AWS open source news and updates #122
July 29th, 2022 - Instalment #122
Welcome
Welcome back to my regular readers and hello to new readers, I hope you will enjoy and come back again to the AWS open source newsletter episode #122.
This week we have another great collection of community and AWS related open source tools, demos and samples for you to practice your open source four freedoms. “rds_auto_encrypt” helps you encrypt your Amazon RDS databases, “middy-profiler” is an interesting looking tool to help you understand performance characteristics of your AWS Lambda functions, “simpleiot” is a very nice looking IoT framework to help simplify how you can onboard devices into AWS IoT, “aws-secrets-manager-hybrid-secret-replication-from-hashicorp-vault” (bit of a mouthful to say that one) helps you synchronise your secrets across different secret providers, “automated-forensic-orchestrator-for-amazon-ec2” is a very nice reference solution for automating some of your operational security activities, and we have several other projects for you to dive deep into.
Reading material this week features content on Apache Cassandra, Amazon EMR, MariaDB, AWS ParallelCluster, s2n-quic, Deep Graph Library, Kubernetes, AWS CDK, Apache Kafka, and OpenSearch so there is plenty to keep you busy. This weeks videos are all about Apache Cassandra, including an interesting one around how to manage this at scale. Finally, don’t miss this round up of open source related events including a new Bottlerocket community meet-up.
Feedback
At Amazon we work backwards from our customers, and one of the ways we do that is collecting data to help us know what is important and what we should focus on. Please could you complete this simple, anonymous survey. The first 25 will get an AWS $25 credit code.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Logan Cox, Maciej Radzikowski, Gary Stafford, Regis Wilson, Shaheer Masoor, Vadym Dolin, Oliver Zollikofer, Oliver Perks, Austin Cherian, Panos Kampanakis, Cameron Bytheway, Jiwon Yeom, Elamaran Shanmugam, Re Alvarez-Parmar, Leo Drakopoulos and Marco Ballerini.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
rds_auto_encrypt
rds_auto_encrypt is a super handy tool from Logan Cox that you can use to encrypt RDS instances that were previously created in an unencrypted state.
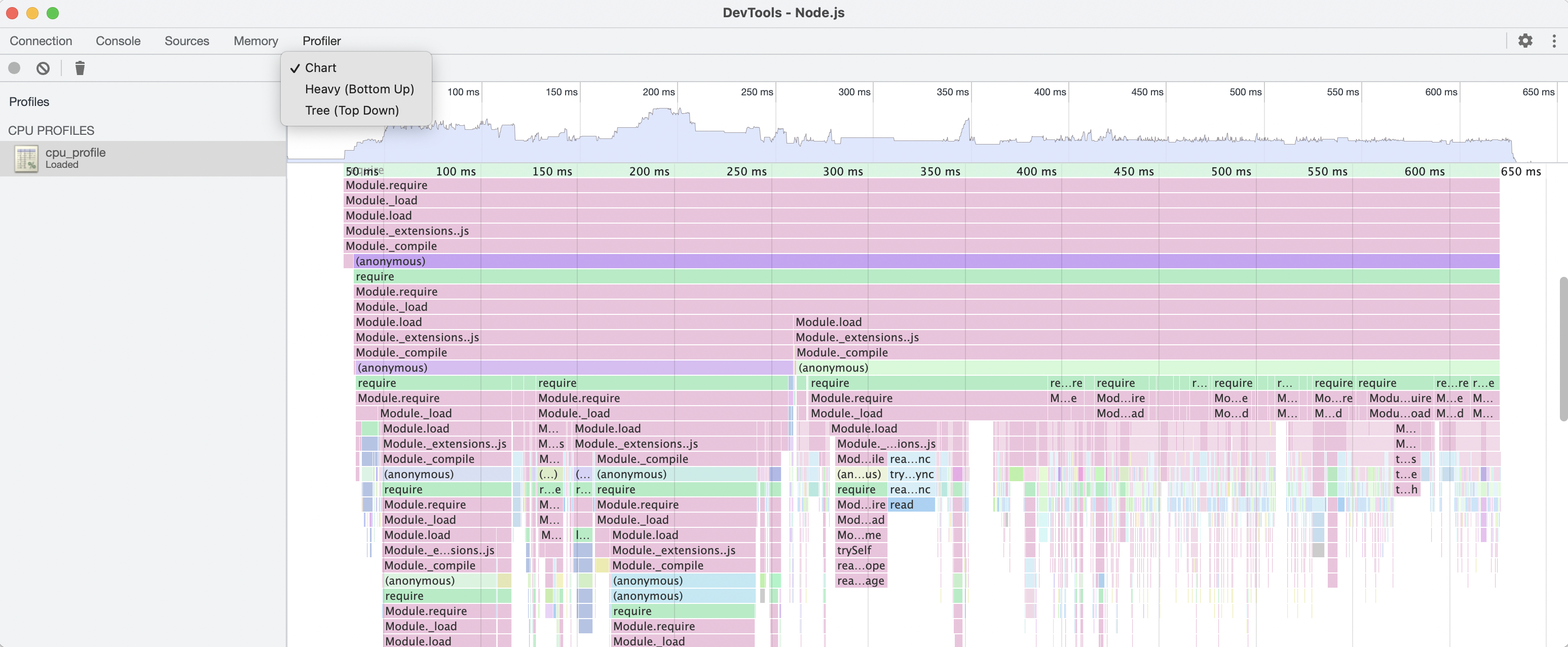
middy-profiler
middy-profiler is a middleware for profiling CPU on AWS Lambda to troubleshoot hidden performance issues which are hard to be identified by tracing #serverless. Captured CPU profiling data is put into specified AWS S3 bucket, which you can then review and analyse.
rds-proxy-iac-terraform
rds-proxy-iac-terraform provides a solution to create an Amazon RDS Proxy in your existing architecture with an Amazon RDS PostreSQL database, using Terraform Infrastructure as Code.
amazon-dynamodb-item-tagging
amazon-dynamodb-item-tagging Amazon DynamoDB is a fast and flexible NoSQL database service for single-digit millisecond performance at any scale. But in order to provide this scalability and performance, data access patterns must be known up front so that optimum keys and indexes can be designed. This is difficult in scenarios such as allowing the users of your platform to define any attributes for their data, then search that data filtering by any number of those attributes. This pattern outlines an approach to solve this problem by demonstrating how to structure a table and its indexes within DynamoDB to allow searching, then at the application layer how to efficiently aggregate results that match the multiple requests attributes.
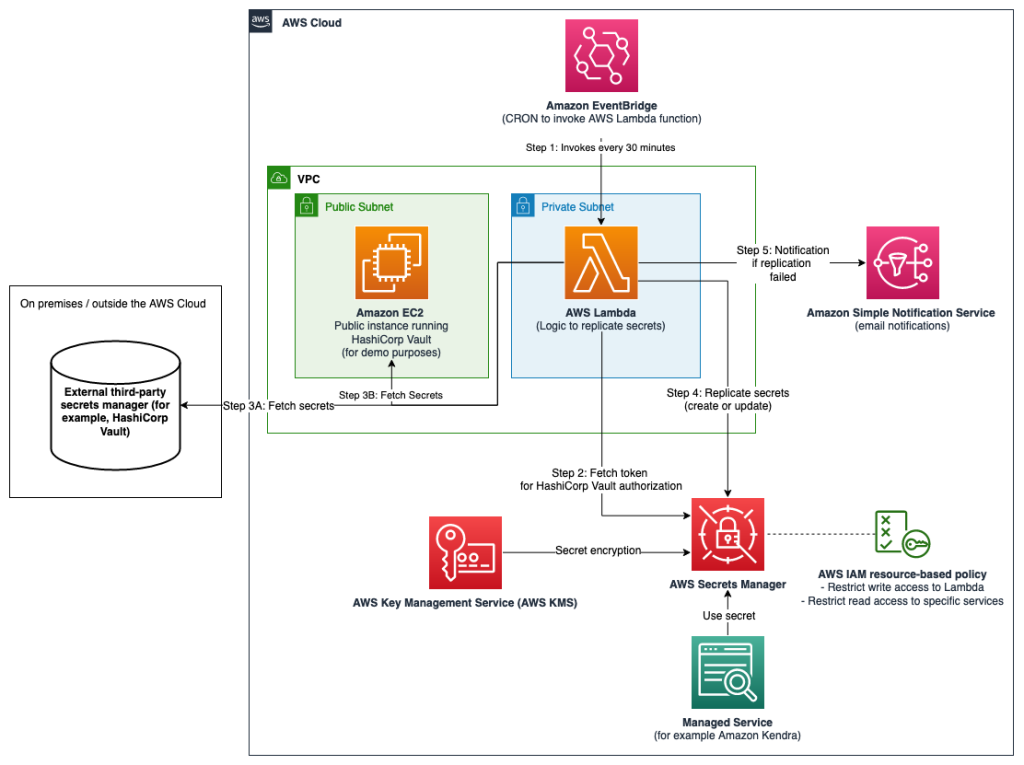
aws-secrets-manager-hybrid-secret-replication-from-hashicorp-vault
aws-secrets-manager-hybrid-secret-replication-from-hashicorp-vault this is a cool repos that shows you how you can use your third-party secrets manager as the source of truth for your secrets, whilst replicating a subset of these secrets to AWS Secrets Manager. By doing this, you will be able to use secrets originating and managed from your third-party secrets manager in AWS Cloud applications or in AWS Services that use Secrets Manager secrets. This sample uses HashiCorp Vault as third-party secrets manager.
simpleiot
simpleiot SimpleIOT is an open source framework that allows you to connect a variety of devices to the cloud. The data can go in both directions if needed. You can find out more about the core concepts from the docs, and then check out the code. Detailed installation guide is provided.
Demos, Samples, Solutions and Workshops
feature-store-end-to-end
feature-store-end-to-end this repository demonstrates an end-to-end ML workflow using various AWS services such as SageMaker (Feature Store, Endpoints), Kinesis Data Streams, Lambda and DynamoDB. The dataset used here is Expedia hotel recommendations dataset from Kaggle and the use-case is predicting a hotel cluster based on user inputs and destination features.

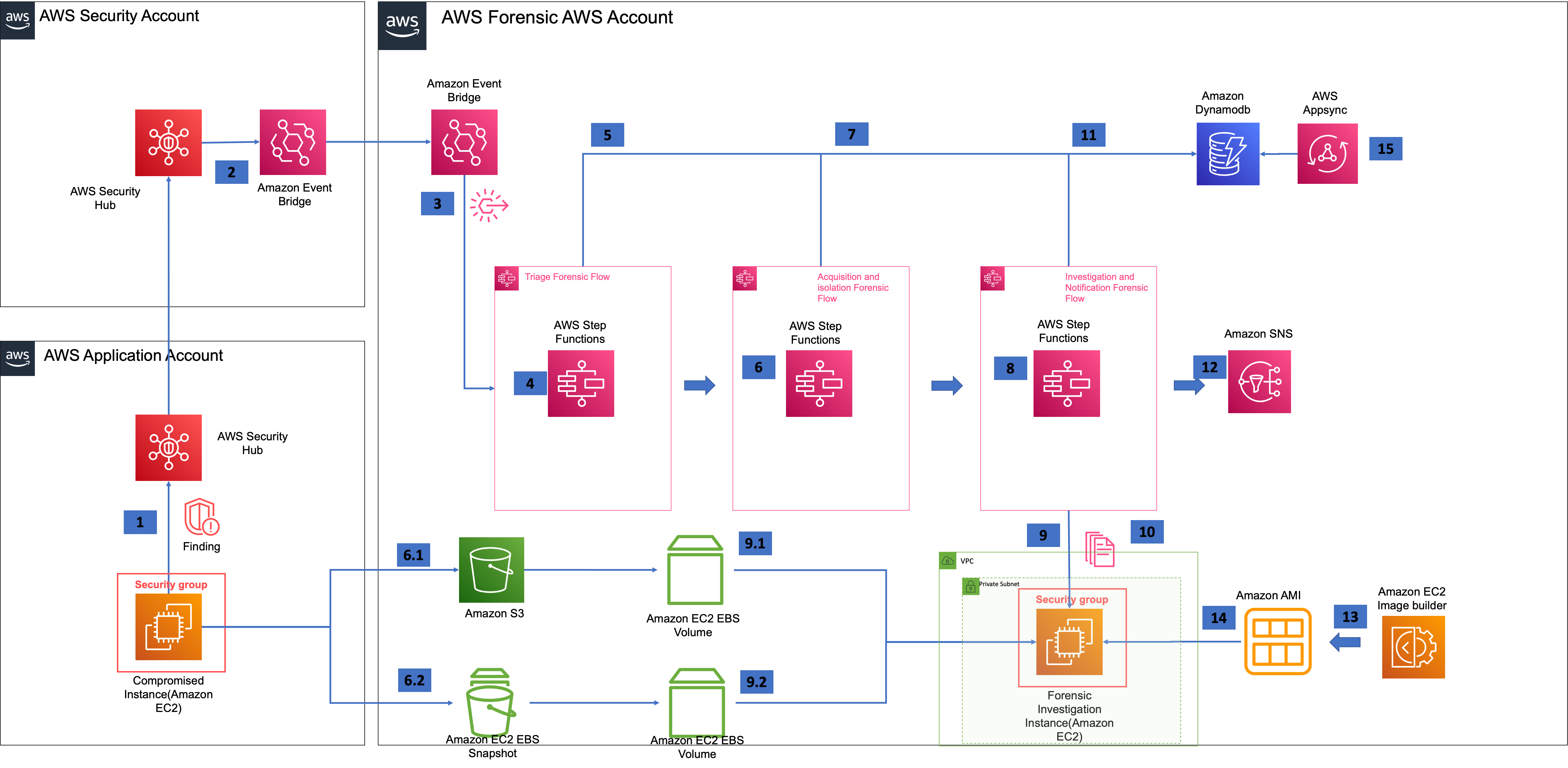
automated-forensic-orchestrator-for-amazon-ec2
automated-forensic-orchestrator-for-amazon-ec2 is a self-service AWS Solution implementation that enterprise customers can deploy to quickly set up and configure an automated orchestration workflow that enables their Security Operations Centre (SOC) to capture and examine data from EC2 instances and attached volumes as evidence for forensic analysis, in the event of a potential security breach. It will orchestrate the forensics process from the point at which a threat is first detected, enable isolation of the affected EC2 instances and data volumes, capture memory and disk images to secure storage, and trigger automated actions or tools for investigation and analysis of such artefacts. All the while, the solution will notify and report on its progress, status, and findings. It will enable SOC to continuously discover and analyse patterns of fraudulent activities across multi-account and multi-region environments. The solution will leverage native AWS services and be underpinned by a highly available, resilient, and serverless architecture, security, and operational monitoring features.
Check out the project for more detailed examples of how to deploy and get started with this.
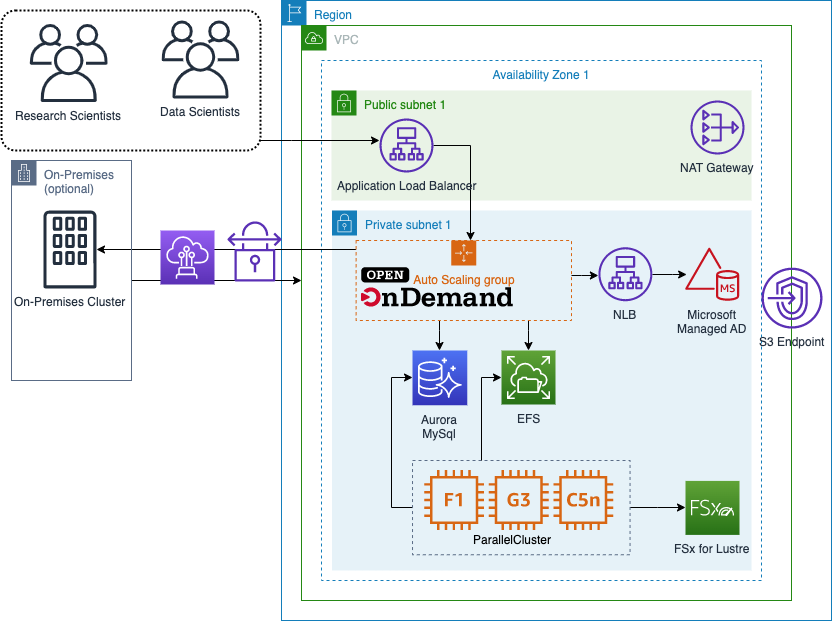
open-on-demand-on-aws
open-on-demand-on-aws the repo contains a reference architecture and provides a set of templates for deploying Open OnDemand (OOD) with AWS CloudFormation and integration points for AWS Parallel Cluster. Open OnDemand in an open source tool that helps computational researchers and students efficiently utilize remote computing resources by making them easy to access from any device.
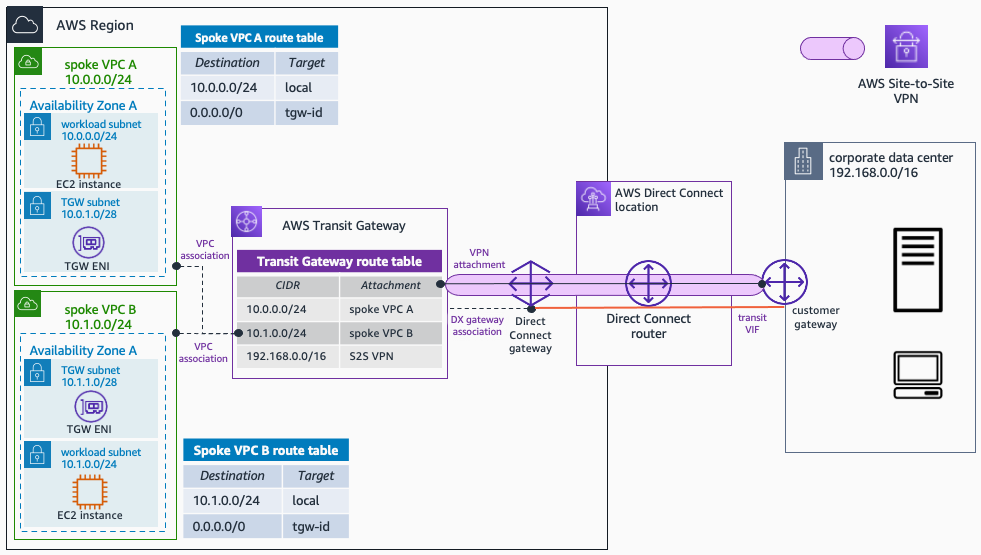
aws-site-to-site-vpn-private-ip-vpn
aws-site-to-site-vpn-private-ip-vpn this repo contains Terraform and AWS CDK code to deploy an AWS Site-to-Site VPN Private IP VPN over AWS Direct Connect.
AWS and Community blog posts
AWS CDK
If you are a fan of posts that contrast and compare, this you will love this post from AWS Community Builder, Maciej Radzikowski. In The AWS CDK, Or Why I Stopped Being a CDK Skeptic, he comes in from the dark side and shares why he is now a fan of AWS CDK. Well worth a read.
Kubernetes
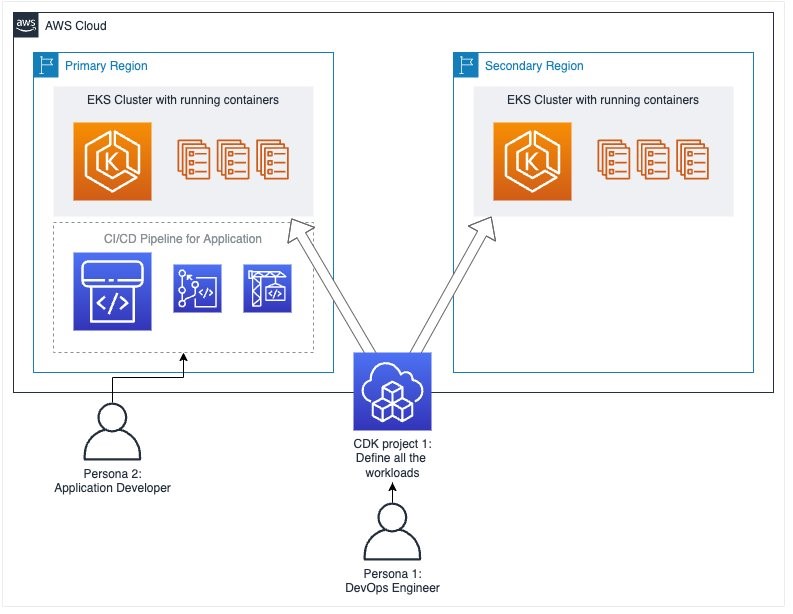
A couple of good posts this week. First up, we have Jiwon Yeom, Elamaran Shanmugam and Re Alvarez-Parmar who put together Using CDK to perform continuous deployments in multi-region Kubernetes environments. In this deep dive, you will learn about how to create continuous deployment pipeline to deploy applications in multiple Amazon EKS clusters running in different regions. [hands on]
Following that we have the post Using Amazon EBS snapshots for persistent storage with your Amazon EKS cluster by leveraging add-ons where Leo Drakopoulos and Marco Ballerini show how to successfully leverage the Amazon EBS CSI driver to add persistent storage to your pods by leveraging Amazon EBS snapshots and EBS volumes. [hands on]
Finally, we have this post which might help folks who are struggling integrating AWS EFS with Amazon EKS. In the post, How to Solve AWS EFS “Operation Not Permitted” Errors in EKS, Regis Wilson provides some things to look at and potential solutions as you mull over his closing remarks,
“we are as imperfect as the imperfect world we live in which means that we should accept the imperfection as the correct way that things should be and thus, the imperfection we see in the world merely reflects the imperfections in ourselves, which makes us perfect in every way.”
Pretty deep for this newsletter.
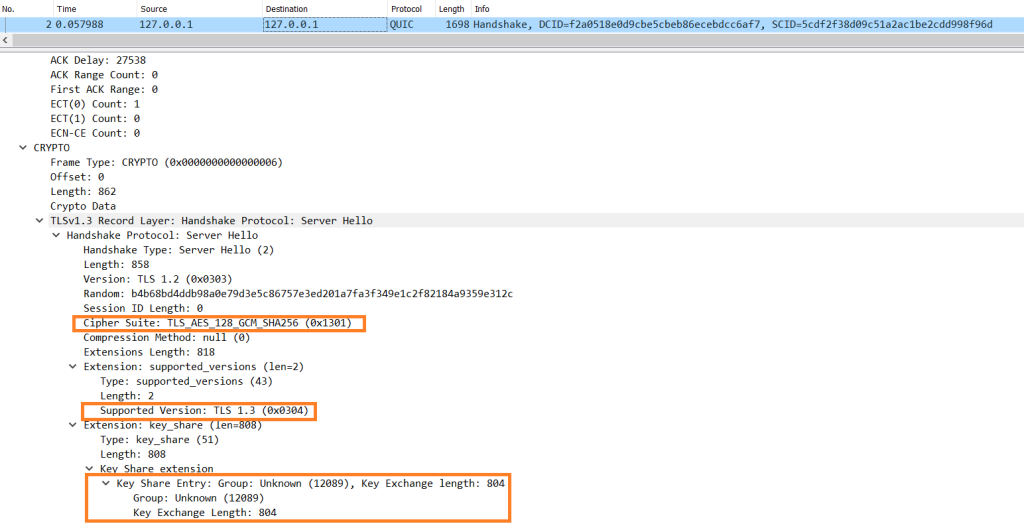
s2n-quic
QUIC is a new multiplexed transport built on top of UDP. HTTP/3 is designed to take advantage of QUIC’s features. s2n-quic is an open sourced library providing an implementation of the QUIC protocol. In the post, Enable post-quantum key exchange in QUIC with the s2n-quic library Panos Kampanakis and Cameron Bytheway show how you can use s2n-quic in conjunction with s2n-tls to enable QUIC connections to negotiate encryption keys in a quantum-resistant manner. [deep dive]
OpenSearch
Being able to search documents that have been uploaded by users of your application is a common use case. OpenSearch is a great open source project that you can use to help you with this use case. In the post, Search text from PDF files stored in an S3 bucket, the folk at Mixpeek walk you through how to implement a Flask based service that uses the APIs surfaced by OpenSearch to enable you to search through your files (in this example, PDFs).
Deep Graph Library
In this collaboration between Mutisya Ndunda from Trumid, and Marc van Oudheusden and Isaac Privitera from AWS, talk about how they built an end-to-end data preparation, model training, and inference process based on a deep neural network model built using the Deep Graph Library for Knowledge Embedding (DGL-KE). This lead to much improved performance that enabled us to better match traders and bonds. Read more about just how much and find out more how they did this by reading, Developing advanced machine learning systems at Trumid with the Deep Graph Library for Knowledge Embedding
Amazon EMR
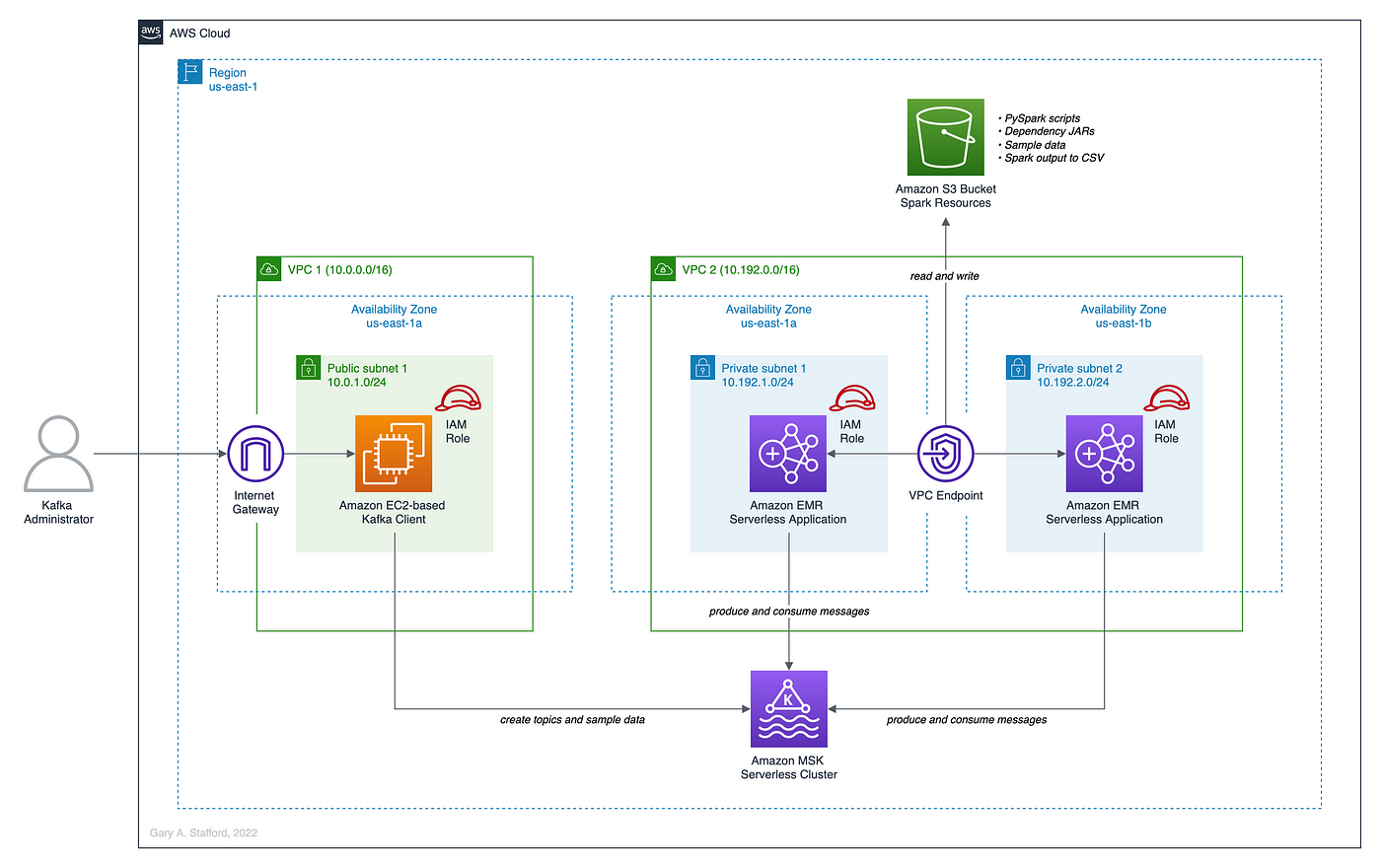
With the ability to run Apache Spark and Apache Kafka serverless, Gary Stafford is on hand to provide one of his amazing deep dive walk throughs in his post, Serverless Analytics on AWS: Getting Started with Amazon EMR Serverless and Amazon MSK Serverless. Grab a cup of your favourite beverage and follow along - you will learn lots. [hands on]
Other posts you might like from the past week
- Expanded filesystems support in AWS ParallelCluster 3.2 looks at new new filesystem support features introduced in the latest version of AWS ParallelCluster (FSx for NetApp ONTAP and FSx for OpenZFS, as well as all the previous ones)
- Slurm-based memory-aware scheduling in AWS ParallelCluster 3.2 explores the memory-aware scheduling in the latest version of AWS ParallelCluster
- Welcoming the AWS Customer Incident Response Team with re:Inforce just been and gone, check out this post which features a number of open source tools and solutions that have been featured in this newsletter over the past few months
Case Studies
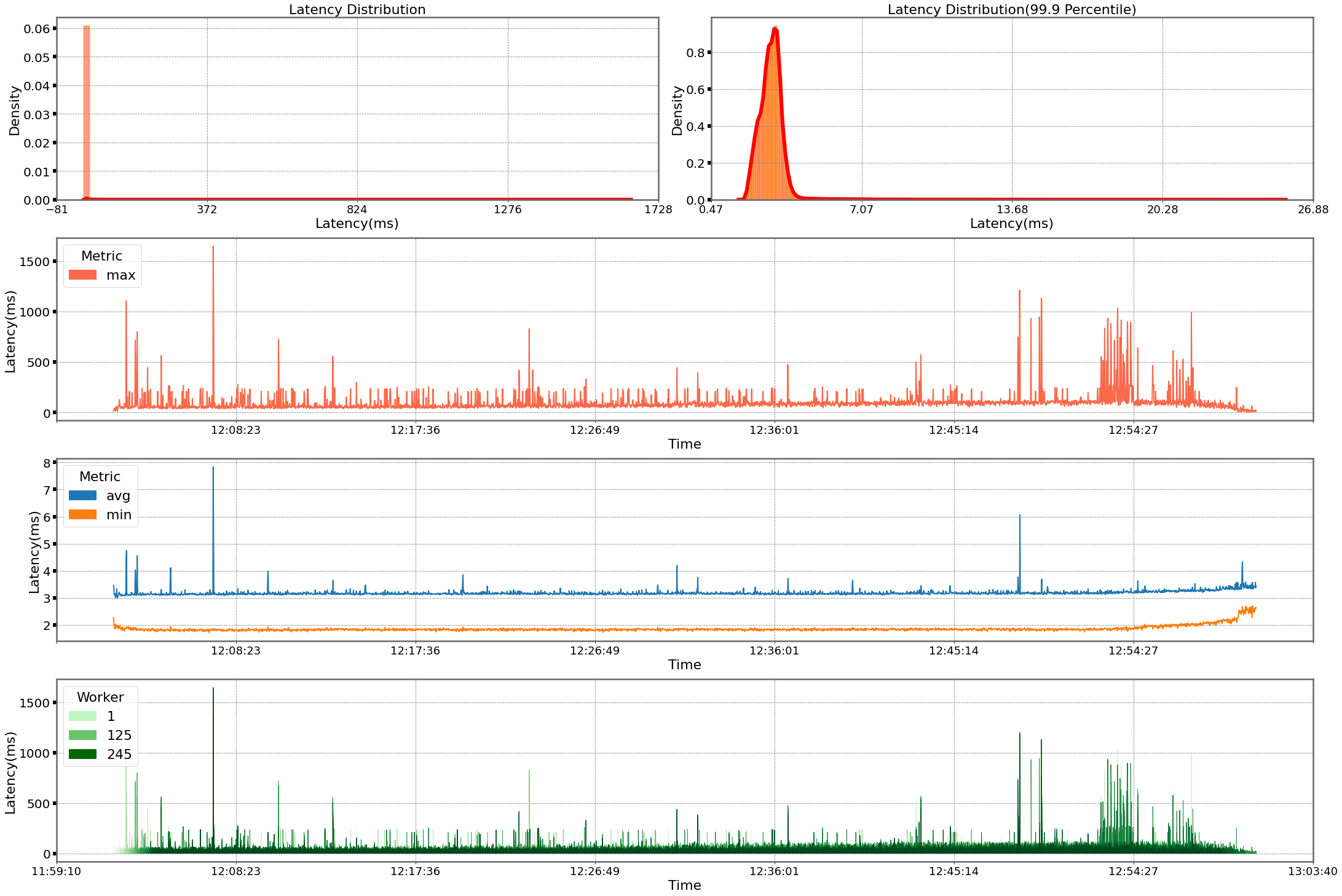
- How SumUp built a low-latency feature store using Amazon EMR and Amazon Keyspaces shows how SumUp built a millisecond-latency feature store, looking at the architectural considerations and presenting results showcasing the setups performance
Quick updates
MariaDB
A couple of quick updates for MariaDB users.
Amazon RDS for MariaDB now supports R5b database (DB) instances. R5b DB instances support up to 3x the I/O operations per second (IOPS) and 3x the bandwidth on Amazon Elastic Block Store (Amazon EBS) compared to the x86-based memory-optimised R5 DB instances. R5b DB instances are a great choice for IO-intensive DB workloads.
Amazon RDS Proxy, a fully managed, highly available database proxy for Amazon Relational Database Service (RDS), now support for Amazon RDS for MariaDB databases running on major versions 10.3, 10.4, or 10.5. With Amazon RDS Proxy, customers can make applications more scalable, more resilient to database failures, and more secure. Amazon RDS Proxy sits between your application and the database to pool and share established database connections, improving database efficiency and application scalability. In case of a failure, Amazon RDS Proxy automatically connects to a standby database instance while preserving connections from your application and reduces failover times for Amazon RDS for MariaDB multi-AZ databases by up to 66%. With Amazon RDS Proxy, database credentials and access can be managed through AWS Secrets Manager and AWS Identity and Access Management (IAM), eliminating the need to embed database credentials in the application.
Amazon EMR
Last week saw two new features that help enforce access controls with Amazon EMR on EC2 clusters (EMR Clusters). These features are supported with jobs that are submitted to the cluster using the EMR Steps API. First is Runtime Role with EMR Steps. A Runtime Role is an AWS Identity and Access Management (IAM) role that you associate with an EMR Step. An EMR Step uses this role to access AWS resources. The second is integration with AWS Lake Formation to apply table and column-level access controls for Apache Spark and Apache Hive jobs with EMR Steps.
Previously, all jobs running on an EMR cluster used the IAM role associated with the EMR cluster’s EC2 Instances to access resources. This role is called the EMR EC2 Instance Profile. For example, if a Spark job and Hive job running on the same cluster needed to access different S3 buckets, then the Instance Profile must allow access to both the buckets. With Runtime Role for EMR Steps, you specify a different IAM role for the Spark and the Hive job, thus scoping down access at a job level. This allows you to simplify access controls on a single EMR cluster that is shared between multiple tenants, wherein each tenant is isolated using IAM roles.
In addition, you can use AWS Lake Formation to apply Table and Column-level permissions with Apache Spark and Apache Hive jobs submitted as EMR Steps. AWS Lake Formation is a fully managed service that makes it easy to build, secure, and manage data lakes. AWS Lake Formation enables you to apply fine-grained access control to data stored in data lakes, through a simple grant or revoke mechanism, much like a relational database management system (RDBMS). With this feature, table and column-level permissions defined in AWS Lake Formation for an IAM Role are seamlessly enforced with Apache Hive and Apache Spark jobs submitted as EMR Steps. This allows you to further simplify access controls, and provide each job with access to specific Databases, Tables, and Columns.
OpenSearch
You can now run OpenSearch and OpenSearch Dashboards version 1.3 on Amazon OpenSearch Service. This version includes several new features and improvements around observability, SQL and PPL, Alerting and Anomaly Detection. You can upgrade your domain seamlessly to OpenSearch version 1.3 from any of the previous OpenSearch versions, or from Elasticsearch versions 6.8 or 7.x directly, using the OpenSearch Service console or APIs.
Read the full release notes at, Amazon OpenSearch Service now supports OpenSearch version 1.3
Videos of the week
Apache Cassandra
Fresh from Containers from the Couch, we have guests Matthew Overstreet and “Rags” Srinivas (DataStax), join Mikhail Shapirov and Sai Vennam to talk about their experiences with running K8ssandra on Kubernetes (and scaling it to over 1200 nodes). Apache Cassandra is an open source NoSQL distributed database capable of achieving incredible scale.
Events for your diary
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
Just-in-time Worker Nodes with Karpenter 5th August, 2pm IST
Karpenter helps improve your application availability and cluster efficiency by rapidly launching right-sized compute resources in response to changing application load. In this webinar with my colleague Rohini Goankar, you will get an overview of Karpenter and it’s features, see a demonstration of how Karpenter simplifies Kubernetes infrastructure with the right nodes at the right time, and there will be practical demos on how to use Karpenter.
Find out more and register via this link, An Open-Source High-Performance Kubernetes Cluster Autoscaler
Digital Payments Architecture and Implementation with AWS Open Source Databases August 18th
Check out this Webinar on how to use open source databases to build a digital payments solution. You can view it live direct on YouTube here
Bottlerocket Community Meeting August, 24th 8:30am PDT
You’re invited to the Bottlerocket community meeting where we’ll discuss project news, share Bottlerocket tips, tricks, and techniques, and you’ll have the opportunity to ask questions in an open forum.
Find out more and reserve your spot here.
OpenSearchCon 2022 Sept 21st, 2022 Seattle
Come to the first annual OpenSearchCon!
This day-long conference will be packed with presenters who build and innovate with OpenSearch. It doesn’t matter if you’re just getting started on your OpenSearch journey, running giant clusters, or contributing tons of code; the event is for everyone. Join us to celebrate the progress and look into the future of the project. Admission is free, and registration will be open in the next few weeks. All you will need to do is sign up, and get to Seattle!
Check out the full details, including signing up and location, at the meetup page here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen