AWS open source news and updates #133
October 28th, 2022 - Instalment #133
Welcome
Welcome to the AWS open source newsletter, edition #133. This week has been all about KubeCon, and there were some important announcements from AWS. If you missed these, I have tried to capture the important ones here, but I want to start off with probably my favourite which was the announcement during Nate Taber keynote on some of the investments we are providing to CNCF and OpenSSF. AWS is providing $3 million in credits to CNCF, as well as providing $10 million over 3 years to the Open SSF and providing fixes and test suites to open source projects.
This week we feature the following new open source projects, “aws-logs-comptroller” keep on top of your AWS CloudWatch log groups, “cloudcanvas” a Mac based app for interacting with some of your AWS resources, “atlearn” a tool to help you with transfer learning, “aws-code-habits” bootstrap your dev setup with some good defaults, “cargo-check-external-types” a tool for Rust developers, “OQpy”, “spin-wasm-multi-compute” a science project on wasm, and plenty more.
We also cover open source topics including MySQL, MariaDB, cdk8s, Apache Kafka, Apache CloudStack, Red Hat Enterprise Linux, OpenFold, Composer, Flask, OQpy, Kotlin, AWS CDK, eventcatalog, traefik, Redis, CNCF, OpenSSF, Ploomber, Soopervisor, and more! Before you go, make sure you check out this weeks videos and we have the usual round up of open source events that are coming up.
Feedback
Please let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing this very short survey that will take you probably less than 30 seconds to complete. Thank you so much!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Sai Vennam, Toshal Dudhwala, Imaya Kumar Jagannathan, Massimo Re Ferrè, Matt Morgan, Shimon Tolts, Philip Reinhold, Li Chen, Jean-Christophe Jaskula, Peter Karalekas, Stephanie Teo, Bandish Shah, Olivier Cruchant, Joseph Keating, Matt Hedges, Steve Roberts, Angel Pizarro, Jason Rupard, Mariana Ramos Franco, Ran Isenberg, Matt Martz, Abhishek Gupta, John Mille, and Elena van Engelen-Maslova.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
aws-logs-comptroller
aws-logs-comptroller is a neat project from Matt Morgan that I found via Corey’s newsletter that allows you to keep on top of your AWS CloudWatch log groups. AWS Logs Comptroller is a CDK Construct that can be used to set CloudWatch log retention as well as prune orphaned LogGroups. AWS Logs Comptroller is written entirely using Step Functions and ASL. As I often have to manually do this for the demos I run, this is going to come in super handy.
cloudcanvas
cloudcanvas is an interesting project to keep your eyes on that provides an interactive canvas to help you manage your cloud resources. It is a downloadable app for your Mac (sorry, Mac only from the looks of it at the moment) that allows you to have a more interactive experience when working with AWS. Currently as this is in early stages, it offers a limited set of AWS services. I have downloaded and installed it, but just need to sort out my test SSO account before I can get stuck in. If I get time, I might show this on the next episode of Build on Open Source.
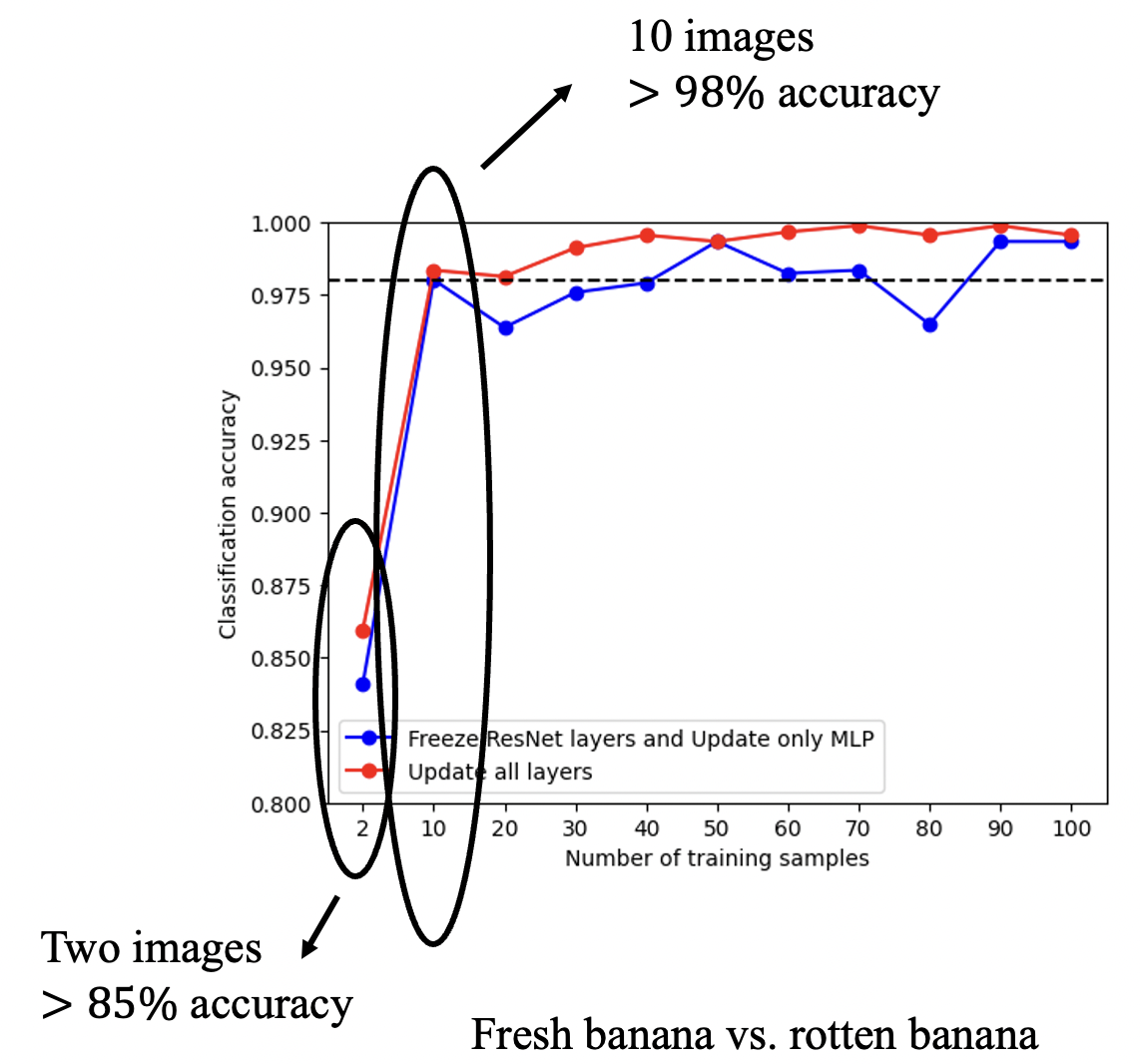
atlearn
atlearn is a Transfer Learning toolkit that supports easy model building on top of the pre-trained models. It provides a set of APIs that enable users to load pre-trained models, build and train their customised transfer learning models, and export the models for inference and deployment. Read the documentation to find out more about why this tool was created and some of the benefits, and then check out the demos provided.
aws-code-habits
aws-code-habits is a library with Make targets, Ansible playbooks, Jinja templates (and more) designed to boost common software development tasks and enhance governance. If you are looking for a way to automate and bootstrap your new projects, why not check this out.

cargo-check-external-types
cargo-check-external-types is a static analysis tool for Rust library authors to set and verify which types from other libraries are allowed to be are exposed in their public API. This is useful for ensuring that a breaking change to a dependency doesn’t force a breaking change in the library that’s using it.
The tool has two output formats to cover different use-cases:
- errors (the default): Output error messages for each type that is exposed in the public API and exit with status 1 if there is at least one error. This is useful for continuous integration.
- markdown-table: Output the places types are exposed as a Markdown table. This is intended as a discovery tool for established projects.
Make sure you check out the docs for more details on this handy tool, as well as some important prereq’s that you need before you can use this too.
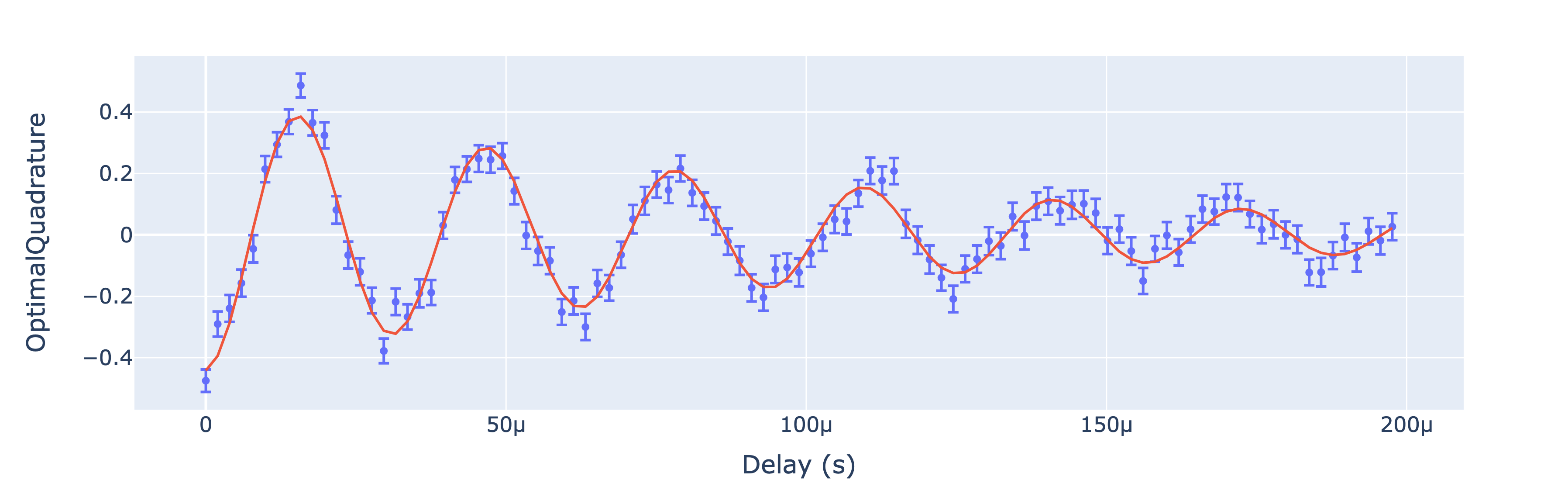
OQpy
OQpy The goal of oqpy (“ock-pie”) is to make it easy to generate OpenQASM 3 + OpenPulse in Python. The oqpy library builds off of the openqasm3 and openpulse packages, which serve as Python reference implementations of the abstract syntax tree (AST) for the OpenQASM 3 and OpenPulse grammars. What are OpenQASM 3 and OpenPulse? Well I had the same questions, and thankfully these are answered in the project readme. We also have this post, AWS open-sources OQpy to make it easier to write quantum programs in OpenQASM 3 where Philip Reinhold, Li Chen, Jean-Christophe Jaskula, Peter Karalekas, and Stephanie Teo collaborate to share an example of what is possible using OQpy and OpenQASM 3.
Demos, Samples, Solutions and Workshops
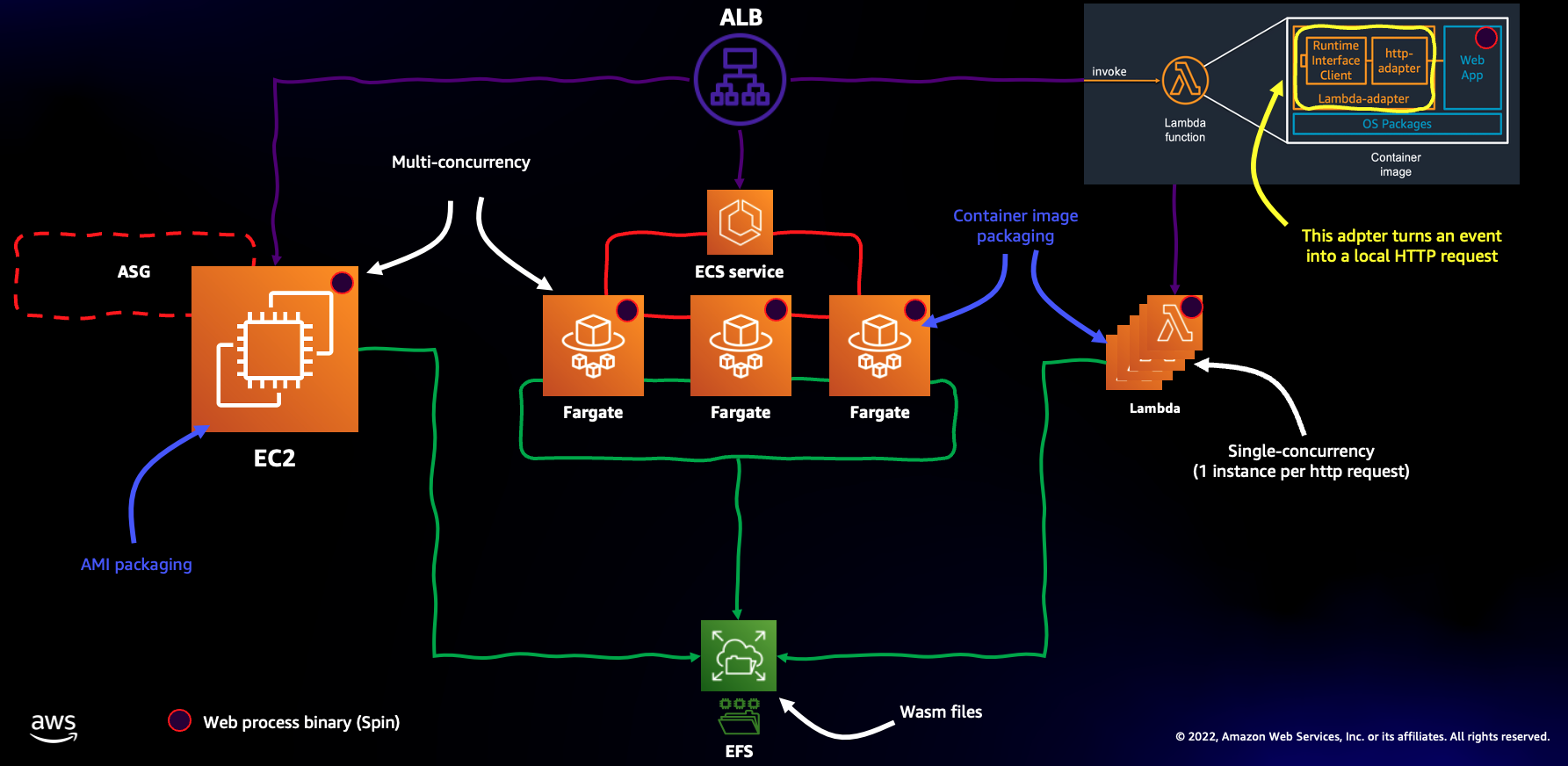
spin-wasm-multi-compute
spin-wasm-multi-compute is a new “science project” from all round good egg Massimo Re Ferrè where he provides some code samples as he explores the wonderful world of wasm. This demo repo is a rough proof of concept for running the same WASM artefact on Amazon EC2, Amazon ECS/Fargate and AWS Lambda. I also love how Massimo has used another open source project (cdk-dia) to visualise the resulting stack that is deployed via AWS CDK.
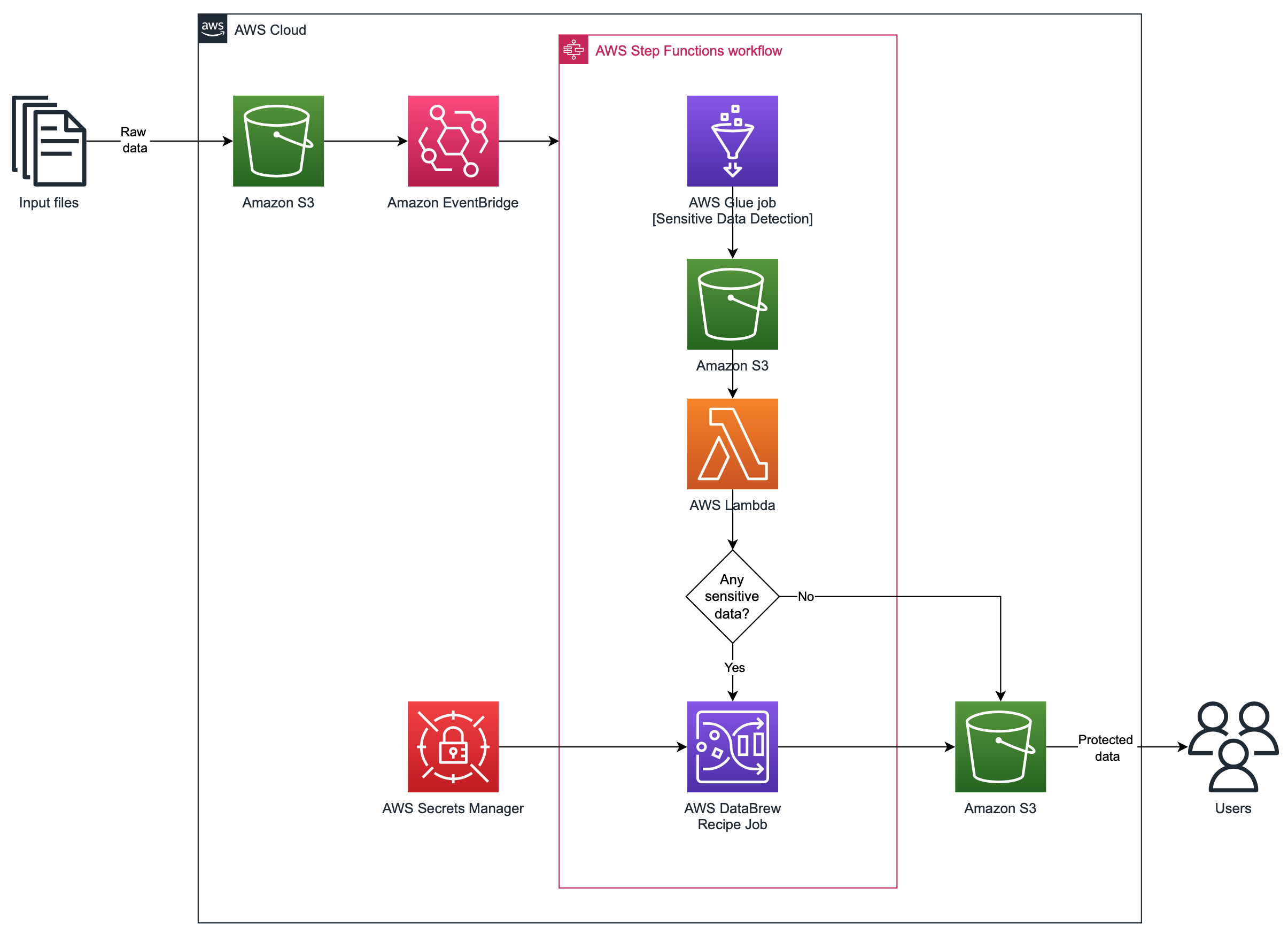
detect-and-handling-custom-pii-with-aws-glue-studio-and-aws-glue-databrew
detect-and-handling-custom-pii-with-aws-glue-studio-and-aws-glue-databrew aside from winning this weeks open source repo with the longest name, provides an AWS CloudFormation (CFn) template that builds sample data pipeline, with the functionality of identifying personal and sensitive data using the Sensitive Data Detection feature of AWS Glue Studio and apply hashing algorithm to protect columns identified with the use of AWS Glue DataBrew, through an event-driven and serverless architecture.
apprunner-hotel-app
apprunner-hotel-app this project provisions the base layer infrastructure to demonstrate how AppRunner leverages a VPC Connector to interact with a DB in a private subnet.
aws-dynamodb-parallel-queries
aws-dynamodb-parallel-queries this repo provides a sample application and queries for you to see how these work and then configure a load generator which you can tune, to see how they perform. Code is in Java.
selective-search-with-mutual-information-cotraining
selective-search-with-mutual-information-cotraining this repo provide code samples for the research paper, MICO: Selective Search with Mutual Information Co-training. What is this research paper on? From the paper:
In contrast to traditional exhaustive search, selective search first clusters documents into several groups before all the documents are searched exhaustively by a query, to limit the search executed within one group or only a few groups. Selective search is designed to reduce the latency and computation in modern large-scale search systems.
AWS and Community blog posts
AWS CDK
AWS Community Builder Ran Isenberg has put together this post, Deploy to AWS with GitHub Actions and AWS CDK that provides a hands on guide to show you how you can use AWS CDK to deploy your CDK stacks via GitHub Actions. Need to give this one a try at some point. [hands on]
eventcatalog
AWS Serverless Developer Advocate all round open source good guy, David Boyne built EventCatalog as a POC and experiment to see if it could help document event driven architectures. Earlier this week he shared a post on how some of the community have been using it and putting together “epic guides” (we need way more epic guides in my opinion). In Using AWS CDK to Deploy EventCatalog Matt Martz shows you how you can deploy EventCatalog to AWS using AWS CDK.

Redis
Fellow Developer Advocate Abhishek Gupta has put together something for Redis fans in his post, Using Redis on Cloud? Here are ten things you should know where he covers a range of Redis-related best practices, tips and tricks including cluster scalability, client side configuration, integration, and metrics.
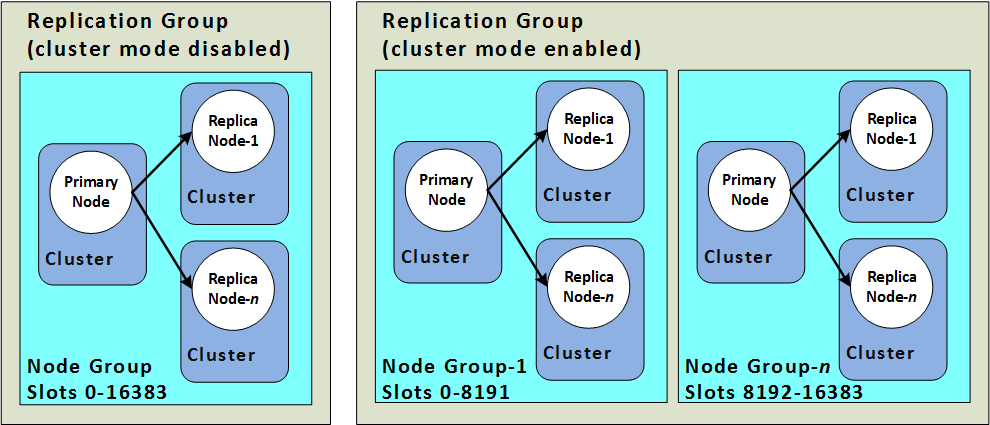
traefik
Traefik is a modern HTTP reverse proxy and load balancer that makes deploying micro services easy. AWS Community Builder John Mille has put together this post, Traefik Proxy in AWS with AWS ECS - Part 2, showing you how you can use this in conjunction with AWS ECS Anywhere to manage your ECS traffic where ever it is.
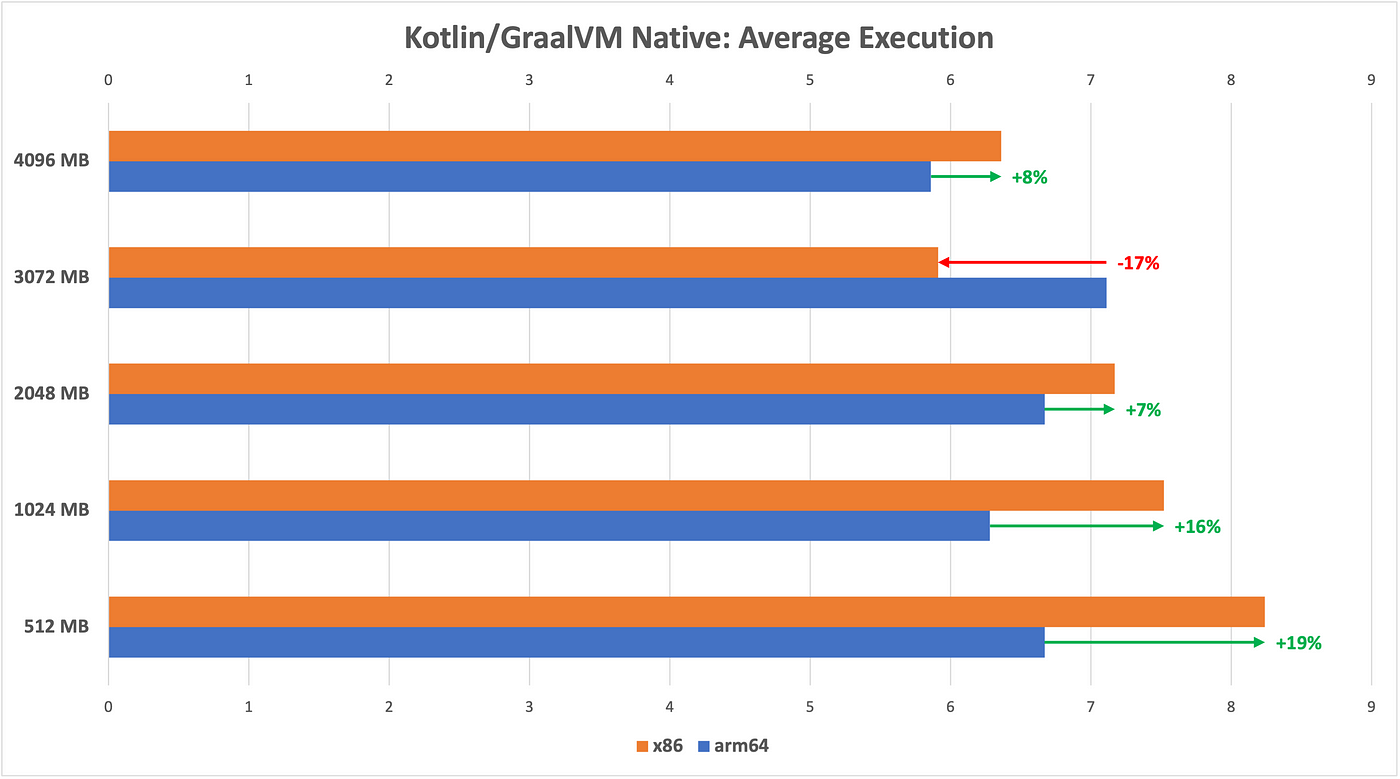
Kotlin
Elena van Engelen-Maslova dives deep into understanding the performance characteristics of Kotlin on AWS Lambda in her post, This Week in Kotlin on AWS Lambda: To ARM64 or Not To ARM64?. Exploring JVM and GraalVM native runtimes and how they compare are just some of the insights that await you dear reader.
Ploomber and Soopervisor
Ploomber and Soopervisor and two open source tools that you can use to build data pipelines in Python (Ploomber) and export those data pipelines to a number of outputs (Argo, Apache Airflow, AWS Batch and others). In the second part of a three part blog post, Deploying a Data Science Platform on AWS: Running containerized experiments (Part II) Eduardo Blancas provides a detailed walk through of how you can use these on AWS. Watch out for part three coming soon.
Flask
In the post, Automate Python Flask Deployment to the AWS Cloud, Joseph Keating and Matt Hedges demonstrate how to use AWS services and open source tools to automate the deployment of a Python Flask application to the AWS Cloud.
Composer
Composer is a PyTorch library that enables you to train neural networks faster, at lower cost, and to higher accuracy. In the post, Reduce deep learning training time and cost with MosaicML Composer on AWS Bandish Shah and Olivier Cruchant highlight challenges commonly reported specifically in Deep Learning (DL) training, and how the open-source library MosaicML Composer helps solve them.
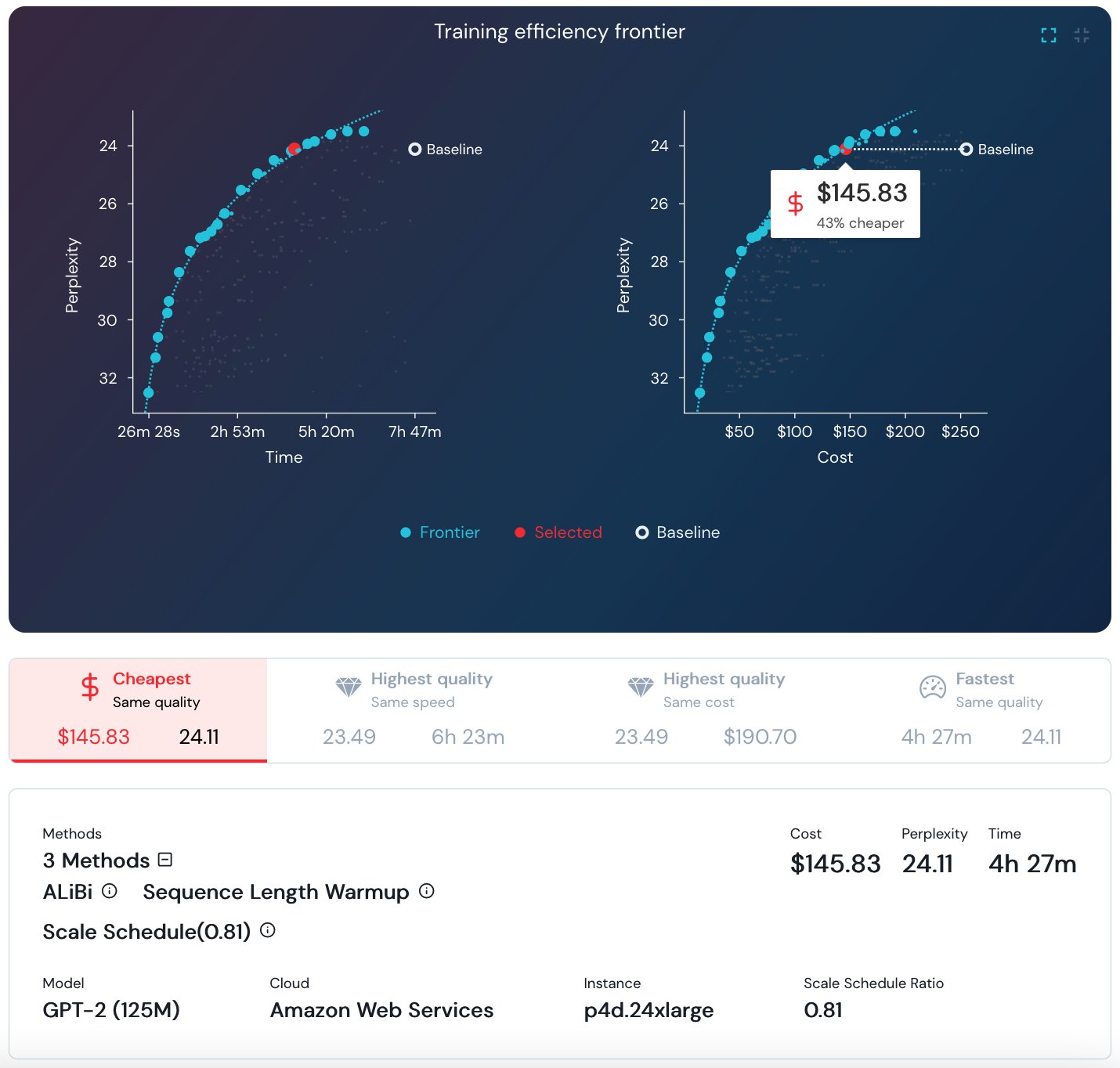
Other posts and quick reads
- Implementing Pod Security Standards in Amazon EKS provides a hands on guide on how to apply various Pod security standards in Amazon EKS [hands on]
- Run inference at scale for OpenFold, a PyTorch-based protein folding ML model, using Amazon EKS shows how you can deploy OpenFold models on Amazon Elastic Kubernetes Service (Amazon EKS) and how to scale the EKS clusters to drastically reduce MSA computation and protein structure inference times [hands on]
- Build real-time multi-user experiences using GraphQL on AWS Amplify is a tutorial where you will build a share-able todo list app using GraphQL and AWS Amplify [hands on]
Kubernetes
As KubeCon NA wraps up, there were a few announcements (covered below in the Quick Updates section) as well as some new blog posts that dive deeper into these.
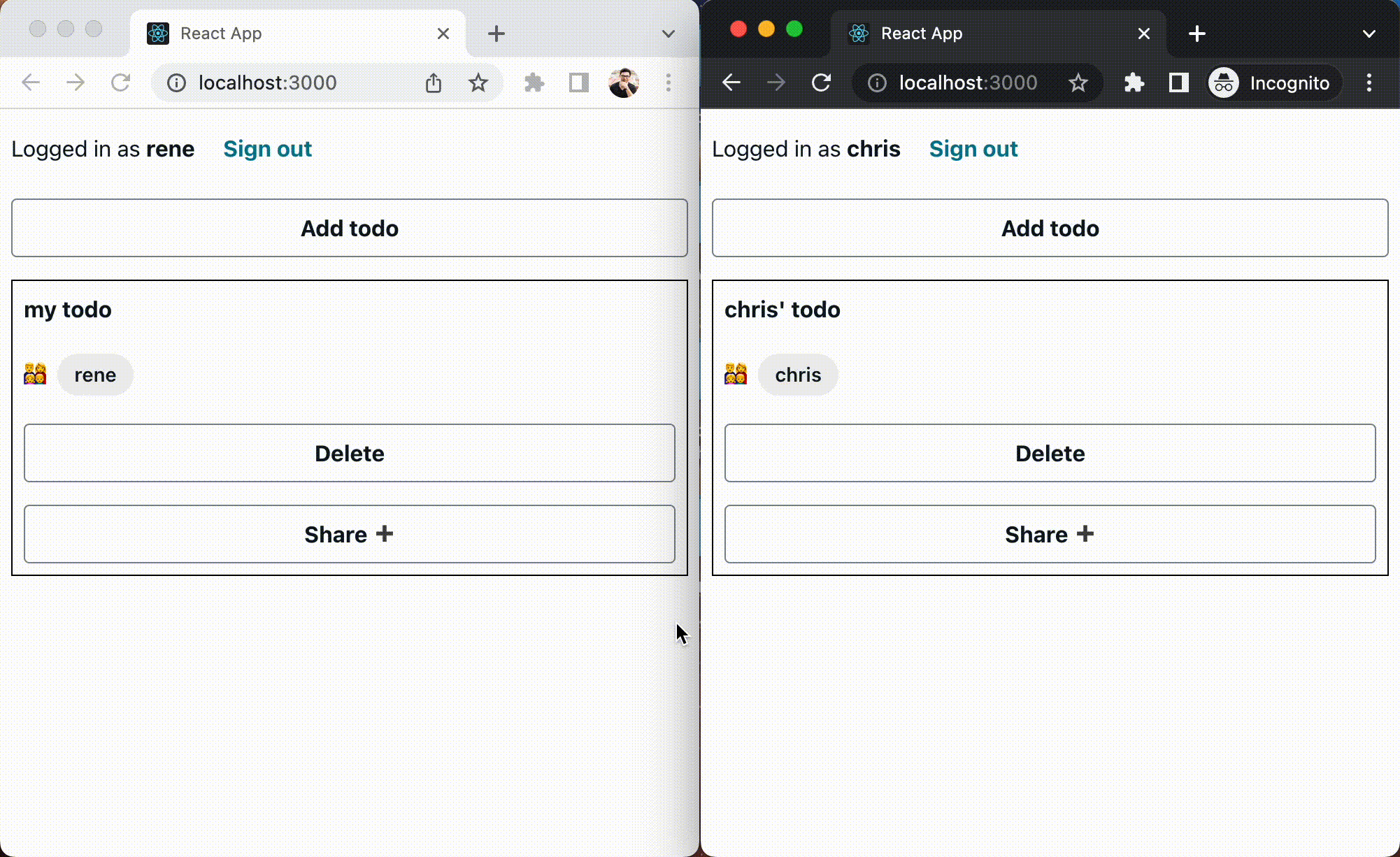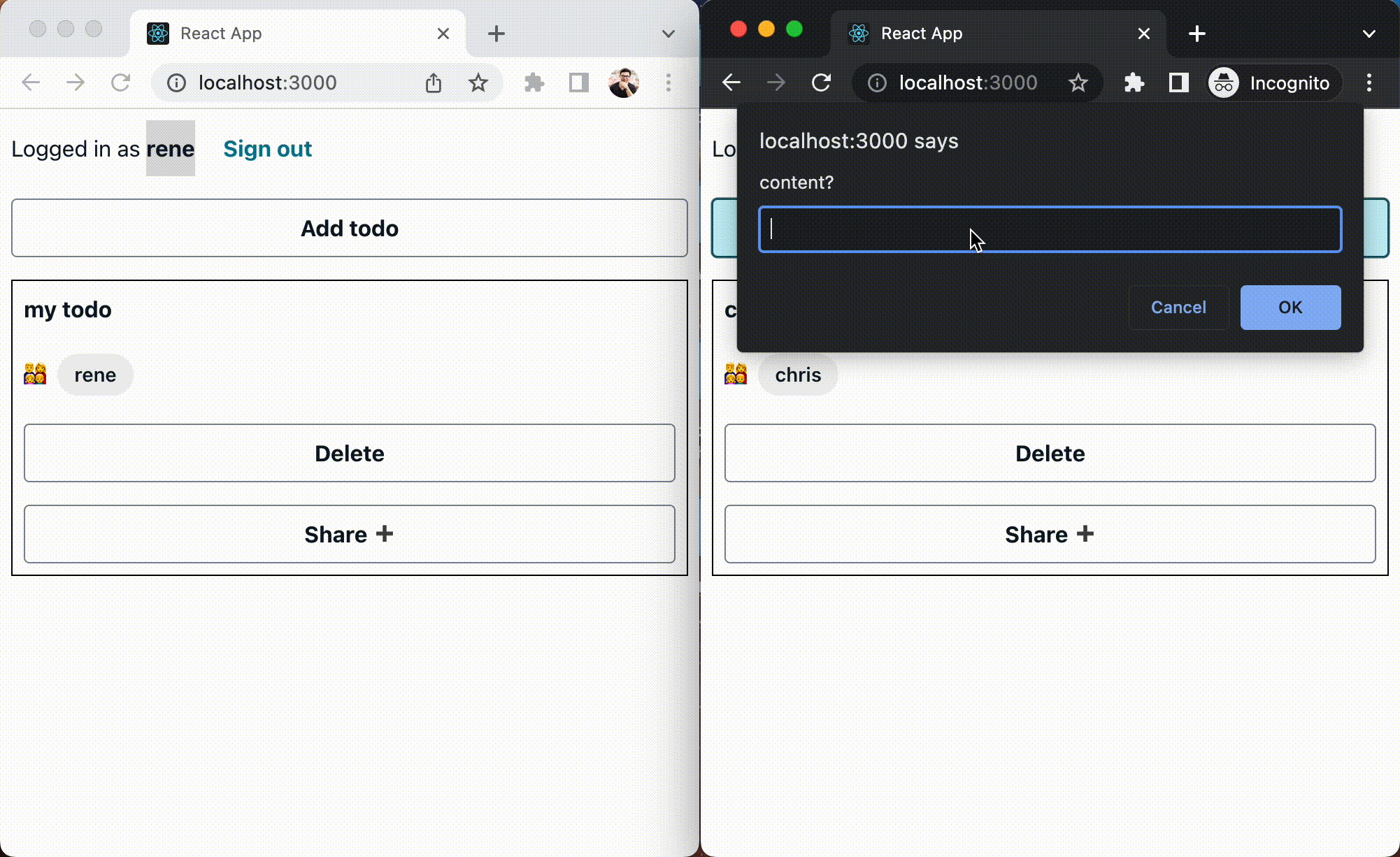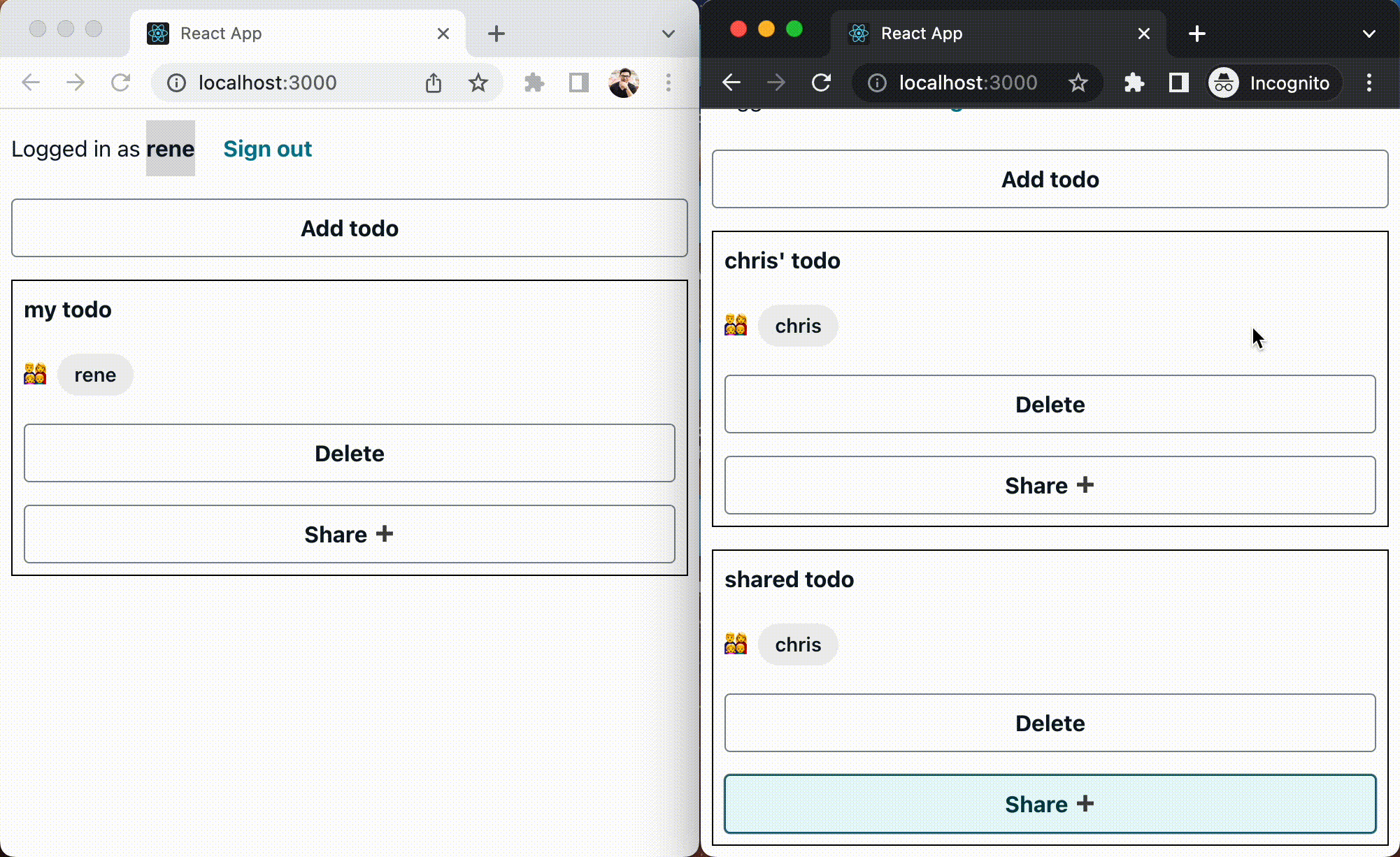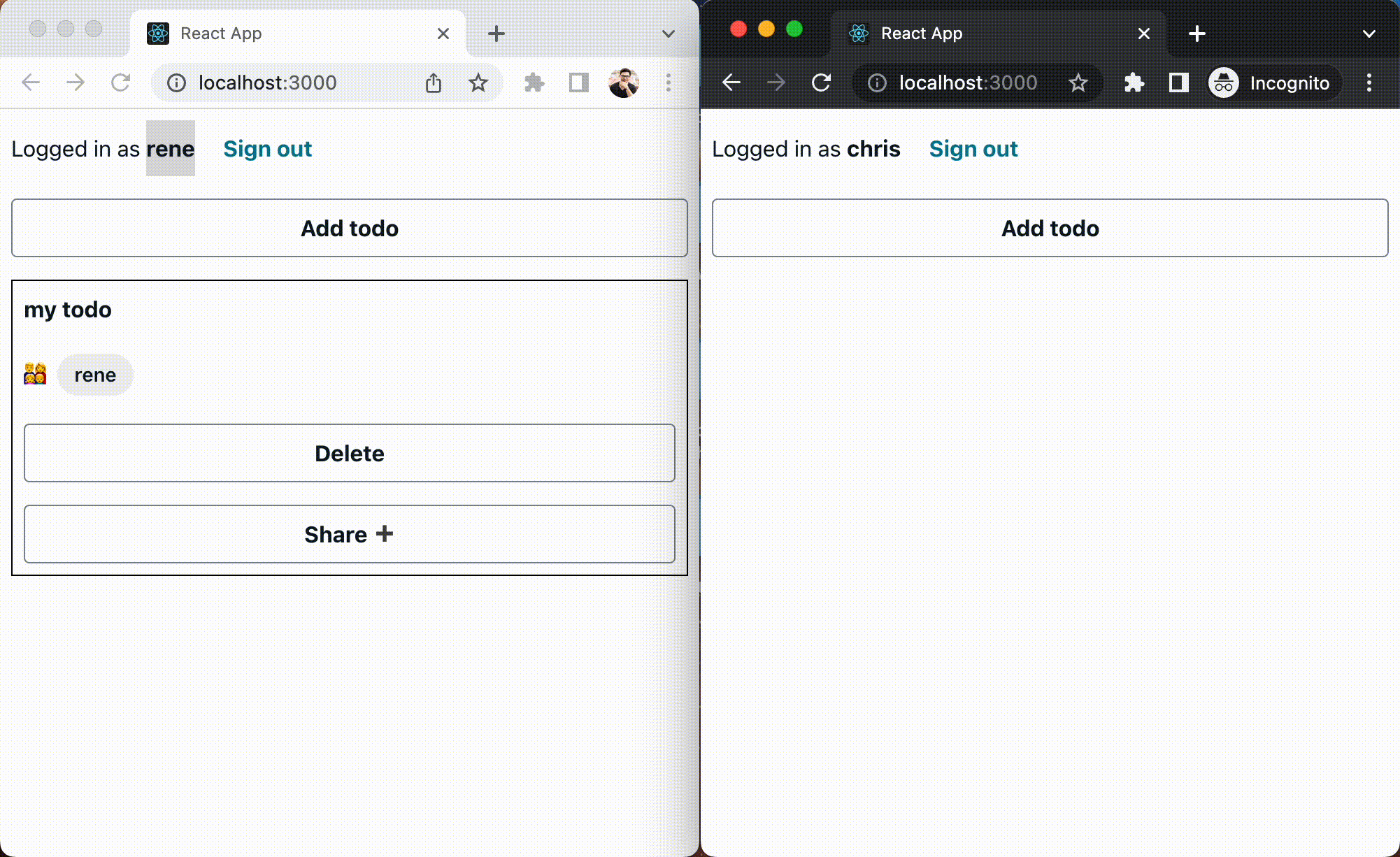
Steve Roberts took a look at AWS Batch for Amazon Elastic Kubernetes Service introducing what it is, and how it works.
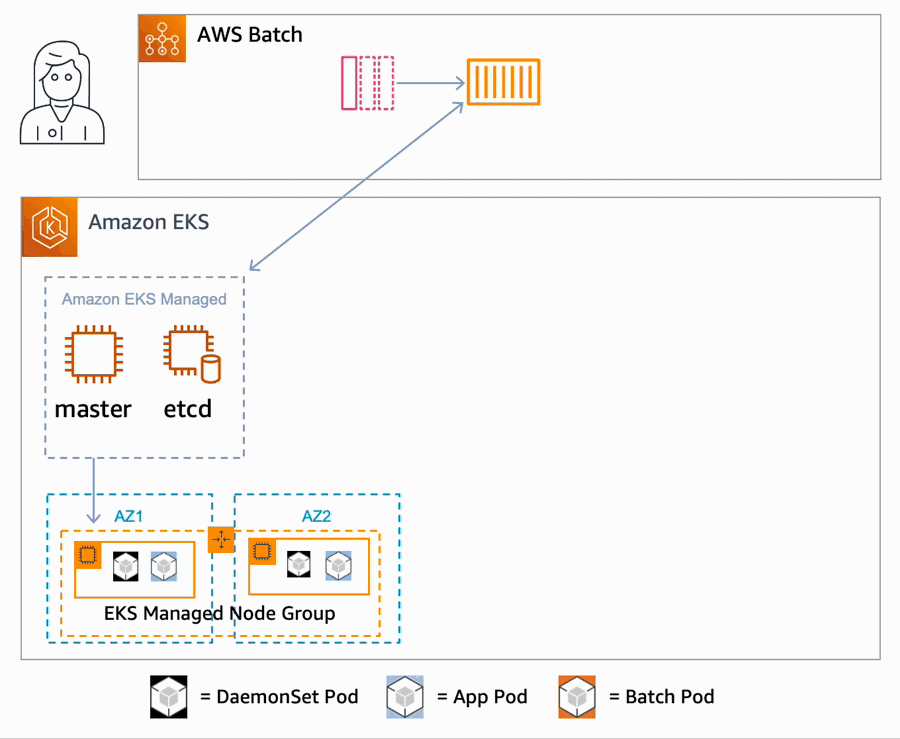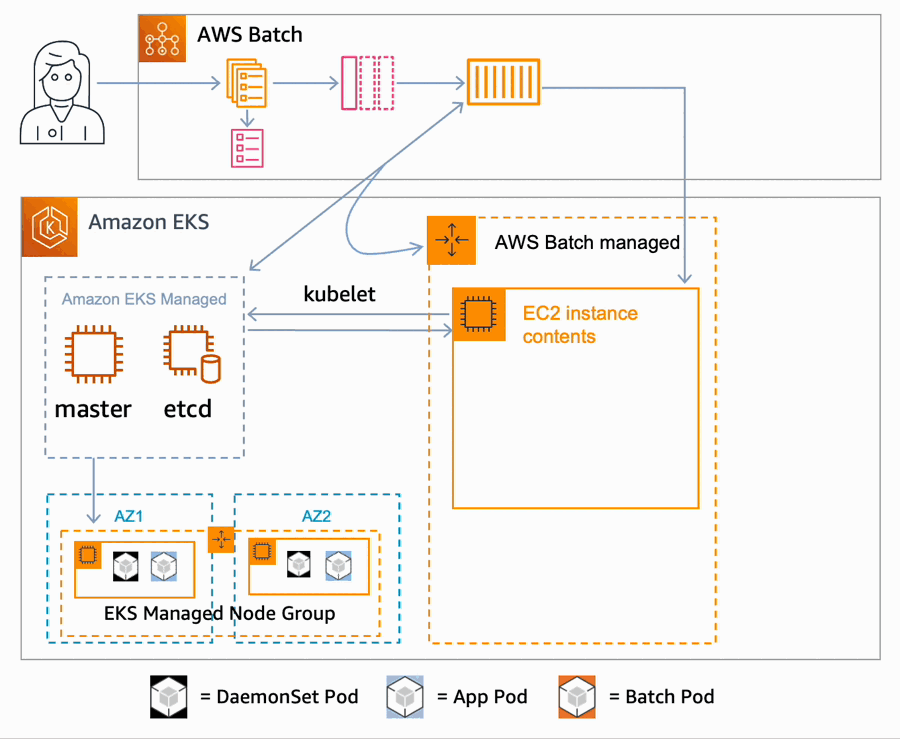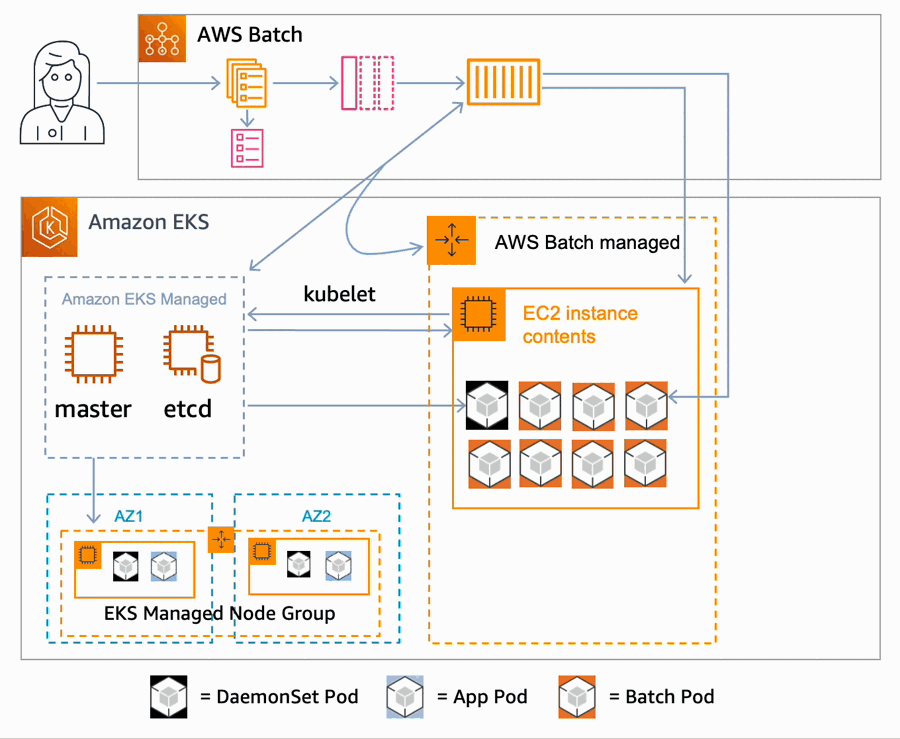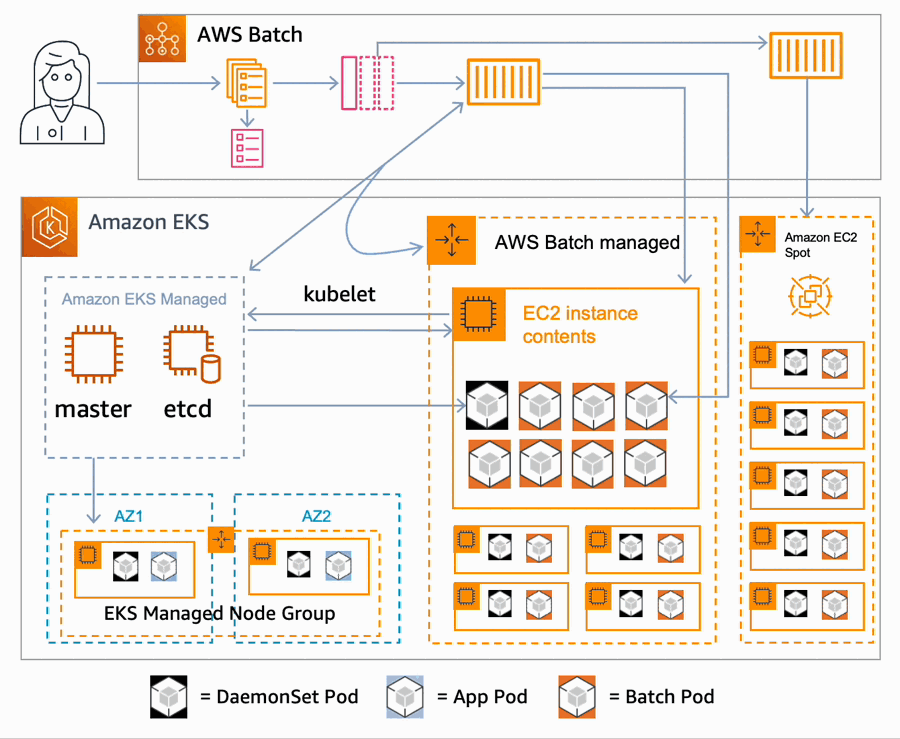
We also have this post, How AWS Batch developed support for Amazon Elastic Kubernetes Service where Angel Pizarro and Jason Rupard look behind the scenes and talk about the initial motivation and design choices when developing the service, as well as some of the challenges that the team overcame.
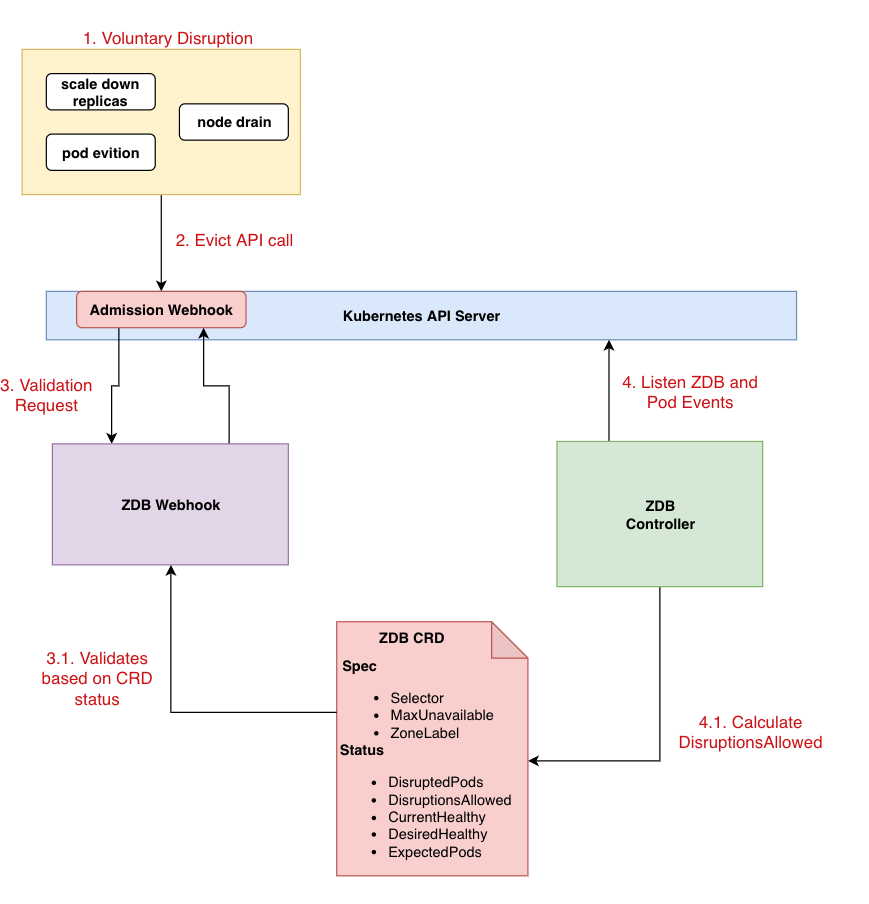
Whilst not related to KubeCon, Mariana Ramos Franco put together this post, Speed up Highly Available Deployments on Kubernetes. The Amazon Managed Service for Prometheus provides a Prometheus-compatible monitoring service that is operated on Kubernetes. In the post, she dives deep into the internals of our Prometheus service and how we speed up our deployment times without impacting availability.
Quick updates
Apache Kafka
Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports Apache Kafka version 3.3.1 for new and existing clusters. Apache Kafka 3.3.1 includes several bug fixes and new features that improve performance. Some of the key features include enhancements to metrics and partitioner. Amazon MSK will continue to use and manage Zookeeper for quorum management in this release for stability. For a complete list of improvements and bug fixes, see the Apache Kafka release notes for 3.3.1.
cdk8s
CDK For Kubernetes Plus (CDK8s+) is a multi-language class library for defining Kubernetes applications using high level intent based constructs. We featured a great overview of this in the last episode of Build on Open Source if you want a primer.
CDK8s+ aims to lower the entry barrier and improve maintainability of Kubernetes manifests by offering a hand crafted construct for each core Kubernetes object, exposing a richer API with reduced complexity. With this launch, CDK8s+ is now generally available and stable for use. This means that the API will remain unchanged and fully supported (no breaking changes), at least until the next major version. CDK8s+ is vended as a separate library for each Kubernetes spec version, all those libraries are now generally available and stable to use.
Customers also want to validate their manifest by applying either community or organisational policies. CDK8s now supports integration with third-party tools that facilitate this, and can perform validation as part of the synthesis process. This supports manifests produced by CDK8s adhering to the necessary policies.
If you want to read more about this, check out this post, Announcing general availability of cdk8s+ and support for manifest validation from Shimon Tolts, CEO and Co-Founder of Datree. The post shows you a few examples of how cdk8s+ can simplify the authoring of Kubernetes manifests, and how cdk8s+ can integrate with third-party policy enforcement tools (such as Datree), to provide a guardrail that protects your manifests against misconfigurations, and prevent them from reaching your cluster.
MySQL, MariaDB, and PostgreSQL
Amazon Relational Database Service (RDS) for MySQL, MariaDB and PostgreSQL now support 15 read replicas per instance, including up to 5 cross region read replicas, delivering up to 3X the previous read capacity.
Amazon RDS Read Replicas provide enhanced performance and durability for Amazon RDS database (DB) instances. They make it easy to elastically scale out beyond the capacity constraints of a single DB instance for read-heavy database workloads. You can create one or more replicas of a given source DB instance and serve high-volume application read traffic from multiple copies of your data, thereby increasing aggregate read throughput. For disaster recovery, read replicas can be promoted when needed to become standalone DB instances.
MySQL
Announced this week was up to 10x faster exports to Amazon S3 for snapshot exports for Amazon Aurora MySQL-Compatible Edition for MySQL 5.7 and 8.0. The performance improvement is automatically applied to all types of database snapshot exports, including manual snapshots, automated system snapshots, and snapshots created by the AWS Backup service.
With this capability, customers can export data up to 10x faster from an Amazon Aurora database and store it in an Amazon S3 bucket using AWS CLI or AWS Management Console. After the data is exported, they can analyze the exported data using Amazon Athena and/or other tools and services. The export process runs in the background and doesn’t affect the performance of active database instances.
Apache CloudStack
Apache CloudStack, a project of the Apache Software Foundation, is open source software designed to deploy and manage large networks of virtual machines. Amazon Elastic Kubernetes Service (Amazon EKS) Anywhere on Apache CloudStack was announced last week, and this expands the choice of infrastructure options for customers running Kubernetes on-premises. Apache CloudStack enhances the list of deployment options for Amazon EKS Anywhere customers, which already includes bare metal servers and VMware vSphere.
While developing this new feature, we collaborated with the Apache CloudStack community to build the Cluster API provider for Apache CloudStack (CAPC), which has now joined the Kubernetes SIG. Amazon EKS Anywhere leverages CAPC to provide customers declarative, Kubernetes-style APIs for cluster creation, configuration, and management.
Red Hat Enterprise Linux
In addition to Bottlerocket and Ubuntu, you can now use Red Hat Enterprise Linux (RHEL) and have broader choice of operating systems to create and operate Amazon EKS Anywhere clusters in your on-premises data centres. RHEL support is available for Amazon EKS Anywhere clusters running on VMware vSphere, on Apache CloudStack, or directly on bare metal servers.
RHEL is a popular operating system for on-premises workloads, and customers often customize their RHEL images with security hardening and other organisational best practices. Now, you can start from your custom base images, and use Amazon EKS Anywhere tooling to build RHEL images for running Kubernetes clusters.
Videos of the week
Kubernetes
Cloud Native Rejekts is the b-side conference giving a second chance to the many wonderful, but rejected, talks leading into KubeCon + CloudNativeCon. You will need to fast forward to 6:52:28 to hear Mariana Ramos Franco do a talk of her blog post that I have highlight above.
Crossplane
What is Crossplane? In this video, Sai Vennam from Containers from the couch shows you how Crossplane enables platform teams to manage their infrastructure and managed services on cloud providers like AWS. He outlines how you can use Crossplane to deploy and manage a production-ready Amazon EKS cluster.
Observability
Join Toshal Dudhwala and Imaya Kumar Jagannathan as they share how you can leverage AWS managed open-source observability solutions to monitor your containerised or serverless workloads at scale.
Build on Open Source
For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs.
We have put together a playlist so that you can easily access all the other episodes of the Build on Open Source show. Build on Open Source playlist
Events for your diary
All Things Open October 30th - 2nd November, Raleigh, NC
I am excited about attending and speaking at All Things Open next week (check out my session, Automating Data Pipelines with Apache Airflow) Matt Auerbach has put together this post, AWS at ATO 2022 and there will be a bunch of AWS open source folk at the AWS booth so hope to see some of you. I will have some very nice AWS Build On Open Source challenge coins, so come find me and share a story or swap some equally cool swag to bag one of these exclusive items.
Build on AWS Open Source November 4th, 9am BST
Join us for the sixth episode of the Build on AWS series, featuring a live round up of the latest projects and news as well as a special guest speaker. We have another special guest lined up, and I am very excited to welcome Javier Ramirez from QuestDB who will be coming on the show and sharing more about this open source times series database that is blazingly fast. Follow the show on @buildonopen for more details. Check it out on https://twitch.tv/aws
AWS Elastic Kubernetes Service (EKS) Workshop November 10th, London 5pm
Join us for an interactive workshop on containers, Docker, Fargate and Amazon EKS, hosted by ClearScale and AWS. This live, virtual workshop includes three hours of interactive presentation and hands-on lab work. You will take part in the setup and deployment of containers using EKS. Follow along and work directly with AWS professionals and ClearScale (an AWS Premier Tier Services Partner) in this Level 200 training session.
You can find out more about this event by checking out the event page and signing up.
re:Invent November 28th - December 3rd, Las Vegas
re:Invent is only a few weeks away so I want to share a few things that will hopefully be of interest.
First up, we will be running the Build On Live stream throughout re:Invent and we would love to feature you! If either yourself, or perhaps you know a community member going to re:Invent and think they will absolutely love to attend the livestream, we want to hear from you. Please nominate a community member you want to hear from during Build On Live using this survey.
Second, check out this handy way to look at all the amazing open source sessions, then check out this dashboard [sign up required]. I would love to hear which ones you are excited about so please let me know in the comments or via Twitter. If you want to hear what my top three, must watch sessions, then this is what I would attend (sadly, as an AWS employee I am not allowed to attend sessions)
- OPN306 AWS Lambda Powertools: Lessons from the road to 10 million downloads - Heitor Lessa is going to deliver an amazing session on the journey from idea to one of the most loved and used open source tools for AWS Lambda users
- BOA204 When security, safety, and urgency all matter: Handling Log4Shell - Cannot wait for this session from Abbey Fuller who will walk us through how we managed this incident
- OPN202 Maintaining the AWS Amplify Framework in the open - Matt Auerbach and Ashish Nanda are going to share details on how Amplify engineering managers work with the OSS community to build open-source software
There are many other great open source sessions, and hopefully I will try and put together a more comprehensive list as approach re:Invent.
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen