AWS open source news and updates #120
July 15th, 2022 - Instalment #120
Welcome to regular and new readers alike, to the AWS open source newsletter episode #120.
The observant will have noticed that it has been two weeks since the last newsletter. We all need some time off, and I spent most of the time cycling around the hills of a new cycle route called King Alfreds Way - highly recommended.
There has been some great new projects created over the past couple of weeks, and of course I have you covered and have shared them below. We have “barometer” a really nice tool that can help you automate the evaluation of your analytics solutions, “vscode-infracost” which takes the really nice Infracost tool and enables you to easily use this from within VSCode, “terraform-aws-mwaa” and “emr-serverless-with-mwaa” a couple of projects for Apache Airflow users that provide a new Terraform module for Apache Airflow and a new operator to work with Amazon EMR serverless, “RDSOSMetrics” some advanced CloudWatch metrics for Amazon RDS, “real_time_streaming_analytics” a nice sample architecture and solution that shows you how to do streaming analytics using a payment example, “shuffle-sharding-demo-app” a great example of how to implement shuffle-sharding, “resource-tagging-automation” a tool to help automate the tagging of your AWS resources, “aws-samples-for-ray” shows you how you can run Ray on AWS four ways, and many more projects too.
We also have a bumper number of great blog posts, featuring topics such as Blazor, OpenSearch, Kyber, Dicoogle, Blender, Babelfish, jsPolicy, Karpenter, Amazon EMR, Apache Airflow, Data Version Control and more. Make sure you check out this weeks videos too, with and overview of the AWS Rust SDK as well as firm favourites, Containers from the Couch, taking a look at bare metal EKS Anywhere - don’t miss that video. As always this week we finish with events.
Feedback
At Amazon we work backwards from our customers, and one of the ways we do that is collecting data to help us know what is important and what we should focus on. Please could you complete this simple, anonymous survey. The first 25 will get an AWS $25 credit code.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Cal Heldenbrand, Dimos Botsaris, Zelda Hessler, Avaneesh Ramprasad, Forrest Sun, Irene Kors, Norm Johanson, François Bouteruche, Brian Jarvis, Gary Stafford, Michael Marie Julie, Quentin Bernard, Pierre Mavro, Joshua Bright, Ashish Agrawal, Paolo Di Francesco and Eitan Sela.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
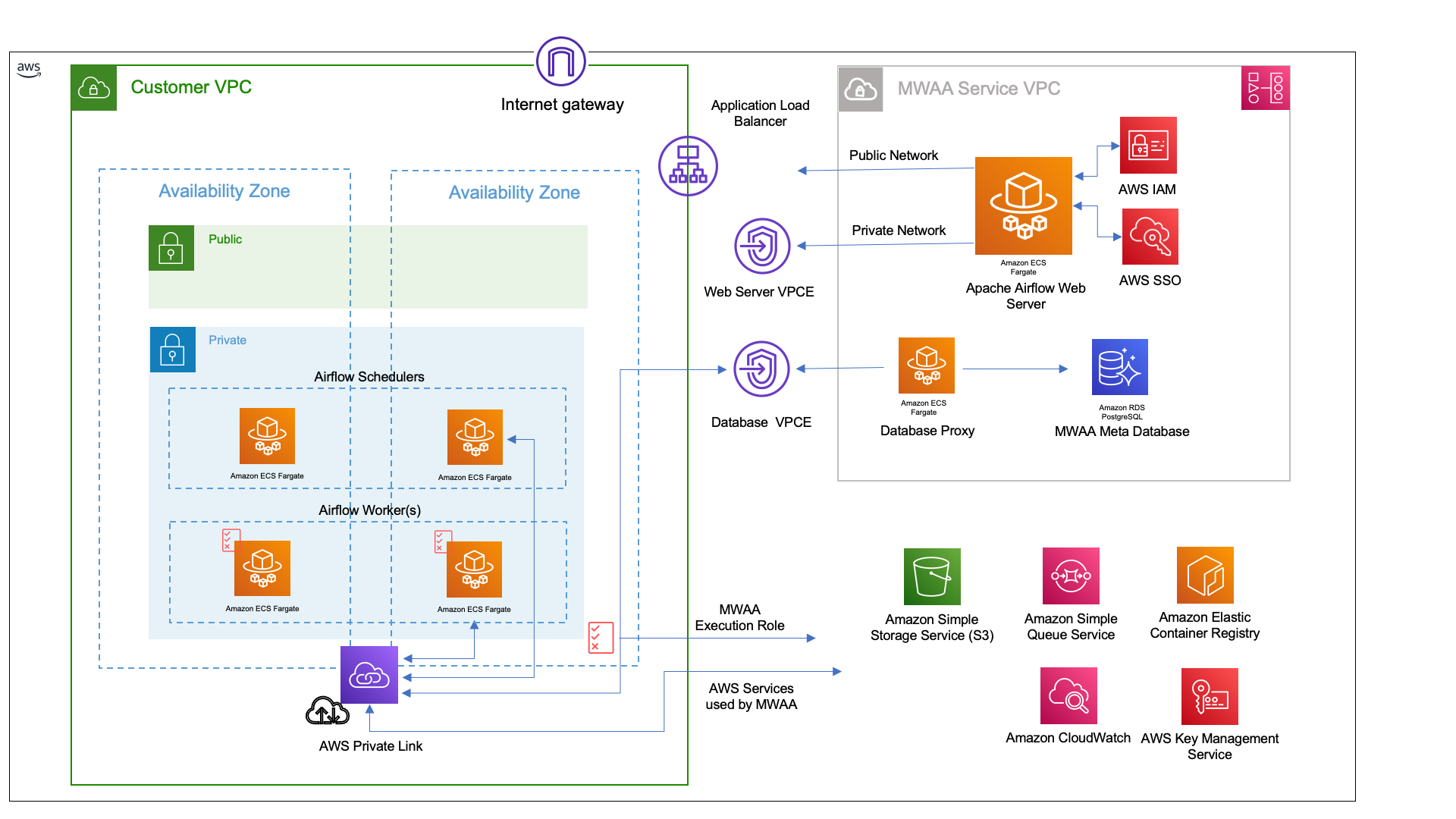
terraform-aws-mwaa
terraform-aws-mwaa is a new Terraform module that helps you configure and deploy Managed Workflow for Apache Airflow (MWAA) environments on AWS. Over the past few weeks I have been helping the AWS-IA team with work on the new Terraform module for Managed Workflows for Apache Airflow (MWAA). I put together this blog, Using Terraform to configure and deploy Managed Workflows for Apache Airflow (MWAA) environments, that shows you how you can configure and deploy your very own MWAA environment using Terraform.
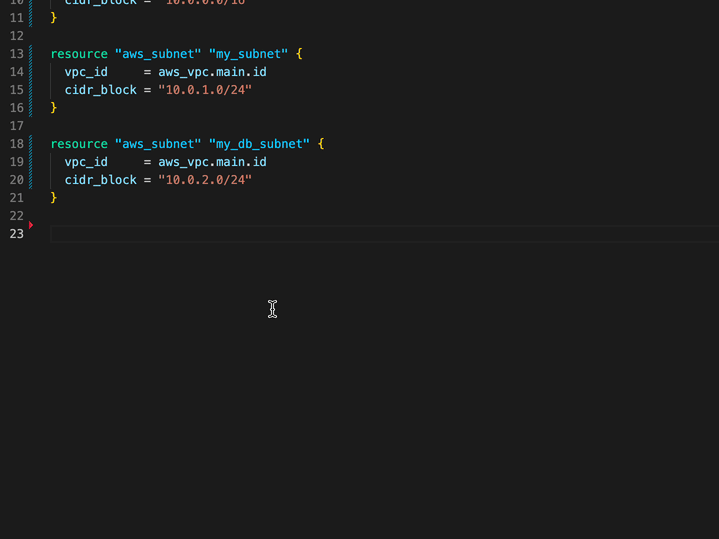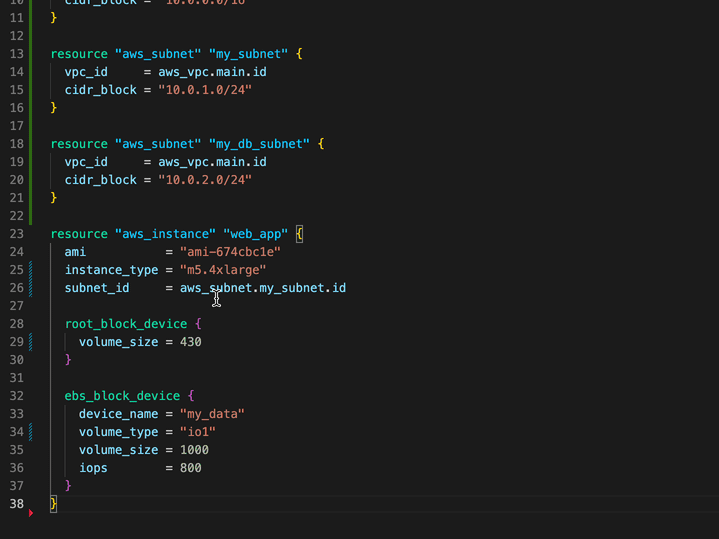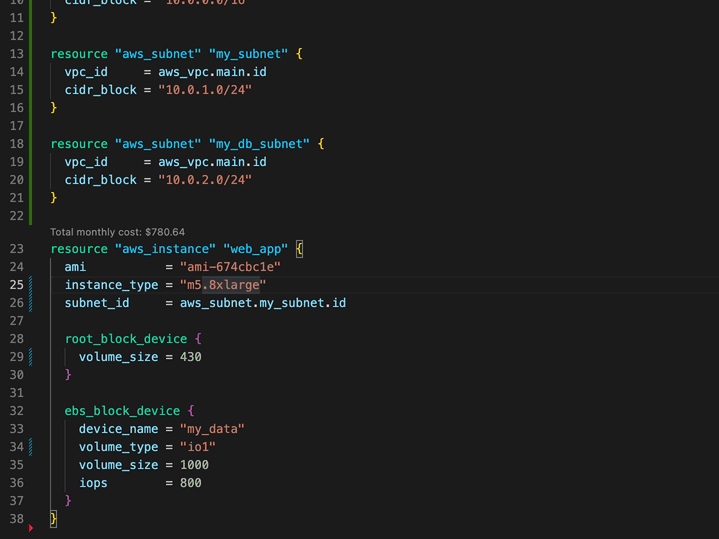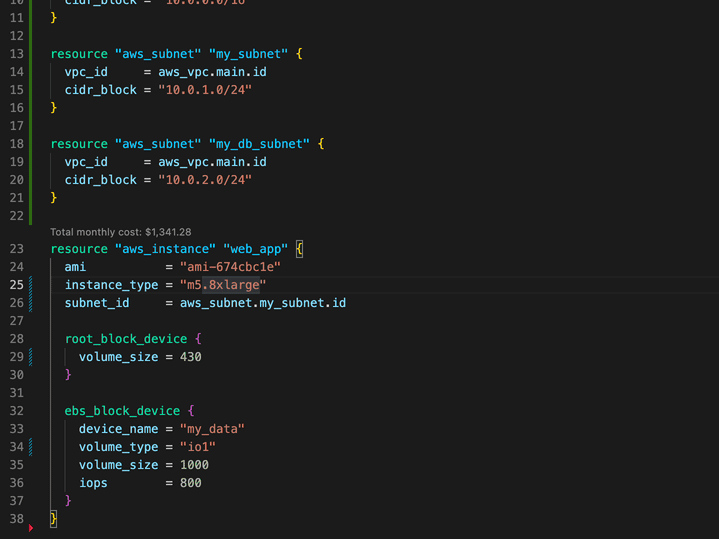
vscode-infracost
vscode-infracost Infracost is a really cool open source tool that helps Terraform users estimate the cost of your AWS deployments. This new project, shows you cost estimates for Terraform right in your VSCode - how cool is that. Detailed documentation provides lots of useful info on how to optimise the setup, so make sure you check it all out.
Bonus Check out my colleagues Darko and Jacqui featuring Infracost in the new weekly Build On AWS show.
RDSOSMetrics
RDSOSMetrics this project from Cal Heldenbrand provides a way of getting advanced AWS CloudWatch metrics for Amazon RDS. This Lambda script pulls metrics from the CloudWatch RDSOSMetrics logs, parses the CPU and memory utilisation for each PID, aggregates, categorizes and then publishes custom CloudWatch metrics for a given RDS instance.

barometer
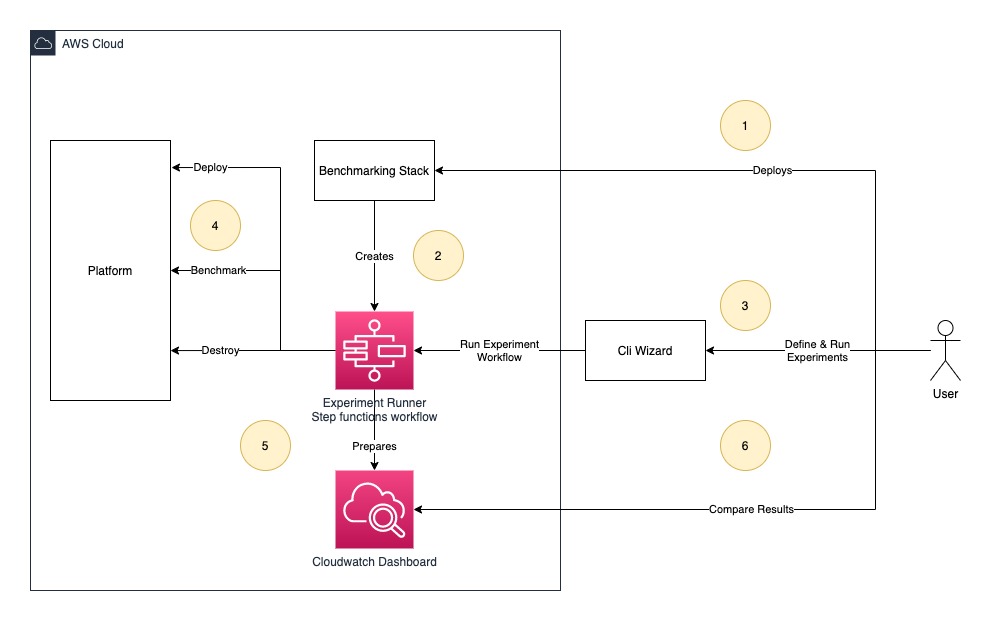
barometer is a new tool from awslabs that will help you to automate analytic platform evaluations. Barometer helps customers to get data points needed for service selection/service configurations for given workload. Barometer will deploy cdk stack which is used to run benchmarking experiments. The experiment is a combination of platform and workload which can be defined using cli-wizard provided by Barometer tool. Detailed documentation with examples, and this is the essential project to check out this week.
resource-tagging-automation
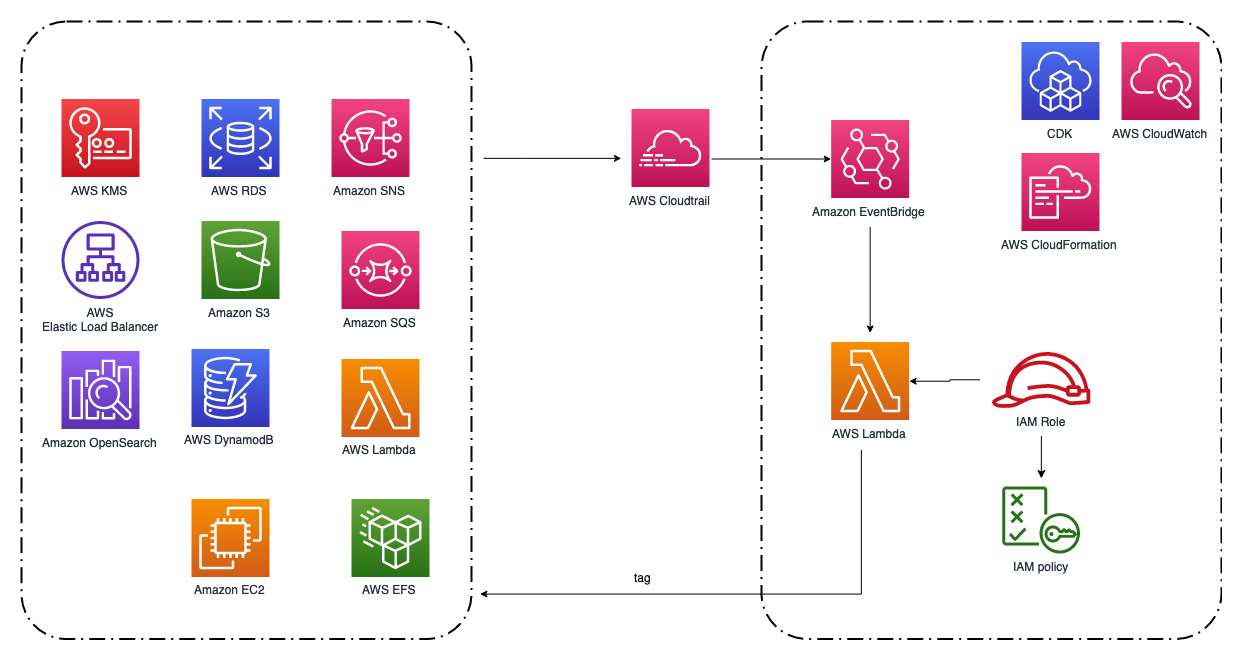
resource-tagging-automation This is a Lambda function that can auto tagging newly created AWS resources. It is triggered by EventBridge events from CloudTrail logs. Currently it supports tagging EC2, S3, DynamoDB, RDS, Lambda, EFS, EBS, ELB, OpenSearch, SNS, SQS and KMS. Notice that the solution can only tag newly created resources.
Demos, Samples, Solutions and Workshops
emr-serverless-with-mwaa
emr-serverless-with-mwaa this repo provides a CDKv2 Python project that deploys an MWAA environment with the Amazon EMR Serverless Operator pre-installed with two sample DAGs.
real_time_streaming_analytics
real_time_streaming_analytics is a new project from Dimos Botsaris, where he shares how they use managed services in arconsis IT-Solutions GmbH, such as Amazon Kinesis to handle our incoming data analytics streams from our sources while AWS handles the undifferentiated heavy lifting of managing the infrastructure.
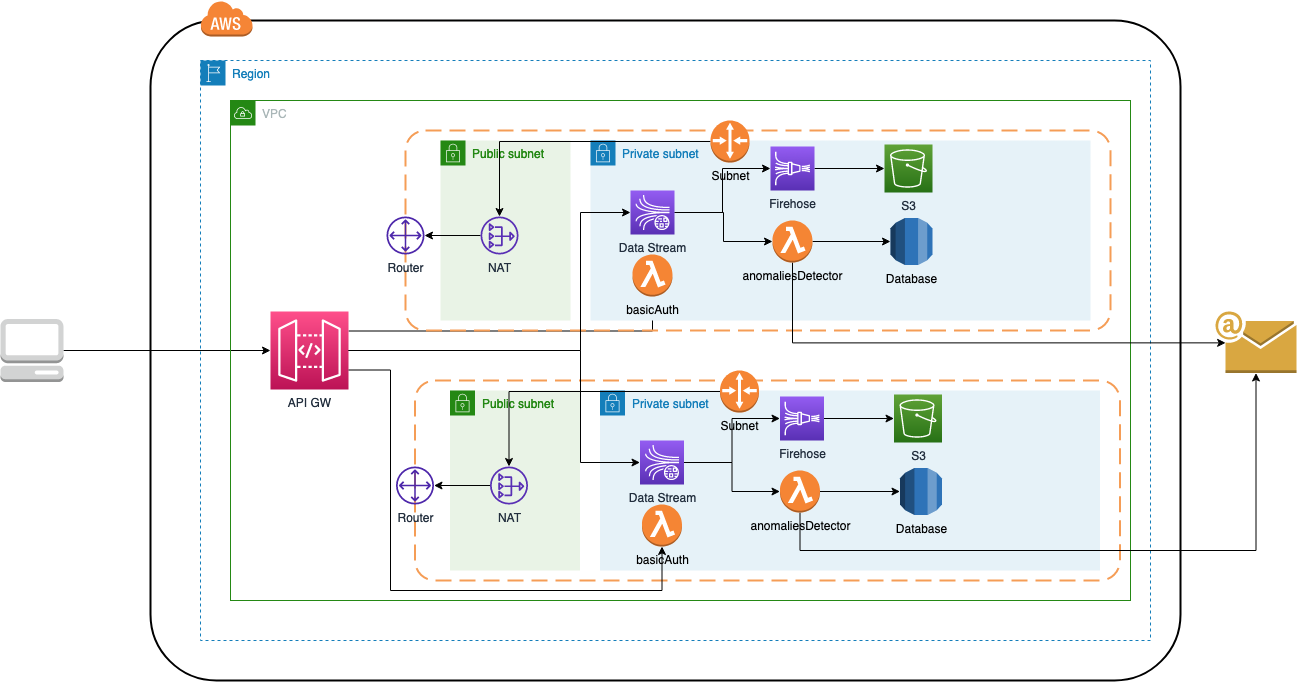
This particular solution, creates a real time streaming service (payment transactions), which are pushed to AWS Kinesis data stream, stored into AWS S3 for cold storage via AWS Kinesis Firehose, and a AWS Lambda detects anomalies in payment transactions (in payment amount > 1000) stores these anomalies to a database and notifies user via email.
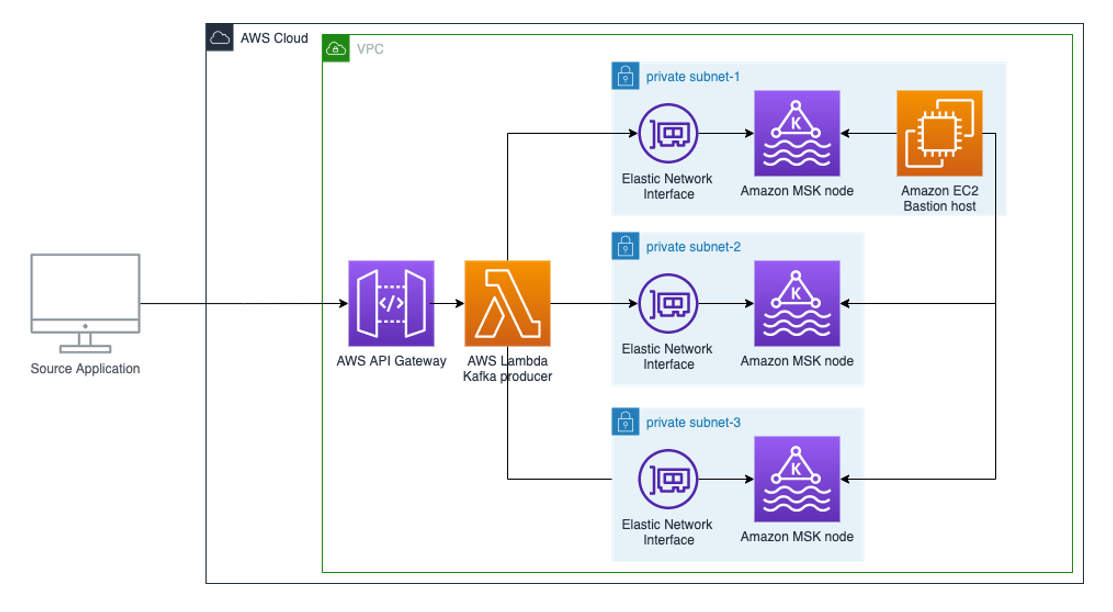
serverless-kafka-producer
serverless-kafka-producer This example walks you through how to build a serverless real-time stream producer application using Amazon API Gateway and AWS Lambda. You can easily deploy via AWS CDK, which creates a demo environment, including an Amazon Managed Streaming for Apache Kafka (MSK) cluster and a bastion host for observing the produced messages on the cluster.
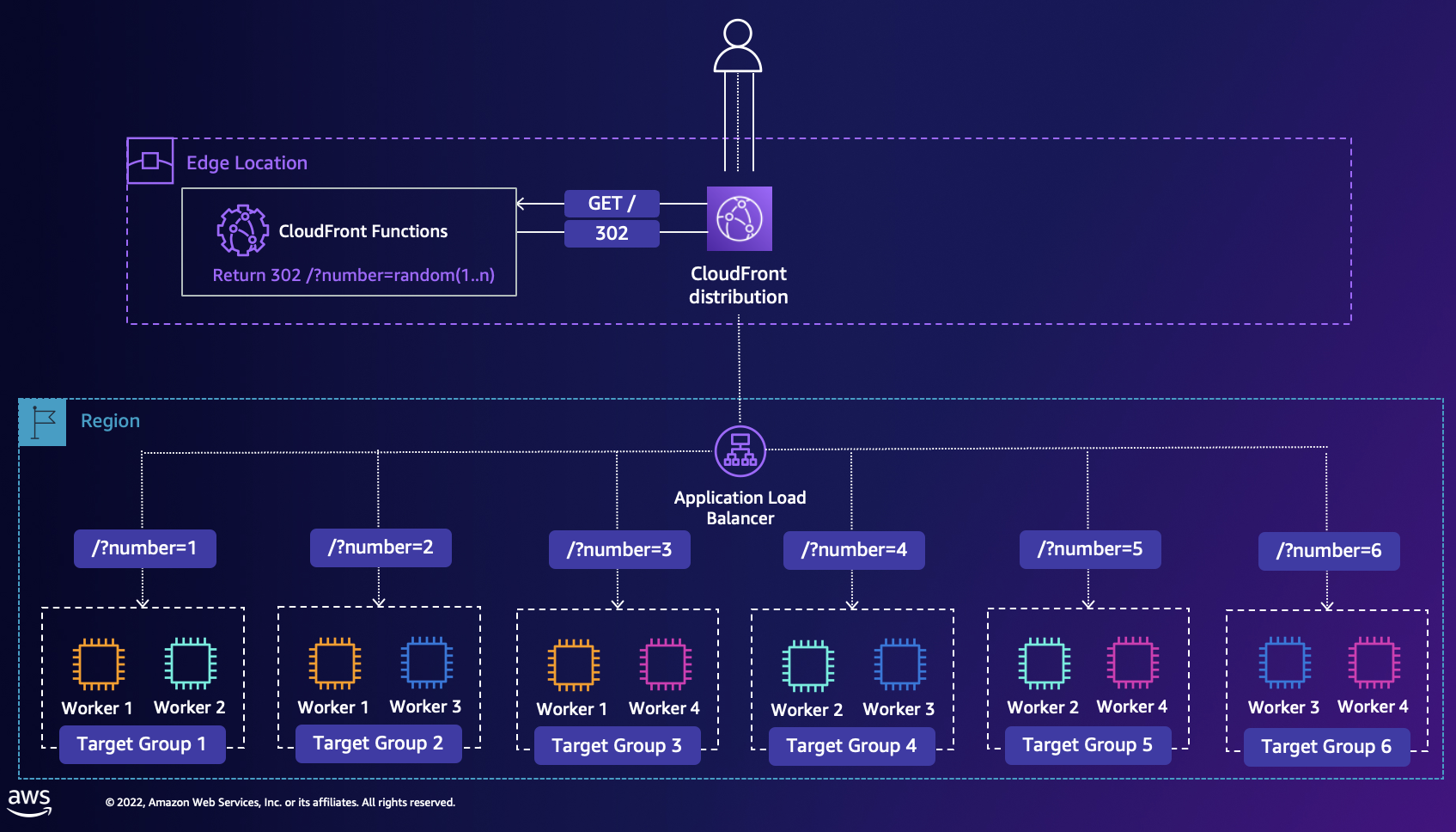
shuffle-sharding-demo-app
shuffle-sharding-demo-app a few years ago, the AWS Builders Library featured a very nice reference article on Workload isolation using shuffle-sharding that has become a core pattern that makes it possible for AWS to deliver cost-effective multi-tenant services that give each customer a single-tenant experience. This project shows you how you can implement the same technique, and provides a demo of Shuffle Sharding solution using Cloudfront and ALB Target groups. The CloudFront distribution (the main entry point to the application) runs a CloudFront Function that allocates a random key, and returns a redirect (302) response to the user with the generated key, and the user is redirected to one of the Target Groups. The demo is quickly deployed via AWS CDK.
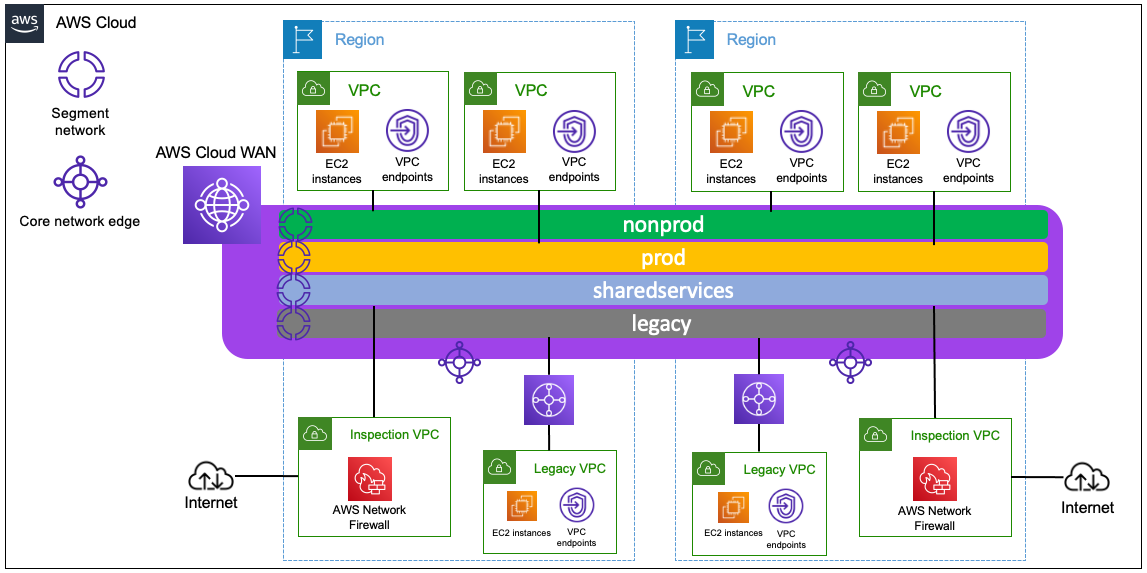
aws-cloudwan-workshop-code
aws-cloudwan-workshop-code perfect timing with the GA announcement last week, AWS Cloud WAN is a managed wide-area networking (WAN) service that you can use to build, manage, and monitor an unified global network that connects resources running across your cloud and on-premises environments. It provides a central dashboard from which you can connect on-premises branch offices, data centers, and Amazon Virtual Private Clouds (VPCs) across the AWS global network. You can use simple network policies to centrally configure and automate network management and security tasks, and get a complete view of your global network. This repository shows you an example of global communication with AWS Cloud WAN, showing the same architecture you can build in the AWS Cloud WAN Workshop using different Infrastructure as Code (IaC) frameworks: CloudFormation, CDK (with Typescript and Python examples) and Terraform.
aws-samples-for-ray
aws-samples-for-ray Ray is a super hot project, it is an open source framework that provides a simple, universal API for building distributed applications. This repo shows you how you can get started using Ray on AWS across Amazon SageMaker, Amazon EC2, Amazon EKS and Amazon EMR.
AWS and Community blog posts
OpenSearch
With OpenSearch 2.0, document-level monitors were released, adding document-level traceability and a new findings index that make it easy to dive deep into the details of what caused an alert. In the latest blog post on the OpenSearch blog, What’s new: Document-level monitors Joshua Bright and Ashish Agrawal talk about document-level monitors within OpenSearch, a feature that allows you to understand and view which documents are triggering alerts.
Data Version Control
A collaboration between Paolo Di Francesco and Eitan Sela in the post, Track your ML experiments end to end with Data Version Control and Amazon SageMaker Experiments explores the open source tool, Data Version Control (DVC), a new type of data versioning, workflow, and experiment management tool and walks you through an example of how to track your experiments across code, data, artefacts, and metrics by using Amazon SageMaker Experiments in conjunction with Data Version Control (DVC). [hands on]

Blazor
In the post Blazor WebAssembly applications my colleague François Bouteruche provides an overview of Blazor WebAssembly and how you can use this on AWS.
Dicoogle
The follow on from a previous post from Forrest Sun, in Running Dicoogle, an open source PACS solution, on AWS (part 2) Forrest continues in showing you how to host a secure Digital Imaging and Communications in Medicine (DICOM) server on AWS using Dicoogle open source software. [hands on]
Redis
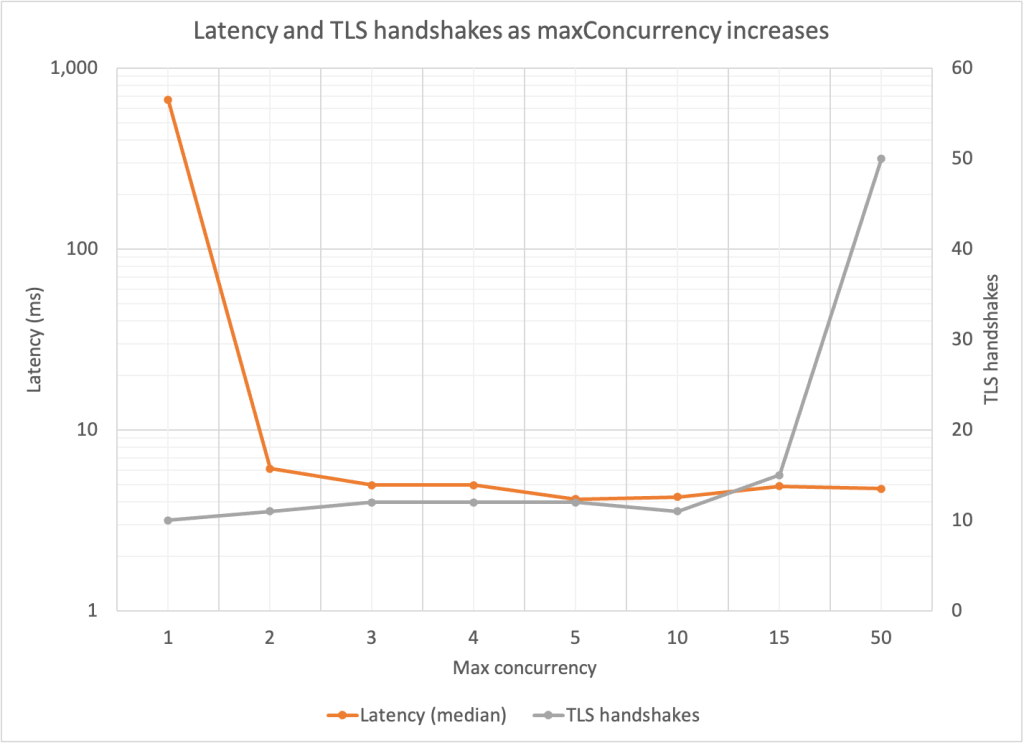
Following on from a previous post, Gary Stafford is back with his latest post, Utilizing In-memory Data Caching to Enhance the Performance of Data Lake-based Applications. In the previous post Gary explored creating a Spring Boot application that interacted with a data lake built on Amazon Athena. In this post, he shows you how to significantly speed things up. Warning, gratuitous use of graphs and benchmarks ahead. As always, another great and must read post. [hands on]
Kyber
Kyber is a key encapsulation method (KEM) designed to be resistant to cryptanalytic attacks with future powerful quantum computers. In the post, How to tune TLS for hybrid post-quantum cryptography with Kyber Brian Jarvis shares how Kyber is available within AWS Key Management Service (KMS) and Amazon Certificate Manager (ACM) and outlines how this new cipher suite raises the security bar and allows you to prepare your workloads for post-quantum cryptography.
Kubernetes
jsPolicy is an open-source framework for managing validating or mutating admission control policies for Amazon Elastic Kubernetes Service (Amazon EKS) clusters using JavaScript (or TypeScript), which is similar to the way AWS Identity and Access Management (IAM) manages AWS accounts and resource access. In the post, Policy management in Amazon EKS using jsPolicy Avaneesh Ramprasad walks you through deploying jsPolicy into an Amazon EKS cluster and implementing two policies—one to deny deployments of resources into the default namespace and another to only allow container images from Amazon Elastic Container Registry (Amazon ECR) [hands on]
Another great post earlier in the week came from Michael Marie Julie and Quentin Bernard from TheFork, who put together, Kubernetes cluster upgrade: the blue-green deployment strategy. An essential component of maintaining Kubernetes is keeping your cluster up-to-date, which requires defining an efficient process that reduces downtime and risk. In this post, they walk you through how they update our Kubernetes clusters while reducing risk to the platform at TheFork.

Karpenter
Pierre Mavro, CTO of Qovery has put together a nice blog post comparing Kubernetes scaling options for your pods in his post, Kubernetes Cluster Autoscaler vs Karpenter
Other posts you might like from the past week
- How to use Amazon RDS and Amazon Aurora with a static IP address is a super nice post that presents a way to access Amazon RDS based on static IP addresses [hands on]
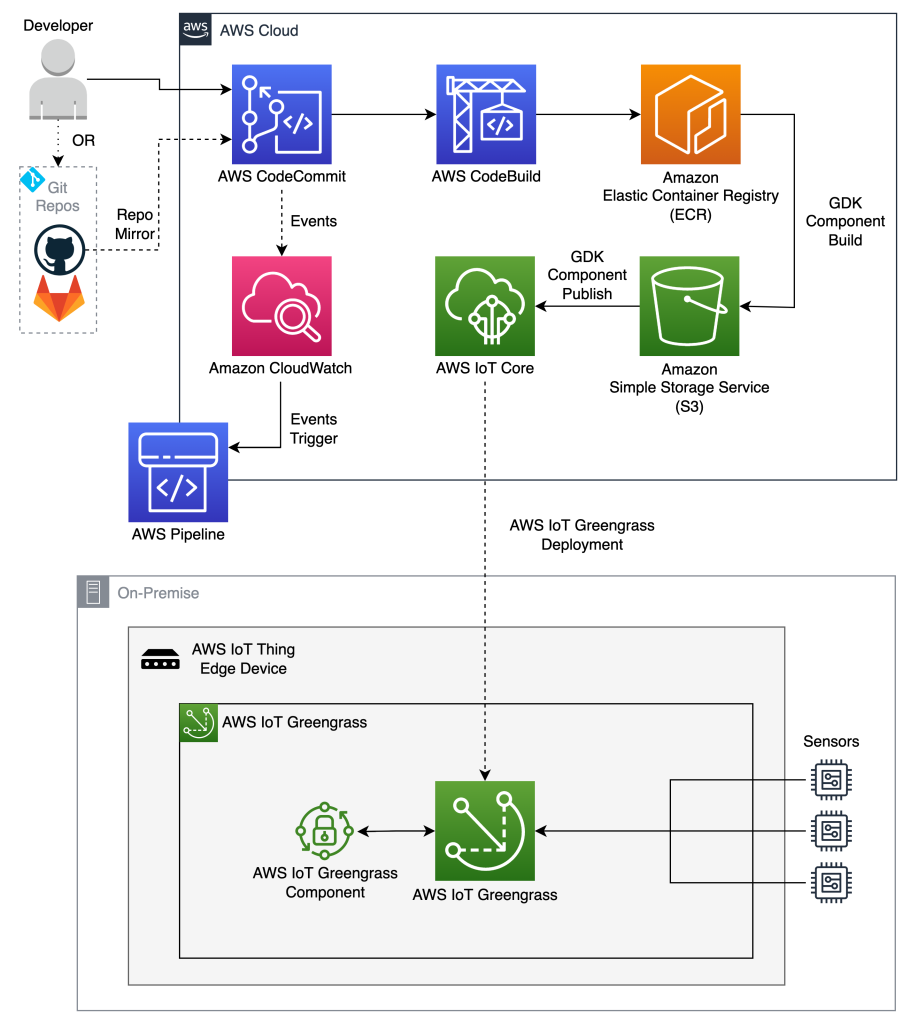
- Automating workflows for AWS IoT Greengrass V2 components highlights the use of AWS CodePipeline for building/publishing AWS IoT Greengrass V2 components and reduces development efforts as well as manual intervention [hands on]
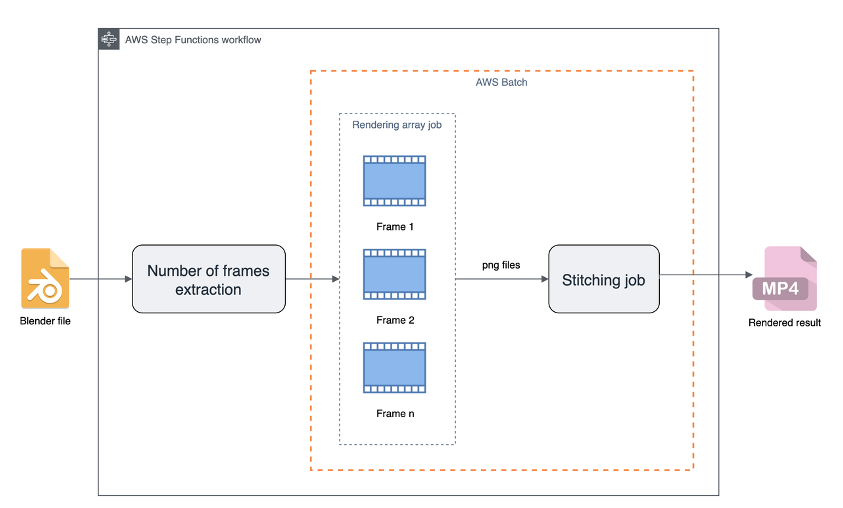
- Efficient and cost-effective rendering pipelines with Blender and AWS Batch explains how to run parallel rendering workloads and produce an animation in a cost and time effective way using AWS Batch and AWS Step Functions [hands on]
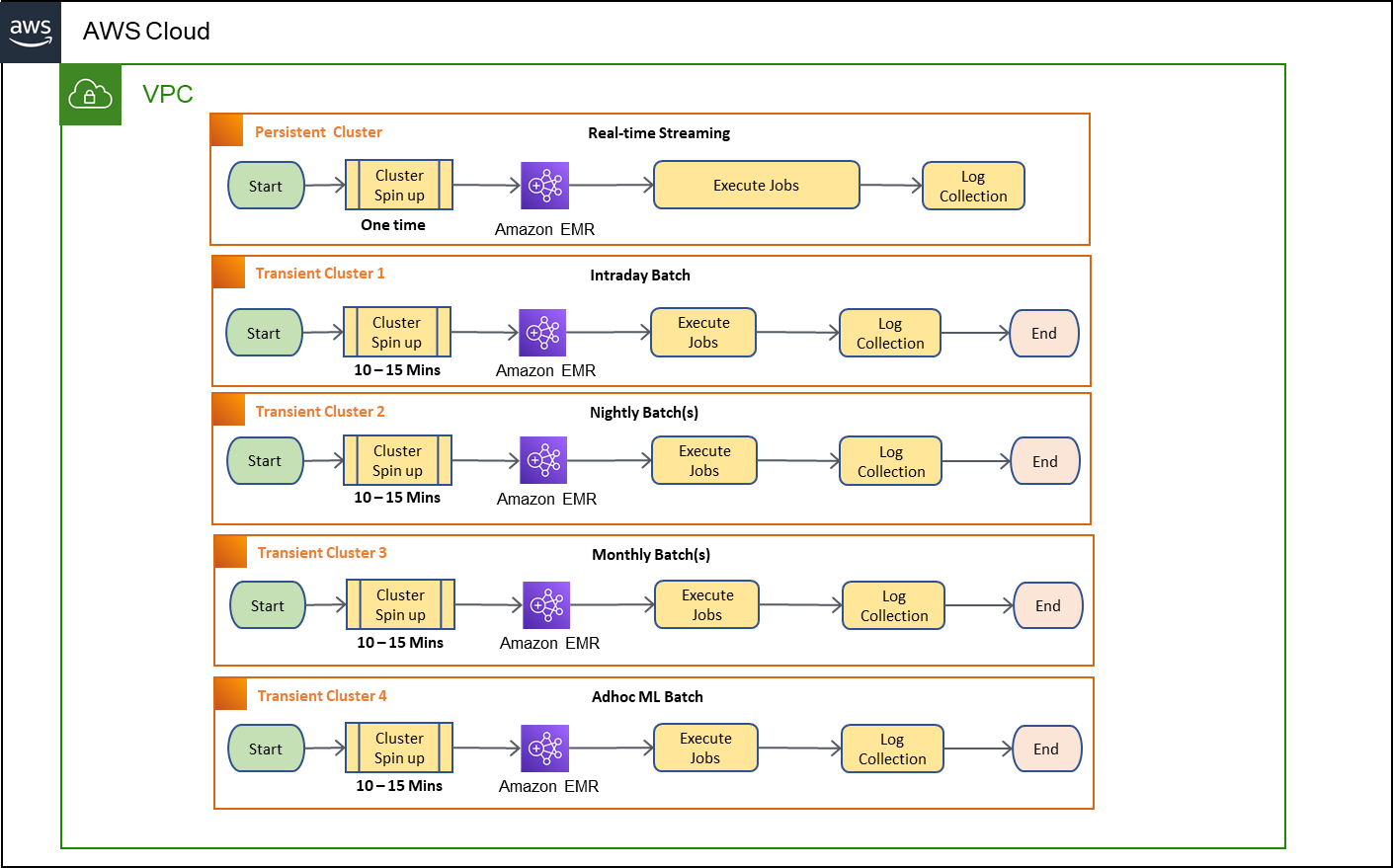
- Using Amazon EMR on Amazon EKS for transient EMR clusters will walk you through how to use EMR on EKS to migrate from transient clusters to a common compute platform [hands on]
Quick updates
OpenSearch
OpenSearch 2.1 is now available for download! This release includes new features and significant enhancements aimed at boosting performance and expanding functionality for search, analytics, and observability use cases. OpenSearch 2.1 delivers a number of capabilities that have come up consistently in the OpenSearch community, including a dedicated node type for running machine learning (ML) workloads at scale, enhanced data protection capabilities, more flexible search options, and user interface upgrades.
Read the full announcement in the post, OpenSearch 2.1 is available now!
MariaDB
Amazon Relational Database Service (Amazon RDS) for MariaDB now supports MariaDB minor versions 10.6.8, 10.5.16, 10.4.25, 10.3.35 and 10.2.44. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MariaDB, and, to benefit from the numerous bug fixes, performance improvements, and new functionality added by the MariaDB community.
Amazon EMR
Result Fragment Caching is a new feature available in Amazon EMR runtime for Apache Spark to help speed up queries that target a static subset of data. In our internal tests derived from the TPC-H benchmark, when using Result Fragment Caching, queries that employ rolling and incremental window functions consistently delivered query performance speedups of up to 15.6x.
Customers often have data in Amazon S3 that does not change over time. However, repeated queries over such datasets need to re-compute results in each run. For e.g. consider eCommerce orders data which contains information about orders that are delivered or returned within 30 days. Suppose a user wants to compare the daily trend of orders for a certain product for the entire year. All orders data is mostly unchanged, except the last 30 days of data, but a query aggregating order returns for every day of last 1 year would need to recompute the results for each day of the year every time the query runs. Result Fragment Caching addresses this by automatically caching results fragments i.e. all parts of the results from subtrees of Spark query plans and then reusing the results on subsequent query executions. Result Fragment Caching allows maximum reuse of the cached data as the fragments i.e. parts of the result can be reused in subsequent queries as opposed to Result Set caching where the query has to exactly match to return the results from cache. Results fragments are stored in a customer-designated S3 bucket and can be re-used across multiple clusters. This can speedup queries especially when the results are significantly smaller than the input data set. With Result Fragment Caching, repeated queries aggregating orders in the last 1 year would only need to compute the last 30 days of changed data while for all previous days of the year, aggregated results could be simply served from cache significantly improving query performance. The speedup could be even more pronounced for queries on data that is mostly immutable and is only inserted for the current day e.g. for IOT events, clickstream data etc. In the rare cases where data is modified, Result Fragment Caching automatically detects and invalidates the cached data ensuring data accuracy.
.NET Core
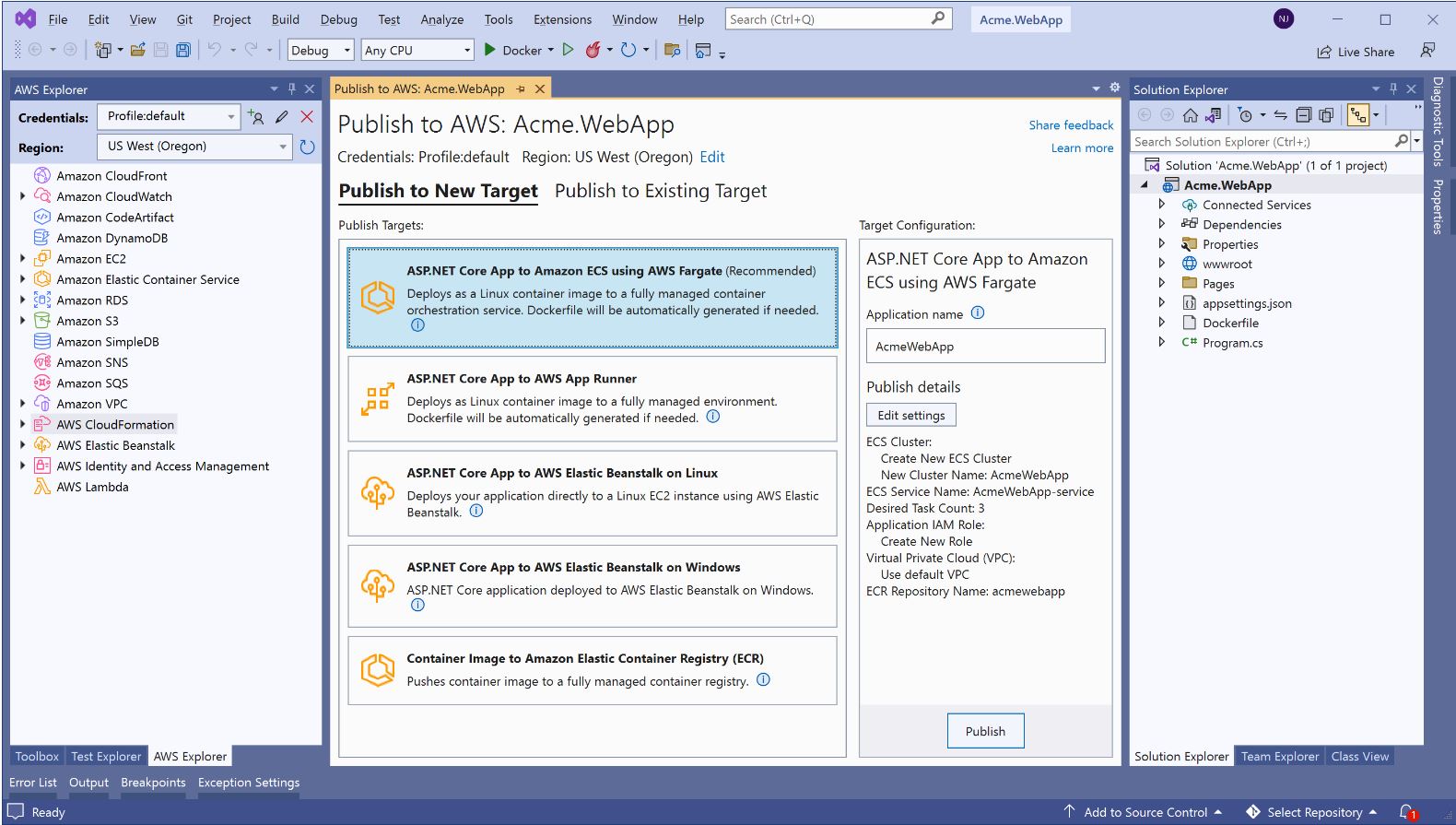
Announced last week was the new deployment experience in both the Visual Studio and the .NET CLI for .NET developers. The new deployment experience focuses on the type of application you want to deploy instead of individual AWS services by providing intelligent compute recommendations.
Read more about this in the post from Irene Kors and Norm Johanson, AWS announces a streamlined deployment experience for .NET applications
Babelfish
AWS Database Migration Service (AWS DMS) has expanded functionality by adding support for Babelfish for Aurora PostgreSQL as a target. Babelfish for Aurora PostgreSQL is a new translation layer for Amazon Aurora PostgreSQL-Compatible Edition that enables Aurora to understand commands from applications written for Microsoft SQL Server. Using AWS DMS, you can now perform full load migrations to Babelfish for Aurora PostgreSQL with minimal downtime.
AWS IoT Greengrass
AWS IoT Greengrass is an Internet of Things (IoT) edge runtime and cloud service that helps customers build, deploy, and manage device software. We are excited to announce our version 2.6 release, which adds edge support for MQTT version 5, an updated device-to-device communication specification that includes many additional feature improvements over the MQTT version 3.1.1 protocol.
Prior to this release, AWS IoT Greengrass provided support for MQTT v3.1.1 through the Moquette open source broker, which works well for many edge device-to-device communications environments where a scalable and low memory solution is needed. Industrial and automotive customers have asked for support for the MQTT v5 protocol, which adds 18+ improvements over the MQTT v3.1.1 protocol with a host of communication, posting, and subscription features. This AWS IoT Greengrass release adds a new component that includes the managed open source MQTT v5 edge broker EMQX, which provides native support for the MQTT v5 protocol. EMQX also includes advanced features such as broker high availability and broker clustering which add performance and resilience improvements for high-throughput use cases.
Videos of the week
Rust
Zelda Hessler a member of the AWS Rust SDK team, provides a quick overview of the AWS Rust SDK. In this talk she covers how to use the SDK to make requests, what’s actually happening when using the SDK to make requests, how the AWS Rust SDK team generates SDKs for 300+ Services, and finally, what to do if you’re interested in contributing to the SDK.
Kubernetes
A return from the Containers from the Couch crew, this time showing you how to run Kubernetes on bare metal servers using EKS Anywhere and the new bare metal support. They show how to provision a cluster, what components run during installation, and how to customise your configuration.
Events for your diary
BOSC 2022 July 13-14, Madison, Wisconsin, USA
The Bioinformatics Open Source Conference (BOSC) has been held annually since 2000, and this year AWS is proud to be a platinum sponsor for this event. BOSC covers all aspects of open source bioinformatics software and open science, including (but not limited to) these topics, Open Science and Reproducible Research, Open Biomedical Data, Citizen/Participatory Science, Standards and Interoperability, Data Science Workflows, Open Approaches to Translational Bioinformatics, Developer Tools and Libraries, Inclusion, and Outreach and Training. This is a hybrid event (in person/virtual) and you find out more by checking out the event page, BOSC 2022
Cloud DevSecOps with Bridgecrew and Terraform July 21st
From scanning infrastructure as code (IaC) for security misconfigurations to implementing automated DevSecOps workflows, this workshop will provide a hands-on experience to automate your cloud security. Check out more details and register using this page, Cloud DevSecOps with Bridgecrew and Terraform
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
OpenSearchCon 2022 Sept 21st, 2022 Seattle
Come to the first annual OpenSearchCon!
This day-long conference will be packed with presenters who build and innovate with OpenSearch. It doesn’t matter if you’re just getting started on your OpenSearch journey, running giant clusters, or contributing tons of code; the event is for everyone. Join us to celebrate the progress and look into the future of the project. Admission is free, and registration will be open in the next few weeks. All you will need to do is sign up, and get to Seattle!
Check out the full details, including signing up and location, at the meetup page here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen