Automating your ELT Workflows with Managed Workflows for Apache Airflow - Part One
Published Apr 21, 2021
Reading time 18 minutes
update: I have changed the post to use standard Apache Airflow variables rather than using AWS Secrets Manager.
Part One - Automating Amazon Athena
As part of an upcoming DevDay event, I have been working on how you can use Apache Airflow to help automate your Extract, Load and Transform (ELT) Workflows. Amazon Athena and Amazon EMR are two AWS services that help customers who have existing SQL skills/expertise and are looking at tools such as Presto or Apache Hive when undertaking those transformations.
This is a two part post, in this post I focus on Amazon Athena, and in Part Two, I look at Amazon EMR, Apache Hive and Presto.
In this post I want to share how you can use open source tools like Apache Airflow to automate the manual steps your developers might run when using tools like Presto or Apache Hive. If you want to learn more about Apache Airflow, then head over to the project’s website at https://airflow.apache.org.
I guess a good question to ask is Why, Why do we need to automate these tasks? Here are some of the things that come to mind (this is not intended to be a comprehensive list but some of the reasons that for me, make sense):
- the ability to reproduce and repurpose the work these developers create so that it can be run when and at scale
- so you can separate the development of the code to the running of it
- reducing the time it takes to get value from your data by enabling code to be run on demand, for example being triggered when a new data payload is received
- adopting of modern development practices such as creation of data pipelines that check your code into source code, validate/test it and then deploy it automatically
There are probably many more, but the outcome is the same - automating those pesky manual tasks is a good thing, and Apache Airflow is our friend here.
Scenarios
In this post I will use two simple scenarios that are typical in many organisations looking at putting data in the hands of their builders. Imagine you have been asked to do any of the following:
- Create some new tables from data in your data lake, which is going to be used by the data visualisation and reporting team to create some dashboards and graphs from that data.
- Create some new data files in the data lake the data scientists need as they want to experiment and create new machine learning models.
The persona that has been asked to do this will have database expertise, with a good understanding of SQL and looking to leverage that as part of the solution.
You will find all the code for this demo at my repo location here
I will not cover the manual steps that we will automate as they are detailed in the GitHub repo. The key takeaways from reading this post will (hopefully) be a clearer understanding of how you can automate the tasks you do in Amazon Athena and Amazon EMR using Apache Airflow. This should give you a good understanding of how to approach automating your own tasks.
Setup
I am going to setup and use Managed Workflows for Apache Airflow (MWAA). I have documented in the past how to get this up and running in these blog posts, Automating the installation and configuration of Amazon Managed Workflows for Apache Airflow and I will be using a CI/CD setup that I shared how to setup in, A simple CI/CD system for your Amazon Managed Workflows for Apache Airflow development workflow. This setup gives me a super easy way to author my Apache Airflow workflows from my local IDE (Visual Studio Code as you asked so nicely:-) and then push this to a git repository and then deployed onto MWAA.
There were a number of things I did need to do however, before I could automate these workflows.
Storing variables
I wanted to use Apache Airflow’s ability to store variables so that I didn’t have to hardcode my workflows (DAGs) so before creating these workflows, I created the following variables using the Apache Airflow UI.
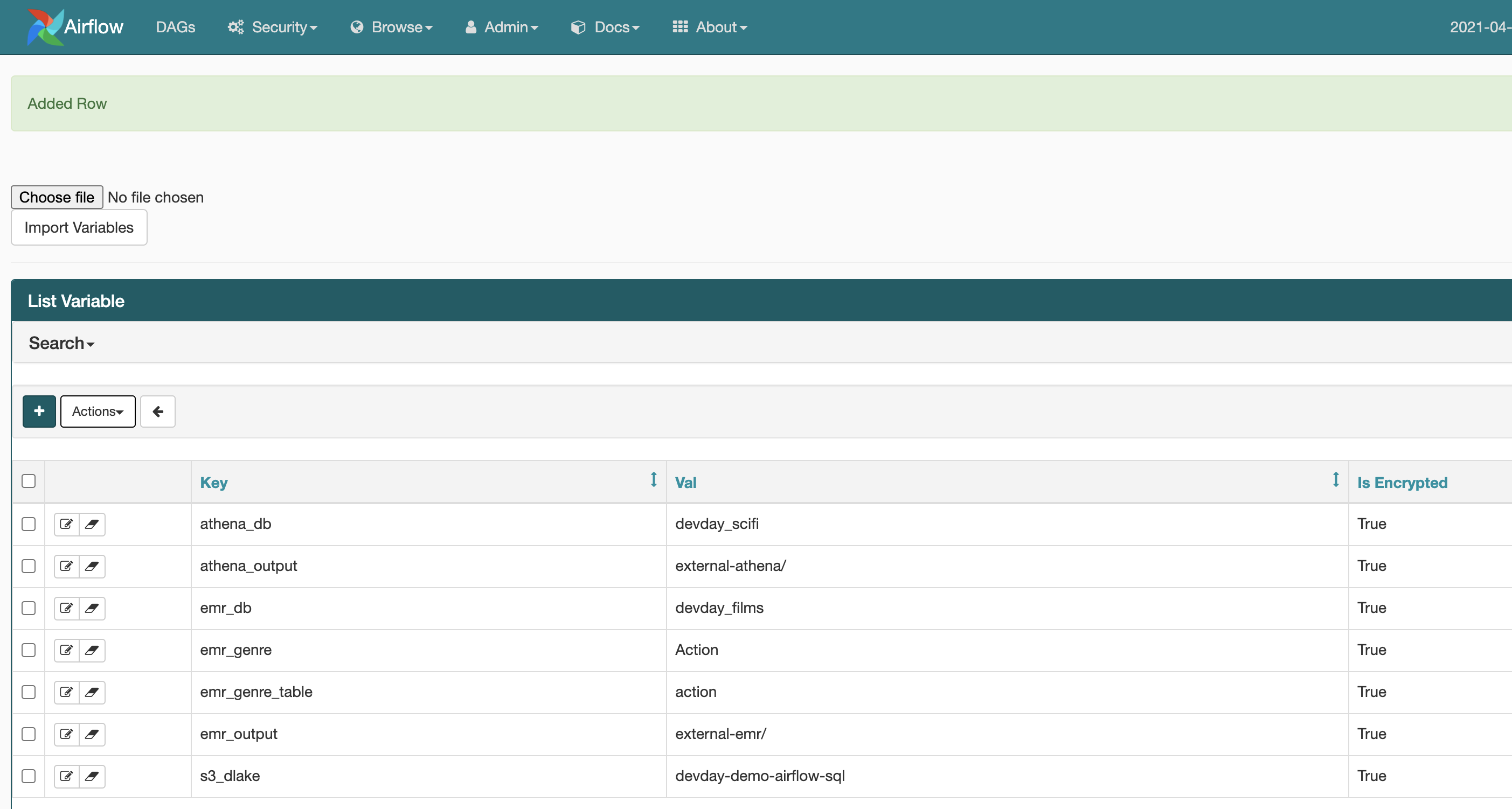
Permissions
From a permissions perspective I did have to make a couple of changes:
- I needed to increase the scope of the permissions that the MWAA execution role had within the Amazon S3 buckets. I do not provide a blanket access, so needed to add a few more resources. If you get any Access Denied errors, then make sure you have the right permissions
- I needed to add new permissions to allow the MWAA worker nodes to kick off and then terminate jobs on Amazon EMR. I scoped down the permissions to the minimum needed for the worker nodes to execute the workflows. I use the default policies when using Amazon EMR (EMR_DefaultRole and EC2_DefaultRole, so change yours as needed):
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ssm:GetParameter"
],
"Resource": "arn:aws:ssm:*: XXXXXXXXXXXX:parameter/*"
},
{
"Effect": "Allow",
"Action": [
"elasticmapreduce:DescribeStep",
"elasticmapreduce:AddJobFlowSteps",
"elasticmapreduce:RunJobFlow",
"elasticmapreduce:TerminateJobFlows"
],
"Resource": "arn:aws:elasticmapreduce:*: XXXXXXXXXXXX:cluster/*"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": [
"arn:aws:iam::XXXXXXXXXXXX:role/EC2_DefaultRole",
"arn:aws:iam::XXXXXXXXXXXX:role/EMR_DefaultRole"
]
}
]
}
- I needed to add new permissions to allow the MWAA worker nodes to access Amazon Athena, which required creating a new policy to scope down access to only what it needed. I used this page of the Amazon Athena documentation to help me scope what I needed - Fine-Grained Access to Databases and Tables in the AWS Glue Data Catalog. This is the one I used during my demo (the Amazon S3 bucket I was using as my data lake was devday-demo-airflow-sql, and the initial database in Amazon Athena was called Movielens. I set a prefix for all new Athena resources to be devday*. You might want to experiment further locking these permissions down if you want more control.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"athena:*"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"glue:CreateDatabase",
"glue:DeleteDatabase",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:UpdateDatabase",
"glue:CreateTable",
"glue:DeleteTable",
"glue:BatchDeleteTable",
"glue:UpdateTable",
"glue:GetTable",
"glue:GetTables",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:DeletePartition",
"glue:BatchDeletePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition"
],
"Resource": [
"arn:aws:glue:*:XXXXXXXXXXXX:catalog",
"arn:aws:glue:*:XXXXXXXXXXXX:database/default",
"arn:aws:glue:*:XXXXXXXXXXXX:database/movielens",
"arn:aws:glue:*:XXXXXXXXXXXX:database/devday-*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:ListMultipartUploadParts",
"s3:AbortMultipartUpload",
"s3:CreateBucket",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::aws-athena-query-results-*",
"arn:aws:s3:::devday-demo-airflow-sql",
"arn:aws:s3:::devday-demo-airflow-sql/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::devday-demo-airflow-sql",
"arn:aws:s3:::devday-demo-airflow-sql/*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListAllMyBuckets"
],
"Resource": [
"arn:aws:s3:::devday-demo-airflow-sql",
"arn:aws:s3:::devday-demo-airflow-sql/*"
]
},
{
"Effect": "Allow",
"Action": [
"sns:ListTopics",
"sns:GetTopicAttributes"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricAlarm",
"cloudwatch:DescribeAlarms",
"cloudwatch:DeleteAlarms"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": [
"*"
]
}
]
}
- As I am using AWS Secrets Managers to hold variables, I needed to allow the MWAA worker nodes permissions, so using the standard SecretsManagerReadWrite policy
This is what the environment looks like - it is an approximation but hopefully lets you see visually all the moving parts.

Automating Amazon Athena
To recap: We are using the Movielens dataset, loaded it into our data lake on Amazon S3 and we have been asked to a) create a new table with a subset of the information we care about, in this instance a particular genre of films, and b) create a new file with the same subset of information available in the data lake.
As part of the set of manual steps we are trying to automate, we are creating Athena databases as well as creating tables and export files. As we are automating this, a lot of the stuff we would not need to do because we absorb that as part of the manual work (for example, I already have a database called XX, so I do not need to re-create that) we need to build into the workflow. So at a high level the steps look like:
- Check to see if a database exists and create it if it does not exist
- Create tables to import the movie and ratings data
- Create a new table that just contains the information we are looking for (in this example, films of a particular genre)
- Export the new table as a csv file, checking first to see if any old data exists and clearing it
- Move the export csv file to a new location in the data lake
For this blog post, it doesn’t really matter whether these are the best steps to achieve the task. Any task you set out to do will have a set of steps, with logic and conditions you need to think about, and interactions with external systems and data. So how do we go from that set of steps to a workflow?
In Apache Airflow, you write your automation as a Directed Acylic Graph (or simply DAG) file, which is a file written in Python where you import Apache Airflow operators (either out of the box ones, third party open source or you can create your own) together with your own helper libraries. There are lots of tutorials and getting started guides that will help you understand more, and the one on the Apache Airflow documentation site is pretty good.
When using Apache Airflow to automate tasks with Amazon Athena we can use the Amazon Athena operator which makes it super easy to submit queries as all we need to do is pass a query to the operator and it will take care of the rest.
All we need to do is import the Python libraries and Apache Airflow operators we want to use. Here is my starting DAG code, importing the Apache Airflow operators I think I am going to use, as well as some addition Python libraries which I need as part of my code. How you know which ones to use will be determined by what you are trying to achieve in your tasks, although there are some typical ones you will tend to see in many workflows (for example, PythonOperator or DAG)
from airflow import DAG, settings, secrets
from airflow.models import Variable
from airflow.utils.trigger_rule import TriggerRule
from airflow.utils.dates import days_ago
from airflow.operators.python_operator import PythonOperator, BranchPythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.contrib.operators.aws_athena_operator import AWSAthenaOperator
import os
import sys
import boto3
import time
Note! As I am using MWAA, I know these libraries are already available to me. If you are using your own instance of Apache Airflow, you will need to make sure these libraries are installed (pip install…)
Apache Airflow operators use a number of arguments, and so to reduce the amount of code we need to write, we can specify these in a section called “default_args” which will be used by each operator we define in our workflow. In our workflow we do not need to set any default arguments other then the typical defaults, so we can use the following.
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1
}
Next up we need to create a DAG object in which our tasks will live. There are a number of ways you can do this, so explore the different options. I am keeping it simple here for the purposes of explaining this workflow.
When creating the DAG object that will represent our workflow, we set things like a name (you can use a string if you wanted, but here I am just assigning the filename to keep things simple), selecting the default_args which we just defined in the previous step, provide a description and then do a few other things. In the schedule, we can define how and when we want this workflow to run - you can think of this like a crontab. In this post I do not want to schedule this and just run it on demand, so I select None. If I wanted to run this daily, I might select @daily or @hourly - check the documentation to find out more. Finally, I can assign tags to the workflow so they are easy to find/search for.
DAG_ID = os.path.basename(__file__).replace('.py', '')
dag = DAG(
dag_id=DAG_ID,
default_args=default_args,
description='DevDay Athena export SciFi DAG',
schedule_interval=None,
start_date=days_ago(2),
tags=['devday','demo'],
)
Next we define some variables, and grab the values from AWS Secrets Manager. I am defining these three variables (assigning the value of “undefined” if it cannot grab the value):
- s3_dlake - is the location of my Amazon S3 data lake
- athena_db - is the name of the database we will create in Amazon Athena
- athena_output - this is the name of the folder under the s3_dlake where Amazon Athena queries are saved, these being generated when we use the Amazon Athena operator.
s3_dlake = Variable.get("s3_dlake", default_var="undefined")
athena_db = Variable.get("athena_db", default_var="undefined")
athena_output = Variable.get("athena_output", default_var="undefined")
Now onto the actual workflow. A workflow is just a series of tasks that are orchestrated. Using the list above, the first task we need to do is create the database. But what if the database already exists (perhaps this is the nth time we are running this workflow)? We need some basic decision making logic in our workflow.
One of the ways we can achieve this is to use an Apache Airflow operator called BranchPythonOperator. We define our steps (check the database/create the database/skip the database creation) so what now. We can create this branch code using that operator as follows:
check_athena_database = BranchPythonOperator(
task_id='check_athena_database',
provide_context=True,
python_callable=check_athena_database,
dag=dag,
)
We give this task a name as well as a task_id which we will use when we come to creating the dependency graph. We want to associate this task with the DAG object we instantiated above, so we use the dag=dag. We use the provide_context=True to enable Apache Airflow to pass keyword arguments in our functions and then we need to point to some code, so we define a function (in this example, it is called check_athena_database). But wait, where is this function?
We need to create it, and importantly, we need to create it before this piece of code. This code is where we will put our logic for testing whether a database exists, and the logic that allows us to return a task within the workflow for either path of our branch.
To check for the existence of the database, I use boto3 and some simple code which will return true if it finds it (the try: loop) and then return “skip_athena_database_creation” and generate an exception (the except: loop) and return “create_athena_database” - we have not created these Apache Airflow tasks yet, so lets do that next.
Before we do that though, you may notice that we use the print statement here to help you log which branch the workflow will take. Any output from tasks will show up when you view logs as the workflow is running. Apache Airflow operators may emit their own information, but you can also add your own. Here is what the logs look like after this task has run:
[2021-04-19 13:30:48,996] {{standard_task_runner.py:78}} INFO - Job 116421: Subtask check_athena_database
[2021-04-19 13:30:49,119] {{logging_mixin.py:112}} INFO - Running %s on host %s <TaskInstance: devday-athena-create.check_athena_database 2021-04-19T13:30:30.821655+00:00 [running]> ip-10-192-21-41.eu-west-1.compute.internal
[2021-04-19 13:30:49,352] {{logging_mixin.py:112}} INFO - No Database Found
[2021-04-19 13:30:49,411] {{python_operator.py:114}} INFO - Done. Returned value was: create_athena_database
[2021-04-19 13:30:49,440] {{skipmixin.py:123}} INFO - Following branch create_athena_database
[2021-04-19 13:30:49,507] {{skipmixin.py:149}} INFO - Skipping tasks ['skip_athena_database_creation']
Back to the code that checks to see whether the Amazon Athena database exists.
def check_athena_database(**kwargs):
ath = boto3.client('athena')
try:
response = ath.get_database(
CatalogName='AwsDataCatalog',
DatabaseName=athena_db
)
print("Database already exists - skip creation")
return "skip_athena_database_creation"
except:
print("No Database Found")
return "create_athena_database"
check_athena_database = BranchPythonOperator(
task_id='check_athena_database',
provide_context=True,
python_callable=check_athena_database,
dag=dag,
)
We create the “skip_athena_database_creation” task first as this is the easiest as there is nothing to do. Here we use the DummyOperator, that does nothing. It is useful when we put these kinds of branches however.
skip_athena_database_creation = DummyOperator(
task_id="skip_athena_database_creation",
trigger_rule=TriggerRule.NONE_FAILED,
dag=dag,
)
You will notice that we have “trigger_rule=TriggerRule.NONE_FAILED”. Trigger Rules are used by Apache Airflow to help you define rules that allow you to control the workflow based on how upstream (previous tasks) have completed in your workflow. The NONE_FAILED means that all previous steps must have been successful or skipped. This is all this task does.
If we look at the “create_athena_database” task code, we can see this is a PythonOperator (rather than the BranchPythonOperator) and calls a python function called “create_db”
create_athena_database = PythonOperator (
task_id='create_athena_database',
provide_context=True,
python_callable=create_db,
dag=dag
)
If we look at the code for “create_db” we can see it is again using boto3 to create the database. In the function we pass in “**kwargs” which allows us to access within the code Apache Airflow arguments, such as variables we have defined and task information. You will also notice that in this code we are accessing the variables we defined earlier. We run this query (the CREATE DATABASE IF NOT EXISTS) with an output location that is “s3://” plus the value of the variable {s3_dlake}. This allows us to create re-usable tasks that are driven by input parameters/variables.
def create_db(**kwargs):
print("Creating the database if it does not exist")
ath = boto3.client('athena')
ath.start_query_execution(
QueryString='CREATE DATABASE IF NOT EXISTS '+ athena_db,
ResultConfiguration={'OutputLocation': 's3://{s3_dlake}/queries/'.format(s3_dlake=s3_dlake)},
WorkGroup="devday-demo"
)
So no we have one final task to create. We have two flow so far - one that is for the creation of the database, and the other is for the skipping of the database. We used the BranchPythonOperator to direct which task to execute. We now need another task that both of these tasks converge towards, and we again use the DummyTask for this.
athena_database_checks_done = DummyOperator(
task_id="athena_database_checks_done",
trigger_rule=TriggerRule.NONE_FAILED,
dag=dag,
)
We now have four tasks in our workflow. The next thing is to create the relationship of these tasks within the workflow. There are a few ways we can do this, but the way we will do it here is to use the “»” to define the relationship.
check_athena_database >> skip_athena_database_creation >> athena_database_checks_done
check_athena_database >> create_athena_database >> athena_database_checks_done
When we save our workflow (DAG) and check it into source control (a reminder I am using my Simple CI/CD setup here) approx 20-30 seconds we will see our workflow appear in the Apache Airflow UI.

So far so good. The next step we want to automate is the population of the movies and ratings tables within this database. For this we can use the AWSAthenaOperator. Before we can use this, we need to define the query we want to run. As we want to create two tables, we need two queries, so our code looks like this:
create_athena_movie_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS {database}.movies (
`movieId` int,
`title` string,
`genres` string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://{s3_dlake}/movielens/movies/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
""".format(database=athena_db, s3_dlake=s3_dlake)
create_athena_ratings_table_query="""
CREATE EXTERNAL TABLE IF NOT EXISTS {database}.ratings (
`userId` int,
`movieId` int,
`rating` int,
`timestamp` bigint
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ',',
'field.delim' = ','
) LOCATION 's3://{s3_dlake}/movielens/ratings/'
TBLPROPERTIES (
'has_encrypted_data'='false',
'skip.header.line.count'='1'
);
""".format(database=athena_db, s3_dlake=s3_dlake)
We have assigned two variables, “create_athena_movie_table_query” and “create_athena_ratings_table_query”. As you can see, we are again using variables so we do not need to hard code the references (the code could be improved by adding more variables for the source data in movielens/* - it is in my backlog!). These queries should look familiar as they are the same ones we ran via the Amazon Athena console.
We now create the task that will create these tables using the AWSAthenaOperator as follows:
create_athena_movie_table = AWSAthenaOperator(
task_id="create_athena_movie_table",
query=create_athena_movie_table_query,
workgroup = "devday-demo",
database=athena_db,
output_location='s3://'+s3_dlake+"/"+athena_output+'create_athena_movie_table'
)
create_athena_ratings_table = AWSAthenaOperator(
task_id="create_athena_movie_ratings",
query=create_athena_ratings_table_query,
workgroup = "devday-demo",
database=athena_db,
output_location='s3://'+s3_dlake+"/"+athena_output+'create_athena_ratings_table'
)
These should begin to look familiar now. Each Operator can have different arguments, and this one requires a “query=” which we point to the variables we defined in the previous step, we define the. Amazon Athena workgroup we want to run this query in, the Amazon Athena database and then the location where the queries will be saved.
Now we have defined these, we need to include them in the actual workflow. We add these to the original so we end up with the following:
check_athena_database >> skip_athena_database_creation >> athena_database_checks_done
check_athena_database >> create_athena_database >> athena_database_checks_done
athena_database_checks_done >> create_athena_movie_table >> create_athena_ratings_table
After committing our code, a few seconds later our workflow now looks like:

I will not repeat for the remaining tasks, as you should have the idea by now. You can check out the full code in the GitHub repository. I did end up breaking this workflow into two workflows, but they could have been combined into a single one. How you decide will be down to what you are trying to automate, whether there are any tasks that make sense to group together (perhaps they might be run more frequently, or need to be run first or in a specific order).
One thing however that I do want to point out is that in the second workflow (devday-athena-export.py) you will notice that rather than the “»” to define the relationship between the tasks, we use the following:
check_athena_export_table.set_upstream(disp_variables)
you can use “.set_upstream” or “.set_downstream” to define the relationship between the tasks if you prefer.
Running the workflow
After committing the code you should have the workflows available in the Apache Airflow UI and can then trigger them via the UI. As each step starts, runs and then completes, you should be able to see the information and logs produced (including any of the Print statements included in the DAG).
Once the workflow has completed, you should now see back in the Amazon Athena console a new database (in my case, a new database called devdays_scifimovies) and within this I have a new table (in my case, I had a table called scifi which contained just a subset of the Movielens data that had been tagged with the scifi genre). If I explore the data lake on Amazon S3, and go to the Movielens folder, I notice that I now also have a new exported csv file which contains the same data.
{% youtube I0ghfwIL1ps %}
This completes the automation of those manual tasks. We have the new tables and we have exported new data into the data lake. Now that we have covered how to do this for Amazon Athena, in the next post we will cover Amazon EMR.
Take me to Post Two