a nice walkthrough of how you can use this new feature.

Videos of the week
Ray
AWS Glue comes with a new engine option called Ray. Ray allows to process large amount of data using python script and python libraries. Ray is based on open-source compute framework and it helps build enterprise level scalable jobs as it leverages distributed processing of the data. This is a great primer on this topic, and provides good background and then a hands on walkthrough.
Apache Cassandra
Check out the post, Amazon Keyspaces (for Apache Cassandra) re:Invent 2022 recap that provides links to the re:Invent 2022 sessions featuring Apache Cassandra, including DAT327, DAT217, and the database leadership sessions. A must for all users of Apache Cassandra.
Apache Iceberg
Dremio’s Developer Advocate Dipankar Mazumdar shows how to use AWS Glue as a catalog with Apache Iceberg & Spark in this hands-on video.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (eight) of the episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
If you are planning any events in 2023, either virtual, in person, or hybrid, get in touch as I would love to share details of your event with readers.
FOSSDEM Feb 4-5th, 2023 in Brussels
FOSDEM is a free event for software developers to meet, share ideas and collaborate. Every year, thousands of developers of free and open source software from all over the world gather at the event in Brussels. 4 & 5 February 2023. A must attend event for all open source fans, check out and register via this link.
State of Open Con 23 Feb 7-8th, 2023 in London
OpenUK will be hosting a 1000 person plus two day conference in Central London, “State of Open Con 23” in association with IEEE, the headline sponsor. Check out more info and sign up here.
Everything Open March14-15th Melbourne, Australia
A new event for the fine folks in Australia. Everything Open is running for the first time, and the organisers (Linux Australia) have decided to run this event to provide a space for a cross-section of the open technologies communities to come together in person. Check out the event details here. The CFP us currently open, so why not take a look and submit something if you can.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen