AWS open source news and updates #125
September 2nd, 2022 - Instalment #125
Welcome
After a couple of weeks off, it is great to welcome to back to the AWS open source newsletter, edition #125. As it has been a couple of weeks, this edition contains even more open source goodness to keep you occupied.
As always, we kick things off we a round up of new open source projects. Over the past couple of weeks, there were so many that it was hard to select them (I will include the others in next weeks newsletter). This weeks project include “AWSGoat” is a project that aims to help you better understand the thread landscape of your AWS environments, “amazon-ec2-instance-selector” is a nice cli tool to help you find the right Amazon EC2 instance you need, “merloc” is a tool that will help you develop and test AWS Lambda functions locally, “streaming-sales-generator” a tool that helps you generate sample date for testing/evaluating streaming technologies, “cw-logs-insights-snippets” is a handy tool to incorporate CloudWatch Log insight queries, “automated-iam-access-analyzer” provides a tool to monitor AWS IAM Role in order to achieve a continuous permission refinement, and many more tools, samples, demos and workshop repositories. Plenty to keep you going over the coming week for sure.
We also have a big collection of recommended reading for you this week, covering some great posts from the past two weeks on topics including Karpenter, Bottlerocket, Grafana, Keycloak, Calico, Jupyter, Open Omics Acceleration Framework, OpenAPI, Flyway, CollectD, Ray, Apache Hudi, Delta Lake, Apache Iceberg, dbt and many more!
If you prefer to consume your content in video form, then check out the videos this week that feature content on Rust, Backstage, AWS SAM, Kubeflow. Finally, check the events section for details of up and coming events you do not want to miss, including next week’s second episode of Build on AWS open source.
Feedback
If you enjoy reading this newsletter, please let me know how we can improve it as well as how AWS can better work with open source projects and technologies by completing this very short survey that will take you probably less than 30 seconds to complete. Thank you so much!
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Rosius Ndimofor, Suraj Narwade, Lars Jacobsson , Kyle Weller, Gary Stafford, Zach Mitchell, Aaron Miller, Siva Guruvareddiar, Luke Popplewell, Dillon Nys, Abdallah Shaban, Ashish Nanda, Harshad Gohil, John Lonappan, Daniel Lorch, James Eastham, Sai Vennam, Suzanne Daniels, Himanshu Mishra, Bryan Landes, Suman Debnath, Bimal Gajjar, Shane Miller
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
AWSGoat
AWSGoat is an open source project that aims to help you better understand the thread landscape of your AWS environments. Compromising an organization’s cloud infrastructure is like sitting on a gold mine for attackers. Sometimes a simple misconfiguration or a vulnerability in web applications is all an attacker needs to compromise the entire infrastructure. Since the cloud is relatively new, many developers are not fully aware of the threatscape and they end up deploying a vulnerable cloud infrastructure.
AWSGoat is a vulnerable by design infrastructure on AWS featuring the latest released OWASP Top 10 web application security risks (2021) and other misconfiguration based on services such as IAM, S3, API Gateway, Lambda, EC2, and ECS. AWSGoat mimics real-world infrastructure but with added vulnerabilities. It features multiple escalation paths and is focused on a black-box approach.
There are plenty of other news posts that mentioned this project, and I found this one, AWSGoat Open-Source Project for Pen Testing AWS Cloud Solutions, particular helpful.
cw-logs-insights-snippets
cw-logs-insights-snippets is an AWS SAM project from AWS Community Builder Lars Jacobsson that adds the snippets from serverlessland.com/snippets as saved queries in CloudWatch Logs. Serverlessland.com/snippets hosts a growing number of community provided snippets. Many of these are useful CloudWatch Logs Insights snippets. Until AWS integrates these in the console natively you can use this stack to get them there.
kubectl-eks
kubectl-eks is kubectl plugin for Amazon EKS from AWS Community Builder Suraj Narwade.
streaming-sales-generator
streaming-sales-generator is a handy tool from Gary Stafford that generates sample streaming sales data for Apache Kafka, written in Python. Each time you want to explore or demonstrate a new streaming technology, you must first find an adequate data source or develop a new source. Ideally, the streaming data source should be complex enough to perform multiple types of analyses on and visualise different aspects with Business Intelligence (BI) and dashboarding tools. Additionally, the streaming data source should possess a degree of consistency and predictability while still displaying a reasonable level of natural randomness. Conversely, the source should not result in an unnatural uniform distribution of data over time. This project’s highly configurable synthetic data generator (producer.py) streams beverage products, semi-random beverage sales transactions, and inventory restocking activities to Apache Kafka topics. It is designed for demonstrating streaming data analytics tools, such as Apache Spark Structured Streaming, Apache Beam, Apache Flink, Apache Pinot, Databricks, Google Cloud Dataproc, and Amazon Kinesis Data Analytics.
Check out the docs, which include a short video to show you how you can get this tool up and running
amazon-ec2-instance-selector
amazon-ec2-instance-selector is a CLI tool and go library which recommends instance types based on resource criteria like vcpus and memory. There are over 270 different instance types available on EC2 which can make the process of selecting appropriate instance types difficult. Instance Selector helps you select compatible instance types for your application to run on. The command line interface can be passed resource criteria like vcpus, memory, network performance, and much more and then return the available, matching instance types. Check out the repo for plenty of examples of how you can use this command.
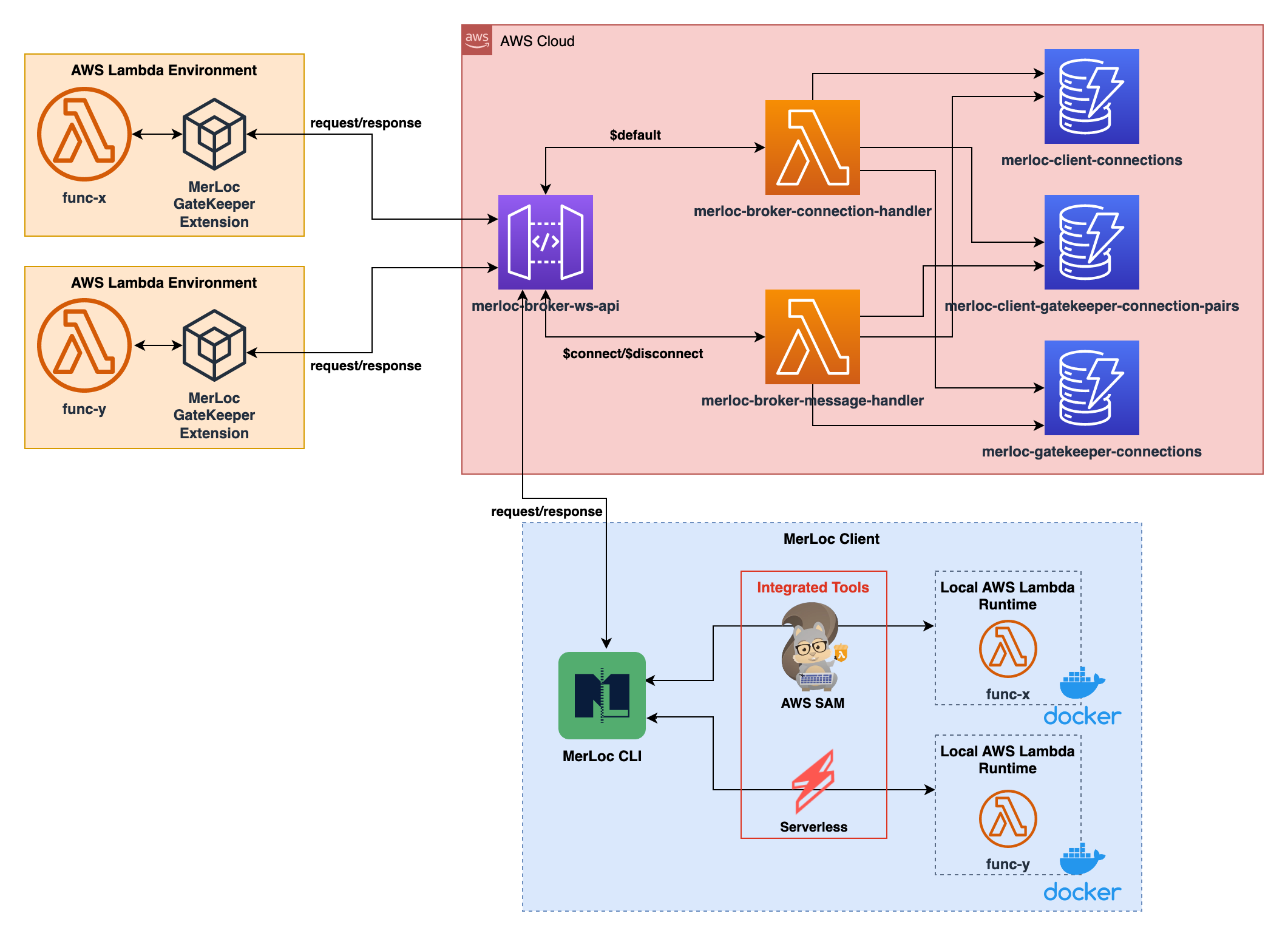
merloc
merloc AWS Hero Serkan Özal tweeted about this new project just before I disappeared on holiday. In his tweet he says:
I am thrilled to announce @thundraio MerLoc an AWS Lambda local development, testing, debugging and hot-reload tool to build and ship #serverless applications faster without need to add console logs and re-deploys after changes
MerLoc is a live AWS Lambda function development and debugging tool. MerLoc allows you to run AWS Lambda functions on your local while they are still part of a flow in the AWS cloud remote. Looks very interesting indeed.
automated-iam-access-analyzer
automated-iam-access-analyzer is a sample implementation of a periodical monitoring of an AWS IAM Role in order to achieve a continuous permission refinement of that role. The goal of the solution is to present an operational, continuous least-privilege approach for a particular role in order to provide for security proliferation in an ongoing manner. Automated IAM Access Analyzer relies on the AWS CloudTrail, AWS IAM Access Analyzer for policy generation, and AWS Step Functions for orchestrating the overall process.
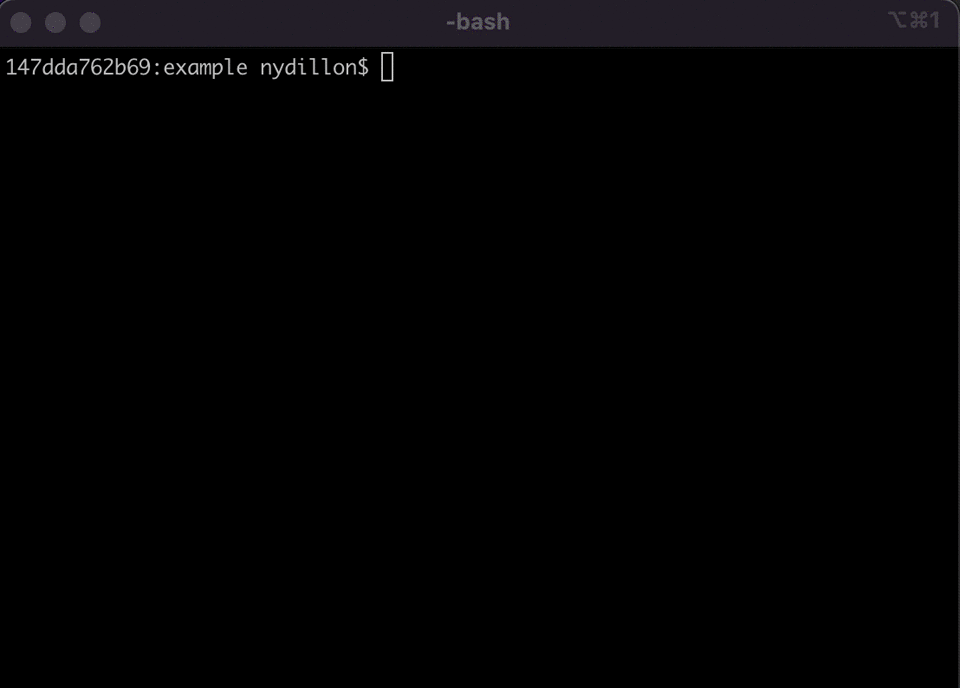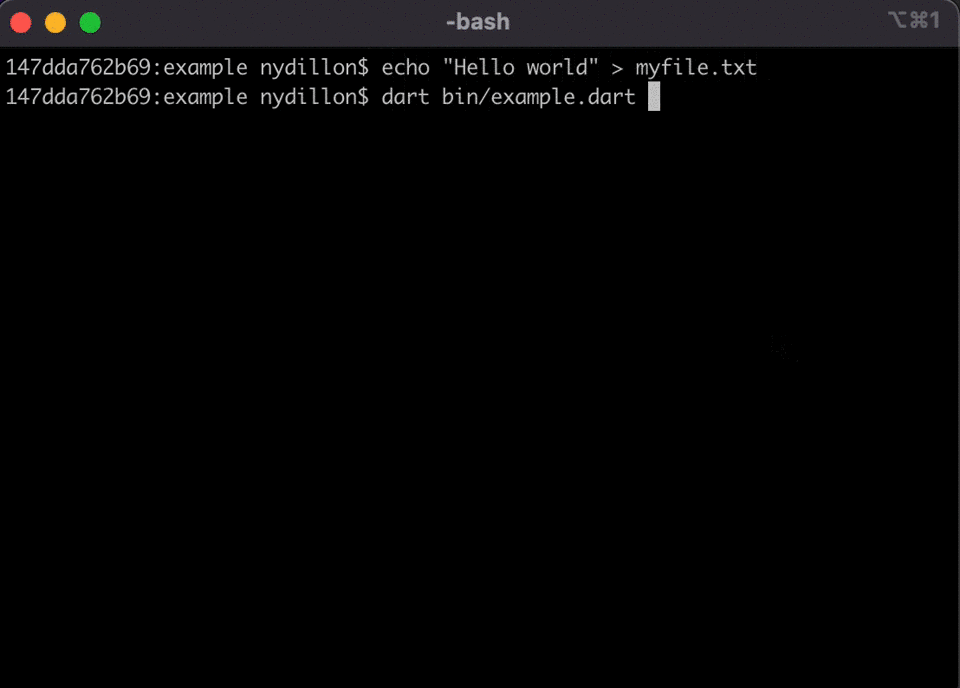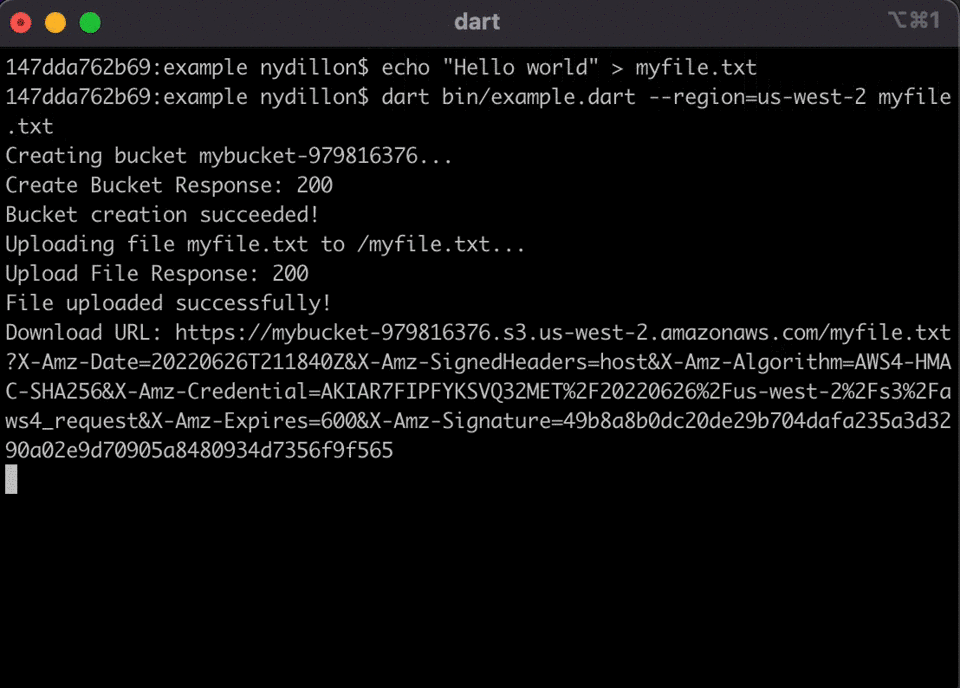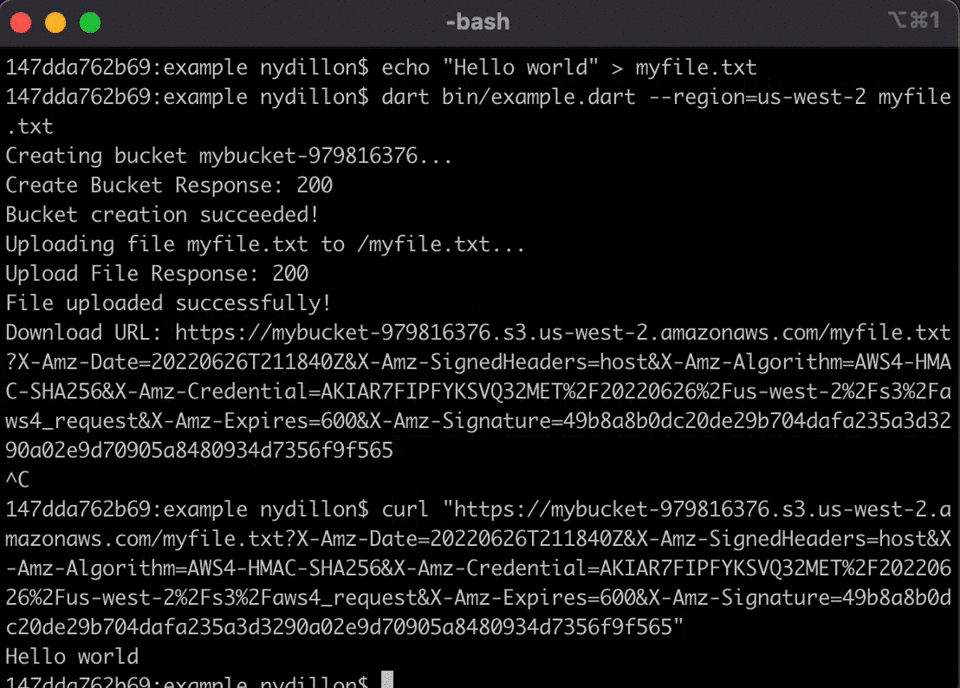
aws_signature_v4
aws_signature_v4 is an open source implementation of the AWS Signature Version 4 protocol in the Dart programming language. The SigV4 signer is a library which developers can include in their projects to sign and send HTTP requests to AWS services using their AWS credentials. To get you started, check out the post Introducing the AWS SigV4 Signer for Dart from Dillon Nys, Abdallah Shaban, and Ashish Nanda.
Demos, Samples, Solutions and Workshops
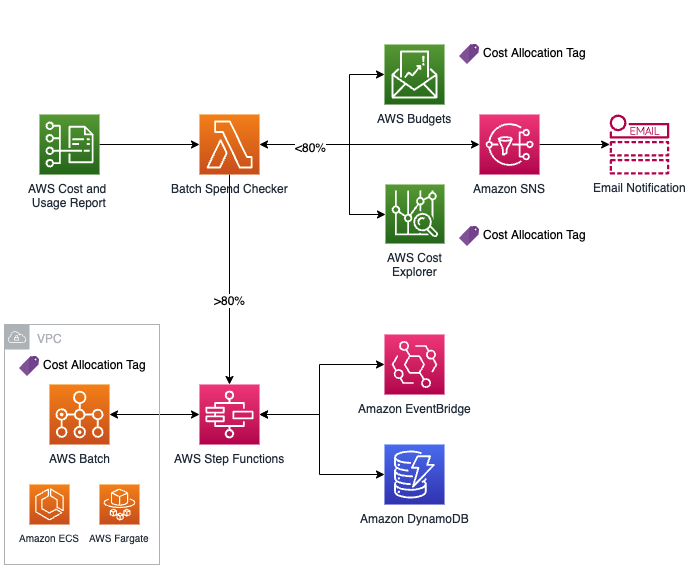
serverless-batch-cost-guardian
serverless-batch-cost-guardian this repo has the code that will deploy and provide a serverless solution that watches jobs in an AWS Batch (Fargate-only) compute environment, and if an AWS Budget threshold is close to being met, will kick in a high-frequency cost checker to stop all jobs before the budget is met. This solution is meant to be a safeguard for long-running jobs and can evaluate Budget status at a much higher rate than AWS Billing’s 2-3 daily limit with 6-8 hour granularity.
graviton2-based-ecommerence-solution
graviton2-based-ecommerence-solution if you are looking for some code for a sample e-commerce solution that leverages AWS Graviton2, then check out this repo. It provides the code from the Graviton2-based-ecommerence-solution Workshop which you will find links for in the README.
aws-mainframe-modernization-carddemo
aws-mainframe-modernization-carddemo is a Mainframe application designed and developed to test and showcase AWS and partner technology for mainframe migration and modernisation use-cases such as discovery, migration, modernisation, performance test, augmentation, service enablement, service extraction, test creation, test harness, etc. I am a big fan of retro computing, and this project really appeals so I need to try and figure out how I can get this one up and running - watch this space!
sam_stepfunctions
sam_stepfunctions AWS Hero Rosius Ndimofor shares a simple Step functions workflow written in SAM and Python for an apartment booking application.
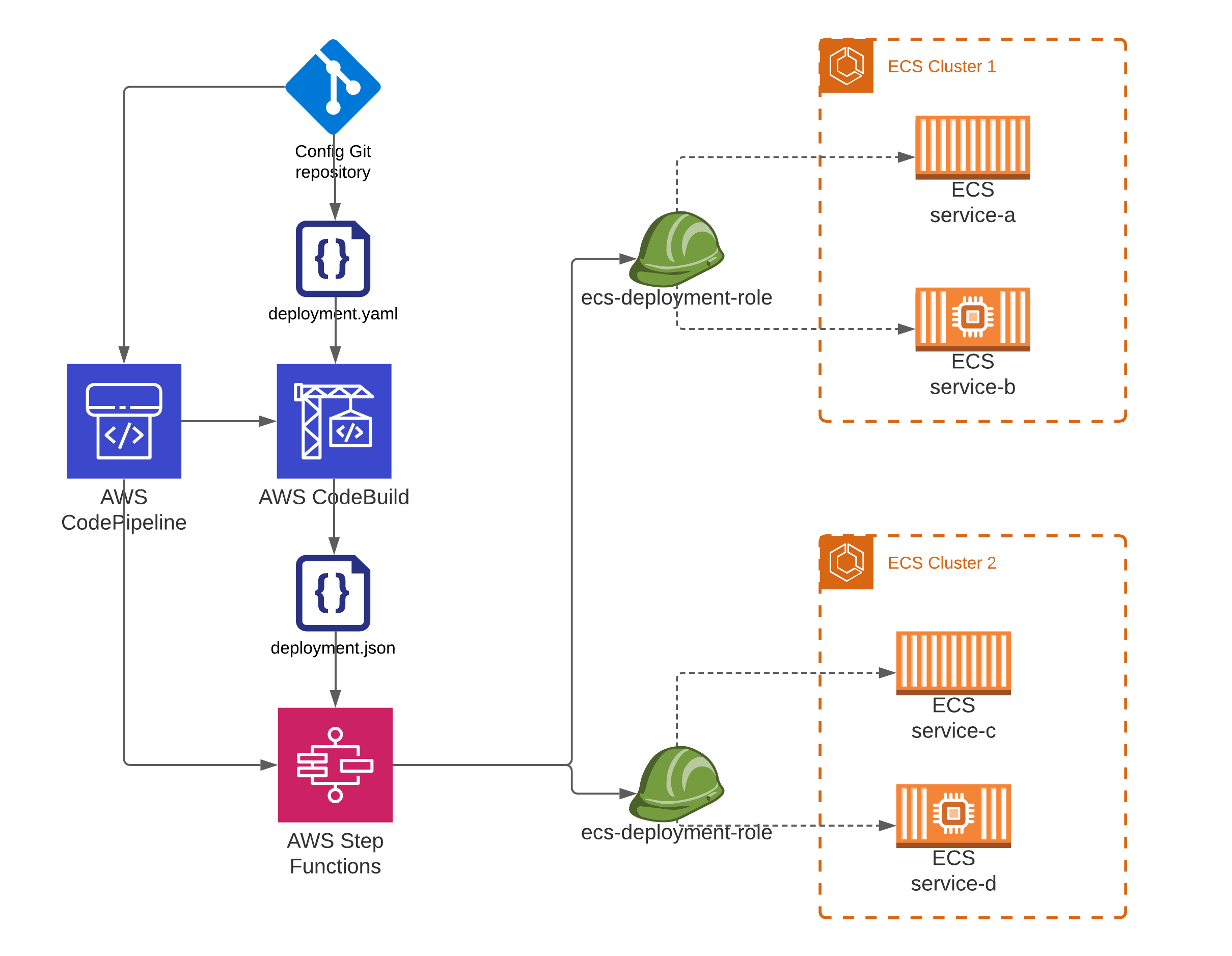
gitops-amazon-ecs-sample
gitops-amazon-ecs-sample is a repo that helps you create a single pipeline to deploy multiple services on Amazon ECS using gitops. What problem is this repo trying to solve? Certain Organizations need to test and deploy multiple, sometimes hundreds of micro-services simultaneously. This could be because of regulatory or compliance requirements where the organisation is mandated to test numerous services together and then release it in one go. Using the traditional strategy of deploying one pipeline per micro-service requires these organisations to coordinate hundreds of pipelines to do a single production release. This increases the deployment window, deployment complexity, and requires coordination from multiple teams that own these micro-services. For example, if 50 services must be deployed in a release, then it would require the team to go and approve 50 production approval gates, which can be a time-consuming and error-prone process. In the case of rollback, it would take considerable time to go and individually rollback each of the pipelines to do a full rollback of the release. These organisations need the ability to reliably deploy multiple services together without the complexity of having to orchestrate numerous pipelines during release. Certain GitOps deployment tools like ArgoCD can facilitate the deployment of multiple services in the Kubernetes space. However, these tools are limited in the Amazon ECS space. This repo attempts to create a single pipeline to provide the ability to deploy multiple Amazon ECS Fargate services and scheduled tasks simultaneously with Git as the source of truth. This is done to reduce the complexity associated with deploying multiple services in a release.
AWS and Community blog posts
dbt
In the first of two posts this week from a writer who regular reader of this newsletter will know, Gary Stafford explores how dbt makes it easy to transform data and materialise models in a modern cloud data lakehouse built on AWS in his post Lakehouse Data Modeling using dbt, Amazon Redshift, Redshift Spectrum, and AWS Glue. [hands on]
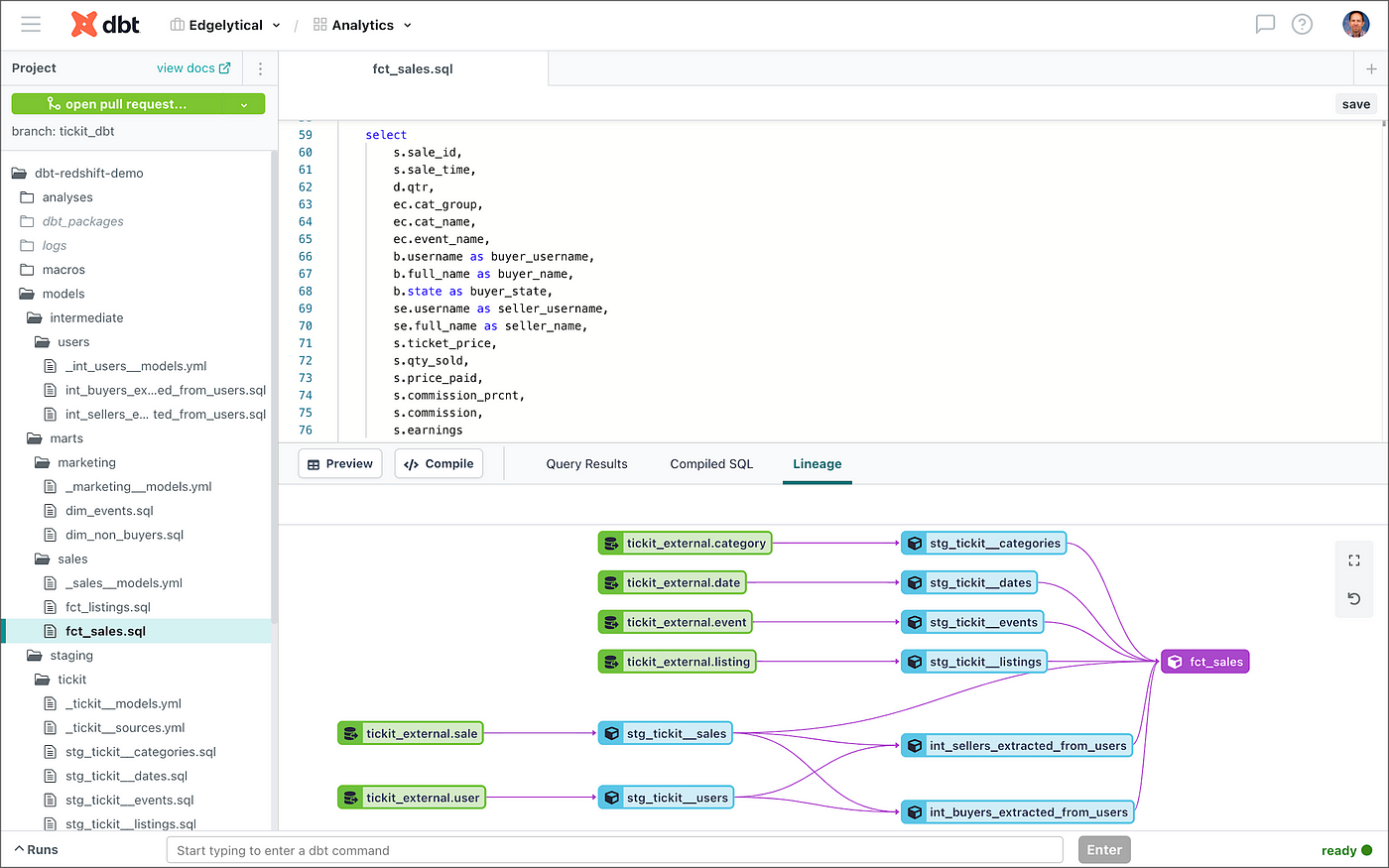
Following that, Gary put together the post dbt and Amazon Redshift Serverless: Serverless Lakehouse Data Modeling which explores the integration of dbt with Amazon Redshift Serverless. [hands on] As always, both posts are recommended reading this week.
Open Source Lakehouses
Kyle Weller from Onehouse has put together this very nice post, Apache Hudi vs Delta Lake vs Apache Iceberg - Lakehouse Feature Comparison, that has a very comprehensive list of features that you might looking for and how each of these open source projects currently meets those, as well as taking a look at some real life use cases and customer stories. I think this post could be useful as you look to explore and think about how you might evaluate these technologies.
Jupyter
Interactive Sessions for Jupyter is a new notebook interface in the AWS Glue serverless Spark environment. This enables a serverless Spark backend to Jupyter notebooks and Jupyter-based IDEs such as Jupyter Lab, Microsoft Visual Studio Code, JetBrains PyCharm, and more. In the post, Introducing AWS Glue interactive sessions for Jupyter, Zach Mitchell shows you how to quickly get started installing via the command line and then running through some interactive notebooks. [hands on]
Flyway
Flyway is an open-source database SQL deployment tool. In the post, Automate schema version control and migration with Flyway and AWS Lambda on Amazon Aurora PostgreSQL, Harshad Gohil and John Lonappan share more details about this open source project and its capabilities, before showing you how you can set up Flyway along with an AWS Lambda function to deploy SQL scripts into various Amazon Aurora PostgreSQL-Compatible Edition environments. [hands on]

Ray
In the post, Scaling AI and Machine Learning Workloads with Ray on AWS, Chris Fregly, Antje Barth, Apoorva Kulkarni, and Simon Zamarin highlight AWS contributions to the scalability and operational efficiency of Ray on AWS.
OpenAPI/Swagger
In the post, Deploy and manage OpenAPI/Swagger RESTful APIs with the AWS Cloud Development Kit, Luke Popplewell demonstrates how AWS Cloud Development Kit (AWS CDK) Infrastructure as Code (IaC) constructs and AWS serverless technology can be used to build and deploy a RESTful Application Programming Interface (API) defined in the OpenAPI specification. [hands on]
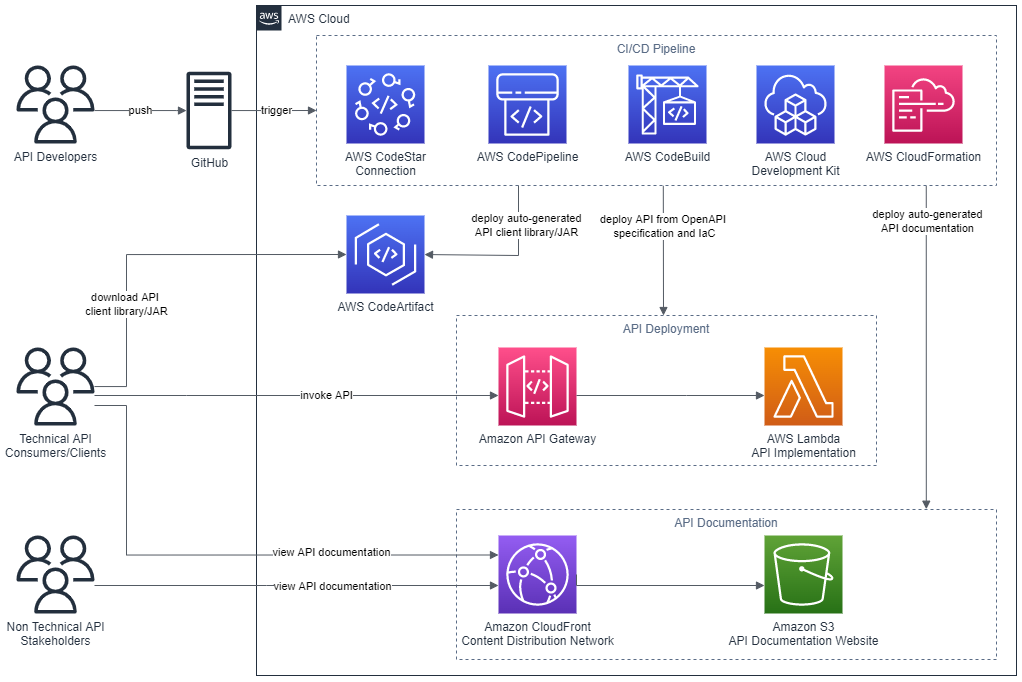
Keycloak
Keycloak is an open source identity and access management solution for modern services and applications with a large and active open source community. Keycloak uses open protocol standards like OpenID Connect and SAML 2.0. It provides features including single sign-on (SSO), user federation, and identity brokering. It also provides both an admin console and an account management console. In the post, Authenticating with Amazon Managed Grafana Using Open Source Keycloak on Amazon EKS Aaron Miller and Siva Guruvareddiar walk you through the steps to deploy and configure Keycloak on Amazon EKS to serve as the SAML authentication provider for Amazon Managed Grafana. [hands on]

CollectD
CollectD is an open-source system statistics collection daemon. When running java workloads, the JVM exposes runtime metrics, such as the heap memory usage, thread count, and classes, through a standard API interface called the Java Management Extension (JMX). In this post, Deliver Java JMX statistics to Amazon CloudWatch using the CloudWatch Agent and CollectD, Daniel Lorch shows you how you can CollectD to collect metrics from JMX and send them to the Amazon CloudWatch agent, as well as allows namespacing metrics per application. Very nice post. [hands on]
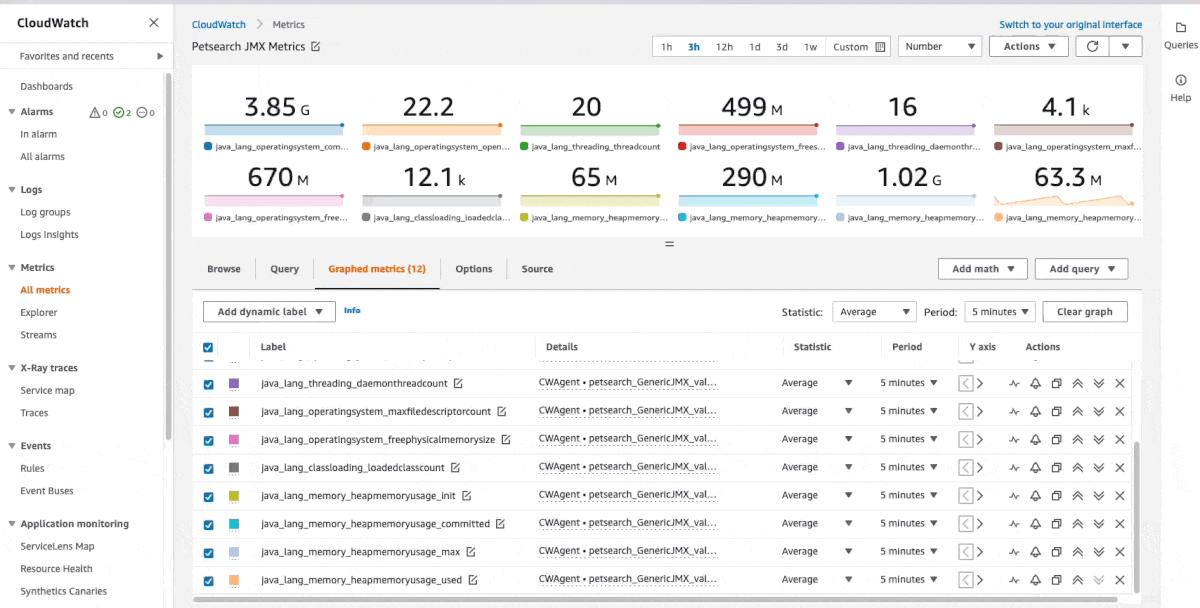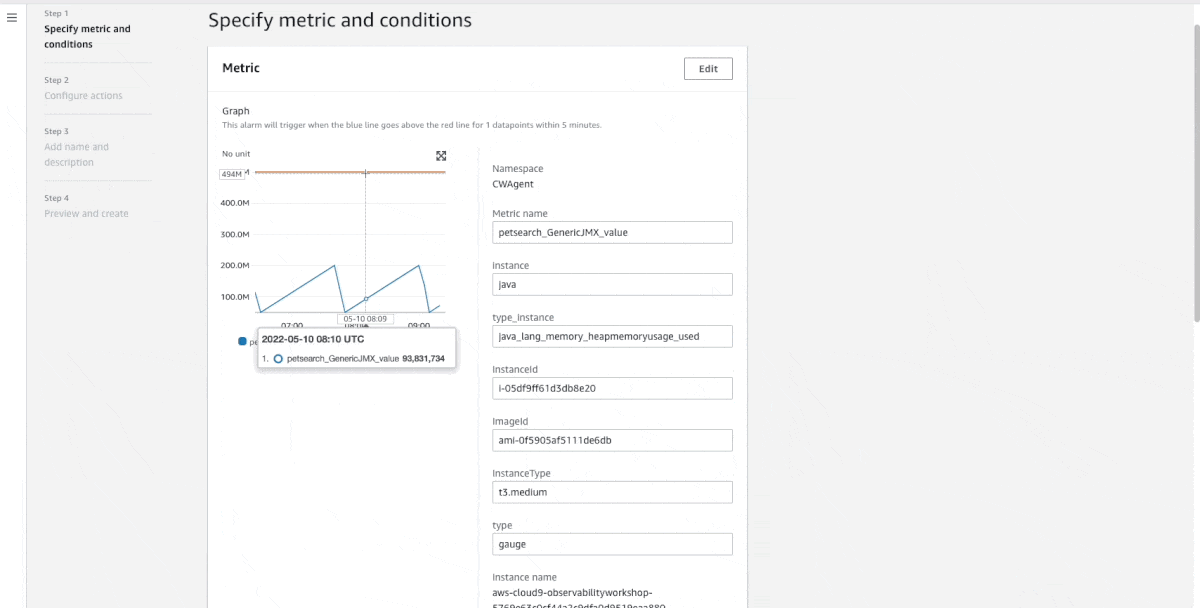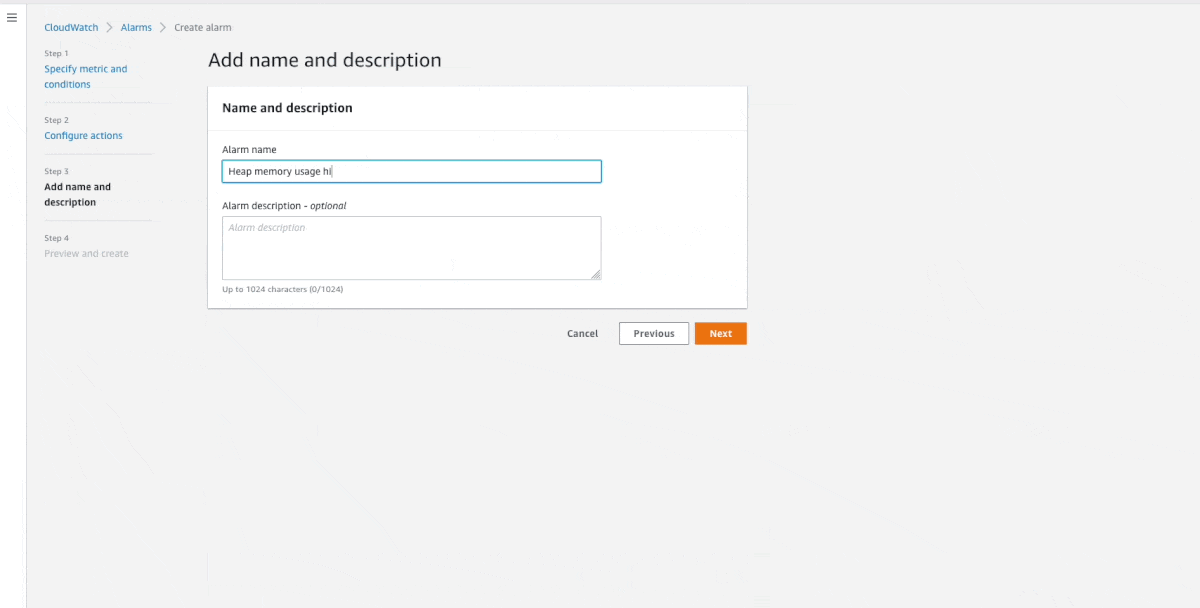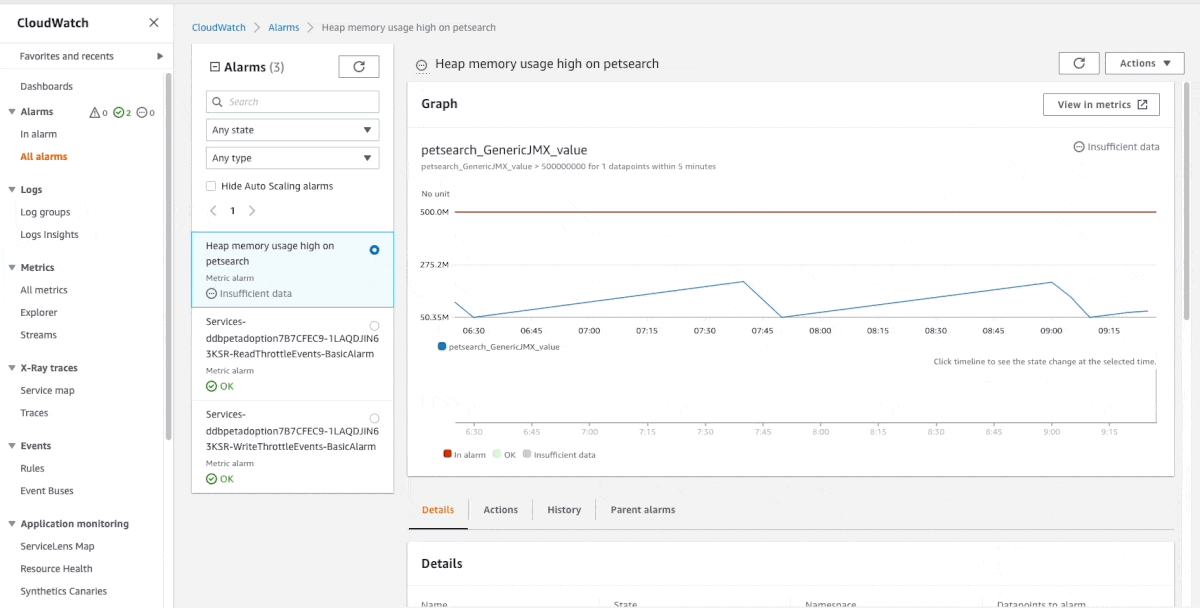
Other posts you might like from the past week
- Continuous Deployment and GitOps delivery with Amazon EKS Blueprints and ArgoCD shows you how to use multi-environment GitOps pipeline pattern to do Git-based delivery for Amazon EKS cluster configurations across multiple environments, onboard new applications to the cluster, while setting the relevant permissions for team members, and GitOps delivery for applications deployed into the cluster using ArgoCD [hands on]
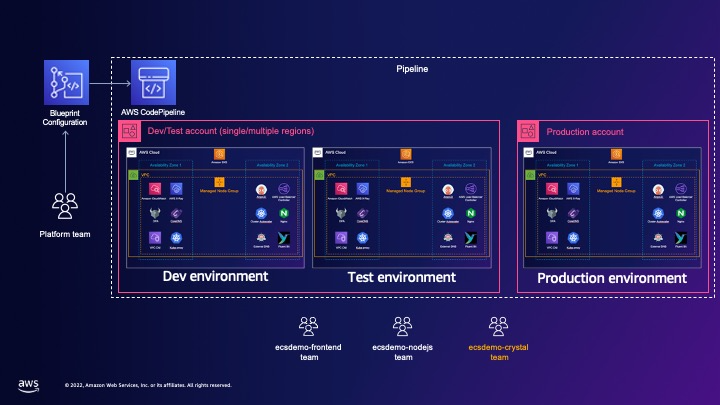
- Amazon EMR on EKS gets up to 19% performance boost running on AWS Graviton3 Processors vs. Graviton2 shares insights from running performance tests observed while running the same EMR Spark runtime on different Graviton-based EC2 instance types
- Implementing Zero-Trust Workload Security on Amazon EKS with Calico demonstrates how you can apply zero-trust workload access controls along with micro segmentation for your workloads that run on Amazon EKS [hands on]
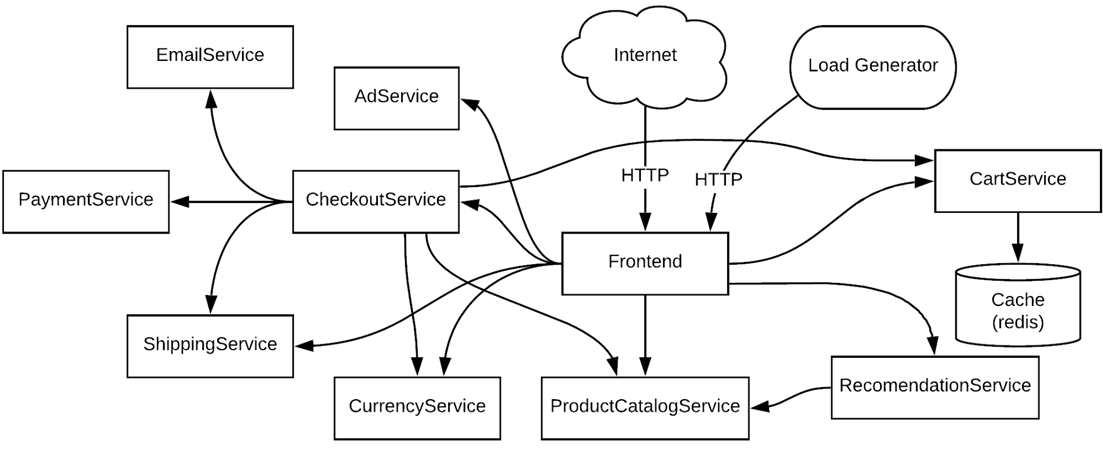
- Accelerating Genomics Pipelines Using Intel’s Open Omics Acceleration Framework on AWS showcases the first version of Intel’s open source Open Omics Acceleration Framework and shares benchmark info of three applications that are used in processing next-generation sequencing data (DNA, mRNA, regulatory regions, the gut microbiome, etc)
- Parallel vacuuming in Amazon RDS for PostgreSQL and Amazon Aurora PostgreSQL shares how parallel vacuuming works in Amazon RDS for PostgreSQL, a feature that was introduced in PostgreSQL 13, that covers the parallel VACUUM parameters and how to run parallel VACUUM in Amazon RDS for PostgreSQL
- Speeding up incremental changes with AWS SAM Accelerate and nested stacks looks at how to increase development velocity by using AWS SAM Accelerate with AWS CloudFormation nested stacks [hands on]
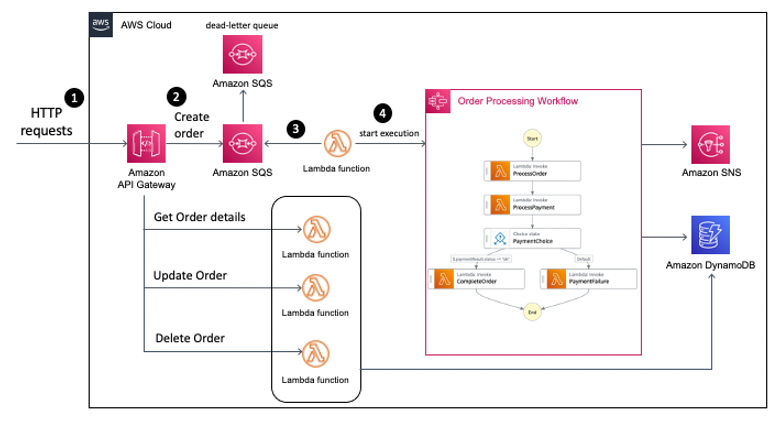
- Deploying AWS Lambda functions using AWS Controllers for Kubernetes (ACK) walks you through deploying a sample Lambda function from a Kubernetes cluster provided by Amazon EKS [hands on]
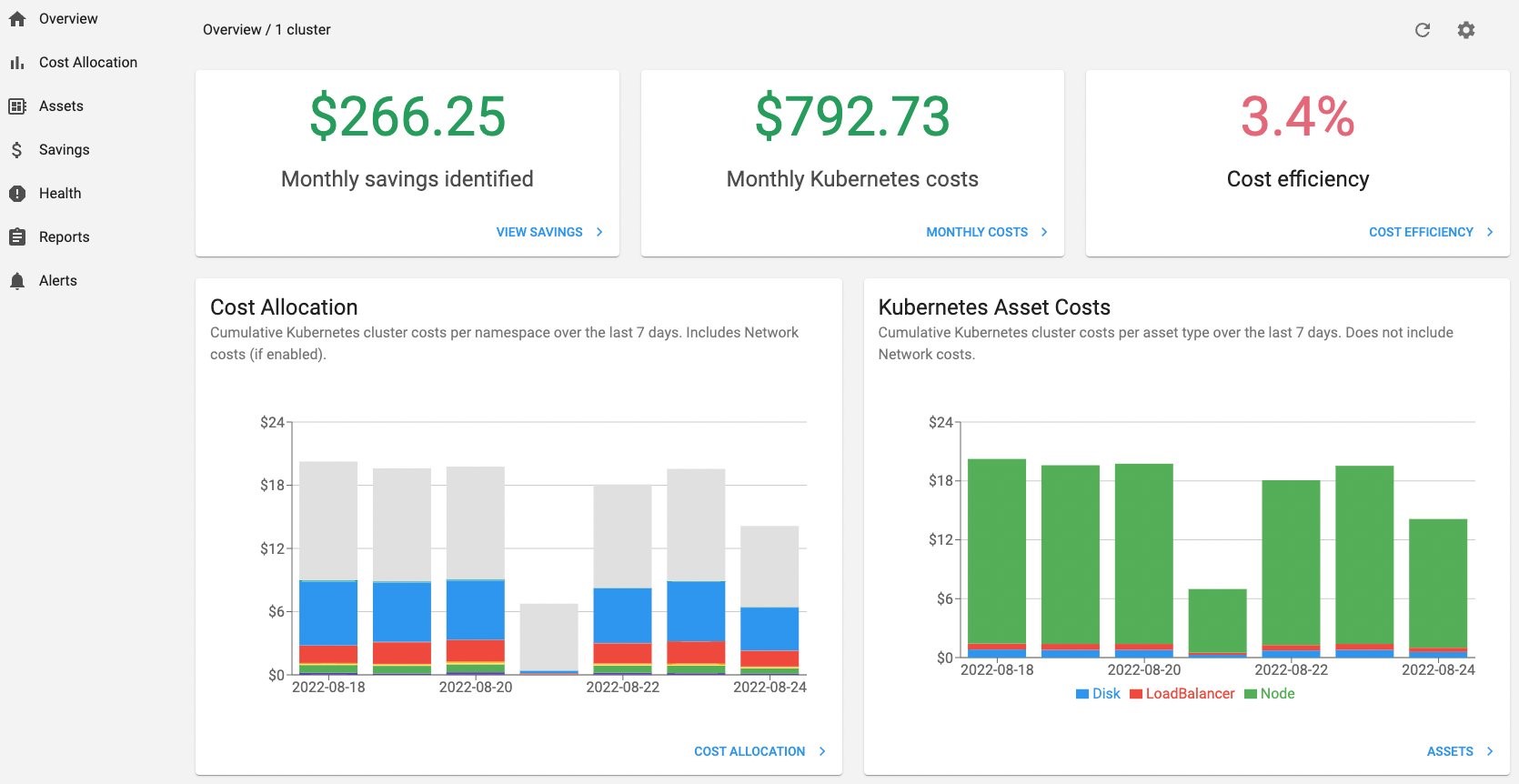
- AWS and Kubecost collaborate to deliver cost monitoring for EKS customers looks at how Amazon EKS customers can deploy an EKS optimised bundle of Kubecost for cluster cost visibility
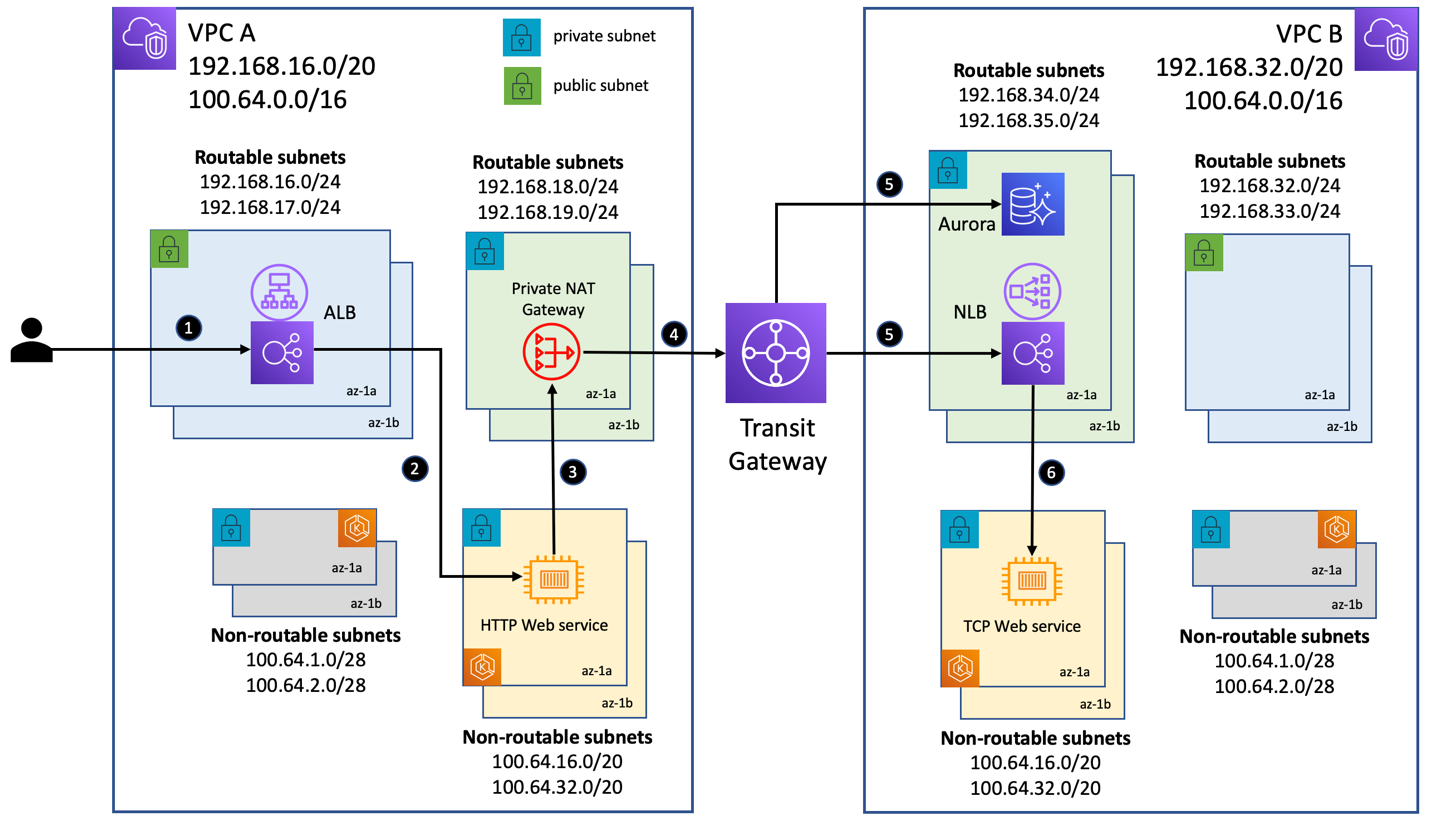
- Addressing IPv4 address exhaustion in Amazon EKS clusters using private NAT gateways shares how you can put together a network design that enabled communication across Amazon EKS clusters deployed to VPCs with overlapping CIDRs
Quick updates
AWS SDK for pandas
AWS Data Wrangler is now AWS SDK for pandas (awswrangler). We’re changing the name we use when we talk about the library, but everything else will stay the same. You’ll still be able to install using pip install awswrangler and you won’t need to change any of your code. As part of this change, we’ve moved the library from AWS Labs to the main AWS GitHub organisation but, thanks to the GitHub’s redirect feature, you’ll still be able to access the project by its old URLs until you update your bookmarks.
AWS SDK for pandas is a popular open source library that enables customers to connect to AWS data and analytics services to obtain data in a pandas dataframe. Customers can then use the pandas library to transform their data before writing back to an AWS service, Used by data scientists, data engineers and developers, AWS SDK for pandas allows easy data movement between 19 types of data store, including Amazon S3, Amazon Athena, Amazon Neptune, Amazon SageMaker, AWS Glue and AWS Lake Formation.
Linux
AWS announced the general availability of the credentials-fetcher open source project. As you modernise your .NET applications to Linux containers, you no longer need to worry about Microsoft Active Directory (AD) dependency. You can use credentials-fetcher to access AD from services hosted on Linux containers using the service account authentication model. This package makes it possible to create kerberos tickets specific to group managed service accounts (gMSAs) in applications running on Linux containers. As part of our launch, the credential-fetcher in packaged in RPM format and added it to Fedora Linux. You can install this package by using dnf install credentials-fetcher. A group managed service account is a managed account that provides automatic password management, service principal name (SPN) management, and the ability to delegate management to administrators over multiple servers or instances.
Karpenter
Karpenter is a flexible, high-performance Kubernetes cluster autoscaler that helps improve application availability, operational overhead, and cluster compute utilisation by launching new EC2 instances that are best fit to the scale, scheduling, and resource requirements of the workloads in a cluster. Customers can use Karpenter with Amazon Elastic Kubernetes Service (EKS) or any conformant Kubernetes cluster. Starting with v0.15.0, Karpenter will automatically consolidate Kubernetes cluster workloads onto new EC2 instances to help increase utilisation and lower cluster compute costs.
As the workloads in a Kubernetes cluster change and scale, it can be necessary to launch new EC2 instances to ensure they have the compute resources they need. Over time, those instances can become under-utilised as some workloads scale down or are removed from the cluster. Workload consolidation for Karpenter automatically looks for opportunities to reschedule these workloads onto a set of more cost-efficient EC2 instances, whether they are already in the cluster or need to be launched. Consolidation for Karpenter can be enabled with a simple configuration change in the Karpenter Provisioner Custom Resource Definition (CRD) in Karpenter v0.15.0 and above.
Kubernetes
AWS App Mesh is a service mesh that provides application-level networking to make it easier for your services to communicate with each other across multiple types of compute infrastructure. AWS App Mesh standardises how your services communicate, giving you end-to-end visibility and options to tune for high-availability of your applications.
You can now define a listener per each application port on your AWS App Mesh Virtual Gateways, Virtual Nodes and Virtual Routers, and define traffic routes to a specific listener. You can configure each listener independently, secure them with individual TLS certificates, and collect traffic metrics separately for each application port.
AWS App Mesh has also introduced support for customisable Envoy access log format for Virtual Nodes and Virtual Gateways. It enables you to diagnose your services with customised logging focusing on specific aspects that are important to you. Now you can specify the desired access log pattern using any Envoy command operators. You can also use JSON or text format to define the pattern. This configuration makes it easier to export the Envoy access log file to other tools for further analysis, which may require a specific format or pattern.
Bottlerocket
Bottlerocket, a Linux-based operating system that is purpose built to run container workloads, now has a Center for Internet Security (CIS) Benchmark. The CIS Benchmark is a catalog of security-focused configuration settings that help Bottlerocket customers configure or document any non-compliant configurations in a simple and efficient manner. The CIS Benchmark for Bottlerocket includes both Level 1 and Level 2 configuration profiles.
PostgreSQL
Amazon Relational Database Service (Amazon RDS) for PostgreSQL now supports PostgreSQL minor version 14.4. We recommend you upgrade to this latest minor version to fix known security vulnerabilities and bugs from prior versions of PostgreSQL. While this release from PostgreSQL community includes a number of fixes, a noteworthy fix included in this release is for CREATE INDEX CONCURRENTLY and REINDEX CONCURRENTLY that can potentially cause silent data corruption of indexes. Amazon RDS has made the fix for the index corruption available since the release of Amazon RDS for PostgreSQL 14.3.
AWS SAM
The AWS Serverless Application Model (SAM) Command Line Interface (CLI) announces general availability of esbuild support in SAM CLI. The AWS SAM CLI is a developer tool that makes it easier to build, test, package, and deploy serverless applications. Esbuild, “an extremely fast JavaScript bundler”, links JavaScript ( js , jsx , ts , and tsx ) and CSS dependencies as deployable assets for the web. Starting today, you can now use esbuild in the SAM CLI build workflow for your JavaScript applications.
Developers using JavaScript and TypeScript can now use esbuild and SAM Accelerate to rapidly iterate on their code changes in the cloud, achieving the same levels of productivity they’re used to when testing locally, while testing against a realistic application environment in the cloud. Support for esbuild includes features such as Minification, Tree Shaking, Source Maps, Loader, External and Main-Fields which can help simplify AWS Lambda development with JavaScript and TypeScript.
Videos of the week
Backstage
Join Sai Vennam and the Containers from the Couch show as he takes a look at Backstage, an open platform for building developer portals. Joining Sai are guests from Spotify Suzanne Daniels and Himanshu Mishra along with Bryan Landes from AWS. Make sure you check this session out.
AWS SAM
James Eastham shows you how to add CICD pipelines to your .NET 6 serverless applications with the AWS SAM CLI, using GitHub Actions to build, test and deploy your application to multiple environments.
Kubeflow
Fresh from the AWS Summit Atlanta, my colleague Suman Debnath shares the stage with Bimal Gajjar as they show you how you can make a scalable architecture for ML training and inference at scale using backend distributed storage with Amazon EFS and Kubeflow with Amazon EKS.
Rust
From Atlanta to San Francisco, this time we have Shane Miller with a must view session for all builders. Rust is one of the most energy-efficient and safe programming languages. With Rust, it may be possible to reduce the environmental impact of the IT industry by 50 percent and prevent 70 percent of all high-severity CVEs. Check out this session to dive into the “super powers” of Rust, and hear about the work ahead to give those powers to every engineer, and learn how you can contribute.
Events for your diary
Build on AWS Open Source September 9th, 9am BST
The second episode of a new show where Derek Bingham and myself walk you through the latest AWS open source news, show you code and demos of some of the interesting projects we think you should know about and we invite guests to share their open source projects via the medium of demo.
This episode (S01E02) we are very lucky to have AWS Hero Ian Mckay talking and showing us some of his open source projects. Do not miss (even if I do say so myself!)
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
OpenSearchCon 2022 Sept 21st, 2022 Seattle
Come to the first annual OpenSearchCon!
This day-long conference will be packed with presenters who build and innovate with OpenSearch. It doesn’t matter if you’re just getting started on your OpenSearch journey, running giant clusters, or contributing tons of code; the event is for everyone. Join us to celebrate the progress and look into the future of the project. Admission is free, and registration will be open in the next few weeks. All you will need to do is sign up, and get to Seattle!
Check out the full details, including signing up and location, at the meetup page here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen