AWS open source news and updates #117
June 17th, 2022 - Instalment #117
Welcome to regular and new readers alike, to the AWS open source newsletter episode #117.
A little behind schedule this week, as I have been speaking at a couple of events this week. It has been good to get back on the stage and to talk and engage with real people. It seems that things are quickly returning back to normal. So this week we have some great new projects for you. Starting off with “cdklightbox” which helps you visualise your AWS CDK stacks (I have already tried it, and this has already helped me spot something in one of my stacks that didn’t look right). We have “glue-data-sanitization” which is a nifty tool to help you sanitise your data as you move it between environments. “automated-security-helper” is a tool to help you quickly test your setup against some quick security checks using some nice open source security tools, and I can see this one quickly being adopted by folk. We have many more projects and demos covering data streaming, generating AppSync compliant schemas from PostgreSQL tables, large file size S3 tools and more.
Also featured this week is content on Apache Cassandra, PostgreSQL, Bottlerocket, Apache APISIX, PostGraphile, OpenSearch, Apache Iceberg, Kubernetes, Yocto Project, Flutter, and many more. We have a couple of videos featuring Karpenter and OpenSearch, so don’t miss those and of course we finish up with events.
As always, if you have anything you want me to include in this weekly round up, please drop me a mail or reply to this post.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Mikael Vesavuori, Brice Pellé, Luke Harvey, Marcio da Ros Gomes, Sebastian Goscik, Sakti Mishra, Daniel Doubrovkine, Juan Lamadrid, Rob Solomon, Saravanan G, Johannes Koch, Carlo Mencarelli, Brian Caffey, Juan Lamadrid, Rob Solomon, Nirmal Mehta, Bret Fisher, Charlotte Henkle, Sean Neumann and Yubo Wang.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
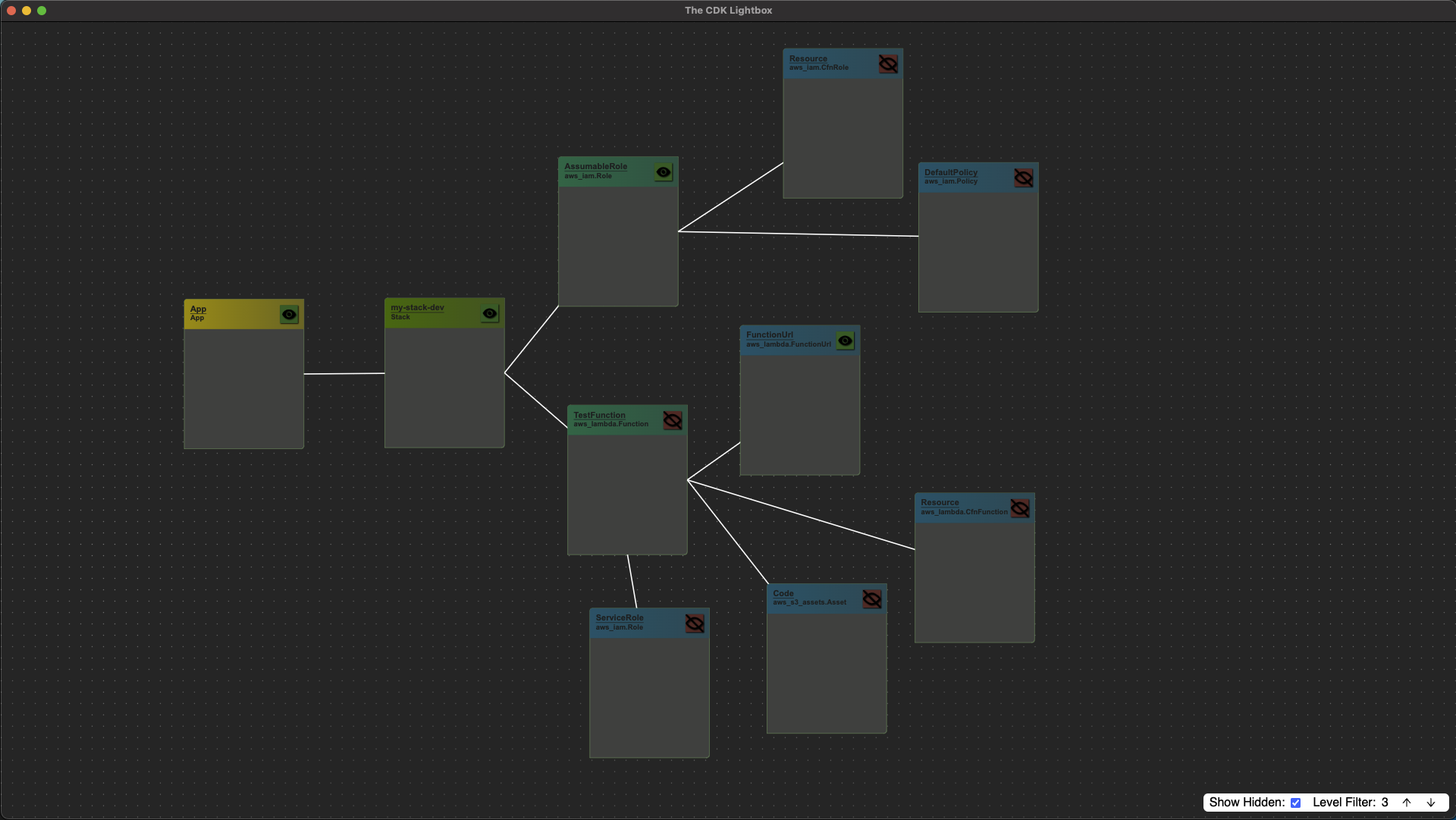
cdklightbox
cdklightbox this project from the Open Construct Foundation is The CDK Lightbox, a tool for visualising your CDK applications. I downloaded this from the releases link and quickly tried it on one of my stacks. It was nice to see my CDK application presented in this way. I was able to change the level of constructs shown, and zoom in/out and move things around.
glue-data-sanitization
glue-data-sanitization-from-production-s3-bucket-to-lower-environment-s3-bucket-apg-example is winner of this weeks longest GitHub repo name award. This repo contains code that you can build upon to help you create solutions that perform data sanitisation (remove of PII and regulated contents) as part of moving data from production to non production (dev/testing for example) environments.
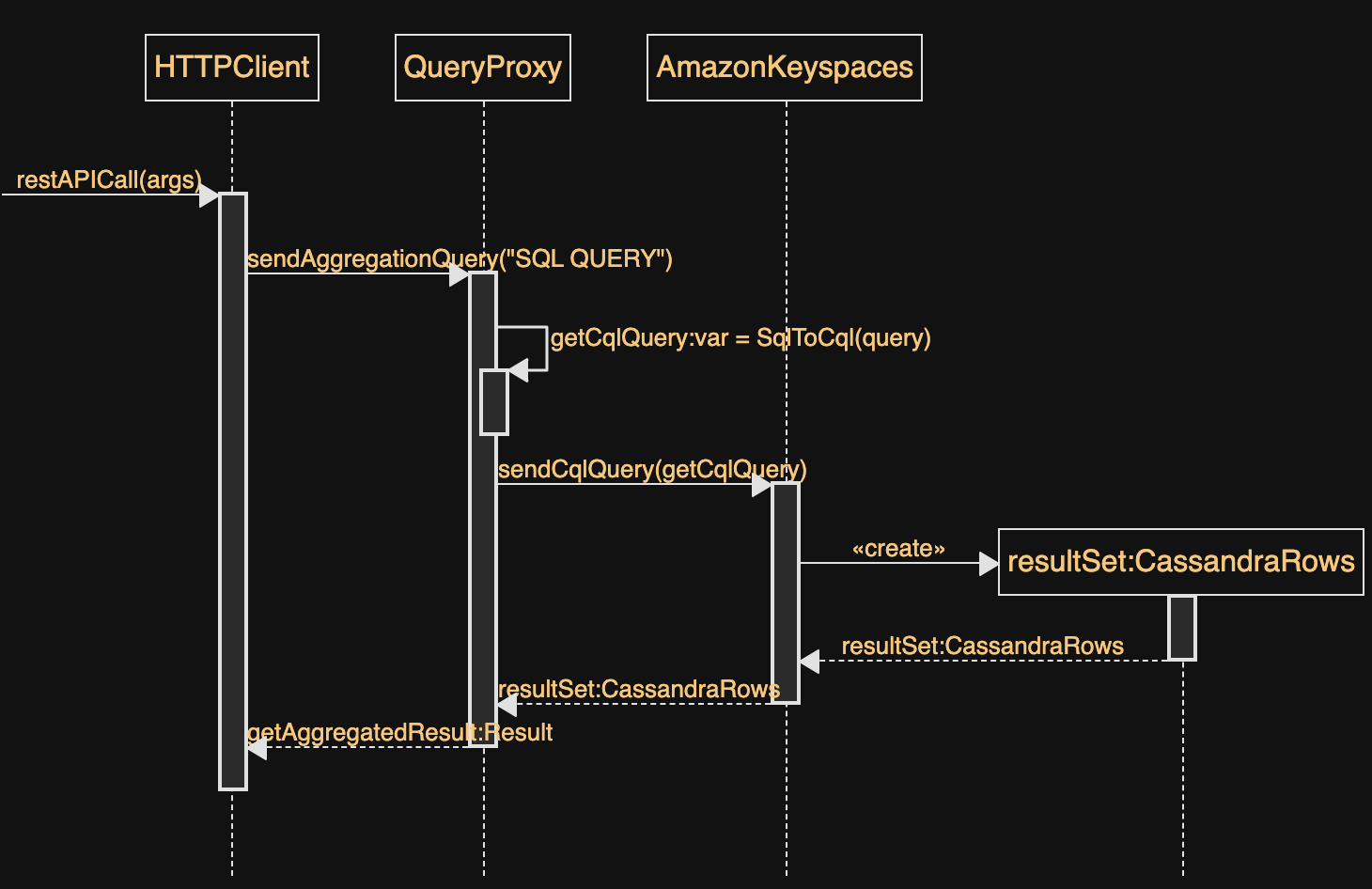
amazon-aggregation-query-proxy
amazon-aggregation-query-proxy this repo is a scalable sidecar application that sits between a customer application and Amazon Keyspaces/DynamoDB. It allows you to run bounded aggregation queries against Amazon Keyspaces and DynamoDB services. The aggregation-query-proxy (AQP) consists of a scalable proxy layer that sits between your application and Amazon Keyspaces/DynamoDB. It provides intermediate aggregation logic which allows existing application to execute aggregation queries against Amazon DynamoDB/Keyspaces. This project then converts the provided aggregation query (SQL-92) to a plain request (CQL/DDBPartiQL). After the plain response (json) has been received the AQP uses IonEngine to aggregate the plain response into the final result set in json format.
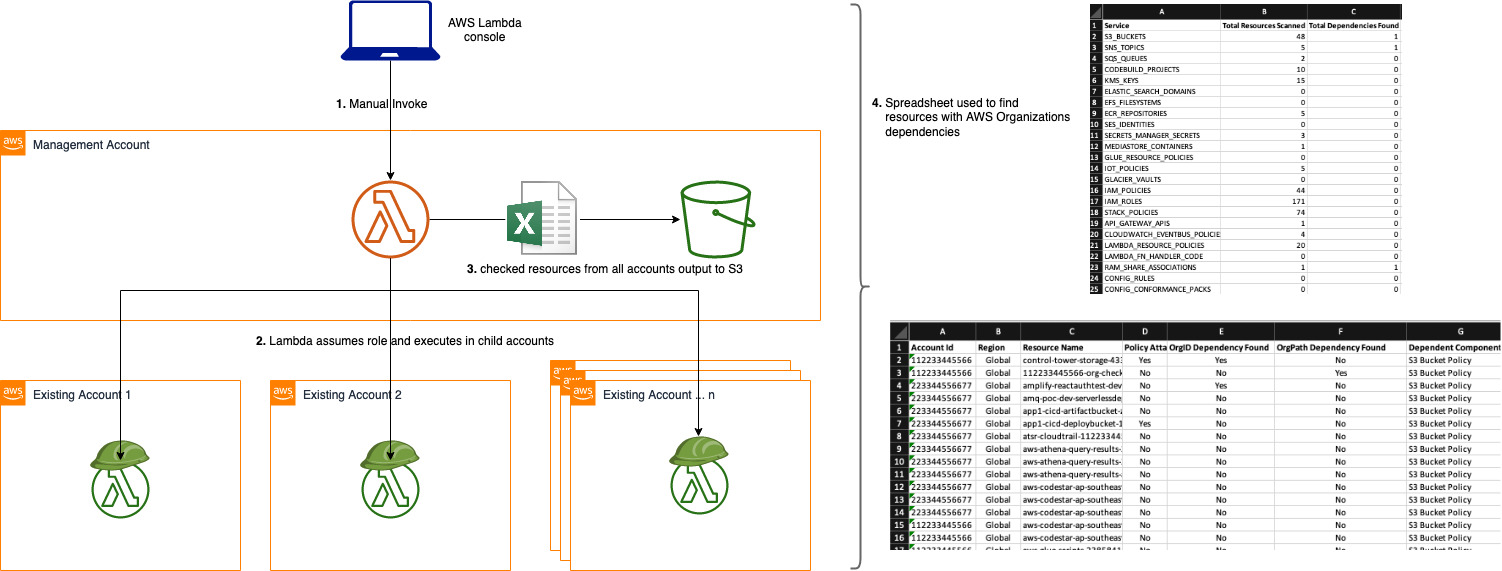
check-aws-resources-for-org-conditions
check-aws-resources-for-org-conditions This repository provides the automation to check for references to Organisational resources in policies across some or all the accounts in an AWS Organisation. Specifically, the tool looks for aws:PrincipalOrgID and PrincipalOrgPaths. This is used in analysing the dependencies when AWS Accounts are migrated from one AWS Organisation to another.
automated-security-helper
automated-security-helper this security helper tool was created to help you reduce the probability of a security violation in a new code, infrastructure or IAM configuration by providing a fast and easy tool to conduct preliminary security check as early as possible within your development process. It is not a replacement of a human review nor standards and it uses light, open source tools to maintain its flexibility and ability to run from anywhere. Very nice tool indeed.
Demos, Samples, Solutions and Workshops
appsync-with-postgraphile-rds
appsync-with-postgraphile-rds this repo provides a CDK-based solution that allows you to create an AWS AppSync API from a defined Postgres database in AWS RDS. This solution leverages PostGraphile to automatically generate an AppSync compliant schema from PostgreSQL tables, and uses Lambda functions to resolve GraphQL queries against a PostgreSQL database in Amazon RDS. To help you get started, check out the blog post Creating serverless GraphQL APIs from RDS databases with AWS AppSync and PostGraphile from Brice Pellé. Very cool post.

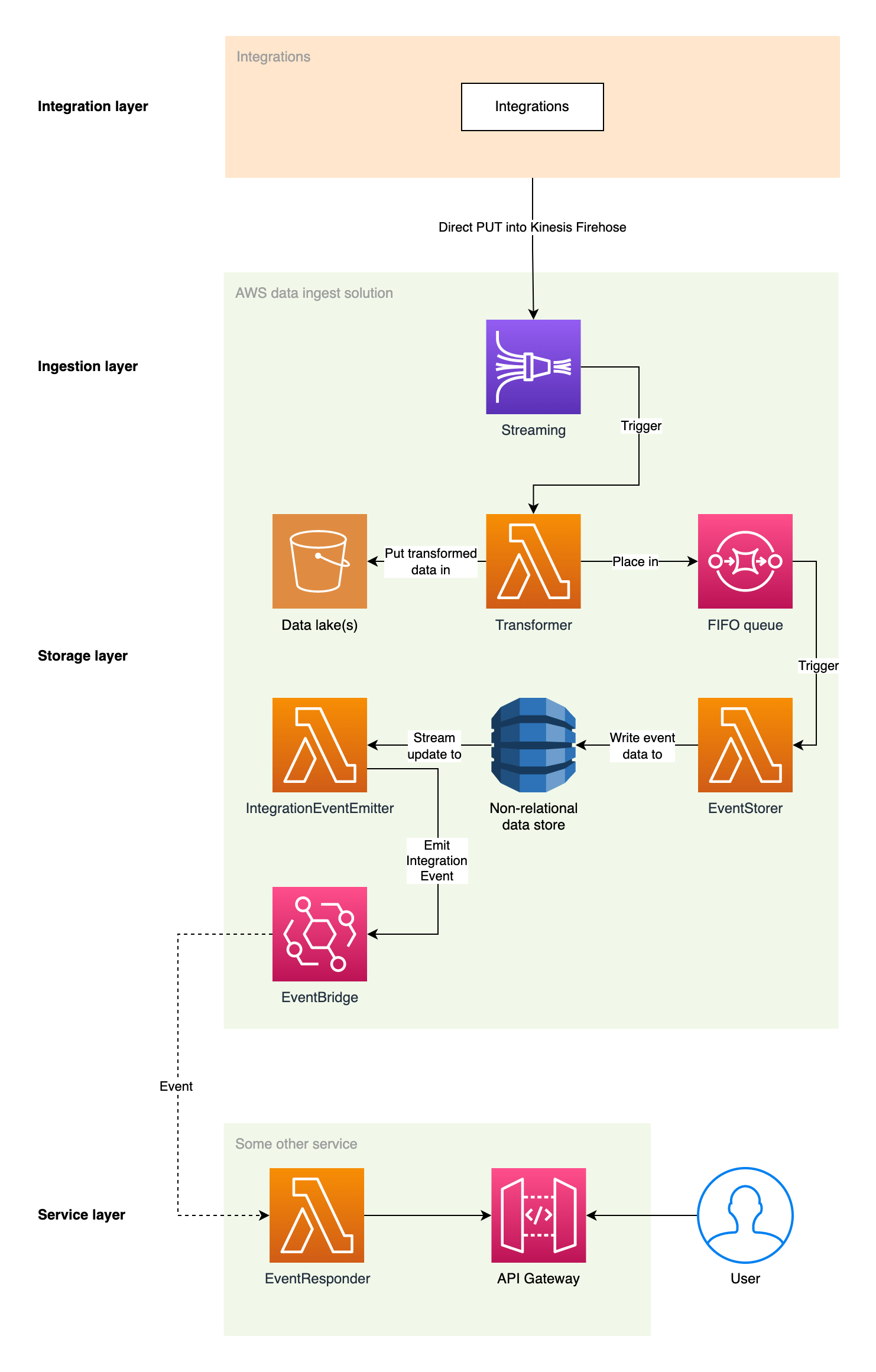
example-aws-stream-data-to-events
example-aws-stream-data-to-events this repo from Mikael Vesavuori contains a complete, working architecture on AWS that will take in streaming data, store it in S3 and DynamoDB, and then emit events with their contents. You can easily deploy thanks to Terraform, and this is what the project will build:
aws-cdk-support-s3-large-deployments
aws-cdk-support-s3-large-deployments this project demonstrate how to upload large file to S3 Bucket using CDK using the inbuilt CDK Assets Bucket and Custom Resource. Assets are local files, directories, or Docker images that can be bundled into AWS CDK libraries and apps; for example, a directory that contains the handler code for an AWS Lambda function. Assets can represent any artefact that the app needs to operate. You can define local files and directories as assets, and the AWS CDK packages and uploads them to Amazon S3 through the aws-s3-assets module. Nicely documented and easy to follow along, and its in Python, so of course that made me very happy indeed.
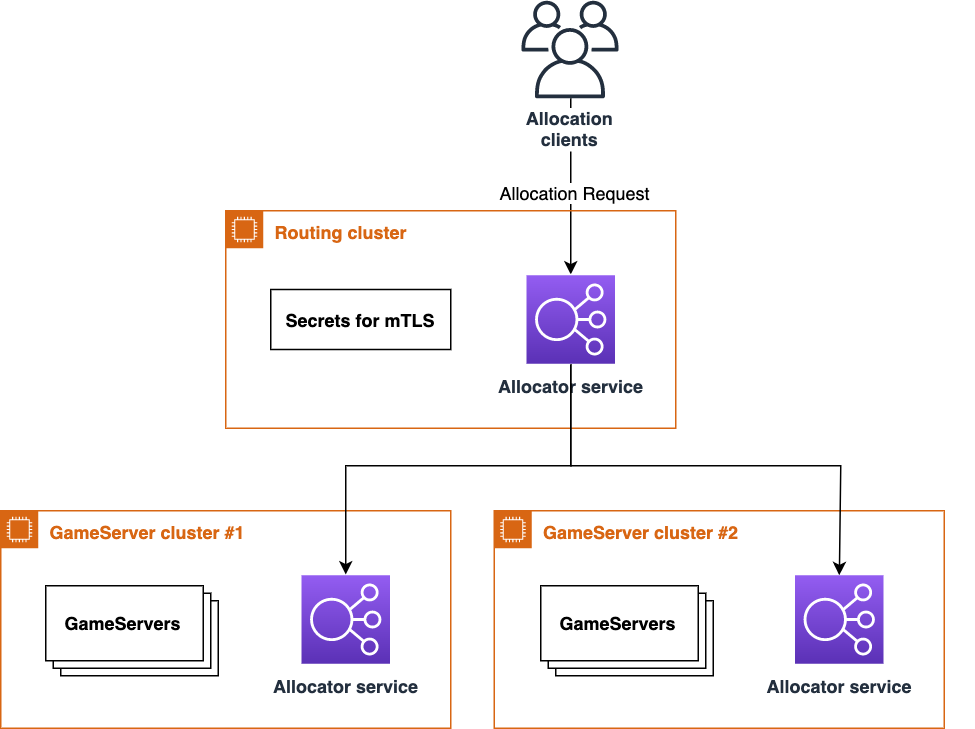
multi-cluster-allocation-demo-for-agones-on-eks
multi-cluster-allocation-demo-for-agones-on-eks This project uses Terraform to deploy an Agones (an open source, batteries-included, multiplayer dedicated game server) multi-cluster configuration to Amazon EKS, one routing cluster and two DGS clusters, with multi-cluster allocation feature enabled.
AWS and Community blog posts
Apache APISIX
Apache APISIX is an open source dynamic, real-time, high-performance API Gateway. My colleague Yubo Wang has put together this great post, Installation and performance testing of API Gateway Apache APISIX on AWS Graviton3 where he shares how you can deploy this project using AWS Graviton3 instance types, and then takes a look at some of the performance characteristics. I don’t want to spoil the ending, so make sure you check out this weeks must read post.

OpenSearch
Want to know what it is like to work on an open source project at Amazon? Open source builder Daniel Doubrovkine has put together this blog post, A Year Working on OpenSearch where he shares a frank and honest summary of working on the OpenSearch project over the past year. Well worth a read I think.
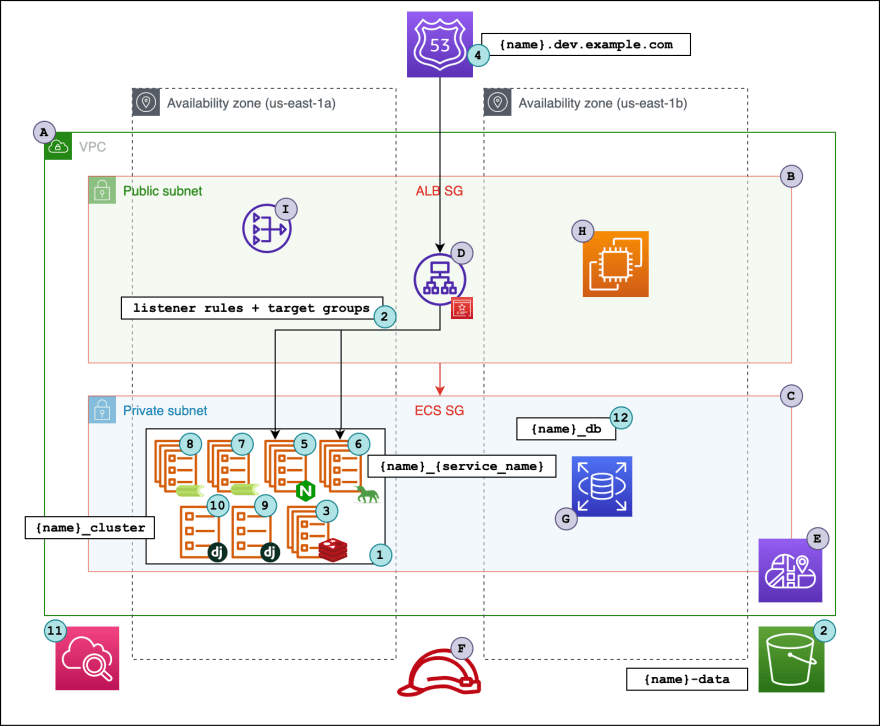
Django
Brian Caffey has put together this comprehensive post, Setting up ad hoc development environments for Django applications with AWS ECS, Terraform and GitHub Actions adopting 12Factor application methodology to show you how you can combine AWS services, open source to deploy a sample microblogging application that uses the Python Django framework. Adaptable to your own use case, this is a nice deep dive. [hands on]
Apache Iceberg
Apache Iceberg is an open table format originally developed at Netflix. It’s designed to support ACID transactions and UPSERT on petabyte-scale data lakes, and is getting popular because of its flexible SQL syntax for CDC-based MERGE, full schema evolution, and hidden partitioning features. In the post Implement a CDC-based UPSERT in a data lake using Apache Iceberg and AWS Glue Sakti Mishra guides you through a solution to implement CDC-based UPSERT or MERGE in an S3 data lake using Apache Iceberg and AWS Glue. [hands on]

Kubernetes
In the post A quick path to Amazon EKS single sign-on using AWS SSO, Juan Lamadrid and Rob Solomon share with you a quick and direct procedure to implement single sign-on to access Kubernetes resources running on your Amazon Elastic Kubernetes Service (Amazon EKS) clusters. You can then use this SSO in combination with Kubernetes Role Based Access Control (RBAC) via the AWS Command Line Interface (CLI) or Kubernetes CLI tools. [hands on]
Yocto Project
In 2021 Arm, AWS, and other founding members announced the Scalable Open Architecture for Embedded Edge (SOAFEE) Special Interest Group, which brings together automakers, semiconductor, and cloud technology leaders to define a new open-standards based architecture to implement the lowest levels of a software-defined vehicle stack. In the post, Building an Automotive Embedded Linux Image for Edge and Cloud Using Arm-based Graviton Instances, Yocto Project, and SOAFEE Luke Harvey, Marcio da Ros Gomes, and Sebastian Goscik introduce a building block toward a novel automotive-software development concept that helps developers create, test, and debug natively compiled software using the cloud.

Following the post you will create a custom Linux distribution using the Yocto Project, an open-source collaboration project that helps developers create custom Linux-based systems regardless of the hardware. It is used by many embedded projects, including the Automotive Grade Linux initiative that is part of the Linux Foundation as well as the SOAFEE reference implementation. Very cool post, so make sure you check this out. [hands on]

Other posts you might like from the past week
- Amazon Aurora PostgreSQL backups and long-term data retention methods explores the primary tools focusing on backups, backup storage, and restore, and discuss some best practices related to applying these tools [hands on]
- Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena demonstrates how to use and interpret EXPLAIN and EXPLAIN ANALYZE statements to improve Athena query performance when querying multiple data sources
- How to centrally manage AWS IoT Greengrass devices using AWS Systems Manager shows you how you can simplify and centralise how you manage your AWS IoT Greengrass devices [hands on]
- Text summarization with Amazon SageMaker and Hugging Face walks you through how to implement one of the most downloaded Hugging Face pre-trained models used for text summarisation, DistilBART-CNN-12-6, within a Jupyter notebook using Amazon SageMaker and the SageMaker Hugging Face Inference Toolkit [hands on]
- Create, train, and deploy a billion-parameter language model on terabytes of data with TensorFlow and Amazon SageMaker covers two main approaches data parallelisation and model parallelisation in how you can tackle large scale model training [hands on]
AWS Community Builder and Hero picks
Here are some posts from the AWS Hero and AWS Community Builders that are worth checking out.
- Getting started with Python based IaC using AWS CDK (Saravanan G) - if you are a Python developer and want to start understanding and using AWS CDK, this is the post for you
- Building a Flutter application for Web, iOS and Android using a CI/CD pipeline on CodeBuild (Johannes Koch) – part of a series of posts where you will build a Flutter application for Web and use AWS CDK to help you
- Linux’s Cloud Init — Benefits, Quirks, and Drawbacks (Carlo Mencarelli) - if you are using Linux instances on AWS, check out these deep dive and learn more about Cloud Init
Quick updates
Bottlerocket
Bottlerocket has added a variant that supports NVIDIA GPU-based Amazon EC2 instance types on Amazon Elastic Container Services (Amazon ECS). Bottlerocket is a Linux-based operating system that is purpose-built to run container workloads. Customers can now benefit from using the same container-focused host operating system for both their non-GPU and GPU workloads while using ECS, including machine learning, video encoding, and streaming workloads. This helps customers standardise on a single operating system that utilises the underlying specialised compute hardware.
Back in March, another Bottlerocket variant was released, for Amazon Elastic Kubernetes Service (Amazon EKS) supporting NVIDIA GPU-accelerated workloads. With the availability of the Bottlerocket ECS variant, customers can now use Bottlerocket with NVIDIA GPUs on two popular orchestration services, Amazon EKS and ECS. The new Bottlerocket AMI includes the necessary software components required to run containerised accelerated workloads built into the base image, while using ECS as their container orchestration service. This configuration enables secure, seamless installation of required NVIDIA drivers and its updates, improves time to node-ready state, and reduces dependencies on external tools and repositories.
Read more and get hands on by checking out the post from Maish Saidel-Keesing, Announcing NVIDIA GPU support for Bottlerocket on Amazon ECS
Apache Cassandra
Amazon Keyspaces (for Apache Cassandra), a scalable, highly available, and fully managed Apache Cassandra-compatible database service, now helps you monitor your table-level storage costs through Amazon CloudWatch. You can now use the BillableTableSizeInBytes CloudWatch metric to monitor and track your table storage costs over time. The BillableTableSizeInBytes metric provides the billable storage size of a table by summing up the encoded size of all the rows in the table.
PostgreSQL
A few of updates this week.
First is that Amazon Aurora PostgreSQL-Compatible Edition now supports the Large Objects (LO) module. The LO module provides support for managing Large Objects (also called LOs or BLOBs).
Following that is news that Amazon Aurora PostgreSQL-compatible edition now supports zero-downtime patching (ZDP). With ZDP, customers can upgrade to a new PostgreSQL version and apply patches to their Aurora cluster without any downtime. ZDP preserves client connections while the database engine restarts. This feature allows you to more frequently upgrade your clusters to newer PostgreSQL minor versions while maintaining business continuity. ZDP is enabled on all Aurora clusters running supported database versions in all regions when you upgrade database minor versions or apply patches. Please review the Aurora documentation for more details.
Finally we have the announcement of updates to the PostgreSQL database by the open source community, we have updated Amazon Aurora PostgreSQL-Compatible Edition to support PostgreSQL 13.7, 12.11, 11.16, and 10.21. These releases contain bug fixes and improvements by the PostgreSQL community. Refer to the Aurora version policy to help you to decide how often to upgrade and how to plan your upgrade process.
This release also includes updates to pglogical and wal2json extensions. pglogical is an open source PostgreSQL extension that helps customers replicate data between independent PostgreSQL databases while maintaining consistent read-write access and a mix of private and common data in each database. Amazon Aurora pglogical uses logical replication to copy data changes between independent PostgreSQL databases, optionally resolving conflicts based on standard algorithms. Customers can enable pglogical from within their PostgreSQL instances, and pay only for the additional clusters and cross-region traffic needed, with no upfront costs or software purchases required. Fully integrated, pglogical requires no triggers or external programs. This alternative to physical replication is a highly efficient method of replicating data using a publish/subscribe model for selective replication.
wal2json is an output plugin for logical decoding. Logical decoding is the process of extracting all persistent changes to a database’s tables into a coherent, easy to understand format which can be interpreted without detailed knowledge of the database’s internal state. Customers can use the extension to export the output of the PostgreSQL write-ahead log (WAL) into JSON objects.
Videos of the week
OpenSearch
The OpenSearch Project is a community-driven, open source search and analytics suite. It consists of a search engine daemon, OpenSearch, and a visualisation and user interface, OpenSearch Dashboards. OpenSearch enables people to ingest, secure, search, aggregate, view, and analyse data. Our goal is to build great software together with a strong and vibrant community. In this talk Sean Neumann and Charlotte Henkle share more about what has been launched so far, what’s coming in the future, and the challenges of stewarding an open-source project while also being associated with a large corporation.
{% youtube FVUMBuExo5E %}
Karpenter
Nirmal Mehta, a Principal Specialist Solution Architect at AWS, and a Docker Captain, joins Bret Fisher to discuss and demo Karpenter. Karpenter is an autoscaling solution that aims to simplify Kubernetes infrastructure by automating node scaling up and down, with the “the right nodes at the right time.”
Open Source in Public Sector
Interesting session from the AWS Summit DC, taking a look at how open-source solutions and the cloud become force multipliers for enabling and accelerating that transformation. Reusing a proven open-source solution reduces lengthy and expensive procurement activities, while the cloud enables rapid deployment. This session looks at some of the case studies from around the world of successful use of open-source applications that have enabled and accelerated digital transformation within the public sector.
Some very interesting data points in this session. Public money, public code. What are your thoughts?
Events for your diary
Observability: Open Source Solutions June 28th, 10:00am - 2:15pm PDT
The AWS Monitoring and Observability Team invites you to participate in a hands on session with Amazon Managed Service for Prometheus, Amazon Managed Service for Grafana and AWS Distro for Open Telemetry. During this session you will use these services in creating workspaces, ingesting/querying metrics, logs and trace data and viewing in a dashboard you will set up. The afternoon will close with demo of what you have done and highlighting the value in MTTD, MTTI, MTTR and application performance.
This event is designed for those looking to implement AWS Observability using open-source services to visualize their data with native or 3rd party tools. Site reliability engineers, operations engineers, systems engineers, and DevOps. Familiarity with monitoring concepts such as logs, metrics, traces, alarms, and the dashboard is recommended, but not required.
Register via this page.
BOSC 2022 July 13-14, Madison, Wisconsin, USA
The Bioinformatics Open Source Conference (BOSC) has been held annually since 2000, and this year AWS is proud to be a platinum sponsor for this event. BOSC covers all aspects of open source bioinformatics software and open science, including (but not limited to) these topics, Open Science and Reproducible Research, Open Biomedical Data, Citizen/Participatory Science, Standards and Interoperability, Data Science Workflows, Open Approaches to Translational Bioinformatics, Developer Tools and Libraries, Inclusion, and Outreach and Training. This is a hybrid event (in person/virtual) and you find out more by checking out the event page, BOSC 2022
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
OpenSearchCon 2022 Sept 21st, 2022 Seattle
Come to the first annual OpenSearchCon!
This day-long conference will be packed with presenters who build and innovate with OpenSearch. It doesn’t matter if you’re just getting started on your OpenSearch journey, running giant clusters, or contributing tons of code; the event is for everyone. Join us to celebrate the progress and look into the future of the project. Admission is free, and registration will be open in the next few weeks. All you will need to do is sign up, and get to Seattle!
Check out the full details, including signing up and location, at the meetup page here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen