AWS open source news and updates #116
June 10th, 2022 - Instalment #116
Welcome to regular and new readers alike, to the AWS open source newsletter episode #116.
Another selection of useful and interesting new open source projects for you to try out this week. First up, we have “aws-exec” a tool to help you do adhoc shell execution in AWS Lambda functions, “edgy” helps you simplify writing tests for Node.js based AWS CloudFront Lambda@Edge functions, “cdk-app-cli” a really nice cli that every AWS CDK user should know about, “Accumulus” a great looking reporting tool for AWS Lambda users, “sqldef-gitops-cdk” is a schema management for several open source databases, “log-hub” helps you to build your own log analytics tool using OpenSearch, “verifiable-controls-evidence-store” a very cool solution that builds a mechanism to centrally store findings and results of cloud security controls governing AWS workloads, and many more! These should keep you all very busy.
On top of that, we feature this week content covering Flutter, MySQL, Open Data, Amazon EMR, CentOS Linux, Rocky Linux, SUSE, PostgreSQL, Redis, Apache Cassandra, Quarkus, GROMACS, AWS ParallelCluster, Open Policy Agent and more, and this weeks videos cover AWS SAM and AWS CDK so make sure you check those out too.
We have events coming up, and I just want to give a plug for my colleagues webinar on the 16th, Machine Learning at scale using Kubeflow with Amazon EKS and Amazon EFS. Very cool demo, so put that in your diary if you are free.
As always, please get in touch if you have any news, projects, events that you would like me to include in this newsletter. I am always looking for the most interesting, unique, novel content to feature, so look forward to hearing from you.
Celebrating open source contributors
The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.
So thank you to the following open source heroes: Taylan Unal, Rucha Deshpande, Santhan Pamulapati, Sean Smith, Nathants, Peter Mescalchin, Marcia Villalba, Laimonas Sutkus, Hantzley Tauckoor, Calvin Ngo, Vinicius Senger, Sami Imseih, Yahav Biran, Rohit Satyanarayana, Hemalatha Katari, Vadim Lyakhovich, Ram Pathangi, Parth Patel, Ashok Padmanabhan, Bret Pontillo, and Gaurav Gundal.
Latest open source projects
The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.
Tools
aws-exec
aws-exec this project from nathants, enables you to do adhoc shell execution in AWS Lambda functions. Check out the documentation around use cases and how this works, but this looks like it might be pretty handy.
edgy
edgy Peter Mescalchin has put together this tool that helps you author tests for Node.js based AWS CloudFront Lambda@Edge functions. Edgy provides four core constructors, which directly relate to each of the four life cycle points available in a CloudFront request. In Peters own words:
Been doing a bit of work recently with CloudFront using Lambda@Edge functions under Node.js, to the point I really needed some half decent unit tests written - so I’ve put together an npm package harness to help write those tests.
Package helps craft Lambda@Edge event payloads for the four available request points, execute those payloads against given functions and returns the result to allow for test assertions. Edgy also does its own semi-extensive validation of function results returned to (at some level) validate it would pass as a valid/expected CloudFront response.
If you find this helpful, make sure you let Peter know.
Accumulus
Accumulus this project is a web application that provides comprehensive charts for direct comparison of functions while presenting bottlenecks and potential areas for resource allocation adjustments. In the post, Meet Accumulus — A Tool to Simplify Your AWS Lambda View, Eric Wu provides more details and shows you how to get started. Looks really nice, so check this one out.
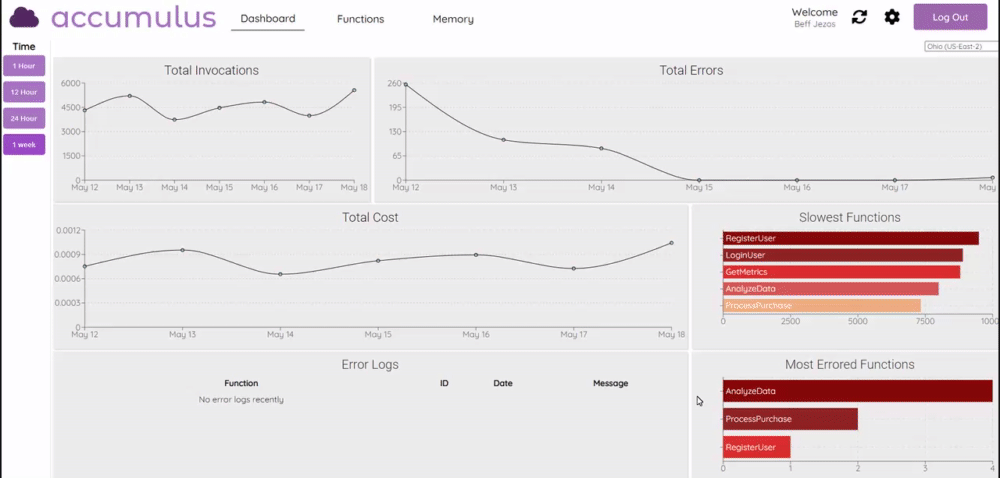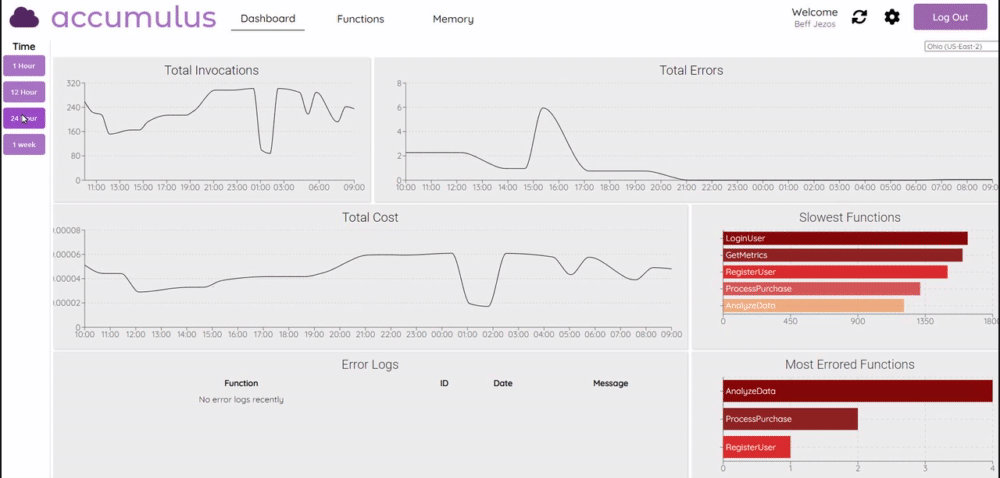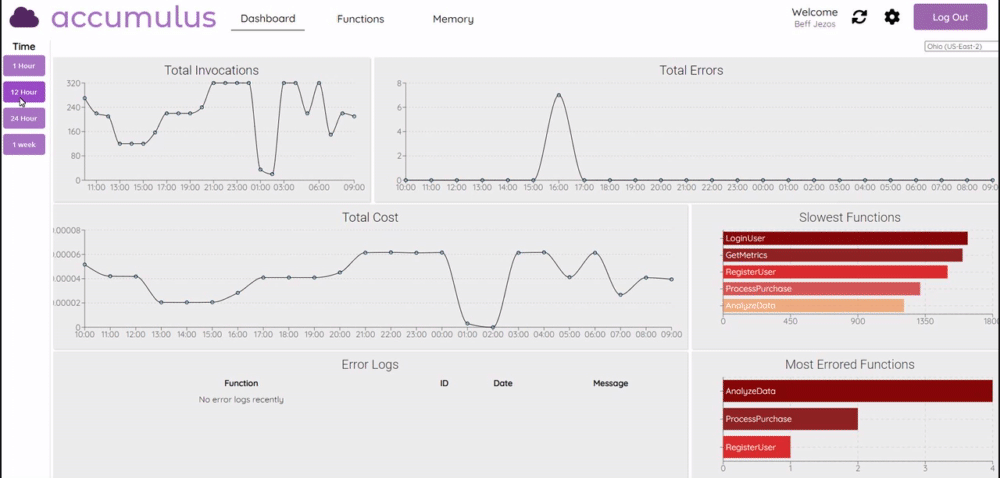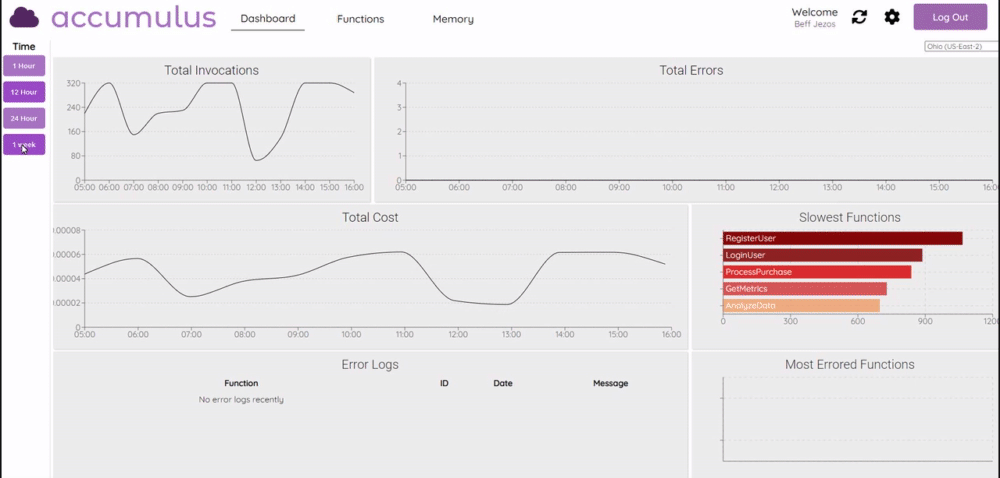
cdk-app-cli
cdk-app-cli this is a new experimental operator CLI for CDK apps. cdk-app lets you associate commands with CDK constructs so that you can quickly invoke functions, redrive queues, visit resources in the AWS console, and more by just referencing the construct name. For example, “cdk-app MyLambda tail-logs” streams logs in real time from the Lambda’s log group, or “cdk-app TransactionTable visit-console” opens the AWS console page for your table.
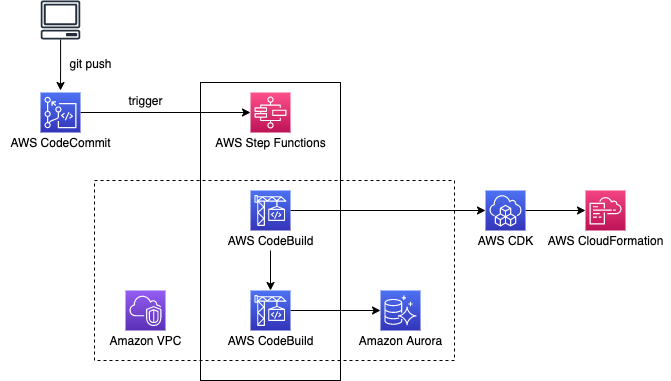
sqldef-gitops-cdk
sqldef-gitops-cdk sqldef is an open source idempotent schema management for MySQL, PostgreSQL, and others. This repo provides a GitOps approach using AWS CDK of how you can approach database table migration.
aws-emr-utilities
aws-emr-utilities is a repository that contains sample code and utilities for using Amazon EMR on EC2. This package is structured around applications (application specific patches, plugins, etc) and utilities (administrative and maintenance utilities for working with EMR)
log-hub
log-hub this repo will help you quickly build your own log analytics platform on OpenSearch. Has detailed documentation including how to get started. Check out the accompanying log-hub-workshop if this is something you like the look of.

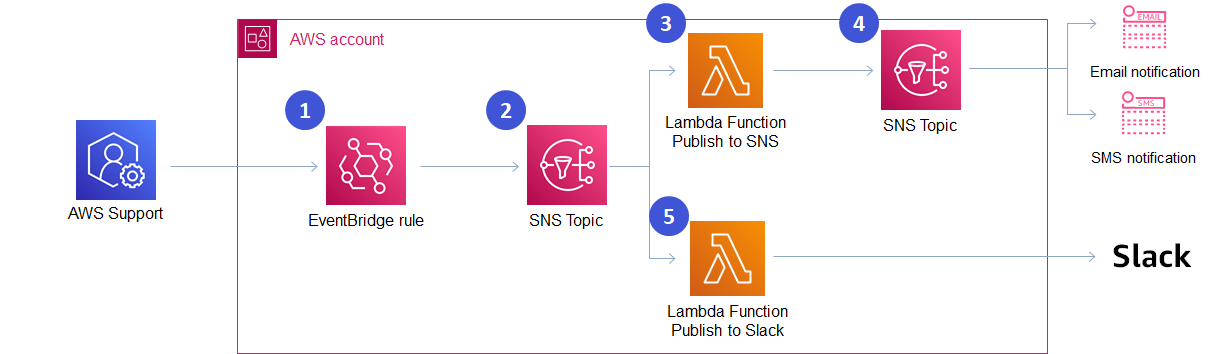
aws-support-case-activity-notifier
aws-support-case-activity-notifier this repo provide a base project that will help you automate your AWS support cases. The repo contains some additional notes as to what you might need to do to productionise this.
Demos, Samples, Solutions and Workshops
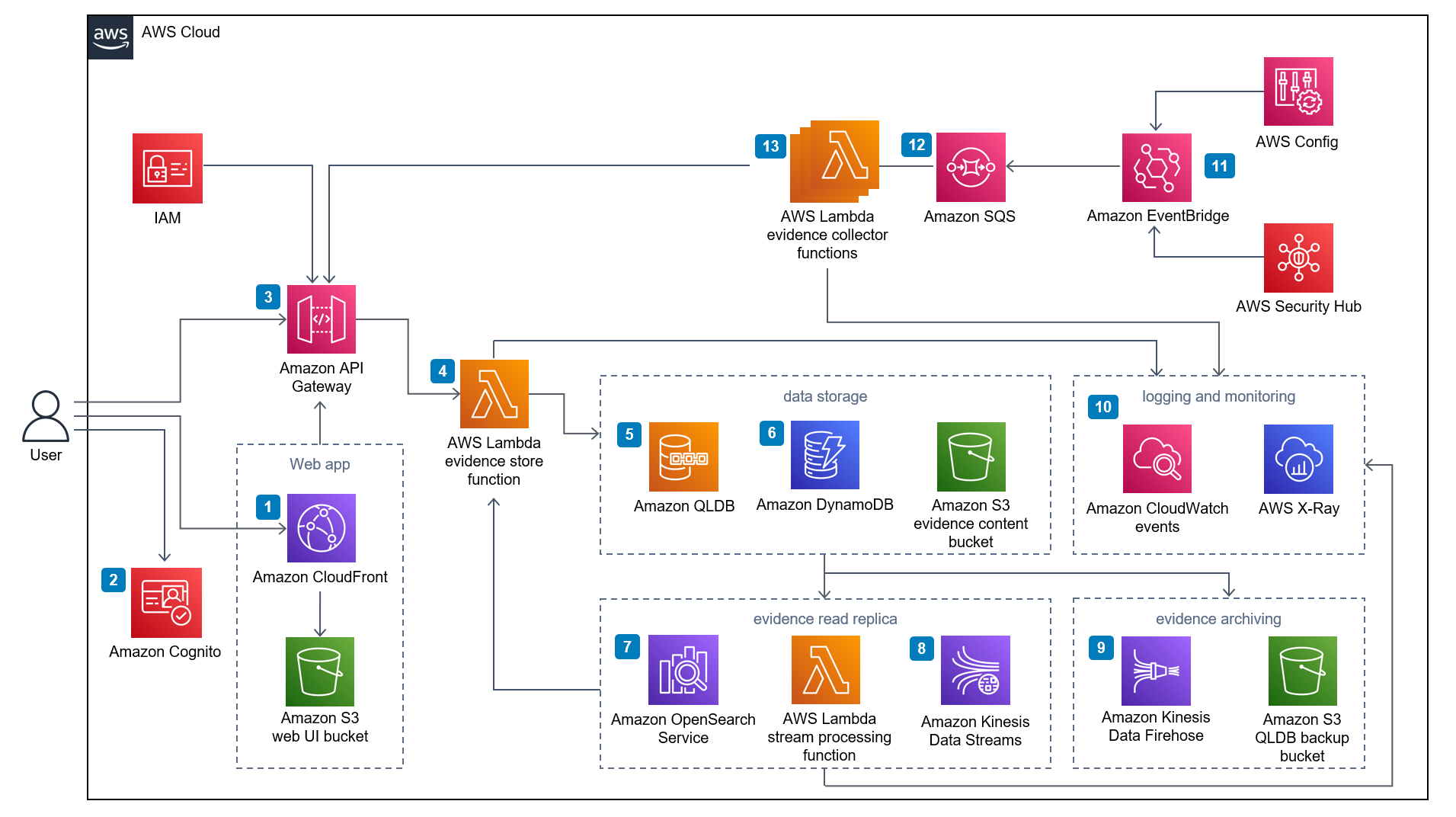
verifiable-controls-evidence-store
verifiable-controls-evidence-store this repo provides everything you need to build The Verifiable Controls Evidence Store (Evidence Store). This solution is a mechanism to centrally store findings and results of cloud security controls governing AWS workloads, in the form of enduring evidence records that are safeguarded against tampering. An evidence record is a system (or human) generated digital record of a historical fact, related to one or more target entities, and is issued by an evidence provider. The solution comes with a RESTful interface with CRUD APIs, as well as a web interface for managing evidences and evidence providers' resources. Very nice indeed.
hive-emr-on-eks
hive-emr-on-eks this repo contains a number of sample configurations and deployments packaged up as AWS CDK apps that show you how you can use Amazon RDS as your Hive metastore.

aws-name-pronunciation
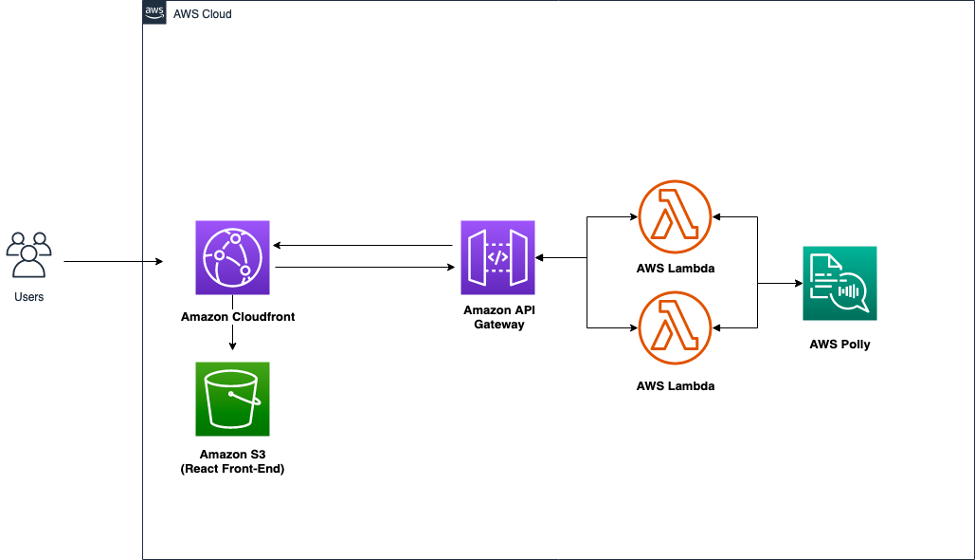
aws-name-pronunciation sample React based application that will allow you to use Amazon Polly to speak different names so you can learn how to pronounce them.
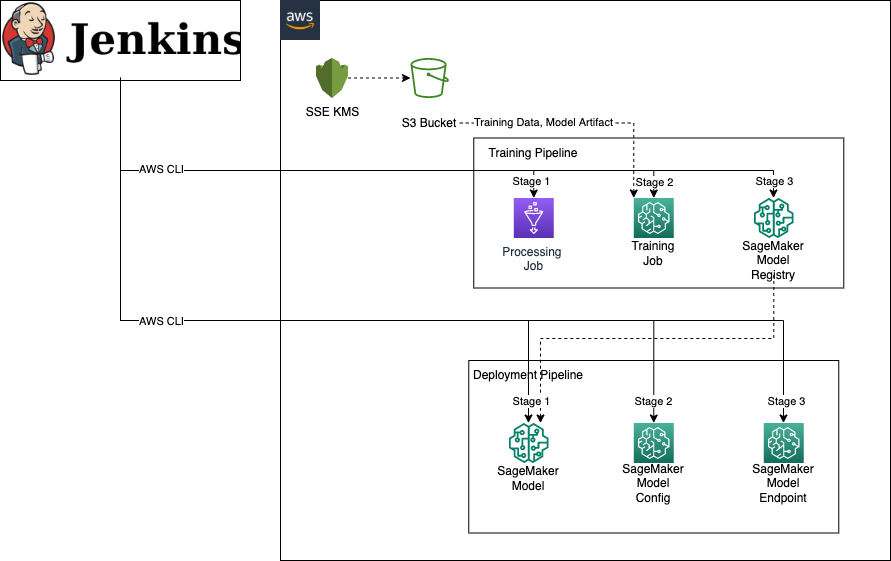
aws-mlops-jenkins-pipelines
aws-mlops-jenkins-pipelines this repository builds an implementation of a CI/CD ML pipeline using AWS Glue for data processing, Amazon SageMaker for training, versioning, and hosting Real-Time endpoints, and Jenkins CI/CD pipelines for orchestrating the Workflow.
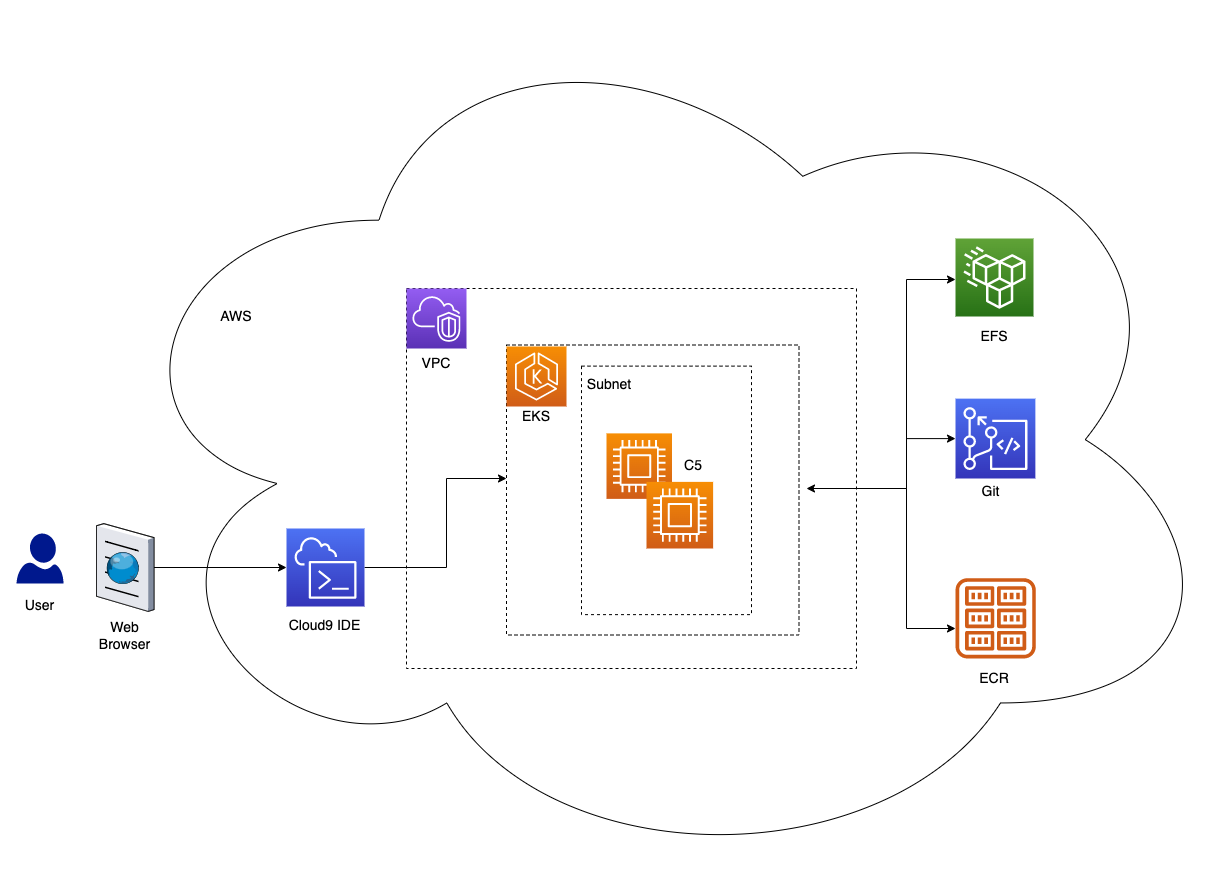
aws-distributed-training-workshop-eks
aws-distributed-training-workshop-eks by completing this workshop you will learn how to run distributed data parallel model training on AWS EKS using PyTorch. The only prerequisite for this workshop is access to an AWS account.
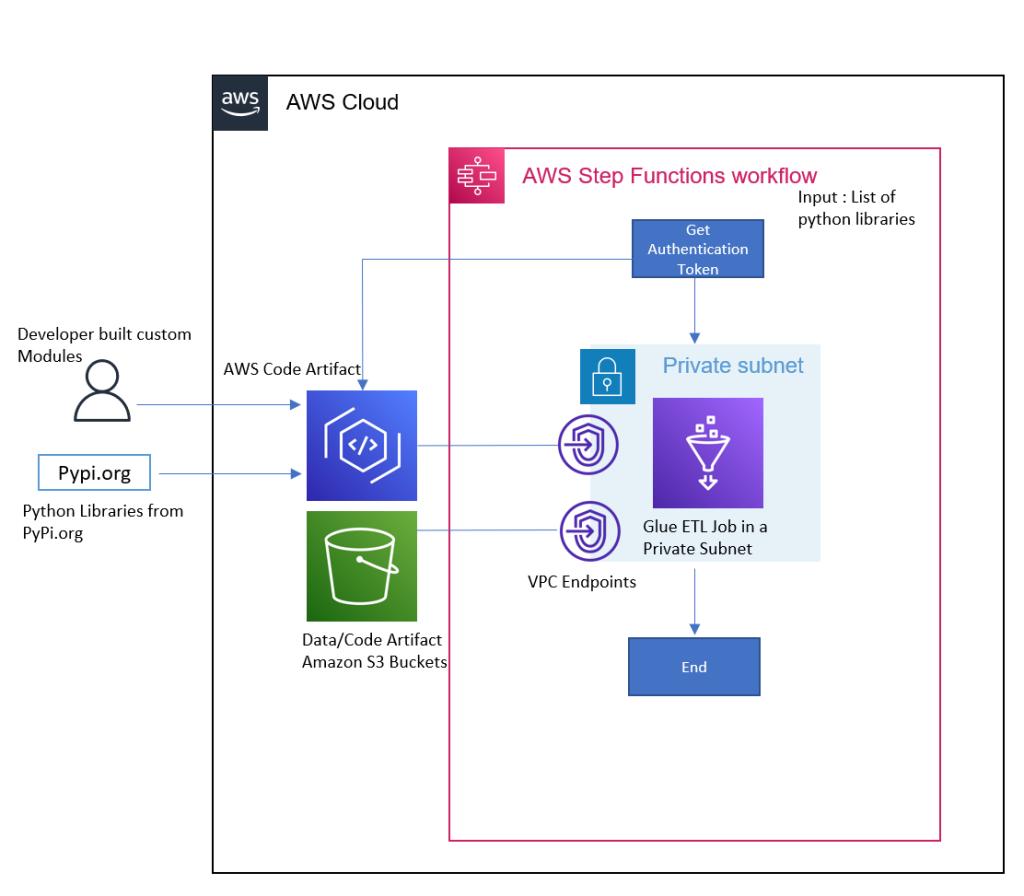
python-lib-management-without-internet-for-aws-glue-in-private-subnets
python-lib-management-without-internet-for-aws-glue-in-private-subnets winner of this weeks longest github repo name, this project contains a CDK app in Python that will show you how to configure AWS Glue in private subnets access to downloading your Python libraries via AWS CodeArtifact. This could be re-used for other AWS Services that you might need to have controlled access to your Python libraries too. To help get you going, read this blog post Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact from Ashok Padmanabhan, Bret Pontillo, and Gaurav Gundal who will guide you through deploying this solution.
AWS and Community blog posts
Open Policy Agent
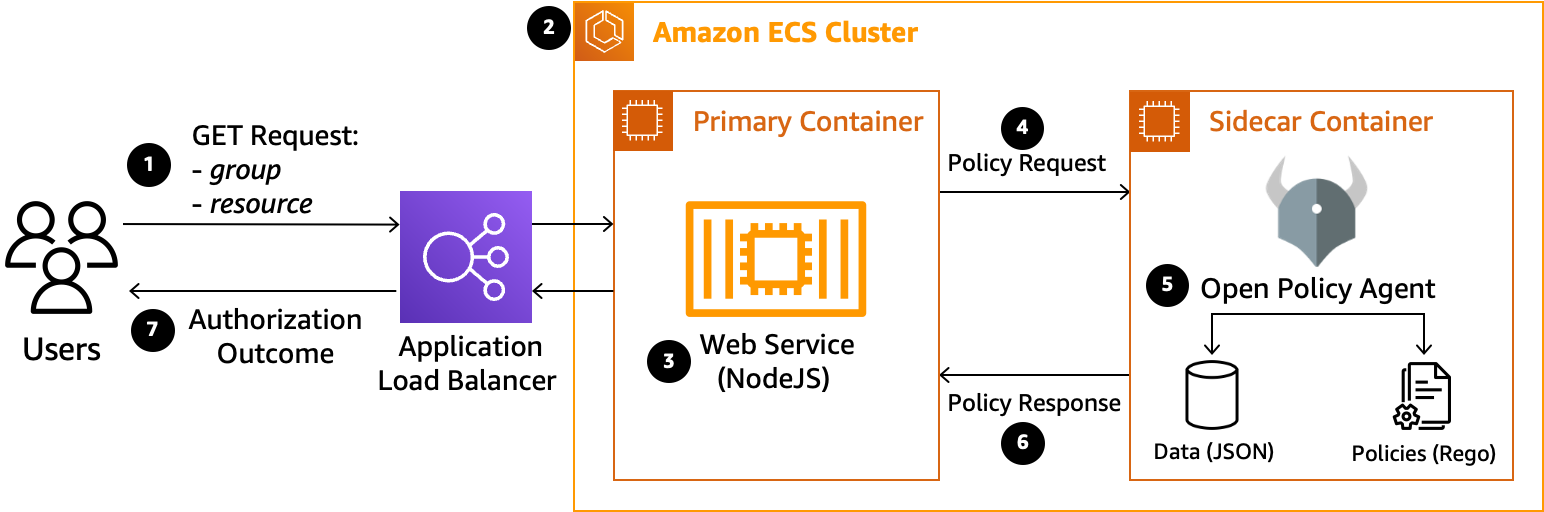
Open Policy Agent (OPA) is an open source, general-purpose policy engine that lets you specify policy as code and provides simple APIs to offload policy decision-making from your applications. In this post, Deploying Open Policy Agent (OPA) as a sidecar on Amazon Elastic Container Service (Amazon ECS) Taylan Unal and Rucha Deshpande show how Open Policy Agent (OPA) can be deployed in a sidecar pattern to provide authorisation decisions for microservices deployed on Amazon Elastic Container Service (Amazon ECS). [hands on]
Quarkus
My colleague Vinicius Senger has put together this excellent post, Cooking Java with Alexa — Ep 1 which is the first in a series of posts that will share how to create from scratch a Modern Java Application using Quarkus. What I really love about this, as a bonus, Vini is going to share how to put together some nutritious and tasty food (in this case, a Sunomono Salad) for those parts of the walkthrough where you might have to wait.
Redis
In the post, Deploy Amazon ElastiCache for Redis using AWS CDK Hantzley Tauckoor and Calvin Ngo show you how you can deploy Amazon ElastiCache for Redis using AWS Cloud Development Kit (AWS CDK). The post then shows you how you can easily integrate this, using a Python Flask application to demonstrate this. There is a GitHub repository that accompanies the post which you can use as the basis for your own needs. [hands on]
PostgreSQL
The post Reduce read I/O cost of your Amazon Aurora PostgreSQL database with range partitioning demonstrates how to use PostgreSQL native partitioning to reduce I/O costs and increase read and write throughput with in-place partitioning that requires minimal downtime. Sami Imseih and Yahav Biran demonstrates a production-scale system that partitions a time series table database with over a hundred columns and relationships. The end result? I won’t spoil the ending, but a significant cost reduction can be seen, so one to check out. [hands on]
Apache Cassandra
If you wanted to know how you could ingest customer data from Amazon Keyspaces (for Apache Cassandra) into SageMaker and train a clustering model, then you are in luck. In the post, Train machine learning models using Amazon Keyspaces as a data source, Vadim Lyakhovich, Ram Pathangi, and Parth Patel show you how you can do this, using a specific use case around segmenting customers. [hands on]
Database Migration Service
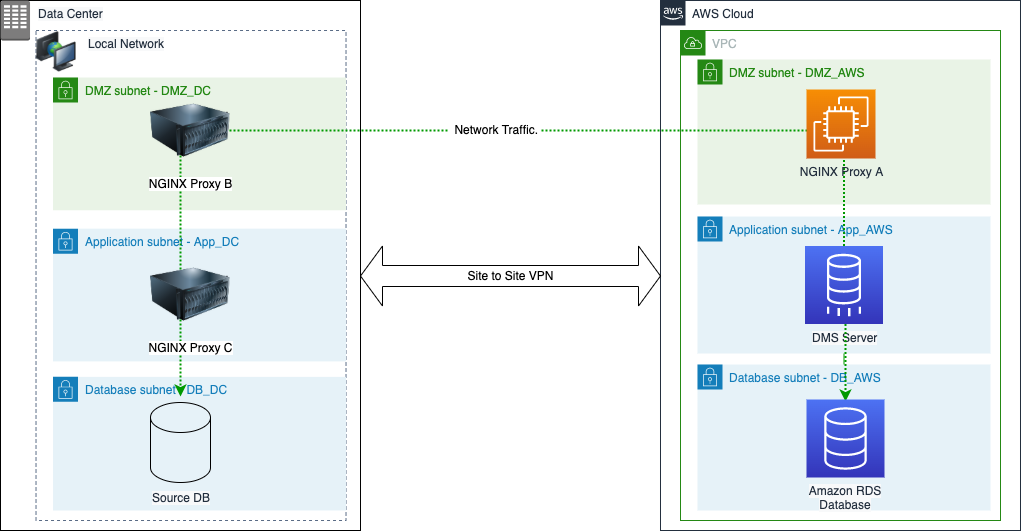
Many customers are using AWS Database Migration service to help them move from proprietary databases to open source ones. In scenarios where you might have strict network controls in place, this might have proven more complex to set up. In this post, Deploy AWS DMS in a multi-tiered secure network using an Nginx proxy server, Rohit Satyanarayana and Hemalatha Katari share how you can use the open source web and proxy server Nginx, to help meet your network isolation and security requirements. [hands on]
GROMACS
GROMACS is a popular open-source software package designed for simulations of proteins, lipids, and nucleic acids. In this post, Running cost-effective GROMACS simulations using Amazon EC2 Spot Instances with AWS ParallelCluster Santhan Pamulapati and Sean Smith collaborate to show how by combining GROMACS features with Spot pricing and scheduling with Slurm (a workload manager/job scheduler), you can architect a cost-effective solution for running GROMACS simulations. In this post they show you how they built a solution with GROMACS installed on AWS ParallelCluster. [hands on]
Other posts you might like from the past week
- Validate database objects after migrating from IBM Db2 LUW to Amazon RDS for MySQL, Amazon RDS for MariaDB, or Amazon Aurora MySQL walks you through how to validate the database schema objects migrated from Db2 to MySQL [hands on]
- AWS MGN Update – Configure DR, Convert CentOS Linux to Rocky Linux, and Convert SUSE Linux Subscription shows you how you can use the AWS Application Migration Service (AWS MGN) to migrate CentOS Linux to Rocky Linux and manage your SUSE Subscriptions
- 8 New features in the Amplify Authenticator for web you should try walks you through some new features recently released for the Amplify Authenticator for React, Vue, and Angular
Case studies
- Amazon EKS and Spot Instances in action at Delivery Hero share how Delivery Hero is using Amazon EKS and Amazon EC2 Spot Instances in production to keep costs under control

- Using open data to study the sounds of the ocean and create art explores a creative use case for some of the data you can find in the AWS open data registery

Quick updates
Amazon EMR
Amazon EMR release 6.6 now supports Apache Spark 3.2, Apache Spark RAPIDS 22.02, CUDA 11, Apache Hudi 0.10.1, Apache Iceberg 0.13, Trino 0.367, and PrestoDB 0.267. You can use the performance-optimized version of Apache Spark 3.2 on EMR on EC2, EKS, and recently released EMR Serverless. In addition Apache Hudi 0.10.1 and Apache Iceberg 0.13 are available on EC2, EKS, and Serverless. Apache Hive 3.1.2 is available on EMR on EC2 and EMR Serverless. Trino 0.367 and PrestoDB 0.267 are only available on EMR on EC2.
Each Amazon EMR release version uses a default Amazon Linux 2 (AL2) Amazon Machine Image (AMI) for Amazon EMR. Prior to Amazon EMR 6.6, the default AMI was based on the latest and up-to-date Amazon Linux AMI available at the time of the Amazon EMR release. Therefore, the Amazon EMR release version was “locked” to its respective assigned AL2 AMI. This means that any new updates to AL2 were not automatically updated, unless you moved to the next Amazon EMR release or manually install them. With Amazon EMR 6.6 and subsequent releases, every time you launch an EMR on EC2 cluster, Amazon EMR automatically uses the latest AL2 release. See our documentation to learn more.
With Amazon EMR release 6.6 and later, applications that use Log4j 1.x and Log4j 2.x will be upgraded to use Log4j 1.2.17 (or higher) and Log4j 2.17.1 (or higher) respectively, and will not require using the bootstrap actions provided above to mitigate the CVE issues.
Further, with Amazon EMR release 6.6, cluster startup time on EMR on EC2 has improved by 80 seconds on average for clusters that use Amazon EMR default AMI option, and install common applications like Apache Hadoop, Apache Spark, and Apache Hive.
MySQL
Following the announcement of updates in MySQL database versions 5.7 and 8.0, we have updated Amazon Relational Database Service (Amazon RDS) for MySQL to support MySQL minor versions 5.7.38, and 8.0.29.
Flutter
The Amplify Flutter team is announcing the release of version 0.5.0 of the Amplify Flutter library. Read more about this in the post, NEW Amplify Flutter Release Notes 0.5.0
In addition to this post, AWS Amplify Flutter has introduced support for creating customisable authentication flows, using Amazon Cognito Lambda triggers. Using this functionality, developers are able to setup customisations for the login experience in their Flutter apps, such as creating OTP login flows, or adding CAPTCHA to their Flutter app.
Developers of Amplify Flutter can setup the Auth category to use custom challenges using the Amplify CLI such as one-time passwords, or Captcha. The Amplify CLI provisions Lambdas in the backend, which then interact with Amazon Cognito to verify the challenges. Developers can build the custom challenges are built in steps, such as providing a one-time password after using an email for login, and a user of the app will have to clear each step in the challenges to get authenticated.
Steampipe
Steampipe is an open source tool where you can use SQL to instantly query your cloud services. Via a collection of “mods” you can do various things, such as compliance checks. NIST 800-53 is a regulatory standard that defines the minimum baseline of security controls for all U.S. federal information systems except those related to national security. A new release, NIST 800-53 Revision 5 was published last week.
Videos of the week
AWS SAM
You can use the Node.js runtime to run TypeScript code in AWS Lambda. Because Node.js doesn’t run TypeScript code natively, you must first transpile your TypeScript code into JavaScript. Then, use the JavaScript files to deploy your function code to Lambda. In this video, Marcia Villalba shows you how to do that using AWS SAM.
AWS CDK
Laimonas Sutkus provides the follow up to a previous video I shared, this is part 2 of the AWS CDK “from zero to hero” workshop. In this episode, expect to find out more about writing integration tests, creating GitHub repo and pushing code and creating CI/CD pipelines.
Events for your diary
Machine Learning at scale using Kubeflow with Amazon EKS and Amazon EFS June 16th, 10am PT
My colleague Suman Debnath, Principal Developer Advocate at AWS, will discuss how to use the open-source machine learning toolkit Kubeflow. Suman will demonstrate how to deploy Kubernetes cluster utilising Amazon Elastic Kubernetes Service (EKS) and Amazon Elastic File System (EFS) as persistent storage in the backend, which will be utilised for staging the dataset for training, hosting jupyter notebooks, and running the machine learning model.
Find out more and register, Machine Learning at scale using Kubeflow with Amazon EKS and Amazon EFS
Observability: Open Source Solutions June 28th, 10:00am - 2:15pm PDT
The AWS Monitoring and Observability Team invites you to participate in a hands on session with Amazon Managed Service for Prometheus, Amazon Managed Service for Grafana and AWS Distro for Open Telemetry. During this session you will use these services in creating workspaces, ingesting/querying metrics, logs and trace data and viewing in a dashboard you will set up. The afternoon will close with demo of what you have done and highlighting the value in MTTD, MTTI, MTTR and application performance.
This event is designed for those looking to implement AWS Observability using open-source services to visualize their data with native or 3rd party tools. Site reliability engineers, operations engineers, systems engineers, and DevOps. Familiarity with monitoring concepts such as logs, metrics, traces, alarms, and the dashboard is recommended, but not required.
Register via this page.
BOSC 2022 July 13-14, Madison, Wisconsin, USA
The Bioinformatics Open Source Conference (BOSC) has been held annually since 2000, and this year AWS is proud to be a platinum sponsor for this event. BOSC covers all aspects of open source bioinformatics software and open science, including (but not limited to) these topics, Open Science and Reproducible Research, Open Biomedical Data, Citizen/Participatory Science, Standards and Interoperability, Data Science Workflows, Open Approaches to Translational Bioinformatics, Developer Tools and Libraries, Inclusion, and Outreach and Training. This is a hybrid event (in person/virtual) and you find out more by checking out the event page, BOSC 2022
OpenSearch Every other Tuesday, 3pm GMT
This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.
Sign up to the next session, OpenSearch Community Meeting
OpenSearchCon 2022 Sept 21st, 2022 Seattle
Come to the first annual OpenSearchCon!
This day-long conference will be packed with presenters who build and innovate with OpenSearch. It doesn’t matter if you’re just getting started on your OpenSearch journey, running giant clusters, or contributing tons of code; the event is for everyone. Join us to celebrate the progress and look into the future of the project. Admission is free, and registration will be open in the next few weeks. All you will need to do is sign up, and get to Seattle!
Check out the full details, including signing up and location, at the meetup page here.
Stay in touch with open source at AWS
I hope this summary has been useful. Remember to check out the Open Source homepage to keep up to date with all our activity in open source by following us on @AWSOpen